Recognizing Indonesian Acronym and Expansion Pairs with Supervised Learning and MapReduce

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
- We introduce eight continuous features to represent the acronym and expansion pairs, which differ from the feature vectors introduced by Chang et al. [16] for scoring abbreviations. The first five features were initially proposed by Wahyudi et al. [23]; however, in this study, two of these features are modified to accommodate the acronyms of typed initialisms, whereas the remaining three are new features that have been introduced to improve the accuracy. The three new features measure the ratio of accurate matching between the characters in the expansion and those in the acronym; furthermore, they can distinguish between accurate and inaccurate ratios. The formulas and their definitions are discussed in Section 4.
- We compare the performance of several supervised learning algorithms, namely SVM [26], K-NN [27], and Bidirectional Encoder Representations from Transformers (BERT) [28], to automatically determine the accurate acronym and expansion pairs from a large Indonesian corpus based on precision, recall, and F-measure. Further, we measure the performance of the SVM using several different kernels, the performance of K-NN using various k values, and the performance of BERT-Base and BERT-Base Multilingual Cased models [28].
- We evaluate the throughput of the big data technology under different data nodes using Hadoop MapReduce to construct the candidate pairs of acronym and expansion and obtain their feature vectors.
2. Related Works
3. Determining the Candidate Pairs of Acronym and Expansion
| Algorithm 1. Generate candidate of acronyms. |
|
| Algorithm 2. Generate candidate of acronym and expansion pairs. |
|
4. Numerical Features
- measures the correlation between the total number of characters in the acronym and the total number of words in the expansion; generally, the former matches the latter. Therefore, is equal to 1 if they match exactly; otherwise, is less than 1. Let A be an acronym and E be the expansion. Let be the length of A for an acronym of type uppercase letters or the number of syllables for an acronym of type sequence of speech sounds. In addition, let be the number of words in E excluding conjunctions and prepositions. Then, is calculated using the following equation:
- measures the number of words in the expansion that are in title case (capitalized in the first word). Let A be an acronym and E be an expansion comprising several words that is denoted as , such that the elements in W represent the words in E. Let be the number of elements that are written in title case, excluding conjunctions and prepositions, and let be the number of words in E, excluding conjunctions and prepositions. Then, is calculated as follows:
- weights the matching of the letters in the acronym and its expansion, excluding conjunctions and prepositions. The acronyms formed by the combination of uppercase letters are generally abbreviated based on the letters in the expansion; thus, provides a good weight for the matching of the letters. Let A be an acronym and be the length of A. Further, we assume that is a total match and is a total mismatch between the letters in the acronym and its expansion. Then, is calculated using the following equation:For example, “NPWP,” which stands for “Nomor Pokok Wajib Pajak” (“Tax ID number” in English), has because it is abbreviated according to the letters in the expansion, i.e., , , and . However, would be less than 1 if at least one mismatch occurred.
- weights the correlation between the first and last letters of the acronym. The first letter of the acronym will be matched with the first letter of the expansion and the last letter of the acronym will be matched with the first letter of the last word of the expansion. For the acronyms formed by a sequence of speech sounds (syllables), this feature weights the correlation between the first syllable of the acronym and that of the expansion. Furthermore, it measures the matching between the last syllable of the acronym and the first syllable of the last word in the definition. is 1 if both the correlations match, 0.5 if at least one correlation matches, and 0 otherwise.
- penalizes the acronym definitions that contain many prepositions and conjunctions because acronyms usually do not contain many prepositions and conjunctions. Let E be an expansion that comprises several words and be the conjunctions and prepositions present in E. Furthermore, let be the number of elements and be the number of words in E. Then, the equation of can be given as follows:
- is the ratio of accurate matching between the characters in the expansion and those in the acronym. Let A be an acronym and be the length of A. Assuming that is a total match, the ratio can be measured using the following equation:
- is introduced to distinguish between the accurate ratio of appearance () and an inaccurate ratio. Therefore, the value of is 1 if is 1, indicating that the order of the acronym characters matches the characters in the expansion; otherwise, the value of is 0 if is less than 1.
