
Deep Hash with Improved Dual Attention for Image Retrieval


Abstract
:1. Introduction
- Firstly, this study designs an IDA module and embeds it in the ResNet18 network model, which learns feature representation and hash code learning at the same time. The position attention module is designed to capture the spatial interdependencies between features. The channel attention module is designed to model channel interdependencies.
- Secondly, to reduce quantization error, this study designs a new piecewise function to process the network output into discrete binary code.
- Thirdly, this study applies DHIDA on different loss functions, and measures its performance with extensive experiments on three standard image retrieval data sets.
2. Related Work
3. Deep Hash with Improved Dual Attention
3.1. Problem Formulation
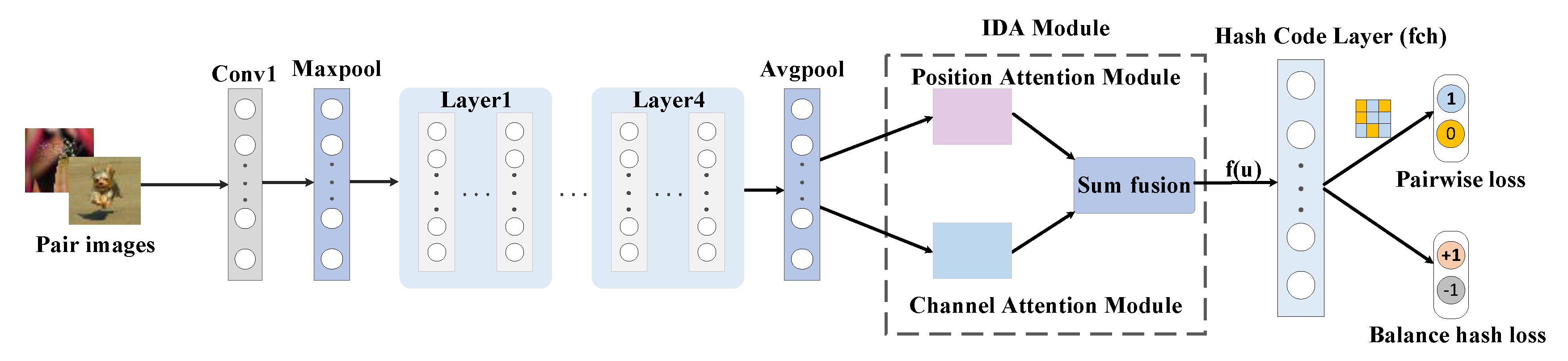
3.2. Network Framework
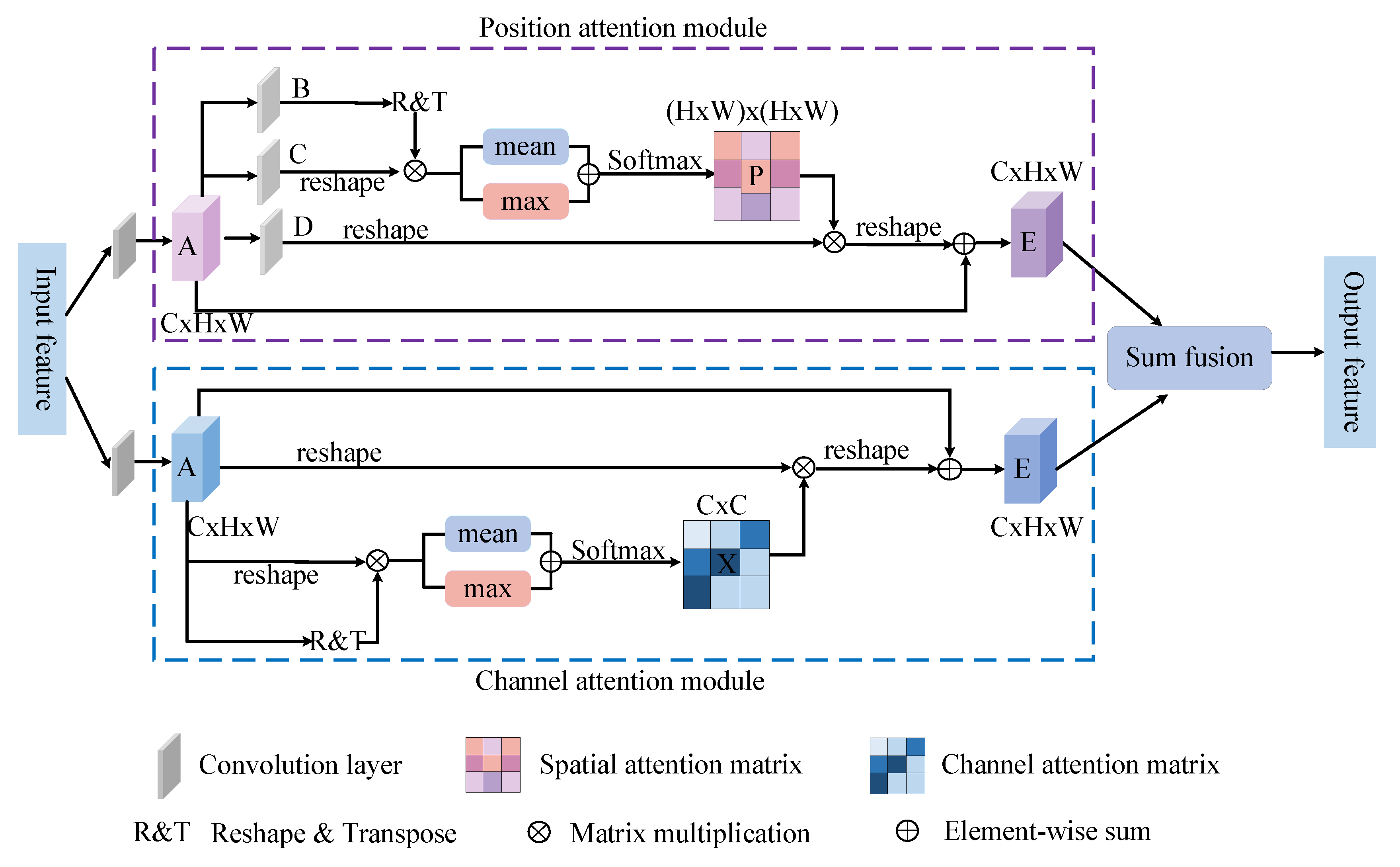
3.3. IDA Module
3.3.1. Position Attention Module
3.3.2. Channel Attention Module
3.4. Model Formulation
3.5. Learning
| Algorithm 1. DHIDA. |
| Input: Given . Output: Updated parameters H. Initialization: Initialize the ResNet18 model; Initialize parameters from the pre-trained ResNet18 model; Randomly sampled from Gaussian distribution. Repeat: Randomly select a mini batch of images from . Execute the following actions for each image ,: Calculate by forward backpropagation; Calculate ; Calculate hash code of and derivatives for according to (17), (18) and (19); Update the parameters Until iterations completed |
