1. Introduction
Collaborative wiki services are becoming an increasingly popular source of knowledge in different countries. One of the most prominent examples of such free knowledge bases is Wikipedia. Nowadays this encyclopedia contains over 52 million articles in over 300 languages versions [
1]. Articles in each language version can be created and edited even by anonymous (not registered) users. Moreover, due to the relative independence of contributors in each language, we can often encounter differences between articles about the same topic in various language versions of Wikipedia.
One of the most important elements that significantly affect the quality of information in Wikipedia is availability of a sufficient number of references to the sources. Those references can confirm facts provided in the articles. Therefore, community of the Wikipedians (editors who write and edit articles) attaches great importance to reliability of the sources. However, each language version can provide its own rules and criteria of reliability, as well as its own list of perennial sources whose use on Wikipedia are frequently discussed [
2]. Moreover, this reliability criteria and list of reliable sources can change over time.
According to English Wikipedia content guidelines, information in the encyclopedia articles should be based on reliable, published sources. The word “source” in this case can have three interpretations [
2]: the piece of work (e.g., a book, article, research), the creator of the work (e.g., a scientist, writer, journalist), the publisher of the work (e.g., MDPI or Springer). The term “published” is often associated with text materials in printed format or online. Information in other format (e.g., audio, video) also can be considered as a reliable source if it was recorded or distributed by a reputable party.
The reliability of a source in Wikipedia articles depends on context. Academic and peer-reviewed publications as well as textbooks are usually the most reliable sources in Wikipedia. At the same time not all scholarly materials can meet reliability criteria: some works may be outdated or be in competition with other research in the field, or even controversial within other theories. Another popular source of Wikipedia information are well-established press agencies. News reporting from such sources is generally considered to be reliable for statements of fact [
2]. However, we need to take precautions when reporting breaking-news as they can contain serious inaccuracies.
Despite the fact that Wikipedia articles must present a neutral point of view, referenced sources are not required to be neutral, unbiased, or objective. However, websites whose content is largely user-generated is generally unacceptable. Such sites may include: personal or group blogs, content farms, forums, social media (e.g., Facebook, Reddit, Twitter), IMDb, most wikis (including Wikipedia) and others. Additionally, some sources can be deprecated or blacklisted on Wikipedia.
Given the fact that there are more than 1.5 billion websites on the World Wide Web [
3], it is a challenging task to assess the reliability of all of them. Additionally, the reliability is a subjective concept related to information quality [
4,
5,
6] and each source can be differently assessed depending on topic and language community of Wikipedia. It should also be taken into account that reputation of the newspaper or website can change over time and periodic re-assessment may be necessary.
According to the English Wikipedia content guideline [
2]: “in general, the more people engaged in checking facts, analyzing legal issues and scrutinizing the writing, the more reliable the publication.” Related work described in
Section 2 showed, that there is a field for improving approaches related to assessment of the sources based on publicly available data of Wikipedia using different measures of Wikipedia articles. Therefore, we decided to extract measures related to the demand for information and quality of articles and to use them to build 10 models for assessment of popularity and reliability of the source in different language versions in various periods. The simplest model was based on frequency of occurrence which is commonly used in other related works [
7,
8,
9,
10]. Other nine novel models used various combinations of measures related to quality and popularity of Wikipedia articles. The models were described in
Section 3.
In order to extract sources from references of Wikipedia articles in different languages, we designed and implemented own algorithms in Python. In
Section 4 we described basic and complex extraction methods of the references in Wikipedia articles. Based on extracted data from references in each Wikipedia article we added different measures related to popularity and quality of Wikipedia articles (such as pageviews, number of references, article length, number of authors) to assess sources. Based on the results we built rankings of the most popular and reliable sources in different languages editions of Wikipedia. Additionally, we compare positions of selected sources in reliability ranking in different language versions of Wikipedia in
Section 5. We also assessed the similarity of the rankings of the most reliable sources obtained by different models in
Section 6.
We also designed own algorithms in leveraging data from semantic databases (Wikidata and DBpedia) to extract additional metadata about the sources, conduct their unification and classification to find the most reliable in the specific domains. In
Section 7 we showed results of analysis sources based on some parameters from citation templates (such as “publisher” and “journal”) and separately we showed the analysis the topics of sources based on semantic databases.
Using different periods we compared the result of popularity and reliability assessment of the sources in
Section 8. Comparing the obtained results we were able to find growth leaders described in
Section 9. We also presented the assessment of effectiveness of different models in
Section 10.1. Additionally we provided information about limitation of the study in
Section 10.2.
