1. Introduction
The depth of penetration of social networks into everyday life is significant, and their advantage is the ability of communication participants to quickly express their opinions to a large group of people. Today, social networks (SN) are not only the means of communication, but also a tool for spreading information. The processes and conflicts in social networks are a reflection of the activity of various actors, whether they are individual, institutional, or group. At the same time, we observe the opposite trend, when conflicts and processes in the information field can generate events and conflicts that change society as a whole, as well as have a direct impact on the social activity of people, their hobbies, and life path. The processes that generate changes in the state of the individual and society occur, as a rule, in a hidden (latent) form, and we find the result of influence, for example, on the child’s consciousness, only at the moment of its culmination, when the process or conflict affect the life and health of the family or individual. An obvious common problem of information security in modern society has become malicious (or destructive, or false) information, which can include such concepts as cyberbullying, slander, and deliberately false information.
In the process of countering the spread of malicious information in the social network, the operator needs to somehow prioritize the selection of observed objects and measures to counter them. Most of the existing monitoring systems focus on three functions: (1) detection of emotions or opinions; (2) modeling of information flows; (3) modeling of opinion networks based on agents [
1,
2]. The existing monitoring systems are based on complexes of algorithms that include sorting in descending order (the number of views, the number of “like” marks, etc.), and among other things, the analysis of relationship graphs or bioinspired approaches are used. For example, the paper [
3] presented an approach to the systematization of research directions in the field of social network analysis. In particular, it was argued that the task of detecting a source in a social network is to find a person or node from which such entities as a virus or disinformation originated. A taxonomy was also proposed, which contains various aspects (factors): network structure; distribution models; centrality measures; evaluation metrics. In [
4], the problem of estimating the source of infection for the Susceptible–Infected model (SI), in which not all nodes are infected, was solved. It was shown in [
4] that for social networks whose structure is more similar to a tree (Twitter, YouTube), the estimate of the source node associated with the most likely path of infection is set by the Jordan center, that is the node with the minimum distance to the set of observed infected nodes. The paper [
5] considered the model of information dissemination as Susceptible–Infected–Susceptible (SIS), according to which any node in a social network can be infected with some information in the process of its dissemination, and then, it transmits it to its neighbors; however, this node remains susceptible to similar information from its neighbors. In [
6], an approach based on a visual analysis of information distribution channels was proposed. This approach, by displaying the main participants in the creation and retransmission of information, allows specialists to independently draw conclusions without the need to analyze a huge amount of text data.
However, still, the existing systems, methods, and algorithms do not distinguish a group of information objects, taking into account the level of feedback from the audience. For malicious information, a delay in taking counteraction measures can be dangerous. If the counteraction to malicious messages and the sources that create and distribute them is carried out without taking into account the audience coverage and engagement metrics, then there is a high probability that in the most dangerous cases, counteraction will not be provided first.
This paper shows how an integral metric can be set that allows one to distribute the operator’s attention in monitoring systems and prioritize sources that distribute destructive content in social networks. At the same time, in the process of developing an approach to ranking information sources in social networks, the basis for analysis is discrete features, such as the number of source messages, the number of comments, and the number of “like” and “dislike” marks from the audience of social networks.
The novelty of the proposed approach is that the developed model of malicious information and a set of algorithms for analyzing and evaluating information sources provide a ranking of sources by priority, considering the number of messages containing destructive content that is created by the source and feedbacks from the audience, without taking into account the connection among objects in the social network. It can significantly reduce resource and time costs in the analysis process.
It is important to note that the aim of the proposed approach was to prioritize the malicious messages according to their importance according to the impact on the audience. The content analysis and the very recognition of the presence of the malicious content were out of the scope of this investigation. It was assumed that all the messages in the input dataset for the approach had a similar amount of malicious information. The difference between messages lied only in their audience and in the activity of this audience.
The paper is structured as follows. The second section presents an analysis of relevant studies. The third section describes the proposed approach, represented by the developed model of malicious information and a set of algorithms for ranking information sources in social networks. The fourth section presents the results of the experiments and shows the applicability of the proposed approach. The fourth section also contains an assessment of the approach and a discussion. The fifth section concludes the paper. The dataset for conducting the research and experiments was obtained from the Russian social network VK by connecting to an open API and preprocessed (depersonalized) for the possibility of open use for scientific purposes.
