
Industrial Networks Driven by SDN Technology for Dynamic Fast Resilience

Abstract
:1. Introduction
- We proposed an MFR approach that guarantees a fast resilience and loss-sensitive requirements in industrial applications composed of both wireless and wired networks;
- The optimum path scheme for traffic-aware routing solutions is demonstrated. This scheme is utilized for the proposed MFR resilience approach;
- We presented different network topology scenarios to show dynamic rerouting traffic among OpenFlow switches. These scenarios help to verify the recoverability of the designed approach through various use cases, such as network expansion and failure state in industrial networks;
- We take advantage of the proposed approach by offering an experimental testbed through the use of physical devices like sensor nodes and Raspberry Pis.
2. Related Works
2.1. Link Failure Recovery
2.2. Resilience Approaches
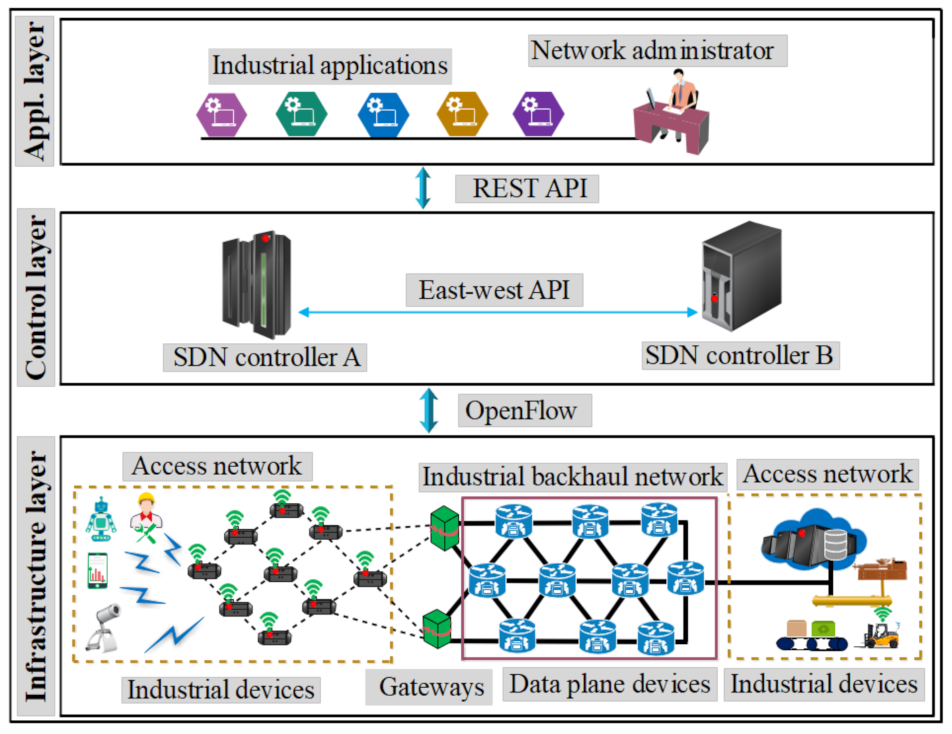
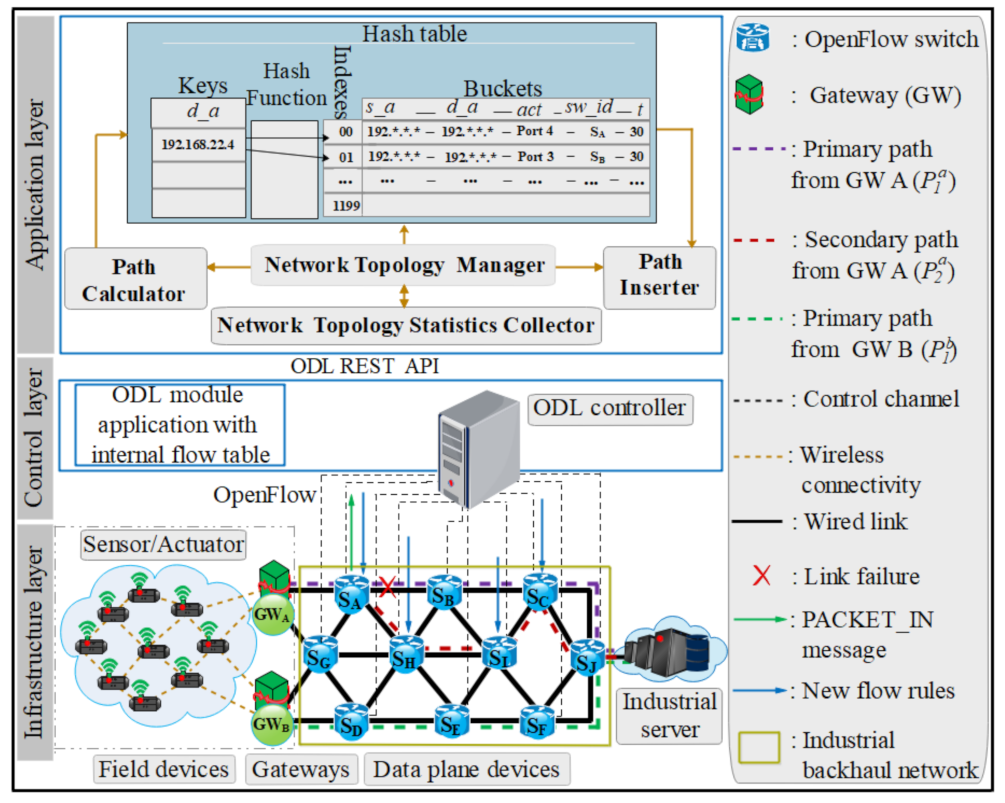
3. System Model of ISDN
3.1. ISDN Resilience Architecture
3.1.1. ISDN Infrastructure Layer
Gateways
Field Devices
Industrial Backhaul Network
3.1.2. ISDN Control Layer
3.1.3. ISDN Application Layer
3.2. MFR Approach
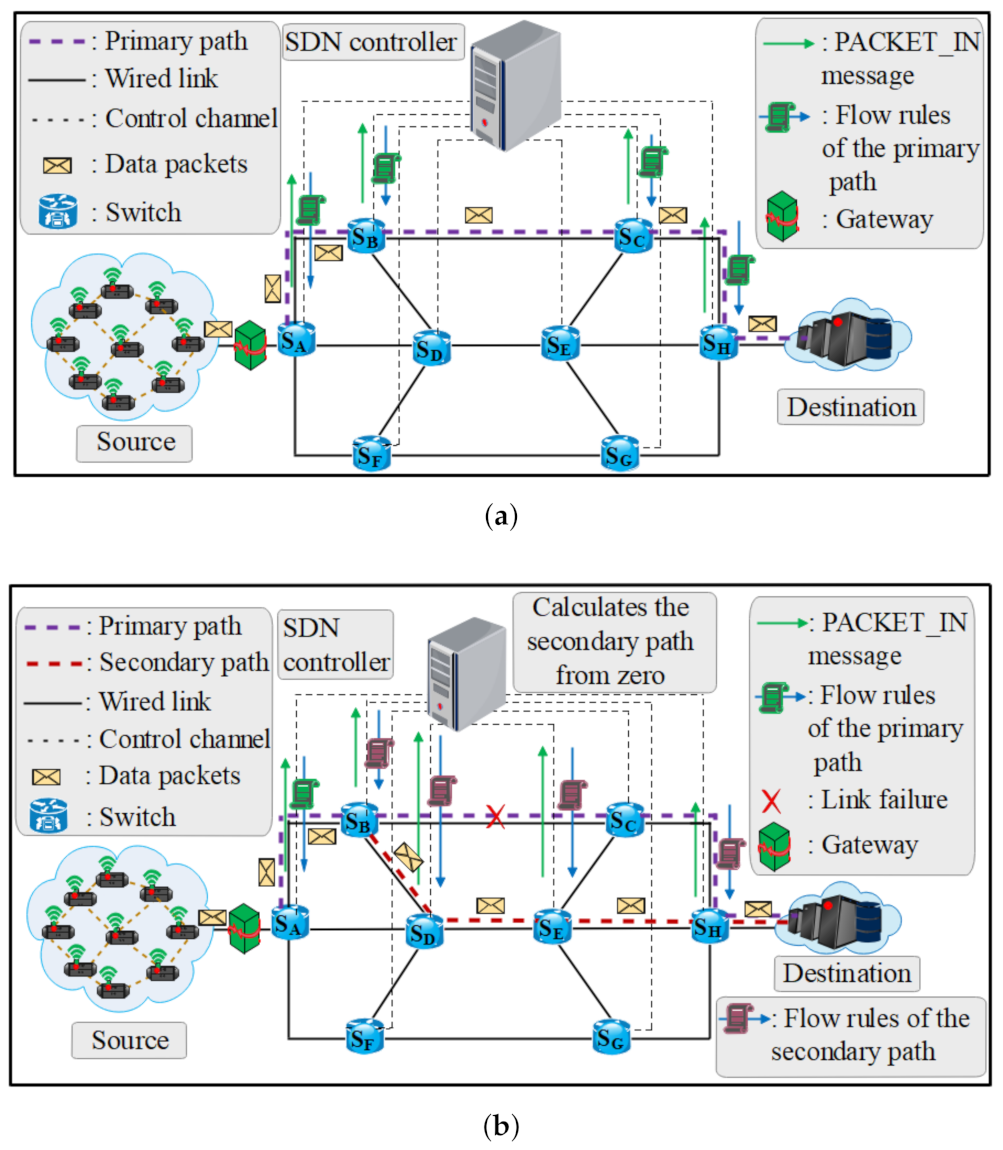
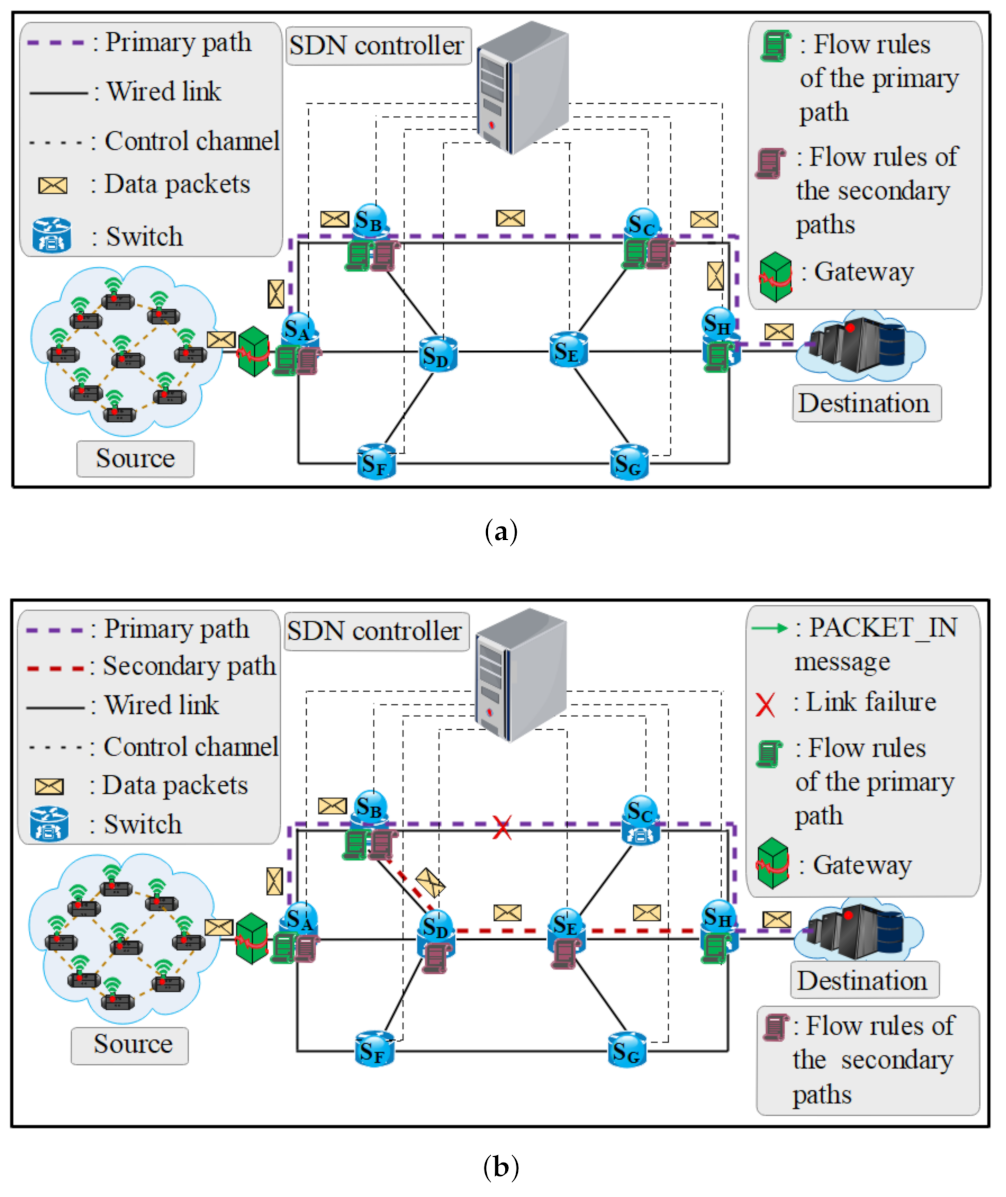
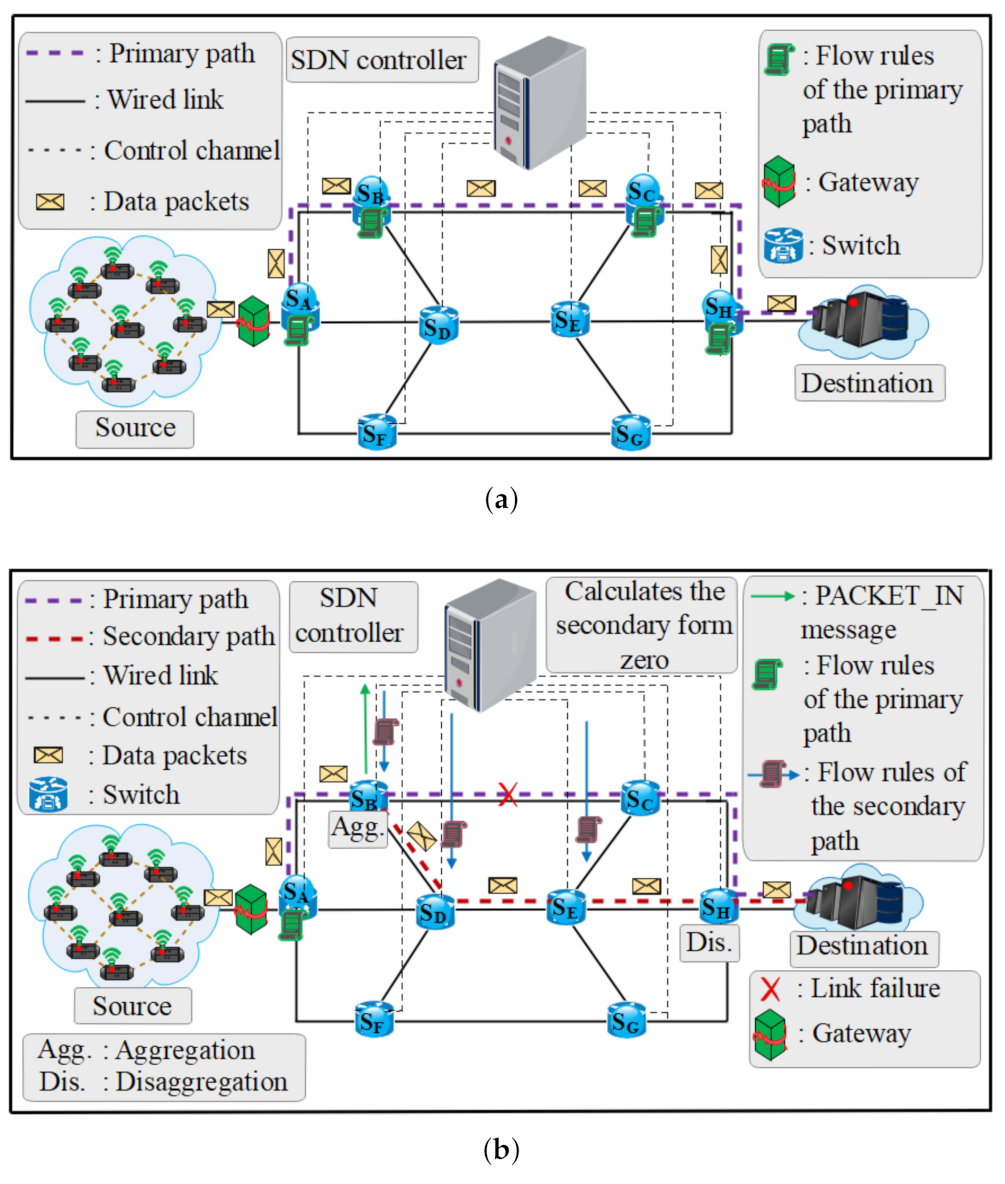
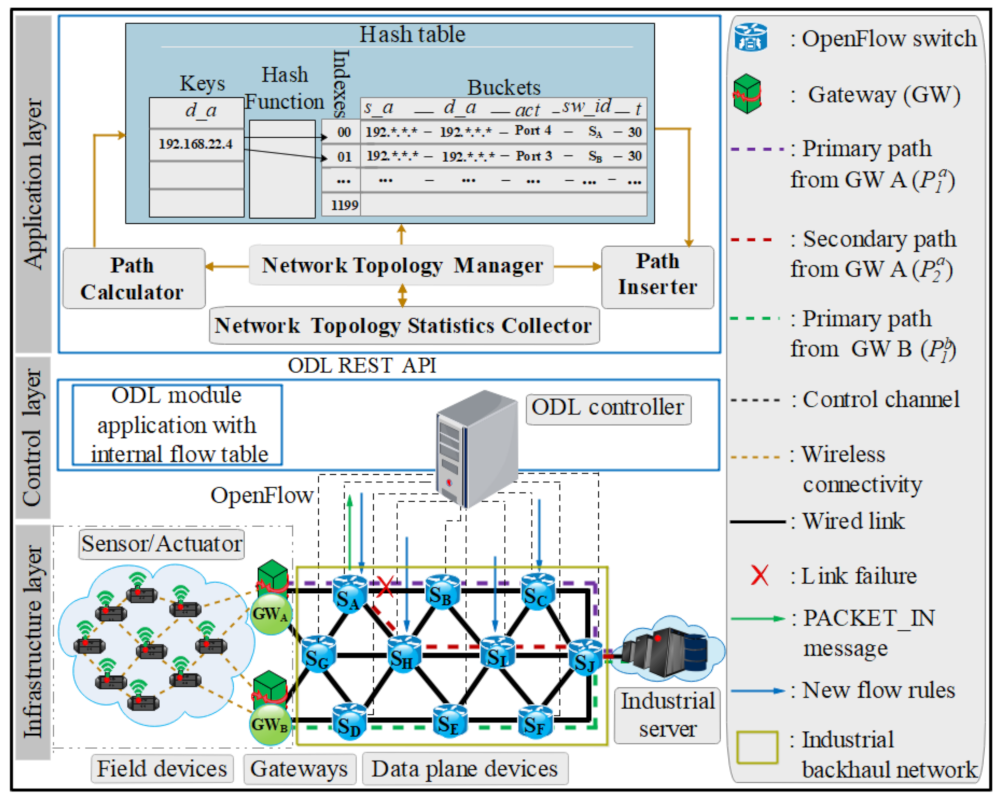
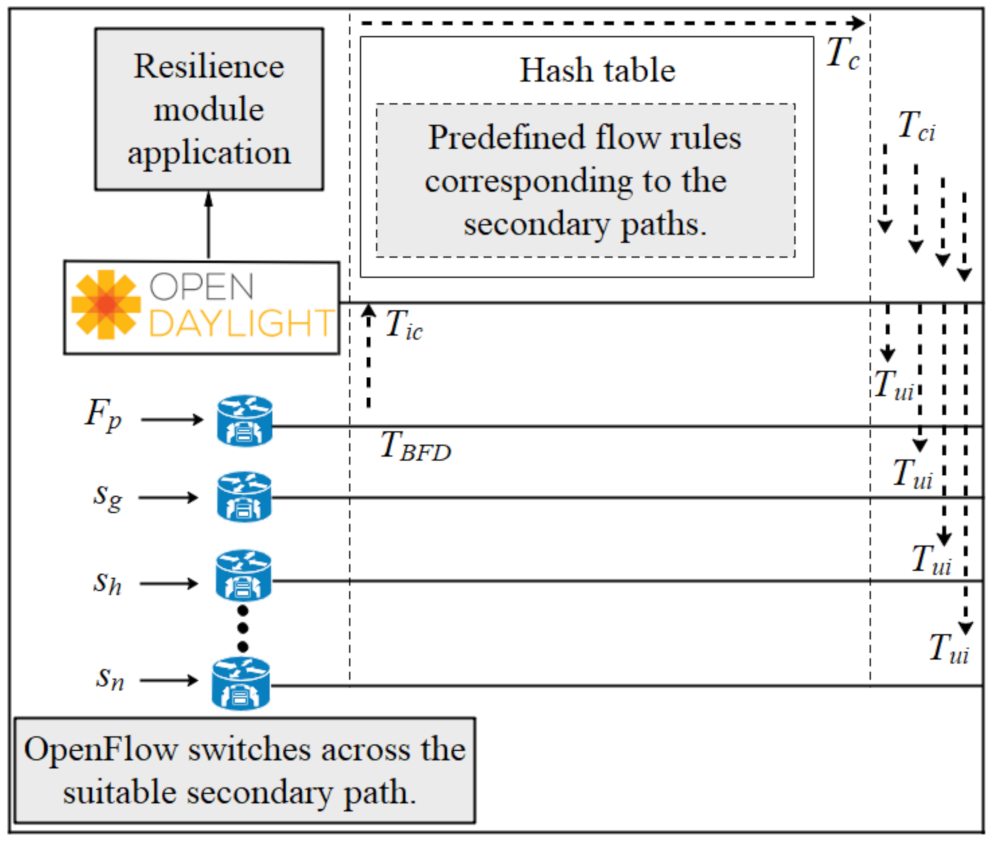
3.2.1. Link Failure Detection
3.2.2. Computation of Primary and Secondary Paths
3.2.3. MFR Performance-Based with Different ISDN Topology
| Algorithm 1: MFR route/reroute performance. |
 |
3.2.4. Analysis of the MFR Approach for the Recovery Process
4. Evaluation Performances
4.1. Simulation Setup
4.2. Evaluation Results
