
Maximizing Image Information Using Multi-Chimera Transform Applied on Face Biometric Modality




Abstract
:1. Introduction
- We suggest a novel scheme for image transform, which can be used for data reduction with maximum information.
- A large-scale evaluation of the proposed scheme using 5913 facial images was performed. The warp faces of AR had (2600) images, the full image of AR had (3315) images, and the full image from websites had (16) images.
- Implement a proposed scheme, which is invariant for subject diversities (142 persons), light conditions (right side, left side, and both sides), facial expression (neutral, smile, anger, scream), and facial occlusions (prescription eyeglasses, sunglasses, scarf, and hat) within different sessions (two sessions 14 days apart).
- The proposed scheme successfully maintained the information for solid biometric such as face and ocular biometric modalities, and it could be applied to preserve the information of soft biometric modalities such as eyebrow, eyeglasses, sunglasses, scraf, and hat.
2. Problem Statement of Image Data Reduction
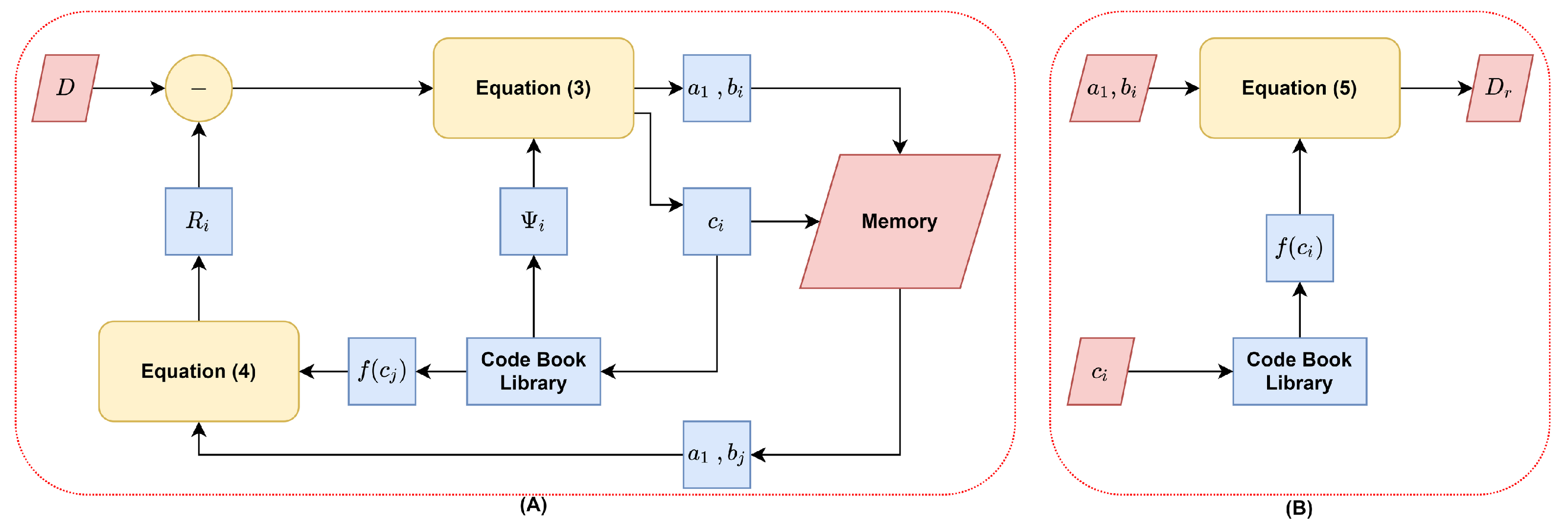
2.1. The Concept of Multi-Chimera Transform (MCT)
2.2. Codebook Generation of MCT
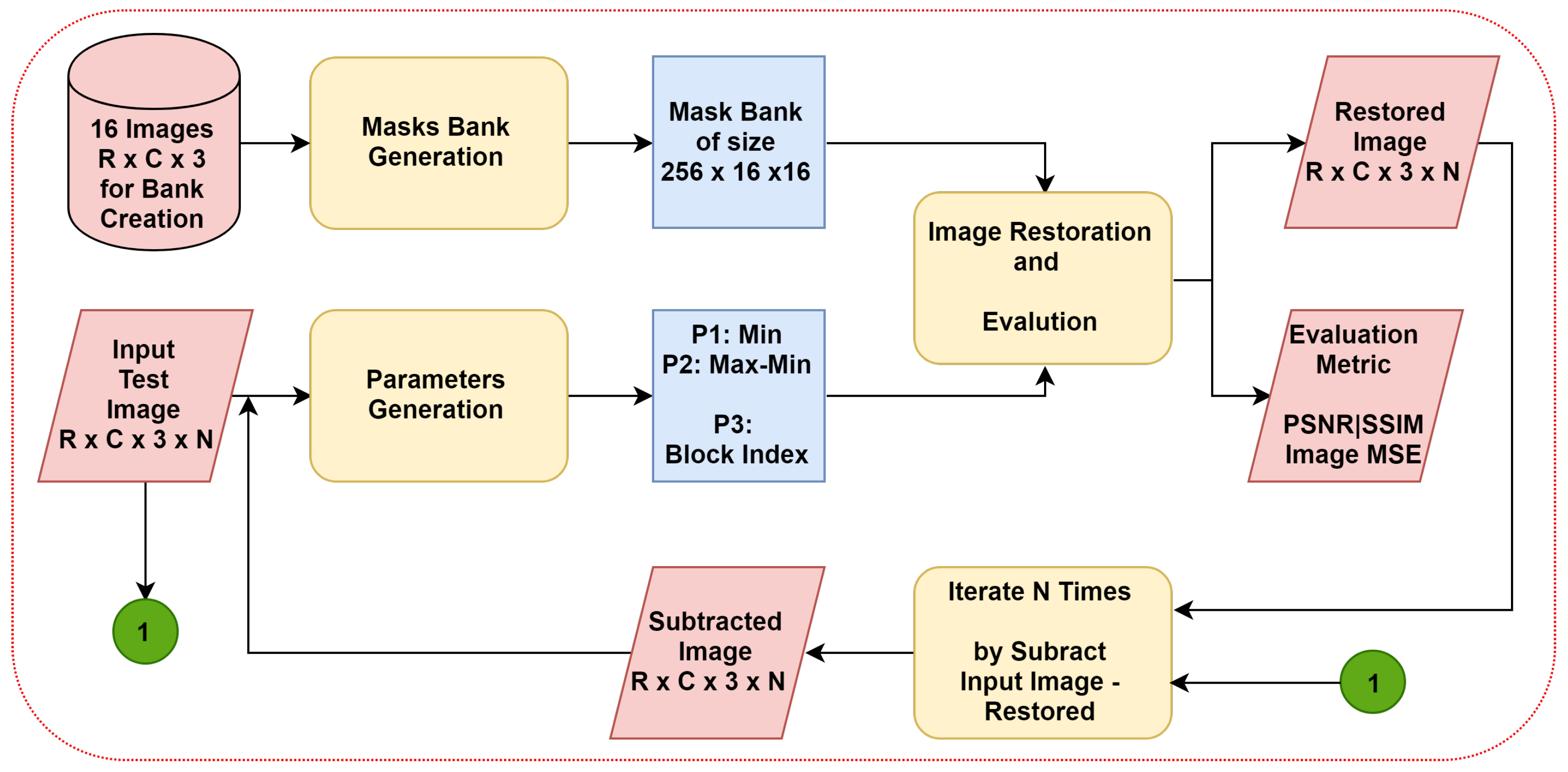
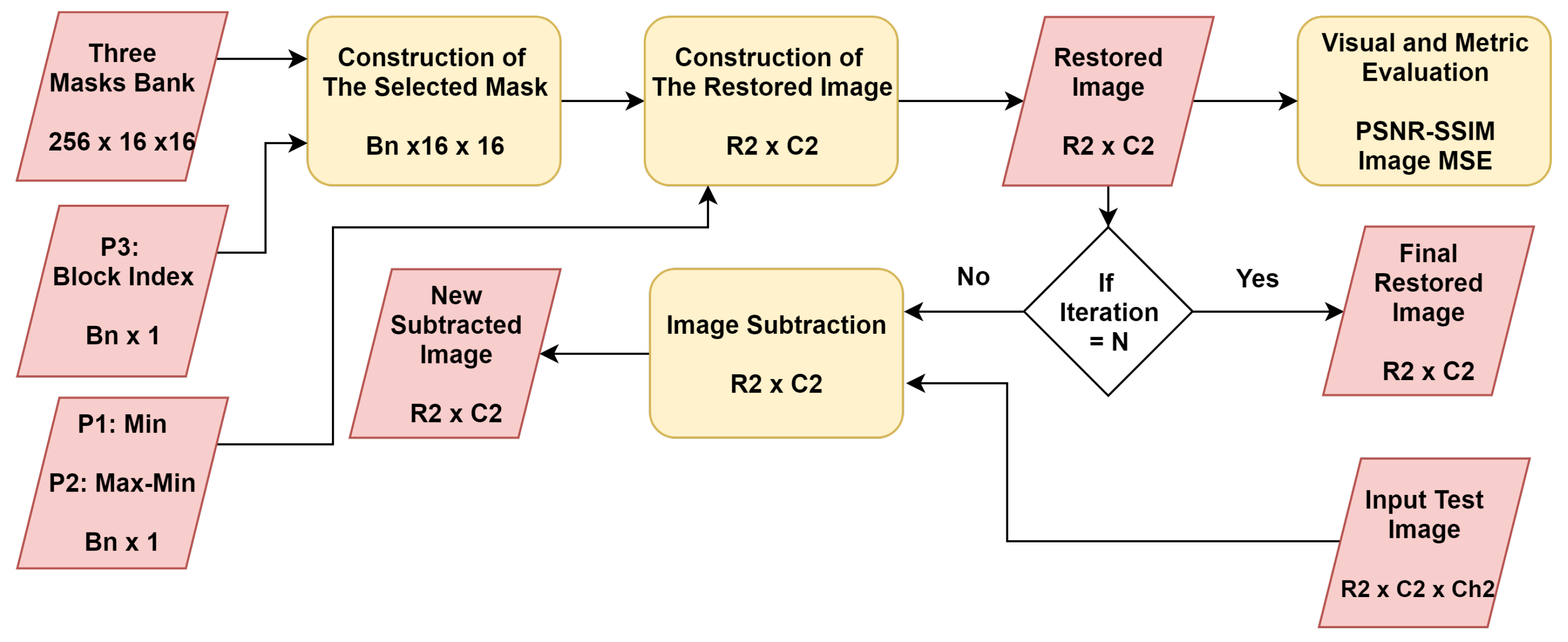
3. The Proposed Approach
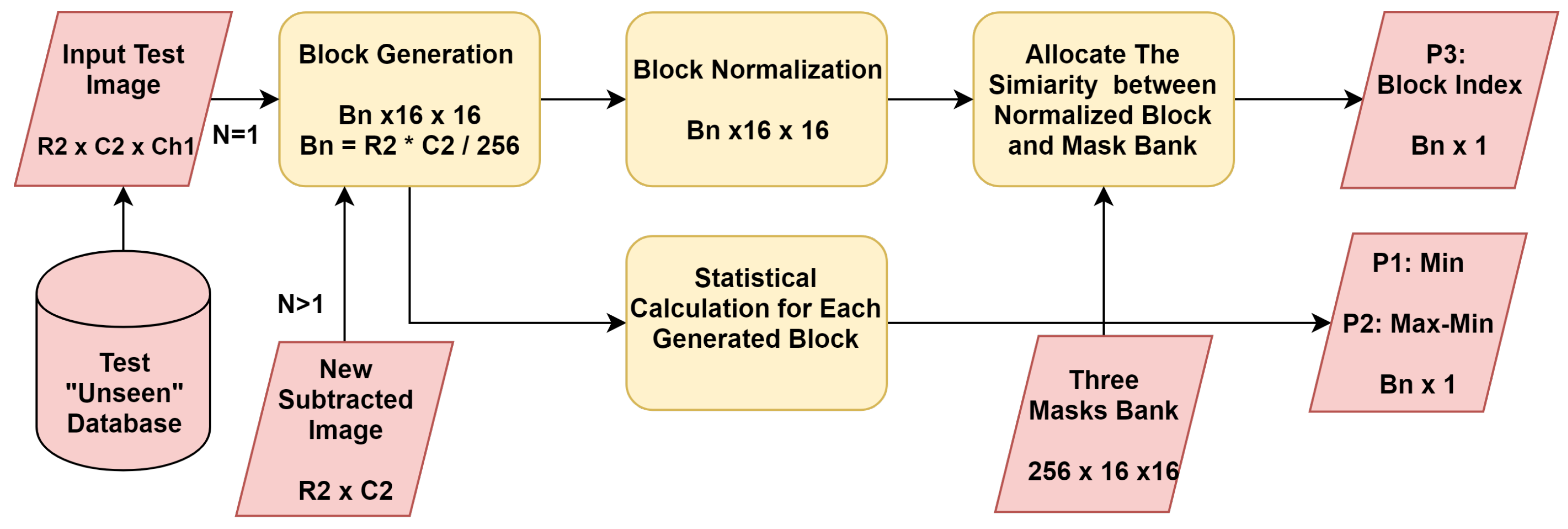
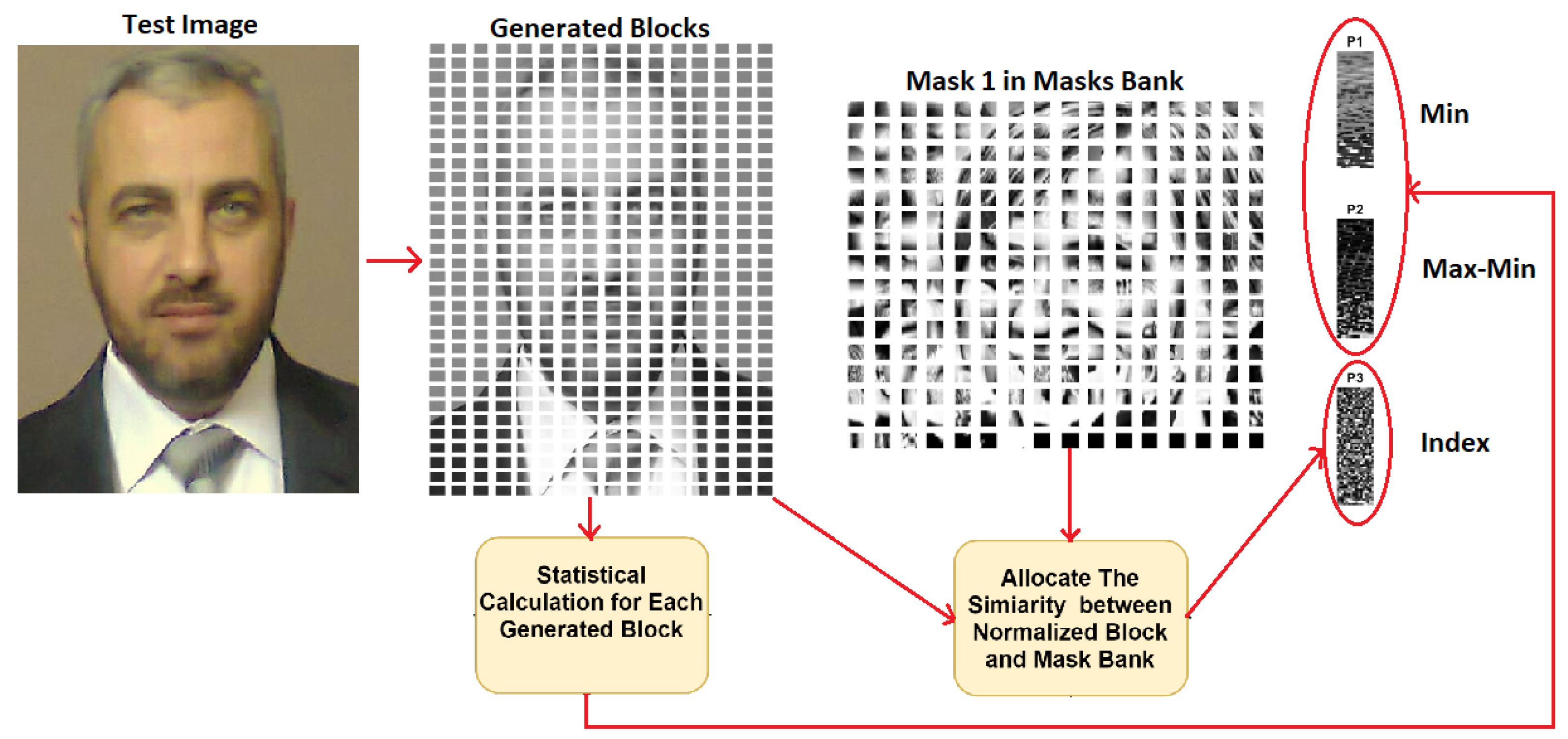
3.1. Mask Bank Generation
- The most similar (minimum MAE) value was kept in the first mask bank while the other 15 values were excluded.