- is the mean of to .
5. Methodology
- BLU::Badan Layanan Umum or Public Service Agency
- Cawapres::Calon Wakil Presiden or Vice-President Candidate
- ZEE::Zona Ekonomi or Economic Zone
- Mapolda::Humas Polda or Regional Police Public Relations
6. Experimental Results
6.1. Data
6.2. Training Models
6.3. Determining the Best Method
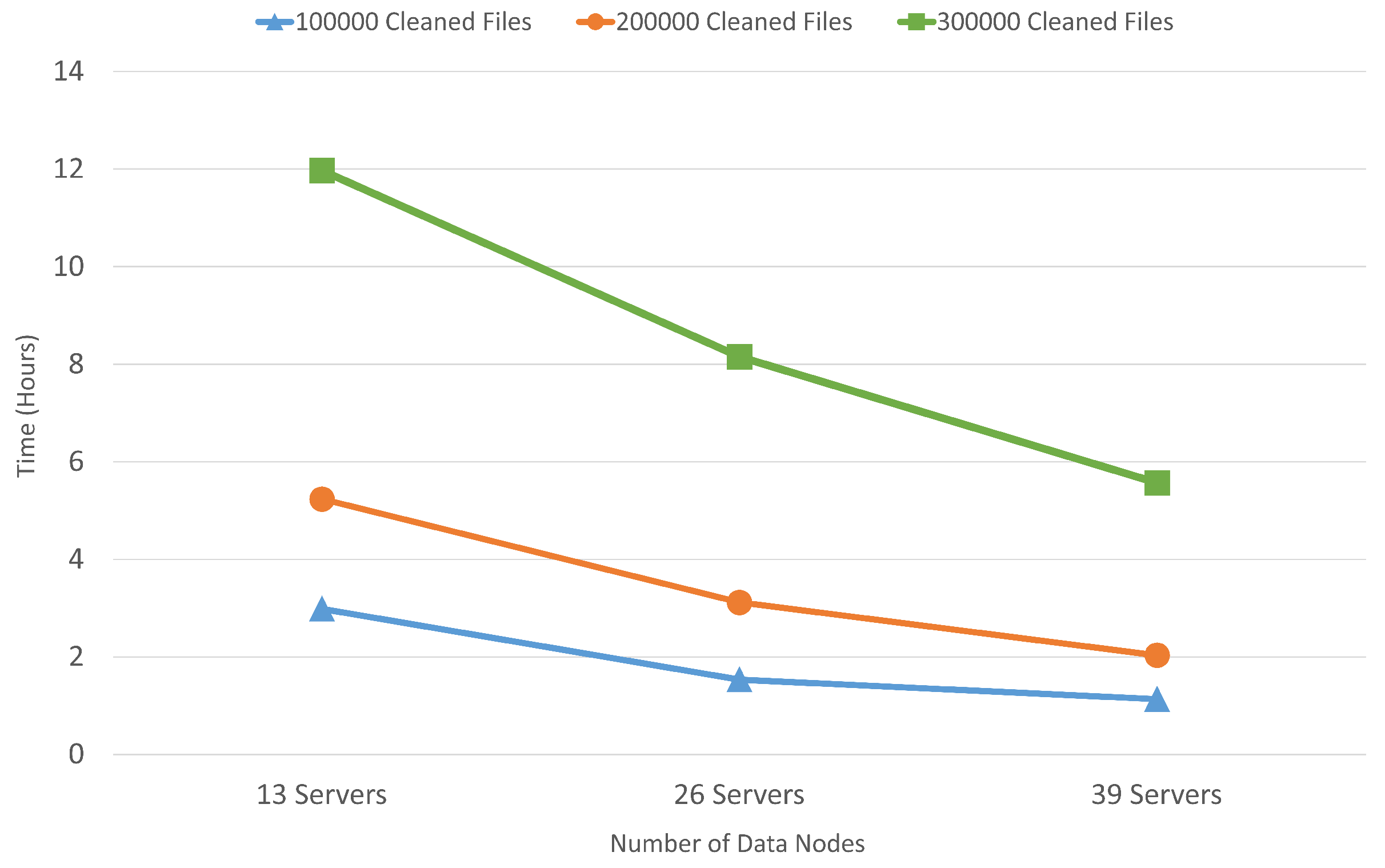
6.4. Hadoop Performance Analysis
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AFP | Acronym finding program |
| BERT | Bidirectional encoder representations from transformers |
| HDFS | Hadoop distributed file system |
| HTML | Hypertext markup language |
| K-NN | K-nearest neighbors |
| NASA | National aeronautics and space administration |
| NER | Named entity recognition |
| SVM | Support vector machine |
| URL | Uniform resource locator |
References
- Oussous, A.; Benjelloun, F.-Z.; Lahcen, A.A.; Belfkih, S. Big data technologies: A survey. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 431–448. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Zhang, C.-Y. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Ali, A.; Shah, G.A.; Farooq, M.O.; Ghani, U. Technologies and challenges in developing machine-to-machine applications: A survey. J. Netw. Comput. Appl. 2017, 83, 124–139. [Google Scholar] [CrossRef]
- Botta, A.; de Donato, W.; Persico, V.; Pescape, A. Integration of cloud computing and Internet of things: A survey. Future Gener. Comput. Syst. 2016, 56, 684–700. [Google Scholar] [CrossRef]
- Lazer, D.; Kennedy, R.; King, G.; Vespignani, A. The parable of Google flu: Traps in big data analysis. Science 2014, 343, 1203–1205. [Google Scholar] [CrossRef] [PubMed]
- Ginsberg, J.; Mohebbi, M.H.; Patel, R.S.; Brammer, L.; Smolinski, M.S.; Brilliant, L. Detecting influenza epidemics using search engine query data. Nature 2009, 457, 1012–1014. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Dobre, C.; Xhafab, F. Intelligent services for big data science. Future Gener. Comput. Syst. 2014, 37, 267–281. [Google Scholar] [CrossRef]
- Woetzel, J.; Remes, J.; Boland, B.; Katrina, L.V.; Sinha, S.; Strube, G.; Means, J.; Law, J.; Cadena, A.; Tann, V.V.D. Smart Cities: Digital Solutions for a More Livable Future; McKinsey Global Institute: New York, NY, USA, 2018. [Google Scholar]
- Lee, I. Big data: Dimensions, evolution, impacts, and challenges. Bus. Horiz. 2017, 60, 293–303. [Google Scholar] [CrossRef]
