Forecasting Appliances Failures: A Machine-Learning Approach to Predictive Maintenance

 ,
,  , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Related Work
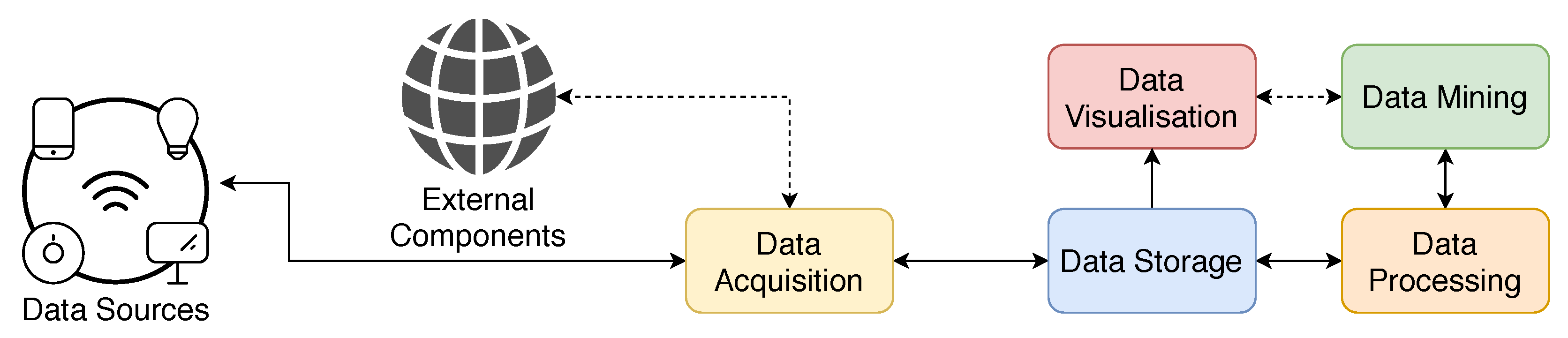
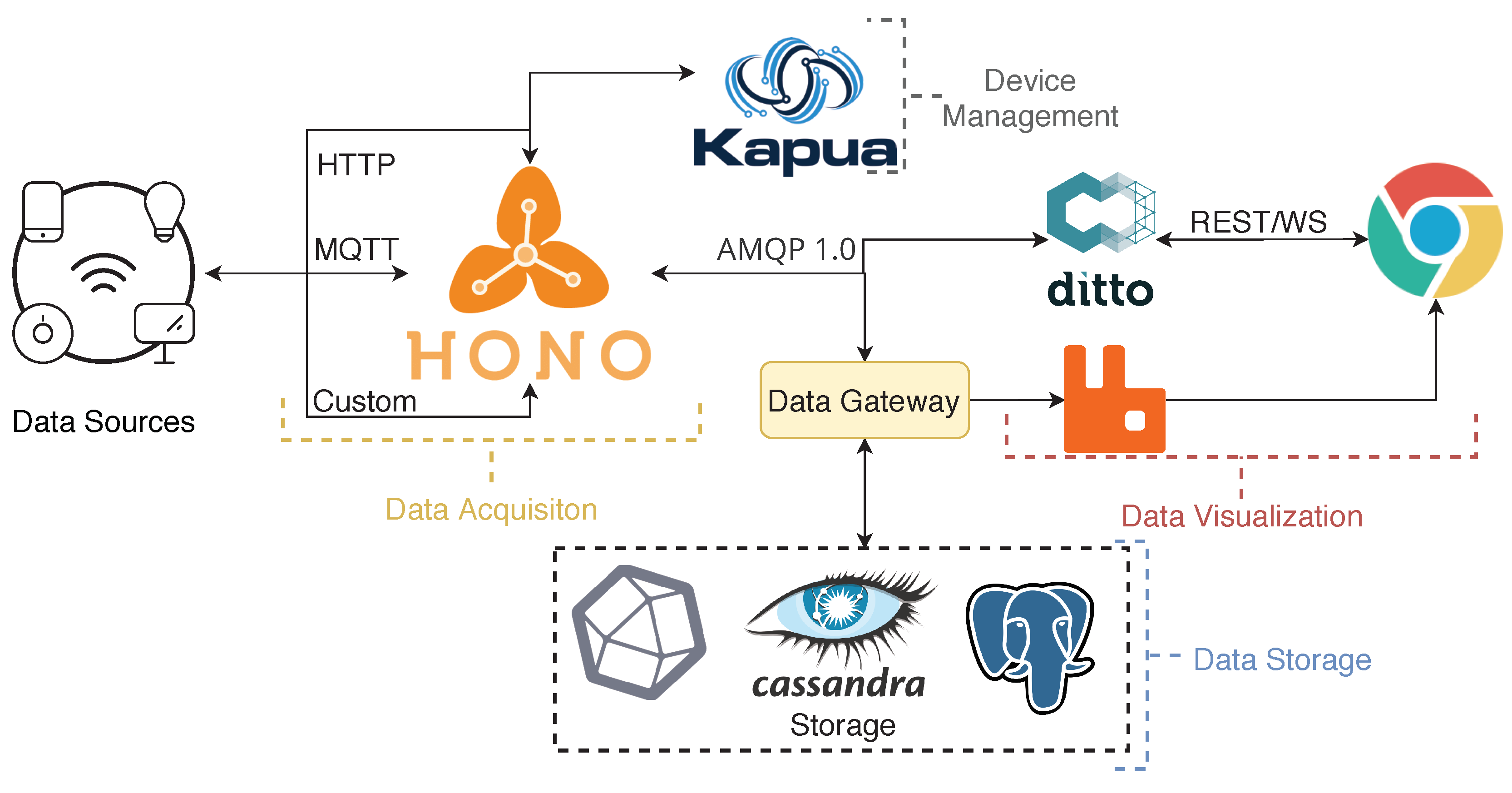
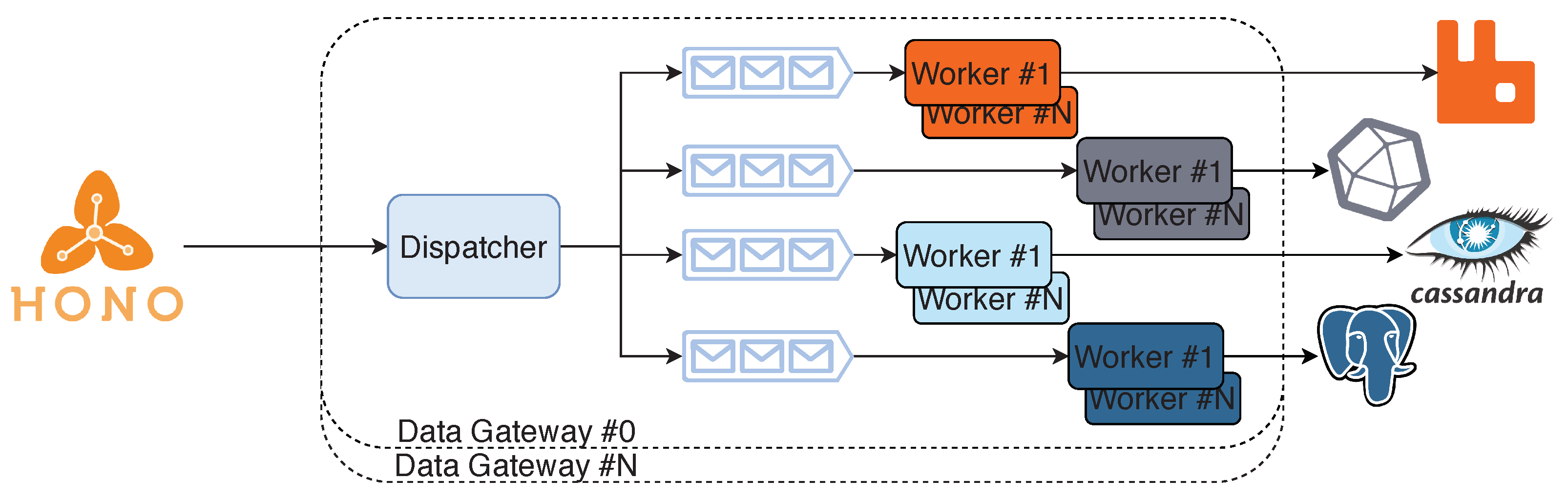
3. SCoT—Smart Cloud of Things
- Distributed architecture—Implementing a multi-node distributed platform which allows distributing workloads evenly among other available machines and making it fault-tolerant by keeping track of the cluster’s health.
- Service replication with load balancing—The implementation allows creating copies of the same service and distributing traffic through these copies aiming to maximise the performance;
- Easier to scale infrastructure and applications—This type of implementation facilitates the way scaling operations of either the cluster or the services of an application are handled, allowing a near-zero downtime when updating services or when scaling the actual cluster;
- Automatic deployment of the platform infrastructure with the application—Create a mechanism that allows deploying the platform with the application facilitating future testing or developing scenarios.
