SVD++ Recommendation Algorithm Based on Backtracking


Abstract
:1. Introduction
2. Recommendation System
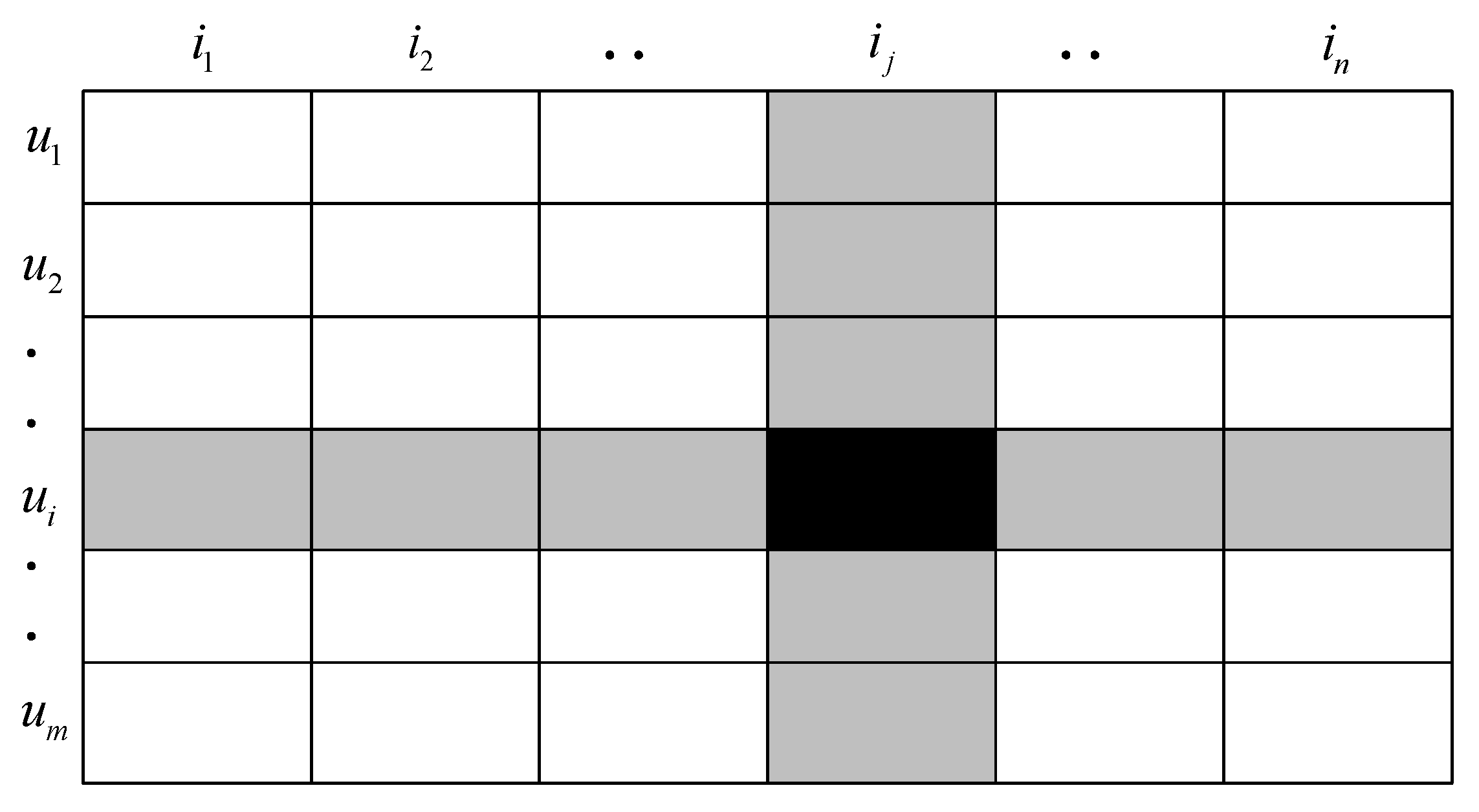
2.1. SVD Recommendation Algorithm
2.2. RSVD and SVD++ Recommendation Algorithm
2.3. Latent Factor Model and Loss Function
3. Backtracking Based SVD++ Model
| Algorithm 1 BLS-SVD++ |
|
4. Experimental Results and Analysis
4.1. Lab Environment
4.2. Evaluation Metrics
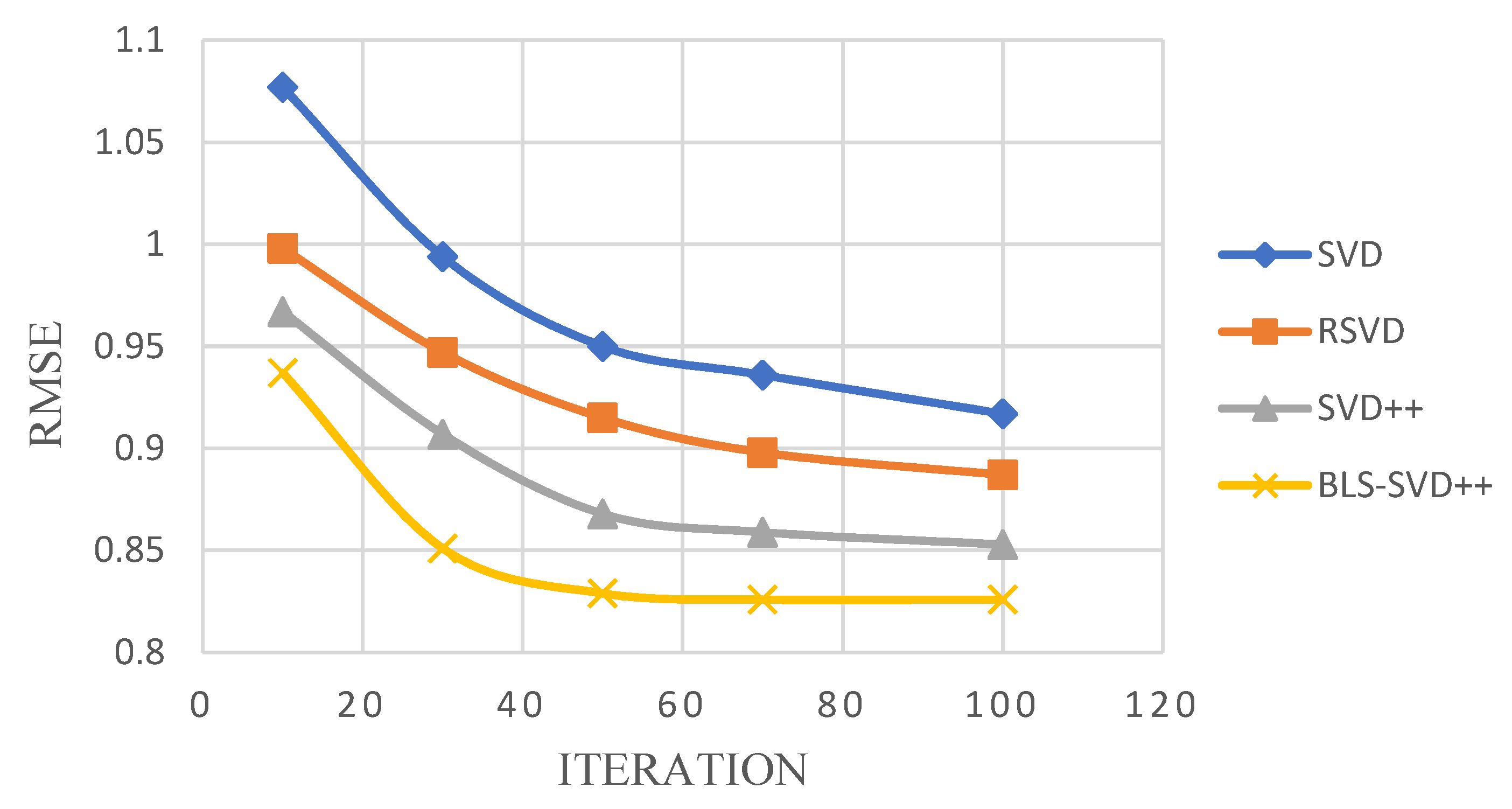
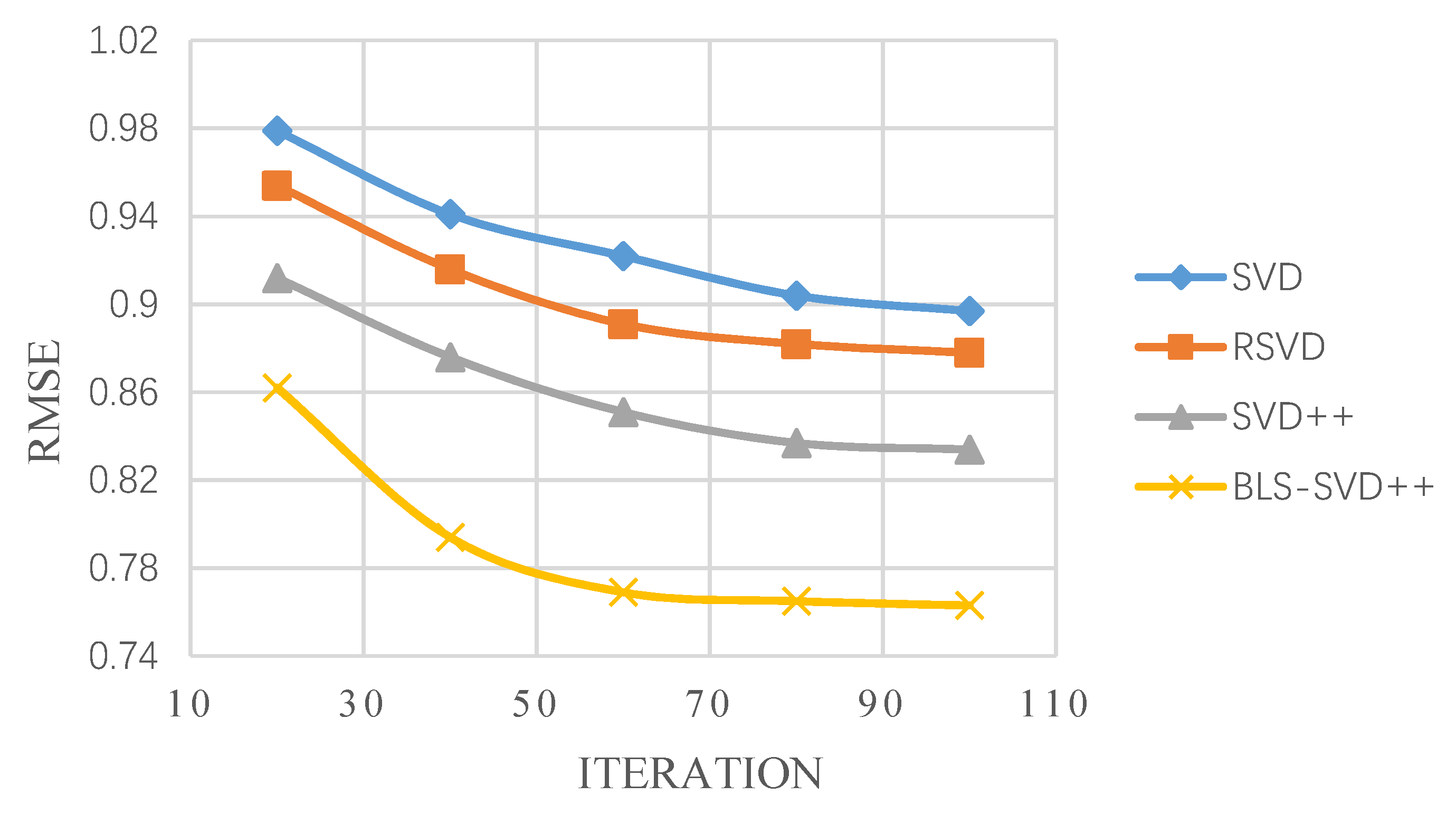
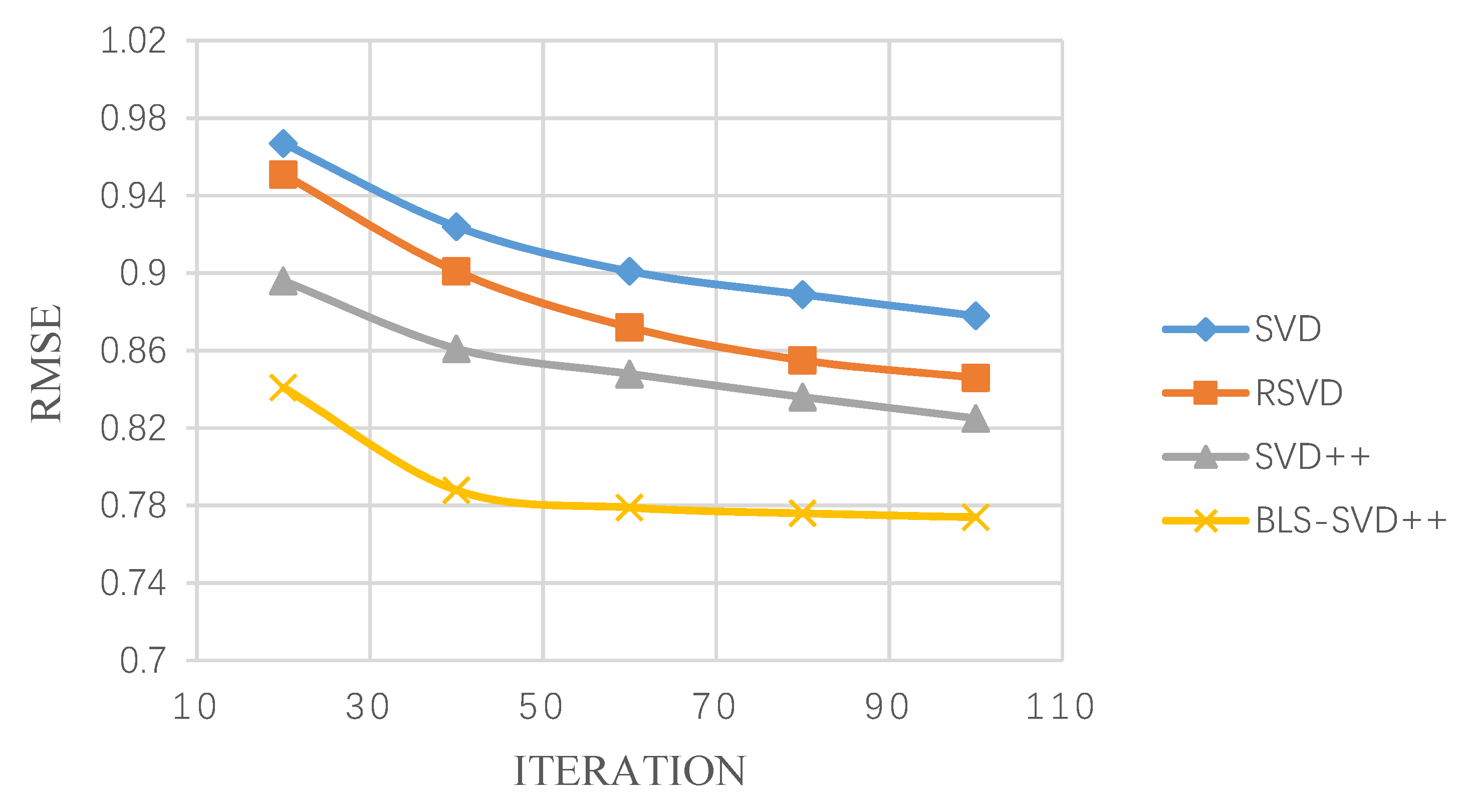
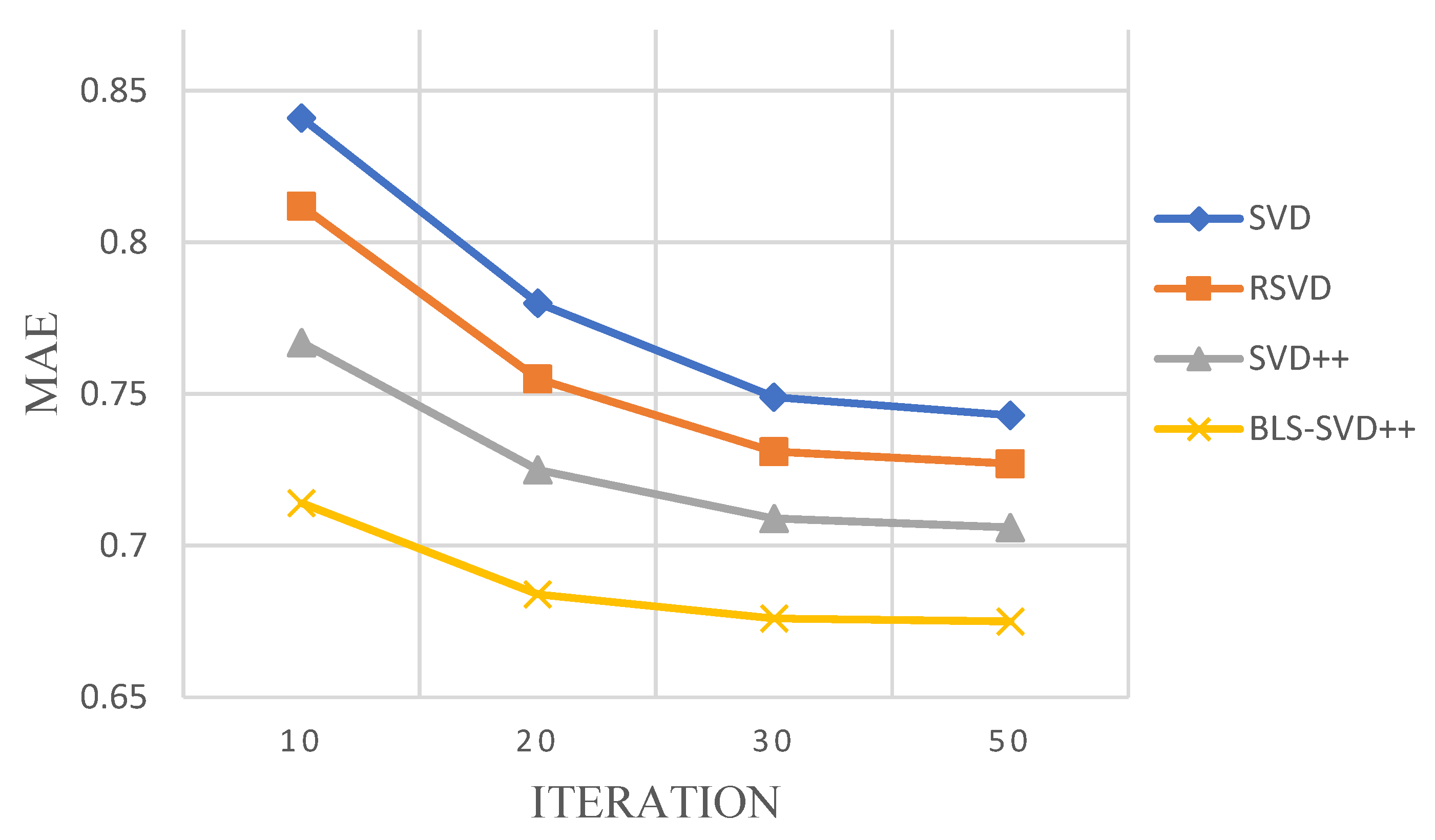
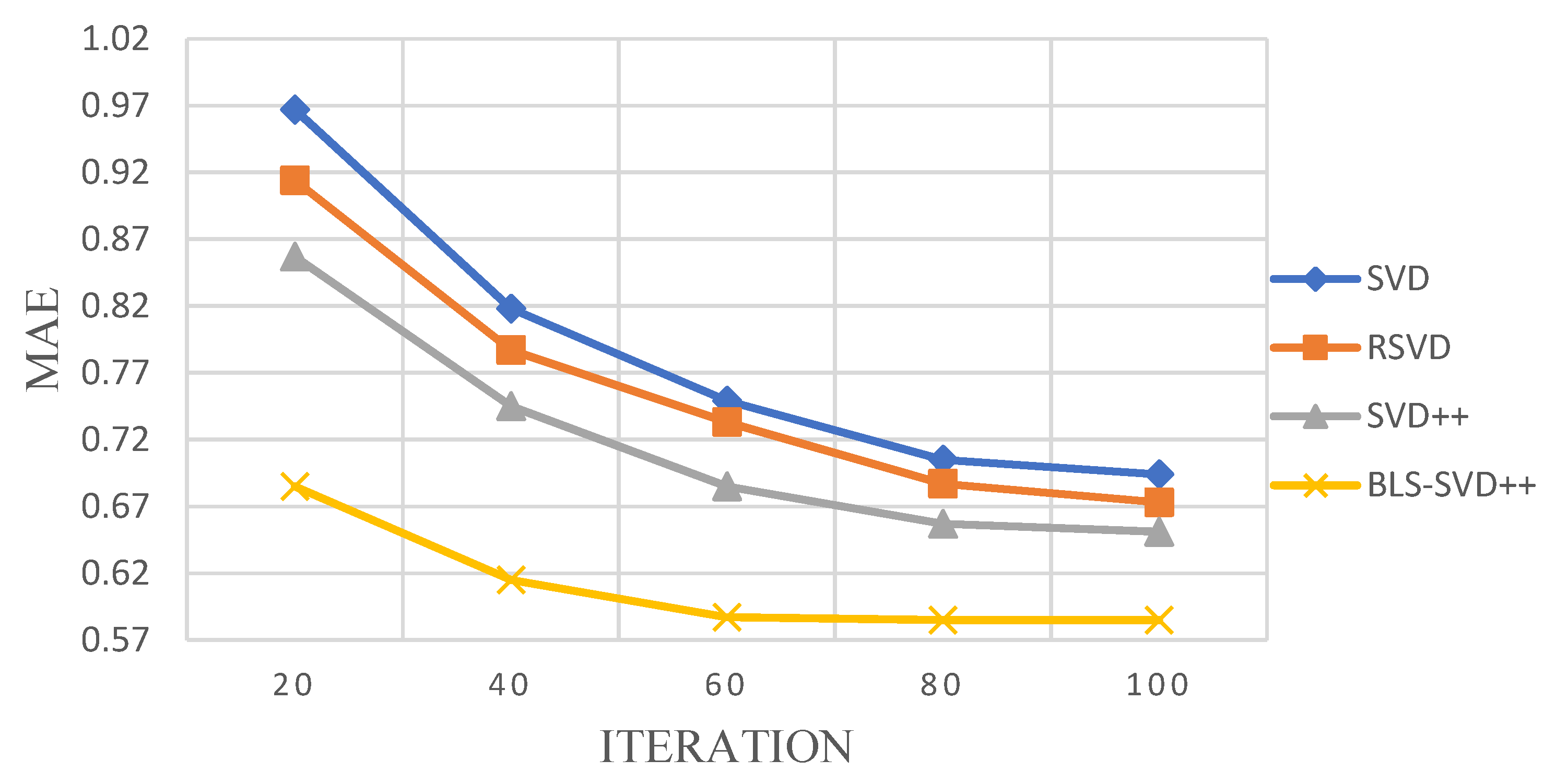
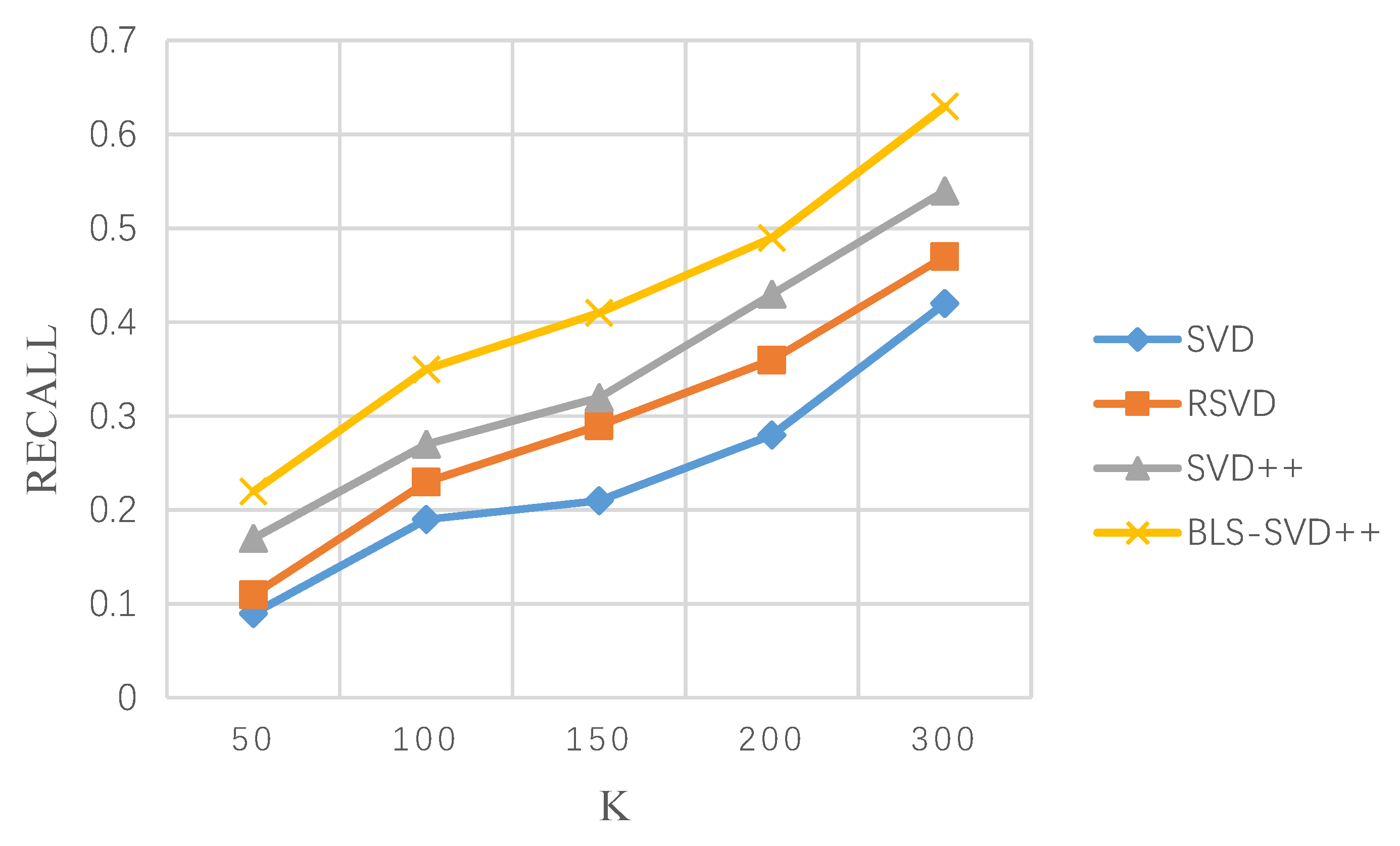
4.3. Evaluating of Result
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wei, J.; Meng, F.; Arunkumar, N. A personalized authoritative user-based recommendation for social tagging. Future Gener. Comput. Syst. 2018, 86, 355–361. [Google Scholar] [CrossRef]