4. Experiments
4.1. Data Sets
4.2. Evaluation Metrics and Settings
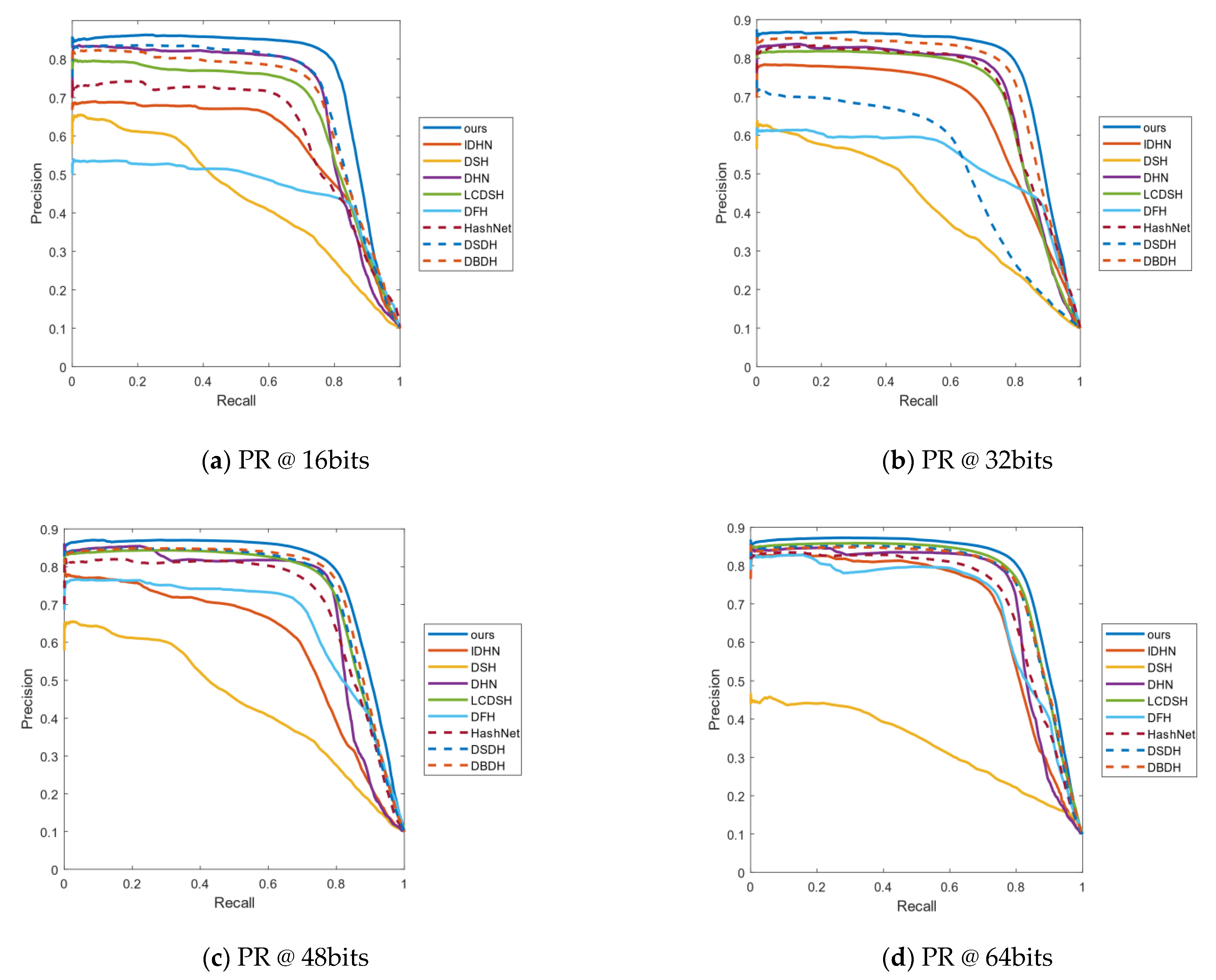
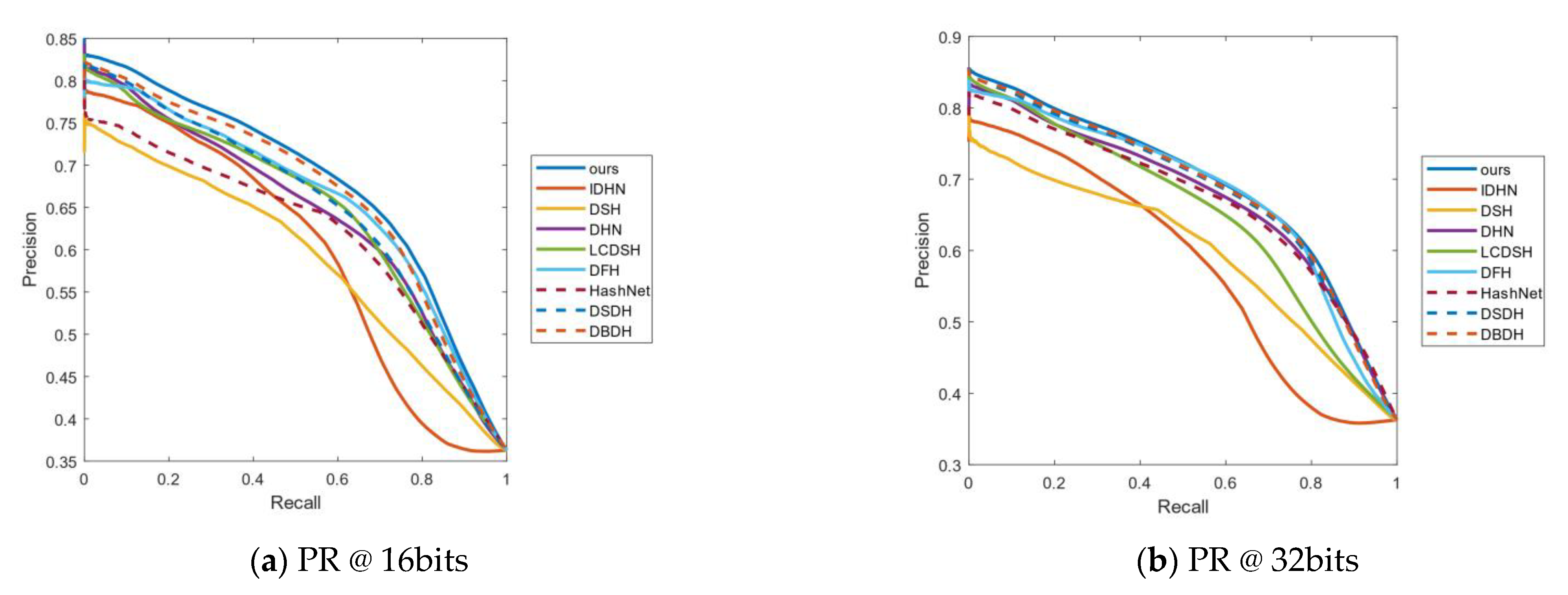
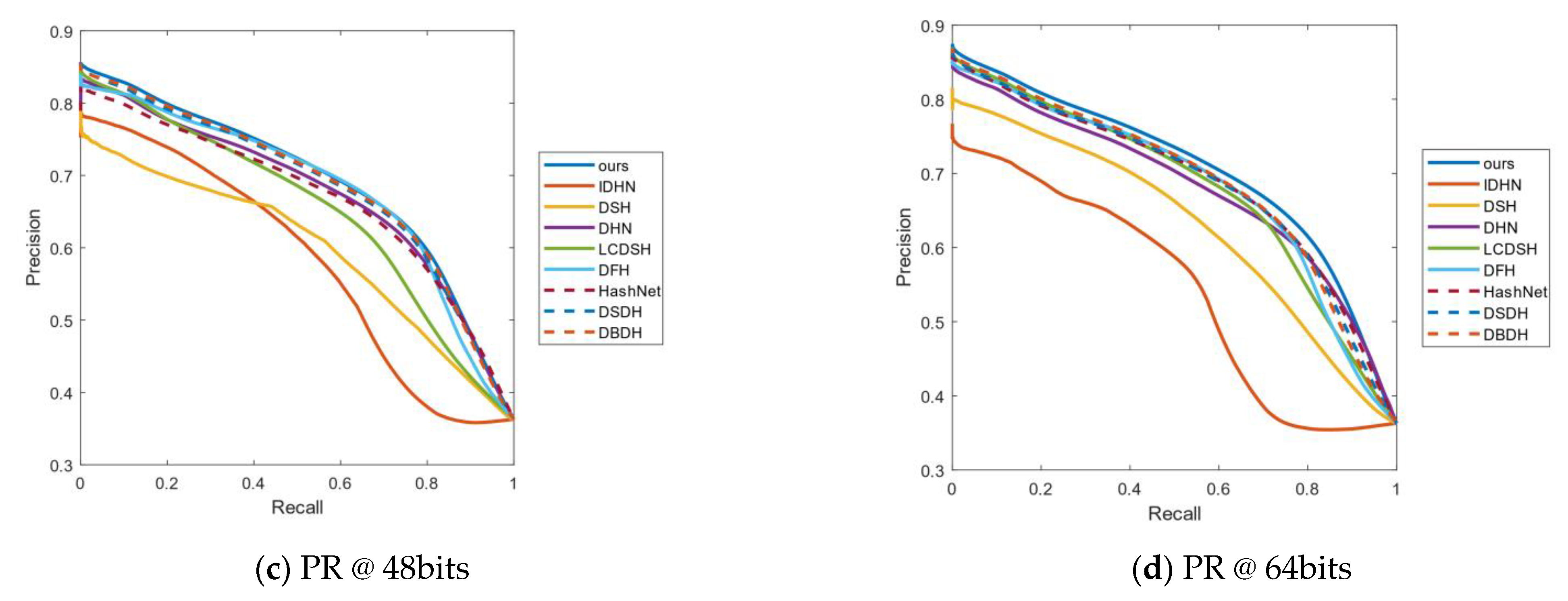
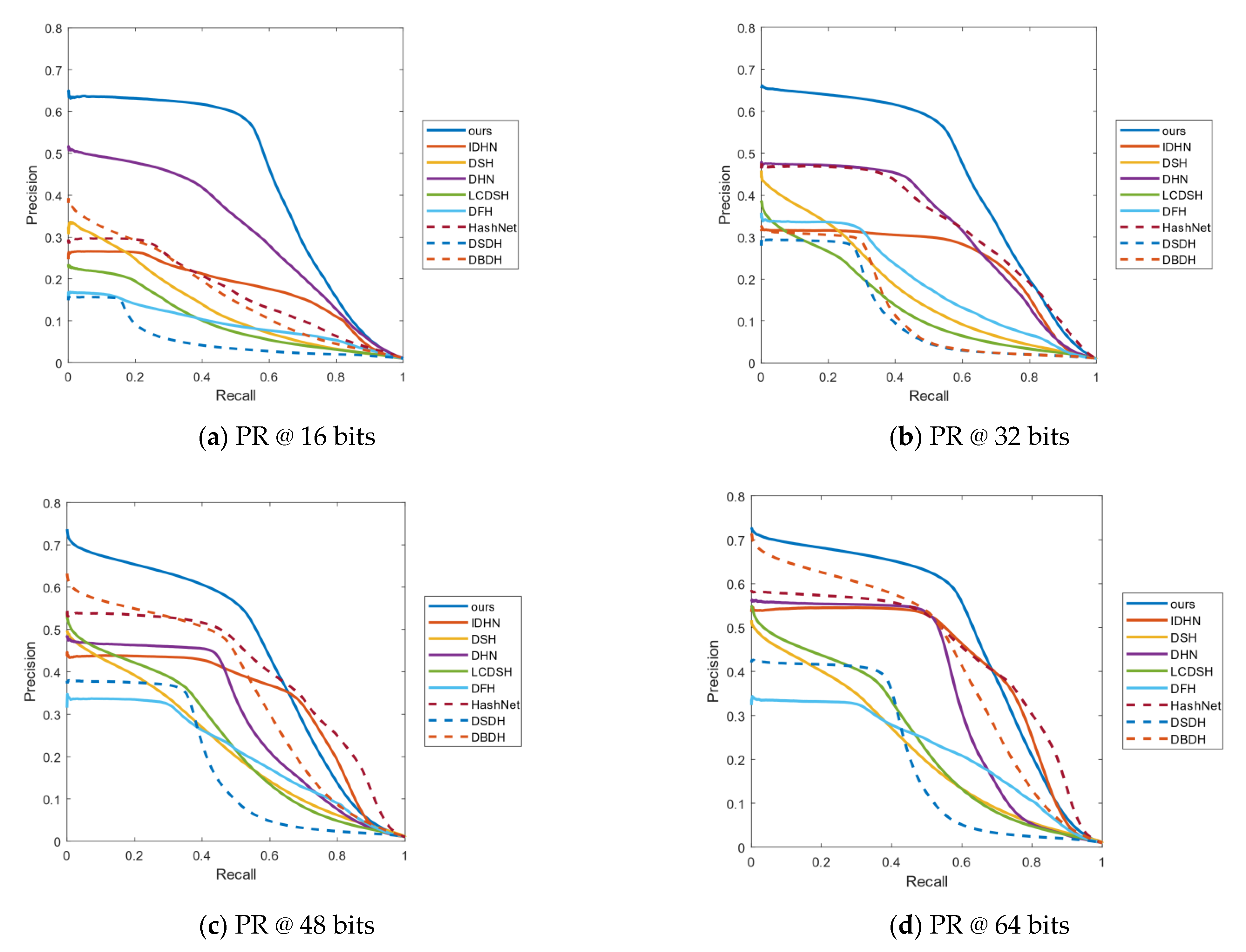
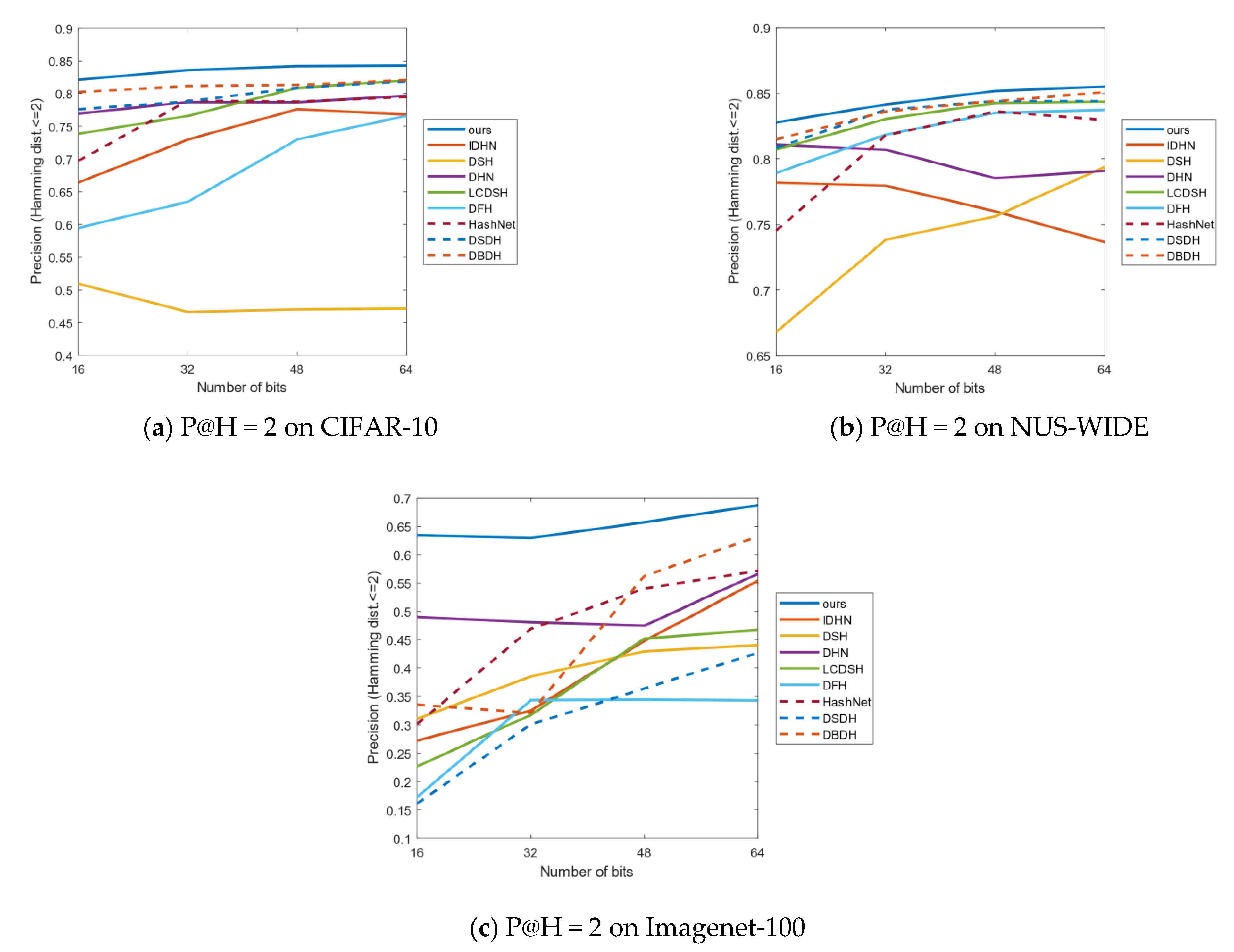
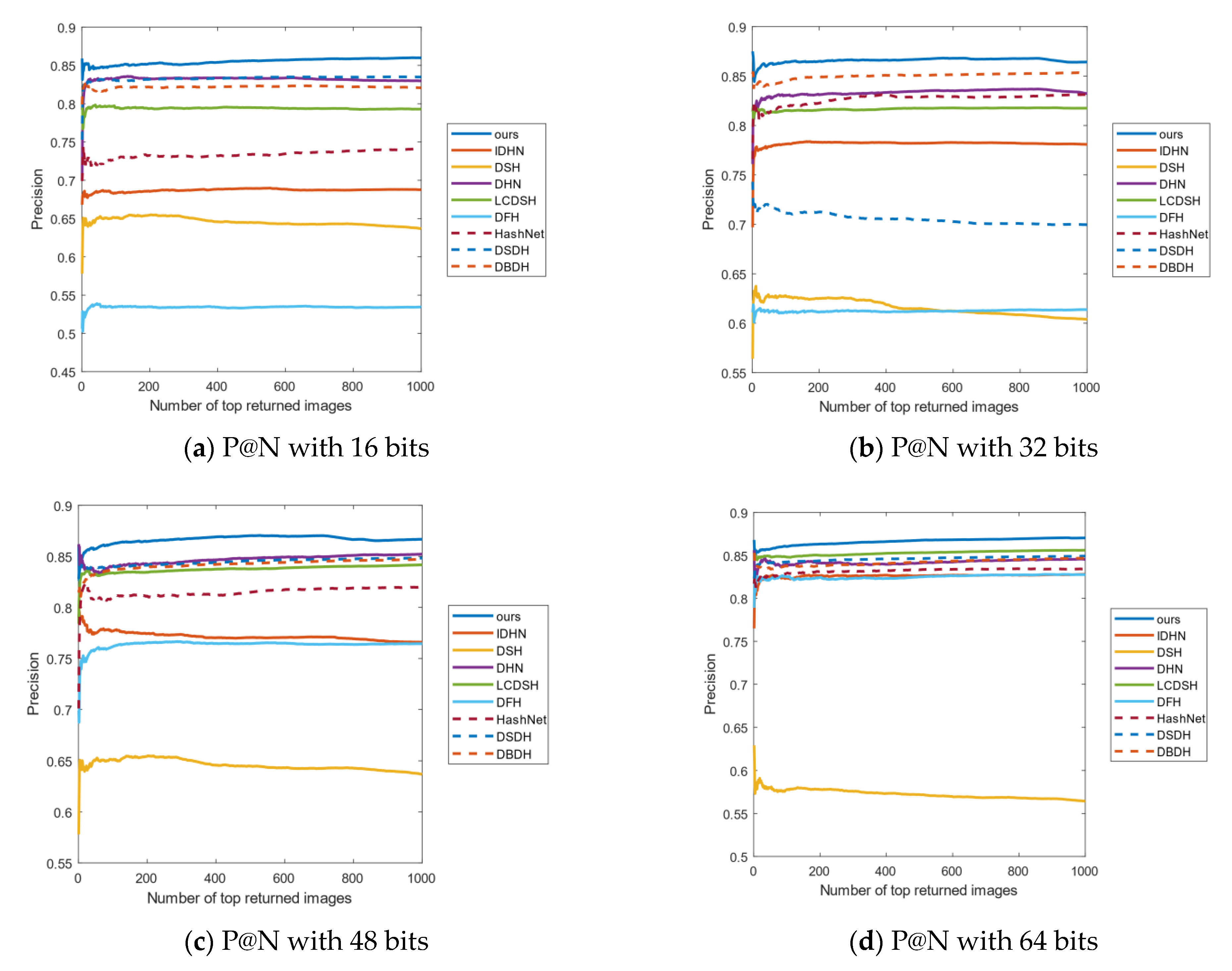
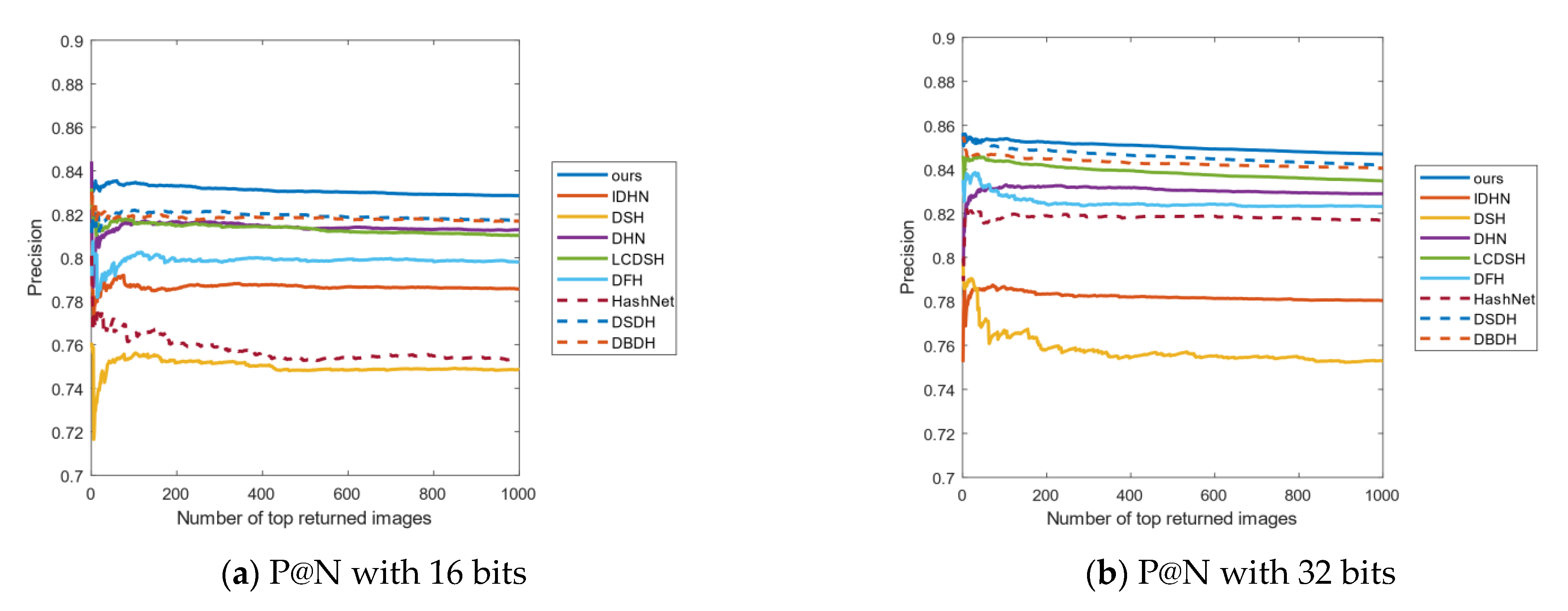
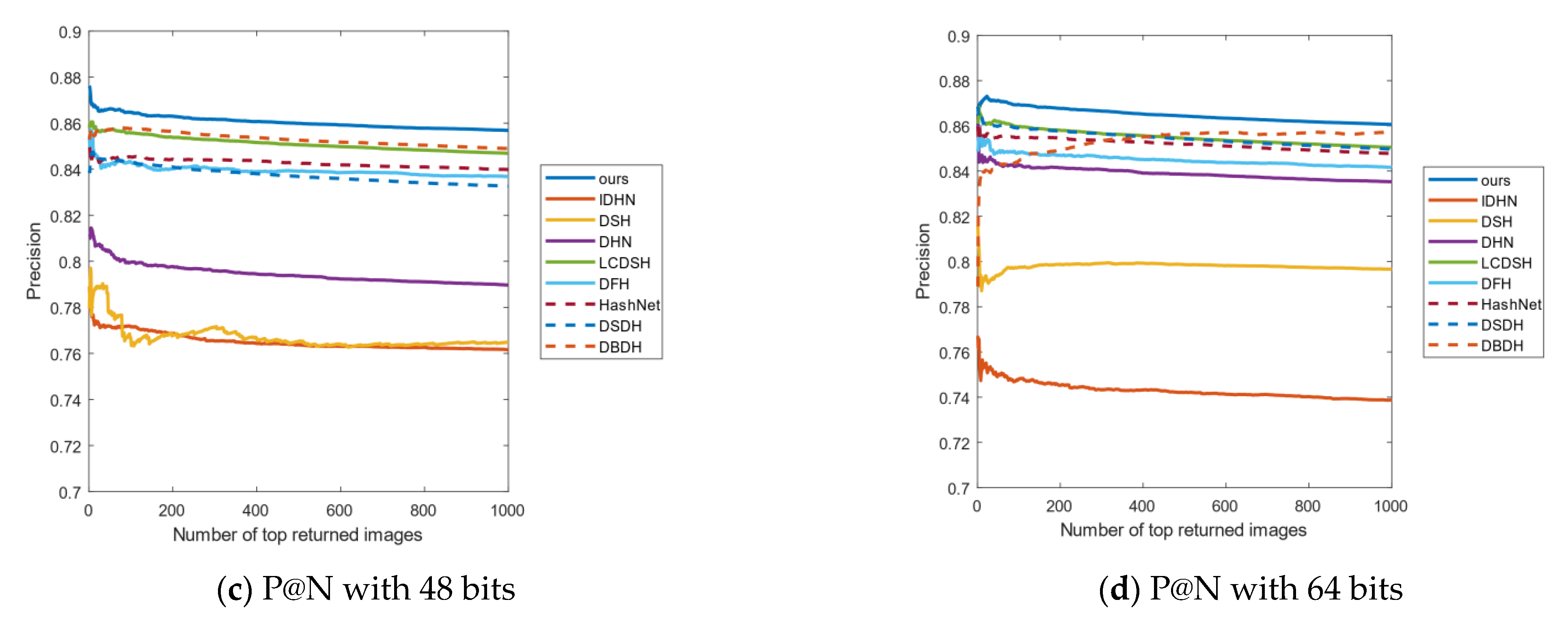
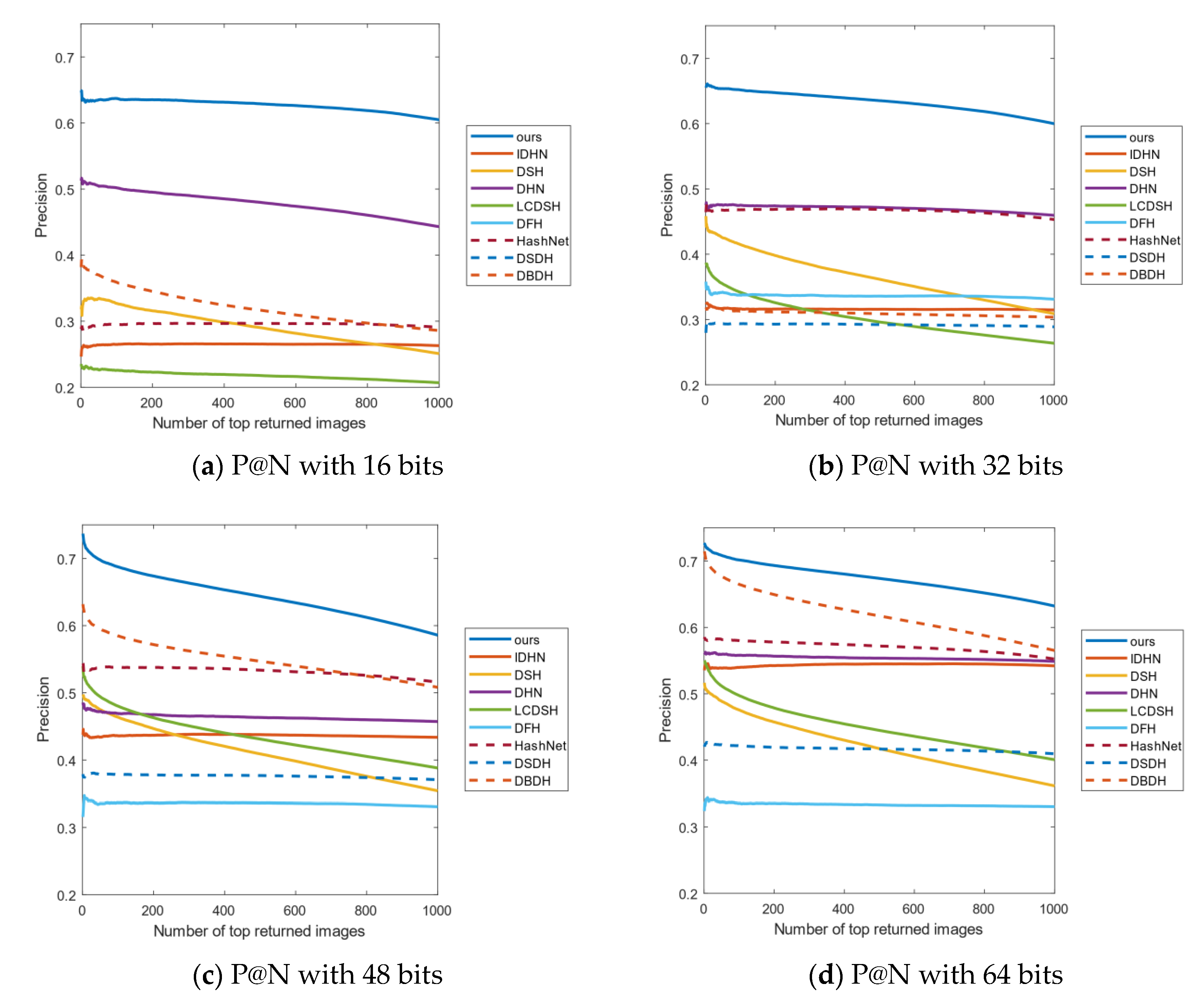
4.3. Results Analysis
4.4. Empirical Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z.; Liu, L.; Shen, F. Binary multi-view clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1774–1782. [Google Scholar] [CrossRef] [PubMed]
- Pachori, S.; Deshpande, A. Hashing in the zero-shot framework with domain adaptation. Neurocomputing 2018, 275, 2137–2149. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Lin, K.; Yang, H.F.; Hsiao, J.H. Deep learning of binary hash codes for fast image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 27–35. [Google Scholar]
- Li, W.J.; Wang, S. Feature learning based deep supervised hashing with pairwise labels. arXiv 2015, arXiv:1511.03855. [Google Scholar]
