Optimal Feature Aggregation and Combination for Two-Dimensional Ensemble Feature Selection


Abstract
:1. Introduction
- Optimal number of ensembles: because the basis of an ensemble is a partition, it is necessary to know the optimal number of partitions. Our research [32] on ensemble feature selection showed that five partitions are better than three and seven.
- Stability of feature selection: this relates to how well the ensemble feature selection produces the same selected features each time.
- Scalability: a conventional feature selection is less efficient in handling big data problems. Logically, ensemble feature selection can handle this problem because of the partition.
- Threshold for rankers: the problem of each feature selection algorithm that uses a filter approach is determining the threshold for the ranker. This threshold determines the number of reduced features.
- Feature aggregation: this problem is related to how to combine features from each subset in the ensemble to produce the most relevant features.
- Explainability: the main problem faced by each algorithm beyond feature selection is clarity of the results obtained. Researchers usually use two approaches, i.e., mathematical proofing or empirical proofing.
2. Materials and Methods
2.1. Resources
2.2. Dataset
2.2.1. Artificial Data
2.2.2. Image Data
2.2.3. Medical Record Data
2.3. Methods
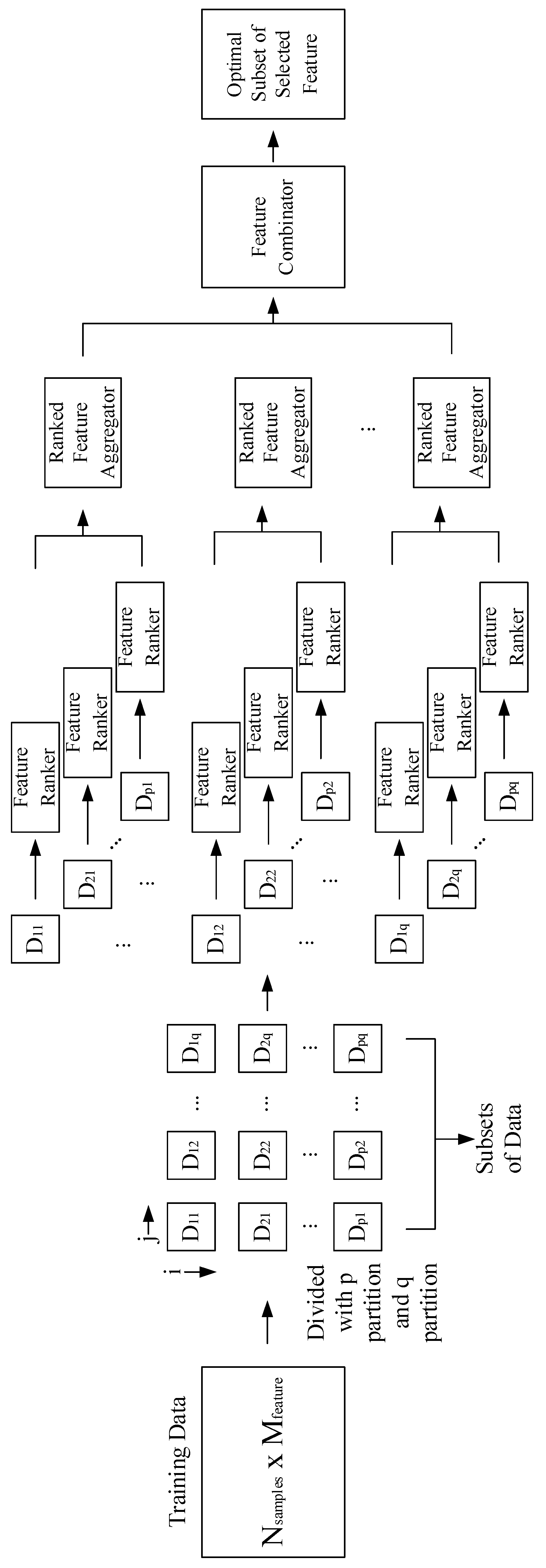
2.3.1. Data Partitioning
2.3.2. Feature Ranker
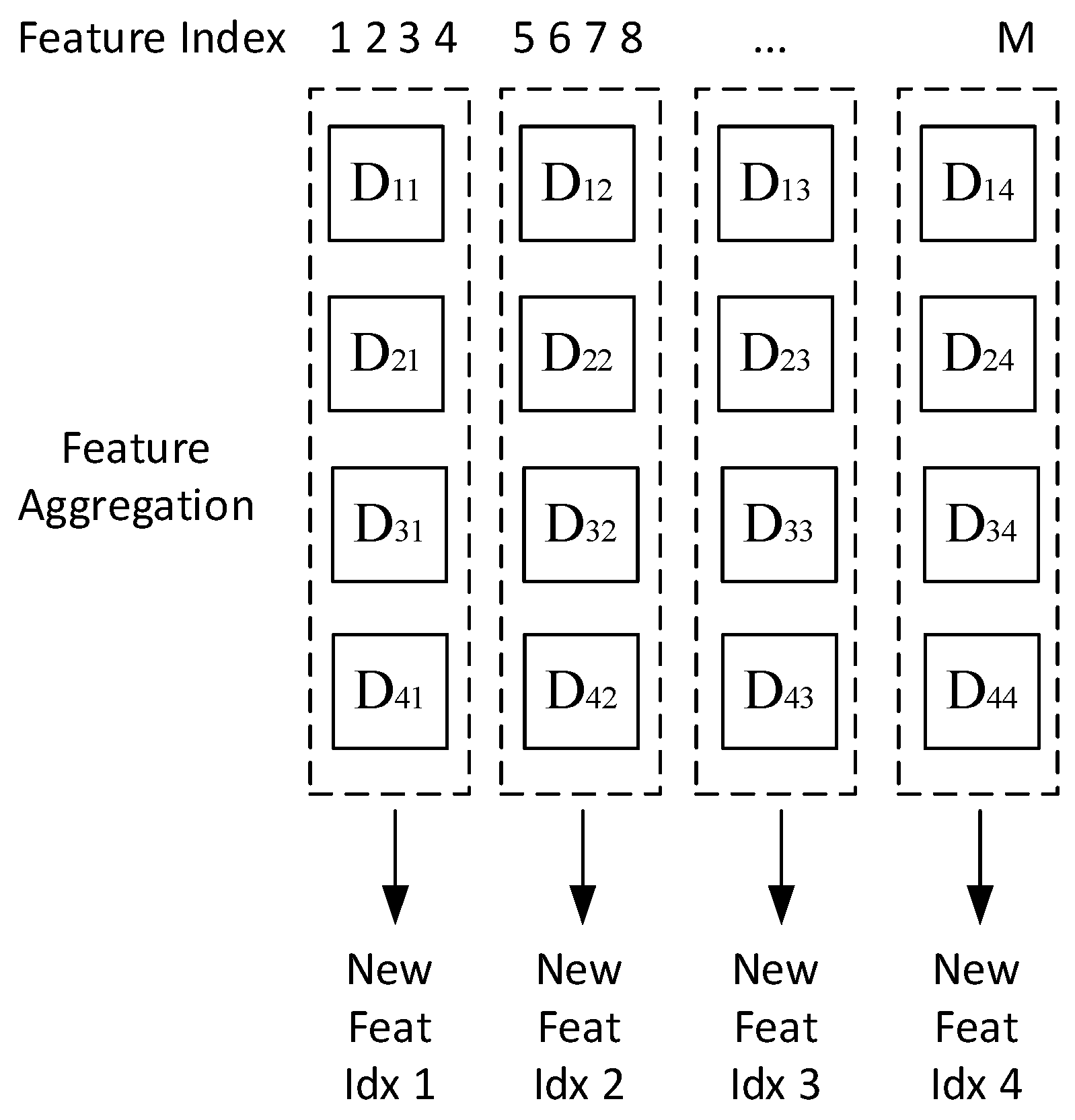
2.3.3. Ranked Feature Aggregator
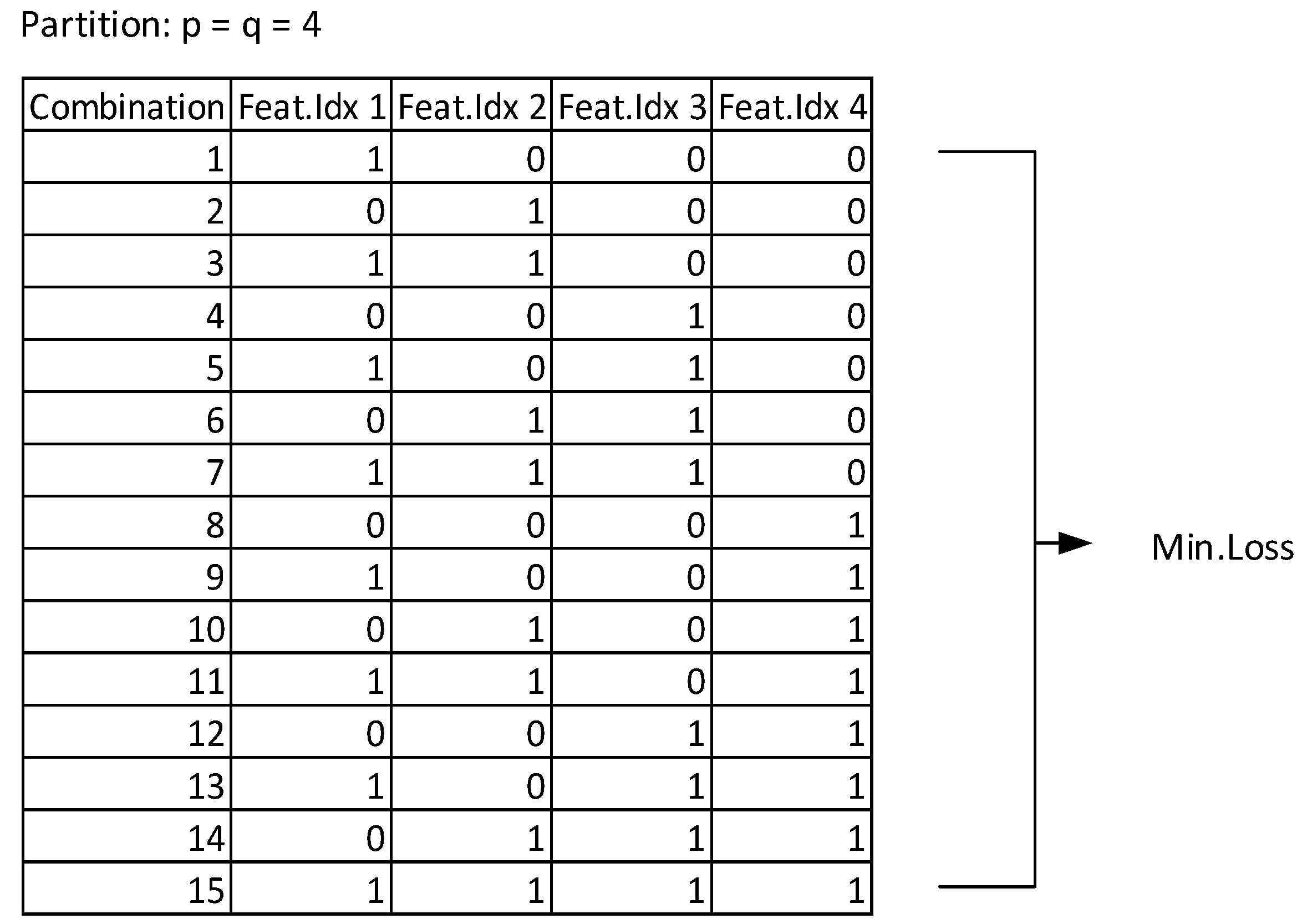
2.3.4. Feature Combinator
2.4. Evaluations
3. Results and Discussion
3.1. Feature Selection Performance
3.2. Overall Performance
3.3. Subset of Relevant Features
3.4. Stability Measurement
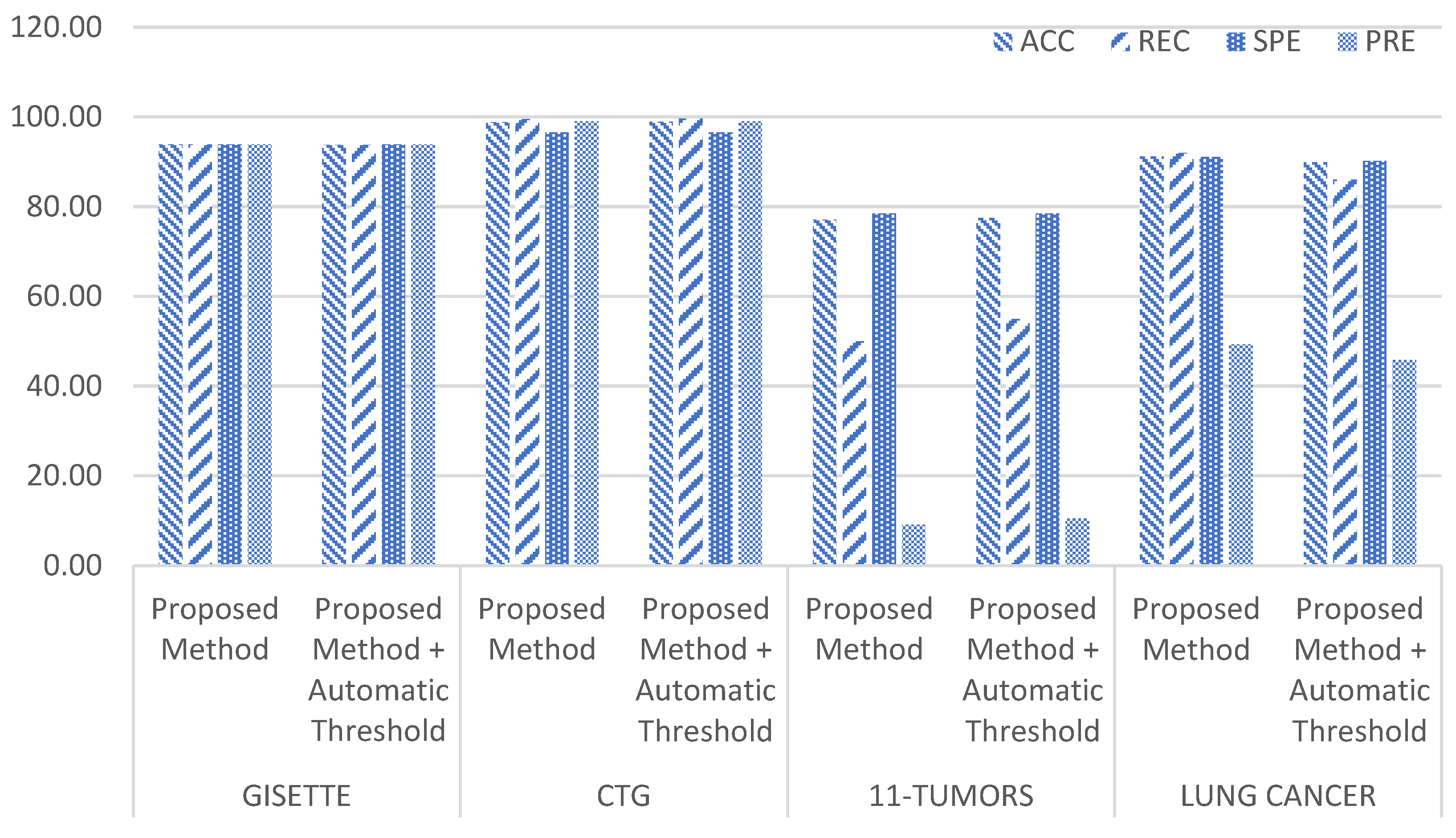
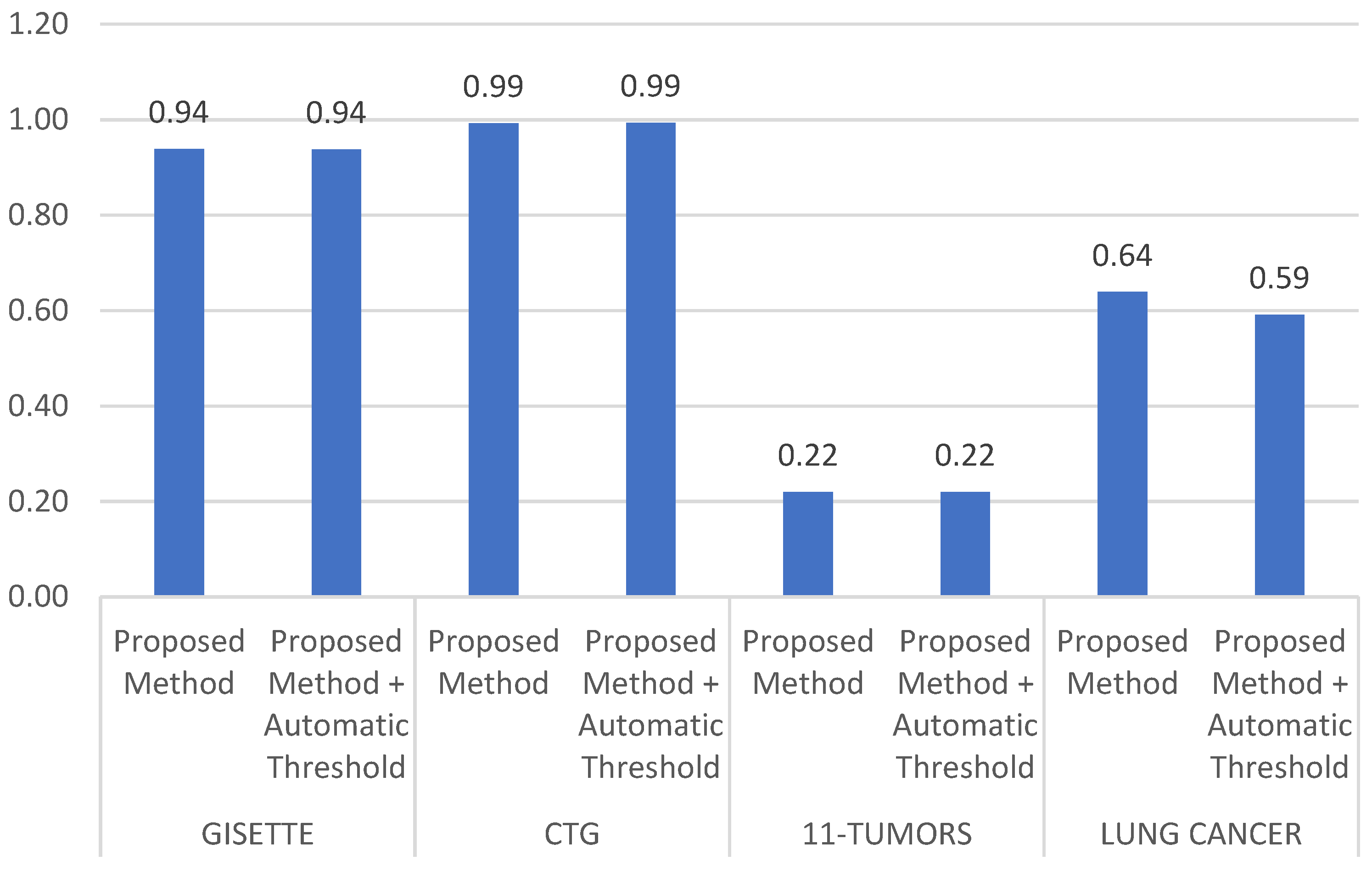
3.5. Applying Automatic Threshold
4. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Durgabai, R.P.L. Feature Selection using ReliefF Algorithm. Int. J. Adv. Res. Comput. Commun. Eng. 2014, 3, 8215–8218. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. Feature selection problem: Traditional methods and a new algorithm. In Proceedings of the Tenth National Conference on Artificial Intelligence, San Jose, CA, USA, 12–16 July 1992. [Google Scholar]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In Proceedings of the Machine Learning: ECML-94; Bergadano, F., De Raedt, L., Eds.; Springer: Berlin/Heidelberg, Germany, 1994; pp. 171–182. [Google Scholar]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the Myopia of Inductive Learning Algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- Urbanowicz, R.J.; Meeker, M.; La Cava, W.; Olson, R.S.; Moore, J.H. Relief-based feature selection: Introduction and review. J. Biomed. Inform. 2018, 85, 189–203. [Google Scholar] [CrossRef]
- Hall, M. Correlation-Based Feature Selection for Machine Learning. Master’s Thesis, University of Waikato Hamilton, Hamilton, New Zealand, 1999. [Google Scholar]
- Chormunge, S.; Jena, S. Correlation based feature selection with clustering for high dimensional data. J. Electr. Syst. Inf. Technol. 2018, 5, 542–549. [Google Scholar] [CrossRef]
- Kohavi, R.H.; John, G. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Foithong, S.; Pinngern, O.; Attachoo, B. Feature subset selection wrapper based on mutual information and rough sets. Expert Syst. Appl. 2012, 39, 574–584. [Google Scholar] [CrossRef]
- Lee, S.J.; Xu, Z.; Li, T.; Yang, Y. A novel bagging C4.5 algorithm based on wrapper feature selection for supporting wise clinical decision making. J. Biomed. Inform. 2018, 78, 144–155. [Google Scholar] [CrossRef]
- Wang, A.; An, N.; Chen, G.; Li, L.; Alterovitz, G. Accelerating wrapper-based feature selection with K-nearest-neighbor. Knowl.-Based Syst. 2015, 83, 81–91. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.B. Feature selection based convolutional neural network pruning and its application in calibration modeling for NIR spectroscopy. Chemom. Intell. Lab. Syst. 2019, 191, 103–108. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, G.; Dong, Z.; Crawford, C. Embedded feature-selection support vector machine for driving pattern recognition. J. Frankl. Inst. 2015, 352, 669–685. [Google Scholar] [CrossRef]