2. Recent Work
Due to the fact that source reliability is important in terms of quality assessment of Wikipedia articles, there is a wide range of works covering the field of references analysis of this encyclopedia.
Part of studies used reference counts in the models for automatic quality assessment of the Wikipedia articles. One of the first works in this direction used reference count as structural feature to predict the quality of Wikipedia articles [
11,
12]. Based on the references users can assess the trustworthiness of Wikipedia articles, therefore we consider the source of information as an important factor [
13].
Often references contain an external link to the source page (URL), where cited information is placed. Therefore, including in models the number of the external links in Wikipedia articles can also help to assess information quality [
14,
15].
In addition to the analysis of quantity, there are studies analyzing the qualitative characteristics and metadata related to references. One of the works used special identifiers (such as DOI, ISBN) to unify the references and find the similarity of sources between language versions of Wikipedia [
8]. Another recent study analyzed engagement with citations in Wikipedia articles and found that references are consulted more commonly when readers cannot find enough information in selected Wikipedia article [
16]. There are also works, which showed that a lot of citations in Wikipedia articles refer to scientific publications [
8,
17], especially if they are open-access [
18], wherein Wikipedia authors prefer to put recently published journal articles as a source [
10]. Thus, Wikipedia is especially valuable due to the potential of direct linking to other primary sources. Another popular source of the information in Wikipedia is news website and there is a method for automatic suggestion of the news sources for the selected statements in articles [
19].
Reference analysis can be important for quality assessment of Wikipedia articles. At the same time, articles with higher quality must have more proven and reliable sources. Therefore, in order to assess the reliability of specific source, we can analyze Wikipedia articles, in which related references are placed.
Relevance of article length and number of references for quality assessment of Wikipedia content was supported by many publications [
15,
20,
21,
22,
23,
24,
25,
26]. Particularly interesting is the combination of these indicators (e.g., references and articles length ratio) as it can be more actionable in quality prediction than each of them separately [
27].
Information quality of Wikipedia depends also on authors who contributed to the article. Often articles with the high quality are jointly created by a large number of different Wikipedia users [
28,
29]. Therefore, we can use the number of unique authors as one of the measures of quality of Wikipedia articles [
26,
30,
31]. Additionally, we can take into the account information about experience of Wikipedians [
32].
One of the recent studies showed that after loading a page, 0.2% of the time the reader clicks on an external reference, 0.6% on an external link and 0.8% hovers over a reference [
9]. Therefore, popularity can play an important role not only for quality estimation of information in specific language version of Wikipedia [
33] but also for checking reliability of the sources in it. Larger number of readers of a Wikipedia article may allow for more rapid changes in incorrect or outdated information [
26]. Popularity of an article can be measured based on the number of visits [
34].
Taking into account different studies related to reference analysis and quality assessment of Wikipedia articles, we created 10 models for source assessment. Unlike other studies we used more complex methods of extraction of references and included more language versions of Wikipedia. Additionally, we used semantic layer to identify source type and metadata to create ranking of the sources in specific domains. We also took into account different periods to compare the reliability indicators of the source in various months and to find the growth leaders. Moreover, models were used to assess references based on publicly available data (Wikimedia Downloads [
35]), so anybody can use our models for different purposes.
3. Popularity and Reliability Models of the Wikipedia Sources
In this Section we describe ten models related to popularity and reliability of the sources. In most cases source means domain (or subdomain) of the URL in references. Models are identified with abbreviations:
F model—based on frequency (F) of source usage.
P model—based on cumulative pageviews (P) of the article in which source appears.
PR model—based on cumulative pageviews (P) of the article in which source appears divided by number of the references (R) in this article.
PL model—based on cumulative pageviews (P) of the article in which source appears divided by article length (L).
Pm model—based on daily pageviews median (Pm) of the article in which source appears.
PmR model—based on daily pageviews median (Pm) of the article in which source appears divided by number of the references (R) in this article.
PmL model—based on daily pageviews median (Pm) of the article in which source appears divided by article length (L).
A model—based on number of authors (A) of the article in which source appears.
AR model—based on number of authors (A) of the article in which source appears divided by number of the references (R) in this article.
AL model—based on number of authors (A) of the article in which source appears divided by article length (L).
Frequency of source usage in
F model means how many references contain the analyzed domain in URL. This method was commonly used in related works [
7,
8,
9,
10]. Here we take into account a total number of appearances of such reference, i.e., if the same source is cited 3 times, we count the frequency as 3. Equation (
1) shows the calculation for
F model.
where
s is the source,
n is a number of the considered Wikipedia articles,
is a number of references using source
s (e.q. domain in URL) in article
i.
