
Individualism or Collectivism: A Reinforcement Learning Mechanism for Vaccination Decisions



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
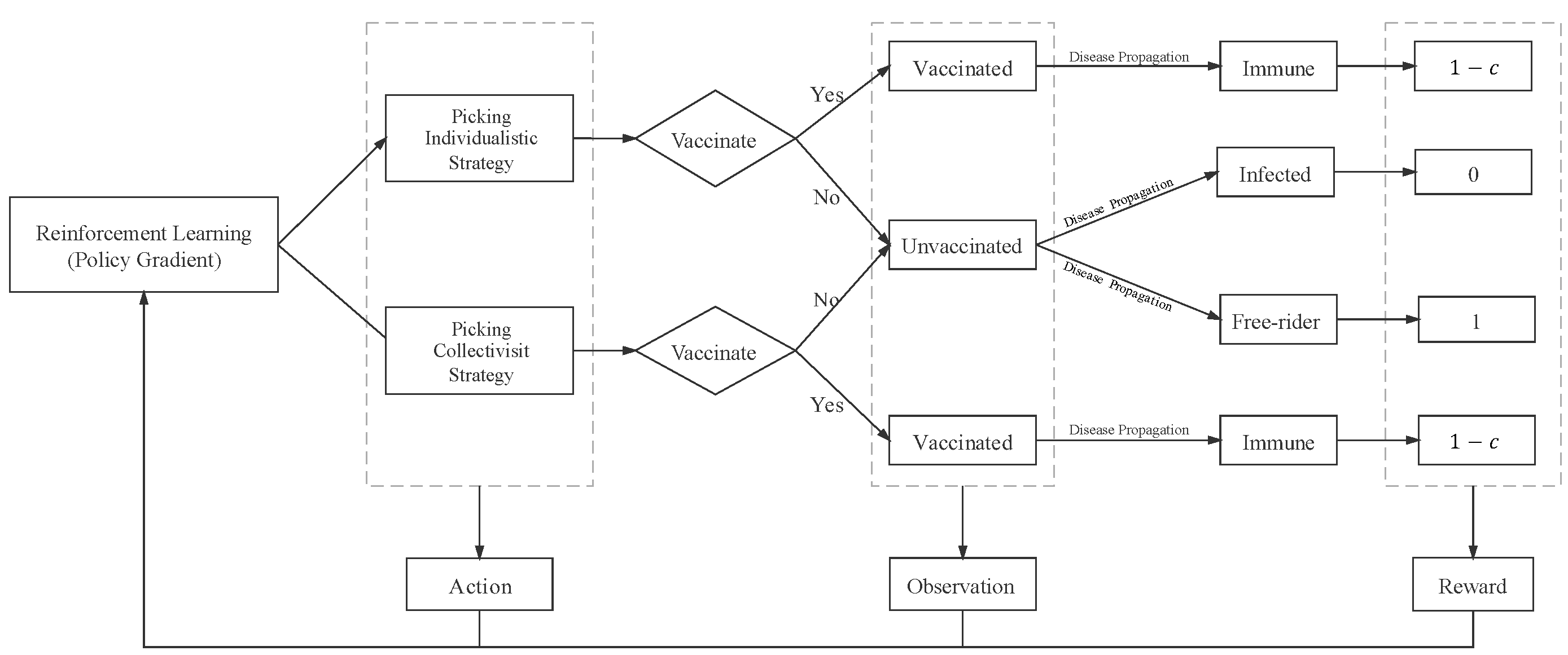
2. Methods
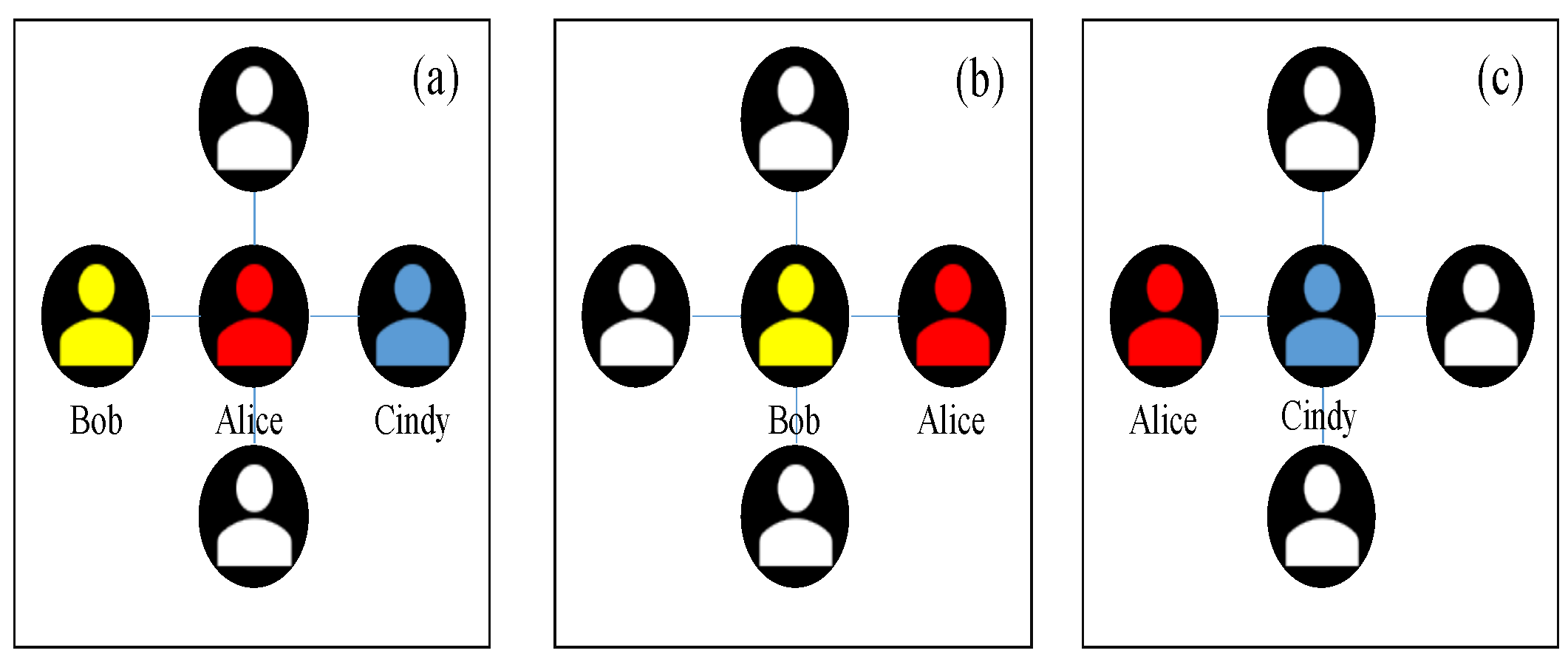
2.1. Individualistic Strategy of Vaccination
2.2. Collectivist Strategy of Vaccination
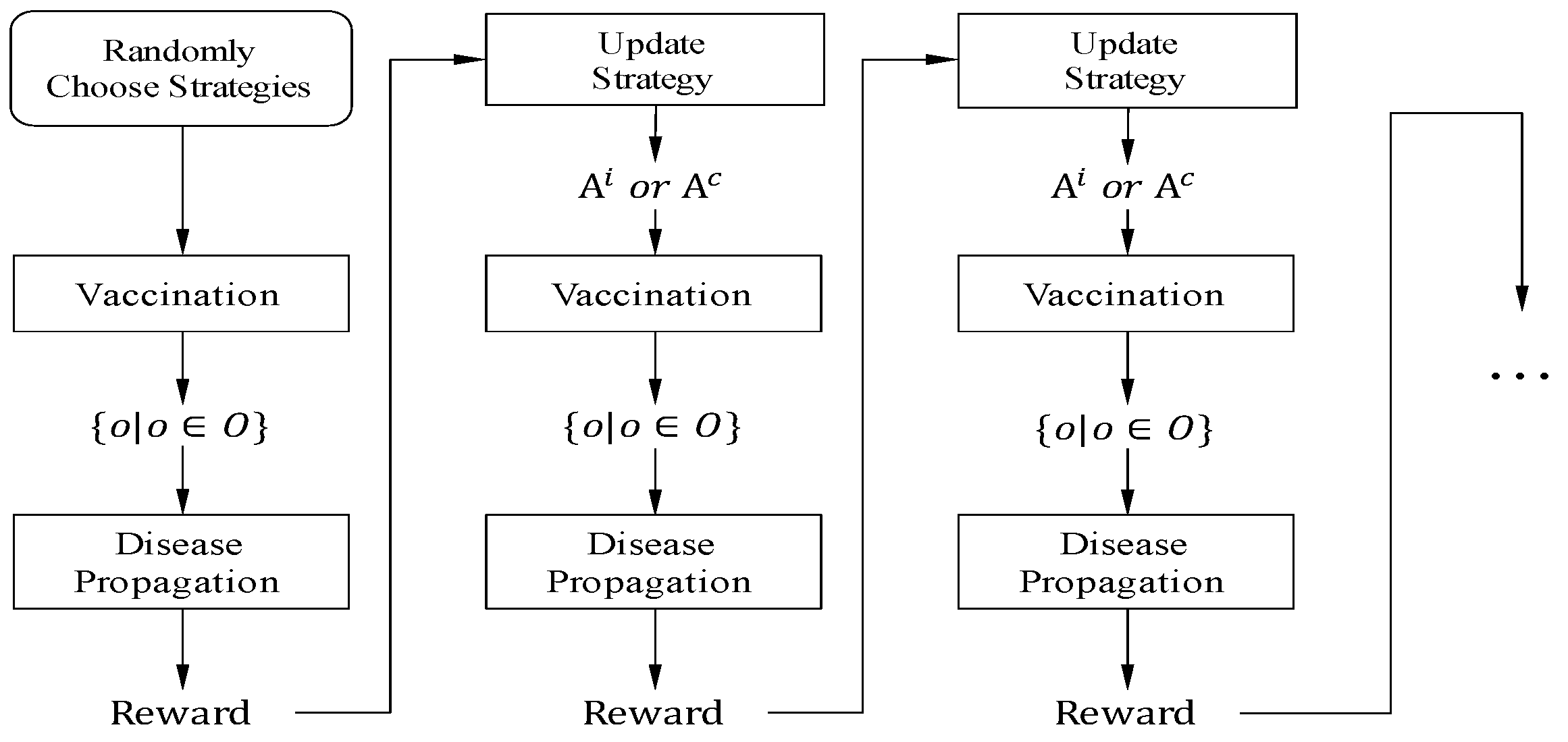
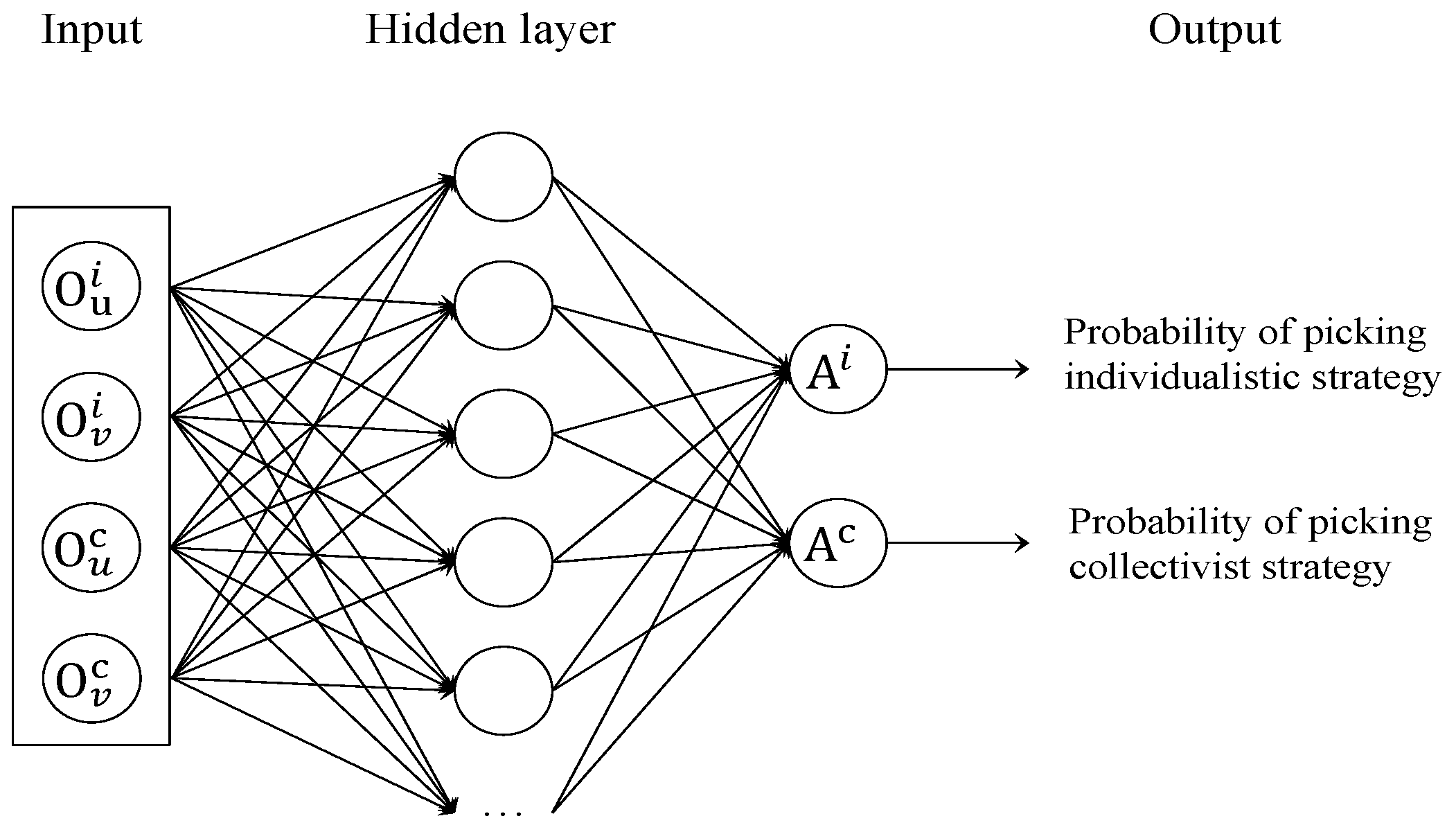
2.3. Reinforcement Learning Mechanism Based on Policy Gradient
| Algorithm 1 Simulation process(). |
Input: N: the number of network nodes; : the number of seasons; Output: epidemic size; vaccination coverage level; number of unvaccinated individuals; for
do if
then // first season initialize arbitrarily; for
do make vaccination decision randomly; end for else // other seasons Reinforcement learning(); Vaccination(); end if randomly set unvaccinated individuals as infectious; set time step ; ; while
do disease spreading using Gillespie algorithm; ; the number of infected number; end while vaccination coverage level among s neighbors; number of unvaccinated individuals of s neighbors and “neighbors of neighbors”; Output epidemic size; Output vaccination coverage level; Output number of unvaccinated individuals; end for |
| Algorithm 2 Reinforcement learning(). |
Input: o, a, ; Output: ; ; ← Neural Networks with parameter ; Output action; return |
| Algorithm 3 Vaccination(). |
Input: p, , , relative cost c, Output: individuals’ vaccination decision for
do if
