
A Markov Chain Monte Carlo Algorithm for Spatial Segmentation


Abstract
:1. Introduction
2. The Spatial Segmentation Problem
3. The Generalized Gibbs Sampler
- Q-step: Given , generate Y from
- R-step: Given Y generate from .
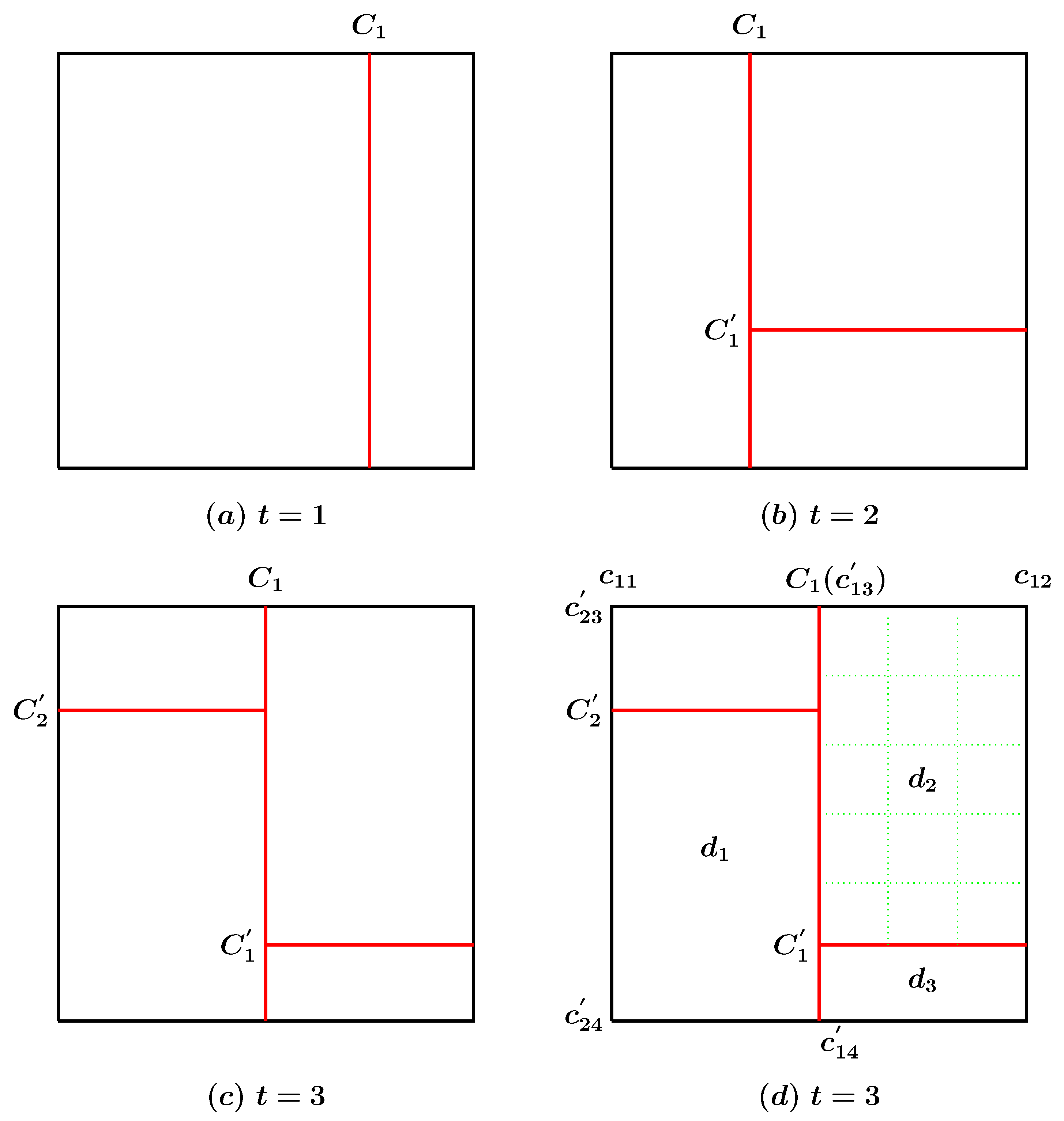
4. The GGS for the Spatial Segmentation Problem
- Calculate the weights for and .
