2. Related Work
Aksu et al. [
3] presented a methodology that uses CVE scores to assess cyber risk in IT systems. Their approach incorporates many facets of the CVE scores given by NIST, and uses them to calculate a numerical product of probability of vulnerability exploitation and impact of the exploitation to determine the risk of attack based on the vulnerabilities. The approach takes into account threat sources and the chance of the attack occurring to estimate the risk. However, anticipating threat capability and motivation to come to a quantifiable measurement can lead to an inaccurate estimation unless the attacker is known to the victim in advance and/or prior extensive knowledge of the attacker is readily available. While CVE scores are meant to provide a measure of severity of the attack should it happen, it is unclear if using the metrics from the CVE score calculation would lead to a correct estimation of exploitation likelihood. They also dismiss certain vulnerabilities due to considering Intrusion Detection Systems (IDS) or Intrusion Prevention Systems (IPS) that may be in place, but do not account for the failure of these systems, time between intrusions and discovery for which the vulnerabilities could be exploited, or the ability of attackers bypassing these systems. Lastly, in contrast with our approach, there are no suggestions for mitigation strategies after the risk is calculated.
Spring et al. [
4] from Carnegie Mellon University presented a paper explaining why the Common Vulnerability Scoring System (CVSS) [
5] scores need to be more justified and transparent. They question some of the aspects of the CVSS calculation, such as the type of measurement and the translation of that measurement into numerical measure. They wonder how the importance of each metric was selected and how they are weighted. Spring et al. remark that the CVSS scores indicate severity of a vulnerability, but the security community may need a different type of indication, namely risk imposed or needed response time, rather than solely the severity. They touch on the areas of dissatisfaction that have been discussed in the cybersecurity community for over 10 years, for instance, the operational scoring issues. Lastly in the paper, the authors suggest methods and practices to refine CVSS scores, such as user and scoring studies as well as a specific rubric to follow for scoring to occur. However, they offer no example formula to create or represent the scores, nor do they suggest a specific rubric to follow to score any software.
Chang et al. [
6] investigated the overall trends of CVEs over the course of 3 years (2007–2010) in an effort to assist in the focusing of preventative and mitigation tactics. The researchers chose to examine the vulnerability types that encompassed the largest amount of CVEs, which include authentication problem, buffer overflow, cryptographic error, and Cross-Site Request Forgery. The data collection resulted in over 10,000 CVEs or nearly 50% of all reported during the time period. The authors found that the number of vulnerabilities had decreased, the severity of them had moved to lower levels, and the majority of them could be exploited through accessing the system’s network without being checked for authentication at any point during the access. However, this work does not provide immediate tactics to mitigate vulnerabilities.
Tripathi and Singh [
7] made an effort to improve response to vulnerabilities by prioritising them by category through developed security metrics. They retrieved information from the National Vulnerability Database (NVD) from April 2010 to May 2011 which categorizes the vulnerabilities into 23 classes. They chose this time frame to account for the largest amount of time it takes to employ fixes. The authors calculated a security score for each of the vulnerability classes using CVSS scores and two factors they deemed important to the impact on severity, namely the availability of the patches and how long ago the vulnerability was initially reported. These are taken into consideration because as time passes from the initial report, the likelihood of the existence and employment of fixes is likely to increase. The scores are then calculated for two divisions of the vulnerabilities, those with patches and those without, and combined into a weighted sum. Tripathi and Singh [
7] found that the top three vulnerability categories are buffer errors, input validation, and resource management errors. Our methodology does not categorize vulnerabilities, but it continuously evaluates the cyber risk score for separate CPS components and the total CPS cyber risk score. Furthermore, our solution supports automatic replacement or reconfiguration of vulnerable CPS components.
Allodi and Massacci [
8] created their own databases in an effort to bridge gaps in the NVD and EnterpriseDB (EDB) for cyber attacks in the wild. The resulting databases are much smaller than those of NVD and EDB, and indicate different results. One of the created databases contains vulnerabilities that are included in Exploit Kits that are sold on the black market trade. The second is built to collect and store information about the particular attacks the researchers have interest in. The database that includes Exploit Kits may not be representative of actual attacks happening through the kits. These kits might be untrusted as they are from malicious sources. The information collection database is derived from another database, Symantec, and therefore is entirely dependent on it to pinpoint threats. The authors also explored the sensitivity of CVSS scores and report that the scores are not a good indication of the actual exploitation of vulnerabilities reported. However, CVSS are supposed to be an indication of the severity of the attack should it be exploited, not if it will be exploited.
A company, Tenable
® [
9], has produced a proprietary software (Tenable
® Lumin) that gathers necessary information from multiple sources to assess the vulnerability and cyber risk of software [
10].
The Cyber Exposure Score (CES) is calculated using two individual scores dubbed Vulnerability Priority Rating (VPR), and Asset Criticality Rating (ACR). The VPR score is a machine-generated number obtained from Tenable®’s machine learning algorithm. It is claimed that the VPR is calculated faster and in a way that prioritises the threat more than using CVSS alone. The ACR score is a user-influenced number that indicates the importance of an asset to the particular user. The Tenable® Lumin software has its own set of rules to assign the ACR score if the user does not look to employ that part of the software.
While the general mathematics and information are very straight forward, the machine learning algorithm, data sources, and anything there within are kept rightfully private by Tenable®. They provide users with a list of recommended actions to follow in order to reduce their CES, which can consist of updates and fixes that may or may not reduce the risk score depending on reports of the solution over time, rather than mitigation by switching to another software component that is considered less of a risk without fixes. The work by the Tenable® Lumin software relies on the geometric mean. They explain that this was chosen to ensure pieces of software with few vulnerabilities are scored closer to a zero value. This would seem to undervalue threats from components with few but very critical vulnerabilities. This software looks at the current setup of components and calculates the proper risk scores. The software would have to be reapplied after a component change. Our solution, in contrast, supports running a separate “What If” procedure to see the change in the total risk score for the system without actually changing the component. Furthermore, our solution supports automatic reconfiguration or replacement of vulnerable software components.
The software tool called “Vulners” [
11] can perform the vulnerability audit for Linux systems and networks. In contrast with this tool, we compute the cyber risk score for each software component and the entire system. Furthermore, our solution can evaluate the cyber risk score for non-Linux software, as well as for the hardware. Finally, our solution is integrated with the CMTD, which replaces the vulnerable components and hardens the system while the reconfiguration is in process.
Schlette et al. [
12] proposed security enumerations that can “cover various Cyber Threat Intelligence (CTI) artifacts such as platforms, vulnerabilities or even natural hazards” in CPS. A CPS security enumerations search engine allows to retrieve information about vulnerabilities related to a search query, for example, the hardware or software product name. In our approach, we compute the cyber risk score for separate CPS components and the entire CPS configuration, including software and hardware, based on registered CVEs. Furthermore, our approach allows automatic software and network reconfigurations in order to replace vulnerable CPS components and harden the CPS.
