An Advanced Abnormal Behavior Detection Engine Embedding Autoencoders for the Investigation of Financial Transactions



Abstract
:1. Introduction
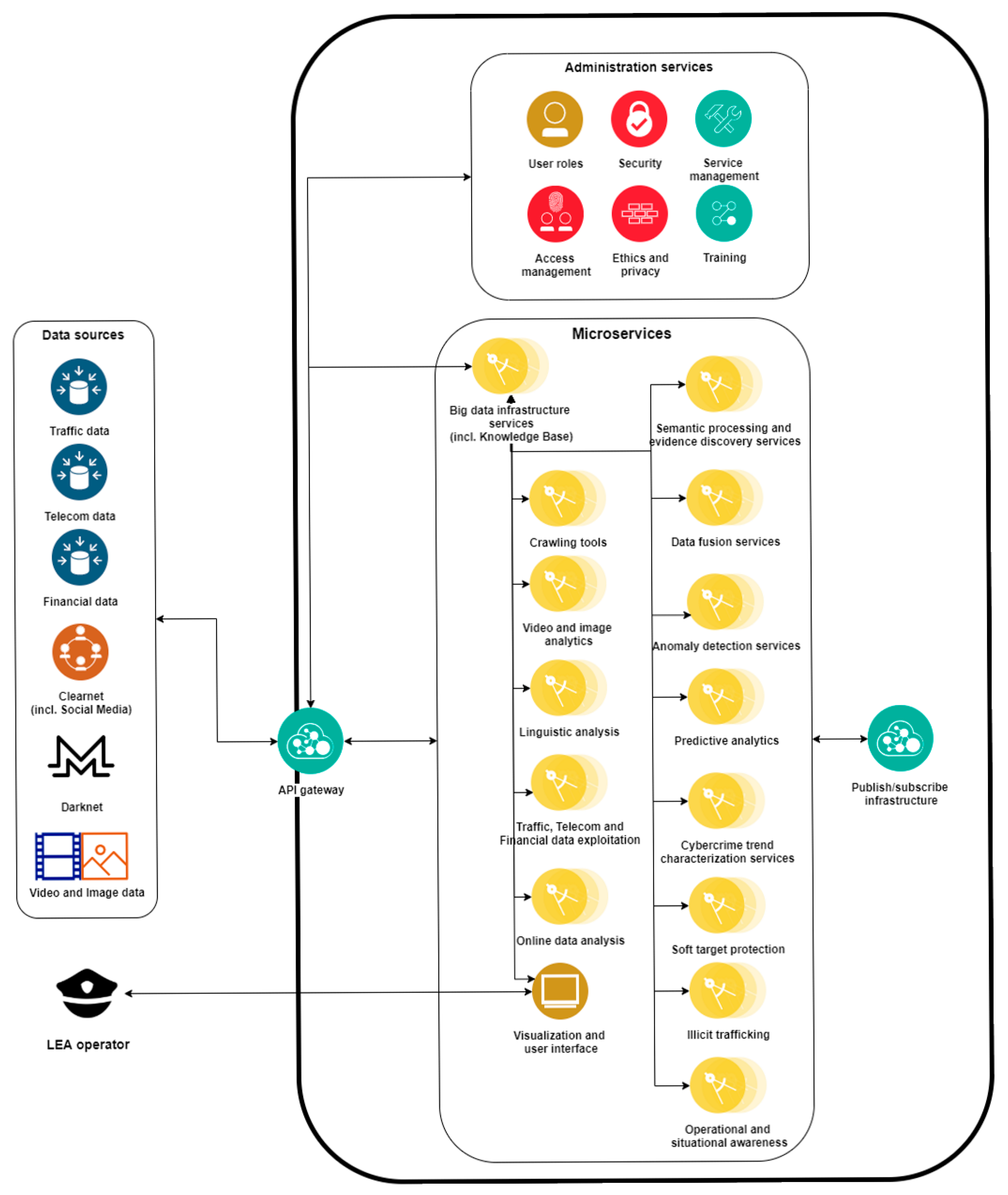
2. High Level Platform Architecture
3. An Overview of Outlier Detection Algorithms and Machine Learning Methods
3.1. Oultiers Detection Theory and Z-score for Data Labelling
- Z-score or Extreme Value Analysis (parametric);
- Probabilistic and Statistical Modelling (parametric);
- Linear Regression Models (PCA, LMS);
- Proximity Based Models (non-parametric);
- Information Theory Models;
- High Dimensional Outlier Detection Methods (high dimensional sparse data).
- Credit-card fraud, where hidden patterns of possible fraudulent or unauthorized activity and/or use of sensitive credit-card number information, as well as transaction data, can be recognized with greater ease.
- Intrusion detection systems, where abnormal or malicious activity of different data types (e.g., network traffic) in various computer systems can be detected and analyzed.