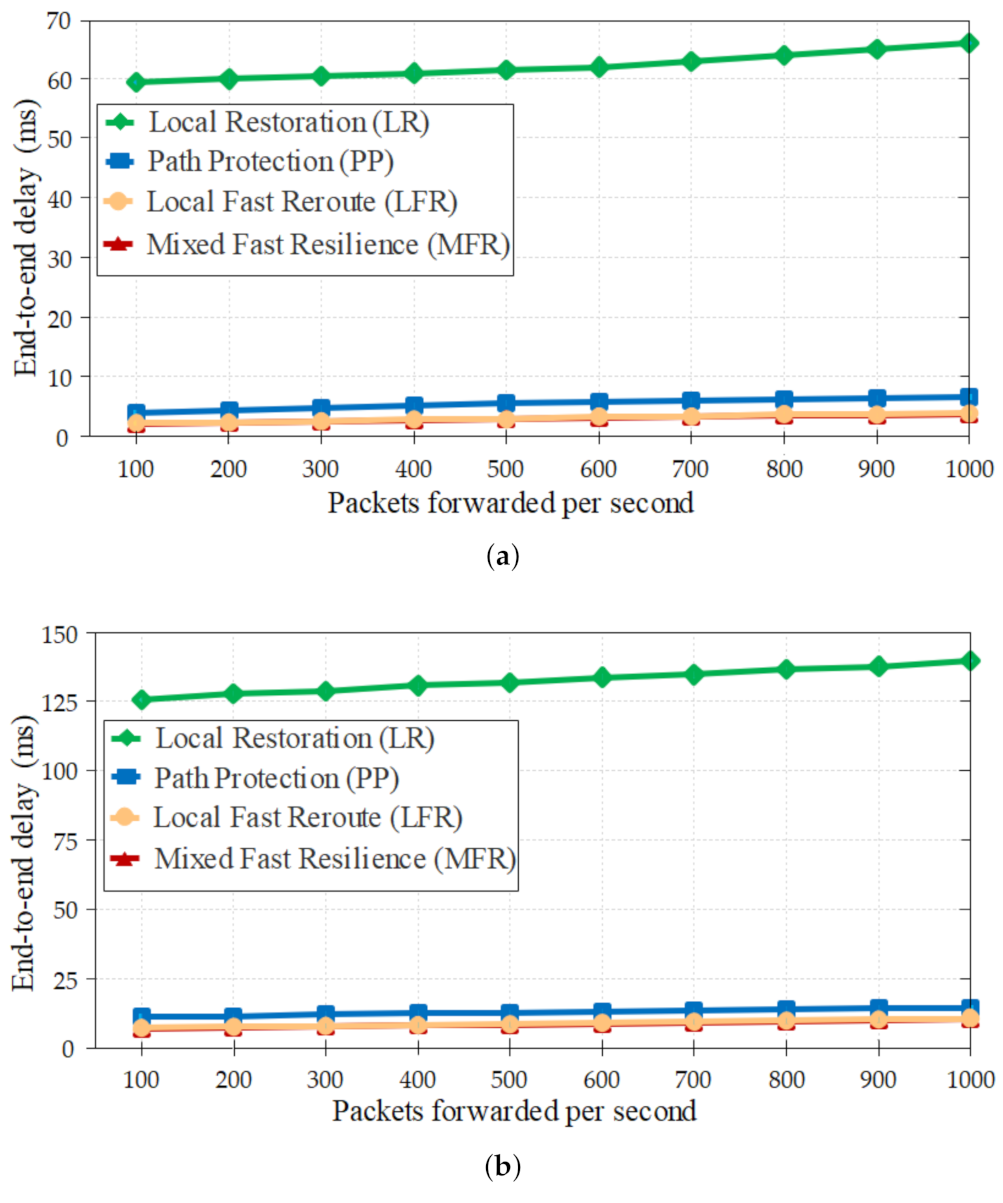
4.2.1. End-to-End Delay before Failure Occurs
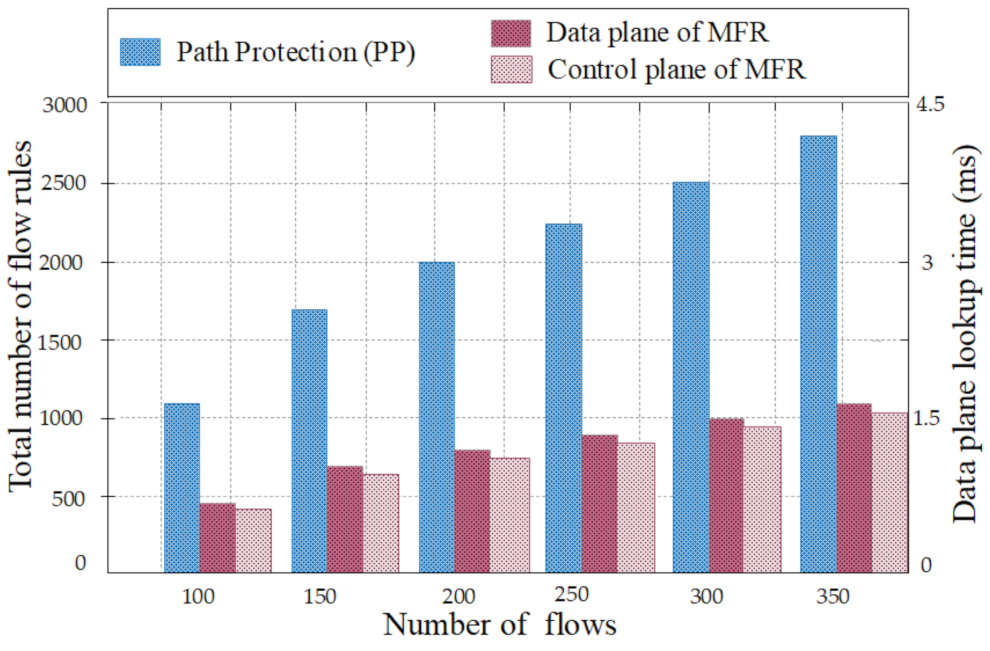
4.2.2. Lookup Time Based on the Number of Flow Rules before Failure Occurs
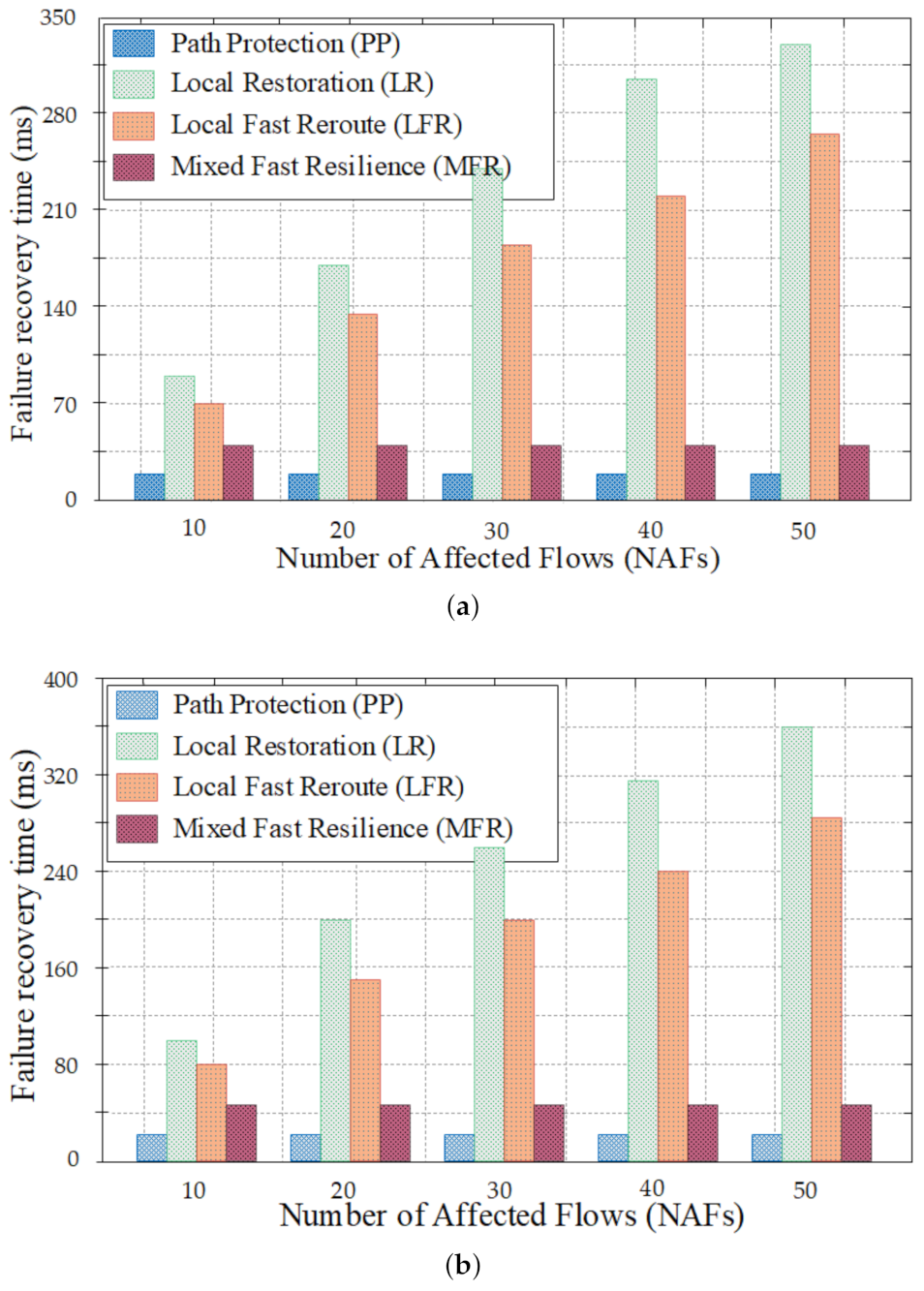
4.2.3. Failure Recovery Time
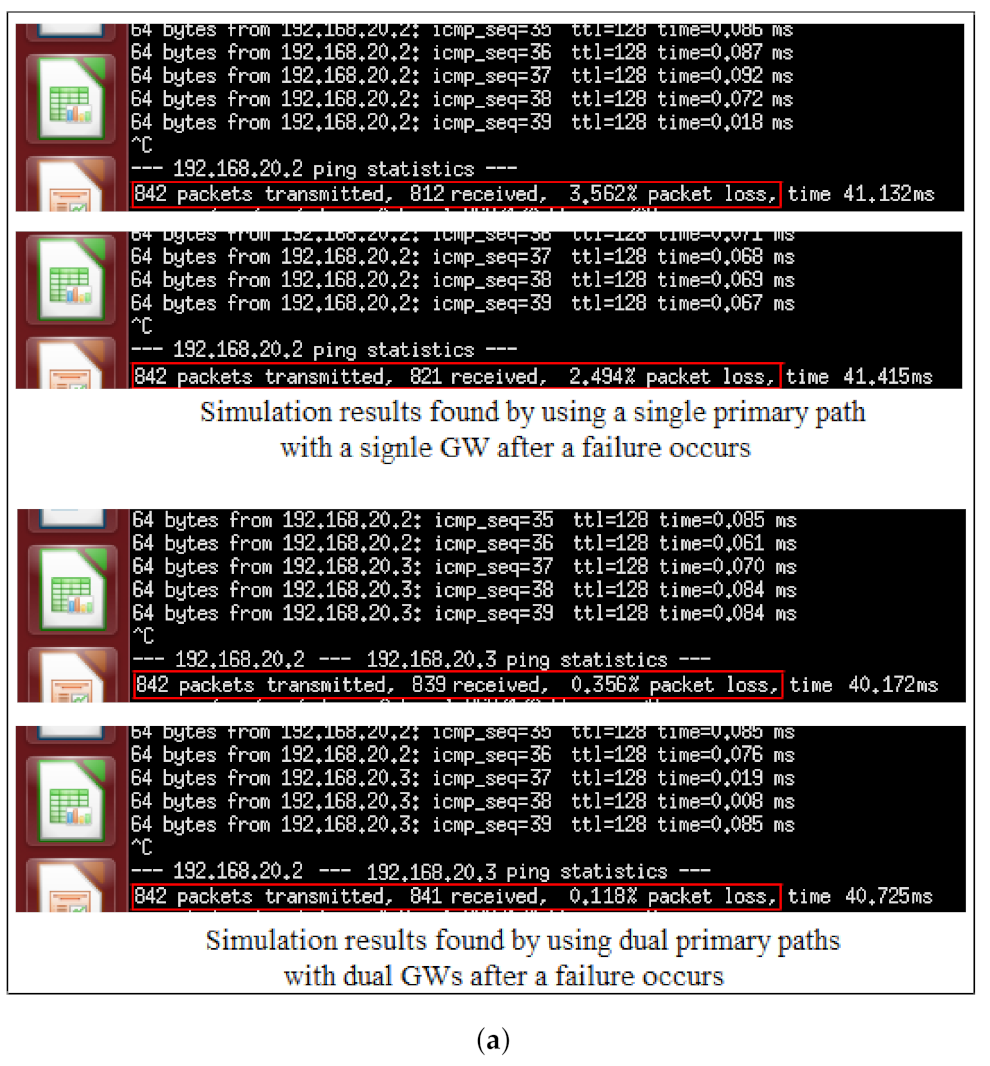
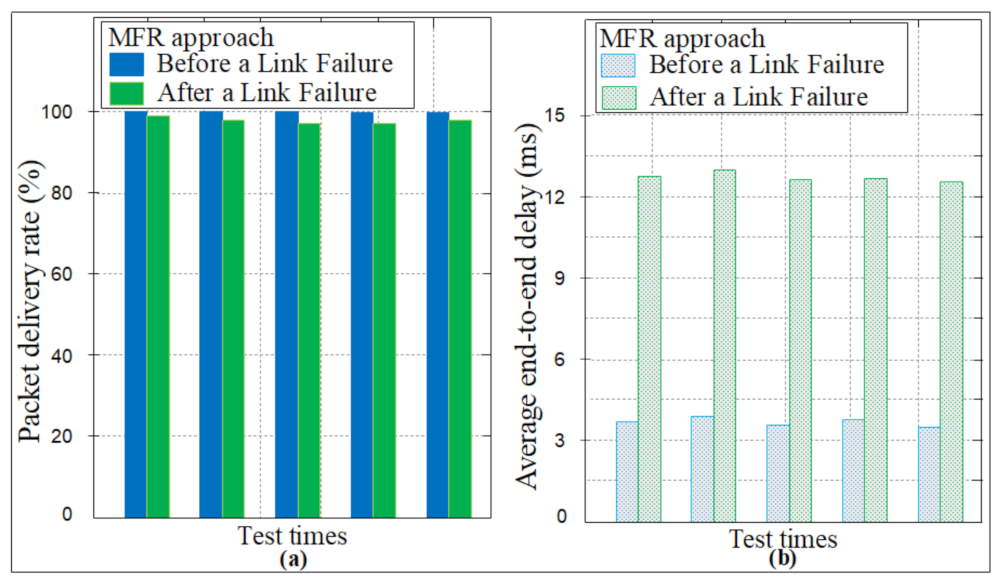
4.2.4. Packet Loss Rate (PLR)
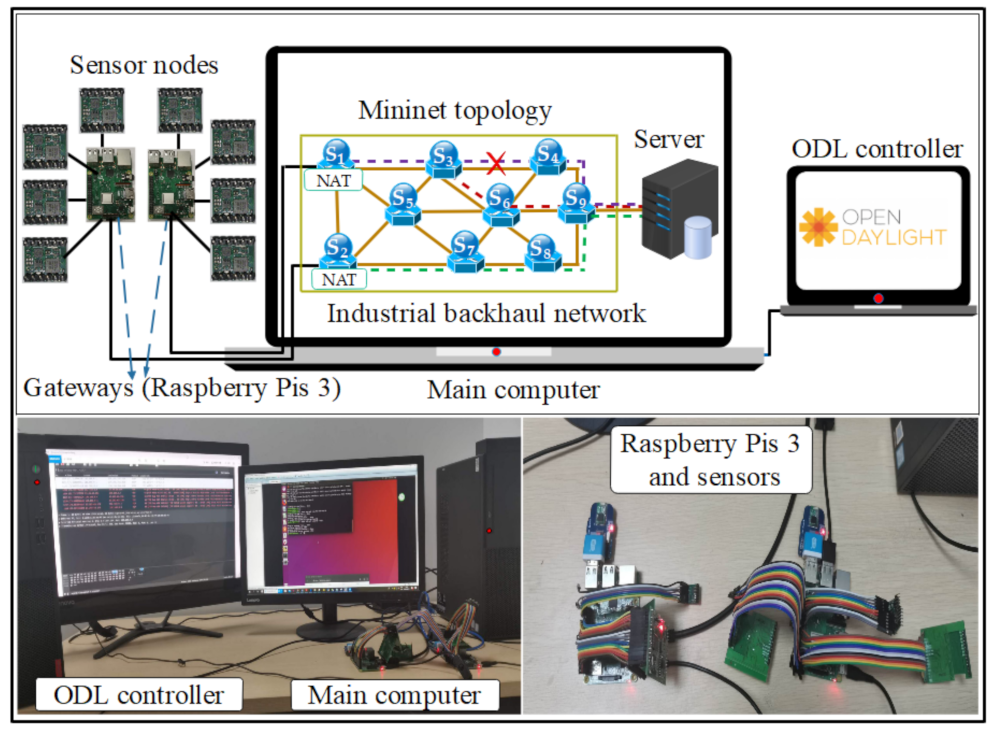
4.3. Experimental Testbed Setup and Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Latif, Z.; Sharif, K.; Li, F.; Karim, M.M.; Biswas, S.; Wang, Y. A comprehensive survey of interface protocols for software defined networks. J. Netw. Comput. Appl. 2020, 156, 102563. [Google Scholar] [CrossRef] [Green Version]
- Bera, S.; Misra, S.; Vasilakos, A.V. Software-defined networking for internet of things: A survey. IEEE Intern. Things J. 2017, 4, 1994–2008. [Google Scholar] [CrossRef]
- Josbert, N.N.; Ping, W.; Wei, M.; Muthanna, M.S.A.; Rafiq, A. A Framework for Managing Dynamic Routing in Industrial Networks Driven by Software-Defined Networking Technology. IEEE Access 2021, 9, 74343–74359. [Google Scholar] [CrossRef]
- Li, D.; Zhou, M.T.; Zeng, P.; Yang, M.; Zhang, Y.; Yu, H. Green and reliable software-defined industrial networks. IEEE Commun. Mag. 2016, 54, 30–37. [Google Scholar] [CrossRef]
- Fonseca, P.C.; Mota, E.S. A survey on fault management in software-defined networks. IEEE Commun. Surv. Tutor. 2017, 19, 2284–2321. [Google Scholar] [CrossRef]
- Ali, J.; Lee, G.M.; Roh, B.H.; Ryu, D.K.; Park, G. Software-defined networking approaches for link failure recovery: A survey. Sustainability 2020, 12, 4255. [Google Scholar] [CrossRef]
