A Big Data Reference Architecture for Emergency Management




Abstract
:1. Introduction
2. Background
2.1. National Planning Framework for Emergency Management
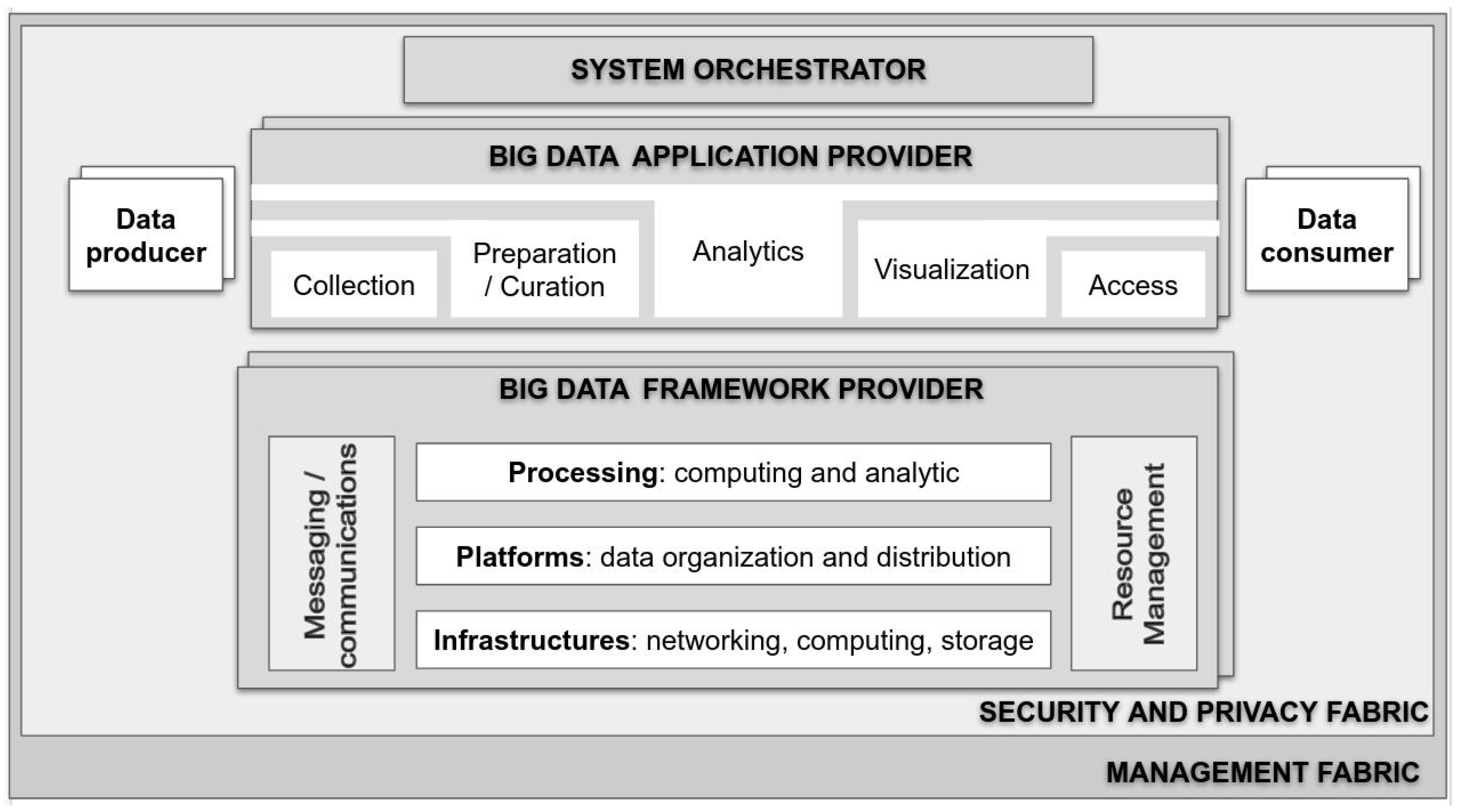
2.2. NIST Big Data Reference Architecture
2.3. Big Data Technologies in Emergency Management
2.4. Digital Humanitarianism in Disasters
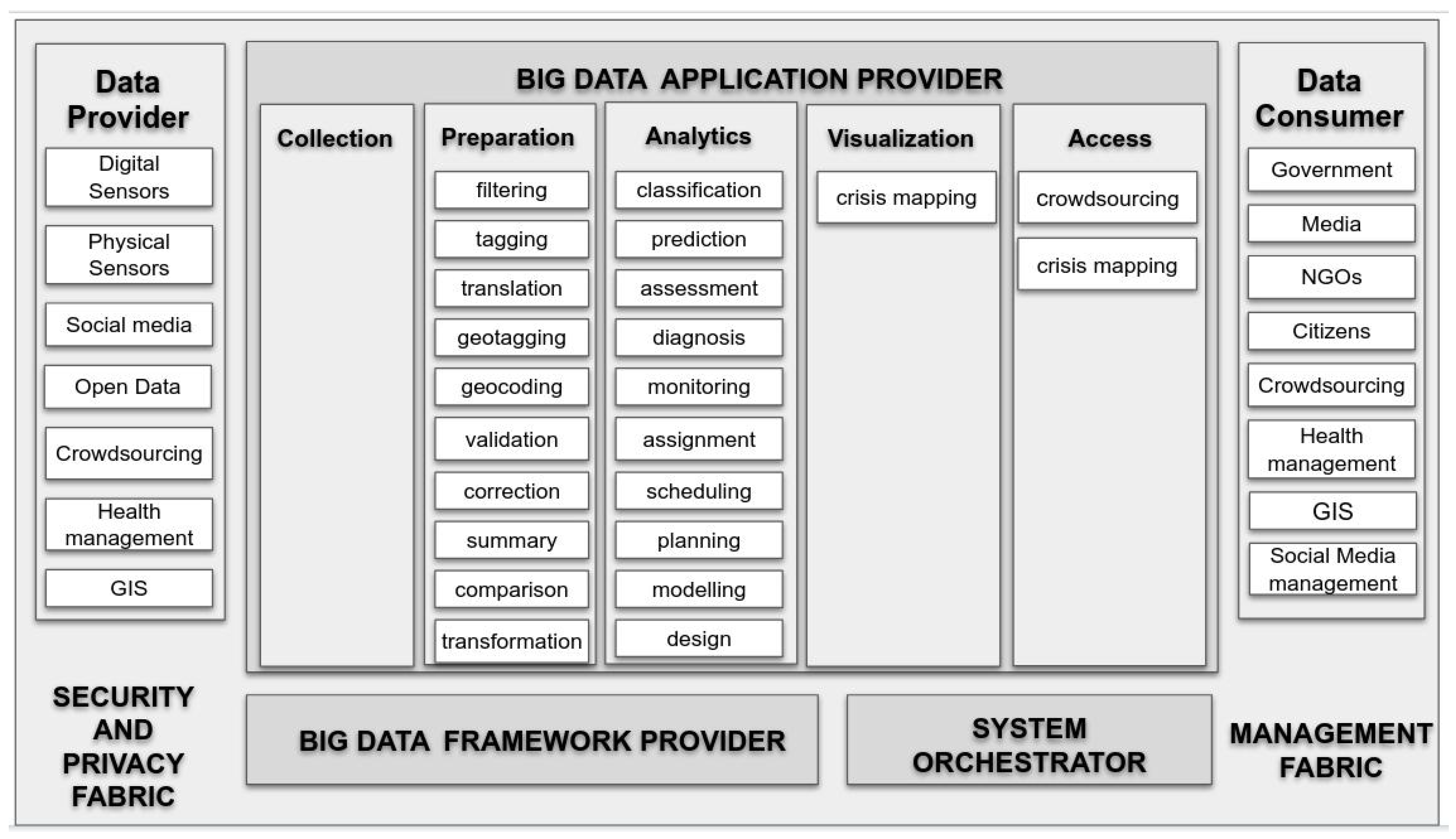
3. Big Data Reference Architecture for Emergency Management
- Digital sensors: data collected passively through the use of digital services (e.g., mobile phones, web searches).
