A Self-Learning Fault Diagnosis Strategy Based on Multi-Model Fusion





Abstract
:1. Introduction
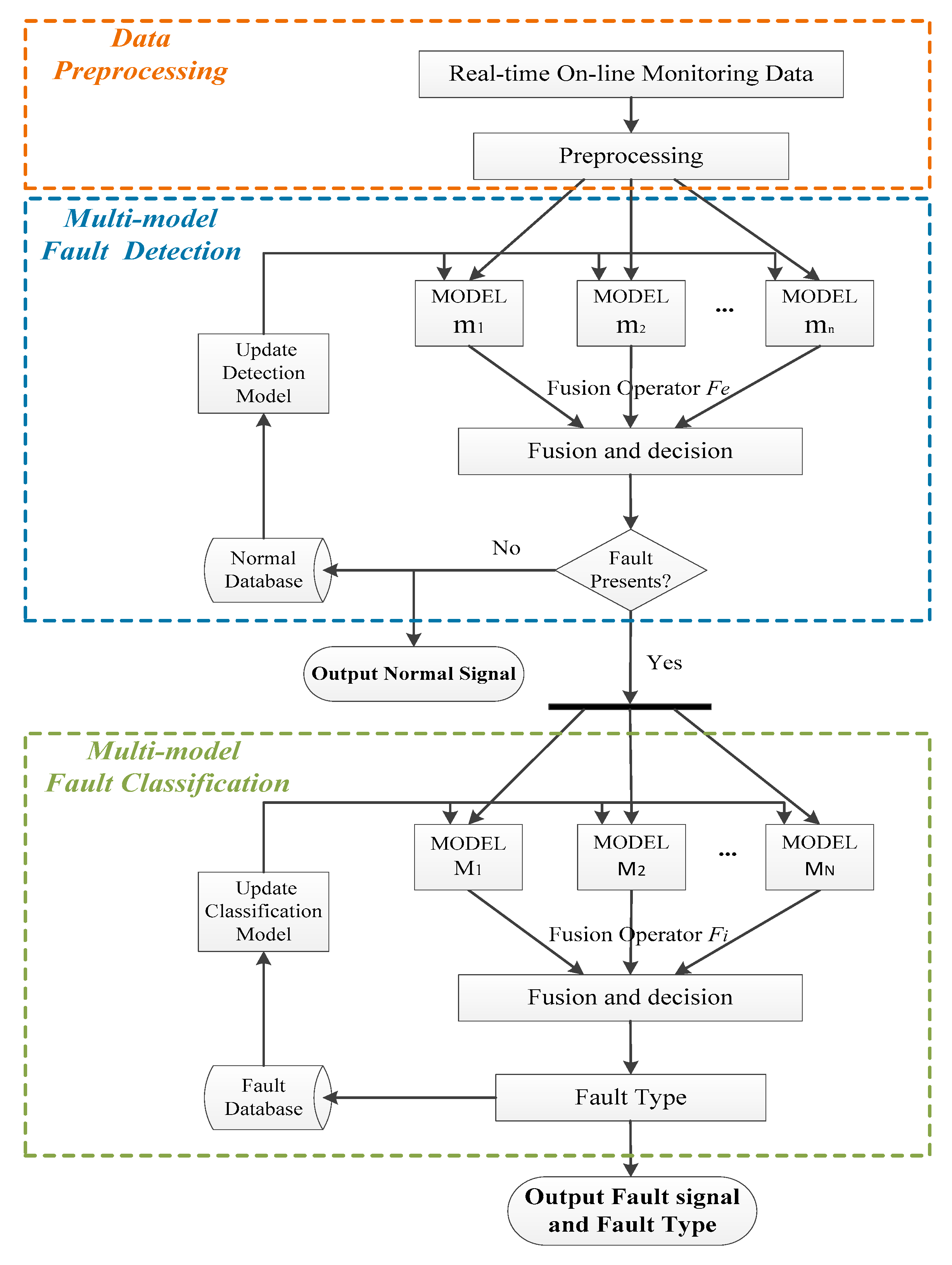
2. Fault Diagnosis Method
2.1. Fault Detection
- ➢
- The detection models we choose are different from each other, or they can be complementary, in order to decrease false alarms and missing alarm rates.
- ➢
- The detection models need to have a high detection accuracy to avoid a cumulative error.
- ➢
- As the detection models will run in parallel, judicious implementation approaches can be used in combination with a multi-core and graphics processing unit (GPU)-based system to reduce the computational time.
2.2. Fault Classification
- ➢
- The classification models are different from each other, in order to increase the classification accuracy.
- ➢
- The classification models need to have a high classification accuracy to avoid the occurrence of cumulative error.
- ➢
- The computational time of each classification model must be as short as possible. Indeed, for fault classification, the time constraint is less.
