
Text Mining and Sentiment Analysis of Newspaper Headlines




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
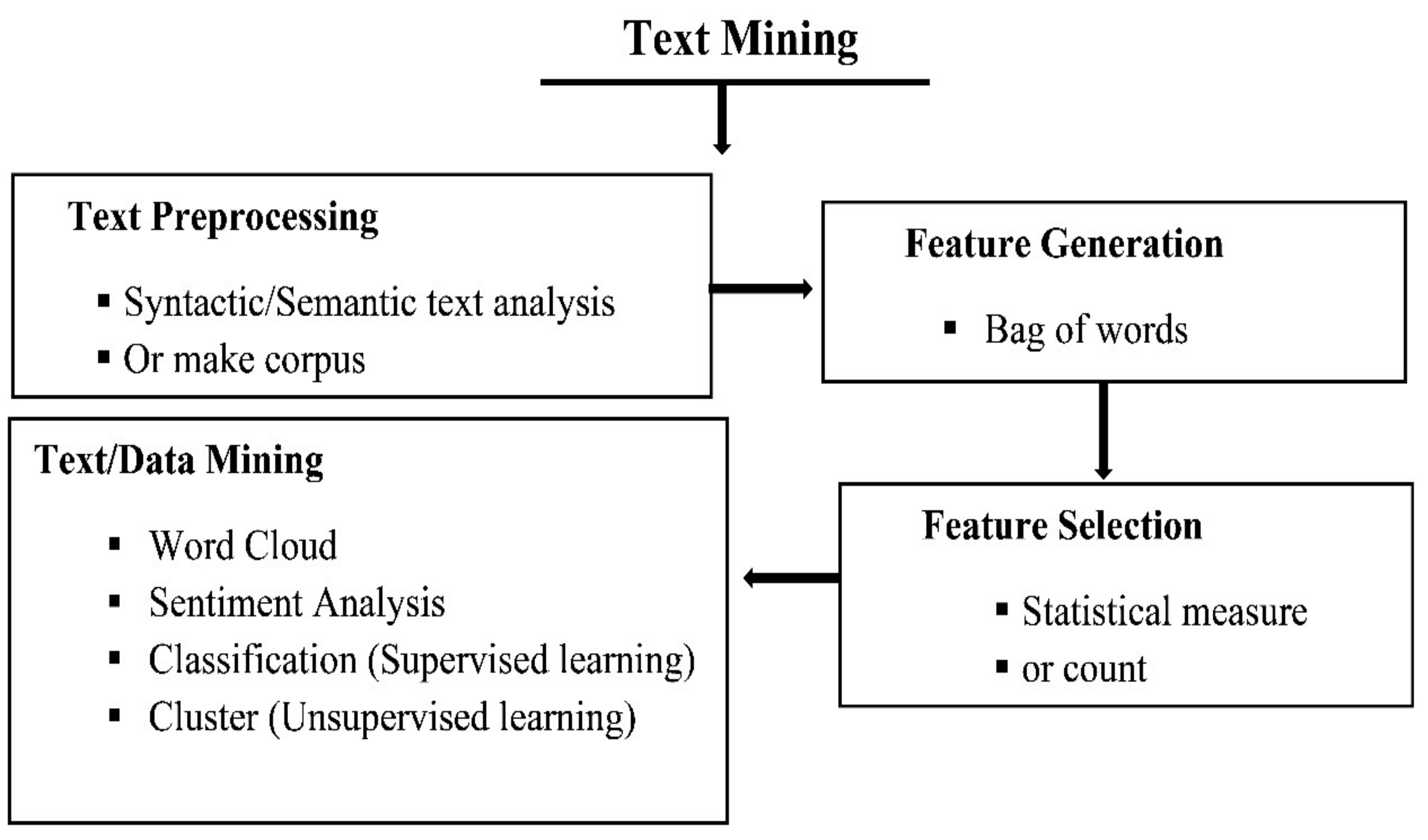
3. Materials and Methods
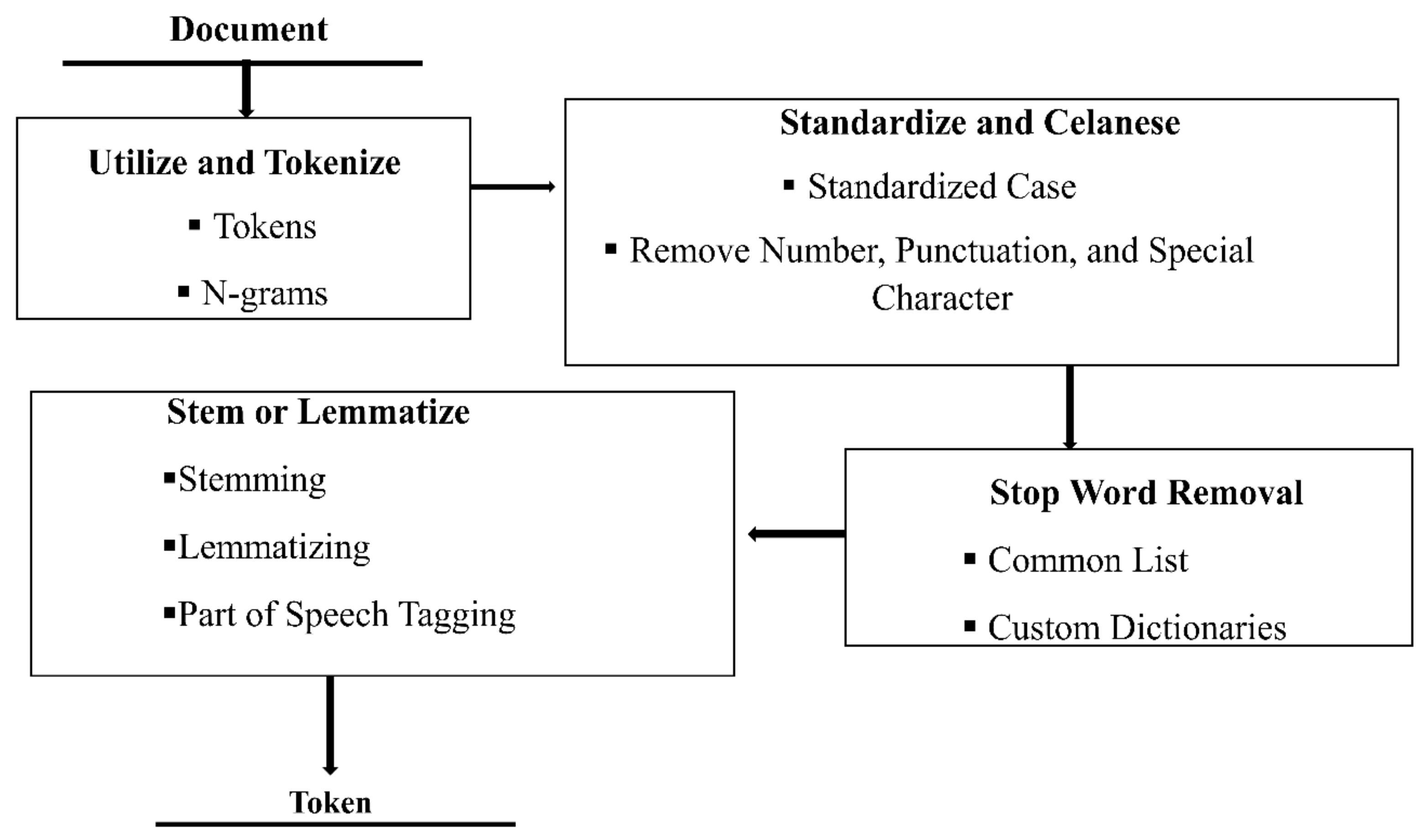
3.1. Data Preparation
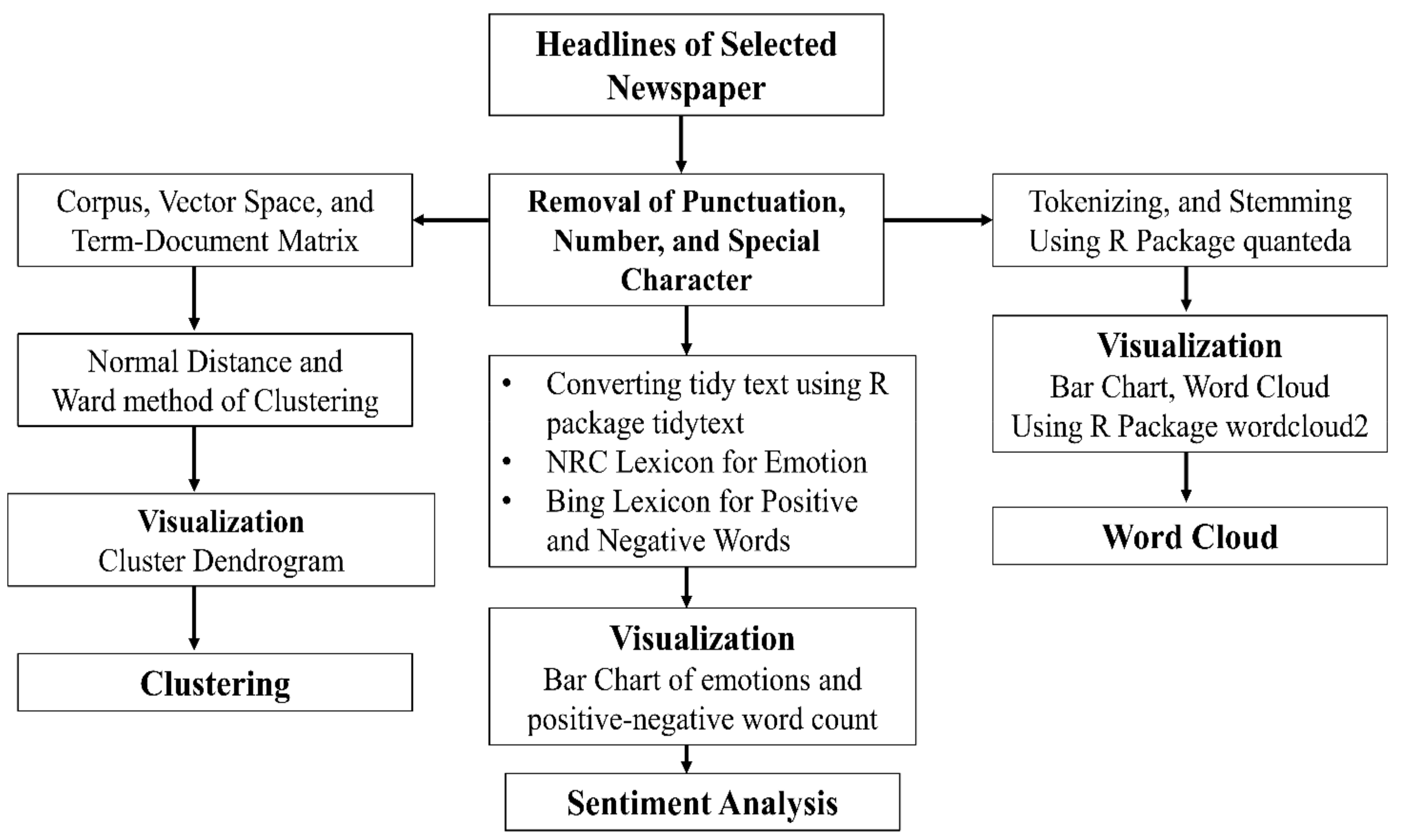
3.2. Methods
3.2.1. Word Cloud
3.2.2. Sentiment Analysis
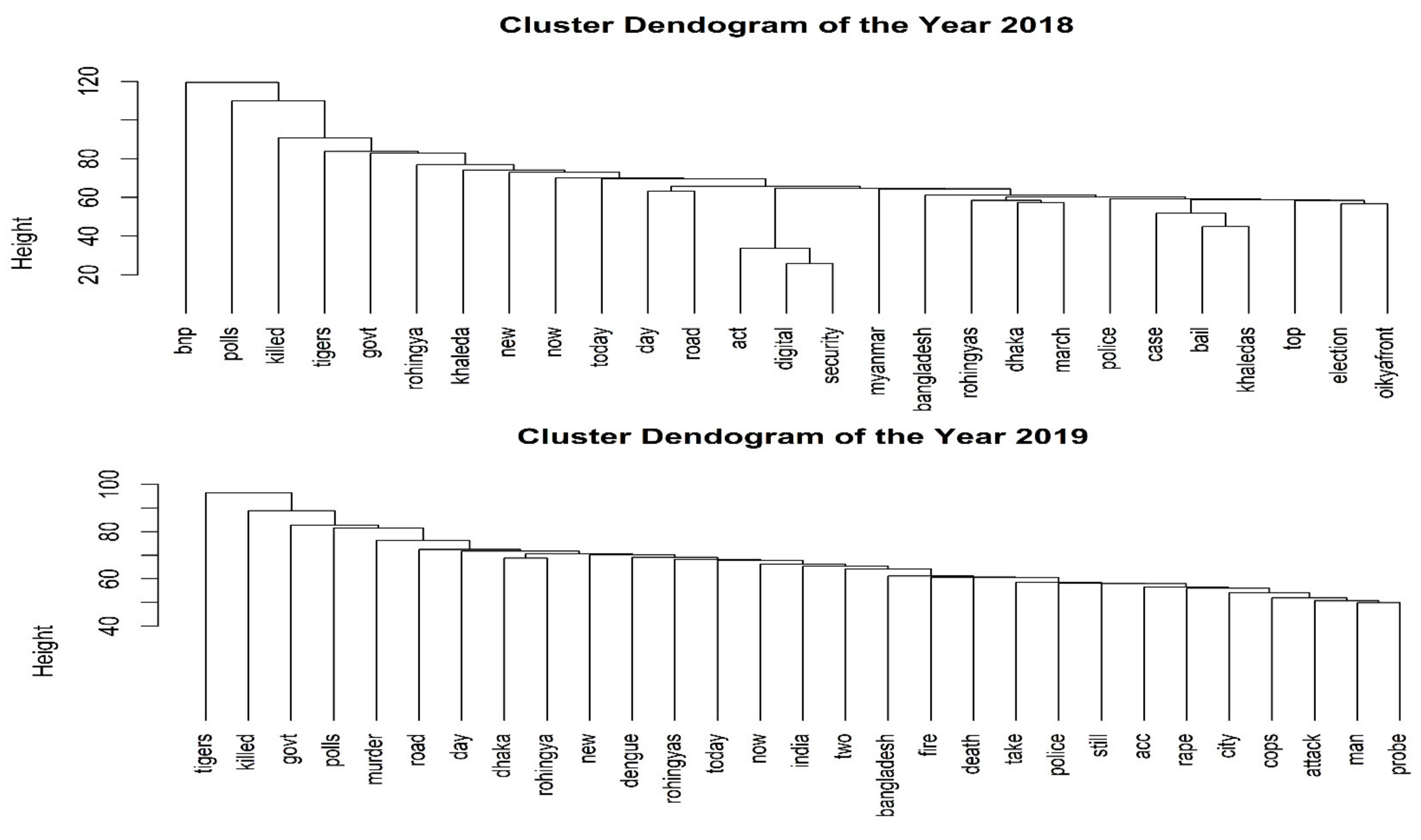
3.2.3. Cluster Analysis
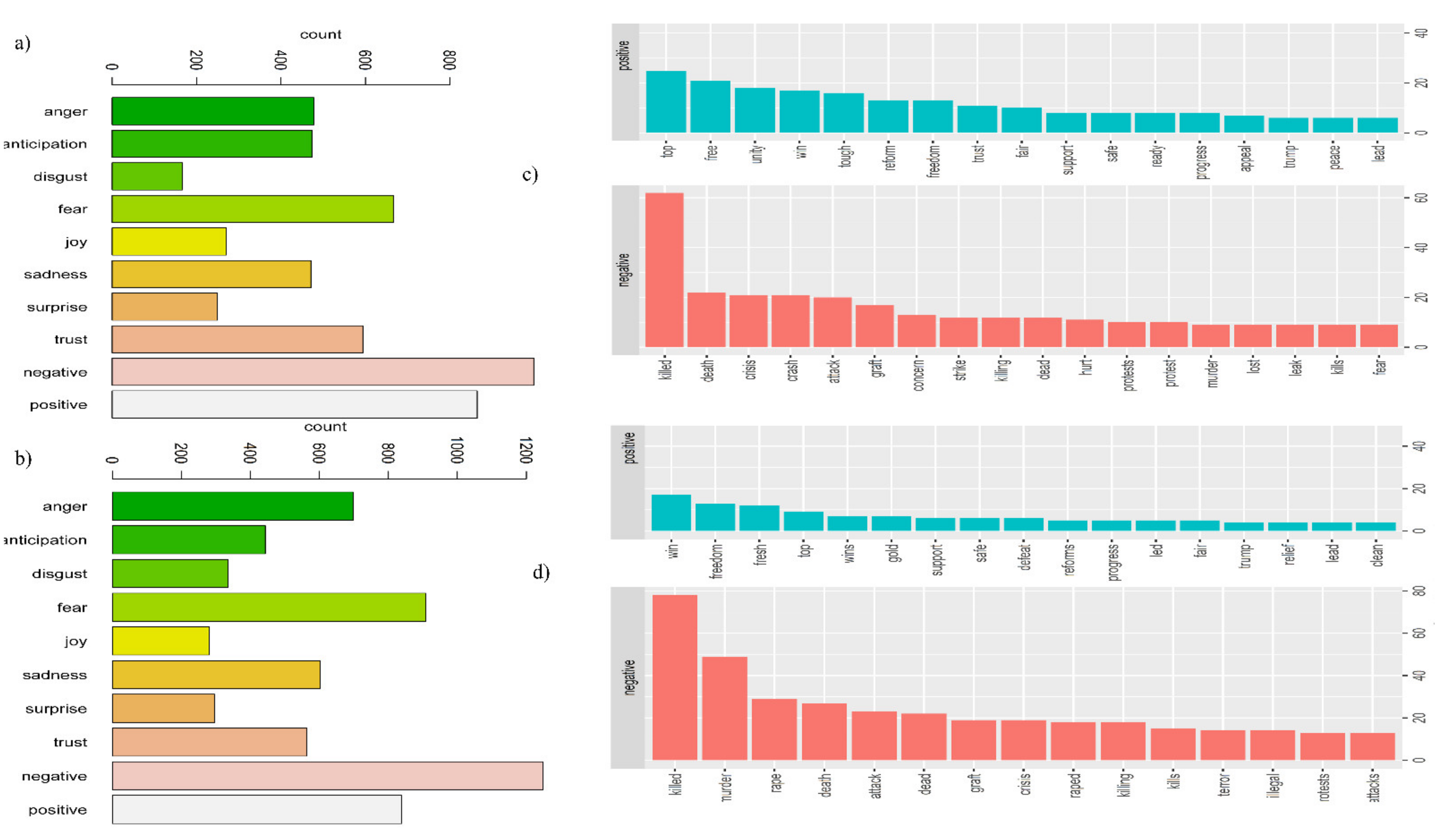
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AL | Awami League |
| AFINN | Lexicon assigns words with a score that runs between −5 and 5, with negative scores indicating negative sentiment and positive scores indicating positive sentiment |
| BING | Lexicon categorizes words in a binary fashion into positive and negative categories |
| BNP | Bangladesh Nationalist Party |
| DTM | Document-Term Matrix |
| NRC | Lexicon categorizes words in a binary fashion (“yes”/“no”) into categories of positive, negative, anger, anticipation, disgust, fear, joy, sadness, surprise, and trust |
| PM | Prime Minister |
| R | Is a programming language and free software environment for statistical computing and graphics supported by the R Foundation for Statistical Computing |