- Kluver, D.; Ekstrand, M.D.; Konstan, J.A. Rating-based collaborative filtering: Algorithms and evaluation. In Social Information Access; Springer: Cham, Switzerland, 2018; pp. 344–390. [Google Scholar]
- Yuan, X.; Han, L.; Qian, S.; Xu, G.; Yan, H. Singular value decomposition based recommendation using imputed data. Knowl. Based Syst. 2019, 163, 485–494. [Google Scholar] [CrossRef]
- Hu, J.; Liang, J.; Kuang, Y. A user similarity-based Top-N recommendation approach for mobile in-application advertising. Expert Syst. Appl. 2018, 111, 51–60. [Google Scholar] [CrossRef]
- Sahoo, A.K.; Pradhan, C.; Mishra, B.S.P. SVD based Privacy Preserving Recommendation Model using Optimized Hybrid Item-based Collaborative Filtering. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Tsaku, N.Z.; Kosaraju, S. Boosting Recommendation Systems through an Offline Machine Learning Evaluation Approach. In Proceedings of the 2019 ACM Southeast Conference, Kennesaw, GA, USA, 18–20 April 2019; pp. 182–185. [Google Scholar]
- Yin, Y.; Zhang, W.; Xu, Y.; Zhang, H.; Mai, Z.; Yu, L. QoS Prediction for Mobile Edge Service Recommendation with Auto-Encoder. IEEE Access 2019, 7, 62312–62324. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, X.; Li, L.; Yan, J. A Novel Algorithm for Group Recommendation Based on Combination of Recessive Characteristics. In Proceedings of the 2018 5th International Conference on Behavioral, Economic, and Socio-Cultural Computing (BESC), Taiwan, 12–14 November 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Royer, C.W.; Wright, S.J. Complexity analysis of second-order line-search algorithms for smooth nonconvex optimization. SIAM J. Optim. 2018, 28, 1448–1477. [Google Scholar] [CrossRef] [Green Version]