- Law enforcement, by generating specific patterns of financial frauds, insurance claims or trading activity under the action of criminal behaviors.
- Medical diagnosis, based on data collected from various sources (e.g., Magnetic Resonance Imaging - MRI, Positron Emission Tomography - PET or electrocardiogram - ECG scans) which reveal possible disease issues.
- Sensor events, since a massive amount of sensing devices (e.g., location parameters) can provide new insights or events at new domains of interest.
- Earth science, where spatiotemporal data (e.g., weather signs or climate change patterns) provide new environmental or climate trends regarding human activity or alternative hidden causes.
- Zi = Z-score for the specific data point;
- xi = individual measurement for a distinct data point;
- μ = the mean of the measurements;
- σ = the standard deviation of the measurements.
- x: the given observation data point;
- w1: class 1 (as the equation refers into a two-class problem);
- w2: class 2;
- λ: the cost between the two classes of the problem;
- P: the posterior probability that observation x is an outlier.
3.2. Outlier Detection Algorithms and Related Work
4. Evaluation and Comparison of Different Methods for Outlier Detection
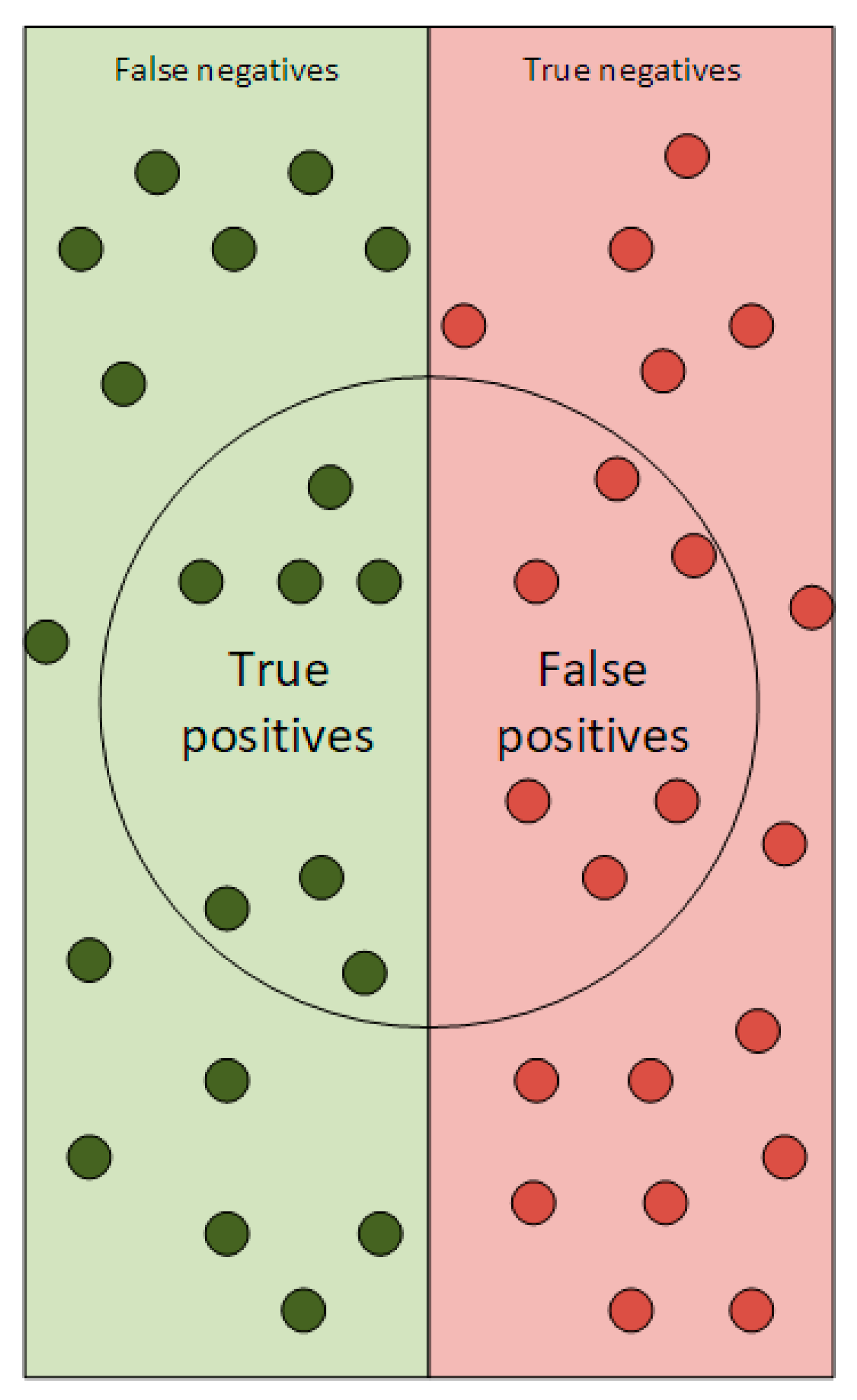
4.1. Evaluation of Results
- t: the defined threshold;
- S(t): the declared outlier;
- G: the true set of outliers in the data set.