- Zurawski, R. Switched Ethernet in Automation. In Industrial Communication Technology Handbook, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2014; pp. 1–1756. [Google Scholar]
- Guimaraes, A.P.; Oliveira, H.M.N.; Barros, R.; Maciel, P.R. Availability analysis of redundant computer networks: A strategy based on reliability importance. In Proceedings of the 2011 IEEE 3rd International Conference on Communication Software and Networks, Xi’an, China, 27–29 May 2011; pp. 328–332. [Google Scholar]
- Åkerberg, J.; Gidlund, M.; Björkman, M. Future research challenges in wireless sensor and actuator networks targeting industrial automation. In Proceedings of the 2011 9th IEEE International Conference on Industrial Informatics, Lisbon, Portugal, 26–29 July 2011; pp. 410–415. [Google Scholar]
- Ali, I.; Hussain, S.S. Control and management of distribution system with integrated DERs via IEC 61850 based communication. Eng. Sci. Technol. Int. J. 2017, 20, 956–964. [Google Scholar] [CrossRef]
- Mahmoodi, T.; Kulkarni, V.; Kellerer, W.; Mangan, P.; Zeiger, F.; Spirou, S.; Askoxylakis, I.; Vilajosana, X.; Einsiedler, H.J.; Quittek, J. VirtuWind: Virtual and programmable industrial network prototype deployed in operational wind park. Trans. Emerg. Telecommun. Technol. 2016, 27, 1281–1288. [Google Scholar] [CrossRef] [Green Version]
- Saha, N.; Bera, S.; Misra, S. Sway: Traffic-aware QoS routing in software-defined IoT. IEEE Trans. Emerg. Top. Comput. 2018, 9, 390–401. [Google Scholar] [CrossRef] [Green Version]
- Schulz, P.; Matthe, M.; Klessig, H.; Simsek, M.; Fettweis, G.; Ansari, J.; Ashraf, S.A.; Almeroth, B.; Voigt, J.; Riedel, I.; et al. Latency critical IoT applications in 5G: Perspective on the design of radio interface and network architecture. IEEE Commun. Mag. 2017, 55, 70–80. [Google