- Rajeswari, K.; Vaithiyanathan, V.; Neelakantan, T.R. Feature Selection in Ischemic Heart Disease identification using feed forward neural networks. Procedia Eng. 2012, 41, 1818–1823. [Google Scholar] [CrossRef] [Green Version]
- Ghaemi, M.; Feizi-Derakhshi, M.-R. Feature selection using Forest Optimization Algorithm. Pattern Recognit. 2016, 60, 121–129. [Google Scholar] [CrossRef]
- Das, A.K.; Das, S.; Ghosh, A. Ensemble feature selection using bi-objective genetic algorithm. Knowl.-Based Syst. 2017, 123, 116–127. [Google Scholar] [CrossRef]
- Singh, S.; Singh, A.K. Web-Spam Features Selection Using CFS-PSO. Procedia Comput. Sci. 2018, 125, 568–575. [Google Scholar] [CrossRef]
- Kar, S.; Sharma, K.D.; Maitra, M. Gene selection from microarray gene expression data for classification of cancer subgroups employing PSO and adaptive K-nearest neighborhood technique. Expert Syst. Appl. 2015, 42, 612–627. [Google Scholar] [CrossRef]
- Vafaee Sharbaf, F.; Mosafer, S.; Moattar, M.H. A hybrid gene selection approach for microarray data classification using cellular learning automata and ant colony optimization. Genomics 2016, 107, 231–238. [Google Scholar] [CrossRef]
- Ebrahimpour, M.K.; Eftekhari, M. Ensemble of feature selection methods: A hesitant fuzzy sets approach. Appl. Soft Comput. J. 2017, 50, 300–312. [Google Scholar] [CrossRef]
- Sheeja, T.K.; Kuriakose, A.S. A novel feature selection method using fuzzy rough sets. Comput. Ind. 2018, 97, 111–121. [Google Scholar] [CrossRef]
- Wang, L.; Meng, J.; Huang, R.; Zhu, H.; Peng, K. Incremental feature weighting for fuzzy feature selection. Fuzzy Sets Syst. 2019, 368, 1–19. [Google Scholar] [CrossRef]