- Social media and news media: the information published on the Internet (e.g., blogs, Twitter) can be traced as social sensors of people’s opinions and intents. Especially relevant is geolocated social media [72].
- Open data: open information provided by governments (e.g., census, statistics) and organizations (e.g., Wikipedia).
- Crowdsourcing: information produced actively by users in order to report information about a disaster (e.g., mobile phone reporting tool, emergency map).
- Health Information Management Systems: health information for managing the disaster, mainly related to patients and hospital management systems.
- GIS: geographical information provided by GIS systems.
- Government: governmental partners responsible for disaster management.
- Media: mass media communication that contributed to information distribution and sharing during the emergency cycle.
- NGOs: participating in the emergency as first responders.
- Citizens: citizens affected or non-affected by the emergency.
- Crowdsourcing: digital humanitarian organizations participating proactively in emergency management.
- Health information management systems: health systems that can use the big data insights for their decision making processes.
- GIS: GIS systems that can aggregate information from the big data system.
- Social media management: social media management tools that can use big data insights for improving information sharing impact.
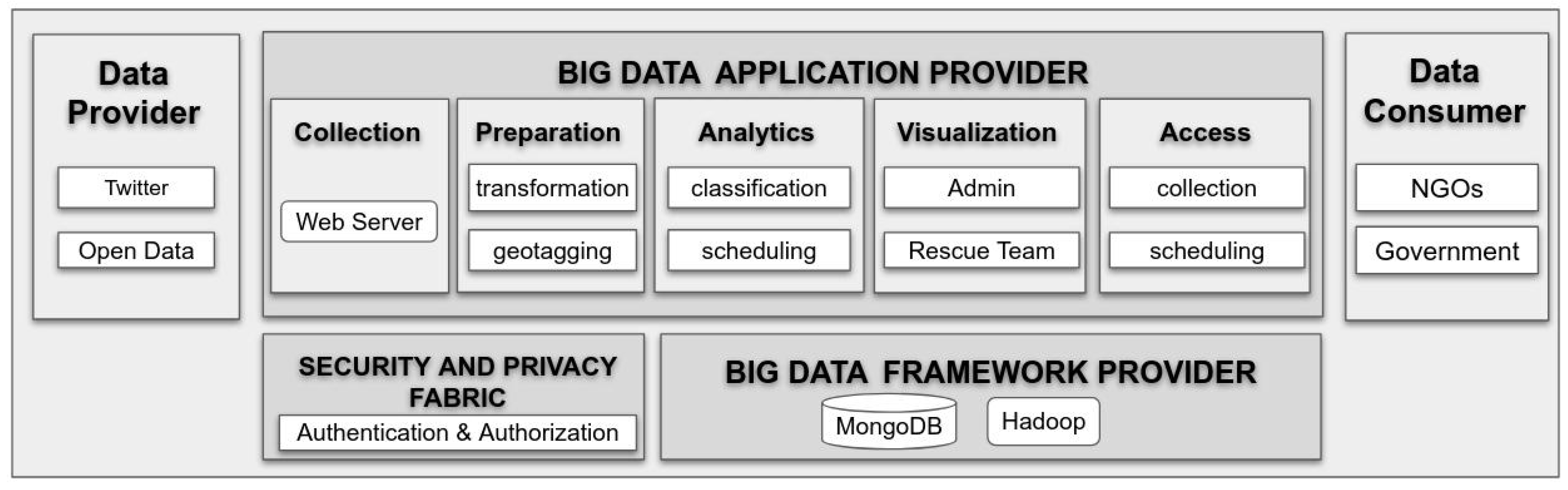
4. Case Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CEOS | Committee on Earth Observation Satellites |
| CSP | Crowdsourced Stream Processing |
| CRG | Community Response Grids |
| ECN | Emergency Communication Network |
| EDXL | EDXL |
| ETL | Extract, Transform, and Load |
| FEMA | Federal Emergency Management Agency |
| GIS | Geographical Information System |
| ICT | Information and Communication Technologies |
| NBDRA | NIST Big Data Reference Architecture |
| NGO | Non-Governmental Organization |
| NRF | National Response Framework |
| OSM | OpenStreetMap |
| SM | Social Media |
| SNS | Social Network Sites |
| USGS | US Geological Survey |
| VGI | Volunteer Geographic Information |
References
- Chang, W.L.; Grady, N. NIST Big Data Interoperability Framework: Volume 1, Definitions; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019.