Scholar] [CrossRef]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Enabling fast failure recovery in openflow networks. In Proceedings of the 2011 8th International Workshop on the Design of Reliable Communication Networks (DRCN), Krakow, Poland, 10–12 October 2011; pp. 164–171. [Google Scholar]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Openflow: Meeting carrier-grade recovery requirements. Comput. Commun. 2013, 36, 656–665. [Google Scholar] [CrossRef]
- Sgambelluri, A.; Giorgetti, A.; Cugini, F.; Paolucci, F.; Castoldi, P. OpenFlow-based segment protection in Ethernet networks. J. Opt. Commun. Netw. 2013, 5, 1066–1075. [Google Scholar] [CrossRef]
- Silva, W.J.A. Avoiding Inconsistency in OpenFlow Stateful Applications Caused by Multiple Flow Requests. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 543–548. [Google Scholar]
- Chan, M.C.; Chen, C.; Huang, J.X.; Kuo, T.; Yen, L.H.; Tseng, C.C. OpenNet: A Simulator for Software-Defined Wireless Local Area Network. In Proceedings of the 2014 IEEE Wireless Communications and Networking Conference (WCNC), Istanbul, Turkey, 6–9 April 2014; pp. 3332–3336. [Google Scholar]
- De Oliveira, R.L.S.; Schweitzer, C.M.; Shinoda, A.A.; Prete, L.R. Using mininet for emulation and prototyping software-defined networks. In Proceedings of the 2014 IEEE Colombian Conference on Communications and Computing (COLCOM), Bogota, Colombia, 4–6 June 2014; pp. 1–6. [Google Scholar]
- Josbert, N.N.; Ping, W.; Wei, M.; Rafiq, A. Solution for Industrial Networks: Resilience-based SDN Technology. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; pp. 392–400. [Google Scholar]
