
Conversation Concepts: Understanding Topics and Building Taxonomies for Financial Services

 , , ,
, , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Conversation Concepts
3.1. Problem Description
- Intent identification, as well as entity detection for the dialogue manager
- Customer intent disambiguation by leveraging other metadata
- Dialogue pattern monitoring in real time to help provide personalized answers
3.2. Use Cases
User: Hi, I am thinking to transfer some money to that account but I am not sure if I am allowed to.
User: Hi, I am thinking to transfer some money to that account but I am not sure if I am allowed to.
User: That’s great, can you please provide instructions for wire transfer
User: What is the routing number?
4. Topic and Taxonomy Extraction
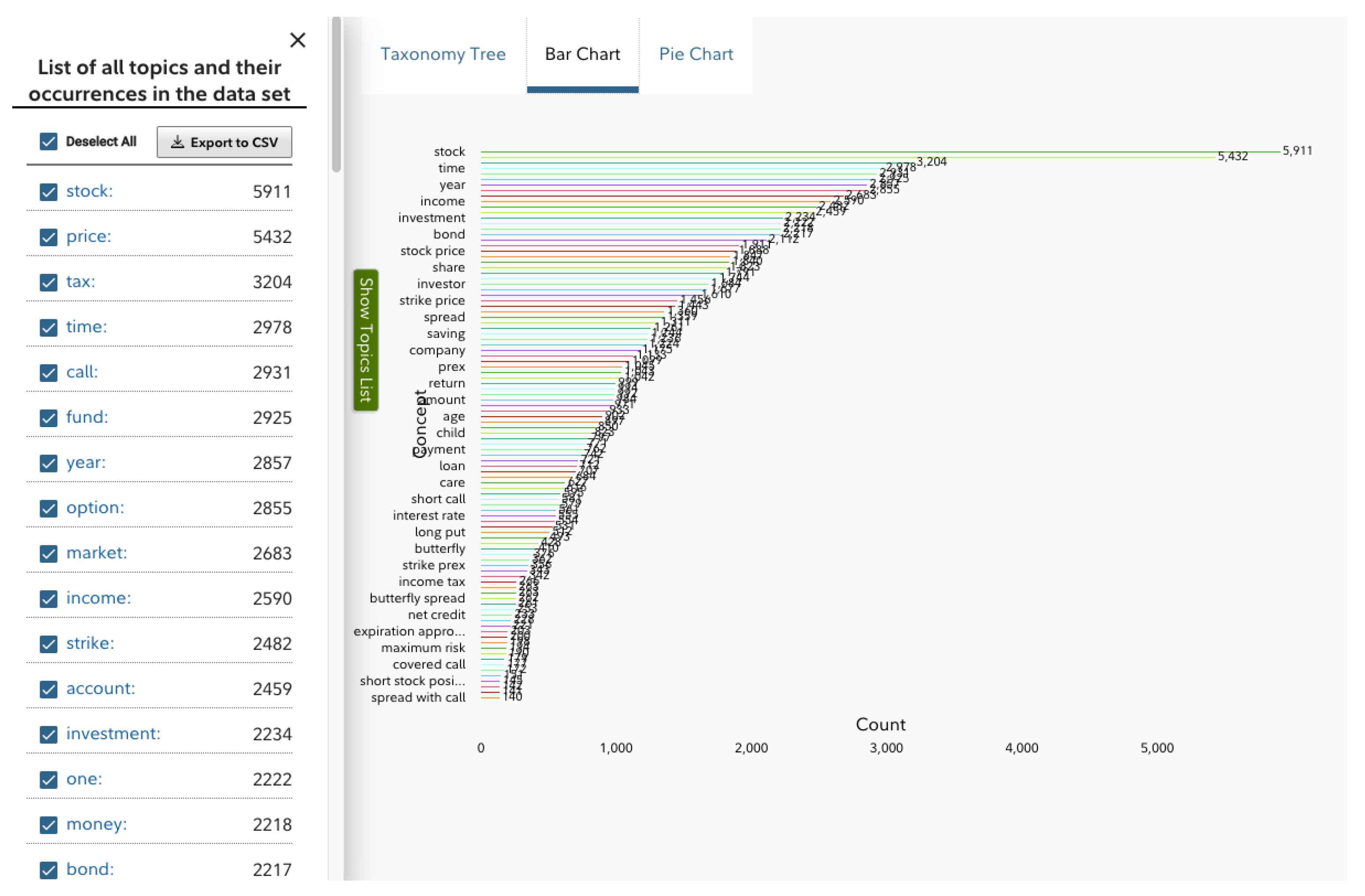
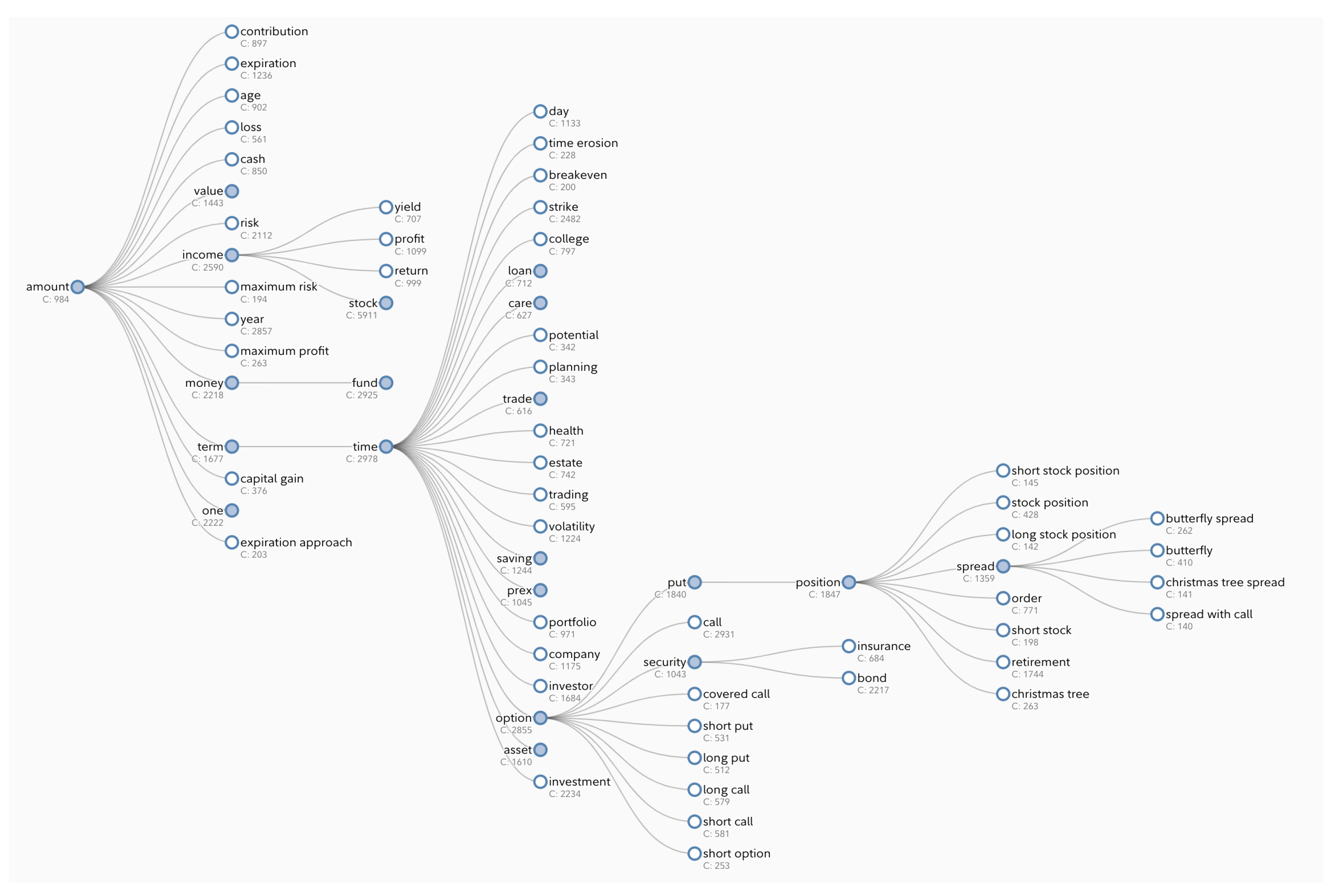
4.1. Automatic Extraction
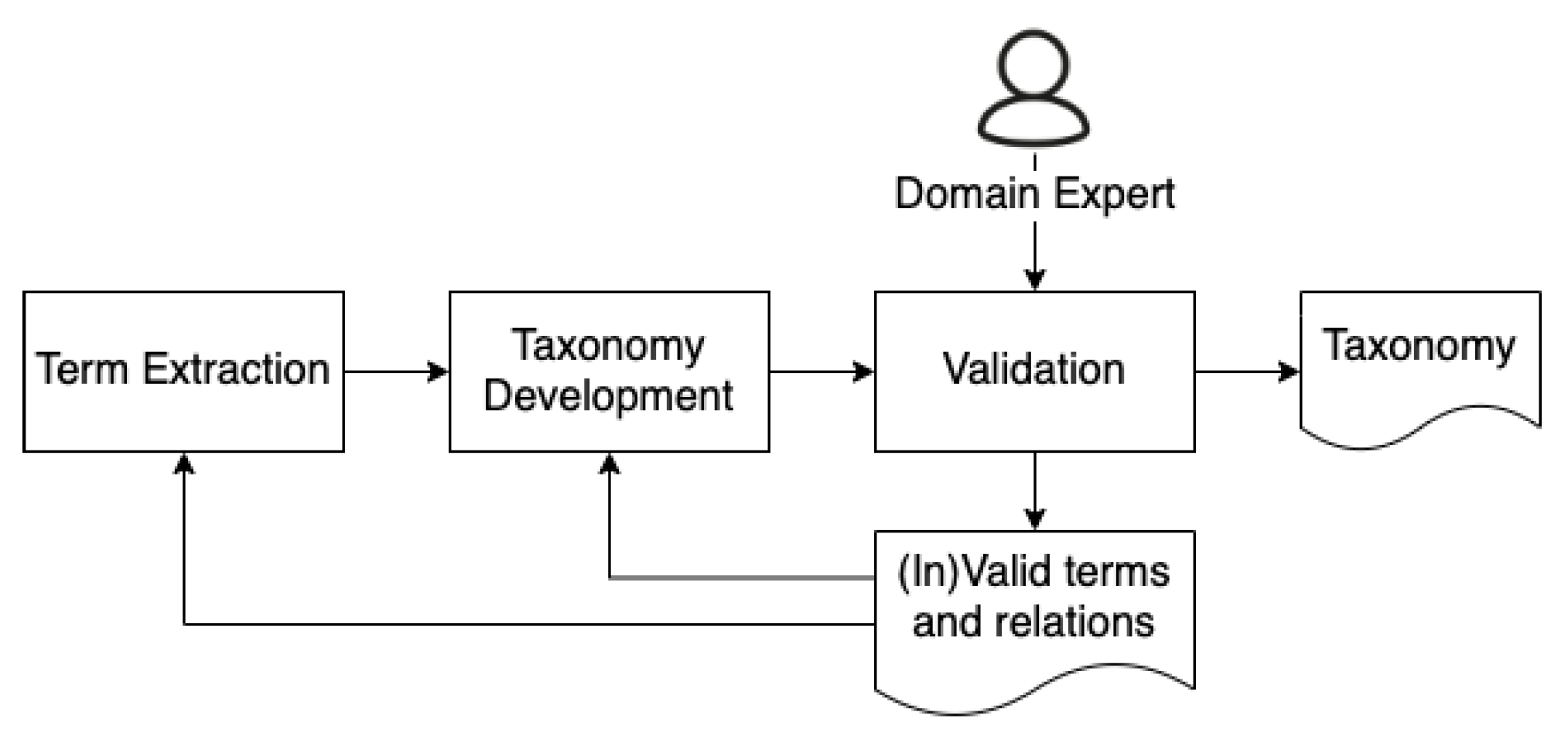
4.2. Semi-Automatic Taxonomy Development
- (i)
- approve a given parent-child relation or
- (ii)
- change the parent for any given term within the taxonomy.
