1. Introduction
Pioneered by Massey [
1], McEliece and Yu [
2], and Arikan [
3], the guessing problem is concerned with recovering the realization of a finite-valued random variable
X using a sequence of yes-no questions of the form “Is
?”, “Is
?”, etc., until correct. A commonly used performance metric for this problem is the
-th moment of the number of guesses until
X is revealed (where
is a positive parameter).
When guessing a length-
n i.i.d. sequence
(a tuple of
n components that are drawn independently according to the law of
X), the
-th moment of the number of guesses required to recover the realization of
grows exponentially with
n, and the exponential growth rate is referred to as the guessing exponent. The least achievable guessing exponent was derived by Arikan [
3], and it equals the order-
Rényi entropy of
X. Arikan’s result is based on the optimal deterministic guessing strategy, which proceeds in descending order of the probability mass function (PMF) of
.
In this paper, we propose and analyze a two-stage guessing strategy to recover the realization of an i.i.d. sequence . In Stage 1, the guesser is allowed to produce guesses of an ancillary sequence that is jointly i.i.d. with . In Stage 2, the guesser must recover . We show the following:
- 1.
When
is generated by component-wise application of a mapping
to
and the guesser is required to recover
in Stage 1 before proceeding to Stage 2, then the least achievable guessing exponent (i.e., the exponential growth rate of the
-th moment of the total number of guesses in the two stages) equals
where the maximum is between the order-
Rényi entropy of
and the conditional Arimoto–Rényi entropy of
X given
. We derive (
1) in
Section 3 and summarize our analysis in Theorem 1. We also propose a Huffman code-based construction of a function
f that is a viable candidate for the minimization of (
1) among all maps from
to
(see Algorithm 2 and Theorem 2).
- 2.
When
and
are jointly i.i.d. according to the PMF
and Stage 1 need not end with a correct guess of
(i.e., the guesser may proceed to Stage 2 even if
remains unknown), then the least achievable guessing exponent equals
where the supremum is over all PMFs
defined on the same set as
; and
and
denote, respectively, the (conditional) Shannon entropy and the Kullback–Leibler divergence. We derive (
2) in
Section 4 and summarize our analysis in Theorem 3. Parts of
Section 4 were presented in the conference paper [
4].
Our interest in the two-stage guessing problem is due to its relation to information measures: Analogous to how the Rényi entropy can be defined operationally via guesswork, as opposed to its axiomatic definition, we view (
1) and (
2) as quantities that capture at what cost and to what extent knowledge of
Y helps in recovering
X. For example, minimizing (
1) over descriptions
of
X can be seen as isolating the most beneficial information of
X in the sense that describing it in any more detail is too costly (the first term of the maximization in (
1) exceeds the second), whereas a coarser description leaves too much uncertainty (the second term exceeds the first). Similarly, but with the joint law of
fixed, (
2) quantifies the least (partial) information of
Y that benefits recovering
X (because an optimal guessing strategy will proceed to Stage 2 when guessing
Y no longer benefits guessing
X). Note that while (
1) and (
2) are derived in this paper, studying their information-like properties is a subject of future research (see
Section 5).
Besides its theoretic implications, the guessing problem is also applied practically in communications and cryptography. This includes sequential decoding [
5,
6], and measuring password strength [
7], confidentiality of communication channels [
8], and resilience against brute-force attacks [
9]. It is also strongly related to task encoding and (lossless and lossy) compression (see, e.g., [
10,
11,
12,
13,
14,
15]).
Variations of the guessing problem include guessing under source uncertainty [
16], distributed guessing [
17,
18], and guessing on the Gray–Wyner and the Slepian–Wolf network [
19].
3. Two-Stage Guessing:
Let be a sequence of i.i.d. random variables taking values on a finite set . Assume without loss of generality that . Let , , and let be a fixed deterministic function (i.e., ). Consider guessing in two stages as follows (Algorithm 1).
Algorithm 1 (two-stage guessing algorithm):
- (a)
Stage 1: is guessed by asking questions of the form:
until correct. Note that as , this stage cannot reveal .
