Quality of Open Research Data: Values, Convergences and Governance


Abstract
:1. Introduction
2. Changing Views on the Nature of Data
3. The Stakeholders of Research Data Quality
- Understanding researchers’ problems and motivations;
- Raising awareness of issues and encouraging behavioral or cultural change;
- Improving the quality and objectivity of the peer-review process;
- Improving scholarly communication infrastructure with journals that publish scientifically sound research.
4. The Nature of Data Quality
4.1. Data Quality Attributes
- Origin (originality);
- Methods of collecting and processing;
- Authenticity;
- Acceptability;
- Applicability;
- Understandability;
- Subject discipline;
- Reputation of the creator(s);
- Biases of the evaluators;
- User’s confidence;
- “Lack of deception”;
- Independent review;
- Reuse.
4.2. Technical and Scientific Quality
- The number of datasets is correct and bigger than 0;
- The size of every dataset is also bigger than 0;
- The datasets and corresponding metadata are accessible;
- The data sizes are controlled and correct;
- The metadata is consistent to the data;
- The format is correct;
- Data and its descriptions are consistent [52].
4.3. Data Quality and Data Reuse
- Who is in charge of checking for quality?
- What process do they use?
- How is missing data handled? [58]
4.4. Other Quality Factors
- Inherent data quality;
- System dependent data quality;
- Inherent and system dependent data quality.
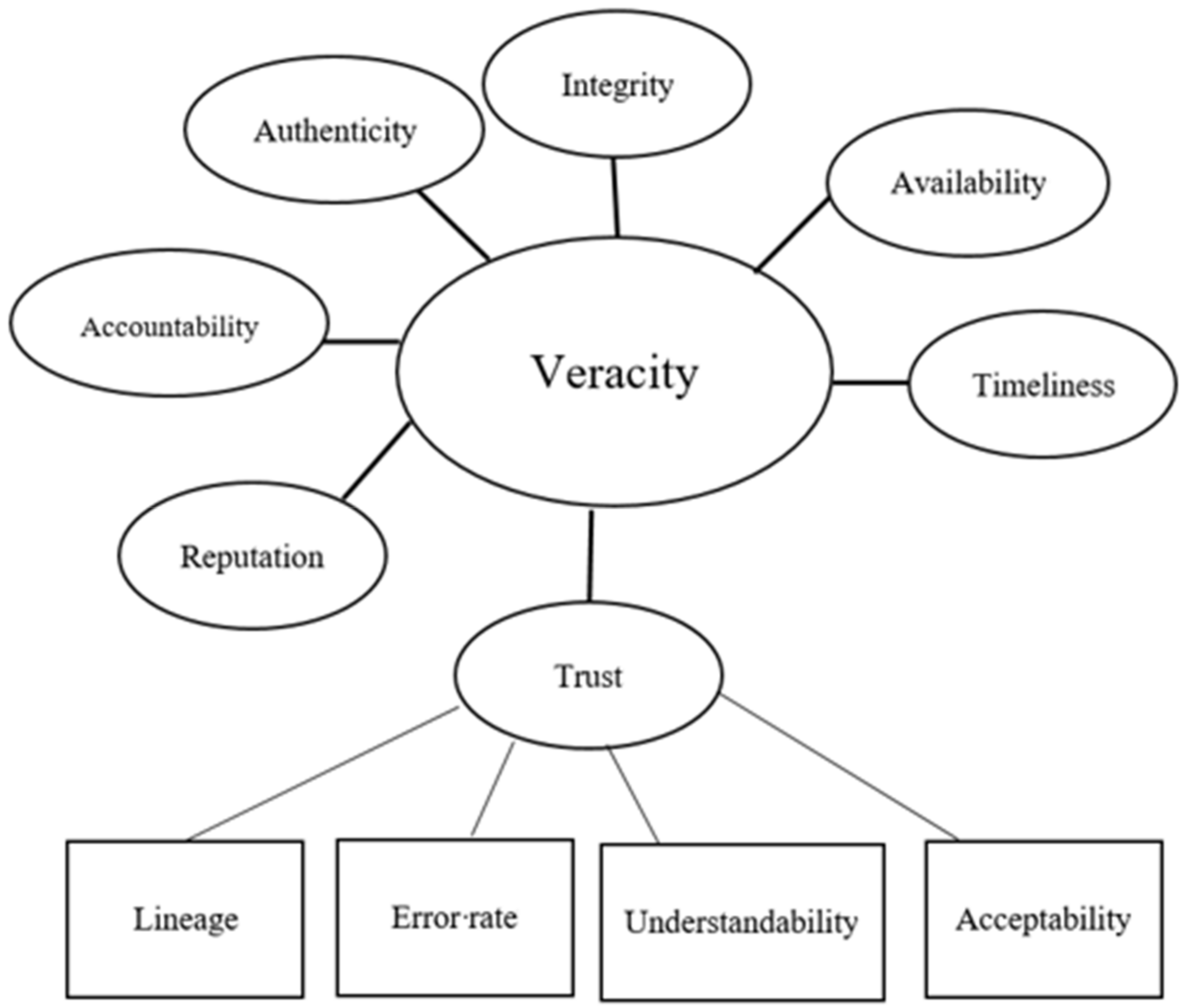
4.5. Big Data Quality and Smart Data
- The integrity of data;
- The identification of both data and source;
- The trustworthiness of computers and storage platforms;
- Availability and timeliness;
- Accountability;
- Reputation [61].