- Muthumanikandan, V.; Valliyammai, C. Link Failure Recovery Using Shortest Path Fast Rerouting Technique in SDN. Wirel. Person. Commun. 2017, 97, 2475–2495. [Google Scholar] [CrossRef]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. In-band control, queuing, and failure recovery functionalities for OpenFlow. IEEE Netw. 2016, 30, 106–112. [Google Scholar] [CrossRef] [Green Version]
- Stephens, B.; Cox, A.L.; Rixner, S. Scalable multi-failure fast failover via forwarding table compression. In Proceedings of the Symposium on SDN Research, Santa Clara, CA, USA, 14–15 March 2016; pp. 1–12. [Google Scholar]
- Lin, Y.D.; Teng, H.Y.; Hsu, C.R.; Liao, C.C.; Lai, Y.C. Fast failover and switchover for link failures and congestion in software defined networks. In Proceedings of the 2016 IEEE International Conference on Communications, ICC 2016, Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Li, Q.; Liu, Y.; Zhu, Z.; Li, H.; Jiang, Y. BOND: Flexible failure recovery in software defined networks. Comput. Netw. 2019, 149, 1–12. [Google Scholar] [CrossRef]
- Satchou, G.A.K.; Anoh, N.G.; N’Takpé, T.; Oumtanaga, S. Optimization of the latency in networks SDN. Int. J. Comput. Commun. Control. 2018, 13, 824–836. [Google Scholar] [CrossRef]
- Zhang, X.; Cheng, Z.; Lin, R.; He, L.; Yu, S.; Luo, H. Local fast reroute with flow aggregation in software defined networks. IEEE Commun. Lett. 2016, 21, 785–788. [Google Scholar] [CrossRef]
- Al-Rubaye, S.; Kadhum, E.; Ni, Q.; Anpalagan, A. Industrial Internet of Things Driven by SDN Platform for Smart Grid Resiliency. IEEE Internet Things J. 2017, 6, 267–277. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Wei, K.; Guo, L.; Hou, W.; Wu, J. SDN-based Resilience Solutions for Smart Grids. In Proceedings of the 2016 International Conference on Software Networking (ICSN), Jeju, Korea, 23–26 May 2016; pp. 1–5. [Google Scholar]