3. Case of Complex Condition
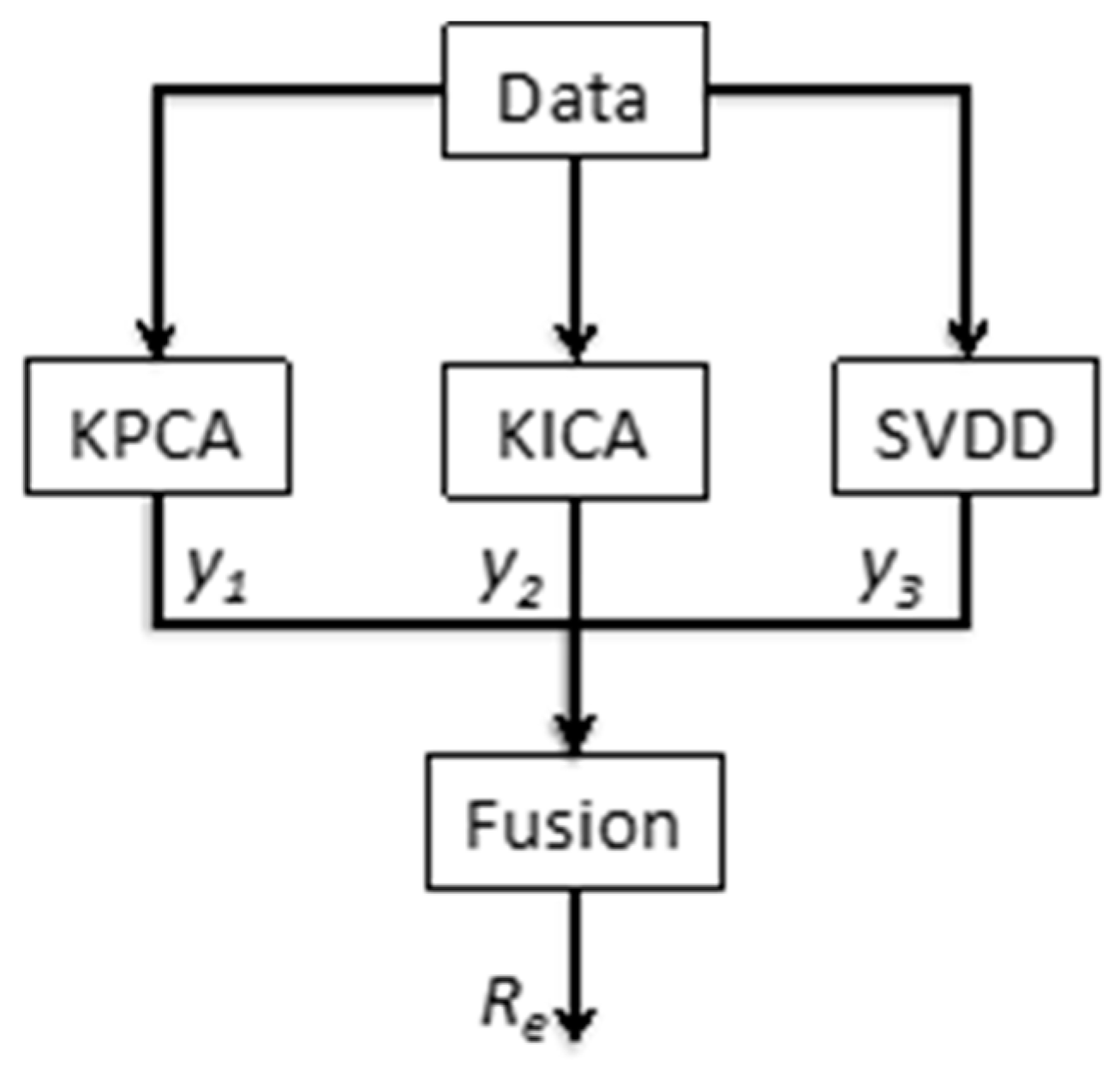
3.1. Fault Detection
3.2. Fault Classification
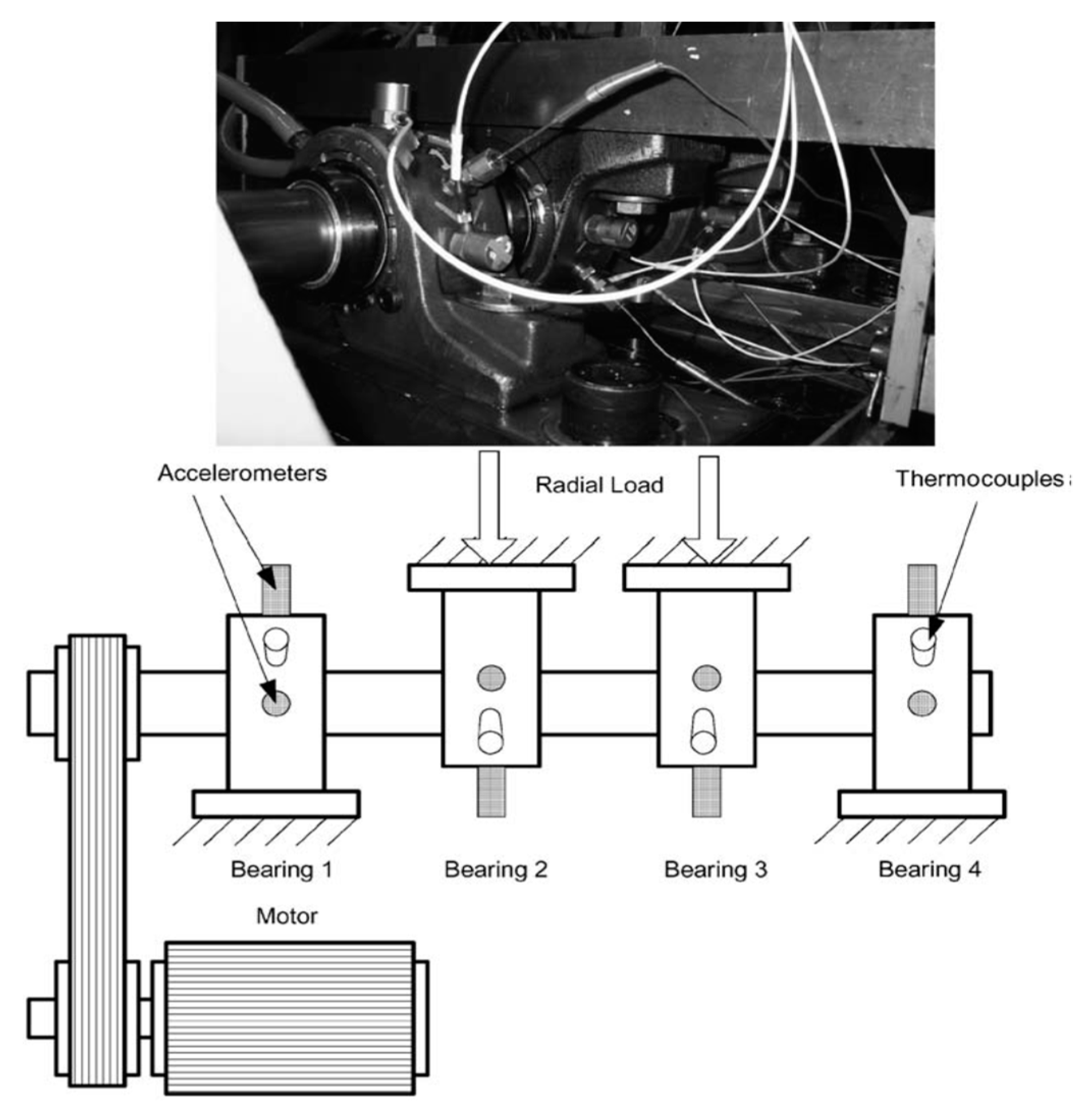
4. Experimental Results and Analysis
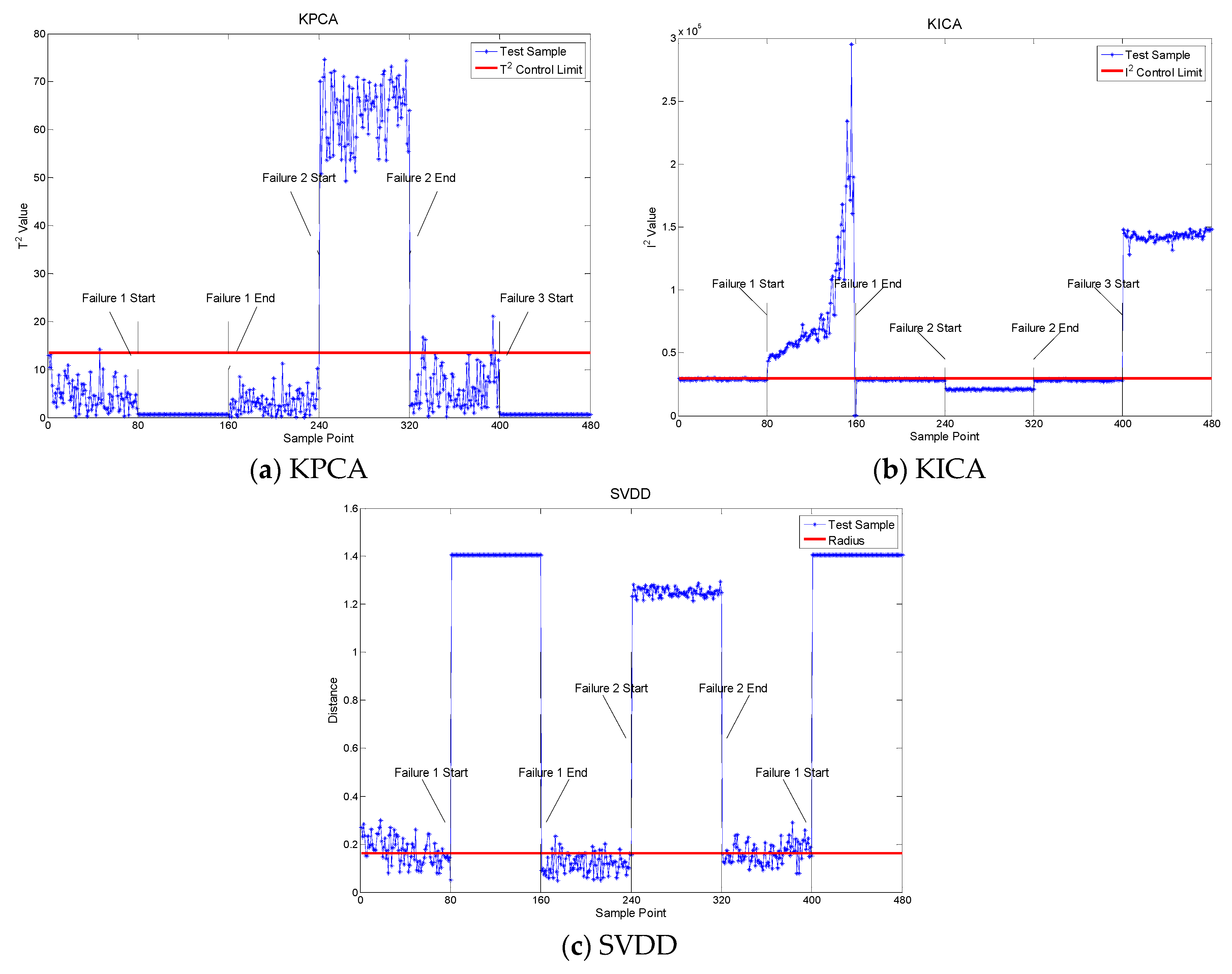
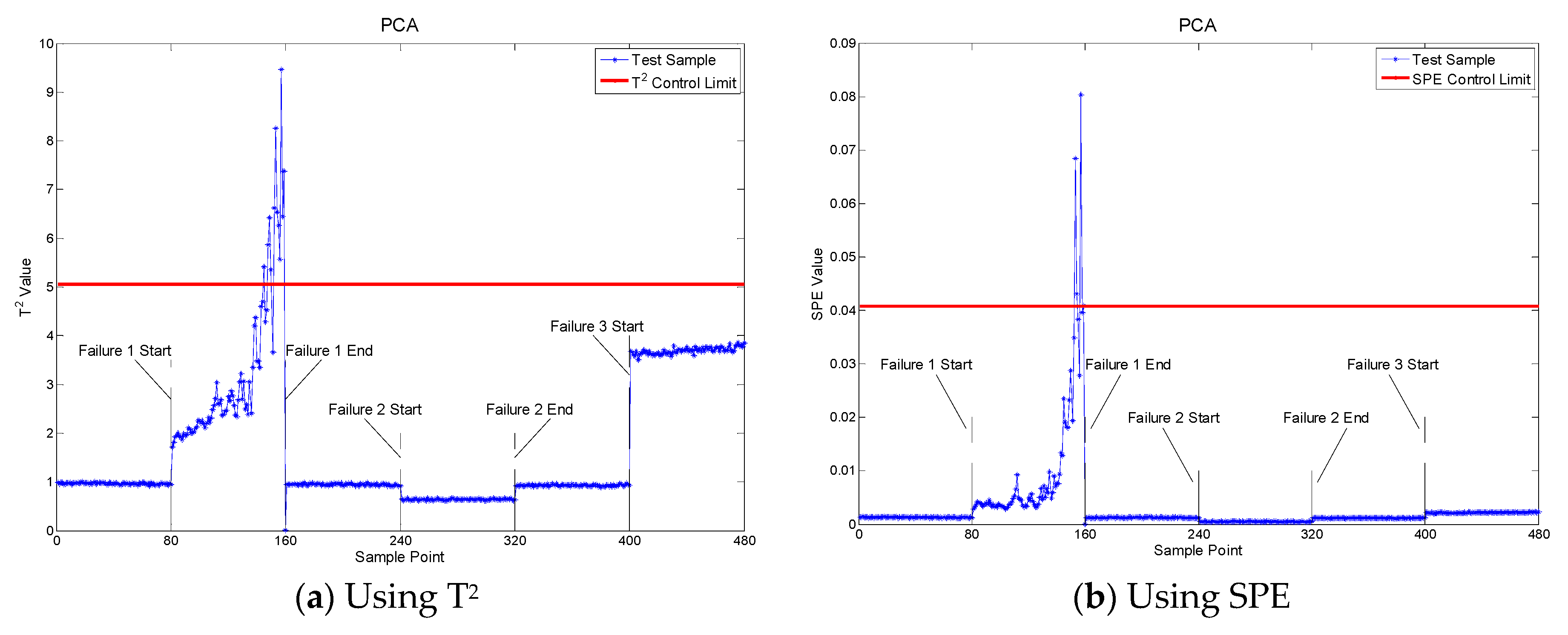
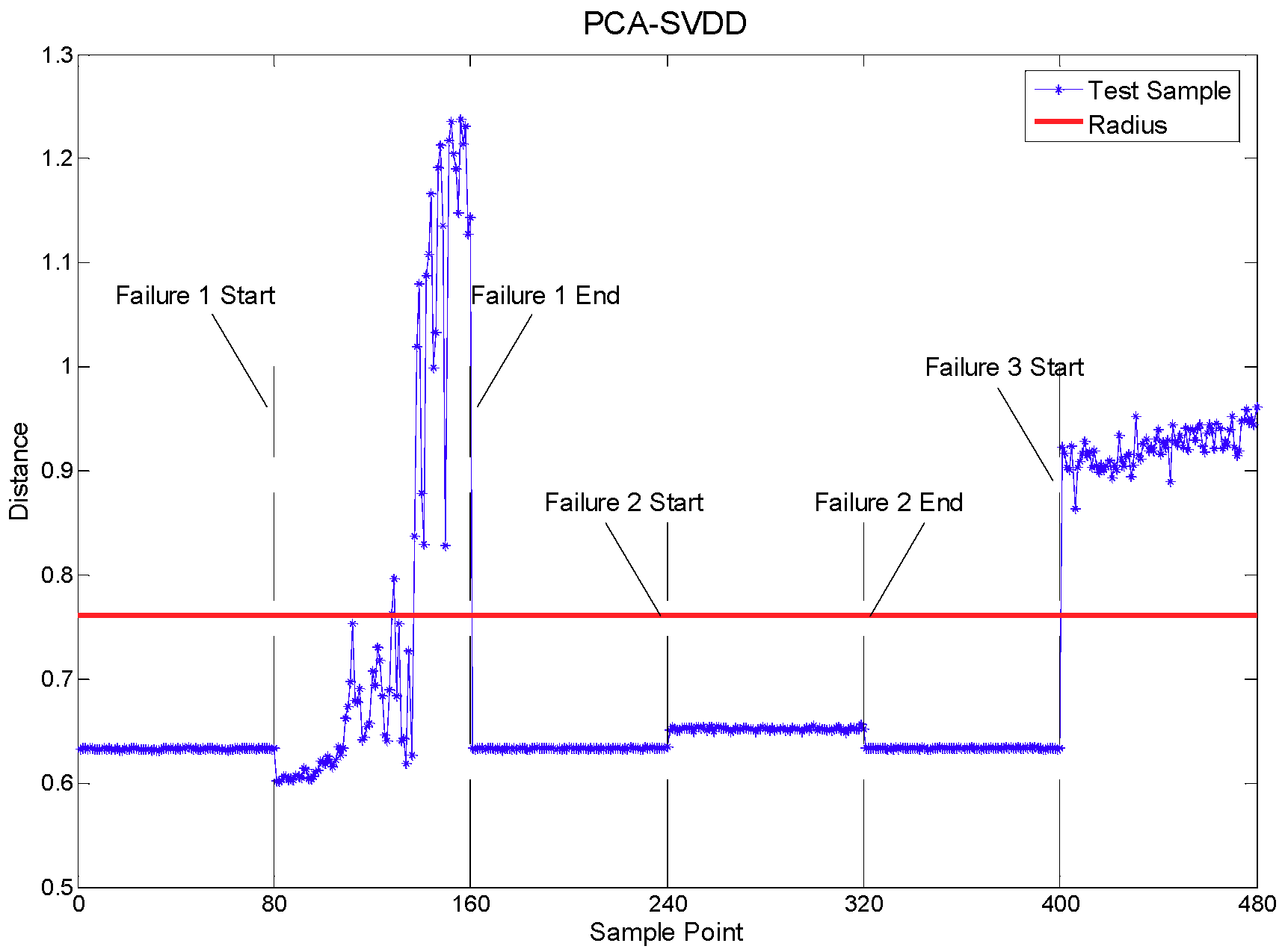
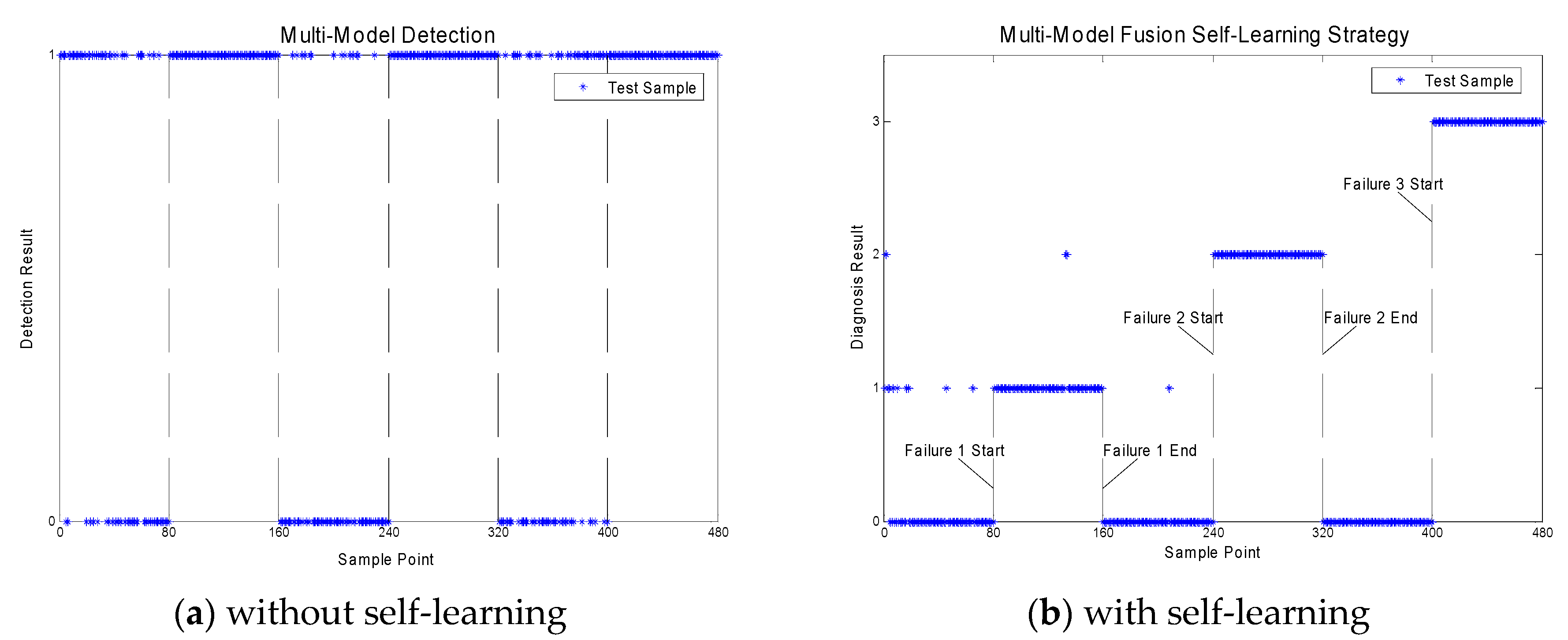
4.1. Fault Detection
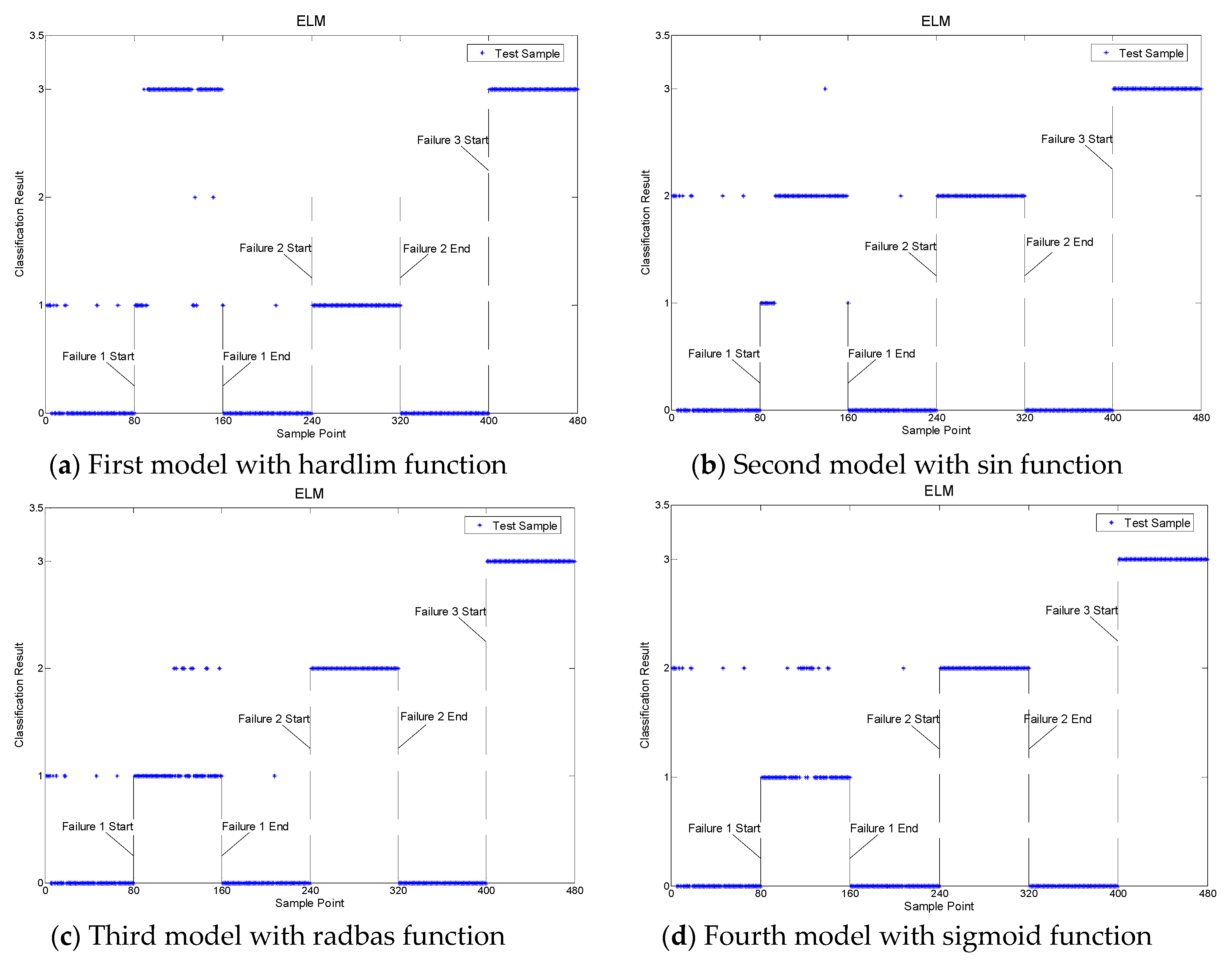
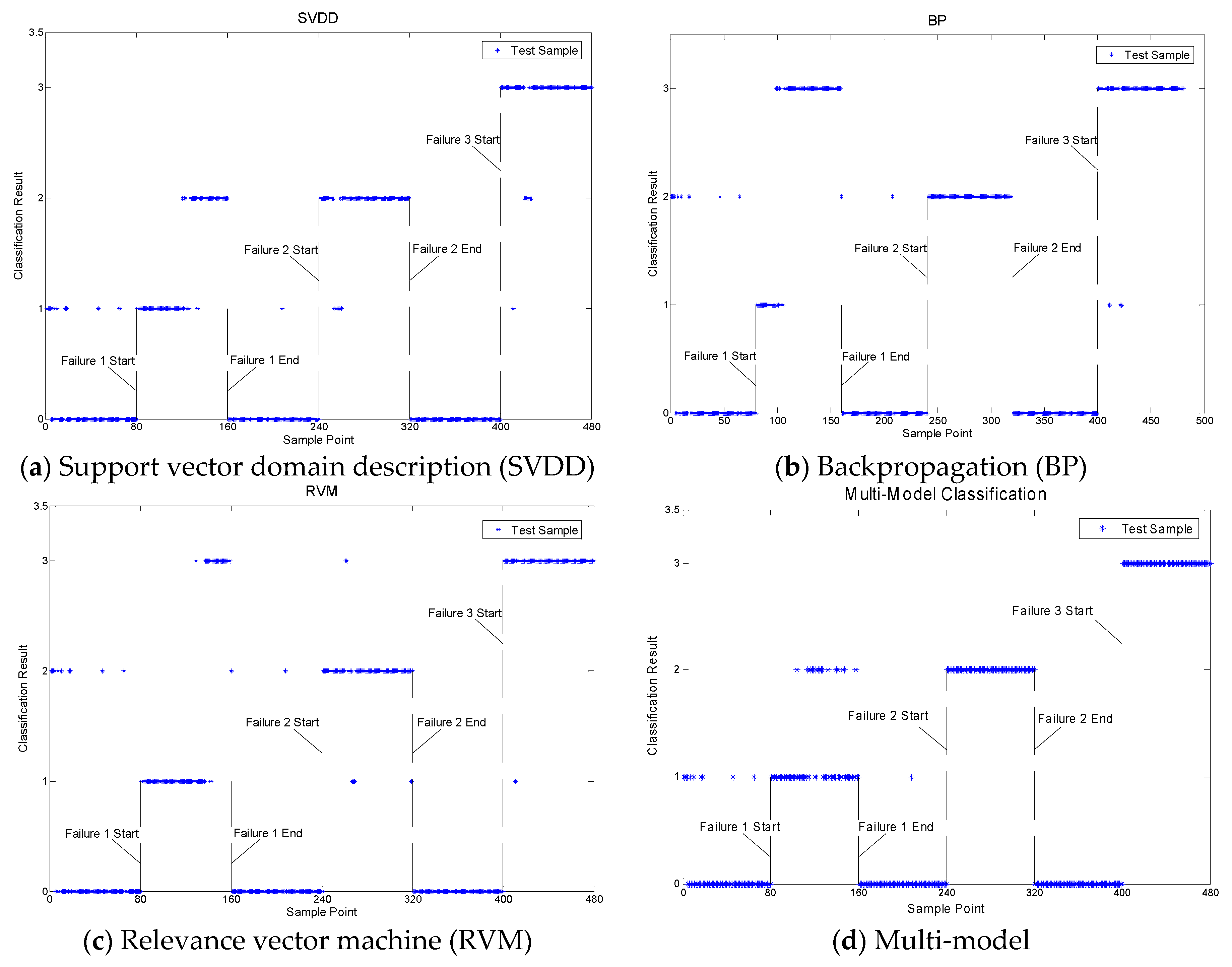
4.2. Fault Classification
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gao, Z.; Ding, S.; Cecati, C. Real-time fault diagnosis and fault-tolerant control. IEEE Trans. Ind. Electr. 2015, 62, 3752–3756. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Li, S.; Shen, X.; Wen, C. The optimal design of industrial alarm systems based on evidence theory. Control Eng. Practice 2016, 46, 142–156. [Google Scholar] [CrossRef]
- Wen, C.; Wang, Z.; Hu, J.; Liu, Q.; Alsaadi, F. Recursive filtering for state-saturated systems with randomly occurring nonlinearities and missing measurements. Int. J. Robust Nonlinearity Control 2018, 28, 1715–1727. [Google Scholar] [CrossRef]
- Wang, T.; Liu, L.; Zhang, J.; Schaeffer, E.; Wang, Y. A M-EKF fault detection strategy of insulation system for marine current turbine. Mechanical Syst. Signal Process. 2019, 115, 26–280. [Google Scholar] [CrossRef]
- Costamagna, P.; Giorgi, A.; Magistri, L.; Moser, G.; Pellaco, L.; Trucco, A. A Classification approach for model-based fault diagnosis in power generation systems based on solid oxide fuel cells. IEEE Trans. Energy Convers. 2016, 31, 676–687. [Google Scholar] [CrossRef]