Jacobs et al. [
13] proposed a machine learning-based solution to find best practices in fixing vulnerabilities. Their solution further illustrates the EPSS model [
14]. In this model they explore on which vulnerabilities should be fixed first rather than lesser ones that get exploited much less. Unlike our solution which handles processing the cyber risk score for the entire system, their solution focuses on each individual CVE for a particular software or hardware.
Nikoloudakis et al. [
15] proposed a machine learning-based solution for an Intrusion Detection System using a Software Defined Networking (SDN). Their approach “detects existing and newly introduced network-enabled entities, utilizing the real-time awareness feature provided by the SDN paradigm, assesses them against known vulnerabilities, and assigns them to a connectivity-appropriate network slice” [
15]. While this work is shown to work with Identify, Protect, and Detect vulnerabilities, they are for the individual entities, while our solution is for an entire system of entities or components. Our approach allows to evaluate and reconfigure the existing CPS in automatic mode, based on the CVE database of cyber vulnerabilities.
Adrian R. Chavez [
16] implemented moving target defense by randomizing IP addresses and ports of each entity in a control system network with nine entities. Their strategy changed the IP addresses and port numbers in a range of frequencies varying from one second to setting static addresses. They used switches capable of Software Defined Networking to manage the moving target defense implementation. A device they called the randomization controller was added to the network to communicate the new addresses and ports to all the devices whenever a change was made. An additional router was added to the implementation to handle out-of-band communications between the switch and randomization controller. In addition to the moving target defense, the hosts in the network are running machine learning algorithms to detect anomalous behavior in the network. In contrast, our CMTD solution can be implemented into most environments without required additional hardware.
Sailik Sengupta [
