
Learning from High-Dimensional and Class-Imbalanced Datasets Using Random Forests


Abstract
:1. Introduction
2. Background and Related Work
3. Methodological Framework
3.1. Imbalance Learning Methods
- RUS (Random Under-Sampling), where instances of the negative class are randomly removed from the training data;
- SMOTE (Synthetic Minority Over-sampling TEchnique), where new synthetic instances of the positive class are introduced by interpolating between positive instances that are near to each other; indeed, this interpolation mechanism has turned out to be more effective than simply duplicating a number of minority instances chosen at random, as in the Random Over-Sampling approach [16,17].
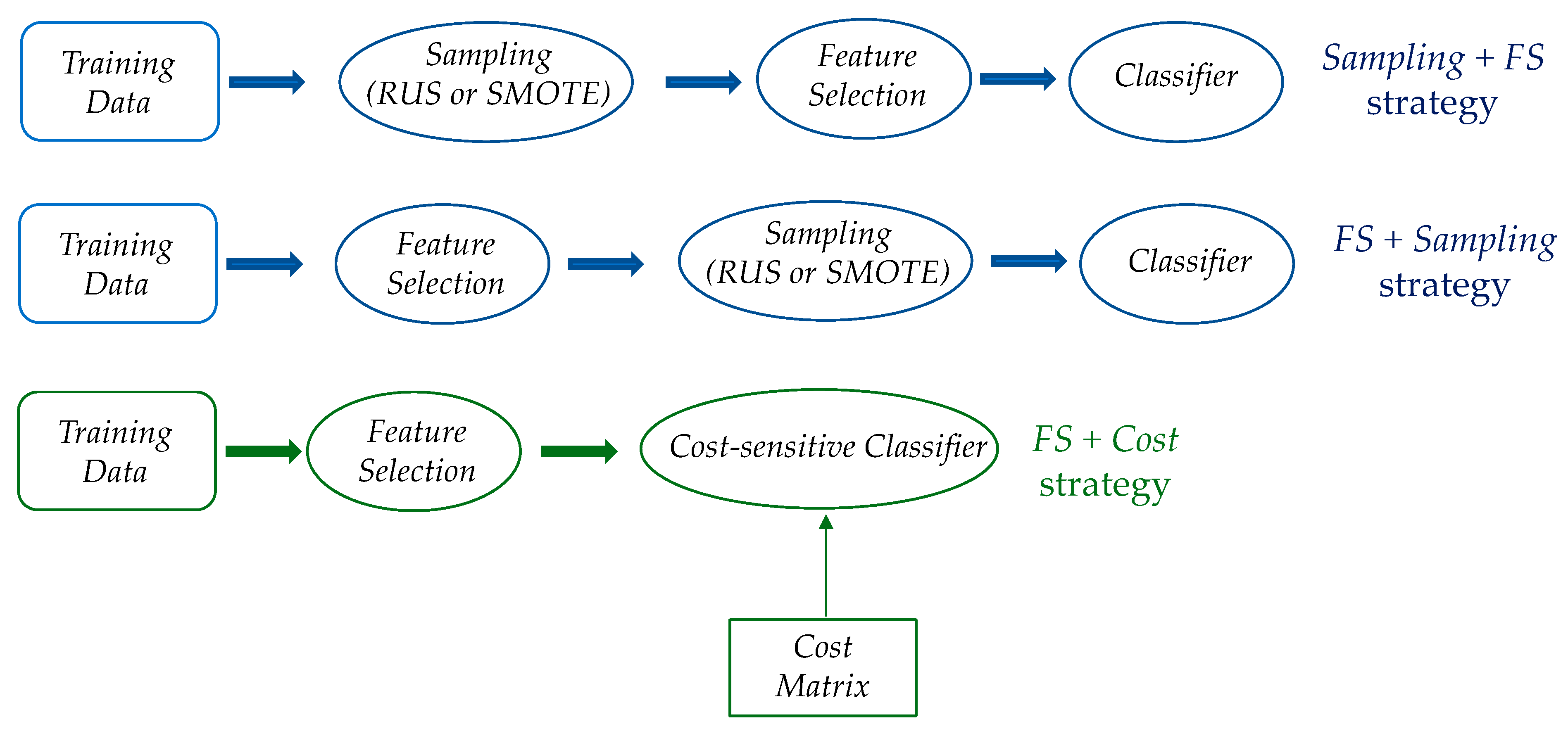
3.2. Integrating Feature Selection with Imbalance Learning
- using feature selection (FS) before data balancing (RUS or SMOTE approach);
- using feature selection (FS) after data balancing (RUS or SMOTE approach);
- using feature selection (FS) in conjunction with cost-sensitive learning (MinCost or Weighting approach).
