Topic Jerk Detector: Detection of Tweet Bursts Related to the Fukushima Daiichi Nuclear Disaster


Abstract
:1. Introduction
2. Related Works
2.1. Tweet Analysis for Fukushima Daiichi Nuclear Disaster
2.2. Modeling Streams of Topics and Burst Detection
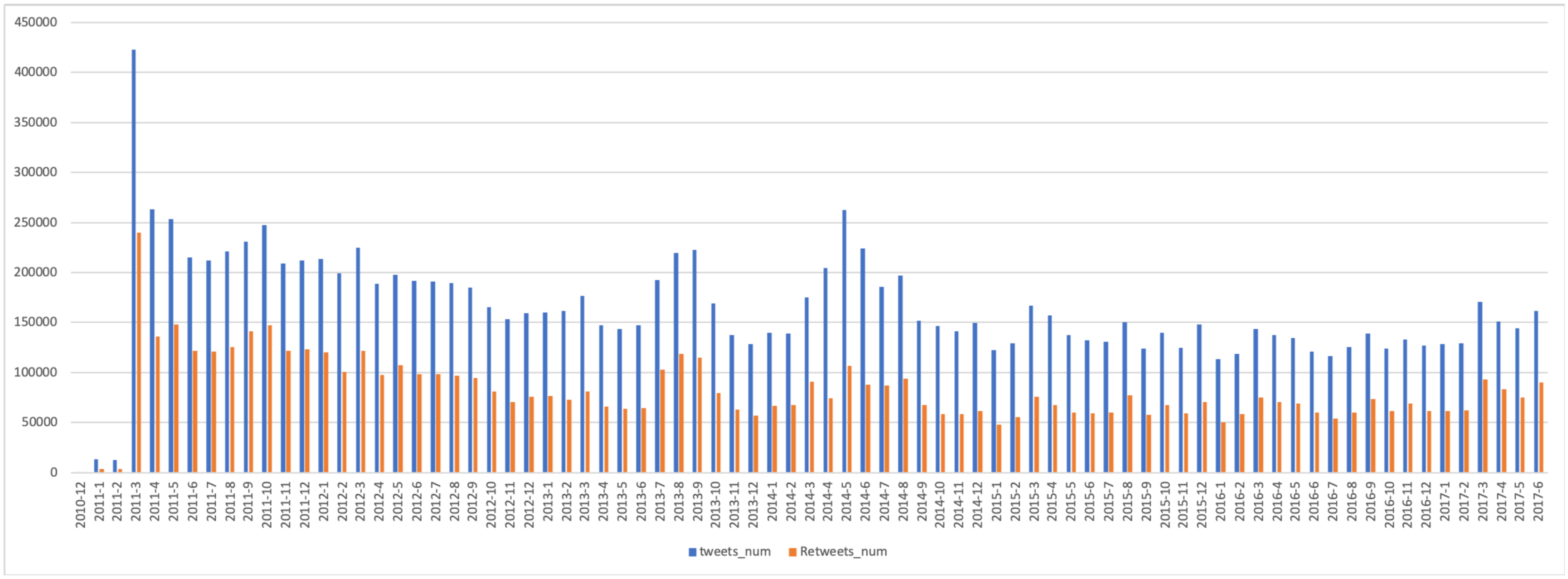