17] discussed using AI algorithms to help make MTD more efficient and how to use MTD to make AI agents more secure. To make MTD more efficient, they used a repeated Bayesian game to determine the best switching scheme for the agents in a web application scenario. To help the algorithm with figuring out if a move is good or bad, they mine data from the CVE database and use the scores from CVSS to generate reward values for the AI algorithm. Our VERCASM-CPS engine triggers CMTD based on cyber risk scores of CPS components in order to replace or reconfigure vulnerable components. Our CMTD switching scheme will also be modified by the cyber risk evaluation results. For example, more vulnerable CPS configurations would require more frequent configuration changes.
Markakis et al. [
18] proposed a system to protect healthcare networks from devices that are vulnerable to common cyber threats. The system continuously monitors devices that are connected to the network, and new devices before they can connect. Devices are assigned to different virtual LANs, where they have differing levels of access based on the safety score of the device. In contrast, our solution provides vulnerability analysis for each individual software and hardware component, as well as for the entire system. If the software is unsafe, our Controlled Moving Target Defense process will change the software to a different version or replace it with a different software. Our solution also hardens the system by changing its configuration, for example, IP addresses.
Markakis et al. [
19] discuss the use of an accelerated device in the network edge to increase computational power and storage of edge devices. Our solution relies on the information about software and hardware versions on each device being shared with the VERCASM-CPS engine. If VERCASM-CPS is implemented in an environment using computationally weak sensors and actuators, accelerators may be added between the CPS hardware and the VERCASM-CPS engine to provide the computational power needed to communicate this data, and to continue its normal tasks.
Toupas et al. [
20] proposed a deep learning model for an IDS. This approach can be integrated with our solution, which can spot vulnerable software and hardware components in the system. The most vulnerable components are more likely to be used by network intruders and be a root cause of an anomaly.
3. VERCASM-CPS Core Design
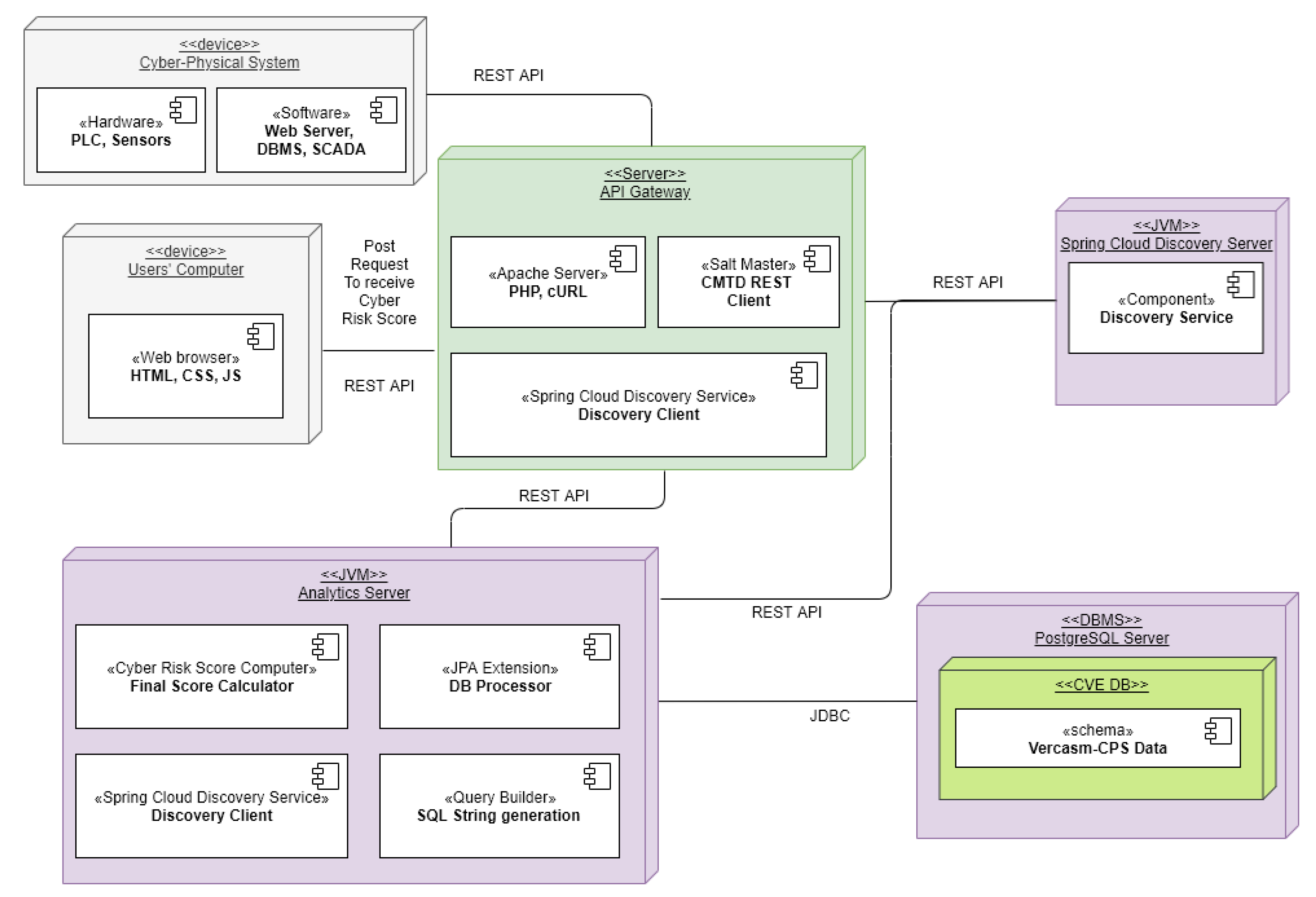