Pageviews, i.e., number of times a Wikipedia article was displayed, is correlated with its quality [
33]. We can expect that articles read by many people are more likely to have verified and reliable sources of information. The more people read the article the more people can notice inappropriate source and the faster one of the readers decides to make changes.
P model includes additionally to the frequency of source also cumulative pageviews of the article in which this source appears. Therefore, the source that was mentioned in a reference in a popular article can have bigger value then source that was mentioned even in several less popular articles. Equation (
2) presents the calculation of measure using
P model.
where
s is the source,
n is a number of the considered Wikipedia articles,
is a number of references using source
s (e.q. domain in URL) in article
i,
is cumulative pageviews value of article
i.
PR model uses cumulative pageviews divided by the total number of the references in a considered article. Unlike the previous model here we take into account visibility of the references using the analyzed source. We assume that in general the more references in the article, the less visible the specific reference is Equation (
3) shows the calculation of measure using
PR model.
where
s is the source,
n is a number of the considered Wikipedia articles,
is total number of the references in article
i,
is a number of the references using source
s (e.q. domain in URL) in article
i,
is cumulative pageviews value of article
i.
Another important aspect of the visibility of each reference is the length of the entire article. Therefore, we provide additional
PL model that operates on the principles described in Equation (
4).
where
s is the source,
n is a number of the considered Wikipedia articles,
is the length of source code (wiki text) of article
i,
is a number of references using source
s (e.q. domain in URL) in article
i,
is cumulative pageviews value of article
i.
Popularity of an article can be measured in different ways. As it was proposed in [
26] we decided to measure pageviews also as daily pageviews median (Pm) of individual articles. Thereby we provided additional models
Pm,
PmR,
PmL that are modified versions of models
P,
PR,
PL, respectively. The modification consists in replacement of cumulative pageviews with daily pageviews median.
As the pageviews value of article is more related to readers, we also propose a measure addressing the popularity among authors, i.e., number of users who decided to add content or make changes in the article. Given the assumptions of previous models we propose analogous models related to authors: models
A,
AR,
AL are described in Equations (
5)–(
7), respectively.
where
s is the source,
n is a number of the considered Wikipedia articles,
is a number of references using source
s (e.q. domain in URL) in article
i,
is total number of authors of article
i.
where
s is the source,
n is a number of the considered Wikipedia articles,
is total number of the references in article
i,
is a number of references using source
s (e.q. domain in URL) in article
i,
is total number of authors of article
i.
where
s is the source,
n is a number of the considered Wikipedia articles,
is the length of source code (wiki text) of article
i,
is a number of references using source
s (e.q. domain in URL) in article
i,
is total number of authors of article
i.
It is important to note that for pageviews measures connected with sources extracted in the end of the assessed period we use data for the whole period (month). For example, if references were extracted based on dumps as of 1 March 2020, then we considered pageviews of the articles for the whole February 2020.
4. Extraction of Wikipedia References
Wikimedia Foundation back-ups each language version of Wikipedia at least once a month and stores it on a dedicated server as “Database backup dumps”. Each file contains different data related to Wikipedia articles. Some of them contain source codes of the Wikipedia pages in wiki markup, some of them describe individual elements of articles: headers, category links, images, external or internal links, page information and others. There are even files that contain the whole edit history of each Wikipedia page.
Variety of dump files gives possibility to extract necessary data in different ways. Some of them allow to get results in a relatively short time using simple parser. However, other important information may be missing in such files. Therefore, in this section we describe two methods of extracting the data about references in Wikipedia.
4.2. Complex Extraction
Using Wikipedia dumps from March 2020, we have extracted all references from over 40 million articles in 55 language editions that have at least 100,000 articles and at least 5 article depth index in recent years as it was proposed in [
26]. Complex extraction was based on source code of the articles. Therefore, we used other dump file (comparing to basic extraction)-for example dump file as of March 2020 for English Wikipedia that we used is “enwiki-20200301-pages-articles.xml.bz2”.
In wiki-code references are usually placed between special tags <ref>…</ref>. Each reference can be named by adding “name” parameter to this tag: <ref name=”...”>...</ref>. After such reference was defined in the articles, it can be placed elsewhere in this article using only <ref name=”...” />. This is how we can use the same reference several times using default wiki markup. However, there are other possibilities to do so. Depending on language version of Wikipedia we can also use special templates with specific names and set of parameters. It is not even mandatory that some of them must be placed under <ref>...</ref> tag.