- Select an element with probabilities proportional to the weights calculated in Step 1.
- If is selected, update by sampling from a beta distribution with parameters and . Otherwise, if is selected, insert a new cut at and select new Bernoulli parameters for domains and by sampling from beta distributions with parameters and , respectively.
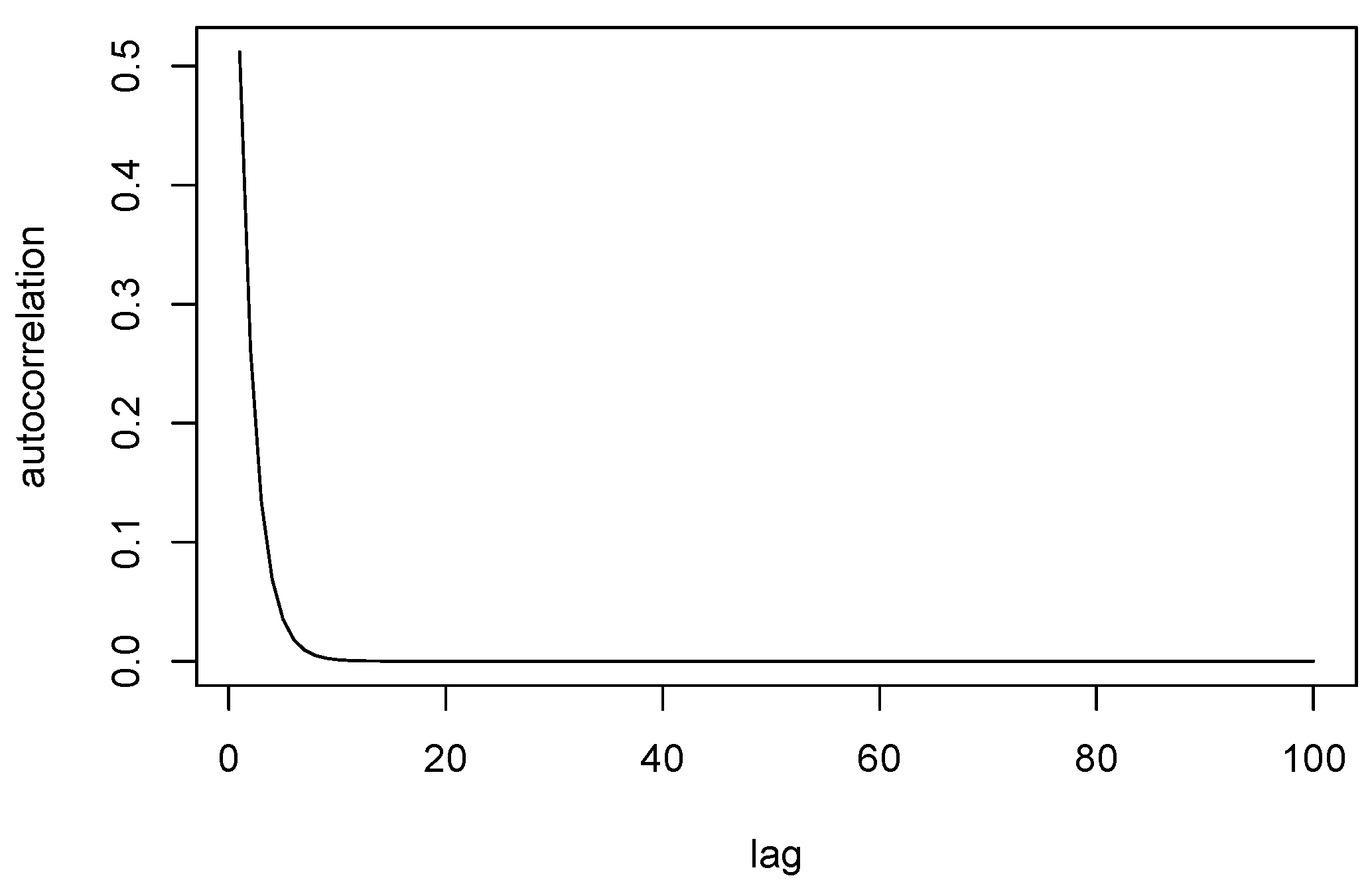
5. Numerical Results
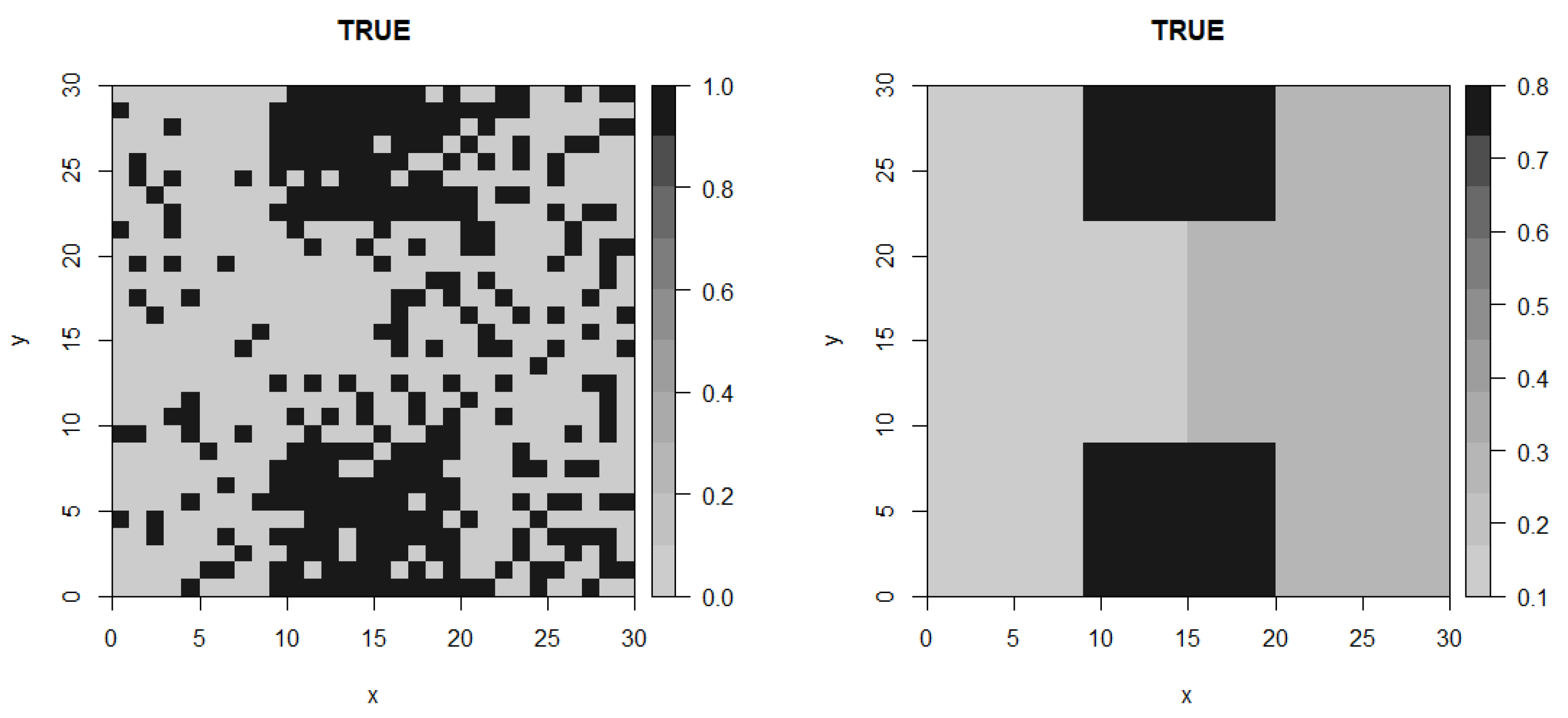
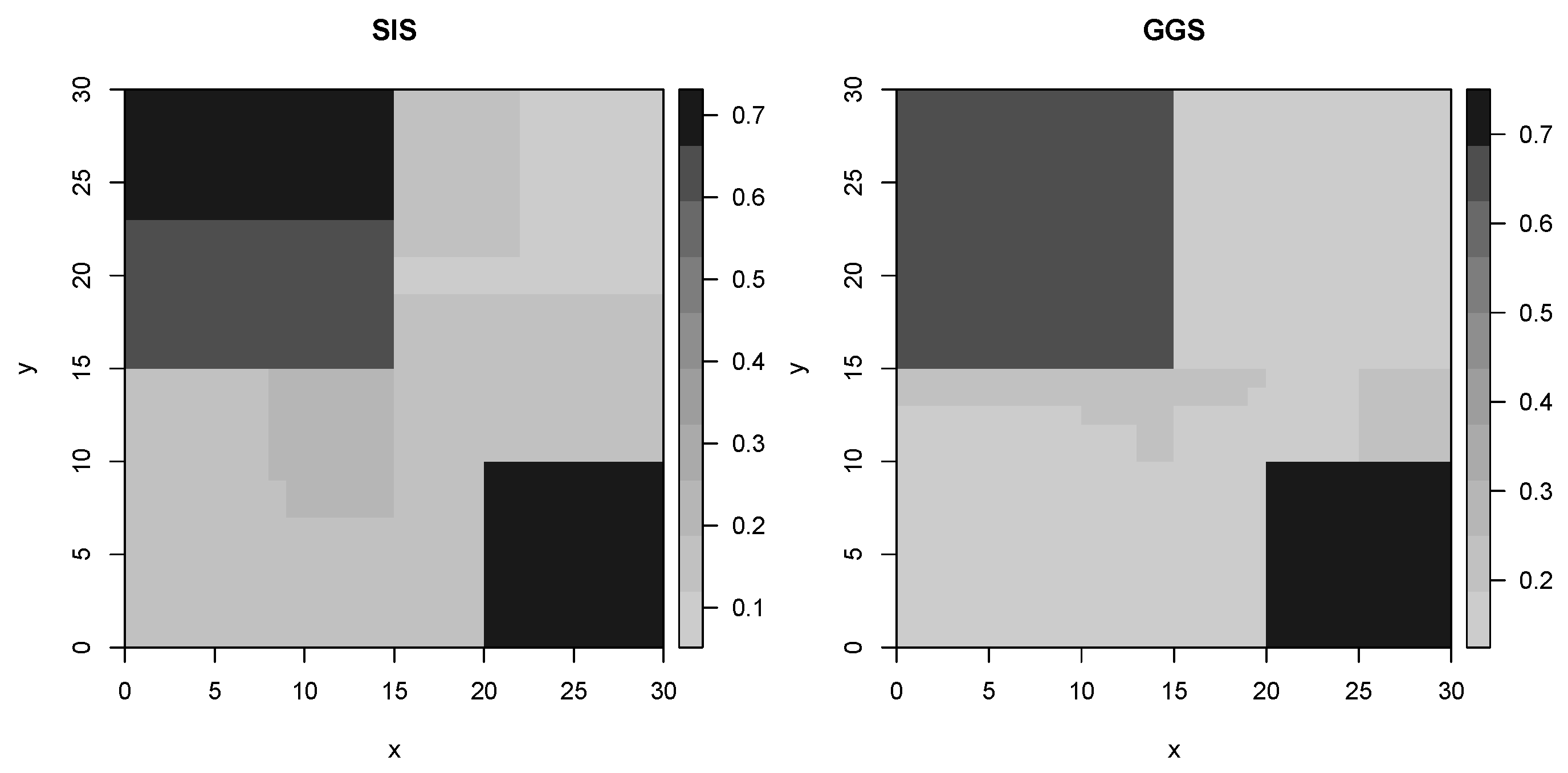
5.1. Artificial Data: Example 1
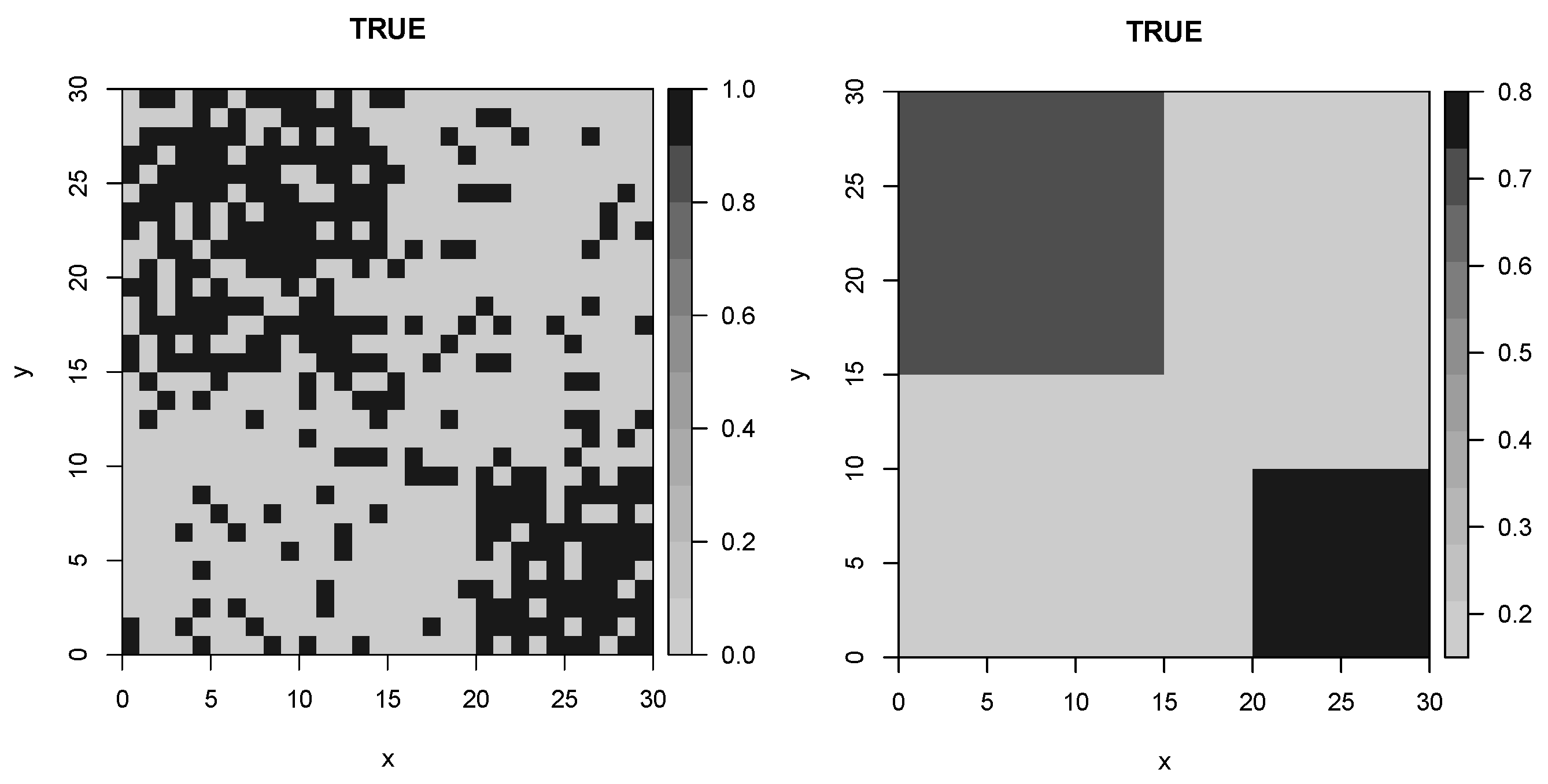
5.2. Artificial Data: Example 2
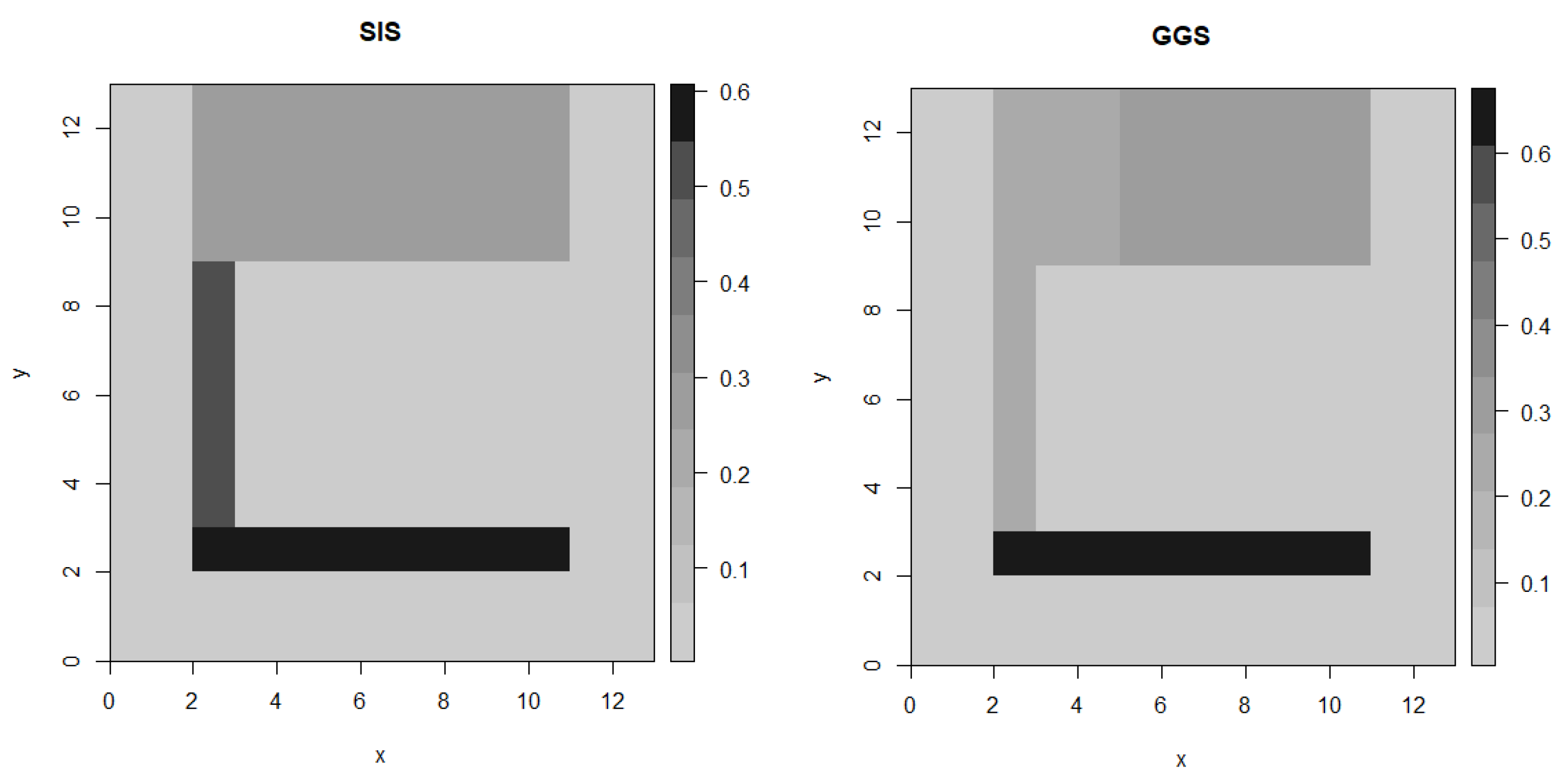
5.3. Real Data
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BIC | Bayesian Information Criterion |
| GGS | Generalized Gibbs Sampler |
| MCMC | Markov Chain Monte Carlo |
| RMSE | Root Mean Squared Error |
| SIS | Sequential Importance Sampling |
References
- Chen, S.S.; Gopalakrishnan, P.S. Clustering via the Bayesian information criterion with applications in speech recognition. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), Seattle, WA, USA, 15 May 1998; pp. 645–648. [Google Scholar] [CrossRef]
- Tung, A.K.; Hou, J.; Han, J. Spatial clustering in the presence of obstacles. In Proceedings of the Data Engineering: 17th International Conference on IEEE, Heidelberg, Germany, 2–6 April 2001; pp. 359–367. [Google Scholar] [CrossRef] [Green Version]
