Image classification which belongs to the main research content of image processing has a broad application prospect in many sciences, such as object recognition, content understanding and image matching. Support vector machine (SVM) [
1], k-nearest neighbor (KNN) [
2] and decision tree (DT) [
3] are all typical machine learning methods applied in this field. These studies prove the effectiveness and reliability of machine learning applied in image classification. In essence, process of the image classification is regarded abstractly as the composition of feature extraction and feature classification: First, the model extracts significant features and helps the latter classifier distinguish features better. Second, the classifier accepts extracted features and identifies them effectively. Feature extraction is an important part of image classification system. In image classification task, extracted feature quality directly affects performance of classification. The previous classifications did not fully extract information from image feature until neural network (NN) was applied to image classification, and image classification quickly became an important research direction in this field. Theoretically, NN can approximate any complex function and effectively solve the problem of image feature extraction. Except for image classification, neural networks have made continuous breakthroughs in target detection [
4,
5], face recognition [
6,
7] and other fields. Among them, CNN is an efficient neural network learning model, whose convolution kernel in the convolutional layer plays an important role in the extraction of features. The features of images are extracted automatically by convolution, and hierarchical structure of CNN can learn high-quality features at each layer. Although CNN is considered as the one of most powerful and effective feature extraction mechanism, the traditional classifier lay of CNN cannot fully grasp the information of feature extracted, which as single classifier cannot perform well in the face of diverse and complex data features. On the basis of the “No Free Lunch” theorem [