- (b)
Stage 2: Based on , the sequence is guessed by asking questions of the form:
until correct. If , the guesses are restricted to -sequences, which satisfy for all .
The guesses
,
, …, in Stage 1 are in descending order of probability as measured by
(i.e.,
is the most probable sequence under
;
is the second most probable; and so on; ties are resolved arbitrarily). We denote the index of
in this guessing order by
. Note that because every sequence
is guessed exactly once,
is a bijection from
to
; we refer to such bijections as ranking functions. The guesses
,
, …, in Stage 2 depend on
and are in descending order of the posterior
. Following our notation from Stage 1, the index of
in the guessing order induced by
is denoted
. Note that for every
, the function
is a ranking function on
. Using
and
, the total number of guesses
in Algorithm 1 can be expressed as
where
and
are the number of guesses in Stages 1 and 2, respectively. Observe that guessing in descending order of probability minimizes the
-th moment of the number of guesses in both stages of Algorithm 1. By [
3], for every
, the guessing moments
and
can be (upper and lower) bounded in terms of
and
as follows:
Combining (
13) and (14), we next establish bounds on
. In light of (
13), we begin with bounds on the
-th power of a sum.
Lemma 1. Let , and let be a non-negative sequence. For every ,whereand If , then the left and right inequalities in (15) hold with equality if, respectively, of the ’s are equal to zero or ; if , then the left and right inequalities in (15) hold with equality if, respectively, or of the ’s are equal to zero.
Using the shorthand notation
,
, we apply Lemma 1 in conjunction with (
13), (14) (and the fact that
) to bound
as follows:
The bounds in (18) are asymptotically tight as
n tends to infinity. To see this, note that
and therefore, for all
,
Since the sum of the two exponents on the right-hand side (RHS) of (
20) is dominated by the larger exponential growth rate, it follows that
and thus, by (
20) and (
21),
As a sanity check, note that if
and
f is the identity function id (i.e.,
for all
), then
is revealed in Stage 1, and (with Stage 2 obsolete) the
-th moment of the total number of guesses grows exponentially with rate
This is in agreement with the RHS of (
22), as
We summarize our results so far in Theorem 1 below.
Theorem 1. Let be a sequence of i.i.d. random variables, each drawn according to the PMF of support . Let , , and define . When guessing according to Algorithm 1 (i.e., after first guessing in descending order of probability as measured by and proceeding in descending order of probability as measured by for guessing ), the ρ-th moment of the total number of guesses satisfies
- (a)
the lower and upper bounds in (18) for all and ;
- (b)
the asymptotic characterization (22) for and .
A Suboptimal and Simple Construction of f in Algorithm 1 and Bounds on
Having established in Theorem 1 that
we now seek to minimize the exponent
in the RHS of (
23) (for given PMF
,
, and
) over all
.
We proceed by considering a sub-optimal and simple construction of f, which enables obtaining explicit bounds as a function of the PMF and the value of m, while this construction also does not depend on .
For a fixed , a non-injective deterministic function is constructed by relying on the Huffman algorithm for lossless compression of . This construction also (almost) achieves the maximal mutual information among all deterministic functions (this issue is elaborated in the sequel). Heuristically, apart from its simplicity, the motivation of this sub-optimal construction can be justified since it is expected to reduce the guesswork in Stage 2 of Algorithm 1, where one wishes to guess on the basis of the knowledge of with for all . In this setting, it is shown that the upper and lower bounds on are (almost) asymptotically tight in terms of their exponential growth rate in n. Furthermore, these exponential bounds demonstrate a reduction in the required number of guesses for , as compared to the optimal one-stage guessing of .
In the sequel, the following construction of a deterministic function
is analyzed; this construction was suggested in the proofs of Lemma 5 in [
26] and Theorem 2 in [
14].
Algorithm 2 (construction of ):
- (a)
Let .
- (b)
If , let , and go to Step c. If not, let with its two least likely symbols merged as in the Huffman code construction. Let , and go to Step b.
