Main Influencing Factors of Quality Determination of Collaborative Open Data Pages



Abstract
:1. Introduction
2. Research Design, Data Collection and Analysis
2.1. Research Design
2.2. Data Collection
2.3. Data Analysis
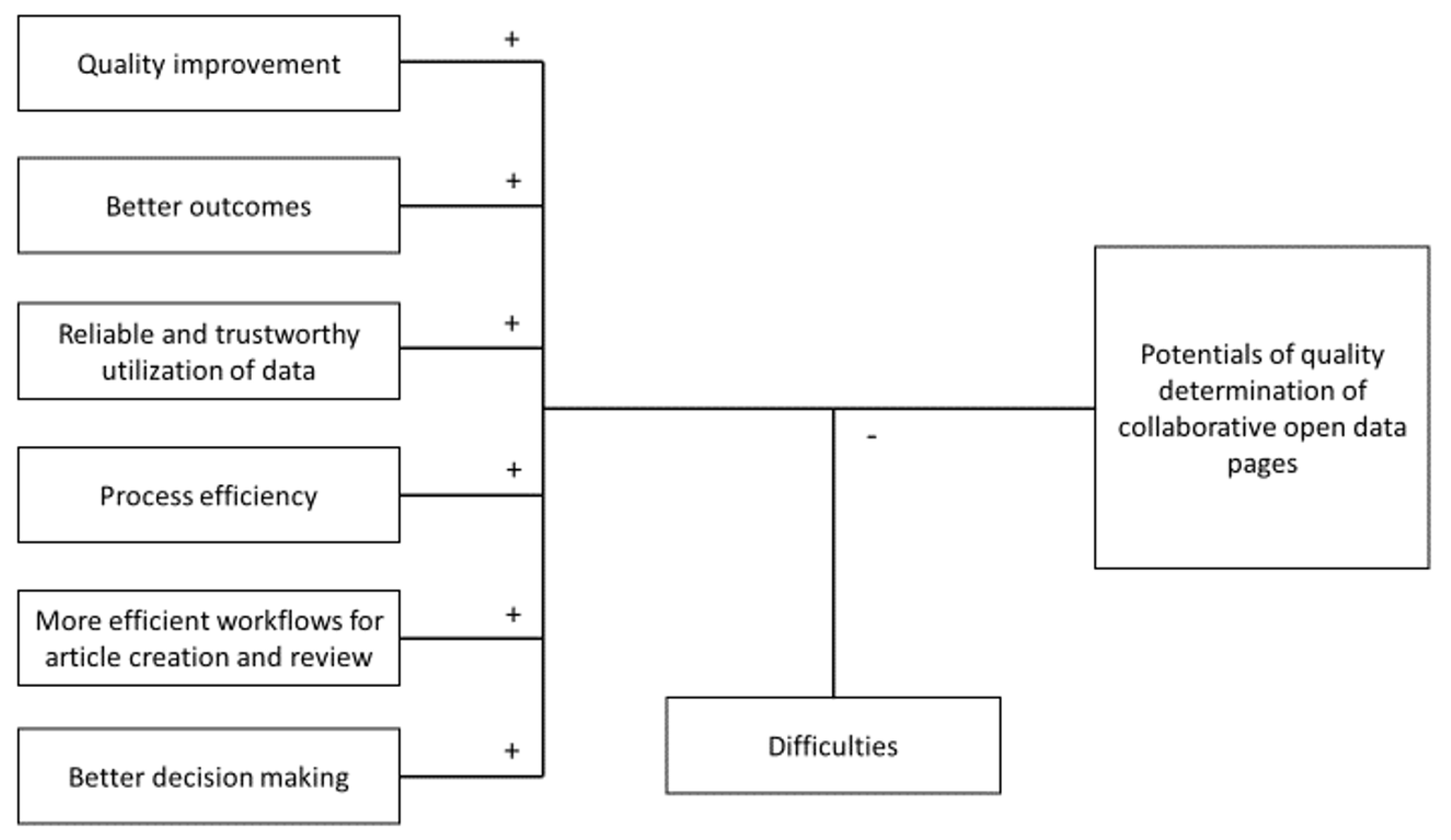
3. The Potentials of Quality Determination of Collaborative Open Data Pages
3.1. Potentials of Quality Determination
- Quality improvement,
- Better outcomes,
- Reliable and trustworthy utilization of data,
- Process efficiency,
- More efficient workflows for article creation and review,
- Better decision making.
3.2. Quality Improvement
3.3. Better Outcomes
3.4. Reliable and Trustworthy Utilization of Data
3.5. Process Efficiency
3.6. More Efficient Workflows for Article Creation and Review
3.7. Better Decision Making
3.8. Limitations
3.9. Descriptive Content
3.9.1. Quality
3.9.2. Metrics
3.9.3. Relevant Groups
4. Conclusions
5. Limitations and Threats to Validity
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
| Number | Question |
|---|---|
| 1 | Personal questions |
| 1.1 | Which institution do you work for? |
| 1.2 | What are the main topics you are currently dealing with? |
| 1.3 | Do you already have scientific publications on this topic? |
| 2 | How do you define “quality” of a free online encyclopedia page (e.g., Wikipedia)? |
| 3 | Do you think an evaluation of the quality of all pages in free online encyclopedias is possible? |
| 4 | What are the challenges in determining the quality of collaborative open data pages and their sources? |
| 5 | Do you think the sources (links, references …) of collaborative open data pages are relevant for determining the quality of the pages? |
| 6 | Do you know metrics (indicators) for determining the quality of collaborative open data pages or their sources? |
| 7 | What other metrics or criteria can be used to determine the quality of collaborative open data and their sources? |
| 8 | How do you assess the potential of the metrics of SEO tools (e.g., Sistrix) to determine quality? |
| 9 | What difficulties can appear in the application of (selected) important metrics? |
| 10 | Do you think there are special metrics required regarding different (not collaborative) open data bases (governmental or users data sets)? |
| 11 | For what reasons do you consider the quality determination to be important? |
| 12 | Which potentials result from the quality determination? |
| 13 | Which groups of people could use these potentials for themselves? |
References
- Wikipedia Meta-Wiki. List of Wikipedias. Available online: https://meta.wikimedia.org/wiki/List_of_Wikipedias (accessed on 7 May 2020).