- Wang, J.; Wu, Y.; Yen, N.; Guo, S.; Cheng, Z. Big Data Analytics for Emergency Communication Networks: A Survey. IEEE Commun. Surv. Tutor. 2016, 18, 1758–1778. [Google Scholar] [CrossRef]
- Arslan, M.; Roxin, A.M.; Cruz, C.; Ginhac, D. A review on applications of big data for disaster management. In Proceedings of the 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 370–375. [Google Scholar]
- Alexander, D.E. Social Media in Disaster Risk Reduction and Crisis Management. Sci. Eng. Ethics 2014, 20, 717–733. [Google Scholar] [CrossRef]
- Neal, D.M.; Phillips, B.D. Effective Emergency Management: Reconsidering the Bureaucratic Approach. Disasters 1995, 19, 327–337. [Google Scholar] [CrossRef]
- Castillo, C. Big Crisis Data; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Scolobig, A.; Prior, T.; Schröter, D.; Jörin, J.; Patt, A. Towards people-centred approaches for effective disaster risk management: Balancing rhetoric with reality. Int. J. Disaster Risk Reduct. 2015, 12, 202–212. [Google Scholar] [CrossRef]
- Boin, A.; McConnell, A. Preparing for Critical Infrastructure Breakdowns: The Limits of Crisis Management and the Need for Resilience. J. Contingencies Crisis Manag. 2007, 15, 50–59. [Google Scholar] [CrossRef]
- Manso, M.; Manso, B. The Role of Social Media in Crisis: A European holistic approach to the adoption of online and mobile communications in crisis response and search and rescue efforts. In Proceedings of the 17th International Command & Control Research & Technology Symposium, Fairfax, VA, USA, 19–21 June 2012. [Google Scholar]
- Gujer, E.; Weekes, B.; Gasser, U.; Maclay, C.; Best, M. Intelligence of the Masses or Stupidity of the Herd? In Peacebuilding in the Information Age: Sifting Hype from Reality; The Berkman Klein Center for Internet & Society at Harvard University: Cambridge, MA, USA, 2011; pp. 23–25. [Google Scholar]
- McClendon, S.; Robinson, A.C.; Currion, P.; de Silva, C.; Walle, B.V.D.; Field, K.; O’Brien, J.; Intagorn, S.; Lerman, K.; Jennex, M.; et al. Leveraging Geospatially-Oriented Social Media Communications in Disaster Response. Int. J. Inf. Syst. Crisis Response Manag. 2013, 5, 22–40. [Google Scholar] [CrossRef] [Green Version]
- Gao, H. Harnessing the Crowdsourcing Power of Social Media for Disaster Relief. IEEE Intell. Syst. 2011, 26, 10–14. [Google Scholar] [CrossRef]
- Morrow, N.; Mock, N.; Papendieck, A.; Kocmich, N. Independent evaluation of the Ushahidi Haiti project. Dev. Inf. Syst. Int. 2011, 8, 2011. [Google Scholar]
- Imran, M.; Castillo, C.; Lucas, J.; Patrick, M.; Rogstadius, J. Coordinating human and machine intelligence to classify microblog communications in crises. In Proceedings of the 11th International ISCRAM Conference, State College, PA, USA, 18–21 May 2014. [Google Scholar]
- Alexander, D.E. Principles of Emergency Planning and Management; Oxford University Press on Demand: Oxford, UK, 2002. [Google Scholar]
- Coetzee, C.; Van Niekerk, D. Tracking the evolution of the disaster management cycle: A general system theory approach. Jàmbá J. Disaster Risk Stud. 2012, 4, 1–9. [Google Scholar] [CrossRef]
- Barid, M.E. The Phases of Emergency Management; University of Memphis: Memphis, TN, USA, 2014. [Google Scholar]
- Khan, H.; Khan, A. Natural Hazards and Disaster Management in Pakistan. Technical Report 11052; Munich Personal RePEc Archive. 2008. Available online: https://mpra.ub.uni-muenchen.de/11052/ (accessed on 2 December 2020).
- Federal Emergency Management Agency (FEMA). Overview of the National Planning Frameworks; U.S. Department of Homeland Security: Hyattsville, MD, USA, 2016.
- Federal Emergency Management Agency (FEMA). National Prevention Framework; U.S. Department of Homeland Security: Hyattsville, MD, USA, 2016.
- Federal Emergency Management Agency (FEMA). National Protection Framework; U.S. Department of Homeland Security: Hyattsville, MD, USA, 2016.
- Federal Emergency Management Agency (FEMA). National Mitigation Framework; U.S. Department of Homeland Security: Hyattsville, MD, USA, 2016.
- Federal Emergency Management Agency (FEMA). National Response Framework; U.S. Department of Homeland Security: Hyattsville, MD, USA, 2016.
- Federal Emergency Management Agency (FEMA). National Disaster Recovery Framework; U.S. Department of Homeland Security: Hyattsville, MD, USA, 2016.
- Nakagawa, E.Y.; Antonino, P.O.; Becker, M. Reference architecture and product line architecture: A subtle but critical difference. In Proceedings of the European Conference on Software Architecture, Essen, Germany, 13–16 September 2011; Springer: Berlin, Germany, 2011; pp. 207–211. [Google Scholar]
- Pääkkönen, P.; Pakkala, D. Reference architecture and classification of technologies, products and services for big data systems. Big Data Res. 2015, 2, 166–186. [Google Scholar] [CrossRef] [Green Version]
- Sang, G.M.; Xu, L.; De Vrieze, P. A reference architecture for big data systems. In Proceedings of the 2016 10th International Conference on Software, Knowledge, Information Management & Applications (SKIMA), Chengdu, China, 15–17 December 2016; pp. 370–375. [Google Scholar]
- Nadal, S.; Herrero, V.; Romero, O.; Abelló, A.; Franch, X.; Vansummeren, S.; Valerio, D. A software reference architecture for semantic-aware Big Data systems. Inf. Softw. Technol. 2017, 90, 75–92. [Google Scholar] [CrossRef] [Green Version]
- Klein, J.; Buglak, R.; Blockow, D.; Wuttke, T.; Cooper, B. A reference architecture for big data systems in the national security domain. In Proceedings of the 2016 IEEE/ACM 2nd International Workshop on Big Data Software Engineering (BIGDSE), Austin, TX, USA, 16 May 2016; pp. 51–57. [Google Scholar]
- Zhang, X.; Ming, X.; Yin, D. Reference architecture of common service platform for Industrial Big Data (I-BD) based on multi-party co-construction. Int. J. Adv. Manuf. Technol. 2019, 105, 1949–1965. [Google Scholar] [CrossRef]
- Palanivel, K.; Chithralekha, T. Big Data Reference Architecture for e-Learning Analytical Systems. Int. J. Recent Innov. Trends Comput. Commun. 2018, 6, 55–67. [Google Scholar]
- Alam, A.; Ullah, I.; Lee, Y.K. Video Big Data Analytics in the Cloud: A Reference Architecture, Survey, Opportunities, and Open Research Issues. IEEE Access 2020, 8, 152377–152422. [Google Scholar] [CrossRef]
- Santana, E.F.Z.; Chaves, A.P.; Gerosa, M.A.; Kon, F.; Milojicic, D.S. Software Platforms for Smart Cities: Concepts, Requirements, Challenges, and a Unified Reference Architecture. ACM Comput. Surv. 2017, 50, 78. [Google Scholar] [CrossRef]
- Chang, W.L.; Boyd, D.; Levin, O. NIST Big Data Interoperability Framework: Volume 6, Reference Architecture; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018.
- Philip Chen, C.; Zhang, C.Y. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Chang, W.L.; Marcus, B.; Baru, C. NIST Big Data Interoperability Framework: Volume 8, Reference Architecture Interfaces; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019.