4.2. Comparison of Different Algorithms, Datasets and Results
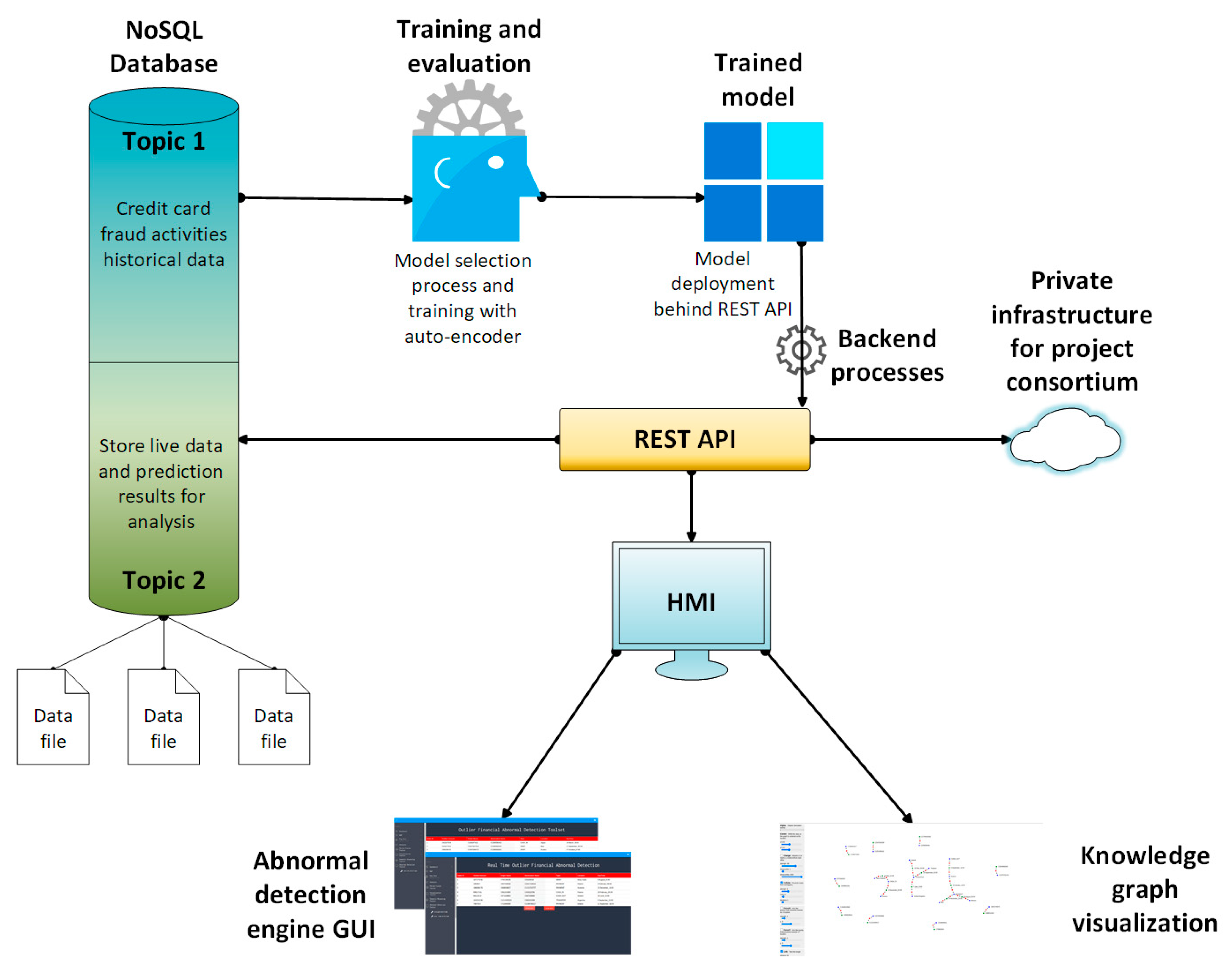
5. Real-Time Abnormal Behavior Detection Engine and Knowledge Base Visualization Tool
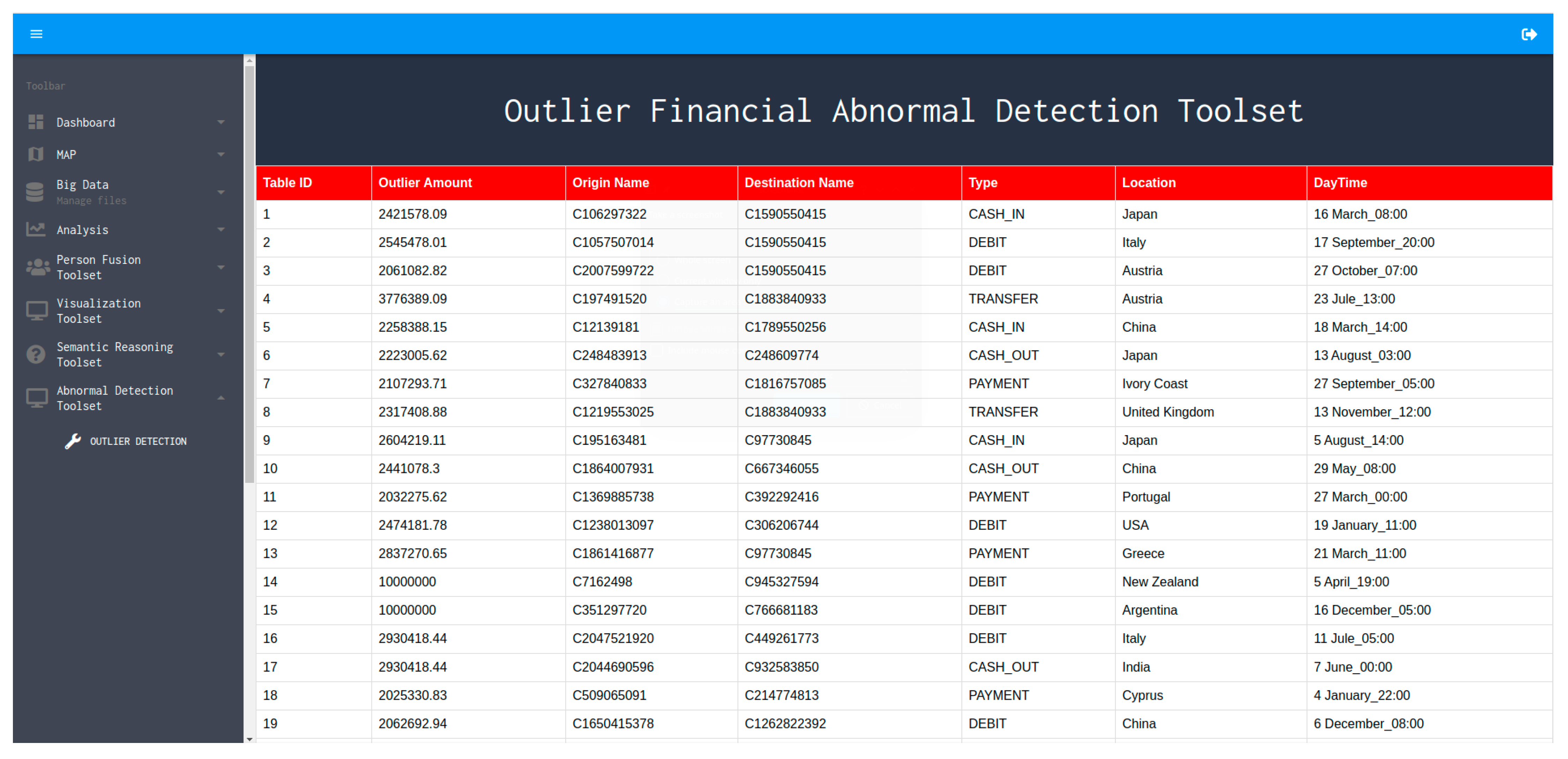
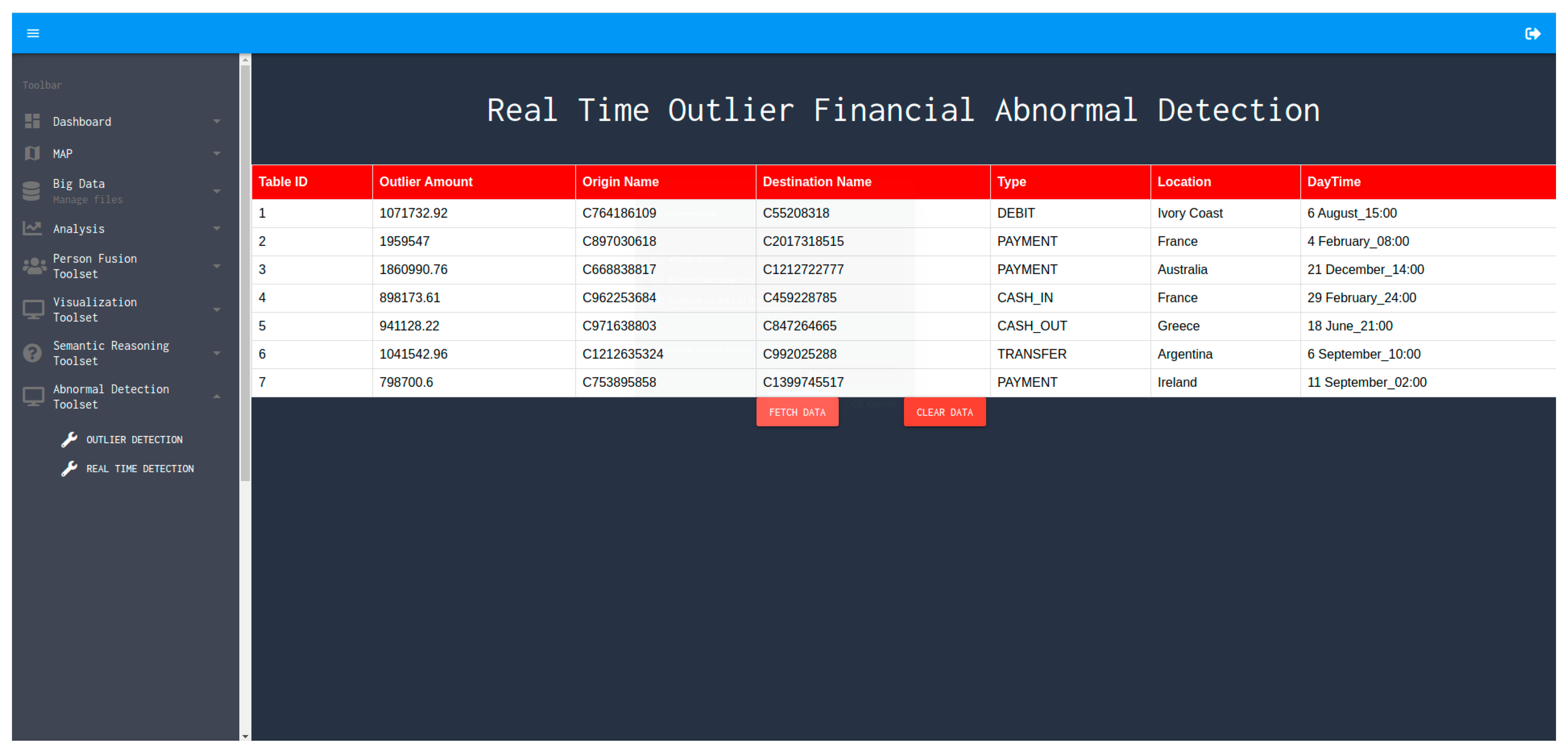
5.1. Real-Time Abnormal Behavior Detection Engine Interface
- The amount of money transferred in the mobile financial transaction;
- The source name of the transaction;
- The destination name of the transaction;
- The execution type of the transaction (includes Cash-in, Cash-out, Debit, Payment, Transfer);
- Location name of the destination endpoint of the executed transaction;
- Date and time of the executed transaction.
5.2. Knowledge Graph Visualization Tool
6. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. SSH: Single Stage Headless Face Detector. arXiv 2017, arXiv:1708.03979v3. [Google Scholar]
- Reichertz, J. Induction, Deduction, Abduction. In The SAGE Handbook of Qualitative Data Analysis; SAGE Publications Ltd.: London, UK, 2020. [Google Scholar]
- Puppe, F. (Ed.) Probabilistic Reasoning. In Systematic Introduction to Expert Systems: Knowledge Representations and Problem-Solving Methods; Springer: Berlin/Heidelberg, Germany, 1993; pp. 57–70. ISBN 978-3-642-77971-8. [Google Scholar]
- Castanedo, F. A Review of Data Fusion Techniques. Sci. World J. 2013, 2013, 704504. [Google Scholar] [CrossRef] [PubMed]
- Muhammed, M.; Obidallah, W.; Bijan, R. Applying Deep Learning Techniques for Big Data Analytics: A Systematic Literature Review. Arch. Inf. Sci. Tech. 2018, 1. [Google Scholar] [CrossRef]
- Hawkins, D.M. Identification of Outliers; Monographs on Applied Probability and Statistics; Chapman and Hall: London, UK; New York, NY, USA, 1980; ISBN 0-412-21900-X. [Google Scholar]
- Barnett, V.; Lewis, T. Outliers in Statistical Data; Wiley Series in Probability and Statistics; Elsevier: Amsterdam, The Netherlands, 1984; ISBN 978-0-471-93094-5. [Google Scholar]
- Aggarwal, C.C. (Ed.) Outlier Analysis; Springer International Publishing: Cham, Switzerlands, 2017; ISBN 978-3-319-47577-6. [Google Scholar]
- Santoyo, S. A Brief Overview of Outlier Detection Techniques. Available online: https://towardsdatascience.com/a-brief-overview-of-outlier-detection-techniques-1e0b2c19e561 (accessed on 30 November 2020).