- Wan, L.; Ding, F. Decomposition- and gradient-based iterative identification algorithms for multivariable systems using the multi-innovation theory. Circuits Syst. Signal Process. 2019, 38. [Google Scholar] [CrossRef]
- Li, Z.; Outbib, R.; Giurgea, S.; Hissel, D. Diagnosis for PEMFC systems: A data-driven approach with the capabilities of online adaptation and novel fault detection. IEEE Trans. Ind. Electr. 2015, 62, 5164–5174. [Google Scholar] [CrossRef]
- Ma, M.; Wong, D.; Jang, S.; Tseng, S. Fault detection based on statistical multivariate analysis and microarray visualization. IEEE Trans. Ind. Inform. 2010, 6, 18–24. [Google Scholar]
- Harmouche, J.; Delpha, C.; Diallo, D. Incipient fault detection and diagnosis based on Kullback–Leibler divergence using principal component analysis: Part I. Signal Process. 2014, 94, 278–287. [Google Scholar] [CrossRef]
- Harmouche, J.; Delpha, C.; Diallo, D. Incipient fault detection and diagnosis based on Kullback–Leibler divergence using principal component analysis: Part II. Signal Process. 2015, 109, 334–344. [Google Scholar] [CrossRef]
- Wang, T.; Xu, H.; Zhang, M.; Han, J.; Elbouchikhi, E.; Benbouzid, M.E.H. Cascaded H-bridge multilevel inverter system fault diagnosis using a PCA and multi-class relevance vector machine approach. IEEE Trans. Power Electr. 2015, 30, 7006–7018. [Google Scholar] [CrossRef]