- Chang, W.L.; Marcus, B.; Baru, C. NIST Big Data Interoperability Framework: Volume 9, Adoption and Modernization; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019.
- Cavanillas, J.M.; Curry, E.; Wahlster, W. (Eds.) New Horizons for a Data-Driven Economy—A Roadmap for Big Data in Europe; Springer: Berlin, Germany, 2015; p. 303. [Google Scholar]
- Tekiner, F.; Keane, J.A. Big data framework. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2013, Manchester, UK, 13–16 October 2013; pp. 1494–1499. [Google Scholar]
- Immonen, A.; Ovaska, E. Evaluating the Quality of Social Media Data in Big Data Architecture. IEEE Access 2015, 3, 2028–2043. [Google Scholar] [CrossRef]
- Laney, D. 3D data management: Controlling data volume, velocity and variety. META Group Res. Note 2001, 6, 1. [Google Scholar]
- Miele, S.; Shockley, R. Analytics: The Real-World Use of Big Data; IBM Institute for Business Value: Somers, NY, USA, 2013. [Google Scholar]
- Qadir, J.; Ali, A.; ur Rasool, R.; Zwitter, A.; Sathiaseelan, A.; Crowcroft, J. Crisis analytics: Big data-driven crisis response. J. Int. Humanit. Action 2016, 1, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Estrin, D. Small data, where n= me. Commun. ACM 2014, 57, 32–34. [Google Scholar] [CrossRef]
- Meier, P. Digital Humanitarians: How Big Data Is Changing the Face of Humanitarian Response; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Cumbane, S.P.; Gidófalvi, G. Review of Big Data and Processing Frameworks for Disaster Response Applications. ISPRS Int. J. Geo-Inf. 2019, 8, 387. [Google Scholar] [CrossRef] [Green Version]
- Kwak, Y.J. Nationwide flood monitoring for disaster risk reduction using multiple satellite data. ISPRS Int. J. Geo-Inf. 2017, 6, 203. [Google Scholar] [CrossRef]
- Duda, K.A.; Jones, B.K. USGS remote sensing coordination for the 2010 Haiti earthquake. Photogramm. Eng. Remote Sens. 2011, 77, 899–907. [Google Scholar] [CrossRef]
- Kryvasheyeu, Y.; Chen, H.; Moro, E.; Van Hentenryck, P.; Cebrian, M. Performance of social network sensors during Hurricane Sandy. PLoS ONE 2015, 10, e0117288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Conrado, S.P.; Neville, K.; Woodworth, S.; O’Riordan, S. Managing social media uncertainty to support the decision making process during emergencies. J. Decis. Syst. 2016, 25, 171–181. [Google Scholar] [CrossRef] [Green Version]
- Hristidis, V.; Chen, S.C.; Li, T.; Luis, S.; Deng, Y. Survey of data management and analysis in disaster situations. J. Syst. Softw. 2010, 83, 1701–1714. [Google Scholar] [CrossRef]
- Miyazaki, H.; Nagai, M.; Shibasaki, R. Reviews of Geospatial Information Technology and Collaborative Data Delivery for Disaster Risk Management. ISPRS Int. J. Geo-Inf. 2015, 4, 1936–1964. [Google Scholar] [CrossRef]
- Li, T.; Xie, N.; Zeng, C.; Zhou, W.; Zheng, L.; Jiang, Y.; Yang, Y.; Ha, H.Y.; Xue, W.; Huang, Y.; et al. Data-driven techniques in disaster information management. ACM Comput. Surv. (CSUR) 2017, 50, 1–45. [Google Scholar] [CrossRef]
- Yu, M.; Yang, C.; Li, Y. Big data in natural disaster management: A review. Geosciences 2018, 8, 165. [Google Scholar] [CrossRef] [Green Version]
- Joseph, J.K.; Dev, K.A.; Pradeepkumar, A.; Mohan, M. Big data analytics and social media in disaster management. In Integrating Disaster Science and Management; Elsevier: Amsterdam, The Netherlands, 2018; pp. 287–294. [Google Scholar]
- Freeman, J.D.; Blacker, B.; Hatt, G.; Tan, S.; Ratcliff, J.; Woolf, T.B.; Tower, C.; Barnett, D.J. Use of big data and information and communications technology in disasters: An integrative review. Disaster Med. Public Health Prep. 2019, 13, 353–367. [Google Scholar] [CrossRef] [Green Version]
- Song, X.; Zhang, H.; Akerkar, R.A.; Huang, H.; Guo, S.; Zhong, L.; Ji, Y.; Opdahl, A.L.; Purohit, H.; Skupin, A.; et al. Big Data and Emergency Management: Concepts, Methodologies, and Applications. IEEE Trans. Big Data 2020. [Google Scholar] [CrossRef]
- Goswami, S.; Chakraborty, S.; Ghosh, S.; Chakrabarti, A.; Chakraborty, B. A review on application of data mining techniques to combat natural disasters. Ain Shams Eng. J. 2018, 9, 365–378. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.Y.; Li, X.; Lin, X. The data mining technology of particle swarm optimization algorithm in earthquake prediction. Adv. Mater. Res. 2014, 989, 1570–1573. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- SHIROTA, Y. Temporal awareness of needs after east japan great earthquake using latent semantic analysis. Inf. Model. Knowl. Bases XXV 2014, 25, 200. [Google Scholar]
- Zhang, K.; Chen, S.C.; Singh, P.; Saleem, K.; Zhao, N. A 3d visualization system for hurricane storm-surge flooding. IEEE Comput. Graph. Appl. 2006, 26, 18–25. [Google Scholar] [CrossRef]
- Surakitbanharn, C.; Ebert, D.S. Improving the communication of emergency and disaster information using visual analytics. In Proceedings of the International Conference on Applied Human Factors and Ergonomics, Los Angeles, CA, USA, 17–21 July 2017; Springer: Berlin, Germany, 2017; pp. 143–152. [Google Scholar]
- Hsu, W.K.; Chiang, W.L.; Xue, Q.; Hung, D.M.; Huang, P.C.; Chen, C.W.; Tsai, C.H. A probabilistic approach for earthquake risk assessment based on an engineering insurance portfolio. Nat. Hazards 2013, 65, 1559–1571. [Google Scholar] [CrossRef]
- Akter, S.; Wamba, S.F. Big data and disaster management: A systematic review and agenda for future research. Ann. Oper. Res. 2019, 283, 939–959. [Google Scholar] [CrossRef] [Green Version]
- Yates, D.; Paquette, S. Emergency knowledge management and social media technologies: A case study of the 2010 Haitian earthquake. Int. J. Inf. Manag. 2011, 31, 6–13. [Google Scholar] [CrossRef]