In designing our VERCASM-CPS solution, we used a microservice style architecture. This leverages the efficiency of resources and allows VERCASM-CPS to more broadly serve clients in CPS. Monoliths require an overcompensation of services, which are barely used, or parts of a system that do not need the resilience of more expensive hardware. With a microservice design, we fully support a REpresentational State Transfer (REST) implementation [
21]. As seen in
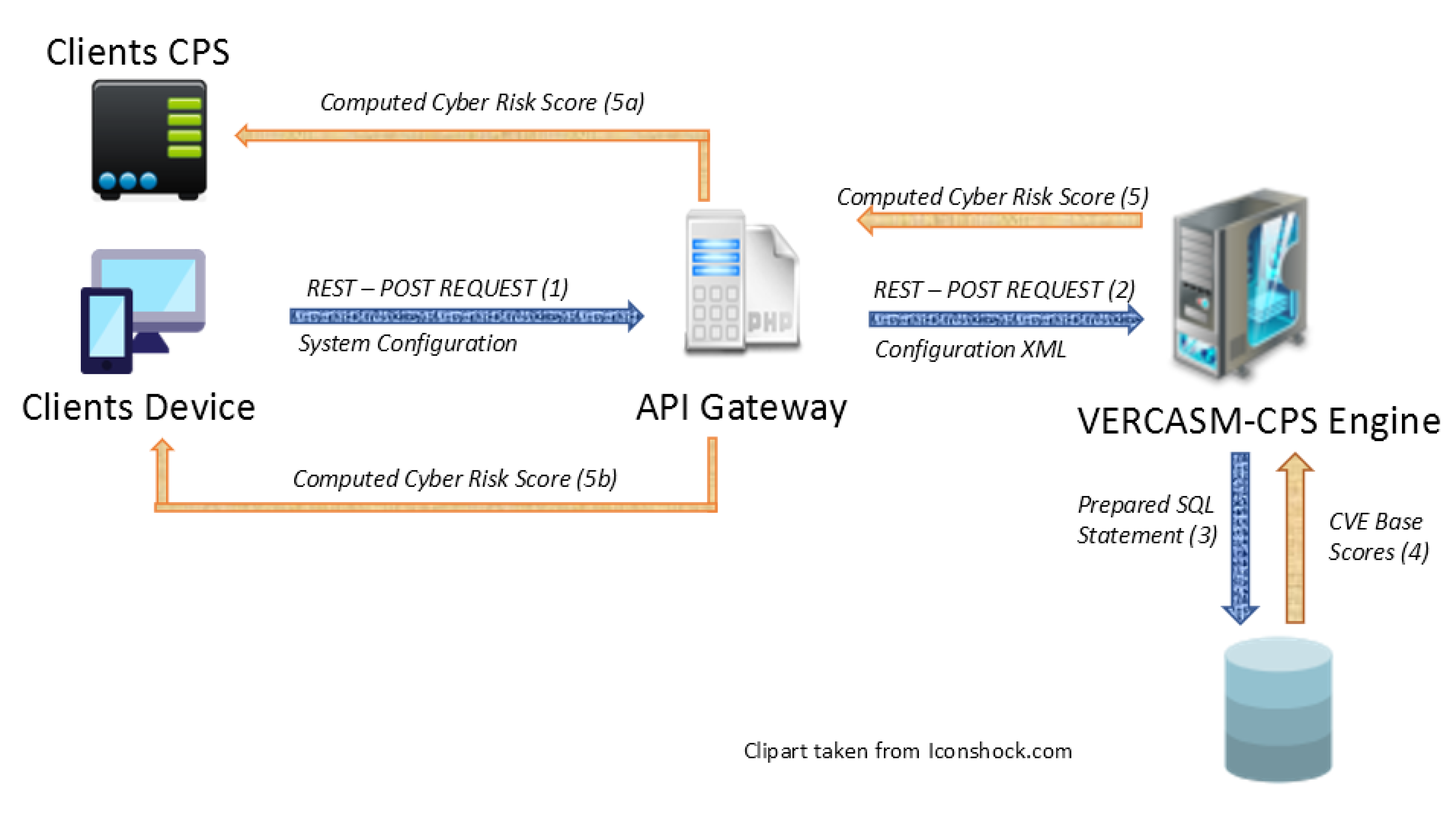
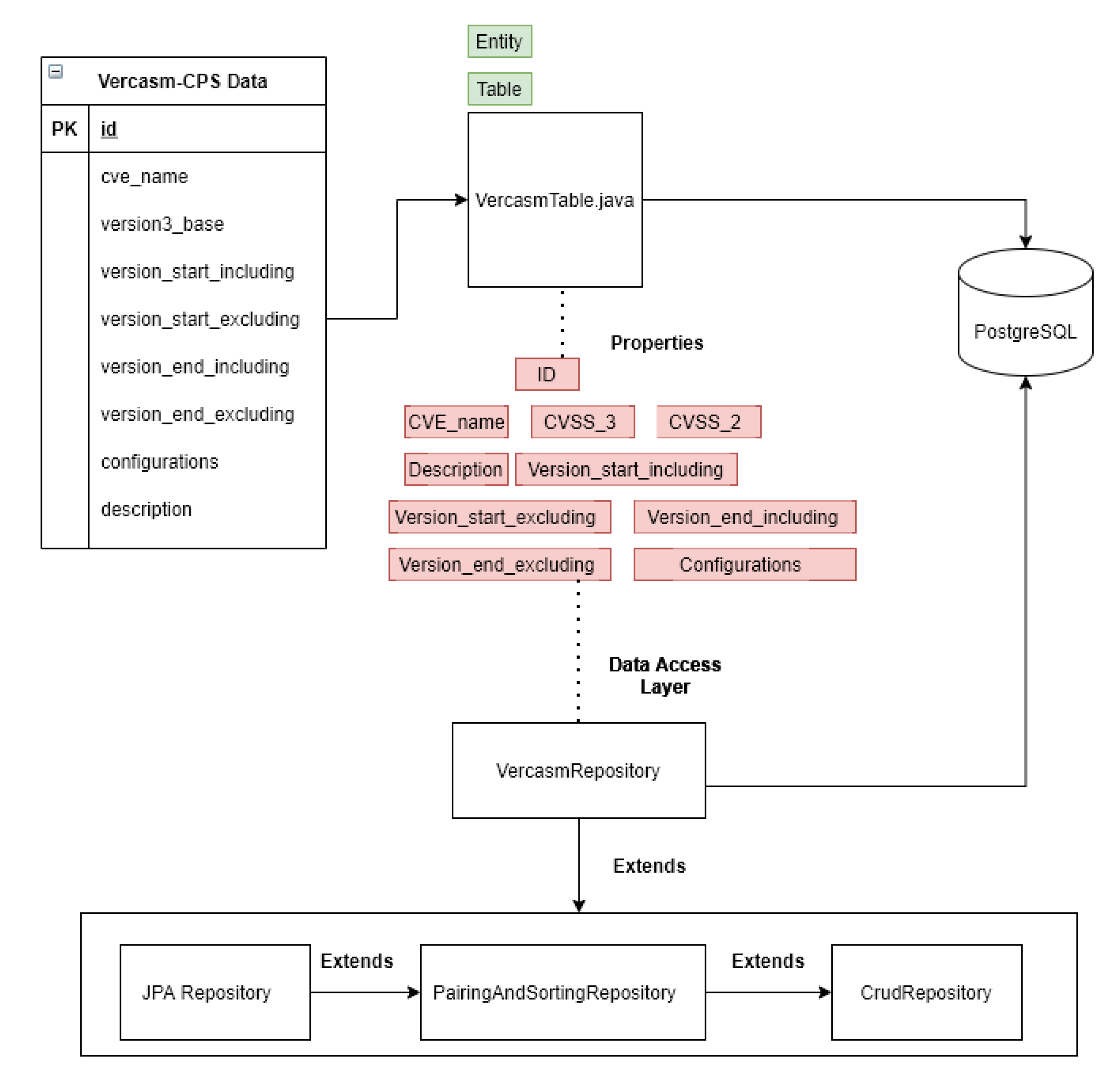
Figure 1, we have three main microservices: Application Programmable Interface (API) Gateway, Discovery Service, and an Analytics Service. Each have their own role defined in the system. Each microservice uses a RESTful process in which they communicate with each other. Each of the microservies besides the API gateway is using Spring Boot for Java Development Kit (JDK), version 11. Spring Boot allows VERCASM-CPS to easily adapt to our needs with use of dependency injections. A simpler representation of data flow can be seen in
Figure 2. We will explain below how each service works and why it is unique to a monolithic design and also how the data flow through our system.
3.5. Controlled Moving Target Defense
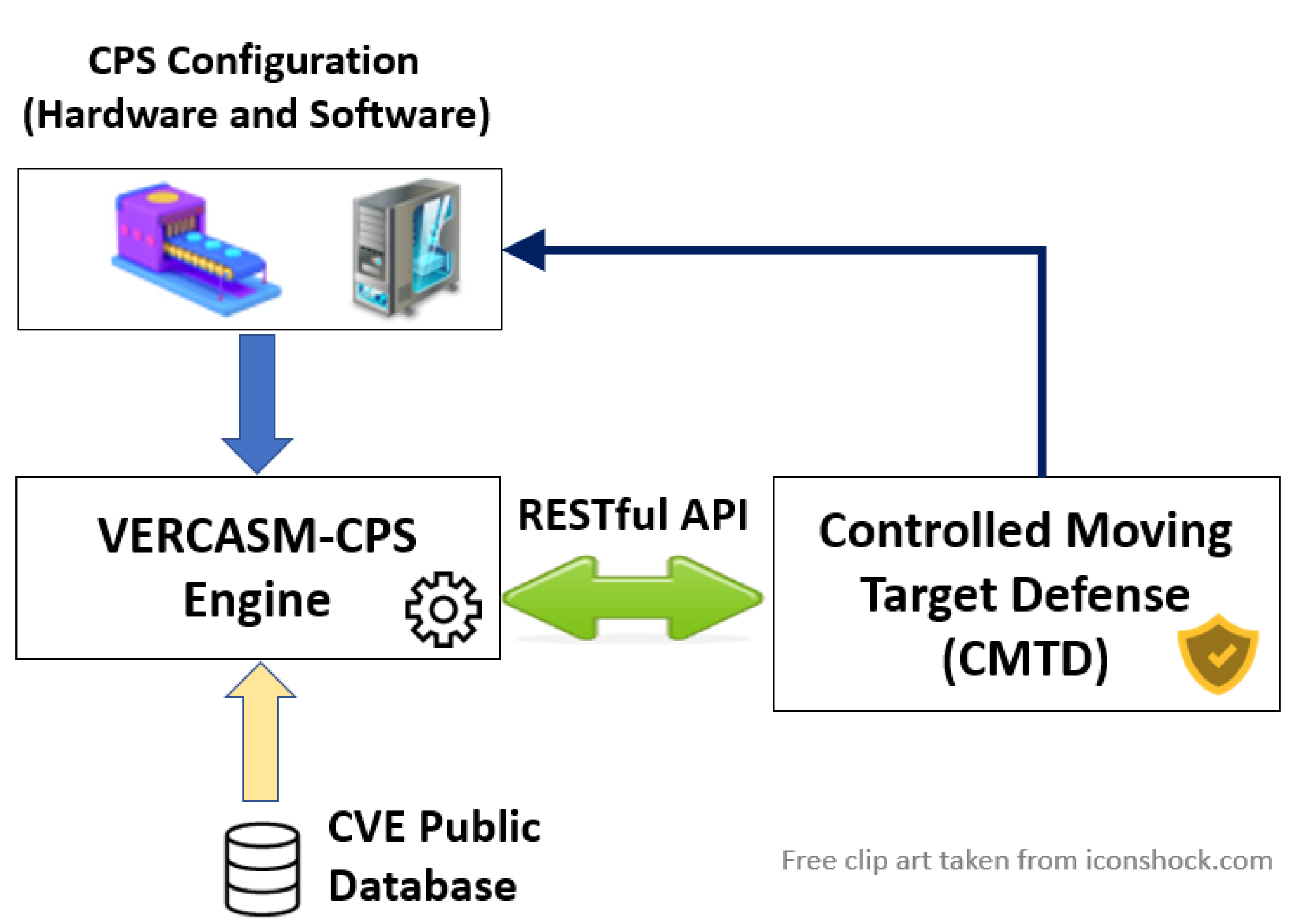
Once the cyber risk score has been evaluated and sent back to the user, if it is above a specified threshold set by system administrators, CPS operators, and engineers, our CMTD solution ensures that the software configuration of the CPS is always the most secure based on the known vulnerabilities gathered from the CVE database. It also hardens the CPS by changing IP addresses and port numbers of the devices in the CPS network. The software configuration changes are handled by the automation and infrastructure management software Salt [
30]. The network configuration changes are performed by scripts located on CPS devices that have enough computational power. Once a significantly large cyber risk score has been detected, Salt will be activated and the scripts on the device will be executed. These scripts are written in shell script. Salt can also change installed software components on the device. Thus, if for example, a web browser has a high cyber risk score determined by the VERCASM-CPS engine, Salt can uninstall that web browser and install a more secure replacement. The workflow of VERCASM-CPS can be seen in
Figure 4.
