
Financial Volatility Forecasting: A Sparse Multi-Head Attention Neural Network

Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Problem Discussion
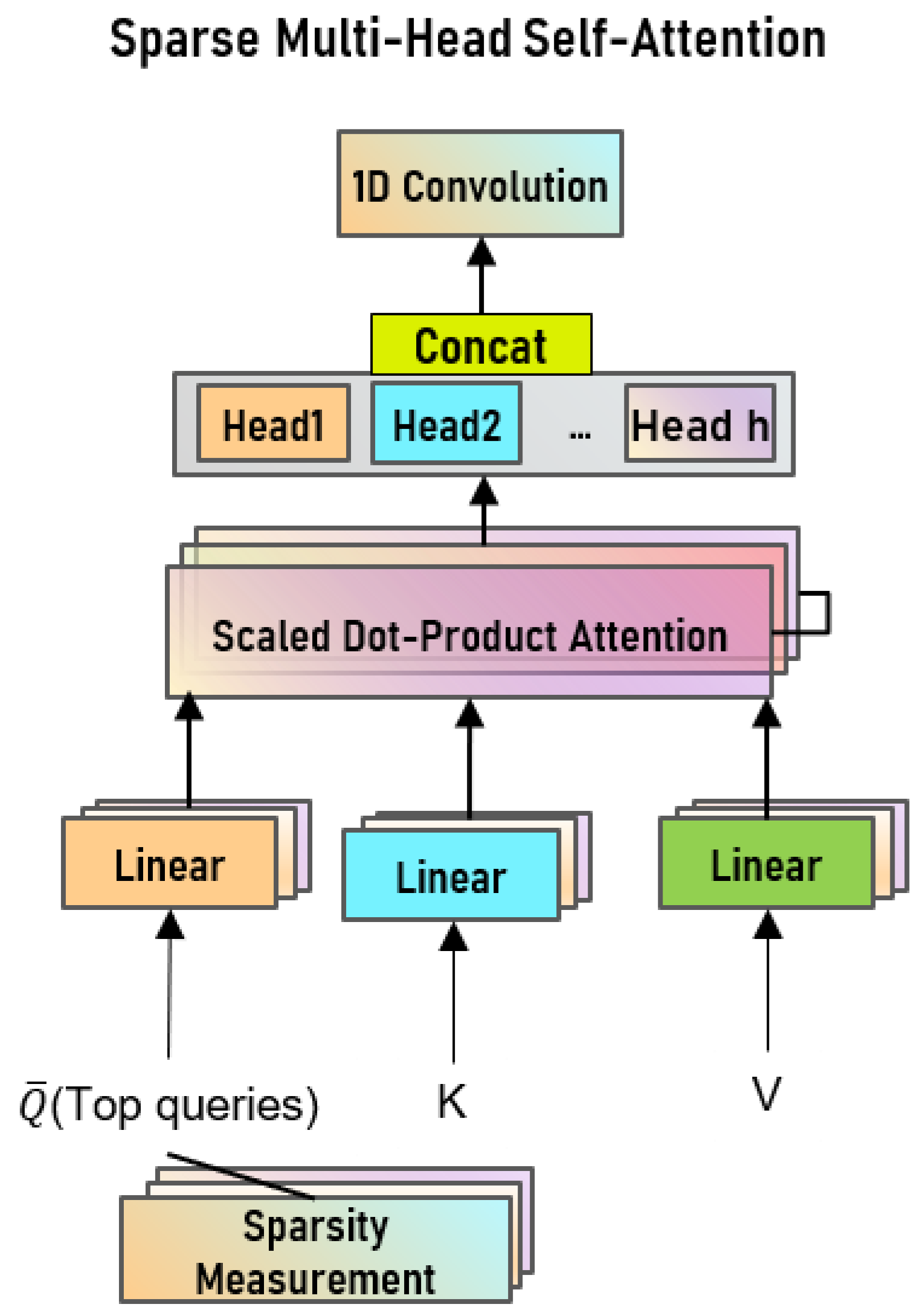
3.2. Sparse Multi-Head Self-Attention
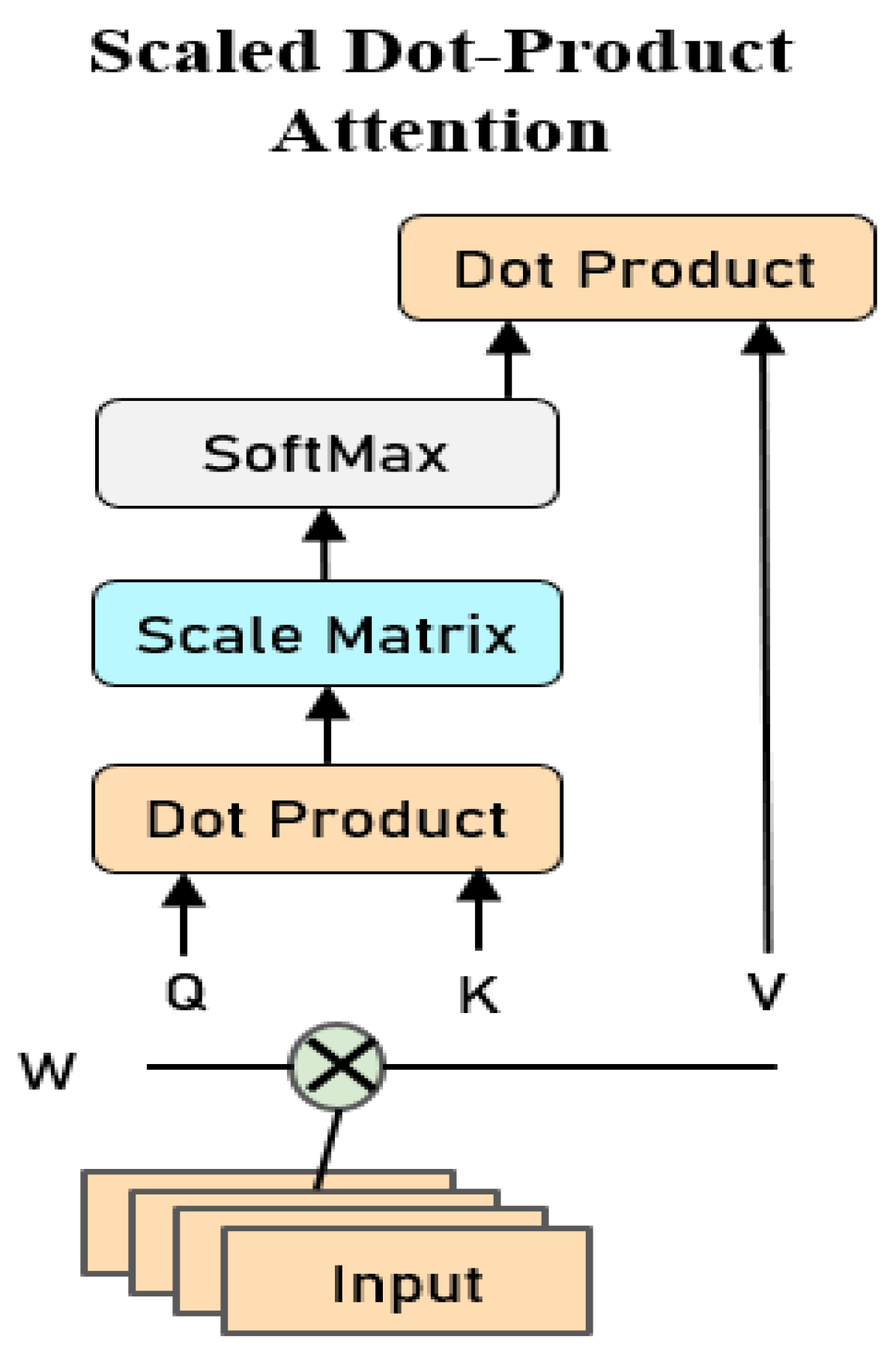
3.2.1. Multi-Head Self-Attention
3.2.2. Sparse Self-Attention
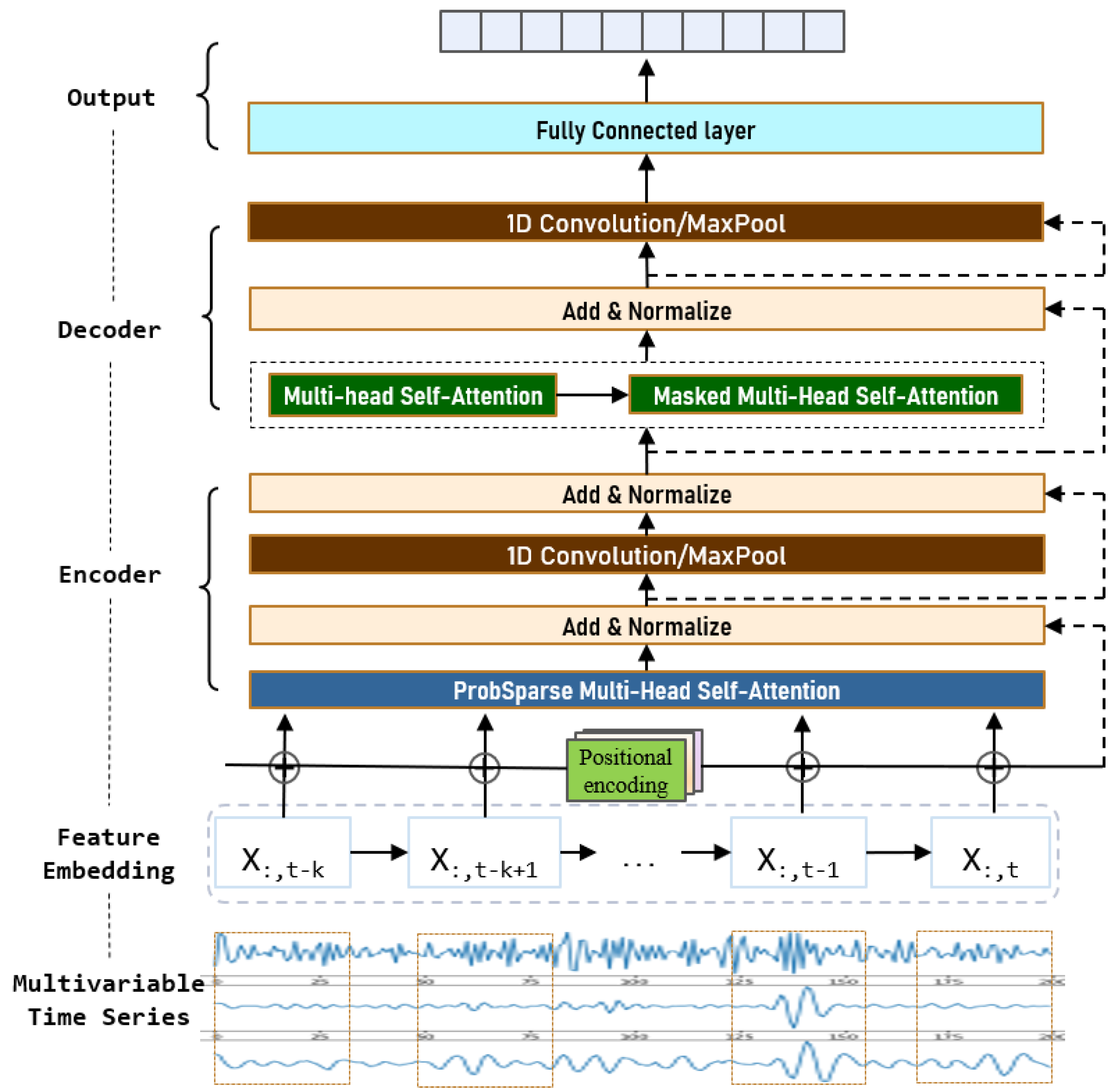
3.3. Model Architecture
3.3.1. Encoder
3.3.2. Decoder
3.3.3. 1D Convolution Neural Networks
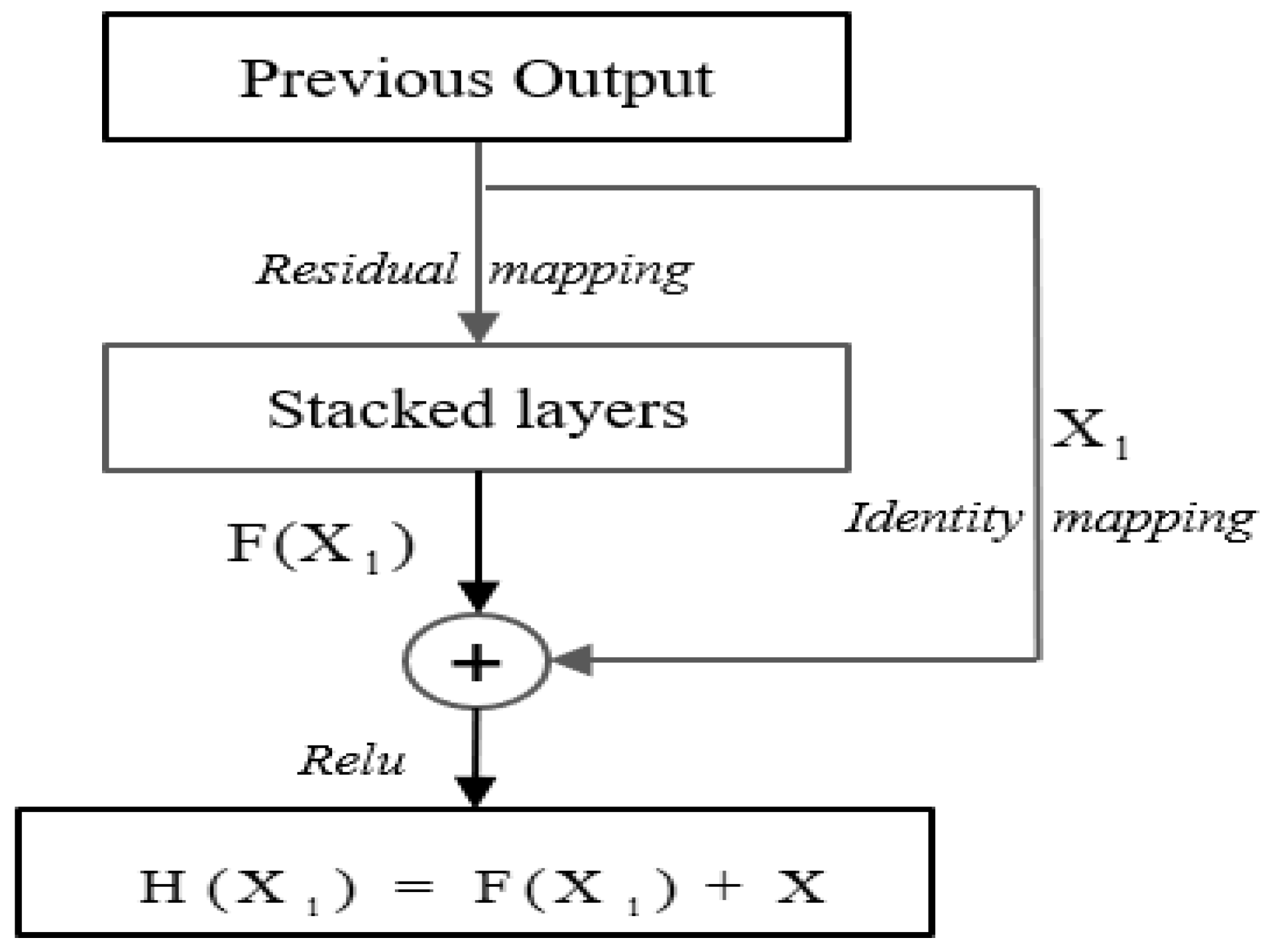
3.3.4. Residual Connection and Normalization Layer
3.3.5. Embedding and Output
3.3.6. Positional Encoding
4. Experiment
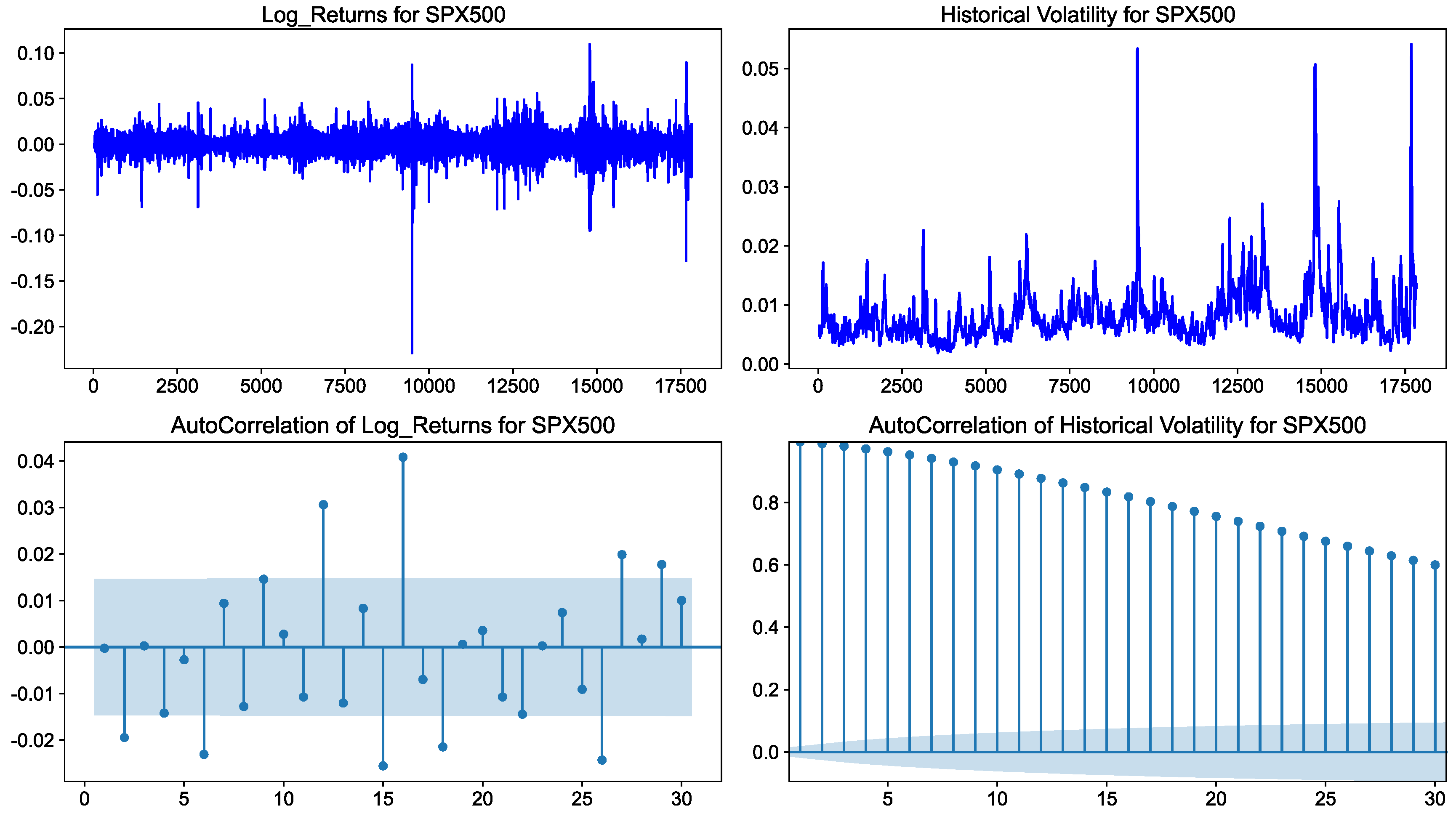
4.1. Dataset
4.2. Baseline Methods
4.3. Metrics
- (1)
- mean absolute error (MAE)
- (2)
- mean squared error (MSE)
- (3)
- Diebold–Mariano test (DM test)
4.4. Experimental Result Analysis
4.5. Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Engle, R.E. Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. Econometrica 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- Brooks, C. A Double-threshold GARCH Model for the French Franc/Deutschmark exchange rate. J. Forecast. 2001, 20, 135–143. [Google Scholar] [CrossRef]
- Efimova, O.; Serletis, A. Energy markets volatility modelling using GARCH. Energy Econ. 2014, 43, 264–273. [Google Scholar] [CrossRef]