- Burns, R. Rethinking big data in digital humanitarianism: Practices, epistemologies, and social relations. GeoJournal 2015, 80, 477–490. [Google Scholar] [CrossRef]
- Kaplan, A.M.; Haenlein, M. Users of the world, unite! The challenges and opportunities of Social Media. Bus. Horiz. 2010, 53, 59–68. [Google Scholar] [CrossRef]
- Boyd, D.M.; Ellison, N.B. Social Network Sites: Definition, History, and Scholarship. J. Comput. Mediat. Commun. 2007, 13, 210–230. [Google Scholar] [CrossRef] [Green Version]
- Howe, J. The Rise of Crowdsourcing. Wired Mag. 2006, 14, 1–5. [Google Scholar]
- Yin, J.; Lampert, A.; Cameron, M.; Robinson, B.; Power, R. Using Social Media to Enhance Emergency Situation Awareness. IEEE Intell. Syst. 2012, 27, 52–59. [Google Scholar] [CrossRef]
- Simon, T.; Goldberg, A.; Adin, B. Socializing in emergencies—A review of the use of social media in emergency situations. Int. J. Inf. Manag. 2015, 35, 609–619. [Google Scholar] [CrossRef] [Green Version]
- Teodorescu, H.N. Using analytics and social media for monitoring and mitigation of social disasters. Procedia Eng. 2015, 107, 325–334. [Google Scholar] [CrossRef] [Green Version]
- Anson, S.; Watson, H.; Wadhwa, K.; Metz, K. Analysing social media data for disaster preparedness: Understanding the opportunities and barriers faced by humanitarian actors. Int. J. Disaster Risk Reduct. 2017, 21, 131–139. [Google Scholar] [CrossRef]
- Saroj, A.; Pal, S. Use of social media in crisis management: A survey. Intern. J. Disaster Risk Reduct. 2020, 48, 101584. [Google Scholar] [CrossRef]
- Poblet, M.; García-Cuesta, E.; Casanovas, P. Crowdsourcing tools for disaster management: A review of platforms and methods. In Proceedings of the International Workshop on AI Approaches to the Complexity of Legal Systems, Bologna, Italy, 11 December 2013; Springer: Berlin, Germany, 2013; pp. 261–274. [Google Scholar]
- Liu, S.B. Crisis Crowdsourcing Framework: Designing Strategic Configurations of Crowdsourcing for the Emergency Management Domain. Comput. Support. Coop. Work. Cscw: Int. J. 2014, 23, 389–443. [Google Scholar] [CrossRef]
- Poblet, M.; García-Cuesta, E.; Casanovas, P. Crowdsourcing roles, methods and tools for data-intensive disaster management. Inf. Syst. Front. 2018, 20, 1363–1379. [Google Scholar] [CrossRef]
- Kankanamge, N.; Yigitcanlar, T.; Goonetilleke, A.; Kamruzzaman, M. Can volunteer crowdsourcing reduce disaster risk? A systematic review of the literature. Int. J. Disaster Risk Reduct. 2019, 35, 101097. [Google Scholar] [CrossRef]
- Fernandez-Luque, L.; Imran, M. Humanitarian health computing using artificial intelligence and social media: A narrative literature review. Int. J. Med Inform. 2018, 114, 136–142. [Google Scholar] [CrossRef]
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing social media messages in mass emergency: A survey. ACM Comput. Surv. (CSUR) 2015, 47, 1–38. [Google Scholar] [CrossRef]
- Nazer, T.H.; Xue, G.; Ji, Y.; Liu, H. Intelligent disaster response via social media analysis a survey. ACM SIGKDD Explor. Newsl. 2017, 19, 46–59. [Google Scholar] [CrossRef]
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing social media messages in mass emergency: Survey summary. In Proceedings of the Companion Proceedings of the Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 507–511. [Google Scholar]
- Imran, M.; Lykourentzou, I.; Castillo, C. Engineering Crowdsourced Stream Processing Systems. arXiv 2013, arXiv:1310.5463. [Google Scholar]
- Dennison, D.; Harvey, T. Data Processing Pipelines. Available online: https://research.google/pubs/pub45329/ (accessed on 4 December 2020).
- Whipkey, K.; Verity, A. Guidance for Incorporating Big Data into Humanitarian Operations. Reptech. Rept. Digital Humanitarian Network. 2015. Available online: https://www.digitalhumanitarians.com/ (accessed on 4 December 2020).
- Mulder, F.; Ferguson, J.; Groenewegen, P.; Boersma, K.; Wolbers, J.; Avgerou, C.; Baack, S.; Brown, J.; Duguid, P.; Cooke, B.; et al. Questioning Big Data: Crowdsourcing crisis data towards an inclusive humanitarian response. Big Data Soc. 2016, 3, 133–146. [Google Scholar] [CrossRef]
- Schreiber, A.T.; Schreiber, G.; Akkermans, H.; Anjewierden, A.; Shadbolt, N.; de Hoog, R.; Van de Velde, W.; Wielinga, B.; Shadbolt, N.R. Knowledge Engineering and Management: The CommonKADS Methodology; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Pulse, U.G. Big Data for Development: Challenges & Opportunities; UN Global Pulse: New York, NY, USA, 2012. [Google Scholar]
- Shams, F.; Cerone, A.; Nicola, R.D. On Integrating Social and Sensor Networks for Emergency Management. In Software Engineering and Formal Methods; Springer: Berlin/Heidelberg, Germany, 2016; pp. 145–160. [Google Scholar]
- CEOS Disaster SBA team and DI-06-09 GEO Task Group. Use of Satellites for Risk Management. Volume I Establishing Global Requirements for Earth Observation Satellite Data to Support Multi-Hazard Disaster Management throughout the Disaster Cycle; Technical Report; CEOS: Gaithersburg, MD, USA, 2008. [Google Scholar]
- Du, C.; Zhu, S. Research on urban public safety emergency management early warning system based on technologies for the Internet of Things. Procedia Eng. 2012, 45, 748–754. [Google Scholar] [CrossRef] [Green Version]
- Lin, W.Y.; Wu, T.H.; Tsai, M.H.; Hsu, W.C.; Chou, Y.T.; Kang, S.C. Filtering disaster responses using crowdsourcing. Autom. Constr. 2018, 91, 182–192. [Google Scholar] [CrossRef]