Salt can be run on any computer that can install the Salt software and connect to the local network. It is based on a master and minion system. This is where the minions know the IP address of the master, and the master can send instructions to the minions. Instructions can be sent to any number of minions at once, so it is possible to change the configurations of every device at once or individual devices. In order for Salt to work, the master and minion process must be running on the respective computers. The master process should be running on the same computer that detects CVE scores, so there is no network communication required to issue commands to the minions. It is important to note that a Salt master can also be a minion, so if the computer detects a high CVE score on itself, Salt can handle the configuration changes and make it more secure.
A Salt master can also check current hardware usage for several components of its minions. By using the status module, a Salt master can read information about the current usage of the CPU, memory, and storage of a minion. This is a useful tool that allows for remote monitoring of the minions, which may lead to the detection of malware that is running on the minion. Once anomalous behavior has been detected, the Salt master can use tools from the ‘ps’ Salt module to see the running processes of a minion and kill any that are suspect. It can also see the usage of each resource that a process is taking, for example how much memory or CPU usage a process is using, which can also help find any programs that are taxing on the performance of the machine, or have crashed and are consuming resources.
CMTD is a process that applies to both the CPS software and hardware. If we find that there is no safe configuration with Linux Ubuntu, we can go in and change the operating system to Microsoft® Windows® 10 with a more secure build. Once the operating system is changed, the Salt minion service will need to be installed and configured again, but once it is running, the Salt master can handle installing packages and software needed by the users.
Our framework can generate recommendations to replace vulnerable hardware in a manual mode. While the replacement is in progress, CMTD can reconfigure vulnerable hardware to make it more resilient against cyber attacks. Since we do not control the software itself, like in the EPSS model for developers, we use CMTD to move configurations around to not arrive at the same vulnerabilities. For example, CMTD can change the hardware network address. Examples of hardware vulnerabilities include the Meltdown and Spectre vulnerabilities that affect most modern CPUs, including those manufactured by AMD, Intel
® (Intel is a trademark of Intel Corporation or its subsidiaries [
31]), and ARM
TM (AMBA, Arm, Arm ServerReady, Arm SystemReady, Arm7, Arm7TDMI, Arm9, Arm11, … are trademarks or registered trademarks of Arm Limited (or its subsidiaries) in the US and/or elsewhere. The related technology may be protected by any or all of patents, copyrights, designs and trade secrets. All rights reserved [
32]).
To summarize, CMTD can be used to change the following things in the system:
4. Evaluation
In testing our core design of VERCASM-CPS, we developed a Cartesian product model where we tested for the mean, geometric mean, and the three classifications of a weighted average. The basis of a Cartesian product allows us an insight into the idea that the size of the categories need not be the same in order to analyze them and how many types of software and hardware configuration setups are possible. This is important to our work because, as previously mentioned, we want our users to be able to design their hardware and software configuration in advance by taking into consideration the most secure software and hardware options. The definition of a Cartesian product follows.
Definition 2. ((Cartesian Product) [
33]).
If A and B are sets, the Cartesian product of A and B is the set: . There is an important property of Cartesian products: “if A and B are finite sets, then
because there are
choices for the first component of each ordered pair and, for each of these,
choices for the second component of the ordered pair [
33].” Since the contents of the categories are finite in our case, we can apply this property to find the number of possible configurations when we examine different sizes of these categories. Thus, since we have six categories of four components being evaluated in our design, this implies
. If we add another two versions of software to any of the categories then it becomes
. This will also allow users to anticipate how many different ways they could possible configure their hardware and software system.
In our methodology, we followed a few assumptions: Windows® and Linux®.
Data Gathered from CVE, such as the CVSS is a trusted, reputable source.
We assume our base hardware and software, such as JVM is trusted.
Furthermore in methodology, we tested using two operating systems (OS) bases, Microsoft
® Each base then included two version each as shown in
Table 4. We then tested each OS for an inclusion of different software categories. These categories included are shown in
Table 5. Categories were chosen based on what an engineer may use on an example of an industrial control system. Each system was tested for all permutations of possible versions and vendors for each OS. For this example, it also aligns with a permutation with replacement model to the same outcome, for which there are four softwares in each category where each version, no matter the vendor, is independent of each other. There are six total categories including one for the operating system. We tested 4
6, 4096, permutations. The system was tested in a sequential format, where the the first permutation ran first up to the number of permutations. However, after choosing our classification, we also tested Linux Ubuntu, adding another 2048 iterations. Below is our system configuration for conducting tests with VERCASM-CPS including the RDBMS, which was hosted on the same computer.