- The most similar (minimum MAE) value was subtracted from the most dissimilar (maximum MAE) value; thereafter, the normalized subtracted value was kept in the second mask bank while the other 14 values were excluded.
- The seventh similar value was subtracted from eighth similar value then the subtracted value was kept in the third mask bank and the other 14 values were excluded.
3.2. Parameter Generation
3.3. Image Restoration
4. Experiments
4.1. Databases
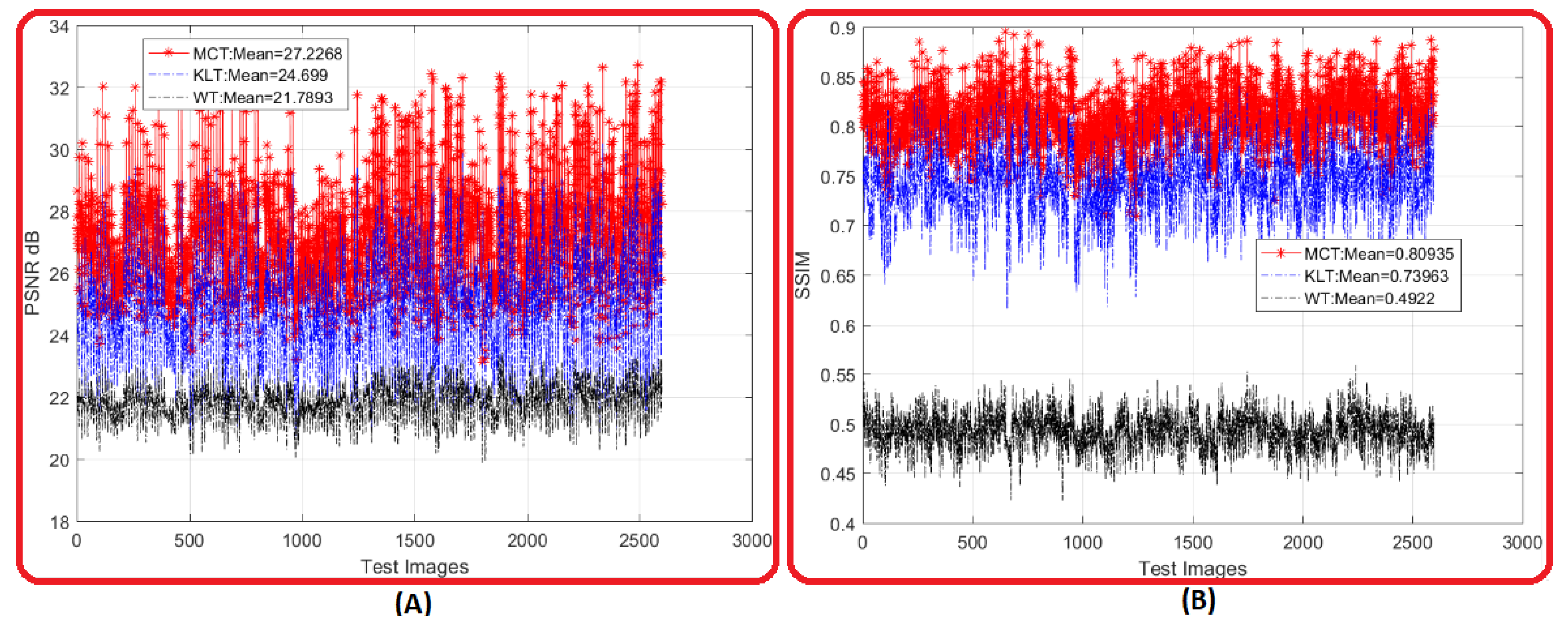
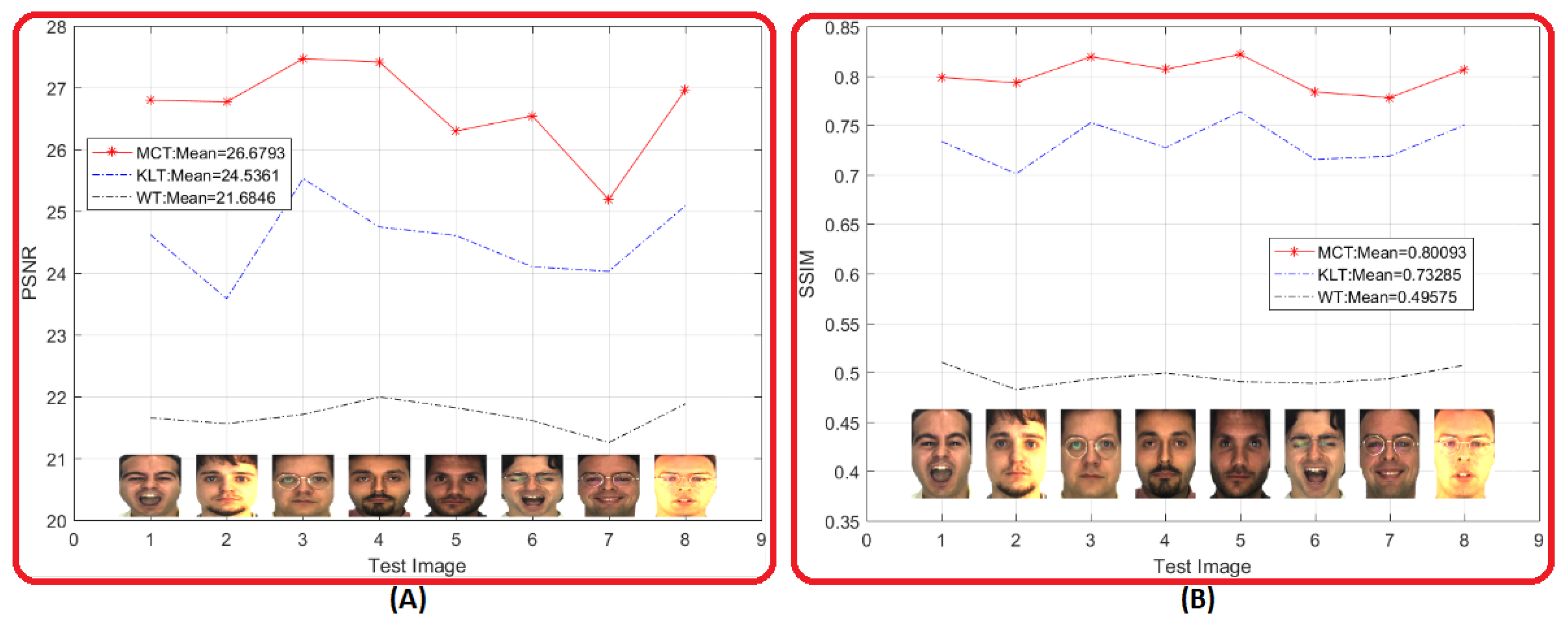
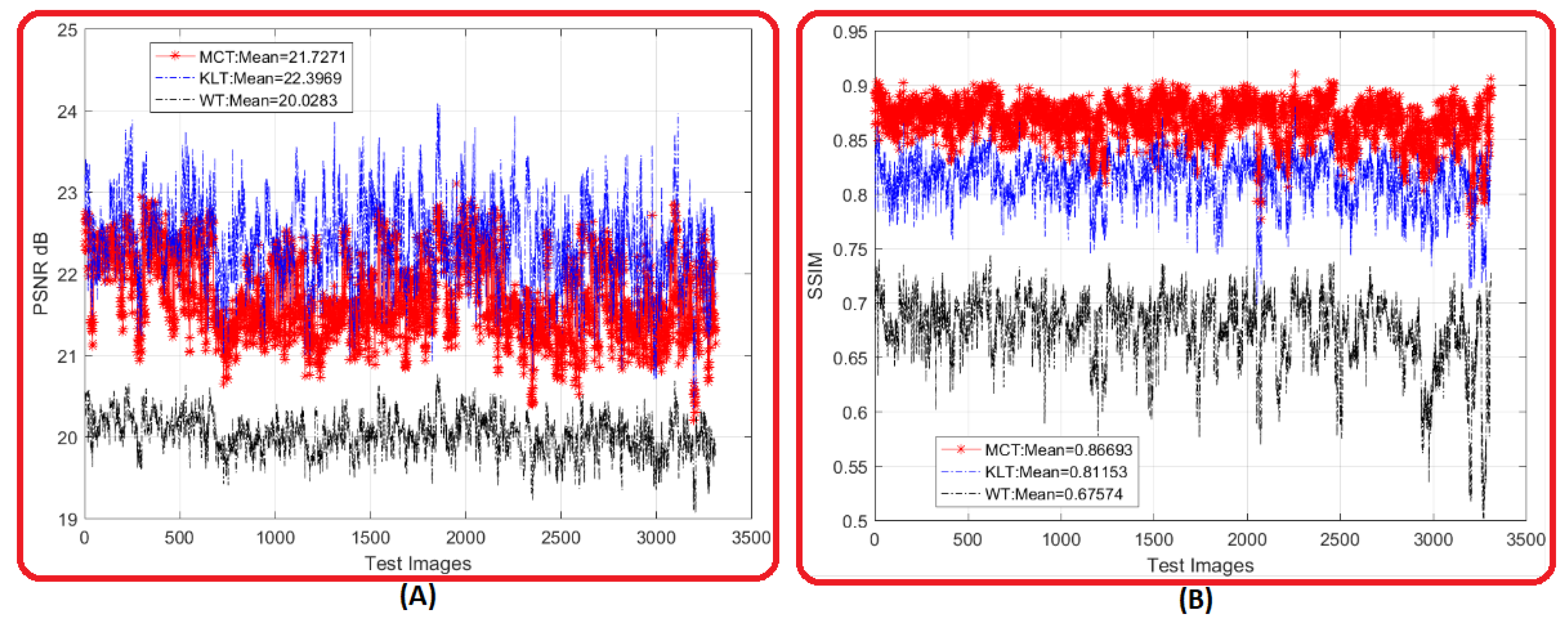
4.2. Visual Comparative Evaluation
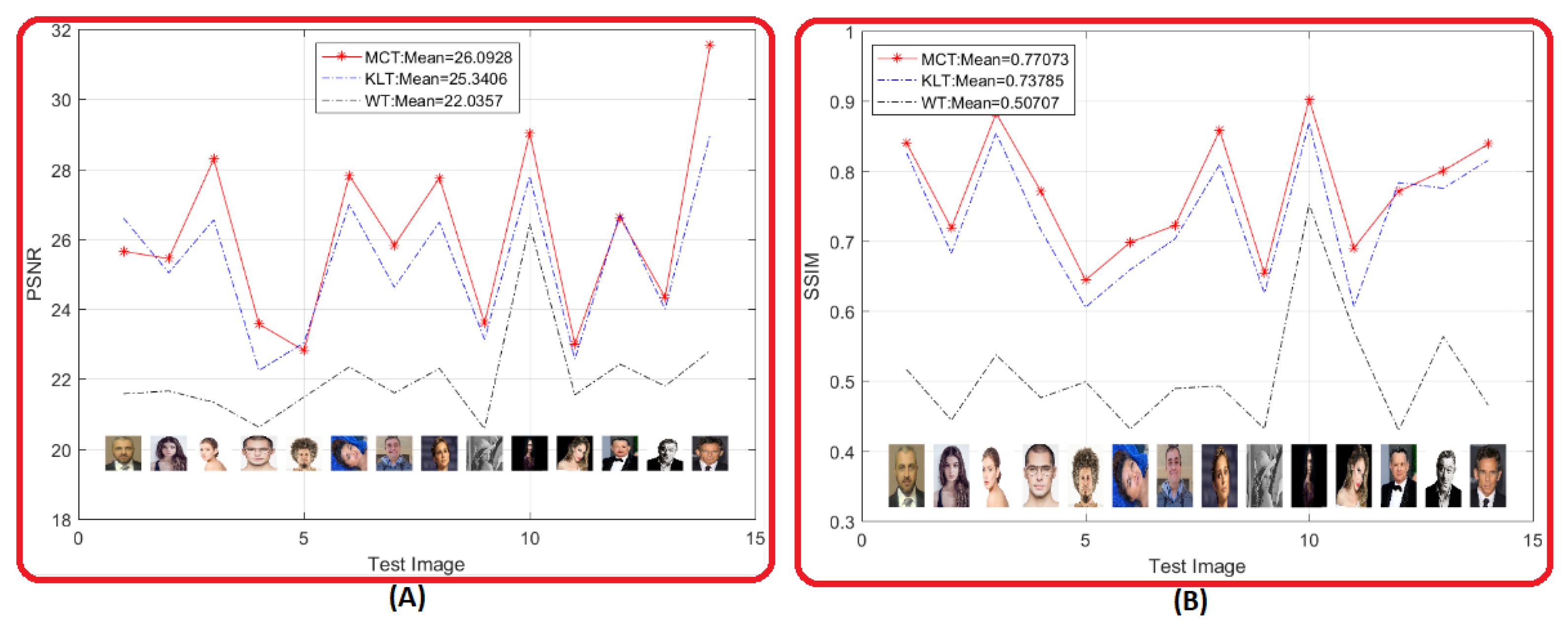
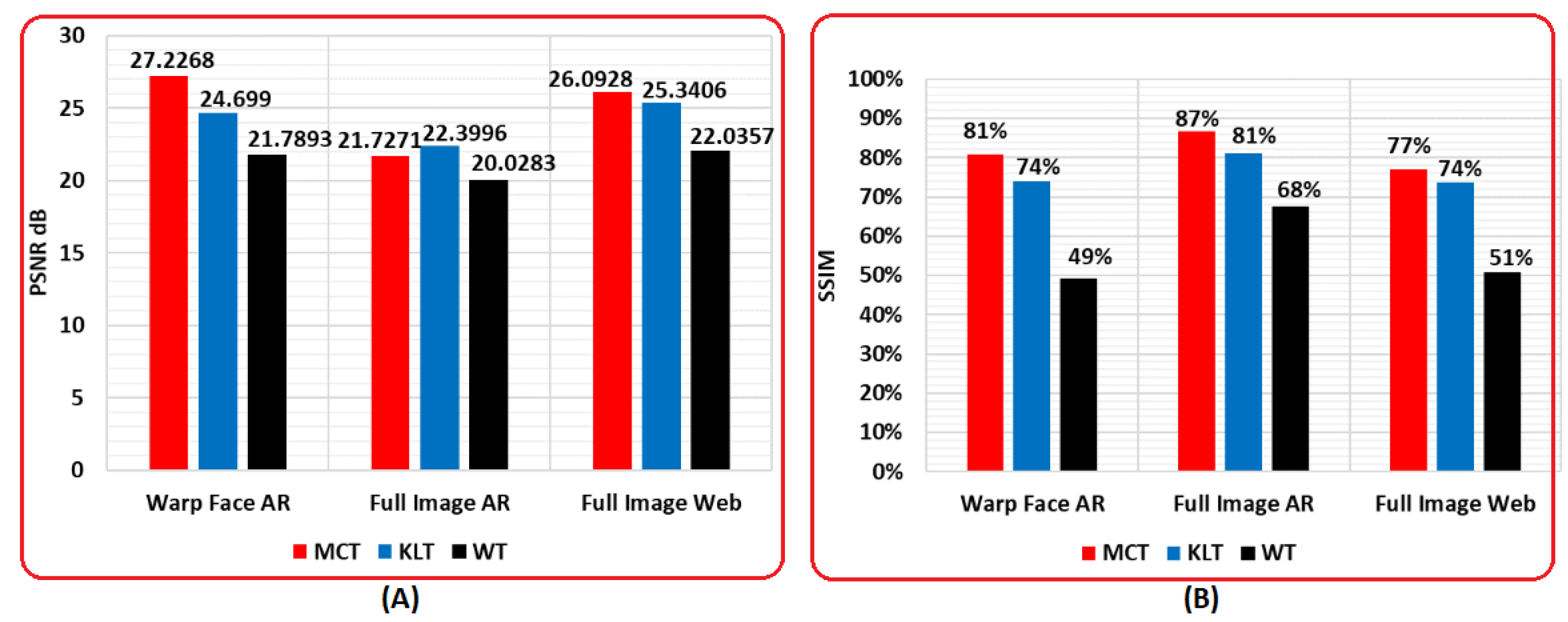
4.3. Metric Comparative Evaluation
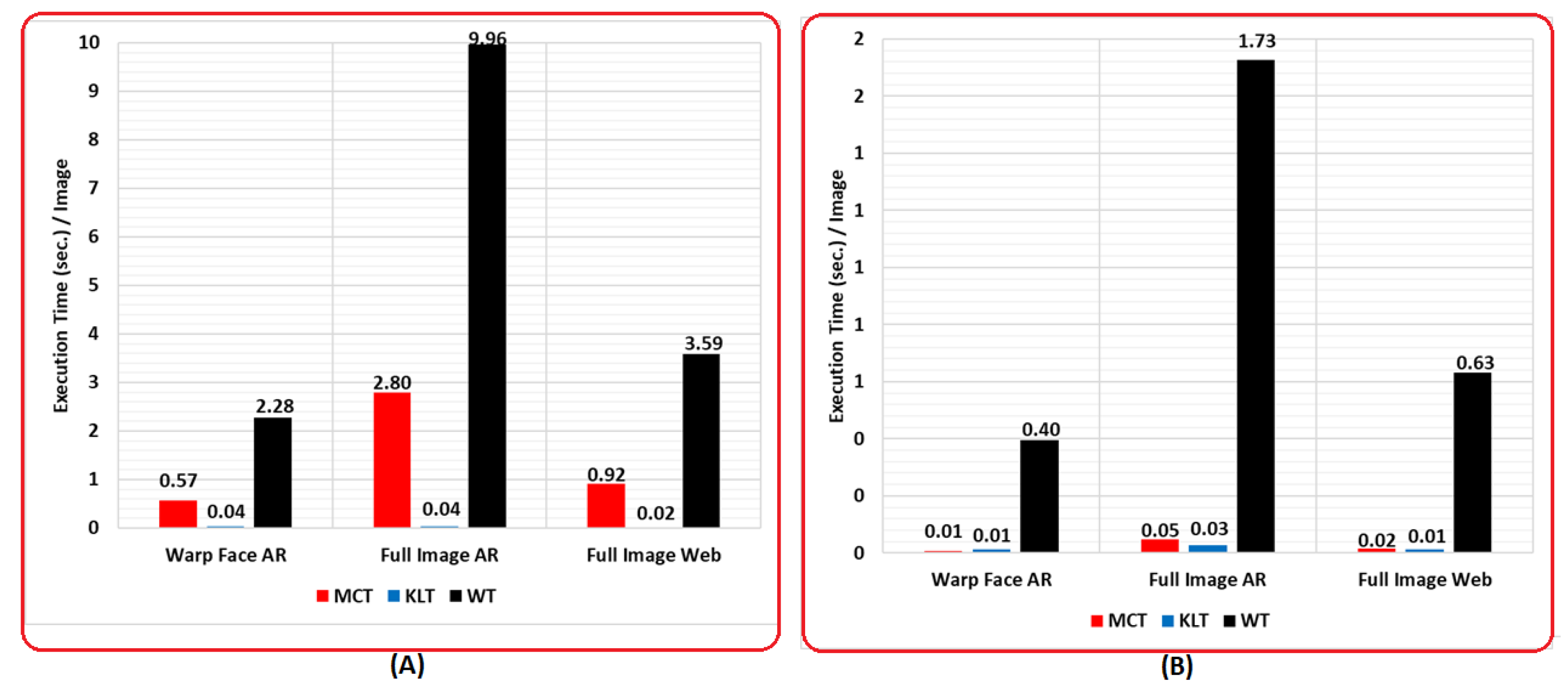
4.4. Complexity and Time Comparative Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MCT | Multi Chimera Transform |
| KLT | Karhunen–Loeve Transform |
| WT | Wavelet Transform |
| DCT | Discrete Cosine Transform |
| DFT | Discrete Fourier Transform |
| CT | Chimera Transform |
| PSNR | Peak Signal to Noise Ratio |
| SSIM | Structure Similarity Index Measure |
References
- Oliver, K.; Hou, W.; Wang, S. Image feature detection and matching in underwater conditions. In Proceedings of the SPIE Ocean Sensing and Monitoring II, Orlando, FL, USA, 20 April 2010; Volume 7678, p. 76780N. [Google Scholar]
- Lecron, F.; Benjelloun, M.; Mahmoudi, S. Descriptive image feature for object detection in medical images. In Proceedings of the International Conference Image Analysis and Recognition, Aveiro, Portugal, 25–27 June 2012; pp. 331–338. [Google Scholar]