- Gangnon, R.E.; Clayton, M.K. Bayesian detection and modeling of spatial disease clustering. Biometrics 2000, 3, 922–935. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anderson, C.; Lee, D.; Dean, N. Bayesian cluster detection via adjacency modelling. Spat. Spatio-Temporal Epidemiol. 2016, 11–20. [Google Scholar] [CrossRef] [Green Version]
- Beckage, B.; Joseph, L.; Belisle, P.; Wolfson, D.B.; Platt, W.J. Bayesian change-point analyses in ecology. New Phytol. 2007, 11–20. [Google Scholar] [CrossRef] [PubMed]
- López, I.; Gámez, M.; Garay, J.; Standovár, T.; Varga, Z. Applications of change-point problem to the detection of plant patches. Acta Biotheor. 2010, 51–63. [Google Scholar] [CrossRef] [PubMed]
- Raveendran, N.; Sofronov, G. Binary segmentation methods for identifying boundaries of spatial domains. Comput. Sci. Inf. Syst. (FedCSIS) 2017, 3, 95–102. [Google Scholar]
- Tripathi, S.; Govindaraju, R.S. Change detection in rainfall and temperature patterns over India. In Proceedings of the Third International Workshop on Knowledge Discovery from Sensor Data, Paris, France, 28 June 2009; ACM: New York, NY, USA, 2009; pp. 133–141. [Google Scholar] [CrossRef]