3. Dataset
3.1. Data Extraction
3.2. Preprocessing
4. Method
4.1. Topic Dynamics
4.2. Topic Jerk Detector: Expanded Method for Bursting Topics Detection
5. Experiment
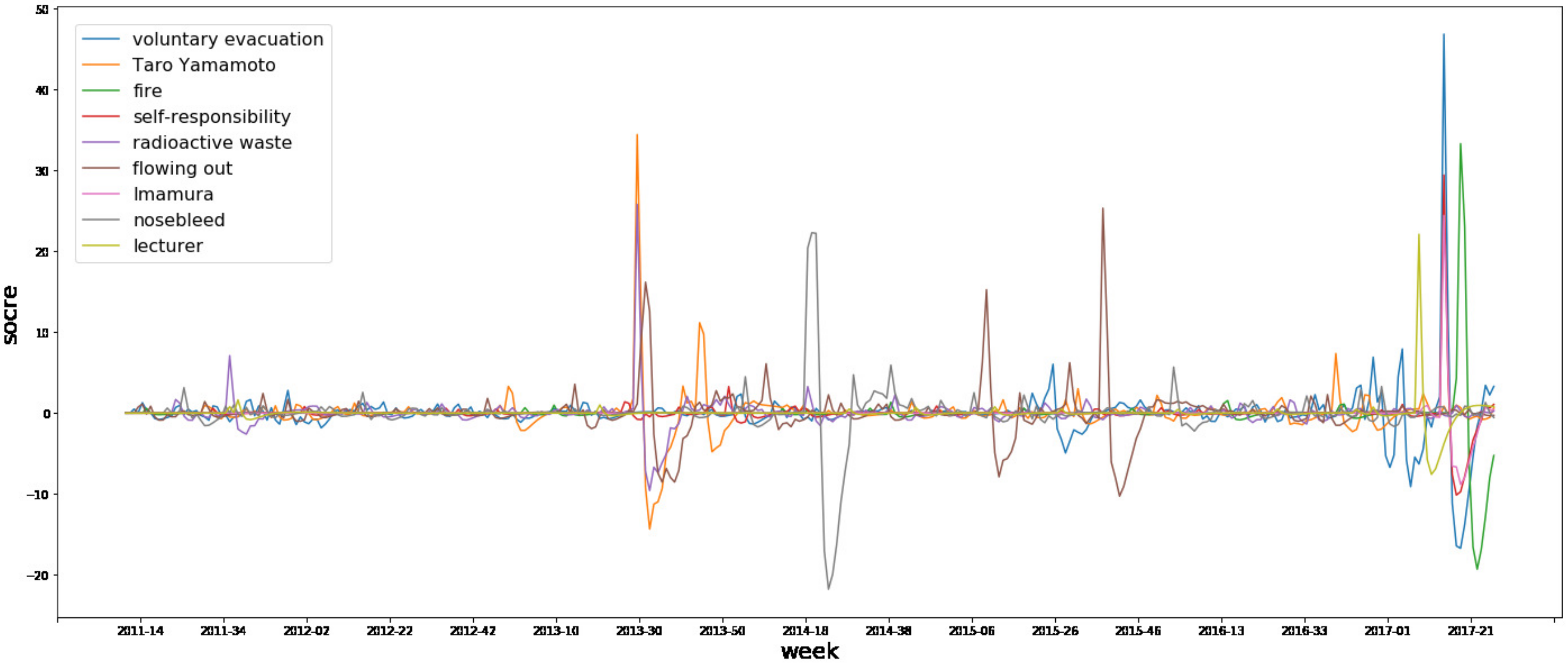
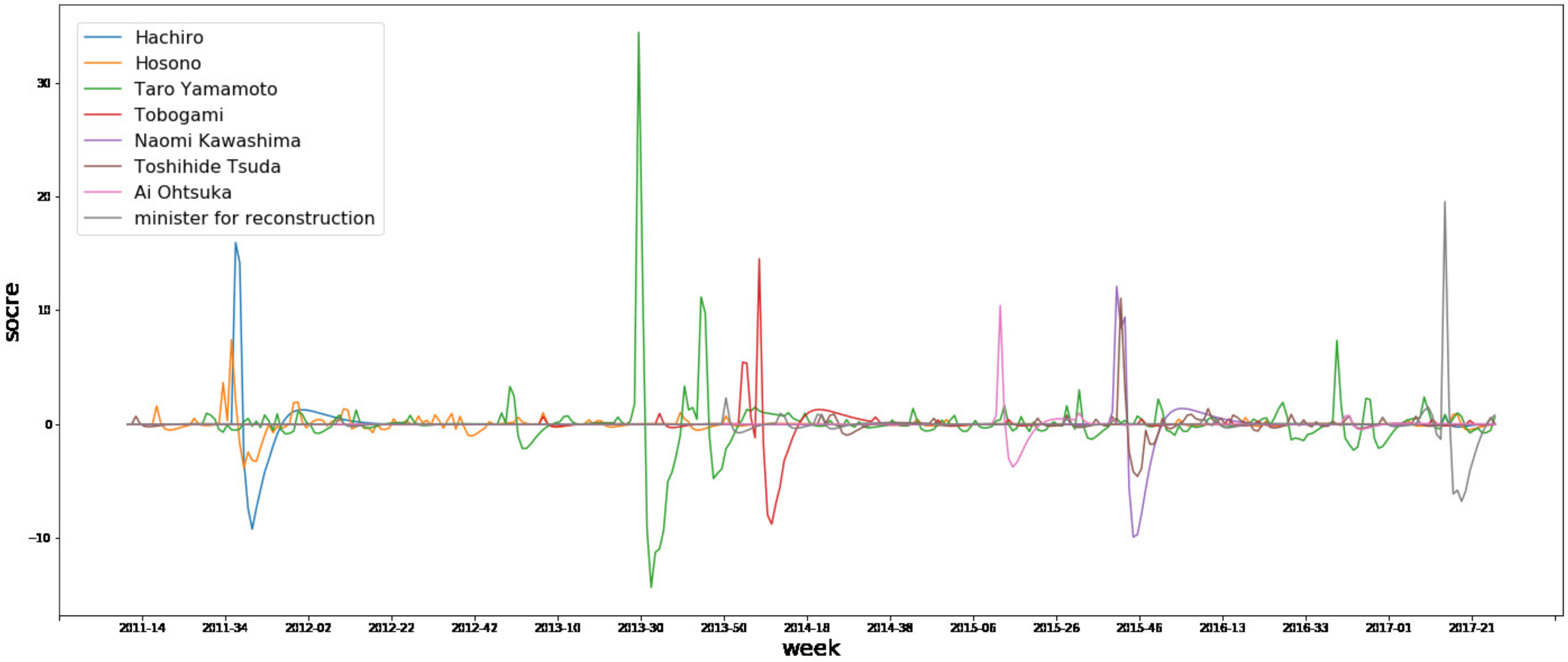