| URL | Uniform Resource Locator |
References
- Anandarajan, M.; Hill, C.; Nolan, T. Text Preprocessing. In Practical Text Analytics: Maximizing the Value of Text Data; Anandarajan, M., Hill, C., Nolan, T., Eds.; Advances in Analytics and Data Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 45–59. ISBN 978-3-319-95663-3. [Google Scholar]
- Chen, R.; Xu, W. The Determinants of Online Customer Ratings: A Combined Domain Ontology and Topic Text Analytics Approach. Electron. Commer. Res. 2017, 17, 31–50. [Google Scholar] [CrossRef]
- Cho, Y.-J.; Fu, P.-W.; Wu, C.-C. Popular Research Topics in Marketing Journals, 1995–2014. J. Interact. Mark. 2017, 40, 52–72. [Google Scholar] [CrossRef]
- Heimerl, F.; Lohmann, S.; Lange, S.; Ertl, T. Word Cloud Explorer: Text Analytics Based on Word Clouds. In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 1833–1842. [Google Scholar]
- Michelson, M.; Macskassy, S.A. Discovering Users’ Topics of Interest on Twitter: A First Look. In Proceedings of the Fourth Workshop on Analytics for Noisy Unstructured Text Data, Toronto, ON, Canada, 26–30 October 2010; Association for Computing Machinery: New York, NY, USA; pp. 73–80. [Google Scholar]