- Helterbr, J.D.; Cressie, N.; Davidson, J.L. A statistical approach to identifying closed object boundaries in images. Adv. Appl. Probab. 1994, 831–854. [Google Scholar] [CrossRef]
- Wang, Y. Change curve estimation via wavelets. J. Am. Stat. Assoc. 1998, 441, 163–172. [Google Scholar] [CrossRef]
- Sfetsos, A.; Siriopoulos, C. Time series forecasting with a hybrid clustering scheme and pattern recognition. IEEE Trans. Syst. Mancybernetics Part A Syst. Hum. 2004, 34, 399–405. [Google Scholar] [CrossRef]
- Arbia, G.; Espa, G.; Quah, D. A class of spatial econometric methods in the empirical analysis of clusters of firms in the space. Empir. Econ. 2008, 34, 81–103. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Chuangang, Y.U.; Juying, Z. Constructing the Regional Intelligent Economic Decision Support System Based on Fuzzy C-Mean Clustering Algorithm; Soft Computing; Springer: Berlin, Germany, 2019; pp. 1–9. [Google Scholar]
- Sofronov, G. A hybrid algorithm for spatial small area estimation under models with complex contiguity. In Proceedings of the 2013 IEEE Symposium on Differential Evolution (SDE), Singapore, 16–19 April 2013; pp. 25–30. [Google Scholar]
- Fan, C.; Nhien-An, L.; Tahar, K. Clustering approaches for financial data analysis: A survey. arXiv 2016, arXiv:1609.08520. [Google Scholar]