In general, we can divide references into two groups: with special template and without it. In the case of references without special template they usually have URL of source and some optional description (e.g., title). References with special templates can have different data describing the source. Here in separate fields one can add information about author(s), title, URL, format, access date, publisher and others. The set of possible parameters with predefined names depends on language version and type of templates, which can describe book, journal, web source, news, conference and others.
Figure 2 shows the most commonly used templates in
<ref> tags in English. Among the most commonly used templates in this Wikipedia language versions are: ’Cite web’, ’Cite news’, ’Cite book’, ’Cite journal’, National Heritage List for England (’NHLE’), ’Citation’, ’Webarchive’, ’ISBN’, ’In lang’, ’Dead link’, Harvard citation no brackets (’Harvnb’), ’Cite magazine’. In order to extract information about sources we created own algorithms that take into account different names of reference templates and parameters in each language version of Wikipedia. The most commonly used parameters in this language version are: title, url, accessdate, date, publisher, last, first, work, website and access-date.
It is important to note that the presence of some references cannot be identified directly based on the source (wiki) code of the articles. Sometimes infoboxes or other templates in the Wikipedia article can put additional references to the rendered version of article.
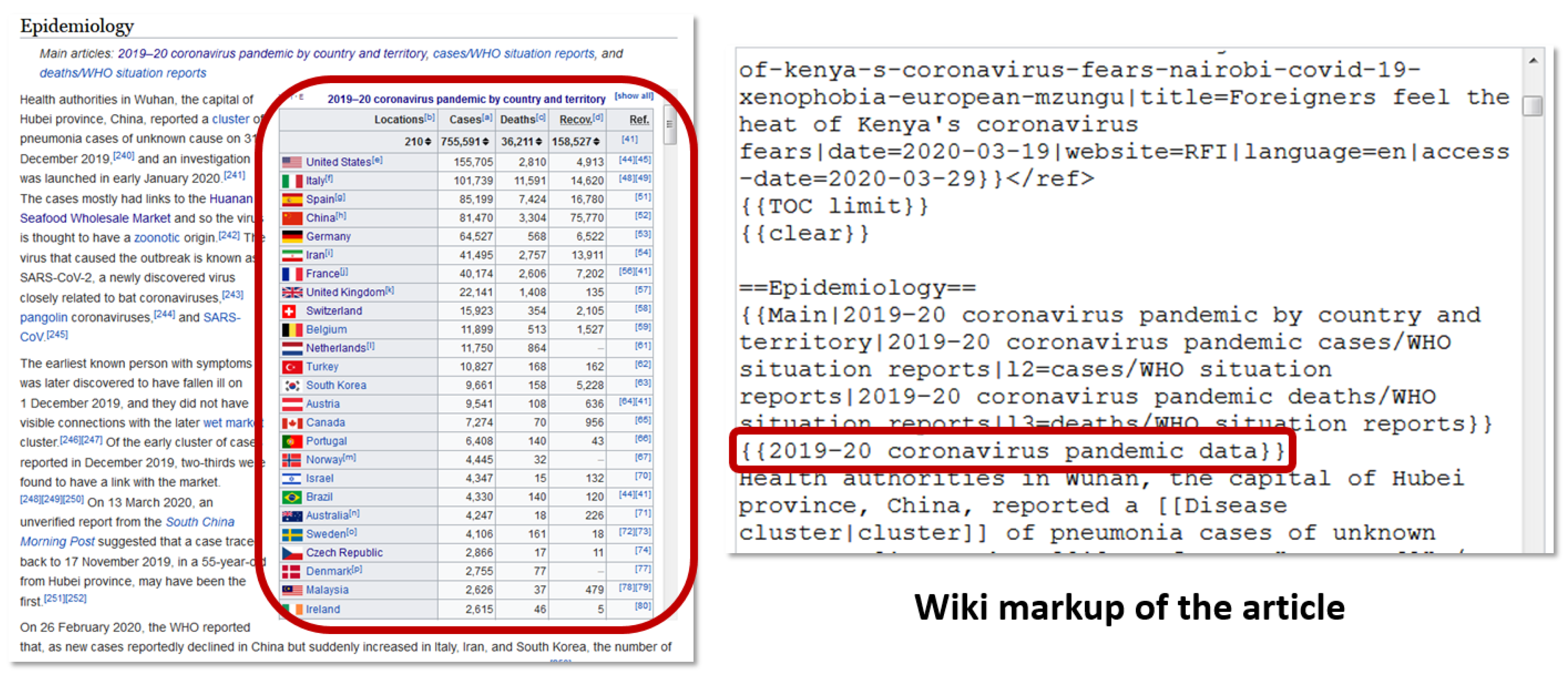
Figure 3 shows such situation on example of table with references in the Wikipedia article “2019–2020 coronavirus pandemic” that was added using template “2019–2020 coronavirus pandemic data”. In our approach we include such references in the analysis when such templates appear in the Wikipedia articles.