In choosing the classification of weights, we ultimately chose classification
C, as seen in
Table 3. We tested all three classifications as seen in
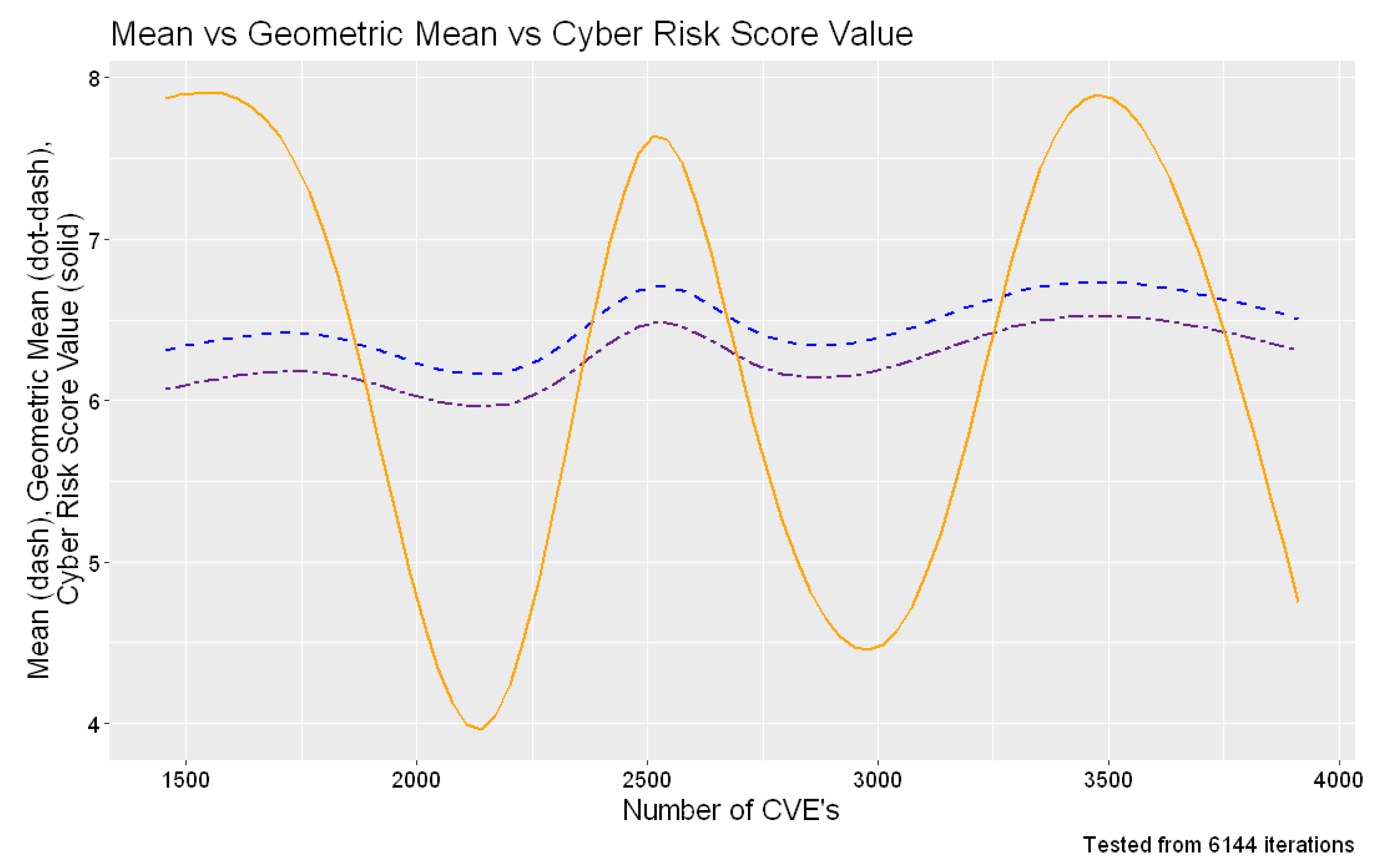
Figure 5. In this test, we used 4096 permutations of software. We also tested for mean and geometric mean as seen in
Figure 6. Our Cyber Risk Score is less conservative, and it better reflects the probability of a given cyber vulnerability to be exploited. Versus other products in this space, our solution works with a wide range of CVEs. We made an effort to ensure that higher CVSS scores are weighted as such. Even though a product may have more vulnerabilities, they all may be minor versus a hardware or software package with few CVSS scores but all above the critical range.
In one example shown in
Table 6, we found many instances where changing the OS or SCADA system to a previous version actually decreased the cyber risk score. In this example, all systems were tested for using Chrome
® 89, Tomcat
® 10.0, 7zip
® 20, for a Web browser, Web Server, and Archiver respectively, the only category which changed was the SCADA version of Webaccess/SCADA between versions 8.3 and 9.0 [
26,
35,
36,
37,
38]. This example shows the benefit of our system of engineer’s trying to find the most secure operating system and SCADA system possible. In some environments, Windows
® is preferred by the user. In this example, an older build of Microsoft
® Windows
®: 2004, would be more secure with the newest version of the SCADA. However, if an engineer needed to use an older version of SCADA, it is recommended to use the new version of Windows
® 20H2. However, if Red Hat
® Enterprise Linux
® could be used, it is applicable to use whatever version SCADA of the two which gave the most benefit, being a clear winner in terms of having a lower cyber risk score. With the inclusion of Ubuntu in testing, we found that it had the highest cyber risk score. The stereotypical notion that Linux
® is more secure is disproved from Ubuntu’s scoring. Just because it is Linux does not automatically make it less vulnerable. The more factors examined, in this case the type of software it is running, the better a result an engineer would receive.
4.2. Controlled Moving Target Defense
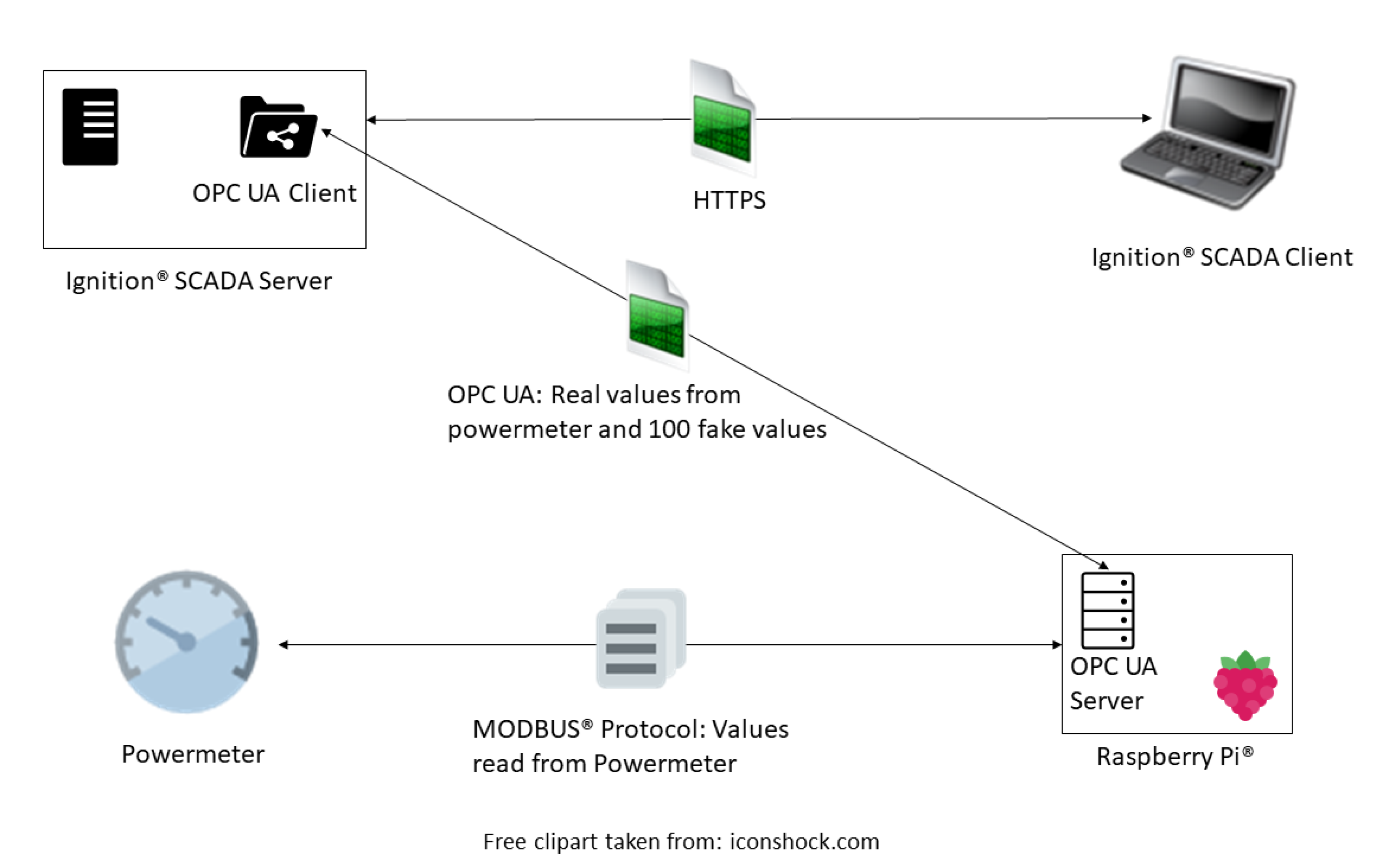
To test the speed of our CMTD mechanism, we created a test bed that includes a powermeter from “Schneider Electric”