- Rousseeuw, P.; Hubert, M. Robust Statistics for Outlier Detection. Wiley Interdisc. Rew. Data Min. Knowl. Discov. 2011, 1, 73–79. [Google Scholar] [CrossRef]
- Cohen, I. Outliers Analysis: A Quick Guide to the Different Types of Outliers. Available online: https://towardsdatascience.com/outliers-analysis-a-quick-guide-to-the-different-types-of-outliers-e41de37e6bf6 (accessed on 1 December 2020).
- Wilcox, R.R. Fundamentals of Modern Statistical Methods, 2nd ed.; Springer: New York, NY, USA, 2010; ISBN 978-1-4419-5525-8. [Google Scholar]
- HACH Quality Corner: Determining Outliers. Available online: https://support.hach.com/ci/okcsFattach/get/1008007_4 (accessed on 1 December 2020).
- Gao, J.; Tan, P. Converting Output Scores from Outlier Detection Algorithms into Probability Estimates. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 212–221. [Google Scholar]
- Aggarwal, C.C. (Ed.) Proximity-Based Outlier Detection. In Outlier Analysis; Springer: New York, NY, USA, 2013; pp. 101–133. ISBN 978-1-4614-6396-2. [Google Scholar]
- Breunig, M.; Kriegel, H.-P.; Ng, R.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the ACM Sigmod Record, Dallas, TX, USA, 16–18 May 2000; Volume 29, pp. 93–104. [Google Scholar]
- Tang, J.; Chen, Z.; Fu, A.W.; Cheung, D. A Robust Outlier Detection Scheme for Large Data Sets. In Proceedings of the 6th Pacific-Asia Conference on Knowledge Discovery and Data Mining, Hong Kong, China, 16–18 April 2001; pp. 6–8. [Google Scholar]
- Chiu, A.L.M. Ada Wai-chee Fu Enhancements on Local Outlier Detection. In Proceedings of the Seventh International Database Engineering and Applications Symposium, Hong Kong, China, 16–18 July 2003; pp. 298–307. [Google Scholar]
- He, Z.; Xu, X.; Deng, S. Discovering Cluster-Based Local Outliers. Pattern Recognit. Lett. 2003, 24, 1641–1650. [Google Scholar] [CrossRef]
- Gao, Z. Application of Cluster-Based Local Outlier Factor Algorithm in Anti-Money Laundering. In Proceedings of the 2009 International Conference on Management and Service Science, Wuhan, China, 20–22 September 2009; pp. 1–4. [Google Scholar]
- Goldstein, M.; Dengel, A. Histogram-Based Outlier Score (HBOS): A Fast Unsupervised Anomaly Detection Algorithm. In Proceedings of the Poster and Demo Track of the 35th German Conference on Artificial Intelligence (KI-2012), Saarbrucken, Germany, 24–27 September 2012; pp. 59–63. [Google Scholar]
- Yang, P.; Huang, B. KNN Based Outlier Detection Algorithm in Large Dataset. In Proceedings of the 2008 International Workshop on Education Technology and Training 2008 International Workshop on Geoscience and Remote Sensing, Shanghai, China, 21–22 December 2008; Volume 1, pp. 611–613. [Google Scholar]
- Hautamaki, V.; Karkkainen, I.; Franti, P. Outlier Detection Using K-Nearest Neighbour Graph. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 26 August 2004; Volume 3, pp. 430–433. [Google Scholar]
- Orair, G.H.; Teixeira, C.H.C.; Meira, W.; Wang, Y.; Parthasarathy, S. Distance-Based Outlier Detection: Consolidation and Renewed Bearing. Proc. VLDB Endow. 2010, 3, 1469–1480. [Google Scholar] [CrossRef]
- Ratnam, V. Credit Card Fraud Detection Using Anti K-Nearest Algorithm. IJCSE 2012, 4, 1035. [Google Scholar]
- Malini, N.; Pushpa, M. Analysis on Credit Card Fraud Identification Techniques Based on KNN and Outlier Detection. In Proceedings of the 2017 Third International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics (AEEICB), Chennai, India, 27–28 February 2017; pp. 255–258. [Google Scholar]
- Rousseeuw, P.J. Least Median of Squares Regression. J. Am. Stat. Assoc. 1984, 79, 871–880. [Google Scholar] [CrossRef]
- Hubert, M.; Debruyne, M.; Rousseeuw, P.J. Minimum Covariance Determinant and Extensions. WIREs Comput. Stat. 2018, 10, e1421. [Google Scholar] [CrossRef] [Green Version]
- Hubert, M.; Debruyne, M. Minimum Covariance Determinant. WIREs Comput. Stat. 2010, 2, 36–43. [Google Scholar] [CrossRef]