4.3. Extending Relation Type Extraction
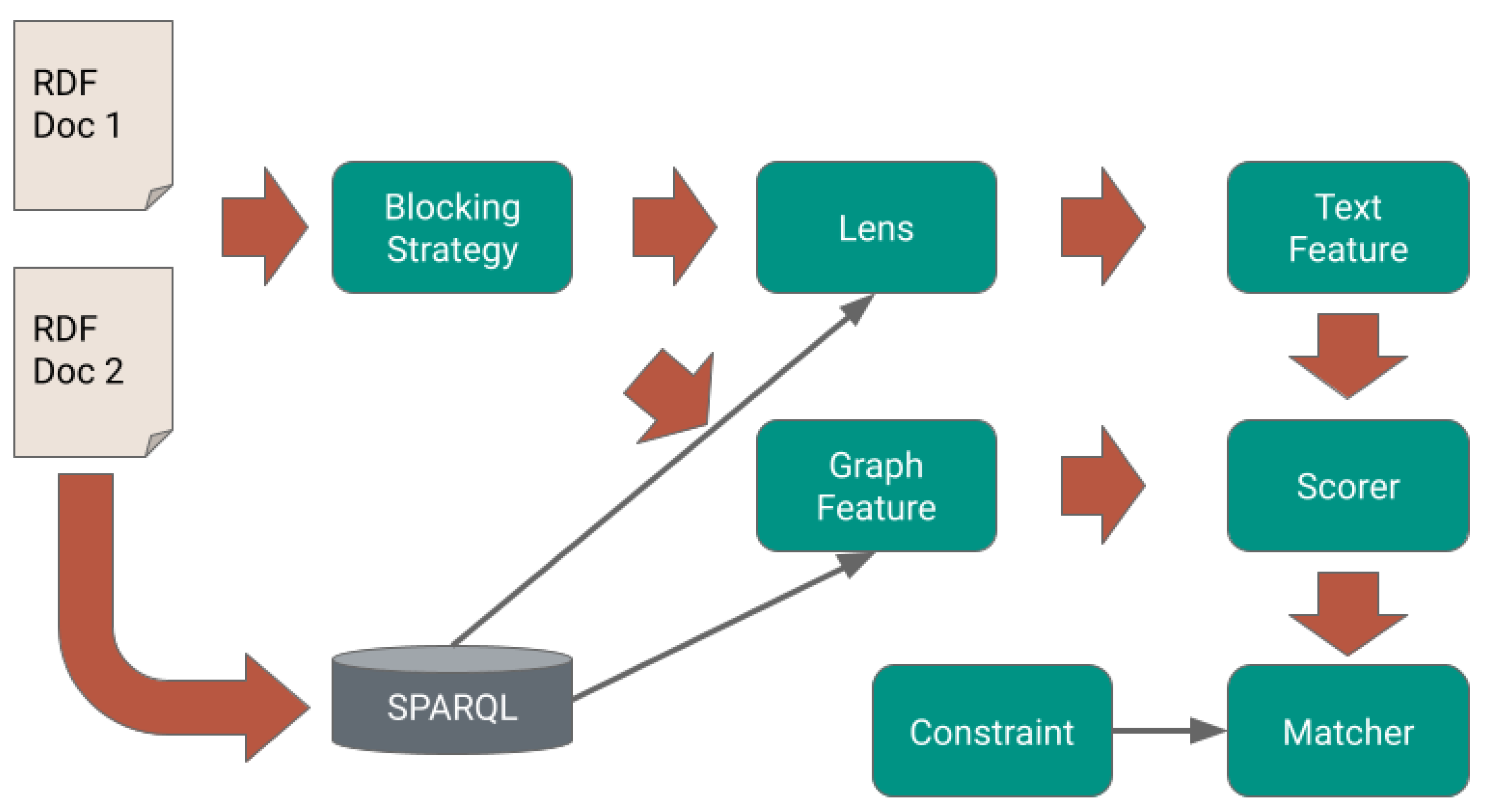
4.4. Integration of Knowledge Graphs
- Analysis of the taxonomies to find the structure of the model;
- Blocking to find (with reduced computational cost) a set of candidate links;
- Pre-linking of those elements where this can easily be achieved, for example because there is only one candidate to link to;
- Lenses to extract relevant textual elements;
- Text features applying state-of-the-art NLP techniques to extract numerical measures of similarity;
- Graph features analysing the graph and finding similar links;
- A scorer analysing each link and finding the likelihood of a link being established;
- Rescaling used to fix the link quality;
- A matcher using “common-sense” constraints to find the most likely global matching.