Some of the most popular templates allows to add identifiers to the source such as DOI, JSTOR, PMC, PMID, arXiv, ISBN, ISSN, OCLC and others. Some references can include special templates related to identifiers such DOI, ISBN, ISSN can be described as separate templates. For example, value for “doi” parameter can be written as “doi|...”. Moreover, some of the templates allow to insert several identifiers for one reference-templates for ISBN, ISSN identifiers allows to put two or more values-for example we can put in code “ISBN|...|...” or “ISSN|...|...|...”.
Table 2 shows the extraction statistics of the references with DOI, ISBN, ISSN, PMID, PMC identifiers.
Table 3 shows the extraction statistics of the references with arXiv, Bibcode, JSTOR, LCCN, OCLC identifiers.
Special identifiers can determine similarity between the references even though they have different parameters in description (e.g., titles in another languages). Unification of these references can be done based on identifiers. For example, if a reference has DOI number “10.3390/computers8030060”, we give it URL “
https://doi.org/10.3390/computers8030060”. More detailed information about identifiers which we used to unifying the references is shown in
Table 4.
One of the advantages of the complex method of extraction (comparing to basic one, which was described in previous subsection) is ability to distinguish between types of source URLs: actual link to the page and archived copy. For linking to web archiving services such as the Wayback Machine, WebCite and other web archiving services special template “Webarchive” can be used. In most cases the template needs only two arguments, the archive url and date. This template is used in different languages and sometimes has different names. Additionally, in a single language this template can be called using other names, which are redirects to original one. For example in English Wikipedia alternative names of this templates can be used: “Weybackdate”, “IAWM”, “Webcitation”, “Wayback”, “Archive url”, “Web archive” and others. Using information from those templates we found the most frequent domains of web archiving services in references.
It is important to note that depending on language version of Wikipedia template about archived URL addresses can have own set of parameters and own way to generate final URL address of the link to the source. For example, in the English Wikipedia template Webarchive has parameter url which must contain full URL address from web archiving service. At the same time related template Webarchiv in German Wikipedia has also other ways to define a link to archived source-one can provide URL of the original source page (that was created before it was archived) using url parameter and (or) additionally use parameters depending on the archive service: “wayback”, “archive-is”, “webciteID” and others. In this case, to extract the full URL address of the archived web page, we need to know how inserted value of each parameter affects the final link for the reader of the Wikipedia article in each language version.
In the extraction we also took into account short citation from “Harvard citation” family of templates which uses parenthetical referencing. These templates are generally used as in-line citations that link to the full citation (with the full meta data of the source). This enables a specific reference to be cited multiple times having some additional specification (such as a page number) with other details (comments). We included in the analysis following templates: “Harvnb” (Harvard citation), “harvnb” (Harvard citation no brackets), “Harvtxt” (Harvard citation text), “Harvcol”, “Harvcolnb”, “Sfn” (Shortened footnote template) and others. Depending on language version of Wikipedia, each template can have another corresponding name and additional synonymous names. For example in English Wikipedia, “Harvard citation”, “Harv” and “Harvsp” mean the same template (with the same rules), while corresponding template in French has such names as “Référence Harvard”, “Harvard” and also “Harv”.
Taking into account unification of URLs based on special identifiers, excluding URLs of archived copies of the sources and including special templates outside
<ref> tags, we counted the number of all and unique references in each considered language version.
Table 5 presents total number of articles, number of articles with at least 1 reference, at least 10 references, at least 100 references and number of total and unique number of references in each considered language version of Wikipedia.
Analysis of the numbers of the references extracted by complex extraction showed other statistics comparing to basic extraction of the external links described in
Section 4.1. The largest share of the article with at least one references has Vietnamese Wikipedia-84.8%. Swedish, Arabic, English and Serbian Wikipedia has 83.5%, 79.2%, 78.2% and 78.1% share of such articles, respectively. If we consider only articles with at least 100 references, then the largest share of such articles will have Spanish Wikipedia-3.5%. English, Swedish and Japanese Wikipedia has 1.1%, 0.9% and 0.8% share of such articles, respectively. However, the largest total number of the references per number of articles has English Wikipedia—9.6 references. Relatively large number of references per article has also Spanish (9.2) and Japanese (7.1) Wikipedia.