3.3. Classification Method and Evaluation Metrics
4. Experimental Study
4.1. Datasets and Settings
- (i)
- cancer classification from genomic data;
- (ii)
- text categorization;
- (iii)
- image classification.
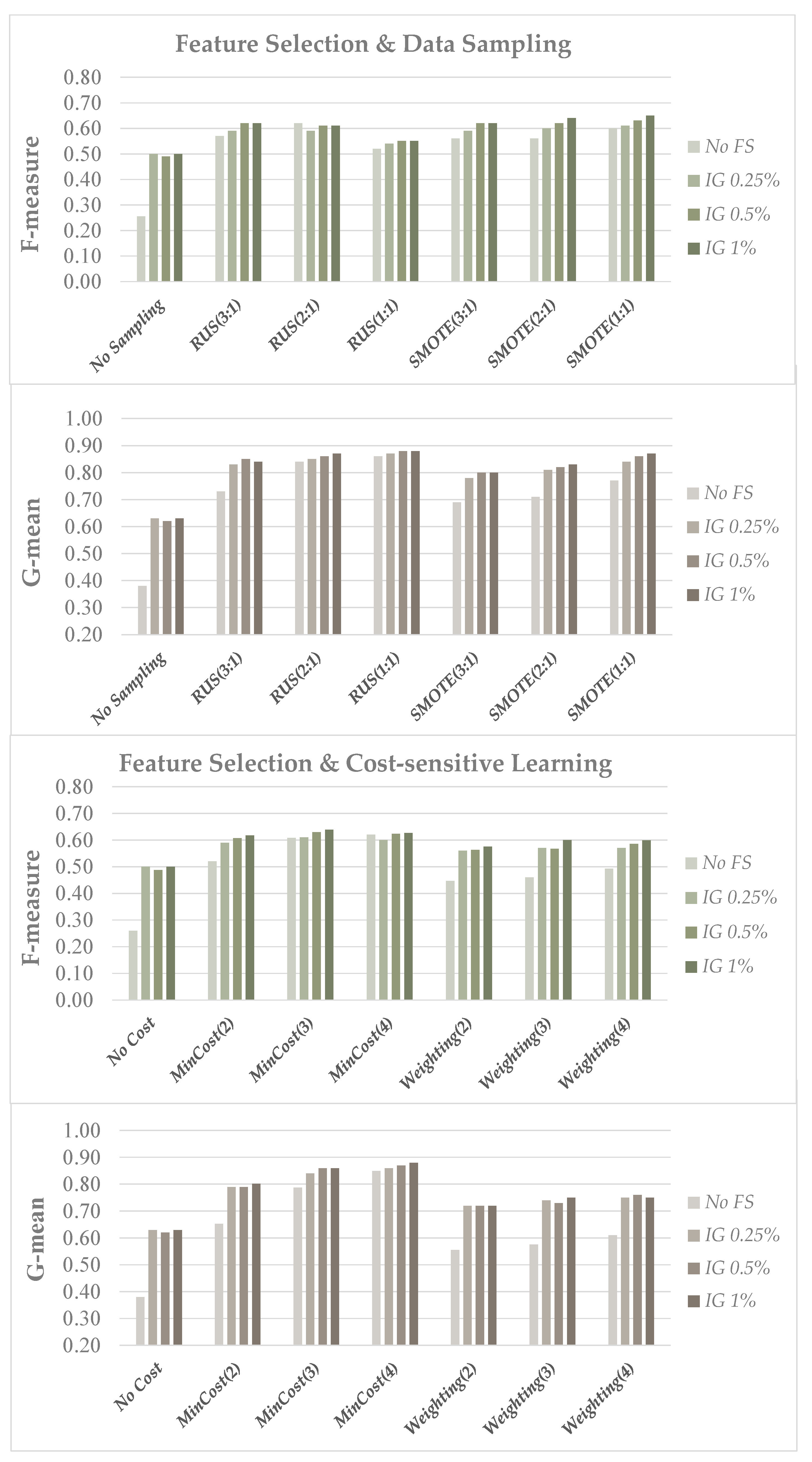