4. Predictive Maintenance Models
4.1. Problem Setting
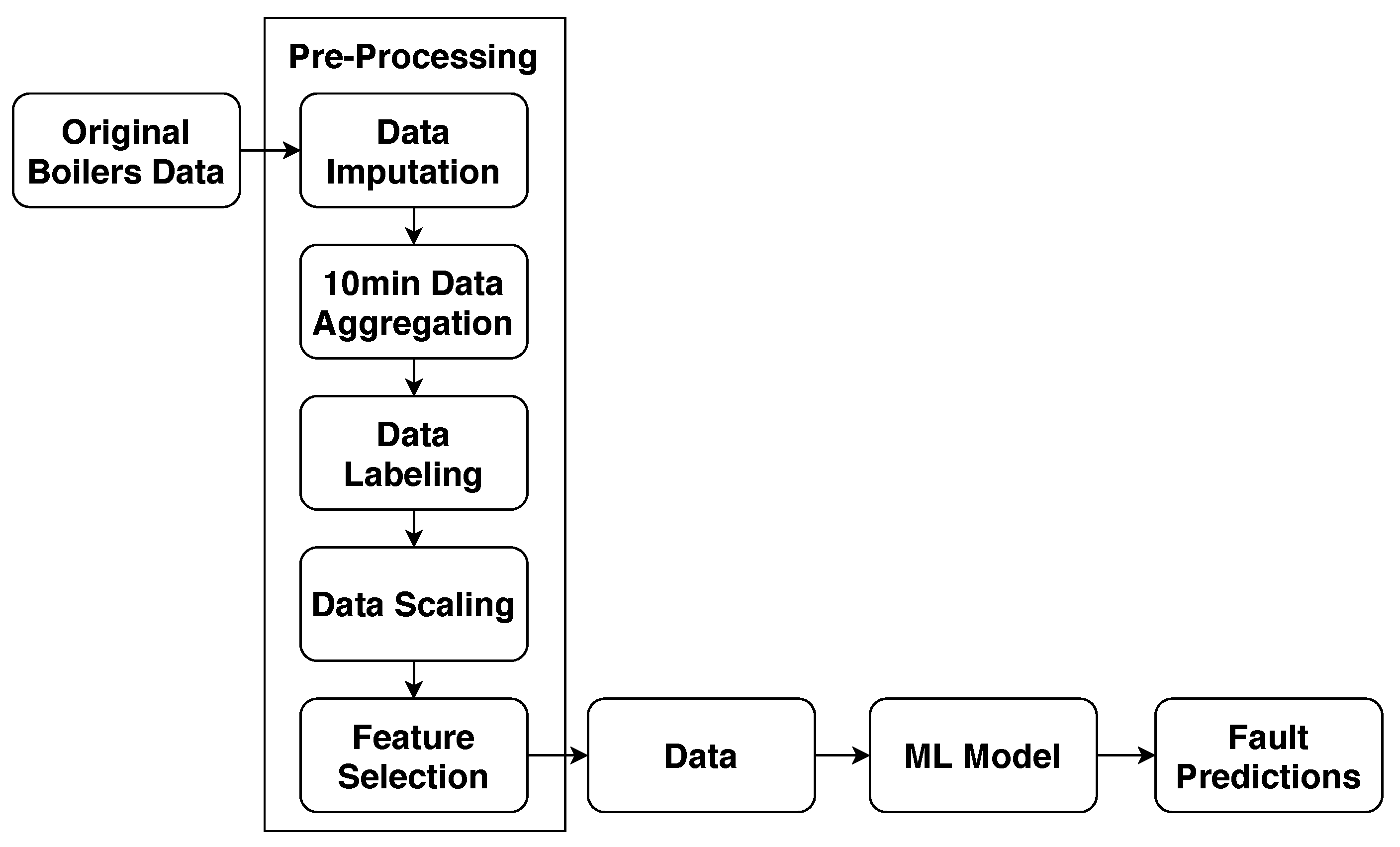
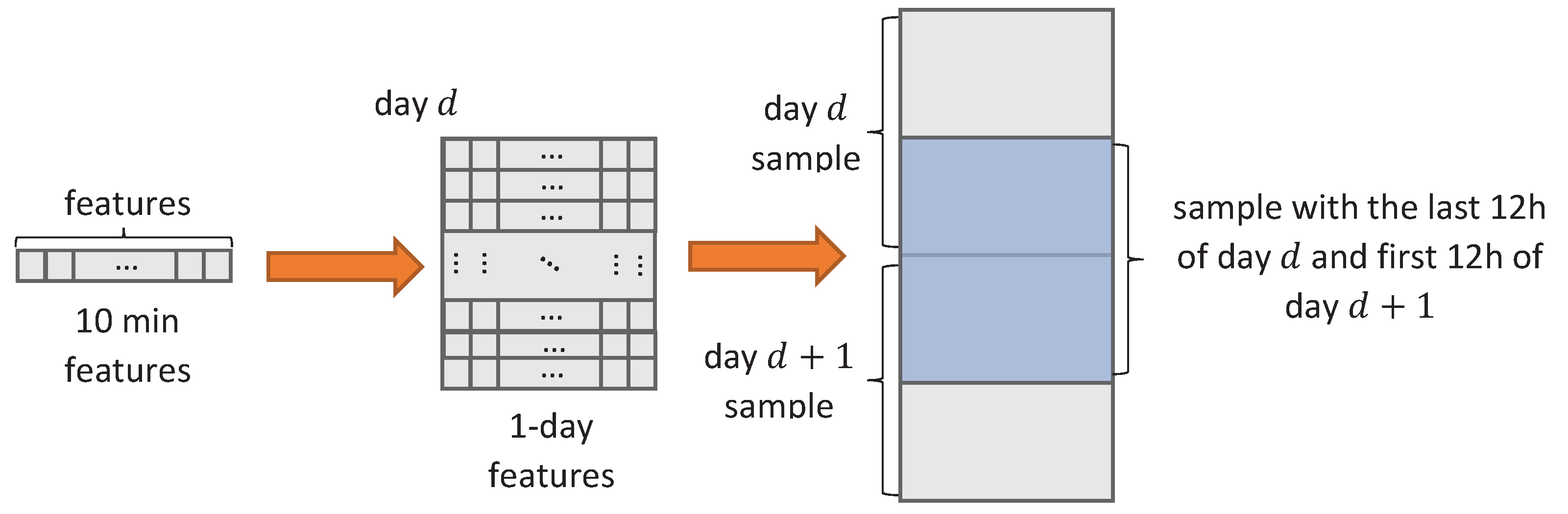
4.2. Data
Data Pre-processing
- values were missing in the logs;
- in most of the cases, there was a log for each boiler at each millisecond, leading to a huge amount of data, which does not necessarily provide meaningful information;
- the data must be re-shaped into supervised problem data format, i.e., for each log, we should set a fault class according to our problem setting;
- different features may assume a different scale of values;
- the number of features in the data was extremely large, which may compromise the learning speed and quality of the model.