8], for different structures and characteristics of changeable data, the prediction accuracy is greatly limited by a single classifier. Ensemble learning combines multiple classifiers that process different hypotheses to construct a better hypothesis and obtain excellent predictions. Dietterich [
9] explained three basic reasons for the success of ensemble learning from three mathematical perspective: statistics, calculation and representativeness. In addition, the bias variance decomposition analyzes the effectiveness of ensemble learning [
10]. Kearns and Valiant [
11] showed that weak classifiers can generate high precision estimates by integrating, as long as data is sufficient. These studies proved that ensemble learning has a better learning ability than a single classifier. Furthermore, Chen [
12] proposed an advanced gradient boosting algorithm, the extreme gradient boosting tree (XGBoost), that has obtained good results in Kaggle data competitions. XGBoost has been widely used in image classification [
7,
13] and has good performance. Ren et al. [
14] proposed an image classification method based on CNN and XGBoost. In this model, CNN is used to obtain features from the input, and XGBoost as a recognizer produces results to provide more accurate output. The experimental results on MNIST and CIFAR-10 show that the performance of this method is better than other methods, which verifies the effectiveness of the combination of CNN and XGBoost in image classification.
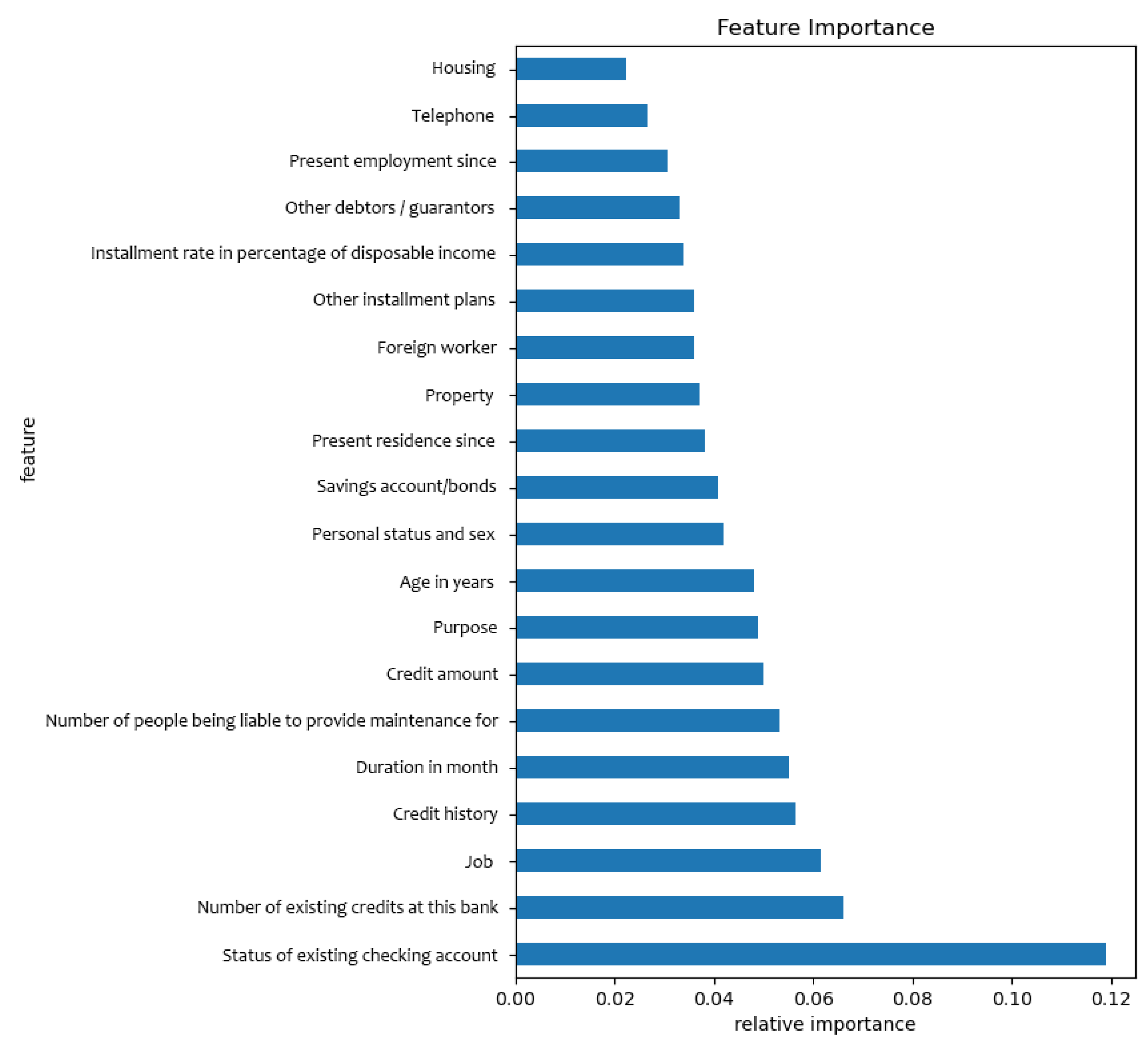
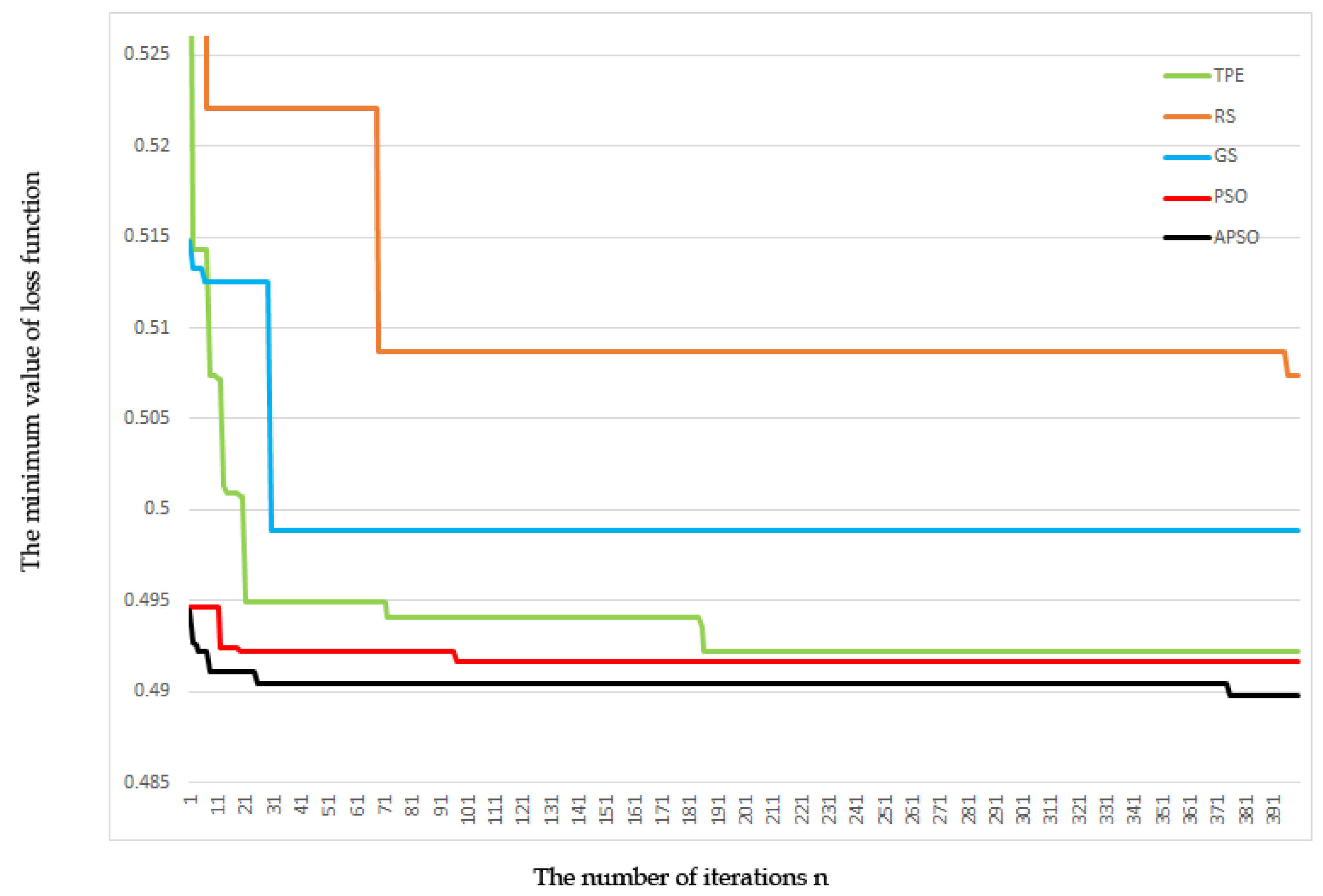
Good performance of models depends on the proper hyper-parameter settings. The hyper-parameters directly affect the structure of models and the performance of the model, so it is particularly important to tune the hyper-parameters appropriately. Generally, models rely on artificial experience tuning, which consumes a great deal of time and computing resources. Hyper-parameter optimization has been used to tune hyper-parameters to overcome the shortage of manual tuning. Most optimization of hyper-parameters performs in a continuous search space. Particle swarm optimization (PSO), originally proposed by Kennedy and Eberhart [