2. Background
The first studies on countering the spread of destructive content were conducted by scientists following the initial development of social networks, from 1995–2000. Fifteen works referring to the resource were published in the Google Academy [
7] Class-mates.com and twenty-eight in SixDegrees.com. With the advent of new platforms, the number of studies in the field of social network analysis is growing exponentially. In 1990, Social Network Analysis (SNA) was the prerogative of such sciences as sociology and political science. For example, the collection of works [
8] contains papers devoted to the analysis of human behavior in society. In [
9], the interpenetration of the theory of exchange and the science of “social network analysis” was discussed. After 15 years, by 2005, the situation began to change dramatically, and by 2021, SNA became a process of studying various social structures [
10]. At the same time, the object of research in SNA is network structures from the point of view of nodes (individual actors, people or things in the network), as well as edges or connections, relationships, or interactions. Many studies are devoted to the analysis of the spread of memes [
11], information exchange [
12], and communication networks among friends, colleagues, and clients [
13]. Some of the works are devoted to the problems of media communications, journalism in social networks, or education through social networks. Thus, the modern section of SNA contains a massive theoretical and practical base of studies relevant to the topic of this study. Bioinspired approaches are also actively developing within the framework of SNA.
In the work presented in paper [
14], the Suspicious–Infected–Removed (SIR) model was considered. It proposed a taxonomy for classifying information content to solve this problem at the stages of origin, distribution, detection, and localization. The study [
15] demonstrated the mechanism of spreading moods on web forums. For this purpose, the possibility of applying the SIR epidemic model to the spread of moods was investigated.
In [
16], a model of group polarization integrated into the SIRS epidemic model was proposed as part of research aimed at studying the evolutionary mechanism and processes of divergences in the opinions of participants in the discussions. At the beginning, an epidemic model was introduced, and the factors of relationship strength were determined to strengthen the transfer of information and interaction among individuals, based on the J-A model proposed by Jager and Amblard [
17]. In addition, the work used the Barabashi–Albert model [
18] for the formation of random scale-free networks.
The work presented in paper [
19] offered a comprehensive approach to monitoring and countering harmful influences in the information space of social networks. The paper considered different approaches—both on the basis of text and graph analysis.
The paper [
20] described a fairly large number of metrics for analyzing social networks, which were divided into several classes: (1) activity; (2) popularity; (3) measures of influence. Algorithms to obtain a numerical coefficient of Social Networking Potential (SNP) to represent the source network and its ability to influence this network were proposed. Such a source was called by the authors of the work as Alpha. It is the SNP algorithms that today allow monitoring systems to evaluate opinion leaders.
The problem is that all existing solutions consider the source from the point of view of the linear Shannon model [
21], according to which the source is either the author, the primary source of information, or the creator of the message. Communication in the transmission/cybernetic tradition is considered as an information processing process. However, in order to find the place and role of the problem of ranking the sources of the distribution of malicious information in social networks, it is necessary to find out what a source is in the context of information exchange in social networks and how information exchange occurs and, with this in mind, to choose a priority object in the process of analyzing a variety of sources of spreading malicious information in social networks. Therefore, it is not necessary to limit ourselves only to technical algorithms to analyze social networks, at the beginning, and it is worth studying achievements in the field of communication theory, political science, and sociology. In the Oxford Dictionary, the theory of communication is interpreted as follows: “It is the study and presentation of the principles and methods by which information is transmitted” [
22].
Most models of communication theory divide sources into primary sources (author of the message or the message itself, as an information object) and secondary sources as media. For example, Theodore Newcomb’s A-B-X model [
23] is more related to such sciences as sociology, journalism, linguistics, and the psychology of communication. The model considers the relations among the participants of the communications and the object under discussion, describing the influence of these relations on the nature and result of the communicative interaction. The proposed approach allows one to expand the range of features for algorithms for analyzing and evaluating the sources of malicious information distribution in social networks through mechanisms to analyze the feedback from the audience. For example, in [
24], a model for detecting sources and messages in SNs was proposed, and one of the strategies was based on the A-B-X model of T. Newcomb. In [
25], a study was conducted on how students choose friends in social networks.
Theodore Newcomb’s A-B-X model answers a number of questions: (1) What motivates the subjects to enter into communication? (2) How do the relations among the subjects affect communication? (3) What will be the possible psychological and sociological effects for the participants of the communication?