- Chen, J.; Mi, J.; Lin, Y. A graph approach for fuzzy-rough feature selection. Fuzzy Sets Syst. 2019, 1. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, X.; Li, L.; Wang, X.; Wang, D. A novel multi-attribute decision making method based on the double hierarchy hesitant fuzzy linguistic generalized power aggregation operator. Information 2019, 10, 339. [Google Scholar] [CrossRef] [Green Version]
- Xia, J.; Liao, W.; Chanussot, J.; Du, P.; Song, G.; Philips, W. Improving Random Forest With Ensemble of Features and Semisupervised Feature Extraction. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1471–1475. [Google Scholar]
- Seijo-Pardo, B.; Porto-Díaz, I.; Bolón-Canedo, V.; Alonso-Betanzos, A. Ensemble feature selection: Homogeneous and heterogeneous approaches. Knowl.-Based Syst. 2017, 118, 124–139. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Seijo-Pardo, B.; Bolón-Canedo, V.; Alonso-Betanzos, A. On developing an automatic threshold applied to feature selection ensembles. Inf. Fusion 2019, 45, 227–245. [Google Scholar] [CrossRef]
- Drotár, P.; Gazda, M.; Vokorokos, L. Ensemble feature selection using election methods and ranker clustering. Inf. Sci. 2019, 480, 365–380. [Google Scholar] [CrossRef]
- Chiew, K.L.; Tan, C.L.; Wong, K.S.; Yong, K.S.C.; Tiong, W.K. A new hybrid ensemble feature selection framework for machine learning-based phishing detection system. Inf. Sci. 2019, 484, 153–166. [Google Scholar] [CrossRef]
- Alhamidi, M.R.; Arsa, D.M.S.; Rachmadi, M.F.; Jatmiko, W. 2-Dimensional homogeneous distributed ensemble feature selection. In Proceedings of the 2018 International Conference on Advanced Computer Science and Information Systems, ICACSIS 2018, Yogyakarta, Indonesia, 27–28 October 2018. [Google Scholar]
- Dowlatshahi, M.B.; Derhami, V.; Nezamabadi-Pour, H. Ensemble of filter-based rankers to guide an epsilon-greedy swarm optimizer for high-dimensional feature subset selection. Information 2017, 8, 152. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I. NIPS 2003 Workshop on Feature Extraction and Feature Selection Challenge. Available online: http://clopinet.com/isabelle/Projects/NIPS2003/#links (accessed on 17 July 2018).