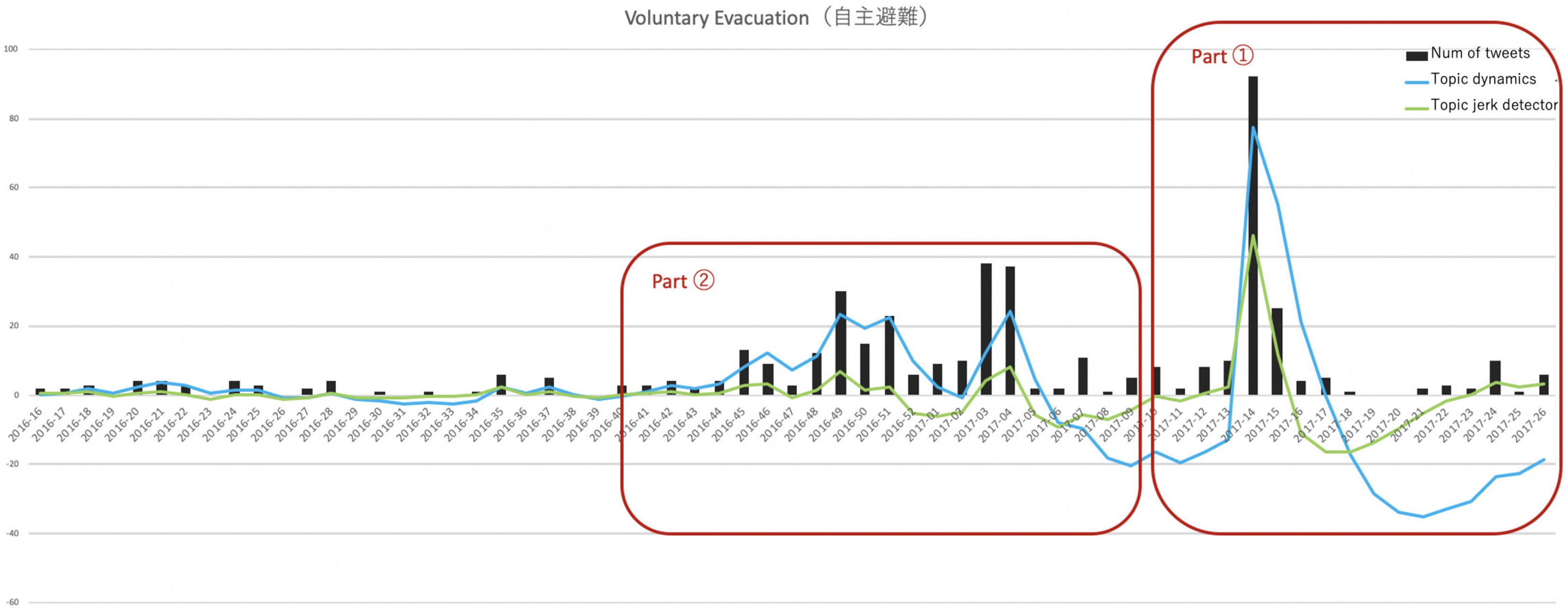
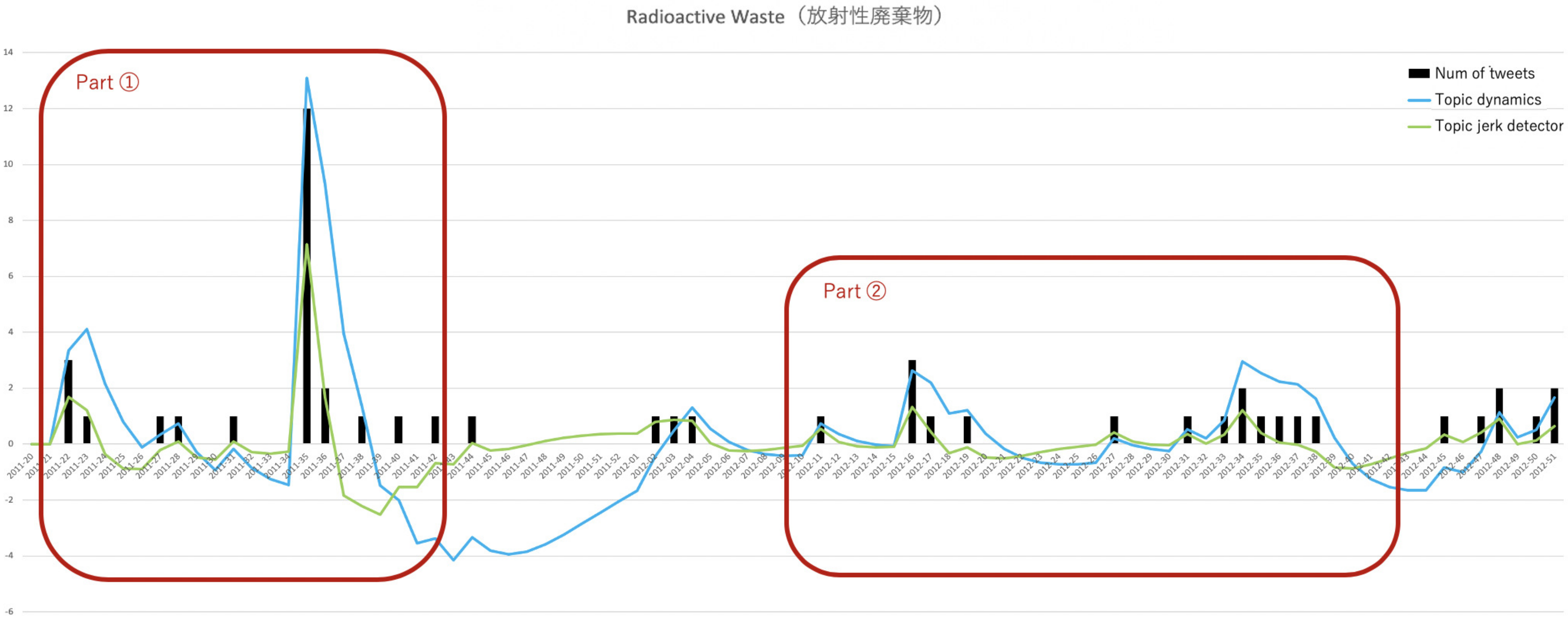
5.1. Detection of Hot Topics and Transition Plotting
5.2. Model Comparison
5.3. Domain Expert Feedback
- Are the results considered appropriate as information diffused to the public for each period in the tables?
- Is there something that says “It is strange that this word has not appeared during this period”?
- Please share the findings obtained during the research and investigation of nuclear power plant accidents related to the analysis results and related matters.