- Paquette, C.; Scheinberg, K. A stochastic line search method with convergence rate analysis. arXiv 2018, arXiv:1807.07994. [Google Scholar]
- Huang, W.; Absil, P.-A.; Gallivan, K.A. A Riemannian BFGS method without differentiated retraction for nonconvex optimization problems. SIAM J. Optim. 2018, 28, 470–495. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Lo, D.; Vasilescu, B.; Serebrenik, A. EnTagRec++: An enhanced tag recommendation system for software information sites. Empir. Softw. Eng. 2018, 23, 800–832. [Google Scholar] [CrossRef] [Green Version]
- Manogaran, G.; Varatharajan, R.; Priyan, M.K. Hybrid recommendation system for heart disease diagnosis based on multiple kernel learning with adaptive neuro-fuzzy inference system. Multimed. Tools Appl. 2018, 77, 4379–4399. [Google Scholar] [CrossRef]
- Rebentrost, P.; Steffens, A.; Marvian, I.; Lloyd, S. Quantum singular-value decomposition of nonsparse low-rank matrices. Phys. Rev. A 2018, 97, 012327. [Google Scholar] [CrossRef] [Green Version]
- Raghuwanshi, S.K.; Pateriya, R.K. Accelerated Singular Value Decomposition (ASVD) using momentum based Gradient Descent Optimization. J. King Saud Univ. Comput. Inf. Sci. 2018. [Google Scholar] [CrossRef]
- Diniz, P.S.R. The least-mean-square (LMS) algorithm. In Adaptive Filtering; Springer: Cham, Switzerland, 2020; pp. 61–102. [Google Scholar]
- Jilg, A.; Bechstein, P.; Saade, A.; Dick, M.; Li, T.X.; Tosini, G.; Rami, A.; Zemmar, A.; Stehle, J.H. Melatonin modulates daytime-dependent synaptic plasticity and learning efficiency. J. Pineal Res. 2019, 66, e12553. [Google Scholar] [CrossRef] [PubMed]
- Medvedeva, M.A.; Simos, T.E.; Tsitouras, C. Variable step-size implementation of sixth-order Numerov-type methods. Math. Methods Appl. Sci. 2020, 43, 1204–1215. [Google Scholar] [CrossRef]