- Vestin, J.; Kassler, A.; Åkerberg, J. FastReact: In-Network Control and Caching for Industrial Control Networks using Programmable Data Planes. In Proceedings of the 2018 IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Turin, Italy, 4–7 September 2018; pp. 219–226. [Google Scholar]
- Vestin, J.; Kassler, A.; Åkerberg, J. Resilient software defined networking for industrial control networks. In Proceedings of the 2015 10th International Conference on Information, Communications and Signal Processing (ICICS), Singapore, 2–4 December 2015; pp. 1–5. [Google Scholar]
- Adrichem, N.L.V.; Asten, B.J.V.; Kuipers, F.A. Fast Recovery in Software-Defined Networks. In Proceedings of the 2014 3rd European Workshop on Software Defined Networks, London, UK, 1–3 September 2014; pp. 61–66. [Google Scholar]
- Jhaveri, R.H.; Tan, R.; Easwaran, A.; Ramani, S.V. Managing industrial communication delays with software-defined networking. In Proceedings of the 2019 IEEE 25th International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Hangzhou, China, 18–21 May 2019; pp. 1–11. [Google Scholar]
- Babiceanu, R.F.; Seker, R. Cyber resilience protection for industrial internet of things: A software-defined networking approach. Comput. Ind. 2019, 104, 47–58. [Google Scholar] [CrossRef]
- Thorat, P.; Challa, R.; Raza, S.M.; Kim, D.S.; Choo, H. Proactive failure recovery scheme for data traffic in software defined networks. In Proceedings of the 2016 IEEE NetSoft Conference and Workshops (NetSoft), Seoul, Korea, 6–10 June 2016; pp. 219–225. [Google Scholar]
- Wang, L.; Yao, L.; Xu, Z.; Wu, G.; Obaidat, M.S. CFR: A cooperative link failure recovery scheme in software-defined networks. Int. J. Commun. Syst. 2018, 31, e3560. [Google Scholar] [CrossRef]