The largest number of the references with DOI identifier has English Wikipedia (over 2 million) at the same time has the largest number of average number of references with DOI per article—34.3%. However, the largest share of the references with DOI among all references has Galician (8.4%) and Ukrainian (6.6%) Wikipedia.
The largest number of the references with ISBN identifier has English Wikipedia (over 3.5 million) at the same time has the largest number of average number of references with ISBN per article-34.3%. However, the largest share of the references with ISBN among all references has Kazakh (20.3%) and Belarusian (13.1%) Wikipedia.
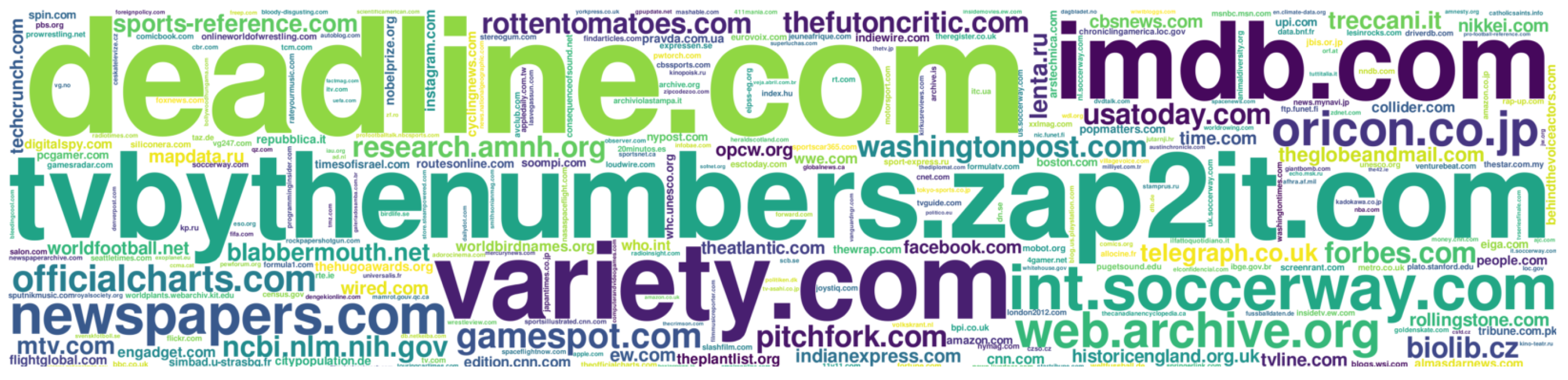
Based on the extraction of URLs from the obtained references, we can find which of the domains (or subdomains) are often used in Wikipedia articles.
Figure 4 shows the most popular domains (and subdomains) in over 200 million references of Wikipedia articles in 55 language versions. Comparing results with basic extraction (see
Section 4.1) we got some changes in the top 10 of the most commonly used sources in references: deadline.com (Deadline Hollywood), tvbythenumbers.zap2it.com (TV by the Numbers), variety.com (Variety-american weekly entertainment magazine), imdb.com (Internet Movie Database), newspapers.com (historic newspaper archive), int.soccerway.com (Soccerway-website on football), web.archive.org (Wayback Machine), oricon.co.jp (Oricon Charts), officialcharts.com (The Official UK Charts Company), gamespot.com (GameSpot-video game website).
6. Similarity of Models
According to the results presented in the previous section, each source can be placed on a different position in the ranking of the most reliable sources depending on the model. It is worthwhile to check how similar are the results obtained by different models. For this purpose we used Spearman’s rank correlation to quantify, in a scale from −1 to 1 degree, which variables are associated. Initially we took only sources that appeared in the top 100 in at least one of the rankings of the most popular and reliable sources in multilingual Wikipedia in February 2020. Altogether, we obtained 180 sources and their positions in each of the rankings.
Table 6 shows Spearman’s correlation coefficients between these rankings.
We can observe that the highest correlation is between rankings based on P and Pm model–0.99. This can be explained through similarities of the measures in models—the first is based on cumulative page views and the latter on median of daily page views in a given month.
Another pair of similar rankings is
PL and
PR models—0.98. Both measures use total page views data. In the first model value of this measure is divided by the number of references, in the second by article length. As we mentioned before in
Section 2 and
Section 3, the number of references and article lengths are very important in quality assessment of the Wikipedia articles and are also correlated—we can expect that longer articles can have a bigger number of references.