4.3. Models
4.4. Evaluation Metrics
5. Results
- The prediction in one week advance is a very hard problem, as it may occur that there might not be enough indicators that the boiler will fail in so much time in advance. This issue is worsened by the fact that we are considering that the fault may occur at any time during the next week.
- The time granularity may also have compromised the model performance. A deeper analysis on the variability of the data so that we can maximise the time span of single time stamp (without losing too much variability) should be carried out.
- A subset of 3 months may not be enough. It may be beneficial to consider a larger time period even if we must discard some boilers, which do not have logs for such a long period.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HVAC | Heating, Ventilation, and Air-Conditioning |
| IoT | Internet of Things |
| LSTM | Long Short-term Memory |
| MCC | Matthews correlation coefficient |
| NN | Neural Network |
| PdM | Predictive Maintenance |
| SCoT | Smart Cloud of Things |
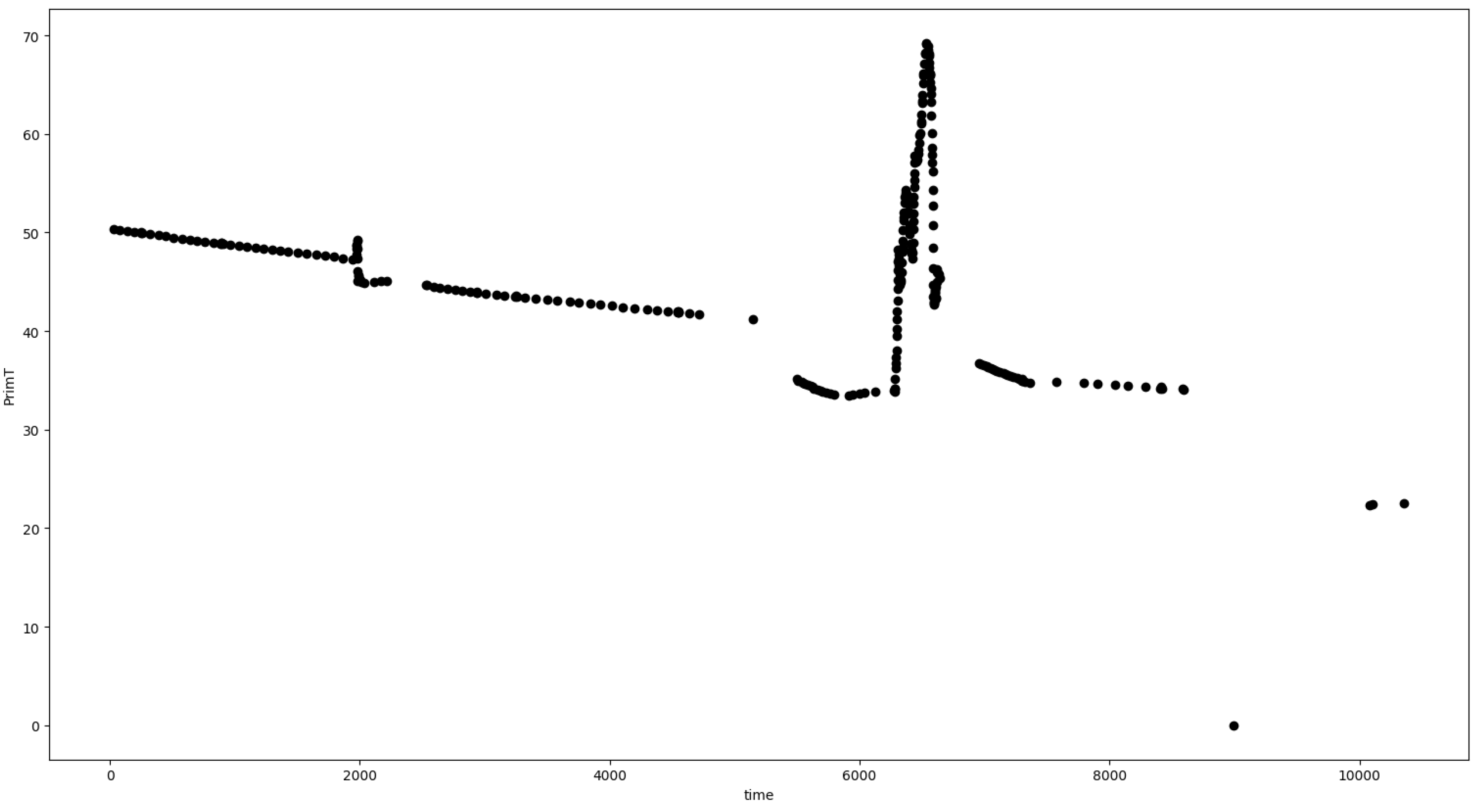
Appendix A. Dataset Prediction Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Architecture | No Fault | Light Fault | Severe Fault | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hlayers | Neurons | P | R | F1 | P | R | F1 | P | R | F1 | Acc | Macro F1 | MCC | |
| Dummy (stratified) | / | / | 0.91 | 0.81 | 0.86 | 0.09 | 0.18 | 0.12 | 0 | 0.01 | 0.01 | 0.75 | 0.33 | 0 |
| Decision Tree | / | / | 0.9 | 0.85 | 0.87 | 0.03 | 0.06 | 0.04 | 0 | 0 | 0 | 0.77 | 0.3 | −0.08 |
| NN | 1 | 15 | 0.92 | 0.86 | 0.89 | 0.12 | 0.16 | 0.14 | 0 | 0.01 | 0 | 0.79 | 0.34 | 0.05 |
| 25 | 0.91 | 0.79 | 0.85 | 0.1 | 0.22 | 0.13 | 0.01 | 0.02 | 0.01 | 0.74 | 0.33 | 0.02 | ||
| 50 | 0.91 | 0.82 | 0.86 | 0.09 | 0.16 | 0.12 | 0 | 0.01 | 0 | 0.76 | 0.33 | 0.01 | ||
| 2 | 15 | 0.91 | 0.85 | 0.88 | 0.1 | 0.16 | 0.13 | 0 | 0 | 0 | 0.79 | 0.34 | 0.02 | |
| 25 | 0.91 | 0.89 | 0.9 | 0.1 | 0.12 | 0.11 | 0.03 | 0.01 | 0.01 | 0.82 | 0.34 | 0.01 | ||
| 50 | 0.91 | 0.82 | 0.86 | 0.08 | 0.14 | 0.1 | 0 | 0 | 0 | 0.76 | 0.32 | −0.02 | ||
| 3 | 15 | 0.91 | 0.82 | 0.86 | 0.09 | 0.19 | 0.13 | 0 | 0 | 0 | 0.76 | 0.33 | 0.01 | |
| 25 | 0.91 | 0.8 | 0.85 | 0.1 | 0.21 | 0.13 | 0 | 0.01 | 0 | 0.74 | 0.33 | 0.01 | ||
| 50 | 0.91 | 0.8 | 0.85 | 0.09 | 0.19 | 0.12 | 0 | 0 | 0 | 0.74 | 0.32 | 0 | ||
| Weighted NN | 1 | 15 | 0.89 | 0.26 | 0.4 | 0.08 | 0.56 | 0.14 | 0 | 0.1 | 0.01 | 0.28 | 0.18 | −0.03 |
| 25 | 0.89 | 0.28 | 0.42 | 0.09 | 0.53 | 0.15 | 0 | 0.12 | 0.01 | 0.3 | 0.19 | −0.02 | ||