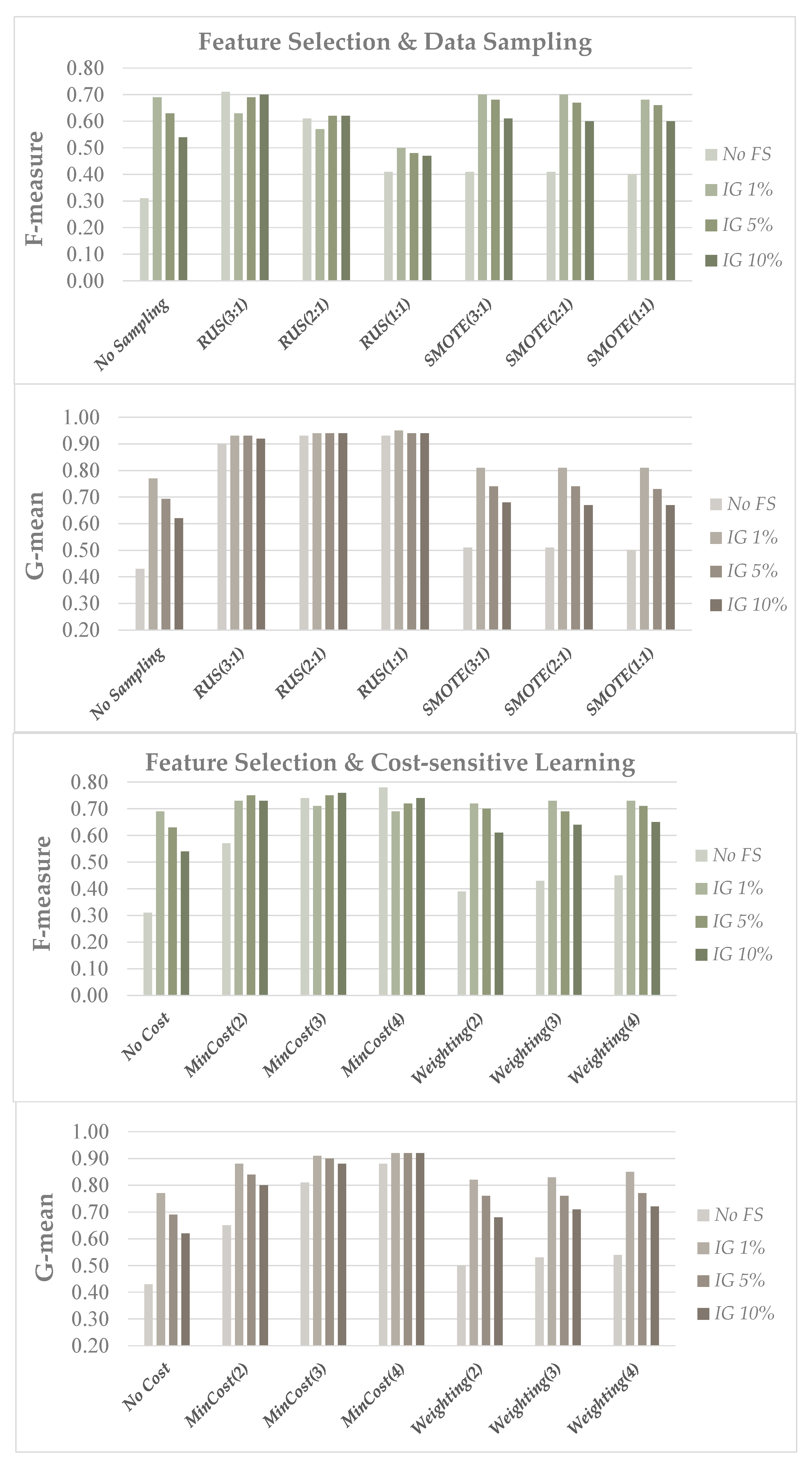
4.2. Results and Discussion
- (i)
- 0.25, 0.5 and 1% of the original dimensionality in the genomic domain;
- (ii)
- 1, 5 and 10% of the original dimensionality in the text categorization domain.