then ; ; ; else //picking collectivist strategy ; ; ; ; end if if a random number then ; // vaccinate else ; // do not vaccinate end if end for |
3. Experimental Results
- Network structure: simulation experiments are conducted in scale-free networks. Each network has nodes whose average degree are equal to four .
- Transmission parameters: disease transmission rate , disease recovery rate , reinforcement learning learning rate , and selection strength [46].
- Initial vaccine coverage rate: in the first season, each individual decides whether to be vaccinated with a probability of . Therefore, the initial season vaccine coverage rate is around .
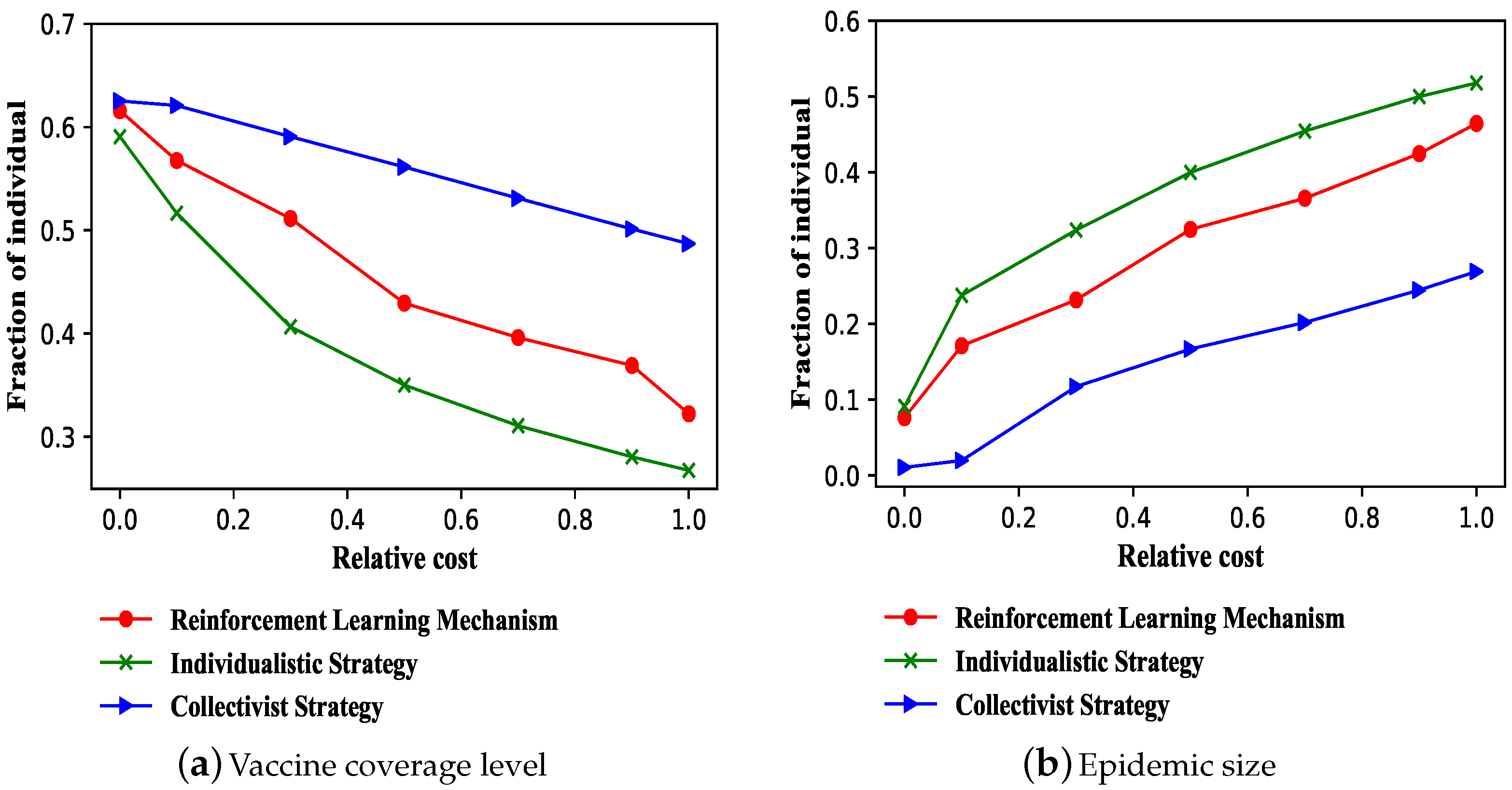
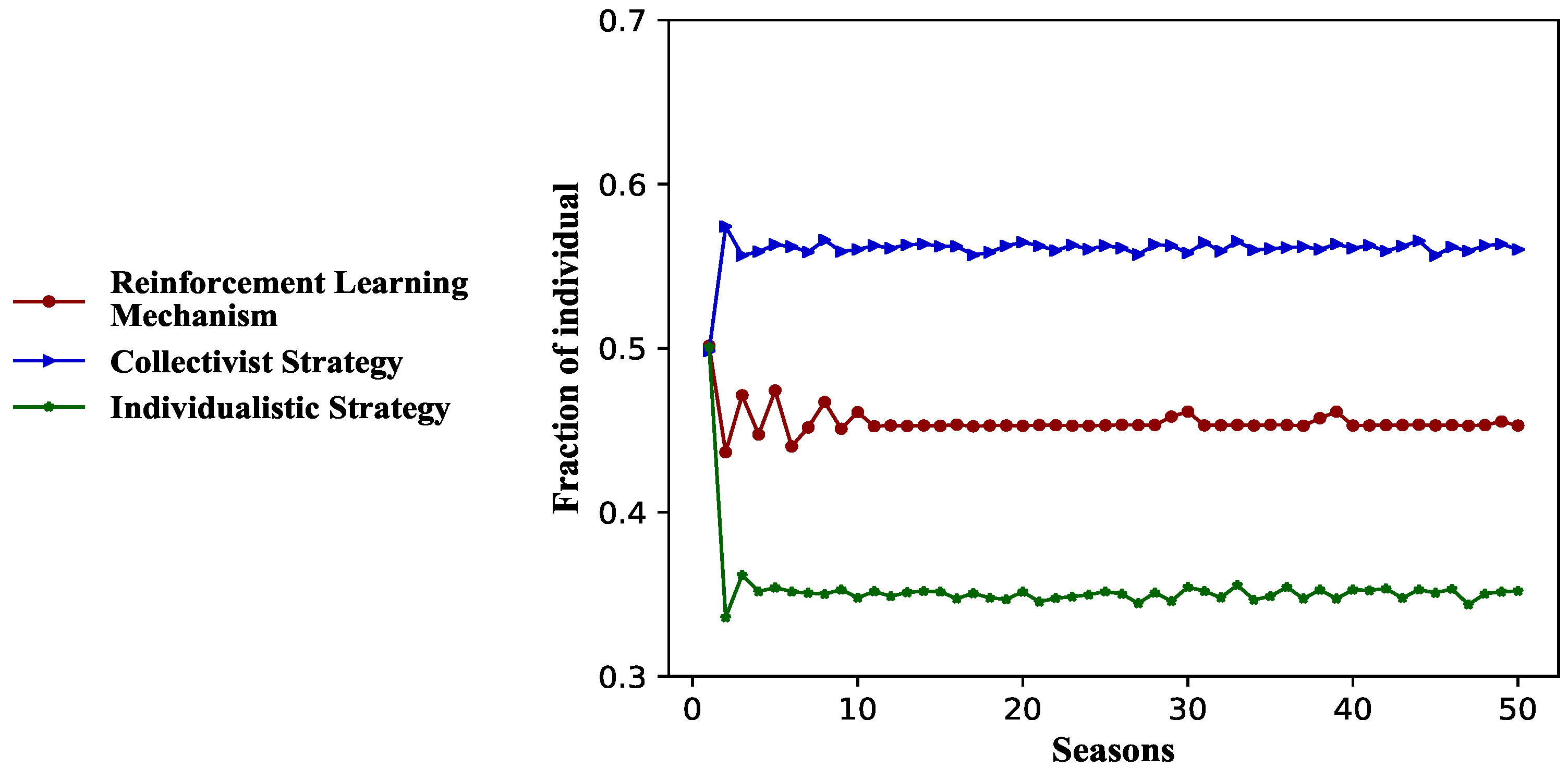
3.1. Effectiveness of Reinforcement Learning Mechanism on Vaccination
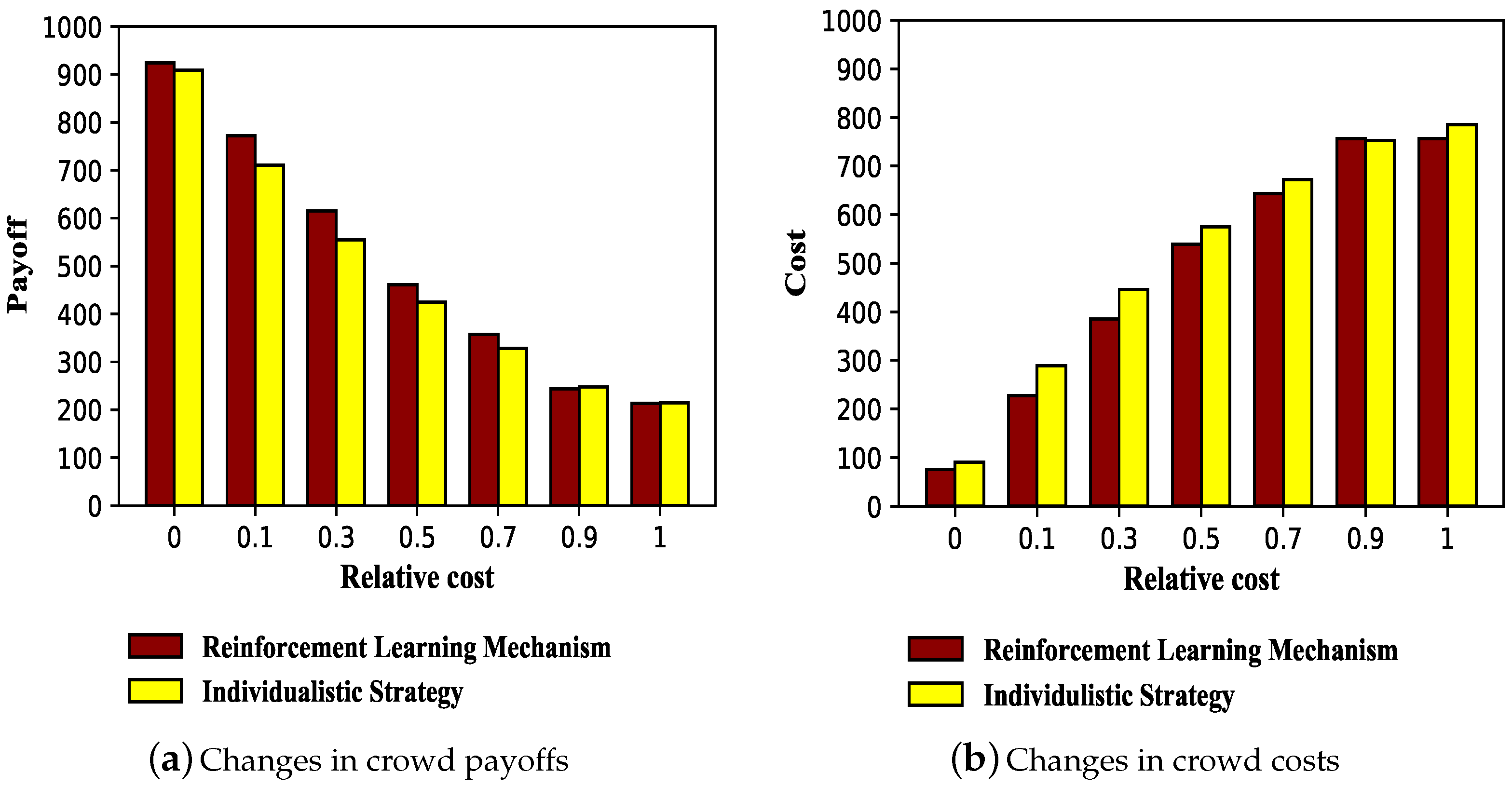
3.2. Payoffs and Costs under Reinforcement Learning Mechanism
3.2.1. Payoffs and Costs of Population
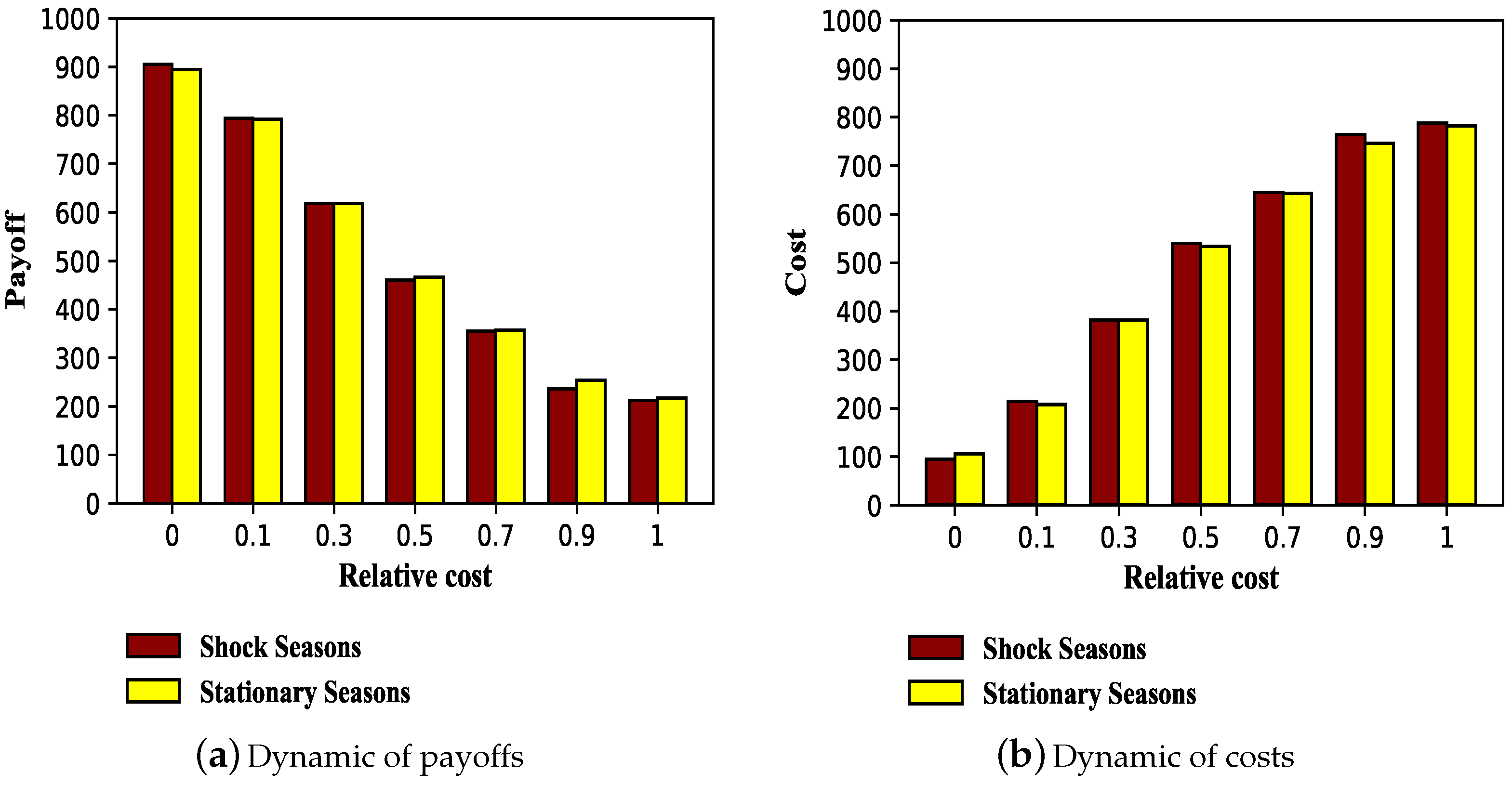
3.2.2. Dynamic of Long-Term Payoffs and Costs
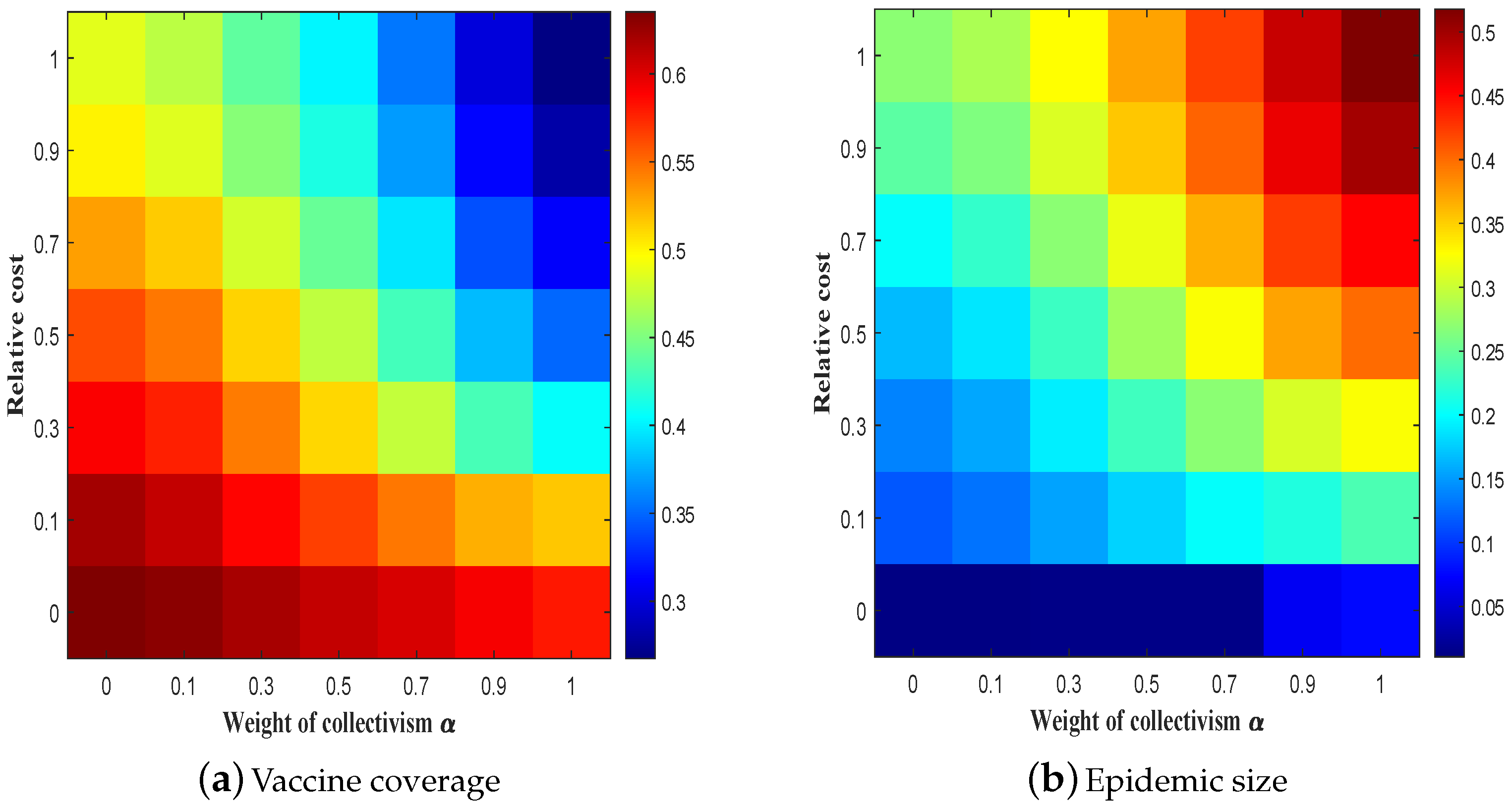
3.3. Effectiveness of Collectivist Strategy
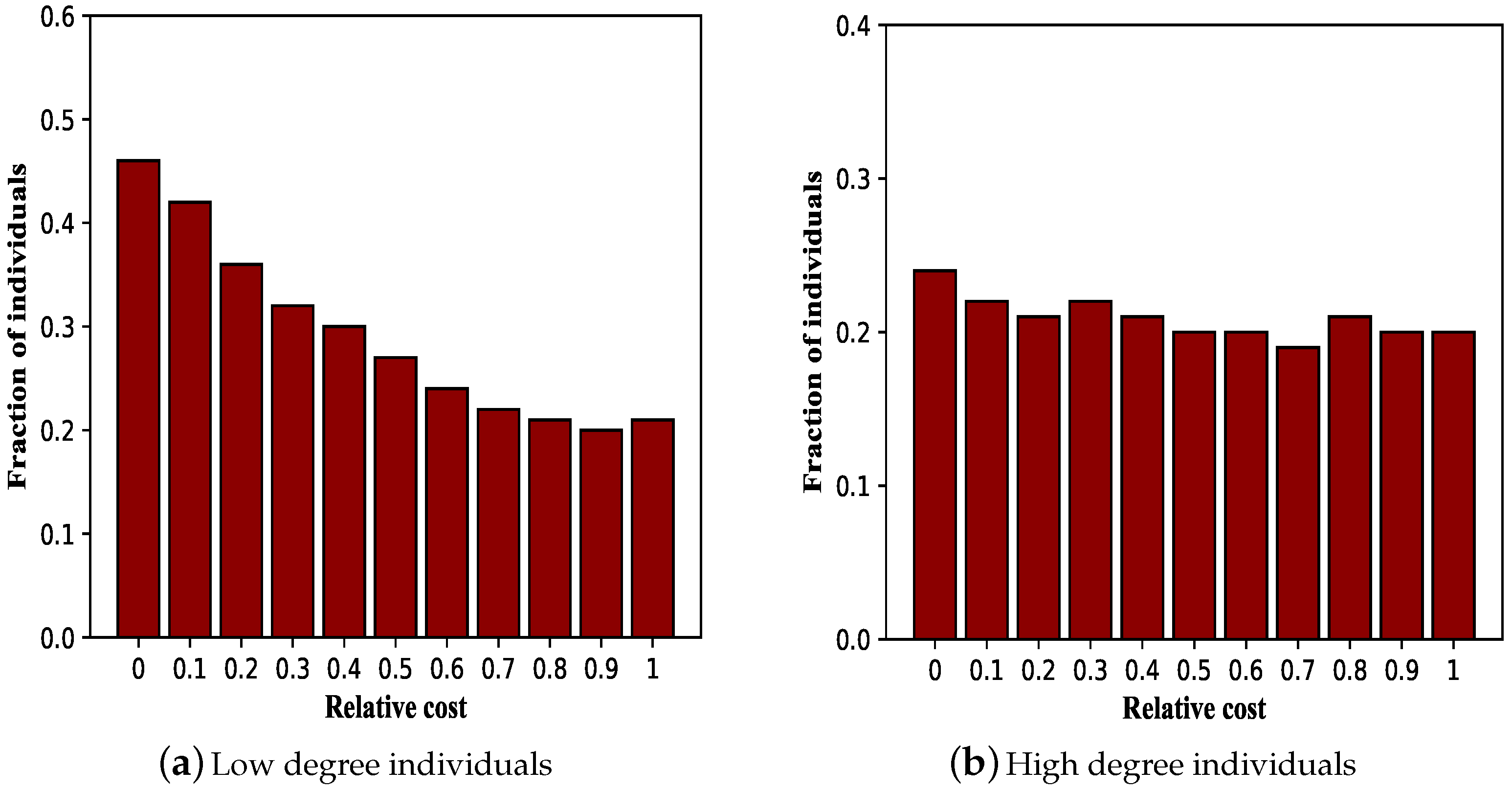
3.4. Effectiveness of Vaccination Mechanism with Respect to Individuals’ Degree
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Marra, M.A.; Jones, S.J.M.; Astell, C.R.; Holt, R.A.; Brooks-Wilson, A. The genome sequence of the SARS-associated coronavirus. Science 2003, 300, 1399. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- The Chinese SARS Molecular Epidemiology Consortium. Molecular evolution of the SARS Coronavirus, during the Course of the SARS epidemic in China. Science 2004, 303, 1666–1669. [Google Scholar] [CrossRef] [PubMed]