15], is a computational intelligence technique. The original PSO algorithm was mainly designed for the optimization of a continuous space owing to the quantities describing the particle state and its motion laws being continuous real numbers. Song and Rama [
16] proposed a XGBoost model combining the improved PSO algorithm to determine the relationship between tensile strength and plasticity and their influencing factors. The experimental results prove the effectiveness and reliability of the method. Le et al. [
17] proposed a building thermal load forecasting and control model PSO-XGBoost. PSO optimizes the XGBoost model as predictor. The experimental results show that the proposed model is the most robust method for comparing the average absolute percentage error (MAPE), variance analysis (VAF) and other indicators of other models (XGBoost, SVM, RF, GP and CART) on the survey data of buildings. These studies prove the effectiveness of PSO to improve the performance of XGBoost learning algorithm. Therefore, PSO is more suitable for the hyper-parameter optimization. PSO finds the optimal solution through iteration, and it has a fast convergence speed. However, its disadvantage is that the states of the particles fall into a local optimum easily, thereby causing premature convergence. In response to this problem, we purpose the adaptive PSO (APSO). It uses the idea of clustering to adaptively divide the particle swarm into different populations and guide the populations by applying different update strategies. This enhances the diversity of particles and helps particles jump out of a local optimum. APSO is more suitable for the parameter optimization, and it improves the model prediction accuracy.