- Besag, J. Spatial interaction and the statistical analysis of lattice systems. J. R. Stat. Soc. Ser. B (Methodol.) 1979, 36, 192–236. [Google Scholar] [CrossRef]
- Sherman, M.; Apanasovich, T.V.; Carroll, R.J. On estimation in binary autologistic spatial models. J. Stat. Comput. Simul. 2006, 76, 167–179. [Google Scholar] [CrossRef]
- Wu, H.; Huffer, F.R.W. Modelling the distribution of plant species using the autologistic regression model. Environ. Ecol. Stat. 1997, 4, 31–48. [Google Scholar] [CrossRef]
- Moller, J.; Pettitt, A.N.; Reeves, R.; Berthelsen, K.K. An efficient Markov chain Monte Carlo method for distributions with intractable normalising constants. Biometrika 2006, 93, 451–458. [Google Scholar] [CrossRef] [Green Version]
- Hughes, J.; Haran, M.; Caragea, P.C. Autologistic models for binary data on a lattice. Environmetrics 2011, 22, 857–871. [Google Scholar] [CrossRef]
- Liang, F. A double Metropolis-Hastings sampler for spatial models with intractable normalizing constants. J. Stat. Comput. Simul. 2010, 80, 1007–1022. [Google Scholar] [CrossRef]
- Keith, J.M.; Kroese, D.P.; Bryant, D.A. Generalized Markov Sampler. Methodol. Comput. Appl. Probab. 2004, 6, 29–53. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Gupta, A.K. Parametric Statistical Change Point Analysis: With Applications to Genetics, Medicine, and Finance; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Eckley, I.A.; Fearnhead, P.; Killick, R. Analysis