- Fouchier, R.A.M.; Kuiken, T.; Schutten, M.; Amerongen, G.V.; Doornum, G.J.J.V.; Hoogen, B.G.V.D.; Peiris, M.; Lim, W.; Stoehr, K.; Osterhaus, A.D.M.E. Aetiology: Koch’s postulates fulfilled for SARS virus. Nature 2003, 423, 240. [Google Scholar] [CrossRef]
- Small, M.; Walker, D.M.; Tse, C.K. Scale-Free distribution of Avian influenza outbreaks. J. Math. Biol. Nat. 2006, 53, 253–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fatimah, S.D.; Seema, J.; Lyn, F.; Michael, W.S.; Novel Swine-Origin Influenza A HN Virus Investigation Team. Emergence of a novel swine-origin influenza A (H1N1) virus in humans. N. Engl. J. Med. 2009, 360, 2605–2615. [Google Scholar]
- Peiris, J.S.M.; Poon, L.L.M.; Guan, Y. Emergence of a novel swine-origin influenza A virus (S-OIV) H1N1 virus in humans. J. Clin. Virol. Off. Publ. Pan Am. Soc. Clin. Virol. 2009, 45, 169–173. [Google Scholar] [CrossRef] [Green Version]
- Alamelu, R. Immunology of tuberculosis. Med. Clin. N. Am. 1993, 77, 1235–1251. [Google Scholar]
- Christopher, D.; Blanc, L. Global tuberculosis control: Surveillance, planning, financing. Wkly. Epidemiol. Rep. 2003, 78, 122–128. [Google Scholar]
- Dye, C.; Scheele, S.; Dolin, P.; Pathania, V.; Raviglione, M.C. Estimated incidence, prevalence, and mortality by country. JAMA 2003, 282, 677. [Google Scholar] [CrossRef] [PubMed]