- (c)
Construct by setting if has been merged into .
We now define
with
Observe that due to [
26] (Corollary 3 and Lemma 5) and because
operates component-wise on the i.i.d. vector
, the following lower bound on
applies:
where
and
From the proof of [
26] (Theorem 3), we further have the following multiplicative bound:
Note that by [
26] (Lemma 1), the maximization problem in the RHS of (
29) is strongly NP-hard [
27]. This means that, unless
, there is no polynomial-time algorithm that, given an arbitrarily small
, produces a deterministic function
satisfying
We next examine the performance of our candidate function when applied in Algorithm 1. To that end, we first bound in terms of the Rényi entropy of a suitably defined random variable constructed in Algorithm 3 below. In the construction, we assume without loss of generality that and denote the PMF of by .
Algorithm 3 (construction of the PMF of the random variable ):
If , then is defined to be a point mass at one;
If , then is defined to be equal to .
Furthermore, for ,
- (a)
If , then Q is defined to be the equiprobable distribution on ;
- (b)
Otherwise, the PMF
Q is defined as
where
is the maximal integer
, which satisfies
Algorithm 3 was introduced in [
26,
28]. The link between the Rényi entropy of
and that of
was given in Equation (
34) of [
14]:
where
The function
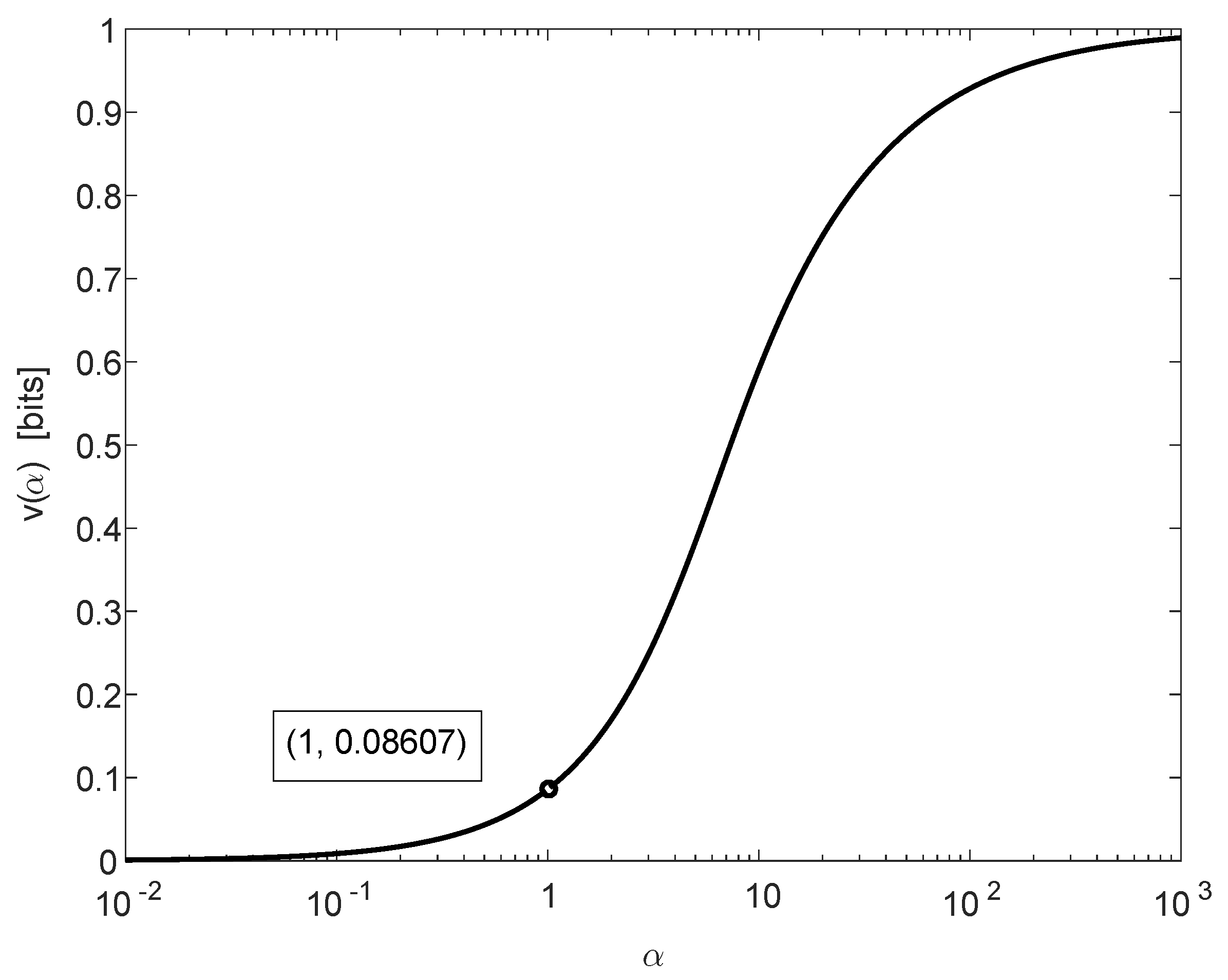
is depicted in
Figure 1 on the following page. It is monotonically increasing, continuous, and it satisfies
Combining (
14a) and (
35) yields, for all
,
where, due to (
30), the difference between the exponential growth rates (in
n) of the lower and upper bounds in (38) is equal to
, and it can be verified to satisfy (see (
30) and (
36))
where the leftmost and rightmost inequalities of (
39) are asymptotically tight as we let
and
, respectively.
By inserting (38) into (18) and applying Inequality (
39), it follows that for all
,
Consequently, by letting
n tend to infinity and relying on (
22),
We next simplify the above bounds by evaluating the maxima in (41) as a function m and . To that end, we use the following lemma.
Lemma 2. For , let the two sequences and be given bywith . Then, - (a)