4.5. Deployment and Future Plans
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Gomez-Perez, J.M.; Pan, J.Z.; Vetere, G.; Wu, H. Enterprise knowledge graph: An introduction. In Exploiting Linked Data and Knowledge Graphs in Large Organisations; Springer: New York, NY, USA, 2017; pp. 1–14. [Google Scholar]
- Pereira, B.; Robin, C.; Daudert, T.; McCrae, J.P.; Buitelaar, P.; Mohanty, P. Taxonomy Extraction for Customer Service Knowledge Base Construction. In Proceedings of the SEMANTicS 2019, Karlsruhe, Germany, 9–12 September 2019; Springer: New York, NY, USA, 2019. [Google Scholar]
- Quillian, M.R. Word concepts: A theory and simulation of some basic semantic capabilities. Behav. Sci. 1967, 12, 410–430. [Google Scholar] [CrossRef] [PubMed]
- Shadbolt, N.; Berners-Lee, T.; Hall, W. The Semantic Web revisited. IEEE Intell. Syst. 2006, 21, 96–101. [Google Scholar] [CrossRef] [Green Version]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data: The story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Hershey, PA, USA, 2011; pp. 205–227. [Google Scholar]
- Brickley, D.; Guha, R.V.; Layman, A. Resource Description Framework (RDF) Schema Specification. 1999. Available online: https://www.w3.org/TR/rdf-schema/ (accessed on 9 April 2021).
- McGuinness, D.L.; Van Harmelen, F. OWL web ontology language overview. W3C Recomm. 2004, 10, 2004. [Google Scholar]
- Singhal, A. Introducing the Knowledge Graph: Things, not Strings. 2012. Available online: https://www.blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 9 April 2021).
- Penela, V.; Álvaro, G.; Ruiz, C.; Córdoba, C.; Carbone, F.; Castagnone, M.; Gómez-Pérez, J.M.; Contreras, J. miKrow: Semantic Intra-enterprise Micro-Knowledge Management System. In The Semanic Web: Research and Applications; Antoniou, G., Grobelnik, M., Simperl, E., Parsia, B., Plexousakis, D., De Leenheer, P., Pan, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 154–168. [Google Scholar]
- Denaux, R.; Ren, Y.; Villazon-Terrazas, B.; Alexopoulos, P.; Faraotti, A.; Wu, H. Knowledge Architecture for Organisations. In Exploiting Linked Data and Knowledge Graphs in Large Organisations; Springer: New York, NY, USA, 2017; pp. 57–84. [Google Scholar]
- Ngomo, A.C.N.; Auer, S.; Lehmann, J.; Zaveri, A. Introduction to linked data and its lifecycle on the web. In Reasoning Web International Summer School; Springer: New York, NY, USA, 2014; pp. 1–99. [Google Scholar]
- Buitelaar, P.; Cimiano, P.; Magnini, B. Ontology Learning from Text: Methods, Evaluation and Applications; IOS Press: Amsterdam, The Netherlands, 2005; Volume 123. [Google Scholar]
- Astrakhantsev, N. ATR4S: Toolkit with state-of-the-art automatic terms recognition methods in Scala. Lang. Resour. Eval. 2018, 52, 853–872. [Google Scholar] [CrossRef] [Green Version]
- Bordea, G.; Buitelaar, P. DERIUNLP: A context based approach to automatic keyphrase extraction. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 146–149. [Google Scholar]
- Hearst, M.A. Automatic acquisition of hyponyms from large text corpora. In Proceedings of the 14th Conference on Computational Linguistics—Volume 2, Gothenburg, Sweden, 26–30 April 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 1992; pp. 539–545. [Google Scholar]
- Shwartz, V.; Santus, E.; Schlechtweg, D. Hypernyms under Siege: Linguistically-motivated Artillery for Hypernymy Detection. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017, Valencia, Spain, 3–7 April 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; Volume 1: Long Papers, pp. 65–75. [Google Scholar]