- (iii)
- On the other hand, the CFS filter has been used for the image datasets, as a subset-oriented approach is more appropriate where the number of features is lower.
5. Concluding Remarks and Future Work
Supplementary Materials
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- He, H.; Garcia, E. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A Survey of Predictive Modeling on Imbalanced Domains. ACM Comput. Surv. 2016, 49, 31. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. Class prediction for high-dimensional class-imbalanced data. BMC Bioinform. 2010, 11, 523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maldonado, S.; Weber, R.; Famili, F. Feature selection for high-dimensional class-imbalanced data sets using Support Vector Machines. Inf. Sci. 2014, 286, 228–246. [Google Scholar] [CrossRef]
- Moayedikia, A.; Ong, K.L.; Boo, Y.L.; Yeoh, W.G.S.; Jensen, R. Feature selection for high dimensional imbalanced class data using harmony search. Eng. Appl. Artif. Intell. 2017, 57, 38–49. [Google Scholar] [CrossRef] [Green Version]
- Shanab, A.A.; Khoshgoftaar, T.M. Is Gene Selection Enough for Imbalanced Bioinformatics Data? In Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration for Data Science, Salt Lake City, UT, USA, 6–9 July 2018; pp. 346–355. [Google Scholar]
- Zhang, C.; Zhou, Y.; Guo, J.; Wang, G.; Wang, X. Research on classification method of high-dimensional class-imbalanced datasets based on SVM. Int. J. Mach. Learn. Cybern. 2019, 10, 1765–1778. [Google Scholar] [CrossRef]
- Fu, G.H.; Wu, Y.J.; Zong, M.J.; Pan, J. Hellinger distance-based stable sparse feature selection for high-dimensional class-imbalanced data. BMC Bioinform. 2020, 21, 121. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. 2014, 2, 602–609. [Google Scholar] [CrossRef] [Green Version]
- Rokach, L. Decision forest: Twenty years of research. Inf. Fusion 2016, 27, 111–125. [Google Scholar] [CrossRef]
- Khoshgoftaar, T.M.; Golawala, M.; Van Hulse, J. An Empirical Study of Learning from Imbalanced Data Using Random Forest. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence, Patras, Greece, 29–31 October 2007; pp. 310–317. [Google Scholar]
- Chen, X.; Ishwaran, H. Random forests for genomic data analysis. Genomics 2012, 99, 323–329. [Google Scholar] [CrossRef] [Green Version]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Fernandez, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-year Anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Zheng, Z.; Wu, X.; Srihari, R. Feature selection for text categorization on imbalanced data. ACM Sigkdd Explor. Newsl. 2004, 6, 80–89. [Google Scholar] [CrossRef]
- Wasikowski, M.; Chen, X. Combating the small sample class imbalance problem using feature selection. IEEE Trans. Knowl. Data Eng. 2010, 22, 1388–1400. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. Feature Selection for High-Dimensional Data, Artificial Intelligence: Foundations, Theory, and Algorithms; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Dessì, N.; Pes, B. Similarity of feature selection methods: An empirical study across data intensive classification tasks. Expert Syst. Appl. 2015, 42, 4632–4642. [Google Scholar] [CrossRef]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Cannas, L.M.; Dessì, N.; Pes, B. A Filter-based Evolutionary Approach for Selecting Features in High-Dimensional Micro-array Data. In Proceedings of the 6th International Conference on Intelligent Information Processing, Manchester, UK, 13–16 October 2010; pp. 297–307. [Google Scholar]