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

| Key Phrase | English Transition |
|---|---|
| 放射 | radio- or radia- |
| 被ばく, 被曝, 被爆 | exposure |
| 除染 | decontamination |
| 線量 | dose |
| ヨウ素 | iodine |
| セシウム | cesium |
| シーベルト, msv, μsv, usv, Sv, mSV, μSV, uSV | Sv, sievert |
| ベクレル, Bq | becquerel, Bq |
| ガンマ線, γ線 | gamma ray, γ-ray |
| 核種 | isotope |
| 甲状腺, 甲状線 | thyroid |
| チェルノブイリ | Chernobyl |
| 規制値 | regulation value |
| 基準値 | standard value |
| 学会 | academic society |
| 警戒区域 | no-entry zone |
| 避難区域 | evacuation zone |
| 産科婦人科 | obstetrics and gynecology |
| 周産期・新生児医 | perinatal and neonatal care |
| 日本疫 | nuclear medicine |
| 核医 | nuclear medicine |
| 電力中央 | central electric |
| 学術会議 | science council |
| 環境疫 | environmental epidemiology |
| 物理学会 | Physical Society |
| プルトニウム | plutonium |
| ストロンチウム | strontium |
| 暫定基準 | provisional standard |
| 暫定規制 | provisional regulation |
| 屋内退避 | sheltering |
| 金町浄水場 | Kanamachi Water Purification Plant |
| 出荷制限 | shipment restriction |
| 管理区域 | control area |
| 避難地域 | evacuation area |
| モニタリング | monitoring |
| スクリーニング | screening |
| ホットスポット | hot spot |
| 汚染 | contamination |
| (土OR 食品OR 水) AND 検査 | (soil OR food OR water) AND inspection |
| (がん OR ガン OR 癌) ANS リスク | cancer AND risk |
| 影響 AND (妊婦 OR 妊娠 OR 出産 OR 子ども OR 子供OR こども OR 児) 母子避難 | effect AND (pregnant woman OR pregnancy OR childbirth OR child) mother and child evacuation |
| 避難弱者 | people having difficulty in evacuation |
| 自主避難 | voluntary evacuation |
| 避難関連死, 避難死 | death associated with evacuation |
| (安心OR 安全OR 不安OR 食品OR 野菜 OR 米OR 牛肉OR 産OR 検査OR 避難) AND (福島OR ふくしま OR フクシマ) | (safety OR relief OR anxiety OR food OR vegetable OR rice OR beef OR product OR inspection OR evacuation) AND Fukushima |
References
- Nagaya, H.; Uno, K.; Torii, H.A. Tracking Topics of Influential Tweets on Fukushima Disaster Over Long Periods of Time. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019. [Google Scholar]
- Graham, S. UNSCEAR 2013 Report. Volume I: Report to the General Assembly, Annex A: Levels and effects of radiation exposure due to the nuclear accident after the 2011 great east-Japan earthquake and tsunami. J. Radiol. Prot. 2014, 34, 725. [Google Scholar]
- Dennis, N. Epidemic of Fear; American Association for the Advancement of Science: Washington, DC, USA, 2016; pp. 1022–1023. [Google Scholar]
- Toriumi, F.; Sakaki, T.; Shinoda, K.; Kazama, K.; Kurihara, S.; Noda, I. Information sharing on Twitter during the 2011 catastrophic earthquake. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Wilcox, C. Guest editorial: It’s time to e-volve: Taking responsibility for science communication in a digital age. Biol. Bull. 2012, 222, 85–87. [Google Scholar] [CrossRef] [PubMed]
- Athanasia, N.; Stavros, P.T. Twitter as an instrument for crisis response: The Typhoon Haiyan case study. In Proceedings of the 12th International Conference on Information Systems for Crisis Response and Management, Kristiansand, Norway, 24–27 May 2015. [Google Scholar]
- Dufty, N. Twitter turns ten: Its use to date in disaster management. Australian Journal of Emergency Management. Aust. J. Emerg. Manag. 2016, 31, 50. [Google Scholar]
- Suh, B.; Hong, L.; Hong, L.; Chi, E.H. Want to be retweeted? Large scale analytics on factors impacting retweet in twitter network. In Proceedings of the 2010 IEEE Second International Conference on Social Computing, Minneapolis, MN, USA, 20–22 August 2010. [Google Scholar]
- Shiels, M. Twitter Co-Founder Jack Dorsey Rejoins Company. Available online: https://www.bbc.co.uk/news/business-12889048 (accessed on 10 April 2020).