- Roller, S.; Kiela, D.; Nickel, M. Hearst Patterns Revisited: Automatic Hypernym Detection from Large Text Corpora. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 2: Short Papers, pp. 358–363. [Google Scholar]
- Wang, C.; Fan, Y.; He, X.; Zhou, A. A family of fuzzy orthogonal projection models for monolingual and cross-lingual hypernymy prediction. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1965–1976. [Google Scholar]
- Bordea, G.; Lefever, E.; Buitelaar, P. SemEval-2016 task 13: Taxonomy extraction evaluation (TExEval-2). In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 1081–1091. [Google Scholar]
- Nayak, G.; Dutta, S.; Ajwani, D.; Nicholson, P.; Sala, A. Automated assessment of knowledge hierarchy evolution: Comparing directed acyclic graphs. Inf. Retr. J. 2019, 22, 256–284. [Google Scholar] [CrossRef] [Green Version]
- Diefenbach, D.; Lopez, V.; Singh, K.; Maret, P. Core techniques of question answering systems over knowledge bases: A survey. Knowl. Inf. Syst. 2018, 55, 529–569. [Google Scholar] [CrossRef]
- Unger, C.; Cimiano, P. Pythia: Compositional meaning construction for ontology-based question answering on the semantic web. In International Conference on Application of Natural Language to Information Systems; Springer: New York, NY, USA, 2011; pp. 153–160. [Google Scholar]
- Lopez, V.; Fernández, M.; Motta, E.; Stieler, N. PowerAqua: Supporting users in querying and exploring the semantic web. Semant. Web 2012, 3, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Lukovnikov, D.; Fischer, A.; Lehmann, J.; Auer, S. Neural network-based question answering over knowledge graphs on word and character level. In Proceedings of the 26th international conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1211–1220. [Google Scholar]
- Ferrucci, D.; Brown, E.; Chu-Carroll, J.; Fan, J.; Gondek, D.; Kalyanpur, A.A.; Lally, A.; Murdock, J.W.; Nyberg, E.; Prager, J.; et al. Building Watson: An overview of the DeepQA project. AI Mag. 2010, 31, 59–79. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.N.; Toor, A.S.; O’Neil, K.; Friedland, D. Cognitive computing and the future of health care cognitive computing and the future of healthcare: The cognitive power of IBM Watson has the potential to transform global personalized medicine. IEEE Pulse 2017, 8, 4–9. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez-Cuellar, J.; Gómez-Pérez, J.M. HAVAS 18 Labs: A Knowledge Graph for Innovation in the Media Industry. In Proceedings of the International Semantic Web Conference (Industry Track), Riva del Garda, Italy, 19–23 October 2014; Volume 1383. [Google Scholar]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Nakashole, N.; Theobald, M.; Weikum, G. Scalable knowledge harvesting with high precision and high recall. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, 9–12 February 2011; pp. 227–236. [Google Scholar]
- Paulheim, H. Identifying wrong links between datasets by multi-dimensional outlier detection. In Proceedings of the Third International Workshop on Debugging Ontologies and Ontology Mappings (WoDOOM), Anissaras/Hersonissou, Greece, 26 May 2014; pp. 27–38. [Google Scholar]
- Lehmann, J.; Gerber, D.; Morsey, M.; Ngomo, A.C.N. Defacto-deep fact validation. In Proceedings of the International Semantic Web Conference, Boston, MA, USA, 11–15 November 2012; Springer: New York, NY, USA, 2012; pp. 312–327. [Google Scholar]