- Rothan, H.A.; Byrareddy, S.N. The epidemiology and pathogenesis of Coronavirus disease (COVID-19) outbreak. J. Autoimmun. 2020, 109, 102433. [Google Scholar] [CrossRef]
- Velavan, T.P.; Meyer, C.G. The COVID-19 epidemic. Trop. Med. Int. Health 2020, 25, 278. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gayle, A.A.; Wilder-Smith, A.; Röcklv, J. The reproductive number of COVID-19 is higher compared to SARS coronavirus. J. Travel Med. 2020, 2020. [Google Scholar] [CrossRef] [Green Version]
- Yin, H.; Wang, S.; Zhu, Y.; Zhang, R.; Ye, X.; Wei, J.; Hou, P.C. The development of critical care medicine in China: From SARS to COVID-19 pandemic. Crit. Care Res. Pract. 1999, 282, 677. [Google Scholar] [CrossRef] [PubMed]
- Paolo, B. Demographic impact of vaccination: A review. Vaccine 1999, 17, S120–S125. [Google Scholar]
- Elwood, J.M. Smallpox and its eradication. J. Epidemiol. Commun. Health 1988, 43, 92. [Google Scholar] [CrossRef] [Green Version]
- Fine, P.E.M.; Jacqueline, A.C. Individual versus public priorities in the determination of optimal vaccination policies. Am. J. Epidemiol. 1987, 124, 1012–1020. [Google Scholar] [CrossRef]
- Kristin, L.N.; April, L.; Karen, L.M.; Maureen, M.; Meri, H.; Sanne, M.; Mari, D. The effectiveness of vaccination against influenza in healthy, working adults. Phys. Life Rev. 1995, 333, 889–893. [Google Scholar]
- Klaus, D. Infectious diseases of humans: Dynamics and control. Parasitol. Today 1992, 8, 179. [Google Scholar]