of changepoint models. In Bayesian Time Series Models; Barber, D., Chiappa, A.T., Cemgil, S., Eds.; Cambridge University Press: Cambridge, UK, 2011; pp. 205–224. [Google Scholar]
- Priyadarshana, W.J.R.M.; Sofronov, G. Multiple Break-Points Detection in Array CGH Data via the Cross-Entropy Method. IEEE/ACM Trans. Comput. Biol. Bioinform. 2015, 12, 487–498. [Google Scholar] [CrossRef]
- Keith, J.; Sofronov, G.; Kroese, D. The Generalized Gibbs Sampler and the Neighborhood Sampler. In Monte Carlo and Quasi-Monte Carlo Methods; Keller, A., Heinrich, S., Niederreiter, H., Eds.; Springer: Berlin, Germany, 2006; pp. 537–547. [Google Scholar]
- Sadia, F.; Boyd, S.; Keith, J.M. Bayesian change-point modeling with segmented ARMA model. PLoS ONE 2018, 13, e0208927. [Google Scholar] [CrossRef]
- Phillips, D.B.; Smith, A.F.M. Bayesian model comparison via jump diffusions. Markov Chain Monte Carlo Pract. 1995, 215, 239. [Google Scholar]
- Green, P.J. Reversible jump Markov Chain Monte Carlo computation and Bayesian model determination. Biometrika 1995, 82, 711–732. [Google Scholar] [CrossRef]
- Sofronov, G.Y.; Glotov, N.V.; Zhukova, O.V. Statistical analysis of spatial distribution in populations of microspecies of Alchemilla L. In Proceedings of the 30th International Workshop on Statistical Modelling, Linz, Austria, 6–10 July 2015; Friedl, H., Wagner, H., Eds.; Statistical Modelling Society: Linz, Austria, 2015; pp. 259–262. [Google Scholar]