- Harrag, A.; Messalti, S. Ic-based variable step size neuro-fuzzy mppt improving pv system performances. Energy Procedia 2019, 157, 362–374. [Google Scholar] [CrossRef]
- Wang, W.; Lu, Y. Analysis of the Mean Absolute Error (MAE) and the Root Mean Square Error (RMSE) in Assessing Rounding Model. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Kazimierz Dolny, Poland, 21–23 November 2019; IOP Publishing: Bristol, UK, 2018; Volume 324, p. 012049. [Google Scholar]
- Vann, J.C.J.; Jacobson, R.M.; Coyne-Beasley, T.; Asafu-Adjei, J.K.; Szilagyi, P.G. Patient reminder and recall interventions to improve immunization rates. Cochrane Database Syst. Rev. 2018, 1, CD003941. [Google Scholar]
- Portugal, I.; Alencar, P.; Cowan, D. The use of machine learning algorithms in recommender systems: A systematic review. Expert Syst. Appl. 2018, 97, 205–227. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | RMSE | |||
|---|---|---|---|---|
| SVD | RSVD | SVD++ | BLS-SVD++ | |
| MovieLens 1 M | 0.891 | 0.874 | 0.831 | 0.763 |
| MovieLens 10 M | 0.864 | 0.845 | 0.822 | 0.734 |
| FilmTrust | 0.903 | 0.887 | 0.853 | 0.826 |
| Dataset | MAE | |||
|---|---|---|---|---|
| SVD | RSVD | SVD++ | BLS-SVD++ | |
| MovieLens 1 M | 0.736 | 0.724 | 0.706 | 0.675 |
| MovieLens 10 M | 0.694 | 0.673 | 0.651 | 0.585 |
| FilmTrust | 0.790 | 0.758 | 0.725 | 0.707 |
| Module | Recommended List Length K | ||||
|---|---|---|---|---|---|
| 50 | 100 | 150 | 200 | 300 | |
| SVD | 0.09 | 0.18 | 0.21 | 0.28 | 0.42 |
| RSVD | 0.11 | 0.23 | 0.29 | 0.36 | 0.47 |
| SVD++ | 0.17 | 0.27 | 0.32 | 0.43 | 0.54 |
| BLS-SVD++ | 0.23 | 0.35 | 0.41 | 0.49 | 0.63 |
| Module | Recommended List Length K | ||||
|---|---|---|---|---|---|
| 50 | 100 | 150 | 200 | 300 | |
| SVD | 0.07 | 0.16 | 0.19 | 0.24 | 0.37 |
| RSVD | 0.09 | 0.20 | 0.23 | 0.32 | 0.41 |
| SVD++ | 0.13 | 0.27 | 0.31 | 0.36 | 0.46 |
| BLS-SVD++ | 0.16 | 0.32 | 0.38 | 0.45 | 0.55 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Sun, G.; Li, Y. SVD++ Recommendation Algorithm Based on Backtracking. Information 2020, 11, 369. https://doi.org/10.3390/info11070369
Wang S, Sun G, Li Y. SVD++ Recommendation Algorithm Based on Backtracking. Information. 2020; 11(7):369. https://doi.org/10.3390/info11070369
Chicago/Turabian StyleWang, Shijie, Guiling Sun, and Yangyang Li. 2020. "SVD++ Recommendation Algorithm Based on Backtracking" Information 11, no. 7: 369. https://doi.org/10.3390/info11070369
APA StyleWang, S., Sun, G., & Li, Y. (2020). SVD++ Recommendation Algorithm Based on Backtracking. Information, 11(7), 369. https://doi.org/10.3390/info11070369