- Chen, F.H. A susceptible-infected epidemic model with voluntary vaccinations. J. Math. Biol. 2006, 53, 253–272. [Google Scholar] [CrossRef]
- Viboud, C.; Boëlle, P.-Y.; Fabrice, C.; Alain-Jacques, V.; Antoine, F. Prediction of the spread of influenza epidemics by the method of analogues. Am. J. Epidemiol. 2003, 158, 996–1006. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Qiu, H.; Shi, B.; Zhen, W. Imitation and memory-based self-organizing behaviors under voluntary vaccination. In Proceedings of the International Conference on Security, Pattern Analysis, and Cybernetics, Shenzhen, China, 15–17 December 2017; pp. 491–496. [Google Scholar]
- Xia, S.; Liu, J. A belief-based model for characterizing the spread of awareness and its impacts on individuals’ vaccination decisions. J. R. Soc. Interface 2014, 11, 20140013. [Google Scholar] [CrossRef]
- Kaufmann, S.H.E.; Mcmichael, A.J. Annulling a dangerous liaison: Vaccination strategies against AIDS and tuberculosis. Nat. Med. 2005, 11, S33. [Google Scholar] [CrossRef]
- Keeling, M.J.; Woolhouse, M.E.J.; Davies, R.M.M.G.; Grenfell, B.T. Modelling vaccination strategies against foot-and-mouth disease. Nature 2003, 421, 136–142. [Google Scholar] [CrossRef] [PubMed]
- Tildesley, M.J.; Savill, N.J.; Shaw, D.J.; Deardon, R.; Brooks, S.P.; Woolhouse, M.E.J.; Grenfell, B.T.; Keeling, M.J. Optimal reactive vaccination strategies for a foot-and-mouth outbreak in the UK. Nature 2006, 404, 83–86. [Google Scholar] [CrossRef]
- Bauch, C.T.; Earn, D.J. Vaccination and the theory of games. Proc. Natl. Acad. Sci. USA 2004, 101, 13391–13394. [Google Scholar] [CrossRef] [Green Version]