- Raveendran, N.; Sofronov, G.Y. Identifying Clusters in Spatial Data via Sequential Importance Sampling. In Recent Advances in Computational Optimization; Fidanova, S., Ed.; Studies in Computational Intelligence Springer: Cham, Switzerland, 2019; pp. 175–189. [Google Scholar]
- Geyer, C. Introduction to Markov Chain Monte Carlo. In Handbook of Markov Chain Monte Carlo; Brooks, S., Gelman, A., Jones, G.L., Meng, X., Eds.; Hall/CRC: Chapman, CA, USA, 2011. [Google Scholar]
- Keith, J.M.; Kroese, D.P.; Sofronov, G. Adaptive independence samplers. Stat. Comput. 2008, 18, 409–420. [Google Scholar] [CrossRef] [Green Version]
- Liu, S. Monte Carlo Strategies in Scientific Computing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Sofronov, G.Y.; Evans, G.E.; Keith, J.M.; Kroese, D.P. Identifying Change-points in Biological Sequences via Sequential Importance Sampling. Environ. Model. Assess. 2009, 14, 577–584. [Google Scholar] [CrossRef]
- Evans, G.E.; Sofronov, G.Y.; Keith, J.M.; Kroese, D.P. Estimating change-points in biological sequences via the Cross-Entropy method. Ann. Oper. Res. 2011, 189, 155–165. [Google Scholar] [CrossRef] [Green Version]