- Liu, S.; d’Aquin, M.; Motta, E. Towards Linked Data Fact Validation through Measuring Consensus. In Proceedings of the 2nd Workshop on Linked Data Quality co-located with 12th Extended Semantic Web Conference (ESWC 2015), Portorož, Slovenia, 1 June 2015. CEUR Workshop Proceedings No. 137. [Google Scholar]
- Stellato, A.; Rajbhandari, S.; Turbati, A.; Fiorelli, M.; Caracciolo, C.; Lorenzetti, T.; Keizer, J.; Pazienza, M.T. VocBench: A web application for collaborative development of multilingual thesauri. In Proceedings of the European Semantic Web Conference, Portoroz, Slovenia, 31 May–4 June 4 2015; Springer: New York, NY, USA, 2015; pp. 38–53. [Google Scholar]
- Hulth, A. Enhancing linguistically oriented automatic keyword extraction. In Proceedings of the HLT-NAACL 2004: Short Papers, Boston, MA, USA, 2–7 May 2004; pp. 17–20. [Google Scholar]
- Bordea, G. Domain Adaptive Extraction of Topical Hierarchies for Expertise Mining. Ph.D. Thesis, NUI Galway, Galway, Ireland, 2013. [Google Scholar]
- Sarkar, R.; McCrae, J.P.; Buitelaar, P. A supervised approach to taxonomy extraction using word embeddings. In Proceedings of the 11th Language Resource and Evaluation Conference (LREC), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. ConceptNet 5.5: An open multilingual graph of general knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z.G. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web, Proceedings of the 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Korea, 11–15 November 2007; Lecture Notes in Computer Science; Aberer, K., Choi, K., Noy, N.F., Allemang, D., Lee, K., Nixon, L.J.B., Golbeck, J., Mika, P., Maynard, D., Mizoguchi, R., et al., Eds.; Springer: New York, NY, USA, 2007; Volume 4825, pp. 722–735. [Google Scholar] [CrossRef] [Green Version]
- Hoffart, J.; Suchanek, F.M.; Berberich, K.; Weikum, G. YAGO2: A spatially and temporally enhanced knowledge base from Wikipedia. Artif. Intell. 2013, 194, 28–61. [Google Scholar] [CrossRef] [Green Version]
- McCrae, J.P.; Buitelaar, P. Linking Datasets Using Semantic Textual Similarity. Cybern. Inf. Technol. 2018, 18, 109–123. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ferrucci, D.; Levas, A.; Bagchi, S.; Gondek, D.; Mueller, E.T. Watson: Beyond Jeopardy! Artif. Intell. 2013, 199, 93–105. [Google Scholar] [CrossRef]
- Noy, N.; Gao, Y.; Jain, A.; Narayanan, A.; Patterson, A.; Taylor, J. Industry-scale knowledge graphs: Lessons and challenges. Queue 2019, 17, 48–75. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McCrae, J.P.; Mohanty, P.; Narayanan, S.; Pereira, B.; Buitelaar, P.; Karmakar, S.; Sarkar, R. Conversation Concepts: Understanding Topics and Building Taxonomies for Financial Services. Information 2021, 12, 160. https://doi.org/10.3390/info12040160
McCrae JP, Mohanty P, Narayanan S, Pereira B, Buitelaar P, Karmakar S, Sarkar R. Conversation Concepts: Understanding Topics and Building Taxonomies for Financial Services. Information. 2021; 12(4):160. https://doi.org/10.3390/info12040160
Chicago/Turabian StyleMcCrae, John P., Pranab Mohanty, Siddharth Narayanan, Bianca Pereira, Paul Buitelaar, Saurav Karmakar, and Rajdeep Sarkar. 2021. "Conversation Concepts: Understanding Topics and Building Taxonomies for Financial Services" Information 12, no. 4: 160. https://doi.org/10.3390/info12040160
APA StyleMcCrae, J. P., Mohanty, P., Narayanan, S., Pereira, B., Buitelaar, P., Karmakar, S., & Sarkar, R. (2021). Conversation Concepts: Understanding Topics and Building Taxonomies for Financial Services. Information, 12(4), 160. https://doi.org/10.3390/info12040160