- Shi, B.; Liu, G.; Qiu, H.; Wang, Z.; Ren, Y.; Chen, D. Exploring voluntary vaccination with bounded rationality through reinforcement learning. Phys. Stat. Mech. Appl. 2019, 515, 171–182. [Google Scholar] [CrossRef]
- Bauch, C.T.; Galvani, A.P.; Earn, D.J. Group interest versus self-interest in smallpox vaccination policy. Proc. Natl. Acad. Sci. USA 2003, 100, 10564–10567. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hershey, J.C.; Asch, D.A.; Thumasathit, T.; Meszaros, J.; Waters, V.V. The roles of altruism, free riding, and bandwagoning in vaccination decisions. Organ. Behav. Hum. Decis. Process. 1994, 59, 177–187. [Google Scholar] [CrossRef]
- Zhang, Q.; Buckling, A.; Ellis, R.J.; Godfray, H.C.J. Coevolution between cooperators and cheats in a microbial system. Evolution 2009, 63, 2248–2256. [Google Scholar] [CrossRef]
- Nowak, M.A. Five rules for the evolution of cooperation. Science 2007, 314, 1560–1563. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, W.D. The genetical evolution of social behaviour. J. Theor. Biol. 1964, 7, 17–52. [Google Scholar] [CrossRef]
- Foster, K.R.; Wenseleers, T.; Ratnieks, F.L.W. Kin selection is the key to altruism. Trends Ecol. Evol. 2006, 21, 57–60. [Google Scholar] [CrossRef] [PubMed]
- Gardner, A.; West, S.A.; Wild, G. The genetical theory of kin selection. J. Evol. Biol. 2011, 24, 1020–1043. [Google Scholar] [CrossRef] [PubMed]