- Algama, M.; Keith, J.M. Investigating genomic structure using changept: A Bayesian segmentation model. Comput. Struct. Biotechnol. J. 2014, 10, 107–115. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domains | Coordinates (Bottom Left to Top Right) | Probability () |
|---|---|---|
| Domain 1 | (0,0)–(30,10) | |
| Domain 2 | (1,10)–(8,20) | |
| Domain 3 | (8,10)–(22,15) | |
| Domain 4 | (8,15)–(22,20) | |
| Domain 5 | (1,20)–(30,30) | |
| Domain 6 | (22,10)–(30,20) |
| Algorithm | RMSE | Computational Time (s) |
|---|---|---|
| GGS | 0.04419 | 30.2928 |
| SIS | 0.06421 | 34.5378 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raveendran, N.; Sofronov, G. A Markov Chain Monte Carlo Algorithm for Spatial Segmentation. Information 2021, 12, 58. https://doi.org/10.3390/info12020058
Raveendran N, Sofronov G. A Markov Chain Monte Carlo Algorithm for Spatial Segmentation. Information. 2021; 12(2):58. https://doi.org/10.3390/info12020058
Chicago/Turabian StyleRaveendran, Nishanthi, and Georgy Sofronov. 2021. "A Markov Chain Monte Carlo Algorithm for Spatial Segmentation" Information 12, no. 2: 58. https://doi.org/10.3390/info12020058
APA StyleRaveendran, N., & Sofronov, G. (2021). A Markov Chain Monte Carlo Algorithm for Spatial Segmentation. Information, 12(2), 58. https://doi.org/10.3390/info12020058