| 50 | 0.9 | 0.39 | 0.55 | 0.09 | 0.49 | 0.14 | 0 | 0.07 | 0.01 | 0.4 | 0.23 | −0.02 | ||
| 2 | 15 | 0.89 | 0.36 | 0.51 | 0.08 | 0.5 | 0.14 | 0 | 0.05 | 0.01 | 0.37 | 0.22 | −0.03 | |
| 25 | 0.89 | 0.49 | 0.63 | 0.07 | 0.36 | 0.12 | 0 | 0.02 | 0 | 0.48 | 0.25 | −0.04 | ||
| 50 | 0.9 | 0.43 | 0.57 | 0.09 | 0.48 | 0.15 | 0 | 0.05 | 0.01 | 0.43 | 0.25 | −0.02 | ||
| 3 | 15 | 0.89 | 0.28 | 0.42 | 0.08 | 0.54 | 0.14 | 0 | 0.1 | 0.01 | 0.3 | 0.19 | −0.03 | |
| 25 | 0.89 | 0.46 | 0.61 | 0.08 | 0.4 | 0.13 | 0 | 0.02 | 0 | 0.46 | 0.25 | −0.05 | ||
| 50 | 0.9 | 0.53 | 0.67 | 0.08 | 0.35 | 0.13 | 0 | 0.01 | 0 | 0.51 | 0.27 | −0.03 | ||
| 1 | 15 | 0.92 | 0.83 | 0.87 | 0.13 | 0.25 | 0.17 | 0.01 | 0.01 | 0.01 | 0.77 | 0.35 | 0.06 | |
| 25 | 0.92 | 0.85 | 0.89 | 0.16 | 0.28 | 0.21 | 0 | 0 | 0 | 0.8 | 0.36 | 0.11 | ||
| 50 | 0.93 | 0.84 | 0.88 | 0.17 | 0.36 | 0.23 | 0 | 0 | 0 | 0.79 | 0.37 | 0.14 | ||
| 2 | 15 | 0.91 | 0.79 | 0.85 | 0.11 | 0.26 | 0.15 | 0 | 0 | 0 | 0.74 | 0.33 | 0.04 | |
| 25 | 0.93 | 0.69 | 0.79 | 0.12 | 0.42 | 0.18 | 0.02 | 0.07 | 0.03 | 0.66 | 0.34 | 0.09 | ||
| 50 | 0.93 | 0.84 | 0.88 | 0.19 | 0.39 | 0.25 | 0 | 0 | 0 | 0.8 | 0.38 | 0.16 | ||
| 3 | 15 | 0.92 | 0.85 | 0.89 | 0.15 | 0.28 | 0.2 | 0 | 0 | 0 | 0.8 | 0.36 | 0.1 | |
| 25 | 0.93 | 0.7 | 0.8 | 0.14 | 0.5 | 0.21 | 0 | 0 | 0 | 0.68 | 0.34 | 0.12 | ||
| 50 | 0.93 | 0.81 | 0.86 | 0.16 | 0.39 | 0.23 | 0 | 0 | 0 | 0.77 | 0.36 | 0.14 | ||
| 1 | 15 | 0.93 | 0.73 | 0.82 | 0.13 | 0.43 | 0.2 | 0 | 0 | 0 | 0.7 | 0.34 | 0.1 | |
| 25 | 0.93 | 0.83 | 0.88 | 0.18 | 0.38 | 0.24 | 0 | 0 | 0 | 0.79 | 0.37 | 0.15 | ||
| 50 | 0.93 | 0.64 | 0.76 | 0.12 | 0.52 | 0.2 | 0.02 | 0.01 | 0.01 | 0.63 | 0.32 | 0.1 | ||
| 2 | 15 | 0.92 | 0.66 | 0.77 | 0.12 | 0.47 | 0.19 | 0 | 0 | 0 | 0.64 | 0.32 | 0.07 | |
| 25 | 0.92 | 0.8 | 0.86 | 0.14 | 0.34 | 0.2 | 0 | 0 | 0 | 0.76 | 0.35 | 0.1 | ||
| 50 | 0.92 | 0.77 | 0.84 | 0.12 | 0.34 | 0.18 | 0 | 0 | 0 | 0.73 | 0.34 | 0.07 | ||
| 3 | 15 | 0.92 | 0.86 | 0.89 | 0.13 | 0.22 | 0.16 | 0 | 0 | 0 | 0.8 | 0.35 | 0.06 | |
| 25 | 0.93 | 0.81 | 0.87 | 0.16 | 0.39 | 0.23 | 0 | 0 | 0 | 0.77 | 0.37 | 0.14 | ||
| 50 | 0.93 | 0.76 | 0.84 | 0.15 | 0.43 | 0.22 | 0 | 0 | 0 | 0.73 | 0.35 | 0.12 | ||
| 1 | 15 | 0.93 | 0.65 | 0.76 | 0.11 | 0.47 | 0.18 | 0 | 0 | 0 | 0.63 | 0.32 | 0.07 | |
| 25 | 0.94 | 0.73 | 0.82 | 0.15 | 0.51 | 0.24 | 0 | 0 | 0 | 0.71 | 0.35 | 0.15 | ||
| 50 | 0.94 | 0.62 | 0.75 | 0.13 | 0.59 | 0.21 | 0 | 0 | 0 | 0.62 | 0.32 | 0.12 | ||
| 2 | 15 | 0.93 | 0.84 | 0.88 | 0.17 | 0.34 | 0.23 | 0.05 | 0.01 | 0.02 | 0.79 | 0.37 | 0.13 | |