- Garcia, R.C.; Contreras, J.; Akkeren, M.V.; Garcia, J.B.C. A GARCH forecasting model to predict day-ahead electricity prices. IEEE Trans. Power Syst. 2005, 20, 867–874. [Google Scholar] [CrossRef]
- Kaiser, T. One-Factor-GARCH Models for German Stocks. Estim. Forecast. 1996, 30, 56–57. [Google Scholar]
- Klaassen, F. Improving GARCH volatility forecasts with regime-switching GARCH. Empir. Econ. 2002, 27, 363–394. [Google Scholar] [CrossRef] [Green Version]
- Abdalla, S.Z.S. Modelling Exchange Rate Volatility using GARCH Models: Empirical Evidence from Arab Countries. Int. J. Econ. Financ. 2012, 4, 216–229. [Google Scholar] [CrossRef]
- Agnolucci, P. Volatility in crude oil futures: A comparison of the predictive ability of GARCH and implied volatility models. Energy Econ. 2009, 31, 316–321. [Google Scholar] [CrossRef]
- Nelson, D.B. Conditional Heteroskedasticity in Asset Returns: A New Approach. Model. Stock Mark. Volatility 1991, 59, 347–370. [Google Scholar] [CrossRef]
- Melino, A.; Turnbull, S.M. Pricing foreign currency options with stochastic volatility. J. Econom. 1990, 45, 239–265. [Google Scholar] [CrossRef]
- Tse, Y.K. Stock returns volatility in the Tokyo stock exchange. Jpn. World Econ. 1991, 3, 285–298. [Google Scholar] [CrossRef]
- Mariani, M.C.; Bhuiyan, M.A.M.; Tweneboah, O.K.; Gonzalez-Huizar, H.; Florescu, I. Volatility models applied to geophysics and high frequency financial market data. Phys. A Stat. Mech. Appl. 2018, 503, 304–321. [Google Scholar] [CrossRef] [Green Version]