- Majumdar, J.; Naraseeyappa, S.; Ankalaki, S. Analysis of agriculture data using data mining techniques: Application of big data. J. Big Data 2017, 4, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Almada, M. Human intervention in automated decision-making: Toward the construction of contestable systems. In Proceedings of the 17th International Conference on Artificial Intelligence and Law (ICAIL), Montreal, QC, Canada, 17–21 June 2019. [Google Scholar]
- Taghva, K.; Gilbreth, J. Recognizing acronyms and their definitions. Int. J. Doc. Anal. Recognit. 1999, 1, 191–198. [Google Scholar] [CrossRef] [Green Version]
- Larkey, L.S.; Ogilvie, P.; Price, A.; Tamilio, B. Acrophile: An automated acronym extractor and server. In Proceedings of the 5th ACM Conference on Digital Libraries, San Antonio, TX, USA, 2–7 June 2000; pp. 205–214. [Google Scholar]
- Park, Y.; Byrd, R.J. Hybrid text mining for finding abbreviations and their definitions. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Pittsburgh, PA, USA, 3–4 June 2001; pp. 126–133. [Google Scholar]
- Chang, J.T.; Schutze, H.; Altman, R.B. Creating an online dictionary of abbreviations from MEDLINE. J. Am. Med. Inform. Assoc. 2002, 9, 612–620. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nadeau, D.; Turney, P.D. A supervised learning approach to acronym identification. In Advances in Artificial Intelligence; Kégl, B., Lapalme, G., Eds.; Springer: Berlin, Germany, 2005; Volume 3501, pp. 319–329. [Google Scholar]
- Xu, J.; Huang, Y. Using SVM to extract acronym from text. Soft Comput. 2007, 11, 369–373. [Google Scholar] [CrossRef]
- Ji, X.; Xu, G.; Bailey, J.; Li, H. Mining, ranking, and using acronym patterns. Lect. Notes Comput. Sci. 2008, 4976, 371–382. [Google Scholar]
- Sanchez, D.; Isern, D. Automatic extraction of acronym definitions from the web. J. Appl. Intell. 2011, 34, 311–327. [Google Scholar] [CrossRef]
- Choi, D.; Kim, P. Identifying the most appropriate expansion of acronyms used in wikipedia text. Softw. Pract. Exp. 2015, 45, 1073–1086. [Google Scholar] [CrossRef]
- Jacobs, K.; Itai, A.; Wintner, S. Acronyms: Identification, expansion and disambiguation. Ann. Math. Artif. Intell. 2018, 49. [Google Scholar] [CrossRef]
- Wahyudi, J.; Abidin, T.F. Automatic determination of acronyms and their expansion from Indonesian texts data. In Proceedings of the SNATIKA, Malang, Indonesia, 10 November 2011; pp. 115–119. (In Indonesian). [Google Scholar]
- Abidin, T.F.; Adriman, R.; Ferdhiana, R. Performance analysis of Apache Hadoop for generating candidates of acronym and expansion pairs and their numerical features. In Proceedings of the 3rd International Conference on Information Technology, Information System and Electrical Engineering, Yogyakarta, Indonesia, 13–14 November 2018; pp. 189–193. [Google Scholar]