- Matsumoto, K.; Yoshida, M.; Kita, K. Analysis of Information Spreading by Social Media based on Emotion and Empathy. In Mass Communication; IntechOpen: London, UK, 2019. [Google Scholar]
- Alam, F.; Ofli, F.; Imran, M. Crisismmd: Multimodal Twitter datasets from natural disasters. In Proceedings of the Twelfth International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Tsou, M.-H.; Jung, C.-T.; Allen, C.; Yang, J.-A.; Han, S.; Spitzberg, B.; Dozier, J. Building a real-time geo-targeted event observation (Geo) viewer for disaster management and situation awareness. In Proceedings of the International Cartographic Conference, Washington, DC, USA, 2–7 July 2017; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Imran, M.; Castillo, C.; Lucas, J.; Meier, P.; Vieweg, S. AIDR: Artificial intelligence for disaster response. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014. [Google Scholar]
- Hughes, A.L.; Palen, L. Twitter adoption and use in mass convergence and emergency events. Int. J. Emerg. Manag. 2009, 6, 248–260. [Google Scholar] [CrossRef] [Green Version]
- Sakaki, T.; Toriumi, F.; Shinoda, K.; Kazama, K.; Kurihara, S.; Noda, I.; Matsuo, Y. Regional analysis of user interactions on social media in times of disaster. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Rantasila, A.; Sirola, A.; Kekkonen, A.; Valaskivi, K.; Kunelius, R. #fukushima Five Years On: A Multimethod Analysis of Twitter on the Anniversary of the Nuclear Disaster. Int. J. Commun. 2018, 12, 22. [Google Scholar]
- Aoki, T.; Suzuki, T.; Yagahara, A.; Hasegawa, S.; Tsuji, S.; Ogasawara, K. Analysis of the Regionality of the Number of Tweets Related to the 2011 Fukushima Nuclear Power Station Disaster: Content Analysis. JMIR Public Health Surveill. 2018, 4, e70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsubokura, M.; Onoue, Y.; Torii, H.A.; Suda, S.; Mori, K.; Nishikawa, Y.; Ozaki, A.; Uno, K. Twitter use in scientific communication revealed by visualization of information spreading by influencers within half a year after the Fukushima Daiichi nuclear power plant accident. PLoS ONE 2018, 13, e0203594. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kleinberg, J. Bursty and hierarchical structure in streams. Data Min. Knowl. Discov. 2003, 7, 373–397. [Google Scholar] [CrossRef]
- Zhu, Y.; Shasha, D. Efficient elastic burst detection in data streams. In Proceedings of the ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003. [Google Scholar]
- Zhang, X.; Shasha, D. Better burst detection. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006. [Google Scholar]
- Wagstaff, K.L.; Tang, B.; Thompson, D.R.; Khudikyan, S.; Wyngaard, J.; Deller, A.T.; Palaniswamy, D.; Tingay, S.J.; Wayth, R.B. A machine learning classifier for fast radio burst detection at the VLBA. Publ. Astron. Soc. Pac. 2016, 128, 084503. [Google Scholar] [CrossRef] [Green Version]
- Thanos, K.-G.; Polydouri, A.; Danelakis, A.; Kyriazanos, D.M.; Thomopoulos, S. Combined Deep Learning and Traditional NLP Approaches for Fire Burst Detection Based on Twitter Posts. Text Mining-Analysis, Programming and Application; IntechOpen: London, UK, 2019. [Google Scholar]
- He, D.; Parker, D.S. Topic dynamics: An alternative model of bursts in streams of topics. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010. [Google Scholar]
- Boulos, M.N.K.; Geraghty, E.M. Geographical tracking and mapping of coronavirus disease COVID-19/severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) epidemic and associated events around the world: How 21st century GIS technologies are supporting the global fight against outbreaks and epidemics. Int. J. Health Geogr. 2020, 19, 8. [Google Scholar]
- World Health Organization. WHO Coronavirus Disease (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 1 June 2020).