5. Data Governance
- Clarifying the role of data as an asset;
- Safeguarding DQ;
- Defining and providing metadata;
- Specifying access requirements;
- Determining the definition, production, retention, and retirement of data.
- The functions of data governance and its structure;
- Organization;
- Technical issues;
- Environmental factors;
- Measuring and monitoring tools.
6. Quality Beyond Characteristics and Attributes
7. Conclusions
Funding
Conflicts of Interest
References
- Bueno de la Fuente, G. What is Open Science? Introduction. Available online: https://www.fosteropenscience.eu/content/what-open-science-introduction (accessed on 29 January 2020).
- Royal Society. Science as an Open Enterprise; Royal Society Science Policy Centre: London, UK, 2012. [Google Scholar]
- Borgman, C.L. Big Data, Little Data, no Data: Scholarship in the Networked World; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Pryor, G. Managing Research Data; Facet Publishing: London, UK, 2012. [Google Scholar]
- Semeler, A.R.; Pinto, A.L.; Rozados, H.B.F. Data science in data librarianship: Core competencies of a data librarian. J. Libr. Inf. Sci. 2017, 51, 771–780. [Google Scholar] [CrossRef]
- The IFRS for SMEs; International Accounting Standards Board: London, UK, 2015.
- Ramírez, M.L. Opinion: Whose role is it anyway? A library practitioner’s appraisal of the digital data deluge. Bull. Am. Soc. Inf. Sci. Technol. 2011, 37, 21–23. [Google Scholar] [CrossRef]
- Foster, J.; McLeod, J.; Nolin, J.; Greifeneder, E. Data work in context: Value, risks, and governance. J. Assoc. Inf. Sci. Technol. 2018, 69, 1414–1427. [Google Scholar] [CrossRef]
- Neylon, C.; Belsø, R.; Bijsterbosch, M.; Cordewener, B.; Foncel, J. Open Scholarship and the Need for Collective Action; Knowledge Exchange: Bristol, UK, 2019. [Google Scholar]
- Rowley, J. The wisdom hierarchy: Representations of the DIKW hierarchy. J. Inf. Sci. 2007, 33, 163–180. [Google Scholar] [CrossRef] [Green Version]
- Makani, J. Knowledge management, research data management, and university scholarship: Towards an integrated institutional research data management support-system framework. Vine 2015, 45, 344–359. [Google Scholar] [CrossRef]
- Frické, M. The knowledge pyramid: A critique of the DIKW hierarchy. J. Inf. Sci. 2009, 35, 131–142. [Google Scholar] [CrossRef]
- Yu, L. Back to the fundamentals again: A redefinition of information and associated LIS concepts following a deductive approach. J. Doc. 2015, 71, 795–816. [Google Scholar] [CrossRef]
- Špiranec, S.; Kos, D.; George, M. Searching for critical dimensions in data literacy. Inf. Res. 2019, 24. Available online: http://InformationR.net/ir/24-4/colis/colis1922.html (accessed on 29 January 2020).
- Golub, K.; Hansson, J. (Big) Data in Library and Information science: A brief overview of some important problem areas. J. Univers. Comput. Sci. 2017, 23, 1098–1108. [Google Scholar] [CrossRef]
- Heidorn, P.B. The emerging role of libraries in data curation and e-science. J. Libr. Admin. 2011, 51, 662–672. [Google Scholar] [CrossRef]
- Sans, S.; Night, W.S. Introduction. In HathiTrust: Large-Scale Data Repository in the Humanities. 2019. Available online: https://akthom.gitboooks.io/hkdcws/content/Introduction/Introduction.html (accessed on 29 January 2020).