As a basic model, Newcomb considered the situation of elementary communicative interaction, that is a dialogue in which subjects “A” and “B” enter into communication about some object external to them “X”. At the same time, “X” is an individual, an event, a message, any information, or any community. Then, any social subjects can also act as A and B—these being individuals, social groups, or social organizations. According to T. Newcomb, A and X are united by a certain topic, called “orientation”. Orientation can be described in the form of positive (+) or negative (−) attitudes. The concept of attitude in psychology and sociology is associated with social attitudes, and they are understood as sets of beliefs and interests of the subject. In this study, the orientation can be expressed through a positive or negative attitude toward the topic by a user of social networks. This model allows one to segment sources and recipients into those who are in solidarity and support topic X related to information and those who condemn topic X.
It is important that according to the A-B-X model, at any given time, the orientation in communication can be symmetric and asymmetric. The issues of the symmetry and asymmetry of communication and its effects are actively developed within the framework of research aimed at studying the behavior of users of social networks [
26].
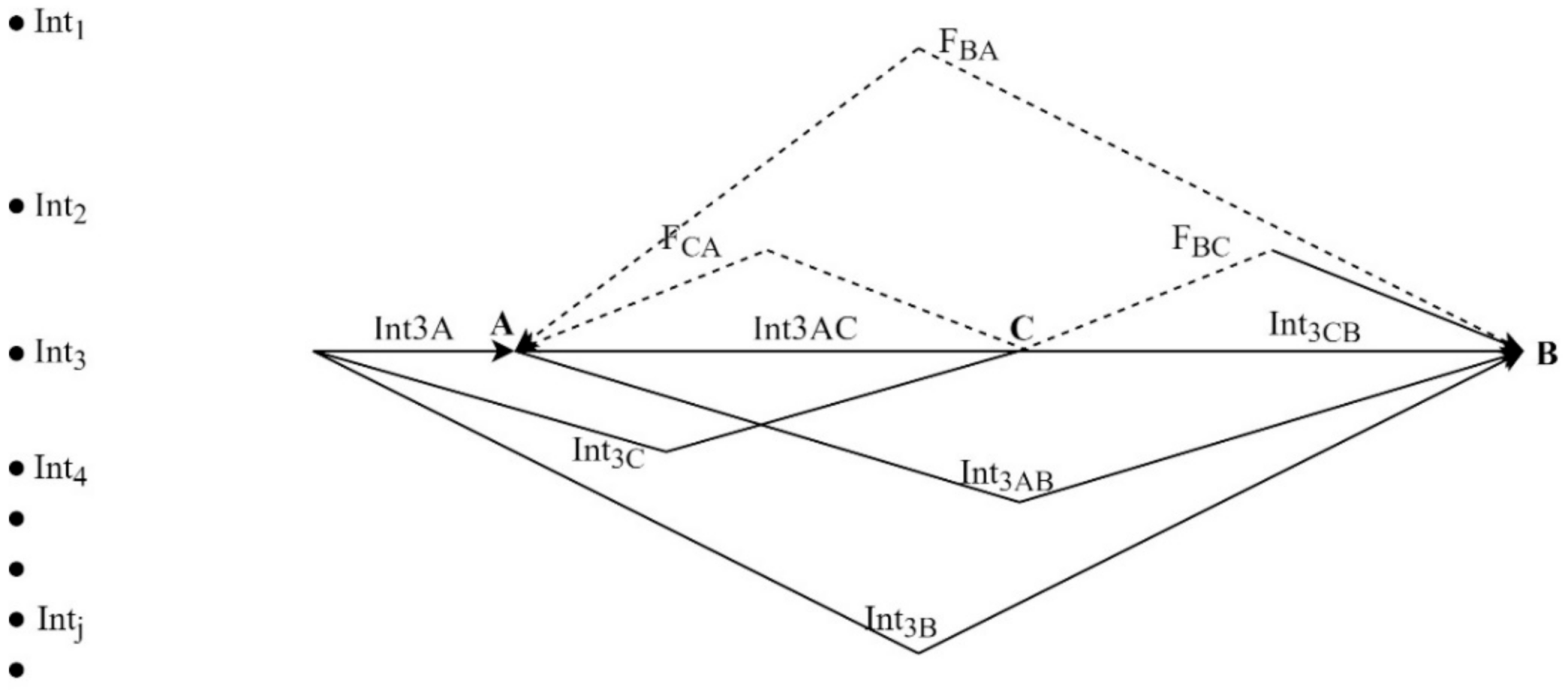
Researchers B. Westley and M. McLean [
23] added an element to the A-B-X model that allows taking into account the subject’s need for information, provided that different sources are available (
Figure 1). In today’s conditions, this is the set of sources that is available to the user to obtain information, that is websites, social networks, news aggregators, video hosting services, and more.