| 25 | 0.93 | 0.64 | 0.76 | 0.12 | 0.53 | 0.2 | 0 | 0 | 0 | 0.63 | 0.32 | 0.1 | ||
| 50 | 0.93 | 0.76 | 0.84 | 0.15 | 0.45 | 0.23 | 0 | 0 | 0 | 0.73 | 0.35 | 0.13 | ||
| 3 | 15 | 0.92 | 0.75 | 0.83 | 0.13 | 0.39 | 0.19 | 0 | 0 | 0 | 0.72 | 0.34 | 0.09 | |
| 25 | 0.93 | 0.74 | 0.82 | 0.15 | 0.47 | 0.22 | 0 | 0 | 0 | 0.71 | 0.35 | 0.13 | ||
| 50 | 0.92 | 0.97 | 0.94 | 0.35 | 0.19 | 0.25 | 0 | 0 | 0 | 0.89 | 0.4 | 0.2 | ||
| 1 | 15 | 0.92 | 0.55 | 0.69 | 0.1 | 0.53 | 0.17 | 0 | 0 | 0 | 0.55 | 0.28 | 0.04 | |
| 25 | 0.93 | 0.89 | 0.91 | 0.24 | 0.35 | 0.28 | 0.05 | 0.01 | 0.02 | 0.84 | 0.4 | 0.21 | ||
| 50 | 0.93 | 0.81 | 0.86 | 0.15 | 0.34 | 0.21 | 0.02 | 0.01 | 0.01 | 0.76 | 0.36 | 0.11 | ||
| 2 | 15 | 0.92 | 0.53 | 0.67 | 0.1 | 0.56 | 0.18 | 0 | 0 | 0 | 0.53 | 0.28 | 0.05 | |
| 25 | 0.91 | 0.37 | 0.53 | 0.09 | 0.63 | 0.15 | 0 | 0 | 0 | 0.39 | 0.23 | 0 | ||
| 50 | 0.94 | 0.56 | 0.7 | 0.12 | 0.61 | 0.2 | 0 | 0 | 0 | 0.56 | 0.3 | 0.1 | ||
| 3 | 15 | 0.93 | 0.49 | 0.64 | 0.11 | 0.64 | 0.18 | 0 | 0 | 0 | 0.5 | 0.27 | 0.07 | |
| 25 | 0.93 | 0.84 | 0.88 | 0.19 | 0.4 | 0.26 | 0 | 0 | 0 | 0.8 | 0.38 | 0.17 | ||
| 50 | 0.93 | 0.4 | 0.56 | 0.1 | 0.71 | 0.18 | 0 | 0 | 0 | 0.42 | 0.25 | 0.06 | ||
| 1 | 15 | 0.92 | 0.47 | 0.62 | 0.09 | 0.56 | 0.16 | 0 | 0 | 0 | 0.48 | 0.26 | 0.02 | |
| 25 | 0.93 | 0.69 | 0.79 | 0.13 | 0.48 | 0.2 | 0.05 | 0.01 | 0.02 | 0.67 | 0.34 | 0.11 | ||
| 50 | 0.93 | 0.7 | 0.8 | 0.14 | 0.5 | 0.22 | 0.01 | 0.01 | 0.01 | 0.68 | 0.34 | 0.12 | ||
| 2 | 15 | 0.93 | 0.5 | 0.64 | 0.1 | 0.6 | 0.18 | 0 | 0 | 0 | 0.5 | 0.27 | 0.06 | |
| 25 | 0.92 | 0.56 | 0.7 | 0.11 | 0.54 | 0.18 | 0 | 0 | 0 | 0.56 | 0.28 | 0.06 | ||
| 50 | 0.94 | 0.5 | 0.65 | 0.12 | 0.71 | 0.21 | 0 | 0 | 0 | 0.51 | 0.28 | 0.12 | ||
| 3 | 15 | 0.93 | 0.49 | 0.64 | 0.11 | 0.63 | 0.18 | 0 | 0 | 0 | 0.5 | 0.28 | 0.07 | |
| 25 | 0.92 | 0.52 | 0.67 | 0.1 | 0.55 | 0.17 | 0 | 0 | 0 | 0.52 | 0.28 | 0.04 | ||
| 50 | 0.94 | 0.55 | 0.69 | 0.12 | 0.64 | 0.2 | 0 | 0 | 0 | 0.55 | 0.3 | 0.11 | ||
References
- Muhuri, P.K.; Shukla, A.K.; Abraham, A. Industry 4.0: A bibliometric analysis and detailed overview. Eng. Appl. Artif. Intell. 2019, 78, 218–235. [Google Scholar] [CrossRef]
- Reis, M.; Gins, G. Industrial Process Monitoring in the Big Data/Industry 4.0 Era: From Detection, to Diagnosis, to Prognosis. Processes 2017, 5, 35. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, T.P.; Soares, F.A.A.M.N.; Vita, R.; Francisco, R.d.P.; Basto, J.P.; Alcalá, S.G.S. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Ribeiro, J.; Antunes, M.; Gomes, D.; Aguiar, R.L. Outlier Identification in Multivariate Time Series: Boilers Case Study. In Proceedings of the International Conference on Time Series and Forecasting (ITISE), Granada, Spain, 19–21 September 2018. [Google Scholar]