- Al-Ruithe, M.; Benkhelifa, E.; Hameed, K. A systematic literature review of data governance and cloud data governance. Pers. Ubiquitous Comput. 2018, 23, 839–859. [Google Scholar] [CrossRef]
- Baskarada, S.; Koronios, A. Data, information, knowledge, wisdom (DIKW): A semiotic theoretical and empirical exploration of the hierarchy and its quality dimension. Aust. J. Inf. Syst. 2013, 18, 5–24. [Google Scholar] [CrossRef] [Green Version]
- Whitmire, A.L.; Boock, M.; Sutton, S.C. Variability in academic research data management practices: Implications for data services development from a faculty survey. Program 2015, 49, 382–407. [Google Scholar] [CrossRef]
- RECODE Policy Recommendations for Open Access to Research Data. RECODE Project Consortium. Available online: https://trilateralresearch.co.uk/wp-content/uploads/2018/09/RECODE-D5.1-POLICY-RECOMMENDATIONS-FINAL.pdf (accessed on 29 January 2020).
- Hrynaszkiewicz, I. Publishers’ Responsibilities in Promoting Data Quality and Reproducibility. In Handbook of Experimental Pharmacology; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Kim, J. Who is teaching data: Meeting the demand for data professionals. J. Edu. Libr. Inf. Sci. 2016, 57, 161–173. [Google Scholar] [CrossRef]
- Corti, L.; Van den Eynden, V.; Bishop, L.; Woollard, M. Managing and Sharing Research Data: A Guide to Good Practice; SAGE Publications Limited: Southend Oaks, CA, USA, 2019. [Google Scholar]
- Schneider, R. Research data literacy. In European Conference on Information Literacy; Springer: Berlin/Heidelberg, Germany, 2013; pp. 134–140. [Google Scholar]
- Hobbs, R. Multiple visions of multimedia literacy: Emerging areas of synthesis. In International Handbook of Literacy and Technology; Routledge: London, UK, 2006; Volume 2, pp. 15–28. [Google Scholar]
- Candela, L.; Castelli, D.; Manghi, P.; Tani, A. Data journals: A survey. J. Assoc. Inf. Sci. Technol. 2015, 66, 1747–1762. [Google Scholar] [CrossRef] [Green Version]
- Lyon, L.; Brenner, A. Bridging the data talent gap: Positioning the iSchool as an agent for change. Int. J. Dig Curation 2015, 10, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Swan, A.; Brown, S. The skills, role, and career structure of data scientists and curators: An assessment of current practice and future needs. 2008, Report to the JISC. Available online: http://eprints.soton.ac.uk/266675 (accessed on 29 January 2020).
- Hayashi, C. What is data science? Fundamental concepts and a heuristic example. In Data Science, Classification, and Related Methods; Springer: Berlin/Heidelberg, Germany, 1998; pp. 40–51. [Google Scholar]
- Voulgaris, Z. Data Scientist: The Definitive Guide to Becoming a Data Scientist; Technics Publications: Basking Ridge, NJ, USA, 2014. [Google Scholar]
- Virkus, S.; Garoufallou, E. Data science from a library and information science perspective. Data Tech. Appl. 2019, 52, 422–441. [Google Scholar] [CrossRef]
- Wang, L. Twinning data science with information science in schools of library and information science. J. Doc. 2018, 74, 1243–1257. [Google Scholar] [CrossRef]
- Cao, L. Data science: Nature and pitfalls. IEEE Intell. Syst. 2016, 31, 66–75. [Google Scholar] [CrossRef]
- Madrid, M.M. A study of digital curator competences: A survey of experts. Intern. Inf. Libr. Rev. 2013, 45, 149–156. [Google Scholar] [CrossRef]
- Nahm, M.; Hammond, W.E. Data standards≠ data quality. Stud. Health Technol. Inf. 2013, 192, 1208. [Google Scholar]
- Abraham, R.; Schneider, J.; vom Brocke, J. Data governance: A conceptual framework, structured review, and research agenda. Int. J. Inf. Manag. 2019, 49, 424–438. [Google Scholar] [CrossRef]
- Janssen, M.; van der Voort, H.; Wahyudi, A. Factors influencing big data decision-making quality. J. Bus. Res. 2017, 70, 338–345. [Google Scholar] [CrossRef]
- Al-Ruithe, M.; Benkhelifa, E.; Hameed, K. Data Governance Taxonomy: Cloud versus Non-Cloud. Sustainability 2018, 10, 95. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.Y.; Strong, D.M. Beyond accuracy: What data quality means to data consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Altman, M.; Marciano, G.; Lee, C.; Bowden, H. Mitigating threats to data quality throughout the curation lifecycle. In Curating For Quality: Ensuring Data Quality to Enable New Science; National Science Foundation: Alexandria, VA, USA, 2012; pp. 1–119. [Google Scholar]
- Sposito, F.A. What do Data Curators Care About? Data Quality, User Trust, and the Data Reuse Plan. Paper Presented at IFLA WLIC 2017. Available online: http://library.ifla.org/1797/ (accessed on 29 January 2020).