- Huang, L.K.; Chen, J. Accelerate learning of deep hashing with gradient attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5271–5280. [Google Scholar]
- Yuan, L.; Wang, T. Central similarity quantization for efficient image and video retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 3083–3092. [Google Scholar]
- Lv, N.; Wang, Y. Deep Hashing for Motion Capture Data Retrieval. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2215–2219. [Google Scholar]
- Gong, Y.; Lazebnik, S. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2916–2929. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Han, L. Hashing nets for hashing: A quantized deep learning to hash framework for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7331–7345. [Google Scholar] [CrossRef]
- Zhe, X.; Chen, S. Deep class-wise hashing: Semantics-preserving hashing via class-wise loss. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1681–1695. [Google Scholar] [CrossRef] [Green Version]
- Yan, X.; Zhu, F.; Yu, P.S.; Han, J. Feature-based similarity search in graph structures. ACM Trans. Database Syst. (TODS) 2006, 31, 1418–1453. [Google Scholar] [CrossRef]
- Liu, D.; Shen, J.; Xia, Z.; Sun, X. A content-based image retrieval scheme using an encrypted difference histogram in cloud computing. Information 2017, 8, 96. [Google Scholar] [CrossRef] [Green Version]
- Zheng, L.; Yang, Y. A Decade Survey of Instance Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1224–1244. [Google Scholar] [CrossRef] [Green Version]
- Datar, M.; Immorlica, N. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the Twentieth Annual Symposium on Computational Geometry, Brooklyn, NY, USA, 8–11 June 2004; pp. 253–262. [Google Scholar]
- Yang, H.F.; Lin, K. Supervised learning of semantics-preserving hash via deep convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 437–451. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, H.; Wang, R. Deep supervised hashing for fast image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2064–2072. [Google Scholar]
- Zheng, X.; Zhang, Y. Deep balanced discrete hashing for image retrieval. Neurocomputing 2020, 403, 224–236. [Google Scholar] [CrossRef]
- Wagenpfeil, S.; Engel, F.; Kevitt, P.M.; Hemmje, M. Ai-based semantic multimedia indexing and retrieval for social media on smartphones. Information 2021, 12, 43. [Google Scholar] [CrossRef]
- Li, Q.; Sun, Z. Deep supervised discrete hashing. arXiv 2017, arXiv:1705.10999. [Google Scholar]
- Fan, L.; Ng, K.W. Deep polarized network for supervised learning of accurate binary hashing codes. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 7–15 January 2020; pp. 825–831. [Google Scholar]
- Wang, J.; Chen, B.; Dai, T.; Xia, S.T. Webly Supervised Deep Attentive Quantization. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2250–2254. [Google Scholar]