The sequence is monotonically increasing (in m), and its first and last terms are zero and , respectively.
- (b)
The sequence is monotonically decreasing (in m), and its first and last terms are and zero, respectively.
- (c)
If , then is strictly monotonically increasing, and is strictly monotonically decreasing. In particular, for all , and are positive and strictly smaller than .
Since symbols of probability zero (i.e.,
for which
) do not contribute to the expected number of guesses, assume without loss of generality that
. In view of Lemma 2, we can therefore define
Using (
44), we simplify (41) as follows:
- (a)
- (b)
Otherwise, if
, then
Note that when guessing
directly, the
-th moment of the number of guesses grows exponentially with rate
(cf. (
14a)), due to Item c) in Lemma 2, since
and also because conditioning (on a dependent chance variable) strictly reduces the Rényi entropy [
24]. Equations (
45) and (
46) imply that for any
, guessing in two stages according to Algorithm 1 with
reveals
sooner (in expectation) than guessing
directly.
We summarize our findings in this section in the second theorem below.
Theorem 2. For a given PMF of support and , let the function be constructed according to Algorithm 2, and let the random variable be constructed according to the PMF in Algorithm 3. Let be i.i.d. according to , and let . Finally, for , letbe the optimal exponential growth rate of the ρ-th moment single-stage guessing of , and letbe given by (23) with . Then, the following holds: - (a)
Cicalese et al., [26]: The maximization of the (normalized) mutual information over all the deterministic functions is a strongly NP-hard problem (for all n). However, the deterministic function almost achieves this maximization up to a small additive term, which is equal to , and also up to a multiplicative term, which is equal to (see (29)–(31)). - (b)
The ρ-th moment of the number of guesses for , which is required by the two-stage guessing in Algorithm 1, satisfies the non-asymptotic bounds in (40a) and (40b). - (c)
The asymptotic exponent satisfies (45) and (46). - (d)
For all ,so there is a reduction in the exponential growth rate (as a function of n) of the required number of guesses for by Algorithm 1 (in comparison to the optimal one-stage guessing).