- Ahmed, N.; Rafiq, J.I.; Islam, M.D.R. Enhanced Human Activity Recognition Based on Smartphone Sensor Data Using Hybrid Feature Selection Model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef] [Green Version]
- Almugren, N.; Alshamlan, H. A Survey on Hybrid Feature Selection Methods in Microarray Gene Expression Data for Cancer Classification. IEEE Access 2019, 7, 78533–78548. [Google Scholar] [CrossRef]
- Dessì, N.; Pes, B. Stability in Biomarker Discovery: Does Ensemble Feature Selection Really Help? In Current Approaches in Applied Artificial Intelligence, Proceedings of the 28th International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, IEA/AIE 2015, Seoul, Korea, 10–12 June 2015; LNCS 9101; Springer: Cham, Switzerland, 2015; pp. 191–200. [Google Scholar]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Pes, B. Ensemble feature selection for high-dimensional data: A stability analysis across multiple domains. Neural Comput. Appl. 2020, 32, 5951–5973. [Google Scholar] [CrossRef] [Green Version]
- Haury, A.C.; Gestraud, P.; Vert, J.P. The Influence of Feature Selection Methods on Accuracy, Stability and Interpretability of Molecular Signatures. PLoS ONE 2011, 6, e28210. [Google Scholar] [CrossRef] [PubMed]
- Drotár, P.; Gazda, J.; Smékal, Z. An Experimental Comparison of Feature Selection Methods on Two-Class Biomedical Datasets. Comput. Biol. Med. 2015, 66, 1–10. [Google Scholar] [CrossRef]
- Pes, B. Feature Selection for High-Dimensional Data: The Issue of Stability. In Proceedings of the 2017 IEEE 26th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Poznan, Poland, 21–23 June 2017; pp. 170–175. [Google Scholar]
- Bolón-Canedo, V.; Rego-Fernández, D.; Peteiro-Barral, D.; Alonso-Betanzos, A.; Guijarro-Berdiñas, B.; Sánchez-Maroño, N. On the scalability of feature selection methods on high-dimensional data. Knowl. Inf. Syst. 2018, 56, 395–442. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. SMOTE for high-dimensional class-imbalanced data. BMC Bioinform. 2013, 14, 106. [Google Scholar] [CrossRef] [Green Version]
- Pes, B. Learning From High-Dimensional Biomedical Datasets: The Issue of Class Imbalance. IEEE Access 2020, 8, 13527–13540. [Google Scholar] [CrossRef]
- Ling, C.X.; Sheng, V.S. Cost-Sensitive Learning. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 231–235. [Google Scholar]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, W.; Li, W.; Huang, Y. Large group activity security risk assessment and risk early warning based on random forest algorithm. Pattern Recognit. Lett. 2021, 144, 1–5. [Google Scholar] [CrossRef]
- Figueroa, A.; Peralta, B.; Nicolis, O. Coming to Grips with Age Prediction on Imbalanced Multimodal Community Question Answering Data. Information 2021, 12, 48. [Google Scholar] [CrossRef]
- OpenML Datasets. Available online: https://www.openml.org/search?type=data (accessed on 30 June 2021).
- Hambali, M.A.; Oladele, T.O.; Adewole, K.S. Microarray cancer feature selection: Review, challenges and research directions. Int. J. Cogn. Comput. Eng. 2020, 1, 78–97. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 30 June 2021).
- Rullo, P.; Policicchio, V.L.; Cumbo, C.; Iiritano, S. Olex: Effective Rule Learning for Text Categorization. IEEE Trans. Knowl. Data Eng. 2009, 21, 1118–1132. [Google Scholar] [CrossRef]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef] [Green Version]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: San Mateo, CA, USA, 2016. [Google Scholar]
- Weka: Data Mining Software in Java. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 30 June 2021).