- Kumawat, A.; Panda, S. Feature detection and description in remote sensing images using a hybrid feature detector. Procedia Comput. Sci. 2018, 132, 277–287. [Google Scholar] [CrossRef]
- Kam-art, R.; Raicharoen, T.; Khera, V. Face recognition using feature extraction based on descriptive statistics of a face image. In Proceedings of the 2009 International Conference on Machine Learning and Cybernetics, Baoding, China, 12–15 July 2009; Volume 1, pp. 193–197. [Google Scholar]
- Tahir, N.M.; Hussain, A.; Samad, S.A.; Husain, H.; Rahman, R. Human shape recognition using Fourier descriptor. J. Electr. Electron. Syst. Res. 2009, 2, 19–25. [Google Scholar]
- Guedri, B.; Zaied, M.; Amar, C.B. Indexing and images retrieval by content. In Proceedings of the 2011 International Conference on High Performance Computing & Simulation, Istanbul, Turkey, 4–8 July 2011; pp. 369–375. [Google Scholar]
- Fareed, M.M.S.; Chun, Q.; Ahmed, G.; Murtaza, A.; Rizwan Asif, M.; Fareed, M.Z. Salient region detection through salient and non-salient dictionaries. PLoS ONE 2019, 14, e0213433. [Google Scholar] [CrossRef] [PubMed]
- Bouganis, C.S.; Pournara, I.; Cheung, P.Y. Efficient mapping of dimensionality reduction designs onto heterogeneous FPGAs. In Proceedings of the 15th Annual IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM 2007), Napa, CA, USA, 23–25 April 2007; pp. 141–150. [Google Scholar]