4. Two-Stage Guessing: Arbitrary
We next assume that
and
are drawn jointly i.i.d. according to a given PMF
, and we drop the requirement that Stage 1 need reveal
prior to guessing
. Given
, our goal in this section is to find the least exponential growth rate (in
n) of the
-th moment of the total number of guesses required to recover
. Since Stage 1 may not reveal
, we can no longer express the number of guesses using the ranking functions
and
as in
Section 3, and need new notation to capture the event that
was not guessed in Stage 1. To that end, let
be a subset of
, and let the ranking function
denote the guessing order in Stage 1 with the understanding that if
, then
and the guesser moves on to Stage 2 knowing only that
. We denote the guessing order in Stage 2 by
where, for every
,
is a ranking function on
that satisfies
Note that while and depend on , we do not make this dependence explicit. In the remainder of this section, we prove the following variational characterization of the least exponential growth rate of the -th moment of the total number of guesses in both stages .
Theorem 3. If are i.i.d. according to , then for all where the supremum on the RHS of (55) is over all PMFs on (and the limit exists). Note that if
is such that
, then the RHS of (
55) is less than or equal to the RHS of (
21). In other words, the guessing exponent of Theorem 3 is less than or equal to the guessing exponent of Theorem 1. This is due to the fact that guessing
in Stage 1 before proceeding to Stage 2 (the strategy examined in
Section 3) is just one of the admissible guessing strategies of
Section 4 and not necessarily the optimal one.
We prove Theorem 3 in two parts: First, we show that the guesser can be assumed cognizant of the empirical joint type of
; by invoking the law of total expectation, averaging over denominator-
n types
on
, we reduce the problem to evaluating the LHS of (
55) under the assumption that
is drawn uniformly at random from a type class
(instead of being i.i.d.
). We conclude the proof by solving this reduced problem, showing in particular that when
is drawn uniformly at random from a type class, the LHS of (
55) can be achieved either by guessing
in Stage 1 or skipping Stage 1 entirely.
We begin with the first part of the proof and show that the guesser can be assumed cognizant of the empirical joint type of ; we formalize and prove this claim in Corollary 1, which we derive from Lemma 3 below.
Lemma 3. Let and be ranking functions that minimize the expectation in the LHS of (55), and likewise, let and be ranking functions cognizant of the empirical joint type of that minimize the expectation in the LHS of (55) over all ranking functions depending on . Then, there exist positive constants a and k, which are independent of n, such that Corollary 1. exists, so does the limit in the LHS of (55), and the two are equal. Proof. The inverse inequality
follows from the fact that an optimal guessing strategy depending on the empirical joint type
of
cannot be outperformed by a guessing strategy ignorant of
. □
Corollary 1 states that the minimization in the LHS of (
55) can be taken over guessing strategies cognizant of the empirical joint type of
. As we show in the next lemma, this implies that evaluating the LHS of (
55) can be further simplified by taking the expectation with
drawn uniformly at random from a type class (instead of being i.i.d.
).
Lemma 4. Let denote expectation with drawn uniformly at random from the type class . Then, the following limits exist andwhere the maximum in the RHS of (64) is taken over all denominator-n types on . Proof. Recall that
is the empirical joint type of
, and let
denote the set of all denominator-
n types on
. We prove Lemma 4 by applying the law of total expectation to the LHS of (
64) (averaging over the events
) and by approximating the probability of observing a given type using standard tools from large deviations theory. We first show that the LHS of (
64) is upper bounded by its RHS:
where (
66) holds for sufficiently large
because the number of types grows polynomially in
n (see
Appendix C); and (
68) follows from [
20] (Theorem 11.1.4). We next show that the LHS of (
64) is also lower bounded by its RHS:
where in (
71),
tends to zero as we let
n tend to infinity, and the inequality in (
71) follows again from [
20] (Theorem 11.1.4). Together, (
68) and (
71) imply the equality in (
64). □
We now have established the first part of the proof of Theorem 3: In Corollary 1, we showed that the ranking functions and can be assumed cognizant of the empirical joint type of , and in Lemma 4, we showed that under this assumption, the minimization of the -th moment of the total number of guesses can be carried out with drawn uniformly at random from a type class.