- Byun, S.-J.; Kim, S.; Rhee, D. Forecasting Future Volatility from Option Prices under the Stochastic Volatility Model. Ssrn Electron. J. 2009. [Google Scholar] [CrossRef]
- Andersen, T.G.; Benzoni, L. Realized Volatility. Ssrn Electron. J. 2008, 71, 555–575. [Google Scholar]
- Corsi, F.; Audrino, F.; Renò, R. HAR Modeling for Realized Volatility Forecasting; John Wiley & Sons, Inc.: New York, NY, USA, 2012. [Google Scholar]
- Qu, H.; Ji, P. Adaptive Heterogeneous Autoregressive Models of Realized Volatility Based on a Genetic Algorithm. Abstr. Appl. Anal. 2014, 2014, 943041. [Google Scholar] [CrossRef]
- Wei, Y. Forecasting volatility of fuel oil futures in China: GARCH-type, SV or realized volatility models? Phys. A Stat. Mech. Appl. 2012, 391, 5546–5556. [Google Scholar] [CrossRef]
- Gavrishchaka, V.V.; Banerjee, S. Support Vector Machine as an Efficient Framework for Stock Market Volatility Forecasting. Comput. Manag. Sci. 2006, 3, 147–160. [Google Scholar] [CrossRef]
- Bucci, A. Realized Volatility Forecasting with Neural Networks. J. Financ. Econom. 2019, 18, 502–531. [Google Scholar] [CrossRef]
- Hamid, S.A.; Iqbal, Z. Using neural networks for forecasting volatility of S&P 500 Index futures prices. J. Bus. Res. 2004, 57, 1116–1125. [Google Scholar]
- Tang, L.; Sheng, H.; Tang, L. Financial Prediction Based on Wavelet Support Vector Machine. Nat. Sci. J. Xiangtan Univ. 2009, 31, 58–63. [Google Scholar]