- Lewoniewski, W.; Węcel, K.; Abramowicz, W. Modeling Popularity and Reliability of Sources in Multilingual Wikipedia. Information 2020, 11, 263. [Google Scholar] [CrossRef]
- English Wikipedia. Template: Grading Scheme. Available online: https://en.wikipedia.org/wiki/Template:Grading_scheme (accessed on 7 May 2020).
- Lewoniewski, W. Measures for Quality Assessment of Articles and Infoboxes in Multilingual Wikipedia. In International Conference on Business Information Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 619–633. [Google Scholar]
- Lewoniewski, W.; Härting, R.C.; Węcel, K.; Reichstein, C.; Abramowicz, W. Application of SEO Metrics to Determine the Quality of Wikipedia Articles and Their Sources. In Information and Software Technologies; Damaševičius, R., Vasiljevienė, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 139–152. [Google Scholar]
- Lewoniewski, W.; Węcel, K.; Abramowicz, W. Relative Quality and Popularity Evaluation of Multilingual Wikipedia Articles. Informatics 2017, 4, 43. [Google Scholar] [CrossRef] [Green Version]
- Glaser, B.G.; Strauss, A.L. Grounded Theory: Strategien qualitativer Sozialforschung; im Original Erschienen: 1967; Huber: Bern, Switzerland, 1998. [Google Scholar]
- Strübing, J. Grounded Theory: Zur Sozialtheoretischen und Epistemologischen Fundierung des Verfahrens der Empirisch Begründeten Theoriebildung; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Kühl, S.; Strodtholz, P.; Taffertshofer, A. Handbuch Methoden der Organisationsforschung. In Quantitative und Qualitative Methoden; VS: Wiesbaden, Germany, 2009. [Google Scholar]
- Cresswell, J.W. Qualitative Inquiry and Research Design: Choosing AMONG Five Traditions; SAGE: Thousand Oaks, CA, USA, 1998. [Google Scholar]
- Stern, P.N.; Allen, L.M.; Moxley, P.A. Qualitative research: The nurse as grounded theorist. Health Care Women Int. 1984, 5, 371–385. [Google Scholar] [CrossRef] [PubMed]
- Atteslander, P. Methoden der Empirischen Sozialforschung; Erich Schmidt Verlag: Berlin, Germany, 2010. [Google Scholar]
- Flick, U.; Kardorff, E.V.; Steinke, I. Qualitative Forschung—Ein Handbuch; Rowohlt Taschenbuch Verlag: Hamburg, Germany, 2008. [Google Scholar]
- Straus, A.; Corbin, J. Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory; SAGE: Thousand Oaks, CA, USA, 1998. [Google Scholar]

| Pseudonym | Institution | Country |
|---|---|---|
| Adrian | Computer scientist and a principal research scientist at the Wikimedia Foundation | St. Petersburg |
| Alexander | Faculty of Computer Science, University | Indonesia |
| Andreas | Department of Telecommunications and Information Processing, University | Gent |
| Anna | Institute of Data Science, University | Maastricht |
| Daniel | Department of Computer Science, University | Leipzig |
| Johannes | Department of Computer Science, University | Darmstadt |
| Karl | Applied Computer Science, University | Bamberg |
| Matthias | Information Systems, Business Information Systems and Programming, University | Aalen |
| Michael | Department of Mathematics and Computer Science, University | Florence |
| Richard | Institute of Technology | Israel |
| Roland | School of Computing, University | Dublin |
| Stefan | Institute of Computer Science | Saarbrücken |
| Construct | Items |
|---|---|
| Quality improvement | Automated metrics as an indicator for quality issues |
| Improvement through measurement | |
| Find coverage gaps | |
| Better outcomes | Accuracy of outcomes |
| Increase the performance | |
| Automated knowledge extraction | |
| Reliable and trustworthy utilization of data | Identification of false data |
| Reliability of data | |
| Data trustworthiness | |
| Process efficiency | Less waste of time and effort |
| Uncover the root cause of the problem | |
| More efficient data driven organizations | |
| More efficient workflows for article creation and review | Insights into their long time behavior |
| Better service for service providers | |
| Editor satisfaction | |
| Better decision making | Information judgement |
| Rate the flood of information, weight the data | |
| Categorization of quality levels | |
| Difficulties | Different open data bases |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Härting, R.-C.; Lewoniewski, W. Main Influencing Factors of Quality Determination of Collaborative Open Data Pages. Information 2020, 11, 283. https://doi.org/10.3390/info11060283
Härting R-C, Lewoniewski W. Main Influencing Factors of Quality Determination of Collaborative Open Data Pages. Information. 2020; 11(6):283. https://doi.org/10.3390/info11060283
Chicago/Turabian StyleHärting, Ralf-Christian, and Włodzimierz Lewoniewski. 2020. "Main Influencing Factors of Quality Determination of Collaborative Open Data Pages" Information 11, no. 6: 283. https://doi.org/10.3390/info11060283
APA StyleHärting, R. -C., & Lewoniewski, W. (2020). Main Influencing Factors of Quality Determination of Collaborative Open Data Pages. Information, 11(6), 283. https://doi.org/10.3390/info11060283