- Senthilkumar, R.M.; Jayanthi, V.E. A survey on acronym-expansion mining approaches from text and web. In Proceedings of the 2nd International Conference on SCI, Vijayawada, India, 27–28 January 2018; Volume 1, pp. 121–133. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the 5th Annual ACM Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Turc, I.; Chang, M.-W.; Lee, K.; Toutanova, K. Well-read students learn better: On the importance of pre-training compact models. arXiv 2019, arXiv:1908.08962v2. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2004, 51, 1–13. [Google Scholar] [CrossRef]
- L’Heureux, A.; Grolinger, K.; Capretz, M.A.M. Machine learning with big data: Challenges and approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Li, R.; Hu, H.; Li, H.; Wu, Y.; Yang, J. MapReduce parallel programming model: A state-of-the-art survey. Int. J. Parallel Program. 2016, 44, 832–866. [Google Scholar] [CrossRef]
- Ghazi, M.R.; Gangodkar, D. Hadoop, mapreduce and HDFS: A developers perspective. Procedia Comput. Sci. 2015, 48, 45–50. [Google Scholar] [CrossRef] [Green Version]
- Luna, J.M.; Padillo, F.; Pechenizkiy, M.; Ventura, S. Apriori versions based on MapReduce for mining frequent patterns on big data. IEEE Trans. Cybern. 2017, 47, 1–15. [Google Scholar] [CrossRef]
- Xun, Y.; Zhang, J.; Qin, X. FiDoop: Parallel mining of frequent itemsets using MapReduce. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 313–325. [Google Scholar] [CrossRef]
- Zhonghua, M. Seismic data attribute extraction based on Hadoop platform. In Proceedings of the 2nd IEEE International Conference on Cloud Computing and Big Data Analysis, Chengdu, China, 28–30 April 2017; pp. 180–184. [Google Scholar]
- Joachims, T. Making Large-Scale SVM Learning Practical; Scholkopf, B., Burges, C., Smola, A., Eds.; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann Publishers: Burlington, MA, USA, 2011. [Google Scholar]
- Zouina, M.; Outtaj, B. A novel lightweight URL phishing detection system using SVM and similarity index. Hum. Centric Comput. Inf. Sci. 2017, 7, 1–13. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Source | URL Patterns |
|---|---|
| Viva news portal | viva.co.id/indeks/berita/all/yyyy/mm/dd |
| Detik news portal | news.detik.com/indeks/[page]?date=mm/dd/yyyy |
| Liputan6 technology portal | liputan6.com/tekno/indeks/yyyy/mm/dd |
| Liputan6 business portal | liputan6.com/bisnis/indeks/yyyy/mm/dd |
| Liputan6 automotive portal | liputan6.com/otomotif/indeks/yyyy/mm/dd |
| Okezone news portal | news.okezone.com/indeks/yyyy/mm/dd |