- Kristjanpoller, R.W.; Michell, V.K. A stock market risk forecasting model through integration of switching regime, ANFIS and GARCH techniques. Appl. Soft Comput. 2018, 67, 106–116. [Google Scholar] [CrossRef]
- Ramos-Pérez, E.; Alonso-González, P.J.; Núñez-Velázquez, J.J. Forecasting volatility with a stacked model based on a hybridized Artificial Neural Network. Expert Syst. Appl. 2019, 129, 1–9. [Google Scholar] [CrossRef]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.Y.; Won, C.H. Forecasting the Volatility of Stock Price Index: A Hybrid Model Integrating LSTM with Multiple GARCH-Type Models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Liu, Y. Novel volatility forecasting using deep learning–Long Short Term Memory Recurrent Neural Networks. Expert Syst. Appl. 2019, 132, 99–109. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473v7. [Google Scholar]
- Cho, K.; Courville, A.; Bengio, Y. Describing Multimedia Content Using Attention-Based Encoder-Decoder Networks. IEEE Trans. Multimed. 2015, 17, 1875–1886. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:abs/1706.03762. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the AAAI, Virtual Online, 2–9 February 2021. [Google Scholar]
- Álvarez-Díaz, M. Is it possible to accurately forecast the evolution of Brent crude oil prices? An answer based on parametric and nonparametric forecasting methods. Empir. Econ. 2020, 59, 1285–1305. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Gandhmal, D.P.; Kumar, K. Systematic analysis and review of stock market prediction techniques. Comput. Sci. Rev. 2019, 34, 100190. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Mean | Std-Dev. | Skewness | Kurtosis | Jarque–Bera |
|---|---|---|---|---|---|
| SPX500 | 9.36 × 10−6 | 0.001525 | −0.011905 | 20.75456 | 170,957.0 |
| Oil | 0.000180 | 0.022712 | −0.540034 | 16.69873 | 62,169.60 |
| Gold | 0.000249 | 0.012181 | 0.062319 | 13.99408 | 66,698.44 |
| Hurst Exponent | SPX500 | WTI | Gold |
|---|---|---|---|
| t = 30 | 0.6440 | 0.6532 | 0.6486 |
| t = 60 | 0.6501 | 0.6556 | 0.6503 |
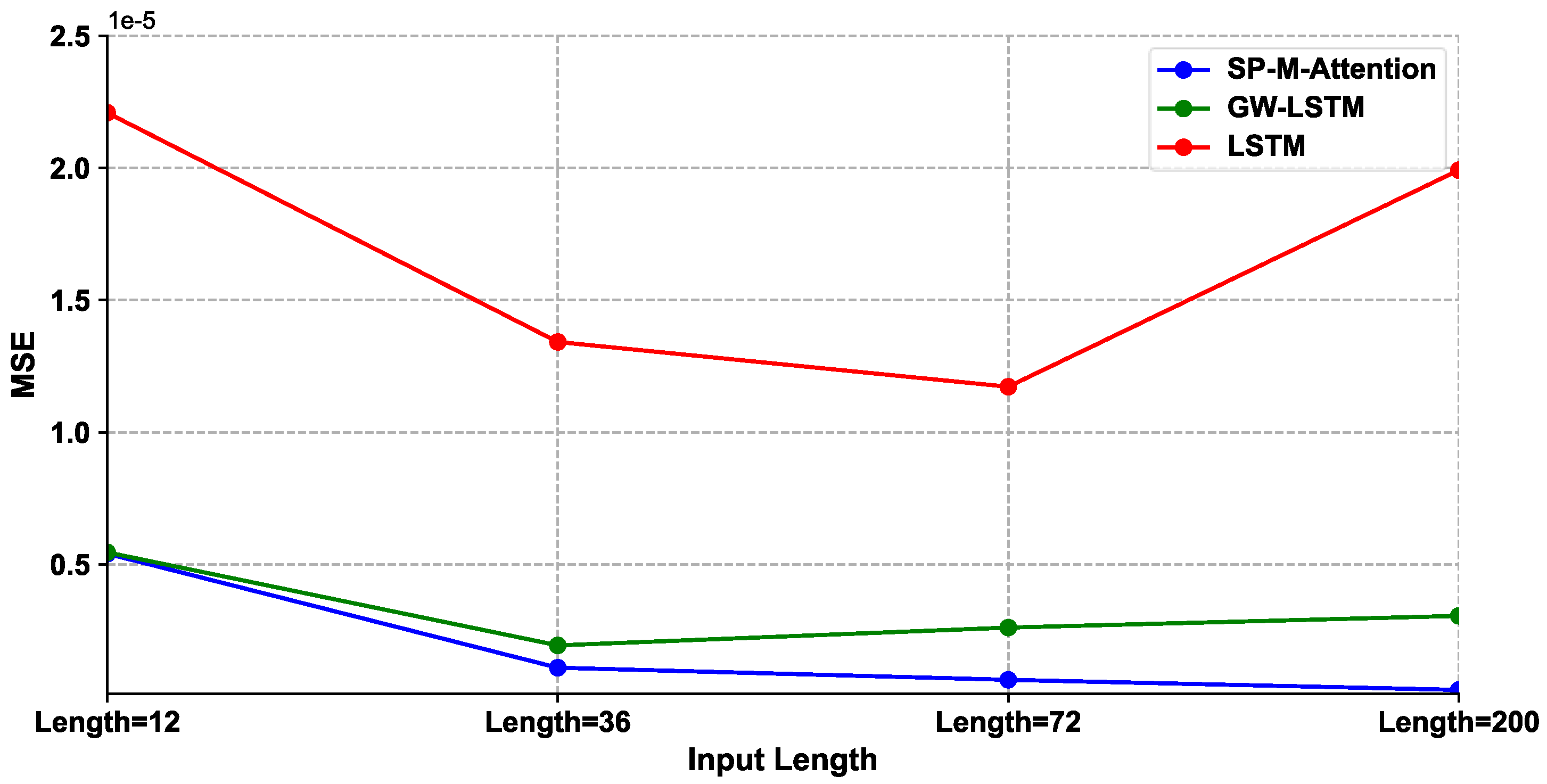
| SPX500 | MAE | MSE | ||||||
| Input Length | 12 | 36 | 72 | 200 | 12 | 36 | 72 | 200 |
| SP-M-Attention | 1.433 × 10−3 | 6.401 × 10−4 | 4.548 × 10−4 | 2.565 × 10−4 | 5.406 × 10−6 | 1.091 × 10−6 | 6.329 × 10−7 | 2.511 × 10−7 |
| GW-LSTM | 1.533 × 10−3 | 9.042 × 10−4 | 1.135 × 10−3 | 1.209 × 10−3 | 5.456 × 10−6 | 1.936 × 10−6 | 2.609 × 10−6 | 3.053 × 10−6 |
| W-SVR | 2.607 × 10−3 | 2.300 × 10−3 | 2.500 × 10−3 | 3.300 × 10−3 | 1.733 × 10−5 | 1.260 × 10−5 | 1.446 × 10−5 | 2.749 × 10−5 |
| LSTM | 2.217 × 10−3 | 1.928 × 10−3 | 2.110 × 10−3 | 3.210 × 10−3 | 2.209 × 10−5 | 1.342 × 10−5 | 1.172 × 10−5 | 1.992 × 10−5 |