- Jiang, Q.; Yan, X.; Huang, B. Performance-driven distributed PCA process monitoring based on fault-relevant variable selection and Bayesian inference. IEEE Trans. Ind. Electr. 2016, 63, 377–386. [Google Scholar] [CrossRef]
- Wang, T.; Wu, H.; Ni, M.; Zhang, M.; Dong, J.; Benbouzid, M.E.H. An adaptive confidence limit for periodic non-steady conditions fault detection. Mechanical Syst. Signal Process. 2016, 72–73, 328–345. [Google Scholar] [CrossRef]
- Yu, J. Bearing performance degradation assessment using locality preserving projections and Gaussian mixture models. Mechanical Syst. Signal Process. 2011, 25, 2573–2588. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z. A distribution-free method for process monitoring. Expert Syst. Appl. 2011, 38, 9821–9829. [Google Scholar] [CrossRef]
- Zhang, Y.; An, J.; Ma, C. Fault detection of non-Gaussian processes based on model migration. IEEE Trans. Control Syst. Tech. 2013, 21, 1517–1526. [Google Scholar] [CrossRef]
- Arnaut, L.; Obiekezie, C. Comparison of complex principal and independent components for quasi-Gaussian radiated emissions from printed circuit boards. IEEE Trans. Electromag. Compat. 2014, 56, 1598–1603. [Google Scholar] [CrossRef]
- Javidi, S.; Took, C.; Mandic, D. Fast independent component analysis algorithm for quaternion valued signals. IEEE Trans. Neural Netw. 2011, 22, 1967–1978. [Google Scholar] [CrossRef] [PubMed]
- Peng, K.; Zhang, K.; He, X.; Li, G.; Yang, X. New kernel independent and principal components analysis-based process monitoring approach with application to hot strip mill process. IET Control Theory Appl. 2014, 8, 1723–1731. [Google Scholar] [CrossRef]