- Feature Selection Dataset. Available online: http://featureselection.asu.edu/datasets.php (accessed on 2 April 2018).
- Dheeru, D.; Karra Taniskidou, E. Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 2 April 2018).
- Gene Expression Model Selector. Available online: http://gems-system.org (accessed on 10 May 2018).
- Mohana Chelvan, P.; Perumal, K. A Survey on Feature Selection Stability Measures. Int. J. Comput. Inf. Technol. 2016, 5, 98–103. [Google Scholar]
- Khaire, U.M.; Dhanalakshmi, R. Stability of feature selection algorithm: A review. J. King Saud Univ. Comput. Inf. Sci. 2019, in press. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Datasets | Categories | # of Samples | # of Features | # of Classes | Source |
|---|---|---|---|---|---|---|
| 1 | MADELON | Artificial data | 2600 | 500 | 2 | [34] |
| 2 | COIL20 | Image data | 1440 | 1024 | 20 | [35] |
| 3 | GISETTE | 7000 | 5000 | 2 | [34] | |
| 4 | USPS | 9298 | 256 | 10 | [35] | |
| 5 | YALE | 165 | 1024 | 15 | [35] | |
| 6 | ORL | 400 | 1024 | 40 | [35] | |
| 7 | CTG | Medical record data | 2126 | 23 | 3 | [36] |
| 8 | 11-TUMORS | 174 | 12,533 | 11 | [37] | |
| 9 | LUNG CANCER | 203 | 12,600 | 5 | [37] | |
| 10 | TOX_171 | 171 | 5748 | 4 | [35] | |
| 11 | PROSTATE_GE | 102 | 5966 | 2 | [35] | |
| 12 | GLI_85 | 85 | 22,283 | 2 | [35] | |
| 13 | LYMPHOMA | 96 | 4026 | 9 | [35] | |
| 14 | SMK_CAN_187 | 187 | 19,993 | 2 | [35] |
| Datasets | Algorithms | ACC | REC | SPE | PRE | F1 |
|---|---|---|---|---|---|---|
| MADELON | ReliefF | 75.26 | 73.85 | 76.67 | 75.99 | 0.75 |
| CFS | 48.21 | 51.79 | 44.62 | 48.33 | 0.50 | |
| mRMR | 70.00 | 73.08 | 66.92 | 68.84 | 0.71 | |
| FCBF | 69.87 | 67.95 | 71.79 | 70.67 | 0.69 | |
| COIL20 | ReliefF | 94.44 | 100.00 | 94.15 | 47.83 | 0.65 |
| CFS | 93.98 | 100.00 | 93.66 | 45.83 | 0.63 | |
| mRMR | 94.21 | 100.00 | 93.90 | 46.81 | 0.64 | |
| FCBF | 92.59 | 100.00 | 92.20 | 40.74 | 0.58 | |
| USPS | ReliefF | 88.45 | 95.48 | 87.05 | 59.60 | 0.73 |