- Zaman, A.; Rousseeuw, P.J.; Orhan, M. Econometric Applications of High-Breakdown Robust Regression Techniques. Econ. Lett. 2001, 71, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Welsch, R.E.; Zhou, X. Application of Robust Statistics to Asset Allocation Models. REVSTAT–Stat. J. 2007, 5, 97–114. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis, 1st ed.; Springer Series in Statistics; Springer: New York, NY, USA, 1986; ISBN 978-1-4757-1904-8. [Google Scholar]
- Xu, H.; Caramanis, C.; Sanghavi, S. Robust PCA via Outlier Pursuit. IEEE Trans. Inf. Theory 2012, 58, 3047–3064. [Google Scholar] [CrossRef] [Green Version]
- Stanimirova, I.; Daszykowski, M.; Walczak, B. Dealing with Missing Values and Outliers in Principal Component Analysis. Talanta 2007, 72, 172–178. [Google Scholar] [CrossRef]
- Amnarttrakul, R.; Thongteeraparp, A. New Statistics for Detection of Outliers Using the Last Few Principal Components. Sci. Asia 2011, 37, 355–359. [Google Scholar] [CrossRef]
- Kriegel, H.-P.; Schubert, M.; Zimek, A. Angle-Based Outlier Detection in High-Dimensional Data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 444–452. [Google Scholar]
- Pham, N.; Pagh, R. A Near-Linear Time Approximation Algorithm for Angle-Based Outlier Detection in High-Dimensional Data. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 877–885. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- John, H.; Naaz, S. Credit Card Fraud Detection Using Local Outlier Factor and Isolation Forest. Int. J. Comput. Sci. Eng. 2019, 7, 1060–1064. [Google Scholar] [CrossRef]
- Laimek, R.; Kaothanthong, N.; Supnithi, T. ATM Fraud Detection Using Outlier Detection. In Proceedings of the Intelligent Data Engineering and Automated Learning (IDEAL 2018), Madrid, Spain, 21–23 November 2018; Yin, H., Camacho, D., Novais, P., Tallón-Ballesteros, A.J., Eds.; Springer International Publishing: Cham, Switzerlands, 2018; pp. 539–547. [Google Scholar]
- Buschjäger, S.; Honysz, P.-J.; Morik, K. Randomized Outlier Detection with Trees. Int. J. Data Sci. Anal. 2020. [Google Scholar] [CrossRef]
- Patterson, D.W. Artificial Neural Networks: Theory and Applications, 1st ed.; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1998; ISBN 0-13-295353-6. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks 2014. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Khamis, A.; Ismail, Z.; Khalid, H.; Mohammed, A. The Effects of Outliers Data on Neural Network Performance. J. Appl. Sci. 2005, 5, 1394–1398. [Google Scholar] [CrossRef]
- Chen, J.; Sathe, S.; Aggarwal, C.; Turaga, D. Outlier Detection with Autoencoder Ensembles. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 90–98. [Google Scholar]
- Yusup Anomaly Detection Part 1: Autoencoder. Available online: https://medium.com/ai3-theory-practice-business/anomaly-detection-part-1-autoencoder-58bdbbea5001 (accessed on 4 December 2020).
- Lenderink, R.J. Unsupervised Outlier Detection in Financial Statement Audits. Master’s Thesis, University of Twente, Enschede, The Netherlands, September 2019. [Google Scholar]
- Bolton, R.; Hand, D. Unsupervised Profiling Methods for Fraud Detection. Credit Scoring Credit Control 2001, 7, 235–255. [Google Scholar]
- Kanhere, P.; Khanuja, H.K. A Methodology for Outlier Detection in Audit Logs for Financial Transactions. In Proceedings of the 2015 International Conference on Computing Communication Control and Automation, Pune, India, 26–27 February 2015; pp. 837–840. [Google Scholar]
- Kanhere, P.; Khanuja, H.K. A Survey on Outlier Detection in Financial Transactions. Int. J. Comput. Appl. 2014, 108, 23–25. [Google Scholar] [CrossRef]
- Zhu, T. An Outlier Detection Model Based on Cross Datasets Comparison for Financial Surveillance. In Proceedings of the 2006 IEEE Asia-Pacific Conference on Services Computing (APSCC’06), Guangzhou, China, 12–15 December 2006; pp. 601–604. [Google Scholar]