- Papaioannou, A.; Zafeiriou, S. Principal component analysis with complex kernel: The widely linear model. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1719–1726. [Google Scholar] [CrossRef]
- Mehrabian, H.; Chopra, R.; Martel, A. Calculation of intravascular signal in dynamic contrast enhanced-MRI using adaptive complex independent component analysis. IEEE Trans. Medical Imag. 2013, 32, 699–710. [Google Scholar] [CrossRef] [PubMed]
- Schölkopf, B.; Smola, A.J. Learning with Kernels; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K. Kernel principal component analysis. Adv. Kernel Methods – Support Vector Learn. 2003, 27, 555–559. [Google Scholar]
- Li, D.; Liu, C. Extending attribute information for small data set classification. IEEE Trans. Knowledge Data Eng. 2012, 24, 452–464. [Google Scholar] [CrossRef]
- Ni, J.; Zhang, C.; Yang, S. An adaptive approach based on KPCA and SVM for real-time fault diagnosis of HVCBs. IEEE Trans. Power Deliv. 2011, 26, 1960–1971. [Google Scholar] [CrossRef]
- Kocsor, A.; Toth, L. Kernel-based feature extraction with a speech technology application. IEEE Trans. Signal Process. 2004, 52, 2250–2263. [Google Scholar] [CrossRef]
- Zhou, F.; Park, J.; Liu, Y.; Wen, C. Differential feature based hierarchical PCA fault detection method for dynamic fault. Neurocomputing 2016, 202, 27–35. [Google Scholar] [CrossRef]
- Ge, Z. Process data analytics via probabilistic latent variable models: A tutorial review. Ind. Eng. Chem. Res. 2018, 57, 12646–12661. [Google Scholar] [CrossRef]