- Nadeau, C.; Bengio, Y. Inference for the Generalization Error. Mach. Learn. 2003, 52, 239–281. [Google Scholar] [CrossRef] [Green Version]
- Alonso-Betanzos, A.; Bolón-Canedo, V.; Morán-Fernández, L.; Seijo-Pardo, B. Feature Selection Applied to Microarray Data. In Microarray Bioinformatics; Methods in Molecular Biology; Bolón-Canedo, V., Alonso-Betanzos, A., Eds.; Humana: New York, NY, USA, 2019; Volume 1986, pp. 123–152. [Google Scholar]
- Dessì, N.; Milia, G.; Pes, B. Enhancing Random Forests Performance in Microarray Data Classification. In Artificial Intelligence in Medicine, Proceedings of the 14th Conference on Artificial Intelligence in Medicine, AIME 2013, Murcia, Spain, 29 May–1 June 2013; LNCS 7885; Springer: Berlin/Heidelberg, Germany, 2013; pp. 99–103. [Google Scholar]
- Cilia, N.D.; De Stefano, C.; Fontanella, F.; Raimondo, S.; Scotto di Freca, A. An Experimental Comparison of Feature-Selection and Classification Methods for Microarray Datasets. Information 2019, 10, 109. [Google Scholar] [CrossRef] [Green Version]
- Sirimongkolkasem, T.; Drikvandi, R. On Regularisation Methods for Analysis of High Dimensional Data. Ann. Data. Sci. 2019, 6, 737–763. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Jiang, H.; Shen, H.; Yang, Z. Gene Selection in Cancer Classification Using Sparse Logistic Regression with L1/2 Regularization. Appl. Sci. 2018, 8, 1569. [Google Scholar] [CrossRef] [Green Version]
- Marafino, B.J.; Boscardin, W.J.; Dudley, R.A. Efficient and sparse feature selection for biomedical text classification via the elastic net: Application to ICU risk stratification from nursing notes. J. Biomed. Inform. 2015, 54, 114–120. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | |||
|---|---|---|---|
| + | − | ||
| actual class | + | C(+,+) | C(+,−) |
| − | C(−,+) | C(−,−) | |
| Domain | Dataset | Number of Instances | Number of Features | Instances-to-Features Ratio | % of Minority Instances |
|---|---|---|---|---|---|
| Genomic data | Uterus | 1545 | 10,935 | 0.14 | 8.0% |
| Omentum | 1545 | 10,935 | 0.14 | 5.0% | |
| Text categorization | Trade | 12,897 | 7599 | 1.70 | 3.8% |
| Interest | 12,897 | 10,457 | 1.23 | 3.7% | |
| Image classification | Mountain | 2407 | 294 | 8.19 | 22.1% |
| Urban | 2407 | 294 | 8.19 | 17.9% |
| Dataset | Performance Measure | Baseline | RUS (3:1) | RUS (2:1) | RUS (1:1) | SMOTE (3:1) | SMOTE (2:1) | SMOTE (1:1) |
|---|---|---|---|---|---|---|---|---|
| Uterus | F-measure | 0.26 (0.09) | 0.57 (0.06) | 0.62 (0.07) | 0.52 (0.05) | 0.56 (0.07) | 0.56 (0.07) | 0.60 (0.07) |
| G-mean | 0.38 (0.08) | 0.73 (0.05) | 0.84 (0.05) | 0.86 (0.03) | 0.69 (0.05) | 0.71 (0.05) | 0.77 (0.05) | |
| Omentum | F-measure | 0.00 (0.00) | 0.48 (0.10) | 0.48 (0.07) | 0.38 (0.06) | 0.41 (0.12) | 0.46 (0.10) | 0.52 (0.08) |
| G-mean | 0.00 (0.00) | 0.69 (0.09) | 0.80 (0.08) | 0.85 (0.05) | 0.60 (0.10) | 0.64 (0.10) | 0.72 (0.08) | |
| Trade | F-measure | 0.31 (0.07) | 0.71 (0.03) | 0.61 (0.02) | 0.41 (0.02) | 0.41 (0.08) | 0.41 (0.07) | 0.40 (0.07) |