- Qiao, Z.; Zhang, X.; Zhou, M.; Wang, A.; Fan, W. A Domain Oriented LDA Model for Mining Product Defects from Online Customer Reviews. In Proceedings of the Annual Hawaii International Conference on System Sciences 2017, Waikoloa, HI, USA, 4–7 January 2017; pp. 1821–1830. [Google Scholar] [CrossRef] [Green Version]
- Scanfeld, D.; Scanfeld, V.; Larson, E.L. Dissemination of Health Information through Social Networks: Twitter and Antibiotics. Am. J. Infect. Control 2010, 38, 182–188. [Google Scholar] [CrossRef] [Green Version]
- Text Mining. 2020. Available online: https://en.wikipedia.org/wiki/Text_mining (accessed on 10 July 2020).
- Kaser, O.; Lemire, D. Tag-Cloud Drawing: Algorithms for Cloud Visualization. arXiv 2007, arXiv:cs/0703109. [Google Scholar]
- Seifert, C.; Jurgovsky, J.; Granitzer, M. FacetScape: A Visualization for Exploring the Search Space. In Proceedings of the 2014 18th International Conference on Information Visualisation, Paris, France, 16–18 July 2014; pp. 94–101. [Google Scholar]
- Lohmann, S.; Heimerl, F.; Bopp, F.; Burch, M.; Ertl, T. Concentri Cloud: Word Cloud Visualization for Multiple Text Documents. In Proceedings of the 2015 19th International Conference on Information Visualisation, Barcelona, Spain, 22–24 July 2015; pp. 114–120. [Google Scholar]