- Wang, Y.; Ding, F. A filtering based multi-innovation gradient estimation algorithm and performance analysis for nonlinear dynamical systems. IMA J. Appl. Math. 2017, 82, 1171–1191. [Google Scholar] [CrossRef]
- Li, Z.; Kruger, U.; Xie, L.; Almansoori, A.; Su, H. Adaptive KPCA Modeling of Nonlinear System. IEEE Trans. Signal Process. 2015, 63, 2364–2376. [Google Scholar] [CrossRef]
- Cai, L.; Tian, X.; Chen, S. Monitoring nonlinear and non-Gaussian processes using Gaussian mixture model-based weighted kernel independent component analysis. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 122–135. [Google Scholar] [CrossRef]
- Vapnik, V. Universal learning technology: Support vector machines. NEC J. Adv. Tech. 2005, 2, 137–144. [Google Scholar]
- Wang, T.; Qi, J.; Xu, H.; Wang, Y.; Liu, L.; Gao, D. Fault diagnosis method based on FFT-RPCA-SVM for cascaded-multilevel inverter. ISA Trans. 2016, 60, 156–163. [Google Scholar] [CrossRef] [PubMed]
- Tax, D.; Duin, R. Support vector data description. Machine Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Dong, J.; Wang, T.; Tang, T.; Benbouzid, M.E.H.; Liu, Z.; Gao, D. Application of a KPCA-KICA-HSSVM hybrid strategy in bearing fault detection. In Proceedings of the 2016 IEEE IPEMC ECCE ASIA, Hefei, China, 22–26 May 2016; pp. 1863–1867. [Google Scholar]
- Lee, J.; Qiu, H.; Yu, G.; Lin, J. Rexnord Technical Services. Bearing Data Set. IMS, University of Cincinnati, NASA Ames Prognostics Data Repository. 2007. Available online: http://data-acoustics.com/measurements/bearing-faults/bearing-4/ (accessed on 1 December 2018).