- Divya, A.; Raja, K.; Venugopal, K. Sorting Pixels based Face Recognition Using Discrete Wavelet Transform and Statistical Features. In Proceedings of the 2019 3rd International Conference on Imaging, Signal Processing and Communication (ICISPC), Singapore, 27–29 July 2019; pp. 150–154. [Google Scholar]
- Manikantan, K.; Govindarajan, V.; Kiran, V.S.; Ramachandran, S. Face recognition using block-based DCT feature extraction. J. Adv. Comput. Sci. Technol. 2012, 1, 266–283. [Google Scholar]
- Hui, S.; Żak, S. Discrete Fourier transform based pattern classifiers. Bull. Pol. Acad. Sci. Tech. Sci. 2014, 62, 15–22. [Google Scholar] [CrossRef] [Green Version]
- Khalaf, W.; Mohammad, A.S.; Zaghar, D. Chimera: A New Efficient Transform for High Quality Lossy Image Compression. Symmetry 2020, 12, 378. [Google Scholar] [CrossRef] [Green Version]
- Georgy, K.; Forczmański, P. Data Dimensionality Reduction for Face Recognition. MGV 2004, 13, 99–121. [Google Scholar]
- Ghazali, K.H.; Mansor, M.F.; Mustafa, M.M.; Hussain, A. Feature extraction technique using discrete wavelet transform for image classification. In Proceedings of the 2007 5th Student Conference on Research and Development, Selangor, Malaysia, 11–12 December 2007; pp. 1–4. [Google Scholar]
- Hafed, Z.M.; Levine, M.D. Face recognition using the discrete cosine transform. Int. J. Comput. Vis. 2001, 43, 167–188. [Google Scholar] [CrossRef]
- Bi, S.; Wang, Q. Fractal image coding based on a fitting surface. J. Appl. Math. 2014, 2014, 634848. [Google Scholar] [CrossRef]