- Pfaff, B.; Lantz, B.; Heller, B.; Barker, C.; Cohn, D.; Talayco, D.; Erickson, D.; Crabbe, E.; Gibb, G.; Appenzeller, G.; et al. OpenFlow 1.1 Specification; Open Networking Foundation: Menlo Park, CA, USA, 2011; pp. 1–56. [Google Scholar]
- Wang, Z.; Crowcroft, J. Quality-of-service routing for supporting multimedia applications. IEEE J. Sel. Areas Commun. 1996, 14, 1228–1234. [Google Scholar] [CrossRef] [Green Version]
- Thubert, P.; Palattella, M.R.; Engel, T. 6TiSCH Centralized Scheduling: When SDN meet IoT. In Proceedings of the 2015 IEEE Conference on Standards for Communications and Networking (CSCN), Tokyo, Japan, 28–30 October 2015; pp. 42–47. [Google Scholar]
- Dujovne, D.; Watteyne, T.; Vilajosana, X.; Thubert, P. 6TiSCH: Deterministic IP-enabled industrial internet (of things). IEEE Commun. Mag. 2014, 52, 36–41. [Google Scholar] [CrossRef]
- Wang, P.; Wang, H.; Zhang, C. SDN-Based WIA-PA Field Network/ipv6 Backhaul Network Joint Scheduling Method. U.S. Patent 10,306,706, 28 May 2019. [Google Scholar]
- Pfaff, B.; Pettit, J.; Koponen, T.; Jackson, E.; Zhou, A.; Rajahalme, J.; Gross, J.; Wang, A.; Stringer, J.; Shelar, P.; et al. The design and implementation of open vswitch. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation, NSDI 15, Oakland, CA, USA, 4–6 May 2015; USENIX Association: Berkeley, CA, USA, 2015; pp. 117–130. [Google Scholar]
- Beshir, A.A.; Kuipers, F.A. Variants of the min-sum link-disjoint paths problem. In Proceedings of the 16th Annual IEEE Symposium on Communications and Vehicular Technology (IEEE SCVT’09), IEEE/SCVT, Louvain-la-Neuve, Belgium, 19 November 2009; pp. 1–6. [Google Scholar]
- AMPL. A Mathematical Programming Language. Available online: http://www.ampl.com/ (accessed on 11 September 2021).