| SVR | 3.500 × 10−3 | 3.300 × 10−3 | 3.600 × 10−3 | 5.500 × 10−3 | 3.112 × 10−5 | 2.749 × 10−5 | 3.354 × 10−5 | 1.369 × 10−4 |
| HAR-RV | 2.340 × 10−3 | 8.877 × 10−6 | ||||||
| SV | 2.600 × 10−3 | 1.733 × 10−5 | ||||||
| EGARCH | 3.045 × 10−3 | 2.033 × 10−5 | ||||||
| GARCH | 3.400 × 10−3 | 2.806 × 10−5 | ||||||
| WTI | MAE | MSE | ||||||
| Input Length | 12 | 36 | 72 | 200 | 12 | 36 | 72 | 200 |
| SP-M-Attention | 1.434 × 10−3 | 6.487 × 10−4 | 4.598 × 10−4 | 4.251 × 10−4 | 5.674 × 10−6 | 1.160 × 10−6 | 6.637 × 10−7 | 5.230 × 10−7 |
| GW-LSTM | 1.525 × 10−3 | 9.438 × 10−4 | 1.140 × 10−3 | 1.212 × 10−3 | 5.911 × 10−6 | 2.125 × 10−6 | 2.958 × 10−6 | 3.087 × 10−6 |
| W-SVR | 2.669 × 10−3 | 2.376 × 10−3 | 2.505 × 10−3 | 3.376 × 10−3 | 1.765 × 10−5 | 1.267 × 10−5 | 1.457 × 10−5 | 2.790 × 10−5 |
| LSTM | 2.230 × 10−3 | 1.823 × 10−3 | 2.114 × 10−3 | 3.210 × 10−3 | 1.155 × 10−5 | 7.145 × 10−6 | 9.867 × 10−6 | 2.525 × 10−5 |
| SVR | 3.549 × 10−3 | 3.330 × 10−3 | 3.605 × 10−3 | 5.521 × 10−3 | 3.448 × 10−5 | 2.771 × 10−5 | 3.373 × 10−5 | 1.370 × 10−4 |
| HAR-RV | 2.014 × 10−3 | 9.167 × 10−6 | ||||||
| SV | 2.625 × 10−3 | 1.775 × 10−5 | ||||||
| EGARCH | 3.037 × 10−3 | 2.048 × 10−5 | ||||||
| GARCH | 3.442 × 10−3 | 2.823 × 10−5 | ||||||
| LGP | MAE | MSE | ||||||
| Input Length | 12 | 36 | 72 | 200 | 12 | 36 | 72 | 200 |
| SP-M-Attention | 8.579 × 10−4 | 5.767 × 10−4 | 4.546 × 10−4 | 2.016 × 10−4 | 1.860 × 10−6 | 8.685 × 10−7 | 6.217 × 10−7 | 1.316 × 10−7 |