- Hua, Z.; Zhang, H.; Li, J. Image super resolution using fractal coding and residual network. Complexity 2019, 2019, 9419107. [Google Scholar] [CrossRef]
- Li, S.; Marsaglia, N.; Garth, C.; Woodring, J.; Clyne, J.; Childs, H. Data reduction techniques for simulation, visualization and data analysis. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2018; Volume 37, pp. 422–447. [Google Scholar]
- Chaturvedi, S.; Chaturvedi, A.; Tiwari, A.; Agarwal, S. Design Pattern Detection using Machine Learning Techniques. In Proceedings of the 2018 7th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 29–31 August 2018; pp. 1–6. [Google Scholar]
- Barreto, J.; Menezes, P.; Dias, J. Human-robot interaction based on haar-like features and eigenfaces. In Proceedings of the IEEE International Conference on Robotics and Automation, 2004, ICRA’04, New Orleans, LA, USA, 26 April–1 May 2004; Volume 2, pp. 1888–1893. [Google Scholar]
- Aznaveh, A.M.; Azar, F.T.; Mansouri, A. Face data base compression by hotelling transform using segmentation. In Proceedings of the 2007 9th International Symposium on Signal Processing and Its Applications, Sharjah, United Arab Emirates, 12–15 February 2007; pp. 1–4. [Google Scholar]
- Martinez, A.M.; Benavente, R. The AR face database. CVC 1998, 24, 24. [Google Scholar]
- Gastpar, M.; Dragotti, P.L.; Vetterli, M. The distributed karhunen–loeve transform. IEEE Trans. Inf. Theory 2006, 52, 5177–5196. [Google Scholar] [CrossRef] [Green Version]
- Pathak, R.S. The Wavelet Transform; Atlantic Press/World Scientific: Paris, France, 2009. [Google Scholar]