- Chowdhury, R.R.; Shahadat Hossain, M.; Hossain, S.; Andersson, K. Analyzing Sentiment of Movie Reviews in Bangla by Applying Machine Learning Techniques. In Proceedings of the 2019 International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, Bangladesh, 27–28 September 2019; pp. 1–6. [Google Scholar]
- Drus, Z.; Khalid, H. Sentiment Analysis in Social Media and Its Application: Systematic Literature Review. Procedia Comput. Sci. 2019, 161, 707–714. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment Analysis Algorithms and Applications: A Survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Emam, A.; Alzahrani, M. Opinion Mining Techniques and Tools: A Case Study on an Arab Newspaper. In Proceedings of the 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2017; pp. 292–296. [Google Scholar]
- Li, J. From Tweets and Newspapers to Polls A Sentiment Study on 2017 United Kingdom General Election. Available online: http://localhost/handle/1874/373203 (accessed on 11 July 2021).
- Patodkar, V.N.; Sheikh, I.R. Twitter as a Corpus for Sentiment Analysis and Opinion Mining. Int. J. Adv. Res. Comput. Commun. Eng. 2016, 5, 320–322. [Google Scholar] [CrossRef]
- Silge, J.; Robinson, D. Text Mining with R: A Tidy Approach; O’Reilly Media, Inc.: California, CA, USA, 2017; ISBN 978-1-4919-8162-7. [Google Scholar]
- Hu, Z.; Wei, Z.; Sun, H.; Yang, J.; Wei, L. Optimization of Metal Rolling Control Using Soft Computing Approaches: A Review. Arch. Comput. Methods Eng. 2021, 28, 405–421. [Google Scholar] [CrossRef]
- Manik, S.; Gurvinder, S.; Rajinder, S. Design of GA and Ontology Based NLP Frameworks for Online Opinion Mining. Recent Pat. Eng. 2019, 13, 159–165. [Google Scholar]
- Chien, Y.-C.; Liu, M.-C.; Wu, T.-T. Discussion-Record-Based Prediction Model for Creativity Education Using Clustering Methods. Think. Ski. Creat. 2020, 36, 100650. [Google Scholar] [CrossRef]
- Li, N.; Wu, D.D. Using Text Mining and Sentiment Analysis for Online Forums Hotspot Detection and Forecast. Decis. Support Syst. 2010, 48, 354–368. [Google Scholar] [CrossRef]
- Introduction to Text Mining for Social Scientists. Available online: https://campus.sagepub.com/blog/introduction-to-text-mining-for-social-scientists (accessed on 19 July 2021).