| CFS | 89.17 | 96.13 | 87.78 | 61.15 | 0.75 | |
| mRMR | 89.60 | 94.84 | 88.55 | 62.38 | 0.75 | |
| FCBF | 86.20 | 93.98 | 84.64 | 55.04 | 0.69 | |
| CTG | ReliefF | 98.27 | 99.40 | 94.33 | 98.40 | 0.99 |
| CFS | 96.86 | 98.19 | 92.20 | 97.79 | 0.98 | |
| mRMR | 86.03 | 94.15 | 57.45 | 88.61 | 0.91 | |
| FCBF | 97.65 | 98.39 | 95.04 | 98.59 | 0.98 | |
| 11-TUMORS | ReliefF | 67.31 | 50.00 | 68.00 | 5.88 | 0.11 |
| CFS | 61.54 | 0.00 | 64.00 | 0.00 | NaN | |
| mRMR | 76.92 | 50.00 | 78.00 | 8.33 | 0.14 | |
| FCBF | 55.77 | 0.00 | 58.00 | 0.00 | NaN |
| Datasets | Algorithms | ACC | REC | SPE | PRE | F1 | # of Selected Features |
|---|---|---|---|---|---|---|---|
| MADELON | ReliefF | 75.59 | 75.54 | 75.64 | 75.67 | 0.76 | 125 |
| 2D ensemble | 69.77 | 69.74 | 69.79 | 69.75 | 0.70 | 108.5 | |
| Proposed Method | 73.15 | 73.18 | 73.13 | 73.15 | 0.73 | 58.9 | |
| COIL20 | ReliefF | 93.43 | 98.61 | 93.15 | 43.90 | 0.61 | 256 |
| 2D ensemble | 95.42 | 100.00 | 95.17 | 52.60 | 0.69 | 224.1 | |
| Proposed Method | 96.00 | 99.09 | 95.83 | 55.81 | 0.71 | 157.1 | |
| GISETTE | ReliefF | 93.29 | 92.74 | 93.84 | 93.78 | 0.93 | 1250 |
| 2D ensemble | 93.28 | 93.05 | 93.51 | 93.49 | 0.93 | 1091.9 | |
| Proposed Method | 93.87 | 93.86 | 93.88 | 93.88 | 0.94 | 700.7 | |
| USPS | ReliefF | 88.64 | 95.88 | 87.19 | 60.06 | 0.74 | 64 |
| 2D ensemble | 90.12 | 95.85 | 88.97 | 63.56 | 0.76 | 57.6 | |
| Proposed Method | 90.12 | 95.85 | 88.97 | 63.56 | 0.76 | 57.6 | |
| YALE | ReliefF | 54.69 | 58.33 | 54.41 | 9.25 | 0.16 | 256 |
| 2D ensemble | 56.33 | 70.00 | 55.43 | 9.38 | NaN | 222.9 | |
| Proposed Method | 60.00 | 66.67 | 59.57 | 9.88 | 0.17 | 143 | |
| ORL | ReliefF | 60.83 | 50.00 | 61.11 | 3.16 | 0.07 | 256 |
| 2D ensemble | 64.08 | 43.33 | 64.62 | 2.99 | 0.06 | 224.4 | |
| Proposed Method | 66.00 | 56.67 | 66.24 | 4.04 | 0.08 | 127.9 | |
| CTG | ReliefF | 98.43 | 99.23 | 95.59 | 98.76 | 0.99 | 6.00 |
| 2D ensemble | 98.60 | 99.38 | 95.88 | 98.84 | 0.99 | 4.5 | |
| Proposed Method | 98.85 | 99.52 | 96.52 | 99.02 | 0.99 | 2.7 | |