- Hester, V.; Shaw, A.; Biewald, L. Scalable crisis relief: Crowdsourced SMS translation and categorization with Mission 4636. In Proceedings of the First ACM Symposium on Computing for Development, London, UK, 17–18 December 2010; pp. 1–7. [Google Scholar]
- Gómez, J.; Manso, M.A.; Alcarria, R. Volunteering assistance to online geocoding services through a distributed knowledge solution. In Proceedings of the RICH-VGI Workshop at 18th AGILE Conference on Geographic Information Science, Lisbon, Portugal, 9–12 June 2015. [Google Scholar]
- Jonathan, C.; Mokbel, M.F. Stella: Geotagging images via crowdsourcing. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 169–178. [Google Scholar]
- Imran, M.; Alam, F.; Qazi, U.; Peterson, S.; Ofli, F. Rapid Damage Assessment Using Social Media Images by Combining Human and Machine Intelligence. arXiv 2020, arXiv:2004.06675. [Google Scholar]
- Mirkin, S.; Venkatapathy, S.; Dymetman, M. Confidence-driven rewriting for improved translation. In Proceedings of the XIV MT Summit, Nice, France, 2–6 September 2013; pp. 257–264. [Google Scholar]
- Wu, S.Y.; Thawonmas, R.; Chen, K.T. Video summarization via crowdsourcing. In Proceedings of the CHI’11 Extended Abstracts on Human Factors in Computing Systems, Vancouver, BC, Canada, 10–11 May 2011; pp. 1531–1536. [Google Scholar]
- Venetis, P.; Garcia-Molina, H. Quality control for comparison microtasks. In Proceedings of the First International Workshop on Crowdsourcing and Data Mining, Beijing, China, 12 August 2012; pp. 15–21. [Google Scholar]
- Wong, H.T.; Chiang, V.C.L.; Choi, K.S.; Loke, A.Y. The need for a definition of Big Data for nursing science: A case study of disaster preparedness. Int. J. Environ. Res. Public Health 2016, 13, 1015. [Google Scholar] [CrossRef]
- Nagendra, N.P.; Narayanamurthy, G.; Moser, R. Management of humanitarian relief operations using satellite big data analytics: The case of Kerala floods. Ann. Oper. Res. 2020, 1–26. [Google Scholar] [CrossRef]
- Bates, D.W.; Saria, S.; Ohno-Machado, L.; Shah, A.; Escobar, G. Big data in health care: Using analytics to identify and manage high-risk and high-cost patients. Health Aff. 2014, 33, 1123–1131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, W.; Jiang, Y. Construction of water pollution monitoring model after flood disaster based on big data analysis. Ccamlr Sci. 2019, 495–506. Available online: https://go.gale.com/ps/anonymous?id=GALE%7CA634165416&sid=googleScholar&v=2.1&it=r&linkaccess=abs&issn=10234063&p=AONE&sw=w (accessed on 4 December 2020).
- Rathore, M.M.; Paul, A.; Ahmad, A.; Imran, M.; Guizani, M. Big data analytics of geosocial media for planning and real-time decisions. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Yang, T.; Xie, J.; Li, G.; Mou, N.; Li, Z.; Tian, C.; Zhao, J. Social Media Big Data Mining and Spatio-Temporal Analysis on Public Emotions for Disaster Mitigation. ISPRS Int. J. Geo-Inf. 2019, 8, 29. [Google Scholar] [CrossRef] [Green Version]
- Júnior, P.S.; Novais, R.; Vieira, V.; Pedraza, L.G.; Mendonça, M.; Villela, K. Visualization mechanisms for crowdsourcing information in emergency coordination. In Proceedings of the 14th Brazilian Symposium on Human Factors in Computing Systems, Salvador, Brazil, 3–6 November 2015; pp. 1–8. [Google Scholar]
- Macdonell, C. Ushahidi: A crisis mapping system. ACM SIGCAS Comput. Soc. 2015, 45, 38. [Google Scholar] [CrossRef]
- Baxter, P.; Aspinall, W.; Neri, A.; Zuccaro, G.; Spence, R.; Cioni, R.; Woo, G. Emergency planning and mitigation at Vesuvius: A new evidence-based approach. J. Volcanol. Geotherm. Res. 2008, 178, 454–473. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, Y.; Yu, K.; Wang, D.; Ding, W. An evaluation of big data analytics in feature selection for long-lead extreme floods forecasting. In Proceedings of the 2016 IEEE 13th International Conference on Networking, Sensing, and Control (ICNSC), Mexico City, Mexico, 28–30 April 2016; pp. 1–6. [Google Scholar]
- Wang, Y.; Deng, M.; Bao, Y.; Zhang, H.; Chen, J.; Qian, J.; Guo, C. Power system disaster-mitigating dispatch platform based on big data. In Proceedings of the 2014 International Conference on Power System Technology, Chengdu, China, 20–22 October 2014; pp. 1014–1019. [Google Scholar]
- Kontokosta, C.E.; Malik, A. The Resilience to Emergencies and Disasters Index: Applying big data to benchmark and validate neighborhood resilience capacity. Sustain. Cities Soc. 2018, 36, 272–285. [Google Scholar] [CrossRef]
- Gouveia, J.P.; Palma, P. Harvesting big data from residential building energy performance certificates: Retrofitting and climate change mitigation insights at a regional scale. Environ. Res. Lett. 2019, 14, 095007. [Google Scholar] [CrossRef]
- Kim, H.S.; Sun, C.G.; Cho, H.I. Geospatial big data-based geostatistical zonation of seismic site effects in Seoul metropolitan area. ISPRS Int. J. Geo-Inf. 2017, 6, 174. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.Q.; Mao, H.; Wang, Y.; Rae, C.; Shaw, W. Hyper-resolution monitoring of urban flooding with social media and crowdsourcing data. Comput. Geosci. 2018, 111, 139–147. [Google Scholar] [CrossRef] [Green Version]
- Merchant, R.M.; Elmer, S.; Lurie, N. Integrating social media into emergency-preparedness efforts. N. Engl. J. Med. 2011, 365, 289–291. [Google Scholar] [CrossRef] [Green Version]
- Barren, D. The President’s National Security Telecommunications Advisory Committee. In Proceedings of the MILCOM 2006-2006 IEEE Military Communications Conference, Washington, DC, USA, 23–25 October 2006. [Google Scholar]