- Queller, D.C.; Strassmann, J.E. Kin selection and social insects. Bioscience 1998, 48, 165–175. [Google Scholar] [CrossRef]
- Ohtsuki, H.; Iwasa, Y. The leading eight: Social norms that can maintain cooperation by indirect reciprocity. J. Theor. Biol. 2006, 239, 435–444. [Google Scholar] [CrossRef]
- Ohtsuki, H.; Iwasa, Y. How should we define goodness? Reputation dynamics in indirect reciprocity. J. Theor. Biol. 2004, 231, 107–120. [Google Scholar] [CrossRef]
- Cucciniello, M.; Pin, P.; Imre, B.; Porumbescu, G.; Melegaro, A. Altruism and Vaccination Intentions: Evidence from Behavioral Experiments. medRxiv 2020. [Google Scholar] [CrossRef]
- Rieger, M.O. Triggering Altruism Increases the Willingness to Get Vaccinated against COVID-19. Soc. Health Behav. 2020, 3, 78. [Google Scholar] [CrossRef]
- Shi, B.; Qiu, H.; Niu, W.; Ren, Y.; Ding, H.; Chen, D. Voluntary vaccination through self-organizing behaviors on locally-mixed social networks. Sci. Rep. 2017, 7, 2665. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Peng, S.; Qiu, H.; Shi, B.; Chen, Y. Perceiving epidemic severity in social network. Complexity 2019, 2019, 13. [Google Scholar]
- Jalil, R.; Mehri, S.; Jorge, D.; Cristina, J.; Nuno, M. On the dynamical complexity of a seasonally forced discrete SIR epidemic model with a constant vaccination strategy. Complexity 2018, 2018. [Google Scholar] [CrossRef]
- Feng, F.; Daniel, I.R.; Wang, L.; Martin, A.N. Imitation dynamics of vaccination behaviour on social networks. Proc. Biol. Sci. 2011, 278, 42–49. [Google Scholar]