In connection with previously described similarities between P and Pm, we can also explain similarity between models PL and PmR with 0.97 value of the Spearman’s correlation coefficient.
The lowest similarity is between F and P model–0.37. It comes from different nature of these measures. In Wikipedia anyone can create and edit content. However, not every change in the Wikipedia articles can be checked by a specialist in the field, for example by checking reliability of the inserted sources in the references. Despite the fact that some sources are used frequently, there is a chance that they have not been verified yet and not replaced by more reliable sources. The next pair of rankings with the low correlation is Pm and F model. Such low correlation is obviously connected with similarity of the page view measures (P and Pm).
It is also important to note the low similarity between rankings based on AR and P models–0.41. Such differences can be connected with the measures that are used in these models. AR model uses the number of authors for whole edition history of article divided by the number of references whereas P uses page view data for selected month.
In the second iteration we extended the number of sources to top 10,000 in each ranking of the most popular and reliable sources in multilingual Wikipedia in February 2020. We obtained 19,029 sources.
Table 7 shows Spearman’s correlation coefficients between these extended rankings.
In case of extended rankings (top 10,000) there are no significant changes with regard to the the Spearman’s correlation coefficient values compared to the top 100 model in
Table 6. However, it should be noted that the largest difference in values of coefficients appears between
PR and
A model–0.26 (0.82 in the top 100 and 0.56 in the top 10,000).
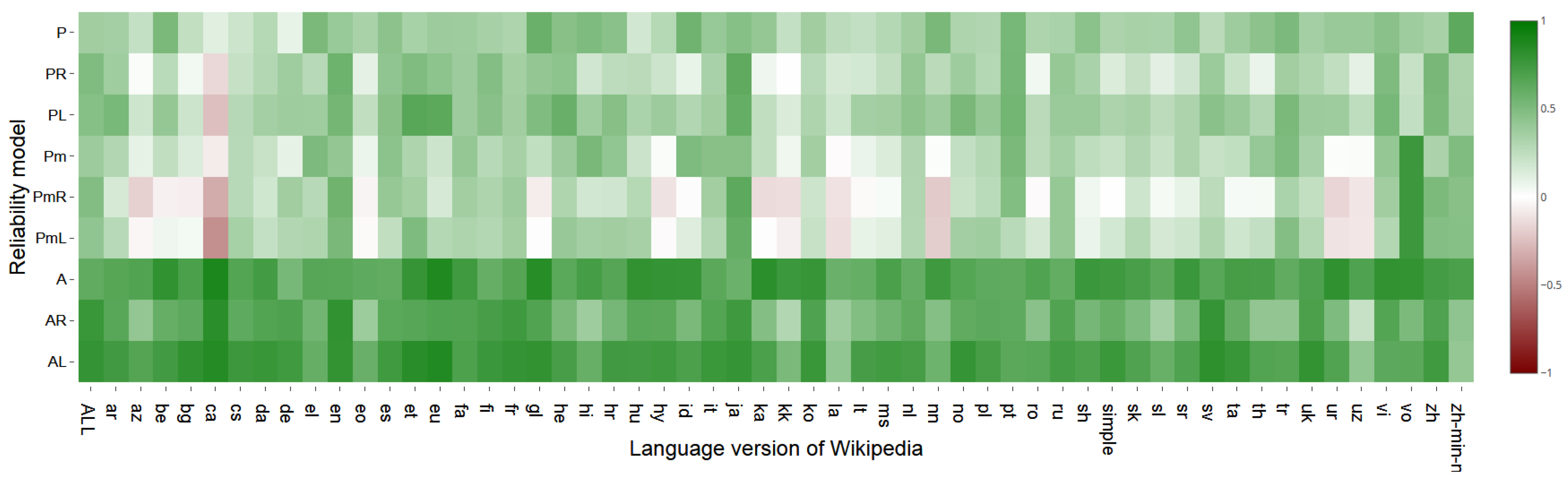
The heatmap in
Figure 5 shows Spearman’s correlation coefficients between rankings of the top 100 most reliable sources in each language version of Wikipedia in February 2020 obtained by
F-model in comparison with other models.
Comparing the results of Spearman’s correlation coefficients within each of considered language version of Wikipedia, we can find that the largest average correlation between F-model and other models is for Japanese (ja) and English (en) Wikipedia—0.61 and 0.59, respectively. The smallest average value of the correlation coefficients among languages have Catalan (ca) and Latin (la) Wikipedia—0.16 and 0.19, respectively. Considering coefficient values among all languages of each pair F-model and other model, the largest average value has F/AL-model pairs (0.71), the smallest—F/PmR-models (0.18).