- Lee, Y.; Watanabe, K.; Li, W.S. Enhancing regional digital preparedness on natural hazards to safeguard business resilience in the Asia-Pacific. In Proceedings of the International Conference on Information Technology in Disaster Risk Reduction, Sofia, Bulgaria, 16–18 November 2016; Springer: Berlin, Germany, 2016; pp. 170–182. [Google Scholar]
- Fekete, A. Critical infrastructure cascading effects. Disaster resilience assessment for floods affecting city of Cologne and Rhein-Erft-Kreis. J. Flood Risk Manag. 2020, 13, e312600. [Google Scholar] [CrossRef]
- Itoh, M.; Yokoyama, D.; Toyoda, M. Visual Exploration of Changes in Passenger Flows and Tweets on Mega-City Metro Network. IEEE Trans. Big Data 2016, 2, 85–99. [Google Scholar] [CrossRef]
- Muhammad, A.; Goda, K. Impact of earthquake source complexity and land elevation data resolution on tsunami hazard assessment and fatality estimation. Comput. Geosci. 2018, 112, 83–100. [Google Scholar] [CrossRef]
- Lian, X.; Melancon, S.; Presta, J.R.; Reevesman, A.; Spiering, B.; Woodbridge, D. Scalable Real-time Prediction and Analysis of San Francisco Fire Department Response Times. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019; pp. 694–699. [Google Scholar]
- Mishra, S.; Singh, S.P. A stochastic disaster-resilient and sustainable reverse logistics model in big data environment. Ann. Oper. Res. 2020, 1–32. [Google Scholar] [CrossRef]
- Rakes, T.R.; Deane, J.K.; Rees, L.P.; Fetter, G.M. A decision support system for post-disaster interim housing. Decis. Support Syst. 2014, 66, 160–169. [Google Scholar] [CrossRef]
- Berawi, M.A.; Siahaan, S.A.O.; Miraj, P.; Leviakangas, P. Determining the Prioritized Victim of Earthquake Disaster Using Fuzzy Logic and Decision Tree Approach. Evergreen 2020, 7, 246–252. [Google Scholar] [CrossRef]
- Zahra, K.; Imran, M.; Ostermann, F.O. Automatic identification of eyewitness messages on twitter during disasters. Inf. Process. Manag. 2020, 57, 102107. [Google Scholar] [CrossRef]
- Zhong, L.; Takano, K.; Ji, Y.; Yamada, S. Big Data Based Service Area Estimation for Mobile Communications during Natural Disasters. In Proceedings of the 2016 30th International Conference on Advanced Information Networking and Applications Workshops (WAINA), Crans-Montana, Switzerland, 23–25 March 2016; pp. 687–692. [Google Scholar]
- Caragea, C.; Squicciarini, A.C.; Stehle, S.; Neppalli, K.; Tapia, A.H. Mapping moods: Geo-mapped sentiment analysis during hurricane Sandy. In Proceedings of the ISCRAM 2014 Conference Proceedings—11th International Conference on Information Systems for Crisis Response and Management, University Park, PA, USA, 18–21 May 2014; pp. 642–651. [Google Scholar]
- Patra, R. Automated Categorization and Mining Tweets for Disaster Management. In Machine Learning Algorithms for Industrial Applications; Springer: Berlin, Germany, 2020; pp. 37–51. [Google Scholar]
- Román, M.O.; Stokes, E.C.; Shrestha, R.; Wang, Z.; Schultz, L.; Carlo, E.A.S.; Sun, Q.; Bell, J.; Molthan, A.; Kalb, V.; et al. Satellite-based assessment of electricity restoration efforts in Puerto Rico after Hurricane Maria. PLoS ONE 2019, 14, e0218883. [Google Scholar] [CrossRef]
- Mudigonda, S.; Ozbay, K.; Bartin, B. Evaluating the resilience and recovery of public transit system using big data: Case study from New Jersey. J. Transp. Saf. Secur. 2019, 11, 491–519. [Google Scholar] [CrossRef]
- Guo, J.; Wu, X.; Wei, G. A new economic loss assessment system for urban severe rainfall and flooding disasters based on big data fusion. Environ. Res. 2020, 188, 109822. [Google Scholar] [CrossRef]
- Banisakher, M.; Nguyen, V.; Mohammed, D. Big Data Analysis and Simulation for Performance Measurement of Hospitals in Emergency Situations. Int. J. Simul. Syst. Sci. Technol. 2017, 18. [Google Scholar] [CrossRef]
- Shibuya, Y.; Tanaka, H. Socio-economic disaster recovery captured by big housing market data. In Proceedings of the 2019 IEEE Global Humanitarian Technology Conference (GHTC), Seattle, WA, USA, 17–20 October 2019; pp. 1–8. [Google Scholar]
- Contreras, D.; Wilkinson, S.; Balan, N.; Phengsuwan, J.; James, P. Assessing Post-Disaster Recovery Using Sentiment Analysis. The case of L’Aquila, Haiti, Chile and Canterbury. In Proceedings of the 17th World Conference on Earthquake Engineering, Sendai, Japan, 19–24 July 2022. [Google Scholar]
- Kabir, M.Y.; Gruzdev, S.; Madria, S. STIMULATE: A System for Real-time Information Acquisition and Learning for Disaster Management. In Proceedings of the 2020 21st IEEE International Conference on Mobile Data Management (MDM), Versailles, France, 30 June–3 July 2020; pp. 186–193. [Google Scholar]
- Bradshaw, S.; Brazil, E.; Chodorow, K. MongoDB: The Definitive Guide: Powerful and Scalable Data Storage; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI16), Savannah, GA, USA, 2–4 December 2016; pp. 265–283. [Google Scholar]
- Wolf-Fordham, S. Integrating Government Silos: Local Emergency Management and Public Health Department Collaboration for Emergency Planning and Response. Am. Rev. Public Adm. 2020, 50, 560–567. [Google Scholar] [CrossRef]
- Patel, J. Bridging Data Silos Using Big Data Integration. Int. J. Database Manag. Syst. 2019, 11, 1–6. [Google Scholar] [CrossRef]
- Chamikara, M.A.P.; Bertók, P.; Liu, D.; Camtepe, S.; Khalil, I. Efficient privacy preservation of big data for accurate data mining. Inf. Sci. 2020, 527, 420–443. [Google Scholar] [CrossRef] [Green Version]
- Scheerlinck, J.; Eeghem, F.V.; Loutas, N. Big Data Interoperability Analysis; Technical Report SC508DI07171; European Union, ISA Programme, EU: Brussels, Belgium, 2018; Available online: https://joinup.ec.europa.eu/sites/default/files/document/2018-05/SC508DI07171%20D05.02%20Big%20Data%20Interoperability%20Analysis_v1.00.pdf (accessed on 2 December 2020).