- Arne, T.; Dirk, S.; Sommerfeld, R.D.; Hans-Jrgen, K.; Manfred, M. Human strategy updating in evolutionary games. Proc. Natl. Acad. Sci. USA 2010, 107, 2962–2966. [Google Scholar]
- Sutton, R.S.; Mcallester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Neural Inf. Process. Syst. 2000, 12, 1057–1063. [Google Scholar]
- Zhang, H.; Shu, P.; Wang, Z.; Tang, M. Preferential imitation can invalidate targeted subsidy policies on seasonal-influenza diseases. Appl. Math. Comput. 2017, 294, 332–342. [Google Scholar] [CrossRef]
- Anderson, R.; May, R. Infectious Diseases of Humans; Oxford University Press: Oxford, UK, 1992. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Qiao, T.; Qiu, H.; Shi, B.; Bao, Q. Individualism or Collectivism: A Reinforcement Learning Mechanism for Vaccination Decisions. Information 2021, 12, 66. https://doi.org/10.3390/info12020066
Wu C, Qiao T, Qiu H, Shi B, Bao Q. Individualism or Collectivism: A Reinforcement Learning Mechanism for Vaccination Decisions. Information. 2021; 12(2):66. https://doi.org/10.3390/info12020066
Chicago/Turabian StyleWu, Chaohao, Tong Qiao, Hongjun Qiu, Benyun Shi, and Qing Bao. 2021. "Individualism or Collectivism: A Reinforcement Learning Mechanism for Vaccination Decisions" Information 12, no. 2: 66. https://doi.org/10.3390/info12020066
APA StyleWu, C., Qiao, T., Qiu, H., Shi, B., & Bao, Q. (2021). Individualism or Collectivism: A Reinforcement Learning Mechanism for Vaccination Decisions. Information, 12(2), 66. https://doi.org/10.3390/info12020066