- Karlgren, J.; Li, R.; Milgrom, E.M.M. Text Mining for Processing Interview Data in Computational Social Science. arXiv 2020, arXiv:2011.14037. [Google Scholar]
- Nguyen, D.; Liakata, M.; DeDeo, S.; Eisenstein, J.; Mimno, D.; Tromble, R.; Winters, J. How We Do Things with Words: Analyzing Text as Social and Cultural Data. Front. Artif. Intell. 2020, 3, 62. [Google Scholar] [CrossRef]
- Carley, K.M.; Bigrigg, M.W.; Diallo, B. Data-to-Model: A Mixed Initiative Approach for Rapid Ethnographic Assessment. Comput. Math. Organ. Theory 2012, 18, 300–327. [Google Scholar] [CrossRef]
- Lee, C.; Cheng, C.-I.; Zeleke, A. Can Text Mining Technique Be Used as an Alternative Tool for Qualitative Research in Education? In Proceedings of the 15th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Las Vegas, NV, USA, 30 June–2 July 2014; pp. 1–6. [Google Scholar]
- Kumar, A.; Jaiswal, A. Empirical Study of Twitter and Tumblr for Sentiment Analysis Using Soft Computing Techniques. In Proceedings of the World Congress on Engineering and Computer Science 2017 Vol I WCECS 2017, San Francisco, CA, USA, 25–27 October 2017; Available online: http://www.iaeng.org/publication/WCECS2017/WCECS2017_pp472-476.pdf (accessed on 2 May 2021).
- Özyirmidokuz, E.K. Mining Unstructured Turkish Economy News Articles. Procedia Econ. Financ. 2014, 16, 320–328. [Google Scholar] [CrossRef] [Green Version]
- Hagenau, M.; Liebmann, M.; Neumann, D. Automated News Reading: Stock Price Prediction Based on Financial News Using Context-Capturing Features. Decis. Support Syst. 2013, 55, 685–697. [Google Scholar] [CrossRef]
- Ammann, M.; Frey, R.; Verhofen, M. Do Newspaper Articles Predict Aggregate Stock Returns? J. Behav. Financ. 2014, 15, 195–213. [Google Scholar] [CrossRef] [Green Version]
- Geva, T.; Zahavi, J. Empirical Evaluation of an Automated Intraday Stock Recommendation System Incorporating Both Market Data and Textual News. Decis. Support Syst. 2014, 57, 212–223. [Google Scholar] [CrossRef]
- De Fortuny, E.J.; De Smedt, T.; Martens, D.; Daelemans, W. Media Coverage in Times of Political Crisis: A Text Mining Approach. Expert Syst. Appl. 2012, 39, 11616–11622. [Google Scholar] [CrossRef] [Green Version]
- Groth, S.S.; Muntermann, J. An Intraday Market Risk Management Approach Based on Textual Analysis. Decis. Support Syst. 2011, 50, 680–691. [Google Scholar] [CrossRef]
- Bai, X. Predicting Consumer Sentiments from Online Text. Decis. Support Syst. 2011, 50, 732–742. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word–emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef] [Green Version]
- Mostafa, M.M. More than Words: Social Networks’ Text Mining for Consumer Brand Sentiments. Expert Syst. Appl. 2013, 40, 4241–4251. [Google Scholar] [CrossRef]
- Ghose, A.; Ipeirotis, P.G. Estimating the Helpfulness and Economic Impact of Product Reviews: Mining Text and Reviewer Characteristics. IEEE Trans. Knowl. Data Eng. 2011, 23, 1498–1512. [Google Scholar] [CrossRef] [Green Version]
- Al-Hasan, A.; Yim, D.; Lucas, H. A Tale of Two Movements: Egypt during the Arab Spring and Occupy Wall Street. IEEE Trans. Eng. Manag. 2018, 66, 84–97. [Google Scholar] [CrossRef]
- Serrano-Contreras, I.-J.; García-Marín, J.; Luengo, Ó.G. Measuring Online Political Dialogue: Does Polarization Trigger More Deliberation? Media Commun. 2020, 8, 63–72. [Google Scholar] [CrossRef]
- Hossain, M.S.; Jui, I.J.; Suzana, A.Z. Sentiment Analysis for Bengali Newspaper Headlines. BSc Thesis, BRAC University, Dhaka, Bangladesh, 2017. [Google Scholar]
- Bhowmik, N.R.; Arifuzzaman, M.; Mondal, M.R.H.; Islam, M.S. Bangla Text Sentiment Analysis Using Supervised Machine Learning with Extended Lexicon Dictionary. Nat. Lang. Process. Res. 2021, 1, 34–45. [Google Scholar] [CrossRef]
- Arafin Mahtab, S.; Islam, N.; Mahfuzur Rahaman, M. Sentiment Analysis on Bangladesh Cricket with Support Vector Machine. In Proceedings of the 2018 International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, Bangladesh, 21–22 September 2018; pp. 1–4. [Google Scholar]