- Mazimwe, A.; Hammouda, I.; Gidudu, A. An empirical evaluation of data interoperability—A case of the disaster management sector in Uganda. ISPRS Int. J. Geo-Inf. 2019, 8, 484. [Google Scholar] [CrossRef] [Green Version]
- Guide, E.I. Emergency Data Exchange Language (EDXL) Implementer’s Guide; OASIS: Burlington, MA, USA, 2005. [Google Scholar]
- Gençtürk, M.; Evci, E.; Guney, A.; Kabak, Y.; Erturkmen, G.B.L. Achieving semantic interoperability in emergency management domain. In Proceedings of the International Symposium on Environmental Software Systems, Zadar, Croatia, 10–12 May 2017; Springer: Berlin, Germany, 2017; pp. 279–289. [Google Scholar]
- Barros, R.; Kislansky, P.; do Nascimento Salvador, L.; Almeida, R.; Breyer, M.; Pedraza, L.G. EDXL-RESCUER Ontology: Conceptual Model for Semantic Integration. In Proceedings of the ISCRAM 2015 Conference, Kristiansand, Norway, 24–27 May 2015. [Google Scholar]
- Purohit, H.; Kanagasabai, R.; Deshpande, N. Towards Next Generation Knowledge Graphs for Disaster Management. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 474–477. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Core Capability | Mitigation | Preparedness | Response | Recovery |
|---|---|---|---|---|
| Planning | ✗ | ✗ | ✗ | ✗ |
| Public information and Warning | ✗ | ✗ | ✗ | ✗ |
| Operational Coordination | ✗ | ✗ | ✗ | ✗ |
| Intelligence and Information Sharing | ✗ | |||
| Community Resilience | ✗ | |||
| Long-term vulnerability reduction | ✗ | |||
| Risk and Disaster Resilience Assessment | ✗ | |||
| Threats and Hazards Identification | ✗ | |||
| Infrastructure Systems | ✗ | ✗ | ||
| Critical transportation | ✗ | |||
| Environmental Response/Health and Safety | ✗ | |||
| Fatality Management Services | ✗ | |||
| Fire Management and Suppression | ✗ | |||
| Logistics and Supply Chain Management | ✗ | |||
| Mass Care Services | ✗ | |||
| Mass Search and Rescue Operations | ✗ | |||
| On-scene Security, Protection and Law Enforcement | ✗ | |||
| Operational Communications | ✗ | |||
| Publish Health, Healthcare, and Emergency Medical Services | ✗ | |||
| Situational Assessment | ✗ | |||
| Economic recovery | ✗ | |||
| Health and Social Services | ✗ | |||
| Housing | ✗ | |||
| Natural and Cultural Resources | ✗ |
| NRF Capability | Task | Example |
|---|---|---|
| Planning | Assessment | Simulation modelling of eruptive processes for identifying eruption scenarios for emergency planning in at Vesuvius, Italy [109] |
| Public information and warning | Communication, Prediction | Big Data analytics for predicting extreme flood risks and create awareness in the community to mitigate its effects [110] |
| Operational Coordination | Schedule | Develop scheduling plans of power supply based on disaster trends and reserves of emergency supply [111]. |
| Community resilience | Assessment | Use of big data technologies to integrate physical, social, economic, and environmental dimensions to assess neighbourhood resilience [112] |
| Long-term vulnerability reduction | Assessment | Harvesting big data from residential buildings for assessment on climate change policies [113]. |
| Risk and Disaster Resilient Assessment | Assessment | Geospatial zonation of seismic site effects in Seoul [114]. |
| Threats and hazards identification | Monitoring | Monitoring social media and crowdsourcing data for early identification of urban flooding [115] |
| NRF Capability | Task | Example |
|---|---|---|
| Planning | Prediction | Ambulance demand forecast based on weather conditions and datasets from hospitals [101] |
| Public information and warning | Communicate | Use of social media to communicate that vaccine against H1N1 influenza was available [116] |
| Operational Coordination | Assessment | Recommendation of using operational analytics to coordinate emergency response across Federal, State, and local agencies [117] |
| Intelligence and Information Sharing | Collection | Usage of big data and open data integration mechanisms for improving information sharing from central to local governments and NGOs during preparedness in Taiwan [118]. |
| NRF Capability | Task | Example |
|---|---|---|
| Planning | Assessment | Analysis of geosocial media post for emergency planning [105] |
| Public information and warning | Assessment | Assessment for managing affected populations based on a spatio-temporal analysis of public emotion information [106] |
| Operational Coordination | Assessment | Improved coordination between rescue teams integrating geographical, satellite, census and mobile phone call reports in Kerala floods [102] |
| Infrastructure systems | Assessment | Spatial assessment of risk and resilience of critical infrastructures for flood disaster [119] |
| Critical transportation | Prediction | Description and prediction of passenger flows, detection of unusual flows and its explanation based on Twitter content during several disasters in Japan [120] |
| Environmental response; Health and safety | Monitoring | Big Data system for monitoring water pollution after flood disaster [104] |
| Fatality management services | Assessment | Fatality estimation and tsunami hazard assessment based on big data earthquake source models [121] |
| Fire management and suppression | Prediction | Real-time prediction of fire department response times in San Francisco [122] |
| Logistics and supply chain management | Assessment | Decision support system for optimal facility location, its state of operation, and production-distribution across countries [123]. |
| Mass care services | Assignment | Decision support system for allocation of temporary housing after the disaster [124] |
| Mass search and rescue operations | Assessment | Decision support system for prioritising victims to be rescued [125] |
| On-scene security, protection and law enforcement | Classification | Identification of eyewitness messages [126] |
| Operational communications | Prediction | Prediction of mobile service disruption during Tokyo earthquakes [127] |
| Public health, healthcare, and emergency medical services | Assessment | Triage based on big data [103] |
| Situational assessment | Classification | Detecting informative tweets [128] |
| NRF Capability | Task | Example |
|---|---|---|
| Planning | Assessment | Assessment of resilience to Emergencies and Disasters at neighbourhood level for improving planning based on big data fusion [112] |
| Public information and warning | Monitoring | Monitoring social media (e.g., Twitter) and classify messages per disaster phase and mine relevant information [129] |
| Operational Coordination | Assessment | Satellite-based assessment of electricity restoration efforts during Hurricane Maria in Puerto Rico [130] |
| Infrastructure systems | Assessment | Evaluation resilience and recovery of public transit systems based on Big Data [131] |
| Economic recovery | Assessment | Economic loss assessment for rainfall and flooding disasters based on Big Data fusion [132] |
| Health and social services | Decision support system for evaluating hospital resources during post-disaster management [133] | |
| Housing | Assessment | Socio-economic analysis of disaster recovery based on housing market data [134] |
| Natural and cultural resources | Assessment | Recovery assessment of monuments based on sentiment analysis of tweets during memorial days [135] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iglesias, C.A.; Favenza, A.; Carrera, Á. A Big Data Reference Architecture for Emergency Management. Information 2020, 11, 569. https://doi.org/10.3390/info11120569
Iglesias CA, Favenza A, Carrera Á. A Big Data Reference Architecture for Emergency Management. Information. 2020; 11(12):569. https://doi.org/10.3390/info11120569
Chicago/Turabian StyleIglesias, Carlos A., Alfredo Favenza, and Álvaro Carrera. 2020. "A Big Data Reference Architecture for Emergency Management" Information 11, no. 12: 569. https://doi.org/10.3390/info11120569
APA StyleIglesias, C. A., Favenza, A., & Carrera, Á. (2020). A Big Data Reference Architecture for Emergency Management. Information, 11(12), 569. https://doi.org/10.3390/info11120569