According to the proposed model, subjects form their information space in order to meet needs or solve problems. It is obvious that the range of interests of the subject is limited by the set Int1, Int2, …, Intn.
Communication is initiated when a certain subject B realizes the interest or the need to obtain information from the information space. In the Westley–Maclean model, the information space around the subject is called the space of elections Int1, Int2, …, Intn.
Suppose Int3 interest is chosen for the choice of the attitude, then depending on the methods of obtaining information, the subject can realize his (her) need through different sources in the modern digital space.
In the simplest example, the subject has the opportunity to simply obtain information through direct interaction with an event or text (Int
3B arc), but when using modern web resources, video hosting, and social networks, there is always an access point to information—“A”. Perhaps the source “A” directly observed or created an object with information on the topic of interest to the subject, Int
3, then it forms an attitude for “B”, and the Int
3AB arc appears. Another option characteristic of social networks is the presence of a translator or repeater, which is any subject who has repeated information from source “A” about Int
3 information. The authors of the model called it an “information intermediary”, or “information gatekeeper”. In fact, this subject is “media” (between). In the work presented in paper [
27], a strategy for ranking information sources by user interests was proposed. Thus, the work took into account the range of interests of the user.
Unlike the A-B-X models of Theodore Newcomb, B. Westley and M. McLean considered the presence of feedback in their model. To do this, they divided communication into direct and indirect (feedback). In
Figure 1, these are the arcs “B” to “A” (arc “FBA”), from “B” to “C” (arc “FBC”), and from “C” to “A” (arc “FCA”). In social networks, comments, responses to comments, “like”, “dislike”, subscriptions, and other actions of participants in the information exchange serve as an example of reverse communication. Therefore, it is possible to evaluate the source as media by the level of feedback from its audience in the SN.
Despite the fact that there are papers that took into account feedback from the user, for example the paper [
28] raised a very important question: the challenges of IoT and social relationships via devices, the following main problems were considered in the paper: (1) social Big Data; (2) social feature processing; (3) social context awareness; (4) social data privacy. The basis for the occurrence of challenges is feedback at any level from the user. In their other work, the same authors suggested the user interest detection paradigm (IoP) [
29]. However, such works are not aimed at detecting a popular source of malicious information.
Based on the analysis, it can be concluded that, despite the many existing approaches and solutions, most of them were developed within the framework of separate scientific schools, either in the technical sciences, or in the framework of research in sociology, political science, and communication theory. A paradigm shift is needed to expand the space of features that characterize the source of the distribution of destructive content. As part of the proposed approach, the authors propose to take into account not only such features as the number of messages from a source in a social network, but also to add an analysis of feedback from the message audience. This will allow one to rank objects by priority, highlighting those that attract the attention of the audience. Then, it will be possible to direct the resources and attention of the expert to priority objects. The same approach will reduce the cost of analyzing relationship graphs, which are an integral part of bioinspired algorithms and existing solutions.
3. An Approach to Ranking the Sources of Information Dissemination
The proposed approach to ranking the sources of information dissemination in social networks is based on the idea that every information object in a social network, whether it is the message itself or the page, on which it is published, has an audience. At the same time, all social networks are built in such a way that we see the number of views, like or dislike marks, and the number of comments. Consequently, both for a single message and for the page on which it is published (the source), such a set of features can be formed that will allow ranking messages, and on the basis of this, the sources can be ranked. It is also important to mention that in the proposed approach, we considered the source as a primary or secondary source, where the message is published. It is not the author; it is primarily a page in the social network.
Ranking sources by priority ensures that the operator’s attention is distributed from the most active and popular sources among the audience to the least noticeable. Furthermore, according to Hootsuite, in 2020, only the social network Facebook had 2.74 billion monthly active users per month [
30]. Even if only 0.001 of these users post a message with destructive content, there will be 1,000,000 of them per month. The approach of ranking the sources of information dissemination in social networks ensures the distribution of the operator’s attention.