| Kompas news portal | news.kompas.com/search/yyyy-mm-dd |
| Supervised Learning Method | Actual Label | Prediction | Precision (%) | Recall (%) | F1-Score (%) | |
|---|---|---|---|---|---|---|
| SVM linear | 2452 | 17 | 99.03 | 99.31 | 99.17 | |
| 24 | 2507 | |||||
| SVM polynomial | 2463 | 6 | 99.27 | 99.76 | 99.52 | |
| 18 | 2513 | |||||
| SVM radial | 2458 | 11 | 99.19 | 99.55 | 99.37 | |
| 20 | 2511 | |||||
| SVM sigmoid | 2449 | 20 | 98.99 | 99.19 | 99.09 | |
| 25 | 2506 | |||||
| K-NN | 2451 | 18 | 99.03 | 99.27 | 99.15 | |
| 24 | 2507 | |||||
| K-NN | 2451 | 18 | 99.03 | 99.27 | 99.15 | |
| 24 | 2507 | |||||
| K-NN | 2451 | 18 | 98.95 | 99.27 | 99.11 | |
| 26 | 2505 | |||||
| K-NN | 2451 | 18 | 98.95 | 99.27 | 99.11 | |
| 26 | 2505 | |||||
| BERT-base | 2351 | 118 | 95.49 | 95.22 | 95.36 | |
| 111 | 2420 | |||||
| BERT-base multilingual cased | 2384 | 85 | 95.44 | 96.56 | 95.99 | |
| 114 | 2417 | |||||
| Supervised Learning Method | Actual Label | Prediction | Precision (%) | Recall (%) | F1-Score (%) | |
|---|---|---|---|---|---|---|
| SVM polynomial using eight features | 968 | 32 | 99.08 | 96.80 | 97.93 | |
| 9 | 991 | |||||
| SVM polynomial using five features | 829 | 171 | 99.52 | 82.90 | 90.45 | |
| 4 | 996 | |||||
| K-NN using eight features | 943 | 57 | 99.47 | 94.30 | 96.82 | |
| 5 | 995 | |||||
| K-NN using five features | 925 | 75 | 99.04 | 92.50 | 95.66 | |
| 9 | 991 | |||||
| BERT-base | 974 | 26 | 70.27 | 97.40 | 81.64 | |
| 412 | 588 | |||||
| BERT-base multilingual cased | 992 | 8 | 79.23 | 99.20 | 88.10 | |
| 260 | 740 | |||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abidin, T.F.; Mahazir, A.; Subianto, M.; Munadi, K.; Ferdhiana, R. Recognizing Indonesian Acronym and Expansion Pairs with Supervised Learning and MapReduce. Information 2020, 11, 210. https://doi.org/10.3390/info11040210
Abidin TF, Mahazir A, Subianto M, Munadi K, Ferdhiana R. Recognizing Indonesian Acronym and Expansion Pairs with Supervised Learning and MapReduce. Information. 2020; 11(4):210. https://doi.org/10.3390/info11040210
Chicago/Turabian StyleAbidin, Taufik Fuadi, Amir Mahazir, Muhammad Subianto, Khairul Munadi, and Ridha Ferdhiana. 2020. "Recognizing Indonesian Acronym and Expansion Pairs with Supervised Learning and MapReduce" Information 11, no. 4: 210. https://doi.org/10.3390/info11040210
APA StyleAbidin, T. F., Mahazir, A., Subianto, M., Munadi, K., & Ferdhiana, R. (2020). Recognizing Indonesian Acronym and Expansion Pairs with Supervised Learning and MapReduce. Information, 11(4), 210. https://doi.org/10.3390/info11040210