- Buntine, W.; Jakulin, A. Applying discrete PCA in data analysis. In Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, Banff, AB, Canada, 7–11 July 2004. [Google Scholar]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101 (Suppl. 1), 5228–5235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McCallum, A.; Corrada-Emmanuel, A.; Wang, X. The Author-Recipient-Topic Model for Topic and Role Discovery in Social Networks: Experiments with Enron and Academic Email; Computer Science Department Faculty Publication Series; University of Massachusetts—Amherst: Western Massachusetts, MA, USA, 2005; p. 44. [Google Scholar]
- Blei, D.M.; Lafferty, J.D. Dynamic topic models. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Quercia, D.; Askham, H.; Crowcroft, J. TweetLDA: Supervised topic classification and link prediction in Twitter. In Proceedings of the 4th Annual ACM Web Science Conference, Evanston, IL, USA, 23–26 June 2012. [Google Scholar]
- Hu, Y.; John, A.; Wang, F.; Kambhampati, S. Et-lda: Joint topic modeling for aligning events and their twitter feedback. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Xing, C.; Wang, Y.; Liu, J.; Huang, Y.; Ma, W.-Y. Hashtag-based sub-event discovery using mutually generative lda in twitter. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Xin Zhao, W.; Jiang, J.; Weng, J.; He, J.; Lim, E.-P.; Yan, H.; Li, X. Comparing twitter and traditional media using topic models. In Proceedings of the European Conference on Information Retrieval, Dublin, Ireland, 18–21 April 2011; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Tamura, K.; Matsui, T.; Kitakami, H.; Sakai, T. Identifying local temporal burstiness using macd histogram. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Kowloon, China, 9–12 October 2015. [Google Scholar]
- Xie, W.; Zhu, F.; Jiang, J.; Lim, E.-P.; Wang, K. Topicsketch: Real-time bursty topic detection from Twitter. IEEE Trans. Knowl. Data Eng. 2016, 28, 2216–2229. [Google Scholar] [CrossRef] [Green Version]
- Kudo, T.; Yamamoto, K.; Matsumoto, Y. Applying conditional random fields to Japanese morphological analysis. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Toshinori, S. Neologism Dictionary Based on the Language Resources on the Web for Unidic-Mecab. Available online: https://github.com/neologd/mecab-unidic-neologd (accessed on 1 July 2019).
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Piscataway, NJ, USA, 3–8 December 2003; Volume 242. [Google Scholar]
- Greg, S. The MACD Approach to Derivative (Rate of Change) Estimation. Available online: https:/gregstanleyandassociates.com/whitepapers/FaultDiagnosis/Filtering/MACD-approach/macd-approach.htm (accessed on 1 July 2019).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


| Methods | Physical Quantities Corresponding to the Methods |
|---|---|
| Topic Jerk Detector | Jerk |
| Topic Dynamics | Acceleration |
| MACD | Velocity |
| Week | Word (2011) | Week | Word (2012) | Week | Word (2013) | Week | Word (2014) |
|---|---|---|---|---|---|---|---|
| 2011-36 | minister | 2012-01 | cesium | 2013-29 | Taro Yamamoto | 2014-20 | nosebleed |
| 2011-36 | Hachiro | 2012-32 | Hiroshima | 2013-29 | radioactive waste | 2014-19 | nosebleed |
| 2011-37 | Hachiro | 2012-01 | descent | 2013-36 | Tokyo | 2014-20 | Oishinbo |
| 2011-36 | reporter | 2012-30 | strontium | 2013-31 | spill | 2014-19 | Oishinbo |
| 2011-35 | pain | 2012-37 | thyroid Cancer | 2013-36 | Olympic Games | 2014-18 | nosebleed |
| 2011-36 | Fukushima | 2012-06 | earthworm | 2013-07 | thyroid cancer | 2014-11 | News station |
| 2011-41 | Setagaya | 2012-29 | subcontract | 2013-29 | projected to win | 2014-38 | traffic |
| 2011-15 | Chernobyl | 2012-09 | son | 2013-29 | vegetables | 2014-06 | Tamogami |
| 2011-38 | fireworks | 2012-20 | evacuation | 2013-31 | contaminated water | 2014-45 | photographer |
| 2011-44 | fission reaction | 2012-49 | human | 2013-32 | outflow | 2014-29 | removal |