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet filter-based weak signature detection method and its application on roller bearing prognostics. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]
- Xu, X.; Zheng, J.; Yang, J.; Xu, D.; Chen, Y. Data classification using evidence reasoning rule. Knowl. Based Syst. 2017, 116, 144–151. [Google Scholar] [CrossRef] [Green Version]
- Wen, C.; Wang, Z.; Liu, Q.; Alsaadi, F. Recursive distributed filtering for a class of state-saturated systems with fading measurements and quantization effects. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 930–941. [Google Scholar] [CrossRef]
- Wang, Y.; Ding, F.; Wu, M. Recursive parameter estimation algorithm for multivariate output-error systems. J. Frankl. Inst. 2018, 355, 5163–5181. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, Y. Analytic hierarchy process based fuzzy decision fusion system for model prioritization and process monitoring application. IEEE Trans. Ind. Inform. 2019, 15, 357–365. [Google Scholar] [CrossRef]
- Luo, Y.; Wang, Z.; Wei, G.; Alsaadi, F. Non-fragile fault estimation for Markovian jump 2-D systems with specified power bounds. IEEE Trans. Syst. Man Cybern. Syst. 2018. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Files Sections | Healthy/Faulty |
|---|---|
| 1–80 | Normal |
| 81–160 | Fault 1: Outer race failure in bearing 1 |
| 161–240 | Normal |
| 241–320 | Fault 2: Outer race failure in bearing 3 |
| 321–400 | Normal |
| 401–480 | Fault 3: inner race failure in bearing 3 |