- Ahmed, A.; Yousuf, M.A. Sentiment Analysis on Bangla Text Using Long Short-Term Memory (LSTM) Recurrent Neural Network. In Proceedings of the International Conference on Trends in Computational and Cognitive Engineering, Dhaka, Bangladesh, 17–18 December 2020; Kaiser, M.S., Bandyopadhyay, A., Mahmud, M., Ray, K., Eds.; Springer: Singapore, 2021; pp. 181–192. [Google Scholar]
- Emon, I.S.; Ahmed, S.S.; Milu, S.A.; Mahtab, S.S. Sentiment Analysis of Bengali Online Reviews Written with English Letter Using Machine Learning Approaches. In Proceedings of the 6th International Conference on Networking, Systems and Security, Dhaka, Bangladesh, 17–19 December 2019; Association for Computing Machinery: New York, NY, USA; pp. 109–115. [Google Scholar]
- Chowdhury, S.; Chowdhury, W. Performing Sentiment Analysis in Bangla Microblog Posts. In Proceedings of the 2014 International Conference on Informatics, Electronics Vision (ICIEV), Dhaka, Bangladesh, 23–24 May 2014; pp. 1–6. [Google Scholar]
- Mahmud, K.A.; Ahmed, G.T. Sentiment Analysis on E-Commerce Business in Bangladesh Perspective; Daffodil International University: Dhaka, Bangladesh, 2019; Report for Bachelor of Science in Computer Science and Engineering. [Google Scholar]
- Content Analysis of Agricultural News in the Mainstream Newspapers of Bangladesh. Available online: http://www.ijbssr.com/journal/details/content-analysis-of-agricultural-news-in-the-mainstream-newspapers-of-bangladesh-140132914 (accessed on 2 May 2021).
- Chowdhury, S.M.M.H.; Tumpa, Z.N.; Khatun, F.; Rabby, S.K.F. Crime Monitoring from Newspaper Data Based on Sentiment Analysis. In Proceedings of the 2019 8th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 22–23 November 2019; pp. 299–304. [Google Scholar]
- Rasmussen, J.; Farhad, A.T.M. Media and Communication Studies. MS Thesis, School of Humanities, Education and Social Sciences, Örebro University, Örebro, Sweden, 2016. [Google Scholar]
- Manir, T.I.; Hossain, M.M. Application of Text Mining on the Editorial of a Newspaper of Bangladesh. Int. J. Comput. Appl. 2019, 178, 23–29. [Google Scholar]
- Genilo, J.W.; Asiuzzaman, M.; Osmani, M.M.H. Small Circulation, Big Impact: English Language Newspaper Readability in Bangladesh. Adv. J. Commun. 2016, 4, 127–148. [Google Scholar] [CrossRef] [Green Version]
- The Daily Star. Available online: https://www.thedailystar.net/ (accessed on 11 July 2021).
- Segall, R. Web-Based Text Mining of Hotel Customer Comments Using SAS ® Text Miner and Megaputer Polyanalyst ®. Available online: https://www.semanticscholar.org/paper/Web-Based-Text-Mining-of-Hotel-Customer-Comments-%C2%AE-Segall/989d52db9226bdba077733f43f0f77d024e78d52 (accessed on 11 July 2021).
- Chowdhury, S.M.M.H.; Ghosh, P.; Abujar, S.; Afrin, M.; Hossain, S. Sentiment Analysis of Tweet Data: The Study of Sentimental State of Human from Tweet Text. In Emerging Technologies in Data Mining and Information Security; Abraham, A., Dutta, P., Mandal, J., Bhattacharya, A., Dutta, S., Eds.; Springer: Singapore, 2018; Volume 813, Advances in Intelligent Systems and Computing. [Google Scholar]
- Benoit, K.; Watanabe, K.; Wang, H.; Nulty, P.; Obeng, A.; Müller, S.; Matsuo, A. Quanteda: An R Package for the Quantitative Analysis of Textual Data. JOSS 2018, 3, 774. [Google Scholar] [CrossRef] [Green Version]
- Holtz, Y. The Wordcloud2 Library. Available online: https://www.r-graph-gallery.com/196-the-wordcloud2-library.html (accessed on 19 July 2021).
- Tidytext: Tidytext: Text Mining Using “Dplyr”, “Ggplot2”, and Other. in Tidytext: Text Mining Using “Dplyr”, “Ggplot2”, and Other Tidy Tools. Available online: https://rdrr.io/cran/tidytext/man/tidytext.html (accessed on 11 July 2021).
- Nielsen, F. A New ANEW: Evaluation of a Word List for Sentiment Analysis in Microblogs. In Proceedings of the ESWC2011 Workshop on ‘Making Sense of Microposts’: Big things come in small packages, Heraklion, Crete, 30 May 2011; pp. 93–98. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Hvitfeldt, E.; Silge, J. Textdata: Download and Load Various Text Datasets, R Package Version 0.4.1. 2020. Available online: https://cran.r-project.org/web/packages/textdata/index.html (accessed on 11 July 2021).