- Jiang, Q.Y.; Cui, X.; Li, W.J. Deep discrete supervised hashing. IEEE Trans. Image Process. 2018, 27, 5996–6009. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Z.; Raymond, O.I. Deep attention-guided hashing. IEEE Access 2019, 7, 11209–11221. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Fu, J.; Liu, J.; Jiang, J.; Li, Y.; Bao, Y. Scene segmentation with dual relation-aware attention network. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2547–2560. [Google Scholar] [CrossRef]
- Gong, Y.; Wang, L.; Li, Y. A Discriminative Person Re-Identification Model with Global-Local Attention and Adaptive Weighted Rank List Loss. IEEE Access 2020, 8, 203700–203711. [Google Scholar] [CrossRef]
- Weiss, Y.; Torralba, A. Spectral hashing. NIPS 2008, 1, 4. [Google Scholar]
- Liu, W.; Wang, J.; Kumar, S.; Chang, S.F. Hashing with graphs. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Xia, R.; Pan, Y. Supervised hashing for image retrieval via image representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Lai, H.; Pan, Y. Simultaneous feature learning and hash coding with deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3270–3278. [Google Scholar]
- Wang, X.; Shi, Y. Deep supervised hashing with triplet labels. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 70–84. [Google Scholar]
- Zhu, H.; Long, M.; Wang, J. Deep hashing network for efficient similarity retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Burlingame, CA, USA, 8–12 October 2016; Volume 30. [Google Scholar]
- Cao, Z.; Long, M. Hashnet: Deep learning to hash by continuation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5608–5617. [Google Scholar]
- Cao, Y.; Long, M. Deep cauchy hashing for hamming space retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1229–1237. [Google Scholar]
- Zhang, Z.; Zou, Q. Improved deep hashing with soft pairwise similarity for multi-label image retrieval. IEEE Trans. Multimed. 2019, 22, 540–553. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Peng, C. Hierarchical Deep Hashing for Fast Large-Scale Image Retrieval. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3837–3844. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- Zhu, H.; Gao, S. Locality Constrained Deep Supervised Hashing for Image Retrieval. In Proceedings of the 2017 International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3567–3573. [Google Scholar]
- Li, Y.; Pei, W. Push for quantization: Deep fisher hashing. arXiv 2019, arXiv:1909.00206. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Configuration |
|---|---|
| Conv1 | {64 × 112 × 112, k = 7 × 7, s = 2 × 2, p = 3 × 3, ReLU} |
| Maxpool | {64 × 54 × 54, k = 3 × 3, s = 2 × 2, p = 1 × 1, ReLU} |