| Approach | False Alarm Rate (%) | Missing Alarm Rate (%) | |
|---|---|---|---|
| KPCA | 1.04 | 33.33 | |
| KICA | 3.13 | 17.08 | |
| SVDD | 19.17 | 0.0 | |
| PCA | T2 | 0.0 | 47.50 |
| SPE | 0.0 | 49.17 | |
| PCA-SVDD | 0.0 | 27.92 | |
| Multi-model Detection | 19.38 | 0.0 | |
| Proposed Strategy | 2.29 | 0.0 | |
| Approach | Classification Accuracy | |||
|---|---|---|---|---|
| Fault 1 | Fault 2 | Fault 3 | Overall | |
| ELM | 40.5/80 | 60/80 | 80/80 | 75.20% |
| SVDD | 44/80 | 74/80 | 73/80 | 79.58% |
| BP | 22/80 | 80/80 | 77/80 | 74.58% |
| RVM | 56/80 | 74/80 | 79/80 | 87.08% |
| Multi-model | 62/80 | 80/80 | 80/80 | 92.50% |
| Proposed Strategy | 78/80 | 80/80 | 80/80 | 99.17% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.; Dong, J.; Xie, T.; Diallo, D.; Benbouzid, M. A Self-Learning Fault Diagnosis Strategy Based on Multi-Model Fusion. Information 2019, 10, 116. https://doi.org/10.3390/info10030116
Wang T, Dong J, Xie T, Diallo D, Benbouzid M. A Self-Learning Fault Diagnosis Strategy Based on Multi-Model Fusion. Information. 2019; 10(3):116. https://doi.org/10.3390/info10030116
Chicago/Turabian StyleWang, Tianzhen, Jingjing Dong, Tao Xie, Demba Diallo, and Mohamed Benbouzid. 2019. "A Self-Learning Fault Diagnosis Strategy Based on Multi-Model Fusion" Information 10, no. 3: 116. https://doi.org/10.3390/info10030116
APA StyleWang, T., Dong, J., Xie, T., Diallo, D., & Benbouzid, M. (2019). A Self-Learning Fault Diagnosis Strategy Based on Multi-Model Fusion. Information, 10(3), 116. https://doi.org/10.3390/info10030116