The approach itself includes a model and three algorithms. The model describes information objects, relationships among them, and features. Thus, the model allows one to form requirements for algorithms for analyzing and evaluating sources. A complex of three algorithms receives information about messages, sources, and activity metrics as the input. The first algorithm in the complex provides the ranking of sources by the number of messages published by them. The second algorithm calculates a set of indexes for each message and then for the source (audience activity, coverage, and an integral indicator: the influence of the source on its audience). The third algorithm ranks the sources and sorts them by priority, considering all the indicators obtained earlier.
The approach is divided into three algorithms, since the first and second algorithms provide analysis and evaluation of sources and can be used outside the approach in the process of selecting an object to choose a counteraction measure. However, together, all three algorithms allow one to rank sources considering various parameters.
3.2. Malicious Information Model
The basis for the formation of the concept of malicious information is two terms: (1) information (); (2) information object (). Formally, both of these terms are related to each other, in such a way that , i.e., an information object is an element of the set of all the analyzed information.
Furthermore, in the process of developing a model of malicious information, the authors proceeded from the fact that:
“Dissemination of information” is all actions aimed at obtaining information by an indefinite circle of persons or transmitting information to an indefinite circle of persons;
“Source” is a page in a social network on which information is published that is accessible to an indefinite circle of people;
A “message” is an information object containing a text created and published in the process of information exchange on a social network.
Let us assume that is a malicious information object that contains signs that allow one to decide that information harms society, individuals, the state, or business.
At the same time, the sign (
) of the information threat (
) is set by an expert (operator) depending on the conditions. Let us consider an example of the information and feature table formed by an expert (in
Table 1).
Therefore, the set-theoretic model of malicious information in a social network includes such basic elements as:
IO—the information object;
T—the information threat;
MIO—the malicious information object;
Token—a sign of an information threat contained in a malicious information object;
Feature—discrete attribute of an information object.
The set-theoretic model is formally presented as follows:
where
—a discrete set of information objects,
single information object,
—a discrete set of all possible signs of an information threat,
—one sign of an information threat,
—a discrete set of malicious information objects,
—a separate class of malicious information, a
—a discrete set of features that characterize
.
Thus, to analyze and evaluate the sources of malicious information in social networks, it is necessary to define a discrete set of signs characteristic of the information threat. A distinctive feature of the proposed model is that according to it, the presence features in a set is allowed, such as the date of creation of an information object, feedback from the audience, the frequency of the feature, etc.
3.3. Algorithms for Ranking the Sources of Information Distribution
3.3.1. Algorithm for Ranking Sources by Potential
Let us assume that the collection of messages in the can be divided using that belong to different numbers of messages from the . At the same time, each message is located at a certain depth level of the “message tree” on the source wall. If it is a post, it is the “root of the tree”. If this is a comment to a post, then the message is located on the second level of the tree, the response to the comment occupies the third level. A numerical coefficient is assigned to the each message according to the following: (1) the post coefficient is “1”; (2) the comment coefficient is “0.5”; (3) all additional responses to the comment are assigned a coefficient equal to “0.25”.
Depending on the number of messages on the wall, the sources can be grouped by their potentials, as follows:
The source potential is low
, when it corresponds to Inequality (6):
where
—the sum of the numerical coefficients of all messages on the source wall,
—the amount of messages belonging to the source, and
—the arithmetic mean in the dataset for all sources in
;
The source potential is the medium
, when the inequality is observed (7):
where
—the sum of the numerical coefficients of high-potential messages (message potential greater than
) on the source wall,
—the amount of such messages, and
—the arithmetic mean in the dataset obtained after separating the sources with low potential
. from the original
;
The source potential is high
, if Inequality (8) is kept:
where
—the arithmetic mean in the dataset obtained after separating the sources with low potential
. from the original
(see Formula (7)).
Thus, all sources in the dataset, depending on the number and depth of messages on the source wall, can be ranked by the potential (
Table 2):
Let us consider the algorithm for ranking sources by potential:
A set of tuples is fed to the input to the algorithm to rank sources by potential. Next, the data are processed in steps:
Step 1. Assigning a numerical coefficient to each message in the set depending on the attribute and summing the numerical coefficients of all messages for each source. The output is formed by the tuple ;
Step 2. Calculation of the first arithmetic mean by the number of messages belonging to the sources. For sources with a value less than the first arithmetic mean, a low potential indicator is assigned equal to 1. Sources with low potential are separated, and a new tuple is formed;
Step 3. Calculation of the second arithmetic mean by the number of source messages. For sources with a value less than or equal to the second arithmetic mean, a potential indicator equal to 2 is assigned. For sources with a value greater than the second arithmetic mean, the potential indicator is 3.