- Perez, D.G.; Lavalle, M.M. Outlier Detection Applying an Innovative User Transaction Modeling with Automatic Explanation. In Proceedings of the 2011 IEEE Electronics, Robotics and Automotive Mechanics Conference, Cuernavaca, Morelos, 15–18 November 2011; pp. 41–46. [Google Scholar]
- Zhao, Y.; Nasrullah, Z.; Li, Z. PyOD: A Python Toolbox for Scalable Outlier Detection. arXiv 2019, arXiv:1901.01588. [Google Scholar]
- Spackman, K.A. Signal Detection Theory: Valuable Tools for Evaluating Inductive Learning. In Proceedings of the Sixth International Workshop on Machine Learning, New York, NY, USA, 26–27 June 1989; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1989; pp. 160–163. [Google Scholar]
- Hanley, J.A.; Mcneil, B. The Meaning and Use of the Area Under a Receiver Operating Characteristic (ROC) Curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Fawcett, T. Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; The MIT Press: Cambridge, MA, USA, 2012; ISBN 0-262-01825-X. [Google Scholar]
- Lopez-Rojas, E.A.; Elmir, A.; Axelsson, S. PaySim: A Financial Mobile Money Simulator for Fraud Detection. In Proceedings of the 28th European Modeling and Simulation Symposium, Larnaca, Cyprus, 26–28 September 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proximity-Based | LinearModel | Vector-Based | Outlier Ensembled | Neural Networks | |||||
|---|---|---|---|---|---|---|---|---|---|
| Metric | LOF | CBLOF | HBOS | KNN | MCD | PCA | ABOD | I-FOREST | AUTO-ENCODER |
| AUC—Train | 0.4942 | 0.8244 | 0.5677 | 0.9285 | 0.7964 | 0.9192 | 0.4731 | 0.9785 | 0.9985 |
| Precision—Train | 0.0099 | 0.8475 | 0.8247 | 0.8379 | 0.7522 | 0.7546 | 0.3085 | 0.9274 | 0.9474 |
| AUC—Test | 0.4831 | 0.8238 | 0.5711 | 0.9275 | 0.7951 | 0.9185 | 0.4711 | 0.9721 | 0.9974 |
| Precision—Test | 0.0086 | 0.8462 | 0.8234 | 0.8367 | 0.7487 | 0.7533 | 0.3074 | 0.9263 | 0.9461 |
| Dataset | LOF | CBLOF | HBOS | KNN | MCD | PCA | ABOD | I-FOREST |
|---|---|---|---|---|---|---|---|---|
| arrhythmia | 0.7787 | 0.7835 | 0.8219 | 0.7861 | 0.7790 | 0.7815 | 0.7688 | 0.8005 |
| letter | 0.8594 | 0.5070 | 0.5927 | 0.8766 | 0.8074 | 0.5283 | 0.8783 | 0.6420 |
| mnist | 0.7161 | 0.8009 | 0.5742 | 0.8481 | 0.8666 | 0.8527 | 0.7815 | 0.8159 |
| pendigits | 0.4500 | 0.5089 | 0.8732 | 0.3708 | 0.3979 | 0.5086 | 0.4667 | 0.7253 |
| satellite | 0.5573 | 0.5572 | 0.7581 | 0.6836 | 0.8030 | 0.5988 | 0.5714 | 0.7022 |
| Dataset | LOF | CBLOF | HBOS | KNN | MCD | PCA | ABOD | I-FOREST |
|---|---|---|---|---|---|---|---|---|
| arrhythmia | 0.4334 | 0.4539 | 0.5111 | 0.4464 | 0.3995 | 0.4613 | 0.3808 | 0.4961 |
| letter | 0.3641 | 0.0749 | 0.0715 | 0.3312 | 0.1933 | 0.0875 | 0.3801 | 0.1003 |
| mnist | 0.3343 | 0.3348 | 0.1188 | 0.4204 | 0.3462 | 0.3846 | 0.3555 | 0.3135 |
| pendigits | 0.0653 | 0.2768 | 0.2979 | 0.0984 | 0.0893 | 0.3187 | 0.0812 | 0.3422 |
| satellite | 0.3893 | 0.4152 | 0.5690 | 0.4994 | 0.6845 | 0.4784 | 0.3902 | 0.5676 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Demestichas, K.; Peppes, N.; Alexakis, T.; Adamopoulou, E. An Advanced Abnormal Behavior Detection Engine Embedding Autoencoders for the Investigation of Financial Transactions. Information 2021, 12, 34. https://doi.org/10.3390/info12010034
Demestichas K, Peppes N, Alexakis T, Adamopoulou E. An Advanced Abnormal Behavior Detection Engine Embedding Autoencoders for the Investigation of Financial Transactions. Information. 2021; 12(1):34. https://doi.org/10.3390/info12010034
Chicago/Turabian StyleDemestichas, Konstantinos, Nikolaos Peppes, Theodoros Alexakis, and Evgenia Adamopoulou. 2021. "An Advanced Abnormal Behavior Detection Engine Embedding Autoencoders for the Investigation of Financial Transactions" Information 12, no. 1: 34. https://doi.org/10.3390/info12010034
APA StyleDemestichas, K., Peppes, N., Alexakis, T., & Adamopoulou, E. (2021). An Advanced Abnormal Behavior Detection Engine Embedding Autoencoders for the Investigation of Financial Transactions. Information, 12(1), 34. https://doi.org/10.3390/info12010034