10. Discussion of the Results
This study describes different models for popularity and reliability assessment of the sources in different language version of Wikipedia. In order to use these models it is necessary to extract information about the sources from references and also measures related to quality and popularity of the Wikipedia articles. We observed that depending on the model positions of the websites in the rankings of the most reliable sources can be different. In language versions that are mostly used on the territory of one country (for example Polish, Ukrainian, Belarusian), the highest positions in such rankings are often occupied by local (national) sources. Therefore, community of editors in each language version of Wikipedia can have own preferences when a decision is made to enable (or disable) the source in references as a confirmation of the certain fact. So, the same source can be reliable in one language version of Wikipedia, while the community of editors of another language may not accept it in the references and remove or replace this source in an article.
The simplest of the proposed models in this study was based on frequency of occurrences, which is commonly used in related studies. Other 9 novel models used various combinations of measures related to quality and popularity of Wikipedia articles. We provided analysis on how the results differ depending on the model. For example, if we compare frequency-based (F) rankings with other (novel) in each language version of Wikipedia, then the highest average similarity will have AL-model (0.71 of rank correlation coefficient), the least – PmR-model (0.18 of rank correlation coefficient).
The analysis of sources was conducted in various ways. One of the approaches was to extract information from citation templates. Based on the related parameter in references of English Wikipedia we found the most popular publishers (such as United States Census Bureau, Oxford University Press, BBC, Cambridge University Press). The most commonly used journals in citation templates were: Nature, Astronomy and Astrophysics, Science, The Astrophysical Journal, Lloyd’s List, PLOS ONE, Monthly Notices of The Royal Astronomical Society, The Astronomical Journal, Billboard. However, such approach was limited and did not include references without citation templates. Therefore, we decided to use semantic databases to identify the sources and their types.
After obtaining data about types of the sources we found that magazines and business-related sources are in the top 10 of the most reliable types of sources in all considered languages. However, the preferred type of source in references depends on language version of Wikipedia. For example, film databases are one of the most reliable sources in Arabic, French, Italian, Polish and Portuguese Wikipedia. In other languages such sources are placed below 19th place.
Including data from Wikidata and DBpedia allowed us to find the best sources in specific area. Using information about the source types and after choosing only periodical ones, we found that there are sources that have stable reliability in all models - “Variety” has always 1st place, “Entertainment Weekly” 2nd-3nd place, “The Washington Post” occupies 2nd-4th place, “USA Today” took 4th-5th place depending on the model. Despite the fact that “Lenta.ru” is the 6th most commonly used periodical source in different languages of Wikipedia (using F model), it is placed on 21st and 19th place using P and Pm models respectively. “The Daily Telegraph” is in the top 10 most reliable periodical sources in all models. “People” is on 18th place in the frequency ranking but at the same time took 4th place in PmR model.
Using complex extraction of the references in addition to data from February 2020 we also used dumps from November 2019, December 2019, and January 2020. Based on those data we measured popularity and reliability of the sources in different months. After limiting the sources to periodicals we found that in four considered months the top 10 most reliable periodical sources in multilingual Wikipedia always included: “Variety”, “Entertainment Weekly”, “The Washington Post”, ”People”, “USA Today”, “The Indian Express”, “The Daily Telegraph”, “Pitchfork”, and “Time”. Minor changes in the ranking of sources appearing during the considered period are mainly due to a large margin in absolute values of popularity and reliability measurement.
Different approaches assessing reliability of the sources presented in this research contribute to a better understanding which references are more suitable for specific statements that describe subjects in a given language. Unified assessment of the sources can help in finding data of the best quality for cross-language data fusion. Such tools as DBpedia FlexiFusion or GlobalFactSync Data Browser [
41,
42] collect information from Wikipedia articles in different languages and present statements in a unified form. However, due to independence of edition process in each language version, the same subjects can have similar statements with various values. For example, population of the city in one language can be several years old, while other language version of the article about the same city can update this value several times a year on a regular basis along with information about the source. Therefore, we plan to create methods for assessing sources of such conflict statements in Wikipedia, Wikidata and DBpedia to choose the best one. This can help to improve quality in cross-language data fusion approaches.
Proposed models can also help to assess the reliability of sources in Wikipedia on a regular basis. It can support understanding preferences of the editors and readers of Wikipedia in particular month. Additionally, it can be helpful to automatically detect sources with low reliability before user will insert it in the Wikipedia article. Moreover, results obtained using the proposed models may be used to suggest Wikipedians sources with higher reliability scores in selected language version or selected topic.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