At the output of the algorithm for ranking sources by potential, the tuple .
The algorithm for ranking sources by potential, unlike existing ones, considers the number of published messages and the depth of their location on a page in a social network when ranking sources.
3.3.2. The Algorithm for Evaluating Sources
Let the set of include all the features of feedback from the audience of malicious information on a social network, while is the number of “like” marks, is the number of “repost”, is the number of views, and is the number of comments.
The set includes the source ID and the address of messages in the social network.
In accordance with the requirements, it is necessary to find a tuple of attributes that characterize the through the elements of the and the relation where is the index of activity, is the index of viewability, and is the index of influence of the source.
The activity index can be set via the objective Function (9):
where
—activity of the source’ audience and
—source activity index. The value of the activity index is between 0 and 2, and at the same time, normalization is applied to the values of the indices (
); the normalization method is a comparative normalization, in which the maximum is selected for the ideal value.
The index of viewability can be set by Function (10):
where
—source visibility and
—the index of the viewability of the source, the value of which is normalized.
The index of the influence of the source can be set by the objective Function (11):
where
—the influence of the source and
—the index of the influence of the source to which the comparative normalization is applied.
All indexes mentioned above (index_active, index_viewability, and index_impact) can have values of “0”, “1”, and “2” for different messages. These values reflect the importance of the message in each aspect (auditory activity, viewing ability of the message—size of the auditory and possible impact of the message), where “2” is the maximal importance and “0” is the minimal importance.
The algorithm for evaluating sources, unlike analogues, considers the quantitative characteristics of feedback from the audience of malicious information in the process of information exchange and converts them into qualitative (indexes).
3.3.3. Algorithm for Ranking Sources by Priority
The algorithm for ranking sources by priority is related to the algorithms for ranking sources by potential and evaluating sources in such a way that it receives output data from these algorithms at the input and sorts sources by priority at the output. This allows us to rank sources taking into account the fact that the input is based on 2 axes (i.e., the priority of the source and the potential of the source). Besides reducing them to an integral indicator, this makes it possible to perform ranking to support the operator’s decision-making. An assessment of the effectiveness of this approach to support decision-making is given in
Section 4.3.
Formally, the objective function of prioritizing sources can be given by Formula (12):
where
—source,
—source priority,
—potential, and
—influence index.
The algorithm for ranking sources by priority is based on a method with the step-by-step consideration of criteria such as the index of influence and potential. The procedure consists of alternately rejecting the worst-case variants for each of the normalized criteria, pre-ordered by degree of importance in a priority series, starting from the first. The worst options are determined by the minimum values of the corresponding criteria (the index of influence and potential) and close to the minimum.
According to the algorithm for ranking sources by priority, the rules for choosing a priority source for distributing information are as follows:
where is a set of sources of information diffusion ranked by priority, is the source priority, and symbol is read as equal (if the ranks for the influence index and for the source potential are equal to the maximum/minimum) or it is read as approximately equal (then, the rank of one of the criteria may not be the maximum/minimum).
A set of tuples is passed to the input of the sorting algorithm for the objects of influence, where —the address of the message in SN, —ID of the message source, —source potential, and —influence index.
The algorithm is based on sorting with binary search, for which the arithmetic mean value of the index of influence of all sources in the array is calculated at the first step. Next, the objects with high and low priority are selected. A set of tuples is created separately with a priority index .
At the output, two lists and a set of tuples are formed: (1) list —targets where the objects of observation are , having the highest priority and the highest potential; (2) list —targets where the objects of observation are , having a low priority (perhaps, the operator should not pay attention to these objects); such information objects have the lowest potential and influence index; (3) list —a set of tuples that is passed to experts for additional evaluation; for such sources, the influence index can either be maximum, but the source potential is average, or vice versa.
Thus, the model and algorithms provide the ranking of sources of information dissemination in social networks by priority, depending on the feedback from the audience on messages containing destructive content and depending on the number of such messages belonging to one source.








{kind=link}
{kind=link}