| G-mean | 0.43 (0.06) | 0.90 (0.03) | 0.93 (0.02) | 0.93 (0.01) | 0.51 (0.06) | 0.51 (0.05) | 0.50 (0.05) | |
| Interest | F-measure | 0.53 (0.03) | 0.72 (0.04) | 0.69 (0.03) | 0.50 (0.03) | 0.58 (0.03) | 0.58 (0.03) | 0.59 (0.03) |
| G-mean | 0.62 (0.02) | 0.88 (0.03) | 0.92 (0.02) | 0.95 (0.01) | 0.67 (0.03) | 0.67 (0.02) | 0.68 (0.02) | |
| Mountain | F-measure | 0.51 (0.04) | 0.56 (0.06) | 0.63 (0.04) | 0.61 (0.02) | 0.54 (0.04) | 0.61 (0.04) | 0.64 (0.04) |
| G-mean | 0.60 (0.03) | 0.64 (0.04) | 0.74 (0.04) | 0.79 (0.02) | 0.63 (0.03) | 0.71 (0.04) | 0.77 (0.03) | |
| Urban | F-measure | 0.56 (0.05) | 0.65 (0.05) | 0.68 (0.04) | 0.61 (0.02) | 0.64 (0.04) | 0.67 (0.04) | 0.68 (0.03) |
| G-mean | 0.64 (0.04) | 0.75 (0.04) | 0.81 (0.02) | 0.83 (0.02) | 0.72 (0.03) | 0.77 (0.03) | 0.81 (0.02) |
| Dataset | Performance Measure | Baseline | MinCost (2) | MinCost (3) | MinCost (4) | Weighting (2) | Weighting (3) | Weighting (4) |
|---|---|---|---|---|---|---|---|---|
| Uterus | F-measure | 0.26 (0.09) | 0.52 (0.08) | 0.61 (0.06) | 0.62 (0.06) | 0.45 (0.08) | 0.46 (0.09) | 0.49 (0.08) |
| G-mean | 0.38 (0.08) | 0.65 (0.06) | 0.79 (0.04) | 0.85 (0.03) | 0.56 (0.06) | 0.58 (0.07) | 0.61 (0.06) | |
| Omentum | F-measure | 0.00 (0.00) | 0.14 (0.11) | 0.42 (0.13) | 0.50 (0.10) | 0.05 (0.06) | 0.09 (0.10) | 0.11 (0.09) |
| G-mean | 0.00 (0.00) | 0.24 (0.17) | 0.58 (0.12) | 0.72 (0.09) | 0.10 (0.13) | 0.16 (0.16) | 0.21 (0.15) | |
| Trade | F-measure | 0.31 (0.07) | 0.57 (0.05) | 0.74 (0.04) | 0.78 (0.02) | 0.39 (0.07) | 0.43 (0.08) | 0.45 (0.06) |
| G-mean | 0.43 (0.06) | 0.65 (0.03) | 0.81 (0.03) | 0.88 (0.02) | 0.50 (0.06) | 0.53 (0.06) | 0.54 (0.05) | |
| Interest | F-measure | 0.53 (0.03) | 0.65 (0.03) | 0.72 (0.02) | 0.75 (0.02) | 0.59 (0.03) | 0.60 (0.03) | 0.61 (0.02) |
| G-mean | 0.62 (0.02) | 0.73 (0.02) | 0.82 (0.02) | 0.88 (0.01) | 0.68 (0.02) | 0.69 (0.02) | 0.70 (0.02) | |
| Mountain | F-measure | 0.51 (0.04) | 0.65 (0.03) | 0.61 (0.03) | 0.57 (0.02) | 0.61 (0.04) | 0.64 (0.04) | 0.65 (0.03) |
| G-mean | 0.60 (0.03) | 0.78 (0.02) | 0.79 (0.02) | 0.76 (0.02) | 0.70 (0.04) | 0.74 (0.04) | 0.77 (0.03) | |
| Urban | F-measure | 0.56 (0.05) | 0.69 (0.04) | 0.66 (0.02) | 0.61 (0.03) | 0.65 (0.04) | 0.68 (0.04) | 0.69 (0.03) |
| G-mean | 0.64 (0.04) | 0.81 (0.03) | 0.85 (0.01) | 0.83 (0.02) | 0.74 (0.03) | 0.78 (0.03) | 0.79 (0.02) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pes, B. Learning from High-Dimensional and Class-Imbalanced Datasets Using Random Forests. Information 2021, 12, 286. https://doi.org/10.3390/info12080286
Pes B. Learning from High-Dimensional and Class-Imbalanced Datasets Using Random Forests. Information. 2021; 12(8):286. https://doi.org/10.3390/info12080286
Chicago/Turabian StylePes, Barbara. 2021. "Learning from High-Dimensional and Class-Imbalanced Datasets Using Random Forests" Information 12, no. 8: 286. https://doi.org/10.3390/info12080286
APA StylePes, B. (2021). Learning from High-Dimensional and Class-Imbalanced Datasets Using Random Forests. Information, 12(8), 286. https://doi.org/10.3390/info12080286