- Wickham, H. RStudio Tidyr: Tidy Messy Data. 2021. Available online: https://tidyr.tidyverse.org/reference/tidyr-package.html (accessed on 11 July 2021).
- Wickham, H.; François, R.; Henry, L.; Müller, K. RStudio Dplyr: A Grammar of Data Manipulation. 2021. Available online: https://dplyr.tidyverse.org/reference/dplyr-package.html (accessed on 11 July 2021).
- Wickham, H.; Chang, W.; Henry, L.; Pedersen, T.L.; Takahashi, K.; Wilke, C.; Woo, K.; Yutani, H.; Dunnington, D. RStudio Ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics; 2021. Available online: https://cran.r-project.org/web/packages/ggplot2/index.html (accessed on 11 July 2021).
- Hahsler, M.; Piekenbrock, M.; Arya, S.; Mount, D. Dbscan: Density Based Clustering of Applications with Noise (DBSCAN) and Related Algorithms, R Package Version 1.1-8. 2021. Available online: https://cran.r-project.org/web/packages/dbscan/index.html (accessed on 11 July 2021).
- Hennig, C. Fpc: Flexible Procedures for Clustering, R Package Version 2.2-9. 2020. Available online: https://cran.r-project.org/web/packages/fpc/index.html (accessed on 11 July 2021).
- Hornik, K.; Böhm, W. Clue: Cluster Ensembles, R Package Version 0.3-59. 2021. Available online: https://cran.r-project.org/web/packages/clue/index.html (accessed on 11 July 2021).
- Ihaka, R.; Murrell, P.; Hornik, K.; Fisher, J.C.; Stauffer, R.; Wilke, C.O.; McWhite, C.D.; Zeileis, A. Colorspace: A Toolbox for Manipulating and Assessing Colors and Palettes, R Package Version 2.0-2. 2021. Available online: https://cran.r-project.org/web/packages/colorspace/index.html (accessed on 11 July 2021).
- Maitra, R.; Ramler, I.P. A k -Mean-Directions Algorithm for Fast Clustering of Data on the Sphere. J. Comput. Graph. Stat. 2010, 19, 377–396. [Google Scholar] [CrossRef]
- Meyer, D.; Buchta, C. Proxy: Distance and Similarity Measures, R Package Version 0.4-26. 2021. Available online: https://cran.r-project.org/web/packages/proxy/index.html (accessed on 11 July 2021).
- Tm Package—RDocumentation. Available online: https://www.rdocumentation.org/packages/tm/versions/0.7-8 (accessed on 11 July 2021).
- Facebook’s New Controversy Shows How Easily Online Political Ads Can Manipulate You. Available online: https://time.com/5197255/facebook-cambridge-analytica-donald-trump-ads-data/ (accessed on 10 July 2021).
- Radio, C.B.C. Data Mining Firm behind Trump Election Built Psychological Profiles of Nearly Every American Voter|CBC Radio. Available online: https://www.cbc.ca/radio/day6/episode-359-harvey-weinstein-a-stock-market-for-sneakers-trump-s-data-mining-the-curious-incident-more-1.4348278/data-mining-firm-behind-trump-election-built-psychological-profiles-of-nearly-every-american-voter-1.4348283 (accessed on 10 July 2021).
- Road Safety in South Asia. Available online: https://www.worldbank.org/en/region/sar/publication/road-safety-in-south-asia (accessed on 10 July 2021).
- In South Asia, the Case for Road Safety Investment is Stronger than Ever. Available online: https://blogs.worldbank.org/transport/south-asia-case-road-safety-investment-stronger-ever (accessed on 10 July 2021).
- Road Safety. Available online: https://www.who.int/bangladesh/news/detail/12-05-2019-road-safety (accessed on 10 July 2021).
- Rahman, A. Statistics-based data preprocessing methods and machine learning algorithms for big data analysis. Int. J. Artif. Intell. 2019, 17, 44–65. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, A.; Karimuzzaman, M.; Hossain, M.M.; Rahman, A. Text Mining and Sentiment Analysis of Newspaper Headlines. Information 2021, 12, 414. https://doi.org/10.3390/info12100414
Hossain A, Karimuzzaman M, Hossain MM, Rahman A. Text Mining and Sentiment Analysis of Newspaper Headlines. Information. 2021; 12(10):414. https://doi.org/10.3390/info12100414
Chicago/Turabian StyleHossain, Arafat, Md. Karimuzzaman, Md. Moyazzem Hossain, and Azizur Rahman. 2021. "Text Mining and Sentiment Analysis of Newspaper Headlines" Information 12, no. 10: 414. https://doi.org/10.3390/info12100414
APA StyleHossain, A., Karimuzzaman, M., Hossain, M. M., & Rahman, A. (2021). Text Mining and Sentiment Analysis of Newspaper Headlines. Information, 12(10), 414. https://doi.org/10.3390/info12100414