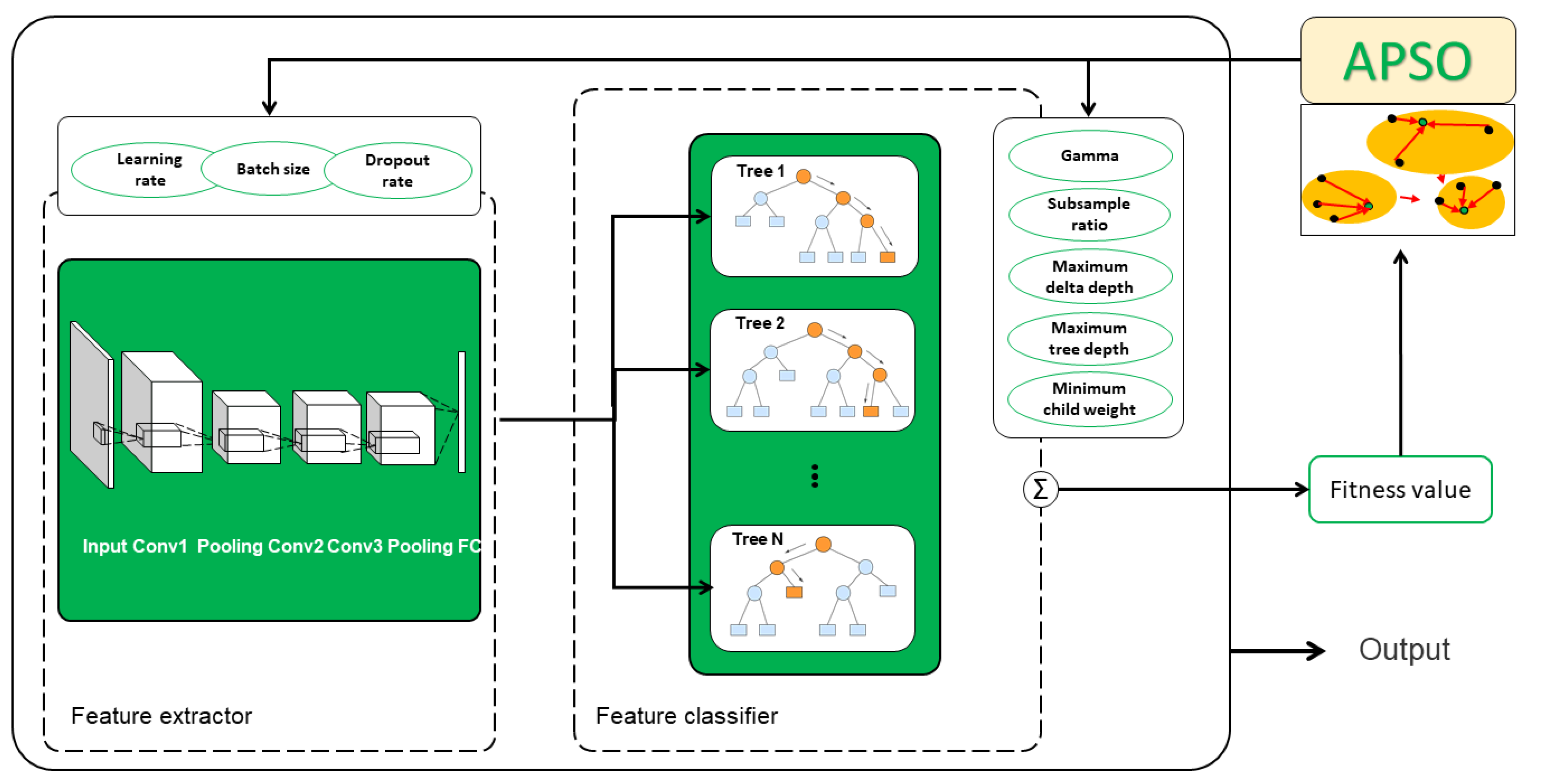
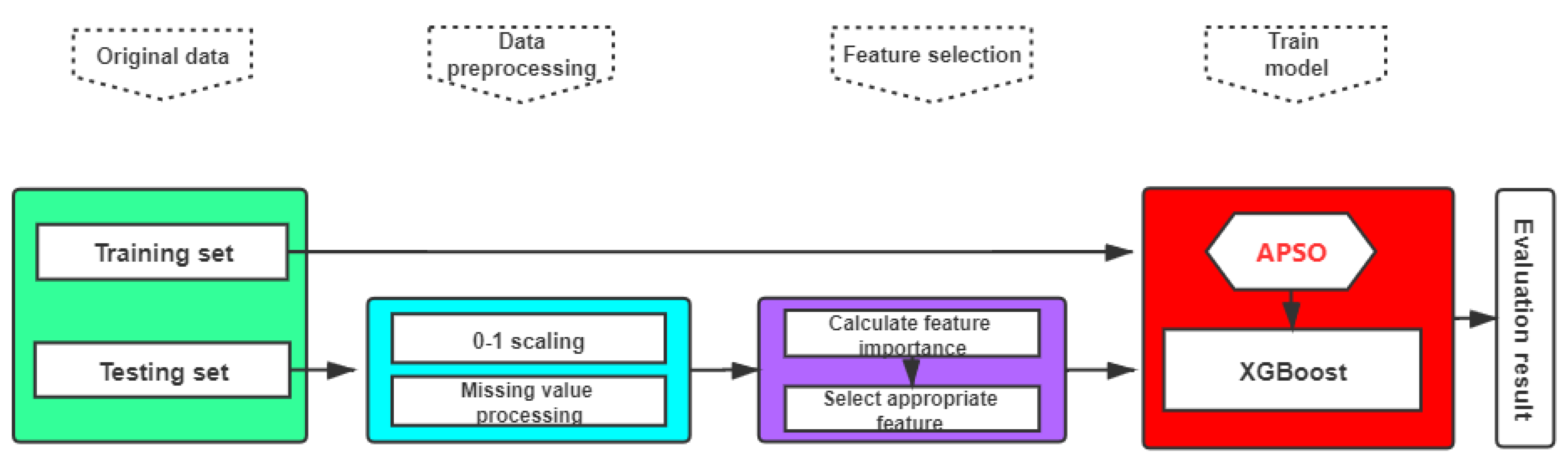
Based on the above, we propose a CNN-XGBoost based on APSO optimization for image classification. CNN is used as a feature extractor to automatically obtain features from the input, and the feature recognizer XGBoost receives the image features and then produces results; the parameter optimizer APSO is applied to optimize the structure of model to match feature, so the model gets accurate results.
Firstly, a novel two-stage fusion image classification CNN-XGBoost based on APSO is proposed. It both ensures CNN can extract image features fully and makes use of XGBoost to distinguish features effectively, so as to ensure high accuracy of image classification as a whole.
Secondly, bidirectional optimization structure is adopted, both CNN and XGBoost are optimized by APSO at the same time. For one thing, optimizing the CNN to extract deep features, so that the extracted features are more suitable for the decision trees XGBoost, and for another, optimizing XGBoost makes the structure of the model match the extracted features, so as to better understand the image features. Bidirectional optimization maintains the characteristics of the two parts themselves meanwhile allowing the two parts to combine more closely together, making the features of the image fully extracted to be used for classification.
Thirdly, the PSO algorithm is improved based on adaptive subgroup division. Two different learning strategies are adopted to update different types of particles, enhance the diversity of particle population and avoid the algorithm falling into local optimal which improves adaptive processing capability of model for image features and increases accuracy of classification.
The rest of the paper is organized as follows:
Section 1 explains the related work on the methods used.
Section 2 introduces the principle of the CNN-XGBoost based on APSO model.
Section 3 describes the experimental setup.
Section 4 reports the experimental analysis results.
Section 5 describes supplementary experiment in detail. Finally,
Section 6 concludes the paper and discusses future work.







{kind=link}
{kind=link}
{kind=link}
{kind=link}