| 2011-11 | discrimination | 2012-34 | greenling | 2013-44 | Taro Yamamoto | 2014-08 | tank |
| 2011-11 | Fukushima | 2012-14 | wood waste | 2013-30 | Taro Yamamoto | 2014-45 | foreigner |
| 2011-28 | beef | 2012-04 | lump | 2013-32 | contaminated water | 2014-06 | Utsunomiya |
| 2011-40 | thyroid | 2012-02 | cesium | 2013-30 | contaminated water | 2014-15 | Obokata |
| 2011-21 | sv | 2012-43 | kg | 2013-38 | block | 2014-52 | thyroid cancer |
| 2011-35 | Hosono | 2012-32 | Nagasaki | 2013-30 | steam | 2014-18 | Oishinbo |
| 2011-44 | xenon | 2012-22 | fertilizer | 2013-02 | element | 2014-11 | thyroid cancer |
| 2011-35 | radioactive waste | 2012-01 | Fukushima | 2013-13 | Sazae-san | 2014-29 | scattering |
| 2011-17 | msv | 2012-01 | highest | 2013-15 | contaminated water | 2014-43 | dismantling |
| 2011-39 | plutonium | 2012-26 | plutonium | 2013-29 | interview | 2014-11 | Housute |
| Week | Word (2015) | Week | Word (2016) | Week | Word (2017) |
|---|---|---|---|---|---|
| 2015-37 | outflow | 2016-46 | bullying | 2017-14 | voluntary evacuation |
| 2015-17 | drone | 2016-06 | high school students | 2017-18 | fire |
| 2015-43 | leukemia | 2016-42 | subcommittee | 2017-14 | self-responsibility |
| 2015-37 | heavy rain | 2016-38 | dam | 2017-14 | Imamura |
| 2015-09 | contaminated water | 2016-44 | car wash | 2017-08 | lecturer |
| 2015-09 | outflow | 2016-06 | external exposure | 2017-19 | fire |
| 2015-32 | Paris | 2016-42 | resignation | 2017-14 | minister for reconstruction |
| 2015-09 | open sea | 2016-42 | doubt | 2017-08 | foreigner |
| 2015-37 | rainwater | 2016-35 | burden | 2017-18 | forest fire |
| 2015-43 | industrial accident | 2016-07 | thyroid Cancer | 2017-18 | forest |
| 2015-35 | fir | 2016-06 | writing | 2017-08 | Kansai Gakuin University |
| 2015-40 | Naomi Kawashima | 2016-52 | thyroid cancer | 2017-08 | discriminatory remarks |
| 2015-43 | Work Accident Certification | 2016-06 | papers | 2017-08 | Fukushima native |
| 2015-48 | papers | 2016-48 | homeroom teacher | 2017-19 | mountain forest |
| 2015-37 | sandbag | 2016-23 | thyroid cancer | 2017-08 | female student |
| 2015-36 | thyroid cancer | 2016-35 | typhoon | 2017-19 | wildfire |
| 2015-43 | certification | 2016-35 | imputation | 2017-08 | student |
| 2015-41 | Toshihide Tsuda | 2016-52 | reduction | 2017-14 | minister |
| 2015-12 | Ai Otsuka | 2016-16 | cost | 2017-19 | Namie |
| 2015-06 | newspaper | 2016-38 | groundwater | 2017-15 | voluntary evacuation |
| Week | Word (English) | Word (Japanese) | Score |
|---|---|---|---|
| 2017-14 | voluntary evacuation | 自主避難 | 46.202 |
| 2013-29 | Taro Yamamoto | 山本太郎 | 34.372 |
| 2017-18 | fire | 火災 | 33.838 |
| 2017-14 | self-responsibility | 自己責任 | 29.074 |
| 2013-29 | radioactive waste | 放射性廃棄物 | 26.248 |
| 2015-37 | flowing out | 流出 | 25.327 |
| 2017-14 | Imamura | 今村 | 24.445 |
| 2014-20 | nosebleed | 鼻血 | 22.384 |
| 2017-08 | lecturer | 講師 | 22.046 |
| 2014-19 | nosebleed | 鼻血 | 21.96 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagaya, H.; Hayashi, T.; A. Torii, H.; Ohsawa, Y. Topic Jerk Detector: Detection of Tweet Bursts Related to the Fukushima Daiichi Nuclear Disaster. Information 2020, 11, 368. https://doi.org/10.3390/info11070368
Nagaya H, Hayashi T, A. Torii H, Ohsawa Y. Topic Jerk Detector: Detection of Tweet Bursts Related to the Fukushima Daiichi Nuclear Disaster. Information. 2020; 11(7):368. https://doi.org/10.3390/info11070368
Chicago/Turabian StyleNagaya, Hiroshi, Teruaki Hayashi, Hiroyuki A. Torii, and Yukio Ohsawa. 2020. "Topic Jerk Detector: Detection of Tweet Bursts Related to the Fukushima Daiichi Nuclear Disaster" Information 11, no. 7: 368. https://doi.org/10.3390/info11070368
APA StyleNagaya, H., Hayashi, T., A. Torii, H., & Ohsawa, Y. (2020). Topic Jerk Detector: Detection of Tweet Bursts Related to the Fukushima Daiichi Nuclear Disaster. Information, 11(7), 368. https://doi.org/10.3390/info11070368