- Oki, E. Disjoint path routing. In Linear Programming and Algorithms for Communication Networks: A Practical Guide to Network Design, Control, and Management, 1st ed.; CRC Press: Boca Raton, FL, USA, 2012; pp. 1–192. [Google Scholar]
- Gurobi, I. Optimization, Gurobi Optimizer Reference Manual. 2016. Available online: https://www.gurobi.com (accessed on 13 August 2021).
- Jaffe, J.M. Algorithms for finding paths with multiple constraints. Networks 1980, 14, 95–116. [Google Scholar] [CrossRef]
- Al-Jawad, A.; Shah, P.; Gemikonakli, O.; Trestian, R. Policy-based QoS management framework for software-defined networks. In Proceedings of the 2018 International Symposium on Networks, Computers and Communications (ISNCC), Rome, Italy, 19–21 June 2018; pp. 1–6. [Google Scholar]
- Karger, D.; Lehman, E.; Leighton, T.; Panigrahy, R.; Levine, M.; Lewin, D. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the world wide web. In Proceedings of the Twenty-Ninth Annual ACM Symposium on Theory of Computing, El Paso, TX, USA, 4–6 May 1997; pp. 654–663. [Google Scholar]
- Dixit, A.; Hao, F.; Mukherjee, S.; Lakshman, T.V.; Kompella, R. Towards an elastic distributed SDN controller. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 7–12. [Google Scholar] [CrossRef]
- Oktian, Y.E.; Lee, S.; Lee, H.; Lam, J. Distributed SDN controller system: A survey on design choice. Comput. Netw. 2017, 121, 100–111. [Google Scholar] [CrossRef]
- Cholda, P.; Jajszczyk, A. Recovery and Its Quality in Multilayer Networks. J. Lightw. Technol. 2009, 28, 372–389. [Google Scholar] [CrossRef]
- Iqbal, F.; Kuipers, F.A. Disjoint paths in networks. Wiley Encycl. Electr. Electron. Eng. 2015, 4, 1–14. [Google Scholar]
- OpenDaylight. Available online: https://www.opendaylight.org/ (accessed on 15 August 2021).
- Knight, S.; Nguyen, H.X.; Falkner, N.; Bowden, R.; Roughan, M. The internet topology zoo. IEEE J. Sel. Areas Commun. 2011, 29, 1765–1775. [Google Scholar] [CrossRef]
- Apache FtpServer. Available online: http://mina.apache.org/ftpserver-project/ (accessed on 17 August 2021).
- Stanford-Clark, A.; Truong, H.L. MQTT For Sensor Networks (MQTT-SN); Protocol Specification Version 1.2.; IBM: Armonk, NY, USA, 2013. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Sort | Key Metrics | Approval |
|---|---|---|---|
| Al-Rubaye et al. [28] | Restoration | End-to-end latency and data traffic flow | Simulation |
| Zhang et al. [29] | Restoration | CPU utilization of SDN controller (NOX) and its average, end-to-end delay and its average | Simulation |
| Vestin et al. [30] | Protection | Delay, network load, message reception interval, and request-response time | Prototype |
| Jhaveri et al. [33] | Restoration | Estimated end-to-end delay, average throughput, path restoration delay, and success rate | Simulation |
| Muthumanikandan et al. [21] | Restoration | Recovery time, response time, throughput, and latency | Simulation |
| Satchou et al. [26] | Restoration and protection | Latency when there is a failure | Simulation |
| Li et al. [24] | Restoration and protection | Average recovery time, controller processing time, flow entries, PLR, and link congestion | Simulation |
| Adrichem et al. [32] | Protection | Recovery time | Prototype |
| Zhang et al. [27] | Restoration | Failure recover time and number of flow entries | Simulation |
| MFR | Mixed of protection and restoration based on the dynamic hash table | Failure recovery time, end-to-end delay, PLR, lookup time, and packet delivery rate | Simulation and testbed |
| Notation | Description |
|---|---|
| G is an undirected graph, where V is | |
| the set of nodes (switches | |
| and gateways) and E is the set of links. | |
| the link from node i to node j. | |
| the scale factor for the delay (d). | |
| the scale factor for the loss (l). | |
| the source node of the path k. | |
| the destination node of the path k. | |
| the delay of the link . | |
| the packet-loss probability on the link . | |
| the weight of the link , computed as . | |
| The number of the flow corresponding to | |
| the path sent on the link . | |
| the maximum tolerable delay. | |
| the maximum tolerable loss. | |
| the bandwidth available on the link . | |
| the bandwidth required by the path k. | |
| the primary path from gateway (GW) A. | |
| the primary path from GW B. | |
| the secondary path from GW A. | |
| the secondary path from GW B. | |
| the switches across the . | |
| the flow rules corresponding to the . | |
| the switches across the appropriate . | |
| the flow rules corresponding to the . | |
| the switches across the . | |
| the switches across the appropriate . | |
| f | the failed link in the network topology. |
| the flow rules corresponding to the . | |
| the flow rules corresponding to the . | |
| the number of intermediate switches on the . | |
| the number of intermediate switches on the . | |
| the number of intermediate switches on the . | |
| the number of intermediate switches on the . | |
| working_path_A | the optimum path used for sending the |
| packets from GW A to the destination. | |
| working_path_B | the optimum path used for sending the |
| packets from GW B to the destination. | |
| HT | the hash table. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Josbert, N.N.; Ping, W.; Wei, M.; Li, Y. Industrial Networks Driven by SDN Technology for Dynamic Fast Resilience. Information 2021, 12, 420. https://doi.org/10.3390/info12100420
Josbert NN, Ping W, Wei M, Li Y. Industrial Networks Driven by SDN Technology for Dynamic Fast Resilience. Information. 2021; 12(10):420. https://doi.org/10.3390/info12100420
Chicago/Turabian StyleJosbert, Nteziriza Nkerabahizi, Wang Ping, Min Wei, and Yong Li. 2021. "Industrial Networks Driven by SDN Technology for Dynamic Fast Resilience" Information 12, no. 10: 420. https://doi.org/10.3390/info12100420
APA StyleJosbert, N. N., Ping, W., Wei, M., & Li, Y. (2021). Industrial Networks Driven by SDN Technology for Dynamic Fast Resilience. Information, 12(10), 420. https://doi.org/10.3390/info12100420