| GW-LSTM | 1.146 × 10−3 | 7.730 × 10−4 | 8.126 × 10−4 | 1.125 × 10−3 | 2.474 × 10−6 | 1.155 × 10−6 | 1.221 × 10−6 | 2.563 × 10−6 |
| W-SVR | 1.900 × 10−3 | 1.734 × 10−3 | 1.616 × 10−3 | 1.706 × 10−3 | 6.533 × 10−6 | 7.507 × 10−6 | 5.398 × 10−6 | 7.507 × 10−6 |
| LSTM | 1.409 × 10−3 | 1.315 × 10−3 | 1.280 × 10−3 | 3.445 × 10−3 | 4.822 × 10−6 | 3.938 × 10−6 | 3.677 × 10−6 | 2.034 × 10−5 |
| SVR | 2.800 × 10−3 | 2.726 × 10−3 | 2.900 × 10−3 | 2.932 × 10−3 | 1.485 × 10−5 | 1.386 × 10−5 | 1.598 × 10−5 | 1.679 × 10−5 |
| HAR-RV | 1.364 × 10−3 | 3.656 × 10−6 | ||||||
| SV | 1.800 × 10−3 | 6.216 × 10−6 | ||||||
| EGARCH | 2.102 × 10−3 | 7.913 × 10−6 | ||||||
| GARCH | 2.314 × 10−3 | 1.204 × 10−5 | ||||||
| Steps | SP-M-Attention | GW-LSTM | W-SVR | LSTM | SVR | HAR-RV | SV | EGARCH | GARCH |
|---|---|---|---|---|---|---|---|---|---|
| 5 | 2.537 × 10−6 | 1.176 × 10−5 | 1.372 × 10−5 | 1.215 × 10−5 | 3.334 × 10−5 | 9.674 × 10−6 | 2.069 × 10−5 | 2.233 × 10−5 | 3.0174 × 10−5 |
| 10 | 2.824 × 10−6 | 1.294 × 10−5 | 1.509 × 10−5 | 1.336 × 10−5 | 3.668 × 10−5 | 1.064 × 10−5 | 2.276 × 10−5 | 2.457 × 10−5 | 3.087 × 10−5 |
| 20 | 3.152 × 10−6 | 1.424 × 10−5 | 1.660 × 10−5 | 1.470 × 10−5 | 4.035 × 10−5 | 1.171 × 10−5 | 2.504 × 10−5 | 2.703 × 10−5 | 3.396 × 10−5 |
| SP-M-Attention | GW-LSTM | W-SVR | LSTM | SVR | HAR-RV | SV | EGARCH | GARCH | |
|---|---|---|---|---|---|---|---|---|---|