- Satta, R.; Cavallari, S.; Pomponi, E.; Grasselli, D.; Picheo, D.; Annis, C. A dissimilarity-based approach to predictive maintenance with application to HVAC systems. arXiv 2017, arXiv:1701.03633. [Google Scholar]
- Groba, C.; Cech, S.; Rosenthal, F.; Gossling, A. Architecture of a Predictive Maintenance Framework. In Proceedings of the 6th International Conference on Computer Information Systems and Industrial Management Applications (CISIM’07), Minneapolis, MN, USA, 28–30 June 2007. [Google Scholar] [CrossRef]
- Tan, C.M.; Raghavan, N. A framework to practical predictive maintenance modeling for multi-state systems. Reliab. Eng. Syst. Saf. 2008, 93, 1138–1150. [Google Scholar] [CrossRef]
- Dhall, R.; Solanki, V.K. An IoT Based Predictive Connected Car Maintenance Approach. Int. J. Interact. Multimed. Artif. Intell. 2017, 4, 16. [Google Scholar] [CrossRef] [Green Version]
- Canizo, M.; Onieva, E.; Conde, A.; Charramendieta, S.; Trujillo, S. Real-time predictive maintenance for wind turbines using Big Data frameworks. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017. [Google Scholar] [CrossRef] [Green Version]
- Lindström, J.; Larsson, H.; Jonsson, M.; Lejon, E. Towards Intelligent and Sustainable Production: Combining and Integrating Online Predictive Maintenance and Continuous Quality Control. Procedia CIRP 2017, 63, 443–448. [Google Scholar] [CrossRef]
- Antunes, M.; Barraca, J.P.; Gomes, D.; Oliveira, P.; Aguiar, R.L. Smart Cloud of Things: An Evolved IoT Platform for Telco Providers. J. Ambient. Wirel. Commun. Smart Environ. (AMBIENTCOM) 2016, 1, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Cai, H.; Xu, B.; Jiang, L.; Vasilakos, A.V. IoT-Based Big Data Storage Systems in Cloud Computing: Perspectives and Challenges. IEEE Internet Things J. 2017, 4, 75–87. [Google Scholar] [CrossRef]
- Antunes, M.; Gomes, D.; Aguiar, R.L. Scalable semantic aware context storage. Future Gener. Comput. Syst. 2015, 56, 675–683. [Google Scholar] [CrossRef] [Green Version]
- Saeys, Y.; Abeel, T.; Van de Peer, Y. Robust feature selection using ensemble feature selection techniques. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Geramny, 2008; pp. 313–325. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Gorodkin, J. Comparing two K-category assignments by a K-category correlation coefficient. Comput. Biol. Chem. 2004, 28, 367–374. [Google Scholar] [CrossRef] [PubMed]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]