®, Raspberry Pi, and a laptop running the “Ignition”
® SCADA system. The version of “Ignition”
® we chose is called the “Maker Edition” [
24]. It is a version of “Ignition”
® that is licensed for educational or personal use only. Our Raspberry Pi model is the Raspberry Pi 3 Model B. The overall flow of data can be seen in
Figure 9. The powermeter reads information about devices connected to it, such as voltage and current, then sends those to the Raspberry Pi via the MODBUS
® protocol. The Raspberry Pi reads these values with an OPC UA server that is written in the Python programming language using the FreeOpcUa library [
39]. These values are then converted to OPC UA tags and are sent to the OPC UA client built into “Ignition”
®. A SCADA client can be connected to “Ignition”
® via a web browser on any device. Operating screens can be configured to see these values in a convenient way for the users.
The connection between the OPC UA server running on a device and the OPC UA client running in “Ignition”
® is secured by the Basic256Sha256 security policy [
40] created by the OPC Foundation. The security mode used for the policy is “Sign and Encrypt”. This mode provides data confidentiality and integrity for the communication channel. Confidentiality is provided by encrypting the data with the AES256-CBC algorithm. Integrity is provided because the sender signs the data with their private key, which is generated from the HMAC-SHA2-256 algorithm.
For added security, between the OPC UA server running on the Raspberry Pi and the OPC UA client running in “Ignition”®, we generate noise in the form of randomly generated OPC UA tags. The values that can be assigned to the tags follow a discrete uniform distribution. They can be configured to be in any range that the user wants to set, so any value within that range will have equal probability to be used for the fake tags. These fake tags are sent to the “Ignition”® SCADA system through the same channel as the tags that hold the real values read from the power meter. In order to not confuse the operators of the SCADA system, the fake values are not visualized on the screen of the SCADA client. However, since the OPC UA client on “Ignition”® is still receiving the tags through the communication channel from the OPC UA server, if any attackers are theoretically able to break the encryption and see the data in plaintext, they will see both the real and fake tags, and must determine which are the real tags representing data from the power meter.