- Strong, D.M.; Lee, Y.W.; Wang, R.Y. Data quality in context. Commun. ACM 1997, 40, 103–110. [Google Scholar] [CrossRef]
- Daraio, C.; Lenzerini, M.; Leporelli, C.; Naggar, P.; Bonaccorsi, A.; Bartolucci, A. The advantages of an Ontology-Based Data Management approach: Openness, interoperability and data quality. Scientometrics 2016, 108, 441–455. [Google Scholar] [CrossRef]
- Laranjeiro, N.; Soydemir, S.N.; Bernardino, J. A survey on data quality: Classifying poor data. In Proceedings of the 2015 IEEE 21st Pacific Rim International Symposium on Dependable Computing (PRDC), Zhangjiajie, China, 18–20 November 2015; pp. 179–188. [Google Scholar]
- Wolski, M.; Howard, L.; Richardson, J. A Trust Framework for Online Research Data Services. Publications 2017, 5, 14. [Google Scholar] [CrossRef] [Green Version]
- Giarlo, M.J. Academic libraries as data quality hubs. J. Libr. Sch. Commun. 2013, 1, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Rieh, S.Y. Judgment of information quality and cognitive authority in the Web. J. Am. Soc. Inf. Sci. Technol. 2002, 53, 145–161. [Google Scholar] [CrossRef]
- Buckland, M. Data management as bibliography. Bull. Am. Soc. Inf. Sci. Technol. 2011, 37, 34–37. [Google Scholar] [CrossRef] [Green Version]
- Yoon, A. End users’ trust in data repositories: Definition and influences on trust development. Arch. Sci. 2014, 14, 17–34. [Google Scholar] [CrossRef] [Green Version]
- Miller, H. The multiple dimensions of information quality. Inf. Syst. Manag. 1996, 13, 79–82. [Google Scholar] [CrossRef]
- Deutsche Klimarechenzentrum, Quality Assurance of Data. Available online: https://www.dkrz.de/up/services/data-distribution/data-publication/quality-assurance-of-data (accessed on 29 January 2020).
- Colepicolo, E. Information reliability for academic research: Review and recommendations. New Libr. World 2015, 116, 646–660. [Google Scholar] [CrossRef]
- King, G. Replication, replication. Polit. Sci. Polit. 1995, 28, 444–452. [Google Scholar] [CrossRef] [Green Version]
- Yoon, A.; Lee, Y.Y. Factors of trust in data reuse. Online Inf. Rev. 2019. [Google Scholar] [CrossRef]
- Borgman, C.L. Scholarship in the Digital Age: Information, Infrastructure, and the Internet; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Faniel, I.M.; Kriesberg, A.; Yakel, E. Social scientists’ satisfaction with data reuse. J. Assoc. Inf. Sci. Technol. 2015, 67, 1404–1416. [Google Scholar] [CrossRef] [Green Version]
- Zilinski, L.D.; Nelson, M.S. Thinking critically about data consumption: Creating the data credibility checklist. Proc. Am. Soc. Inf. Sci. Technol. 2014, 51, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Zimmerman, A.S. New knowledge from old data: The role of standards in the sharing and reuse of ecological data. Sci. Technol. Hum. Values 2008, 33, 631–652. [Google Scholar] [CrossRef]
- ISO/IEC 25012. Available online: https://iso25000.com/index.php/en/iso-25000-standards/iso-25012 (accessed on 29 January 2020).