Below, we give the second part of the proof: We show that if the pair
is drawn uniformly at random from
, then
Note that Corollary 1 and Lemma 4 in conjunction with (
74) conclude the proof of Theorem 3:
where the supremum in the RHS of (
77) is taken over all PMFs
on
, and the step follows from (
76) because the set of types is dense in the set of all PMFs (in the same sense that
is dense in
).
It thus remains to prove (
74). We begin with the direct part: Note that when
is drawn uniformly at random from
, the
-th moment of the total number of guesses grows exponentially with rate
if we skip Stage 1 and guess
directly and with rate
if we guess
in Stage 1 before moving on to guessing
. To prove the second claim, we argue by case distinction on
. Assuming first that
,
where (
78) holds because
(see Lemma 1); (
80) holds since, by the latter assumption,
is revealed at the end of Stage 1, and thus, the guesser (cognizant of
) will only guess elements from the conditional type class
; and (
81) follows from the fact that the exponential growth rate of a sum of two exponents is dominated by the larger one. We wrap up the argument by showing that the LHS of (
78) is also lower bounded by the RHS of (
81):
where (
83) follows from Jensen’s inequality; and (
85) follows from [
29] (Proposition 6.6) and the lower bound on the size of a (conditional) type class [
20] (Theorem 11.1.3). The case
can be proven analogously and is hence omitted (with the term
in the RHS of (
83) replaced by one). Note that by applying the better of the two proposed guessing strategies (i.e., depending on
, either guess
in Stage 1 or skip it) the
-th moment of the total number of guesses grows exponentially with rate
. This concludes the direct part of the proof of (
74). We remind the reader that while we have constructed a guessing strategy under the assumption that the empirical joint type
of
is known, Lemma 3 implies the existence of a guessing strategy of equal asymptotic performance that does not depend on
. Moreover, Lemma 3 is constructive in the sense that the type-independent guessing strategy can be explicitly derived from the type-cognizant one (cf. the proof of Proposition 6.6 in [
29]).
We next establish the converse of (
74) by showing that when
is drawn uniformly at random from
,
for all two-stage guessing strategies. To see why (
87) holds, consider an arbitrary guessing strategy, and let the sequence
be such that
and such that the limit
exists. Using Lemma 5 below, we show that the LHS of (
88) (and thus, also the LHS of (
87)) is lower bounded by
if
and by
if
. This establishes the converse, because the lower of the two bounds must apply in any case.
Lemma 5. If the pair is drawn uniformly at random from a type class andthenwhere and denote the X- and Y-marginal of . Proof. Note that since
the RHS of (
91) is trivially upper bounded by
. It thus suffices to show that (
90) yields the lower bound
To show that (
90) yields (
93), we define the indicator variable
and observe that due to (
90) and the fact that
is drawn uniformly at random from
,
Consequently,
tends to zero as
n tends to infinity, and because
we get
This and (
95) imply that
To conclude the proof of Lemma 5, we proceed as follows:
where (
99) holds due to (
95) and the law of total expectation; (
100) follows from [
3] (Theorem 1); (
101) holds because the Rényi entropy is monotonically decreasing in its order and because
; and (
102) is due to (
98). □
We now conclude the proof of the converse part of (
74). Assume first that
(as defined in (
89)) equals zero. By (
88) and Lemma 5,
establishing the first contribution to the RHS of (
87). Next, let
. Applying [
29] (Proposition 6.6) in conjunction with (
89) and the fact that
is drawn uniformly at random from
,
for all sufficiently large
k. Using (
107) and proceeding analogously as in (
82) to (
85), we now establish the second contribution to the RHS of (
87):
where (
110) is due to (
107); and in (
111), we granted the guesser access to
at the beginning of Stage 2.




{kind=link}