| Layer1 | {64 × 56 × 56, k = 3 × 3, s = 1 × 1, p = 1 × 1, ReLU} × 4 |
| Layer2 | {128 × 28 × 28, k = 3 × 3, s = 2 × 2, p = 1 × 1, ReLU} × 4 |
| Layer3 | {256 × 14 × 14, k = 3 × 3, s = 2 × 2, p = 1 × 1, ReLU} × 4 |
| Layer4 | {512 × 7 × 7, k = 3 × 3, s = 2 × 2, p = 1 × 1, ReLU} × 4 |
| Avgpool | 512 × 1 × 1 |
| fch | K, the length of hash code |
| Item | Configuration |
|---|---|
| OS | Ubuntu 16.04 (×64) |
| GPU | Tesla V100 |
| Method | CIFAR-10 (mAP@ALL) | NUS-WIDE (mAP@5000) | Imagenet-100 (mAP@1000) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 bit | 32 bit | 48 bit | 64 bit | 16 bit | 32 bit | 48 bit | 64 bit | 16 bit | 32 bit | 48 bit | 64 bit | |
| DHIDA | 0.8213 | 0.8359 | 0.8420 | 0.8428 | 0.8278 | 0.8414 | 0.8519 | 0.8552 | 0.6346 | 0.6296 | 0.6573 | 0.6870 |
| DBDH | 0.8021 | 0.8113 | 0.8129 | 0.8209 | 0.8150 | 0.8360 | 0.8442 | 0.8484 | 0.3358 | 0.3215 | 0.5626 | 0.6321 |
| DSDH | 0.7761 | 0.7881 | 0.8086 | 0.8183 | 0.8085 | 0.8373 | 0.8441 | 0.8441 | 0.1612 | 0.3011 | 0.3638 | 0.4268 |
| DHN | 0.7695 | 0.7871 | 0.7869 | 0.7966 | 0.8108 | 0.8069 | 0.7854 | 0.7910 | 0.4900 | 0.4808 | 0.4747 | 0.5664 |
| LCDSH | 0.7383 | 0.7661 | 0.8083 | 0.8202 | 0.8071 | 0.8304 | 0.8425 | 0.8436 | 0.2269 | 0.3177 | 0.4517 | 0.4671 |
| HashNet | 0.6975 | 0.7892 | 0.7878 | 0.7949 | 0.7453 | 0.8180 | 0.8361 | 0.8297 | 0.3017 | 0.4690 | 0.5400 | 0.5719 |