| 11-TUMORS | ReliefF | 71.54 | 80.00 | 71.20 | 13.33 | 0.23 | 3134 |
| 2D ensemble | 74.04 | 55.00 | 75.04 | 9.08 | 0.22 | 2715.6 | |
| Proposed Method | 77.12 | 50.00 | 78.47 | 9.13 | 0.22 | 1320.5 | |
| LUNG CANCER | ReliefF | 89.50 | 74.00 | 90.91 | 47.30 | 0.56 | 3150 |
| 2D ensemble | 90.00 | 82.00 | 90.73 | 44.23 | 0.57 | 3151.5 | |
| Proposed Method | 93.33 | 94.00 | 93.27 | 56.35 | 0.70 | 866.8 | |
| TOX_171 | ReliefF | 64.12 | 68.35 | 62.60 | 40.14 | 0.50 | 1437 |
| 2D ensemble | 52.94 | 60.27 | 50.29 | 30.49 | 0.40 | 1360.30 | |
| Proposed Method | 65.88 | 66.15 | 65.81 | 41.29 | 0.50 | 678.2 | |
| PROSTATE_GE | ReliefF | 85.67 | 85.33 | 86.00 | 86.78 | 0.86 | 1492 |
| 2D ensemble | 80.67 | 80.67 | 80.67 | 82.04 | 0.81 | 1363.4 | |
| Proposed Method | 91.33 | 90.00 | 92.67 | 92.61 | 0.91 | 470.4 | |
| GLI_85 | ReliefF | 80.40 | 64.11 | 87.03 | 72.27 | 0.66 | 5571 |
| 2D ensemble | 80.40 | 63.75 | 87.52 | 70.72 | 0.65 | 5572 | |
| Proposed Method | 84.80 | 73.04 | 89.80 | 76.07 | 0.74 | 1671.6 | |
| LYMPHOMA | ReliefF | 66.07 | 83.13 | 51.24 | 60.38 | 0.70 | 1007 |
| 2D ensemble | 64.29 | 72.20 | 57.24 | 60.83 | 0.66 | 874.9 | |
| Proposed Method | 76.79 | 89.73 | 64.95 | 70.51 | 0.79 | 412.1 | |
| SMK_CAN_187 | ReliefF | 57.68 | 52.22 | 62.76 | 57.03 | 0.54 | 4999 |
| 2D ensemble | 63.21 | 61.11 | 65.17 | 62.44 | 0.62 | 5000 | |
| Proposed Method | 71.07 | 68.52 | 73.45 | 70.95 | 0.69 | 2750 |
| Dataset | #1 Run | #2 Run | #3 Run | #4 Run | #5 Run | #6 Run | #7 Run | #8 Run | #9 Run | #10 Run | Intersection |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MADELON | 10 | 8 | 11 | 15 | 10 | 8 | 14 | 14 | 10 | 13 | 2 and 4 |
| YALE | 12 | 11 | 9 | 10 | 11 | 13 | 15 | 10 | 5 | 15 | 1 and 4 |
| ORL | 5 | 3 | 6 | 3 | 7 | 12 | 7 | 12 | 3 | 12 | 1 and 3 |
| CTG | 13 | 12 | 9 | 11 | 8 | 9 | 9 | 11 | 9 | 9 | 1 and 4 |
| TOX_171 | 1 | 13 | 7 | 4 | 5 | 8 | 1 | 15 | 13 | 9 | 1 and 3 |
| PROSTATE_GE | 8 | 8 | 8 | 5 | 2 | 1 | 7 | 8 | 8 | 13 | 1 and 4 |
| GLI_85 | 1 | 8 | 6 | 1 | 5 | 2 | 1 | 1 | 2 | 1 | 1 and 2 |