| Time | PrimT | ChNoStart | BurnNoStart |
|---|---|---|---|
| 07:42:44.304 | 1558.0 | ||
| 07:42:44.404 | 23.7 | 155.0 | |
| 07:42:44.504 | 156.0 | ||
| 07:42:44.604 | 23.8 | 1559.0 | |
| 07:42:44.704 | 155.0 | 1561.0 |
| Model | Architecture | No Fault | Light Fault | Severe Fault | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hlayers | Neurons | P | R | F1 | P | R | F1 | P | R | F1 | Acc | Macro F1 | MCC | |
| Dummy (stratified) | / | / | 0.91 | 0.81 | 0.86 | 0.09 | 0.18 | 0.12 | 0 | 0.01 | 0.01 | 0.75 | 0.33 | 0 |
| Decision Tree | / | / | 0.9 | 0.85 | 0.87 | 0.03 | 0.06 | 0.04 | 0 | 0 | 0 | 0.77 | 0.3 | −0.08 |
| NN | 1 | 15 | 0.92 | 0.86 | 0.89 | 0.12 | 0.16 | 0.14 | 0 | 0.01 | 0 | 0.79 | 0.34 | 0.05 |
| Weighted NN | 2 | 50 | 0.9 | 0.43 | 0.57 | 0.09 | 0.48 | 0.15 | 0 | 0.05 | 0.01 | 0.43 | 0.25 | −0.02 |
| 2 | 25 | 0.93 | 0.69 | 0.79 | 0.12 | 0.42 | 0.18 | 0.02 | 0.07 | 0.03 | 0.66 | 0.34 | 0.09 | |
| 1 | 25 | 0.93 | 0.83 | 0.88 | 0.18 | 0.38 | 0.24 | 0 | 0 | 0 | 0.79 | 0.37 | 0.15 | |
| 3 | 50 | 0.92 | 0.97 | 0.94 | 0.35 | 0.19 | 0.25 | 0 | 0 | 0 | 0.89 | 0.4 | 0.2 | |
| 1 | 25 | 0.93 | 0.89 | 0.91 | 0.24 | 0.35 | 0.28 | 0.05 | 0.01 | 0.02 | 0.84 | 0.4 | 0.21 | |
| 1 | 25 | 0.93 | 0.69 | 0.79 | 0.13 | 0.48 | 0.2 | 0.05 | 0.01 | 0.02 | 0.67 | 0.34 | 0.11 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernandes, S.; Antunes, M.; Santiago, A.R.; Barraca, J.P.; Gomes, D.; Aguiar, R.L. Forecasting Appliances Failures: A Machine-Learning Approach to Predictive Maintenance. Information 2020, 11, 208. https://doi.org/10.3390/info11040208
Fernandes S, Antunes M, Santiago AR, Barraca JP, Gomes D, Aguiar RL. Forecasting Appliances Failures: A Machine-Learning Approach to Predictive Maintenance. Information. 2020; 11(4):208. https://doi.org/10.3390/info11040208
Chicago/Turabian StyleFernandes, Sofia, Mário Antunes, Ana Rita Santiago, João Paulo Barraca, Diogo Gomes, and Rui L. Aguiar. 2020. "Forecasting Appliances Failures: A Machine-Learning Approach to Predictive Maintenance" Information 11, no. 4: 208. https://doi.org/10.3390/info11040208
APA StyleFernandes, S., Antunes, M., Santiago, A. R., Barraca, J. P., Gomes, D., & Aguiar, R. L. (2020). Forecasting Appliances Failures: A Machine-Learning Approach to Predictive Maintenance. Information, 11(4), 208. https://doi.org/10.3390/info11040208