- Demchenko, Y.; Grosso, P.; De Laat, C.; Membrey, P. In addressing big data issues in scientific data infrastructure. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 48–55. [Google Scholar]
- Dresp, B.; Dresp-Langley, B.; Ekseth, O.K.; Fesl, J.; Gohshi, S.; Kurz, M.; Sehring, H.-W. Occam’s Razor for Big Data? On detecting quality in large unstructured datasets. Appl. Sci. 2019, 9, 3065. [Google Scholar] [CrossRef] [Green Version]
- Ceravolo, P.; Azzini, A.; Angelini, M.; Catarci, T.; Cudré-Mauroux, P.; Damiani, E.; Mazak, A.; Van Keulen, M.; Jarrar, M.; Santucci, G. Big data semantics. J. Data Semant. 2018, 7, 65–85. [Google Scholar] [CrossRef]
- Frické, M. Big data and its epistemology. J. Assoc. Inf. Sci. Technol. 2015, 66, 651–661. [Google Scholar] [CrossRef]
- Halme, P.; Komonen, A.; Huitu, O. Solutions to replace quantity with quality in science. Trends Ecol. Evol. 2012, 27, 586–588. [Google Scholar] [CrossRef]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inform. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Schöch, C. Big? Smart? Clean? Messy? Data in the Humanities. J. Dig. Hum. 2013, 2, 2–13. [Google Scholar]
- Breaking Big: When Big Data Goes Bad. In The Importance of Data Quality Management in Big Data Environments; Information Builders: New, York, NY, USA, 2014.
- Smith, A.M. Data Governance Best Practices—The Beginning. EIM Insight 2013, 1. Available online: http://www.eiminstitute.org/library/eimi-archives/volume-1-issue-1-march-2007-edition/data-governance-best-practices-2013-the-beginning (accessed on 29 January 2020).
- Willoughby, S. Open data and the environment. In The State of Open Data: Histories and Horizons; Davies, T., Walker, S., Rubinstein, M., Perini, F., Eds.; African Minds and International Development Research Centre: Cape Town, South Africa; Ottawa, ON, Canada, 2019; pp. 103–118. [Google Scholar]
- Khatri, V.; Brown, C.V. Designing data governance. Commun. ACM 2010, 53, 148–152. [Google Scholar] [CrossRef]
- DGI Definitions of Data Governance. Available online: http://www.datagovernance.com/adg_data_governance_definition/ (accessed on 29 January 2020).
- Sarsfield, S. The Data Governance Imperative: A Business Strategy for Corporate Data; IT Governance Publishing: Ely, UK, 2009. [Google Scholar]
- IBM. Successful Information Governance through High-Quality Data; IBM Corporation: Armonk, NY, USA, 2012. [Google Scholar]
- ORACLE. The Five Most Common Big Data Integration Mistakes to Avoid; Oracle Corporation: Redwood City, CA, USA, 2015. [Google Scholar]
- Weber, K.; Otto, B.; Österle, H. One size does not fit all—A contingency approach to data governance. J. Data Inf. Qual. 2009, 1, 4. [Google Scholar] [CrossRef]
- Al-Badi, A.; Tarhini, A.; Khan, A.I. Exploring Big Data Governance Frameworks. Procedia Comput. Sci. 2018, 141, 271–277. [Google Scholar] [CrossRef]
- Rosenbaum, S. Data governance and stewardship: Designing data stewardship entities and advancing data access. Health Serv. Res. 2010, 45, 1442–1455. [Google Scholar] [CrossRef] [Green Version]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seaver, N. The nice thing about context is that everyone has it. Media Cult. Soc. 2015, 37, 1101–1109. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Intrinsic DQ | Accessibility DQ | Contextual DQ | Representational DQ |
|---|---|---|---|
| accuracy | accessibility | the amount of data | concise representation |
| objectivity, | access security | completeness | consistent representation |
| believability | relevancy | ease of understanding | |
| reputation | timelines | interpretability | |
| value-addedness |
| Inherent Data Quality | System-Dependent Data Quality | Inherent and System-Dependent Data Quality |
|---|---|---|
| Accuracy | Availability | Accessibility |
| Completeness | Portability | Compliance |
| Consistency | Recoverability | Confidentiality |
| Credibility | Efficiency | |
| Currentness | Precision | |
| Traceability | ||
| Understandability |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koltay, T. Quality of Open Research Data: Values, Convergences and Governance. Information 2020, 11, 175. https://doi.org/10.3390/info11040175
Koltay T. Quality of Open Research Data: Values, Convergences and Governance. Information. 2020; 11(4):175. https://doi.org/10.3390/info11040175
Chicago/Turabian StyleKoltay, Tibor. 2020. "Quality of Open Research Data: Values, Convergences and Governance" Information 11, no. 4: 175. https://doi.org/10.3390/info11040175
APA StyleKoltay, T. (2020). Quality of Open Research Data: Values, Convergences and Governance. Information, 11(4), 175. https://doi.org/10.3390/info11040175