- Thompson, A. The cascading Haar wavelet algorithm for computing the Walsh–Hadamard transform. IEEE Signal Process. Lett. 2017, 24, 1020–1023. [Google Scholar] [CrossRef] [Green Version]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Coding Time | Decoding Time | ||||
|---|---|---|---|---|---|---|
| MCT | KLT | WT | MCT | KLT | WT | |
| Warp Face AR | 0.574 | 0.041 | 2.284 | 0.008 | 0.013 | 0.395 |
| Full Image AR | 2.801 | 0.040 | 9.959 | 0.048 | 0.027 | 1.728 |
| Full Image Web | 0.918 | 0.023 | 3.591 | 0.015 | 0.013 | 0.633 |
| Average | 1.431 | 0.035 | 5.278 | 0.024 | 0.018 | 0.919 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammad, A.S.; Zaghar, D.; Khalaf, W. Maximizing Image Information Using Multi-Chimera Transform Applied on Face Biometric Modality. Information 2021, 12, 115. https://doi.org/10.3390/info12030115
Mohammad AS, Zaghar D, Khalaf W. Maximizing Image Information Using Multi-Chimera Transform Applied on Face Biometric Modality. Information. 2021; 12(3):115. https://doi.org/10.3390/info12030115
Chicago/Turabian StyleMohammad, Ahmad Saeed, Dhafer Zaghar, and Walaa Khalaf. 2021. "Maximizing Image Information Using Multi-Chimera Transform Applied on Face Biometric Modality" Information 12, no. 3: 115. https://doi.org/10.3390/info12030115
APA StyleMohammad, A. S., Zaghar, D., & Khalaf, W. (2021). Maximizing Image Information Using Multi-Chimera Transform Applied on Face Biometric Modality. Information, 12(3), 115. https://doi.org/10.3390/info12030115