| LYMPHOMA | 1 | 7 | 8 | 9 | 11 | 6 | 4 | 8 | 7 | 12 | 1 and 4 |
| SMK_CAN_187 | 2 | 14 | 9 | 3 | 3 | 7 | 2 | 12 | 15 | 10 | 2 and 4 |
| Iteration | Selected Feature | Feature Representative |
|---|---|---|
| 1 | [1 13 22 20] | [1000000000001000000101] |
| 2 | [13 22 18] | [0000000000001000010001] |
| 3 | [1 22 20] | [1000000000000000000101] |
| 4 | [1 7 22] | [1000001000000000000001] |
| 5 | [22] | [0000000000000000000001] |
| 6 | [1 22 20] | [1000000000000000000101] |
| 7 | [1 22] | [1000000000000000000001] |
| 8 | [1 7 22 20] | [1000001000000000000101] |
| 9 | [3 22] | [0010000000000000000001] |
| 10 | [3 22] | [0010000000000000000001] |
| Hamming | Spearman | Pearson | |||
|---|---|---|---|---|---|
| A | [1 13 22 20] | [1000000000001000000101] | 0.991 | 0.800 | 0.908 |
| B | [13 22 18] | [0000000000001000010001] | |||
| A1 | [1 7 22 20] | [1000001000000000000101] | 0.991 | 0.800 | 0.915 |
| B1 | [3 22] | [0010000000000000000001] | |||
| A2 | [1 22 20] | [1000000000000000000101] | 0.991 | 1.000 | 0.931 |
| B2 | [13 22 18] | [0000000000001000010001] | |||
| A1 | [3 22] | [0010000000000000000001] | 0.995 | 1.000 | 1.000 |
| B2 | [1 22] | [1000000000000000000001] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alhamidi, M.R.; Jatmiko, W. Optimal Feature Aggregation and Combination for Two-Dimensional Ensemble Feature Selection. Information 2020, 11, 38. https://doi.org/10.3390/info11010038
Alhamidi MR, Jatmiko W. Optimal Feature Aggregation and Combination for Two-Dimensional Ensemble Feature Selection. Information. 2020; 11(1):38. https://doi.org/10.3390/info11010038
Chicago/Turabian StyleAlhamidi, Machmud Roby, and Wisnu Jatmiko. 2020. "Optimal Feature Aggregation and Combination for Two-Dimensional Ensemble Feature Selection" Information 11, no. 1: 38. https://doi.org/10.3390/info11010038
APA StyleAlhamidi, M. R., & Jatmiko, W. (2020). Optimal Feature Aggregation and Combination for Two-Dimensional Ensemble Feature Selection. Information, 11(1), 38. https://doi.org/10.3390/info11010038