The key component of this CMTD procedure is changing the IP address of the Raspberry Pi. The scripts that change the network adapter properties of the Pi are Bash [
41] shell scripts. The scripts use Linux commands to change the IP address of the device they are located on by changing the IP of the network interface. Once the IP of the network interface has been changed, the script stops the running OPC UA server and starts a different one that is configured to run on the new IP address. The new OPC UA server is also configured to run on a different port than the previous one. Our CPS test bed includes a computer that is running the “Ignition”
® Supervisory Control And Data Acquisition (SCADA) server. “Ignition”
® has a connection preconfigured for both of the OPC UA servers, so whenever the new server starts, the connection is automatically established and data from the sensors can be transferred again. The number of scripts and OPC UA servers on the device depends on how many different IP addresses the system administrators want to switch to. Below is the description of the system configuration where the experiment was conducted:
SBC: Raspbery Pi 3
® (Raspberry Pi is a trademark of the Raspberry Pi Foundation [
42]) Model B
CPU: Quad Core 1.2 GHz Broadcom® BCM2837; RAM 1 GB DDR3
OS: Raspberry Pi OS®; Kernel 5.10 64 Bit
SCADA: Ignition Maker EditionTM version 8.1.1; Ignition DesignerTM version 1.1.1
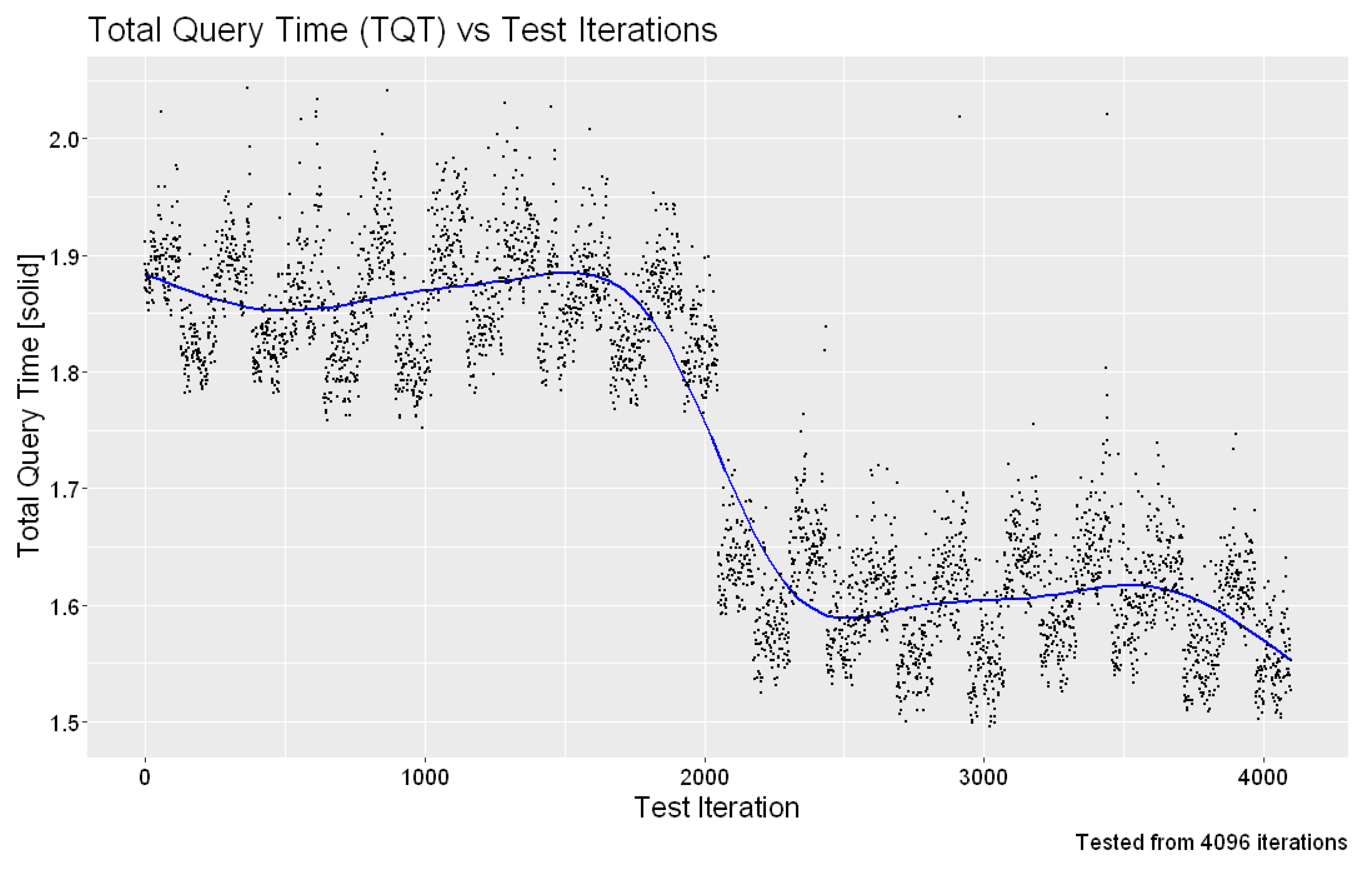
The evaluation of this test bed measures the time it takes from starting the CMTD process to when it finishes. The process stops the running OPC UA server on the Raspberry Pi, changes the IP address of the Raspberry Pi, then starts a new OPC UA server. The measurements start when the running OPC UA server is stopped, and end when the “Ignition”
® SCADA server connects to the new OPC UA server. There were 202 measurements taken from this experiment, and the results can be found in
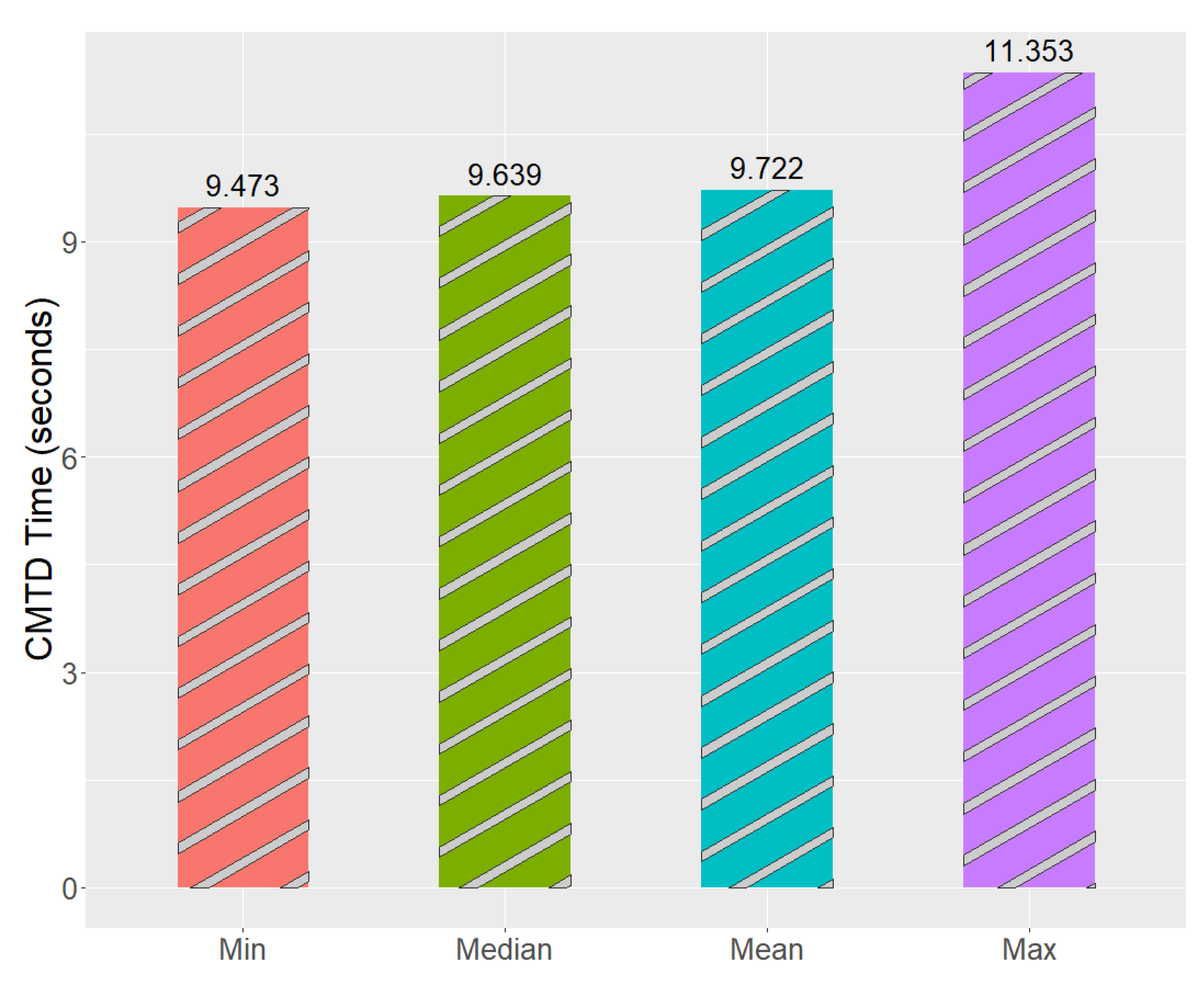
Figure 10. We found that the maximum time for “Ignition”
® to connect to the new OPC UA server was 11.353 s, the mean was 9.722 s, and the minimum was 9.473 s. A lot of this time can be contributed to the OPC UA server starting, then “Ignition”
® polling for the new connection.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}