| IDHN | 0.6641 | 0.7296 | 0.7762 | 0.7682 | 0.7820 | 0.7795 | 0.7601 | 0.7366 | 0.2721 | 0.3255 | 0.4477 | 0.5539 |
| DFH | 0.5947 | 0.6347 | 0.7298 | 0.7662 | 0.7893 | 0.8185 | 0.8350 | 0.8372 | 0.1727 | 0.3435 | 0.3445 | 0.3430 |
| DSH | 0.5095 | 0.4663 | 0.4702 | 0.4714 | 0.6680 | 0.7383 | 0.7563 | 0.7940 | 0.3109 | 0.3848 | 0.4294 | 0.4403 |
| DHIDA-A | DHIDA-I | DHIDA-R | DHIDA-D | DHIDA | |
|---|---|---|---|---|---|
| Alexnet | √ | √ | |||
| ResNet18 | √ | √ | √ | ||
| √ | √ | √ | √ | ||
| DANet | √ | ||||
| IDA | √ | ||||
| mAP | 0.7240 | 0.7641 | 0.8021 | 0.8076 | 0.8213 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Wang, L.; Cheng, S.; Li, Y.; Du, A. Deep Hash with Improved Dual Attention for Image Retrieval. Information 2021, 12, 285. https://doi.org/10.3390/info12070285
Yang W, Wang L, Cheng S, Li Y, Du A. Deep Hash with Improved Dual Attention for Image Retrieval. Information. 2021; 12(7):285. https://doi.org/10.3390/info12070285
Chicago/Turabian StyleYang, Wenjing, Liejun Wang, Shuli Cheng, Yongming Li, and Anyu Du. 2021. "Deep Hash with Improved Dual Attention for Image Retrieval" Information 12, no. 7: 285. https://doi.org/10.3390/info12070285
APA StyleYang, W., Wang, L., Cheng, S., Li, Y., & Du, A. (2021). Deep Hash with Improved Dual Attention for Image Retrieval. Information, 12(7), 285. https://doi.org/10.3390/info12070285