| MSE | 2.340 × 10−7 | 1.801 × 10−6 | 1.172 × 10−5 | 1.090 × 10−5 | 2.557 × 10−5 | 8.256 × 10−6 | 1.612 × 10−5 | 1.891 × 10−5 | 2.610 × 10−5 |
| DM Test | BASELINES | |||||||
|---|---|---|---|---|---|---|---|---|
| GW-LSTM | W-SVR | LSTM | SVR | HAR-RV | SV | EGARCH | GARCH | |
| SP-M-Attention | −10.357 (0.00) | −16.819 (0.00) | −15.432 (0.00) | −33.762 (0.00) | −13.018 (0.00) | −20.664 (0.00) | −24.256 (0.00) | −35.246 (0.00) |
| SP-M-Attention | GW-LSTM | W-SVR | LSTM | SVR | HAR-RV | SV | EGARCH | GARCH | |
|---|---|---|---|---|---|---|---|---|---|
| MSE | 3.153 × 10−8 | 2.592 × 10−7 | 1.715 × 10−6 | 1.615 × 10−6 | 3.692 × 10−6 | 1.196 × 10−6 | 2.331 × 10−6 | 2.742 × 10−6 | 3.850 × 10−6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.; Sun, Q. Financial Volatility Forecasting: A Sparse Multi-Head Attention Neural Network. Information 2021, 12, 419. https://doi.org/10.3390/info12100419
Lin H, Sun Q. Financial Volatility Forecasting: A Sparse Multi-Head Attention Neural Network. Information. 2021; 12(10):419. https://doi.org/10.3390/info12100419
Chicago/Turabian StyleLin, Hualing, and Qiubi Sun. 2021. "Financial Volatility Forecasting: A Sparse Multi-Head Attention Neural Network" Information 12, no. 10: 419. https://doi.org/10.3390/info12100419
APA StyleLin, H., & Sun, Q. (2021). Financial Volatility Forecasting: A Sparse Multi-Head Attention Neural Network. Information, 12(10), 419. https://doi.org/10.3390/info12100419