1. Introduction
Since the World Health Organization (WHO) declared COVID-19 a pandemic on 11 March 2020, social media platforms and traditional media have been flooded by information about the virus and behaviors to be followed to avoid its spread. At the same time, uncertainty and ambiguity regarding information about COVID-19 brought people to respond with non-adaptive coping strategies. In [
1], Ha et al. stated that messaging to the public requires not only status reports and behavioral guidelines but also a component of positive information that can reduce anxiety. When this strategy does not work, people tend to react by generating harmful scenarios such as fake news production to protect themselves by trying to minimize the perceived danger. According to these findings, the COVID-19 pandemic increased the diffusion of wrong and misleading information on social media. In 2020, there was an exponential growth of cases in which a person received forged news and spread it rapidly on social media platforms without verifying its reliability. As reported by Cinelli et al. [
2] and by the World Health Organization,
https://www.who.int/news-room/spotlight/let-s-flatten-the-infodemic-curve (accessed on 15 March 2021), societies worldwide faced a parallel pandemic of fake information that required effective countermeasures to reduce the human effort needed to detect misinformation and to slow fake news diffusion. As reported in the survey by Oshikawa et al. [
3], language models have been widely employed to tackle this problem. In this context, Islam et al. explored multiple deep learning architectures to detect fake news [
4]. In parallel, in [
5], Jiang et al. investigated linguistic signals to find emotional markers in text, and they discovered a different social media interaction by the user when the user is encouraged to read fact-checked articles. In a similar scenario, Glenski et al. monitored different types of reactions to misinformation such as answer, appreciation, elaboration, and question [
6]. Understanding the stance of a user about the content they share is a fundamental passage to effectively classify the user as a supporter or a detractor. All of these works reveal how fake news diffusion mechanisms are linked to the characteristics of the user sharing them. Actually, the definitions of fake news spreaders and checkers are a consequence of the fake news phenomenon on social media. Fake news spreaders are social media users supporting fake news and sharing misinformation. On the other hand, real news checkers are social media users sharing real news and supporting them. We describe the checked fake news as content declared false by fact-checking agencies after a human revision process.
The cited research projects report a growing need for automatic solutions to support fact checking agencies in their monitoring actions as well as to stimulate awareness of citizens in verifying content before sharing. In fact, when a user spreads fake information, they reinforce the trust of the community in the content, exponentially extending its reach, as explained by Vosoughi et al. [
7]. When the information goes viral, the authorities must spend huge efforts to demonstrate its untruthfulness. The existing contributions to this research field show the effectiveness of language model adoptions combined with social media interaction analysis to detect misinformation. Even if these solutions have a big impact on society, we argue that they do not extensively analyze misinformation from the point of view of the user sharing it. An analysis of the user’s posts and behavior on social media platforms fills this gap, expressing their perspective explicitly. The solutions proposed do not explore the encoding of the user’s timeline into sentence embeddings to classify their tendency to share misinformation. In addition, they do not compare natural language processing approaches with respect to the machine learning models by exploiting social media graphs features.
Thus, we conducted our study by answering the following research questions:
- RQ1
Is sentence encoding based on transformers and deep learning effective in classifying spreaders of fake news in the context of COVID-19 news?
- RQ2
Which gold standard can be used for classifying spreaders of fake news in the context of COVID-19 news?
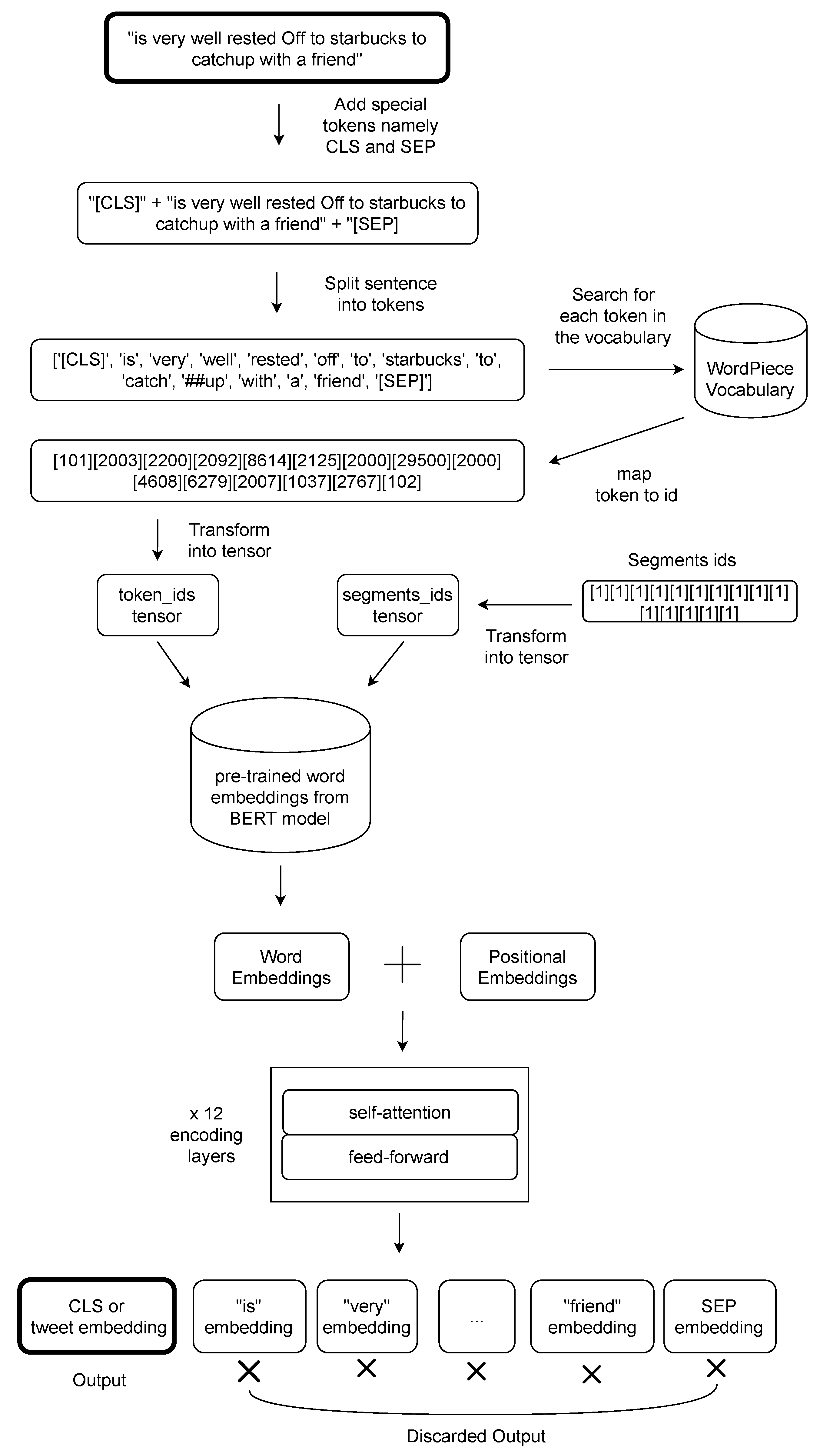
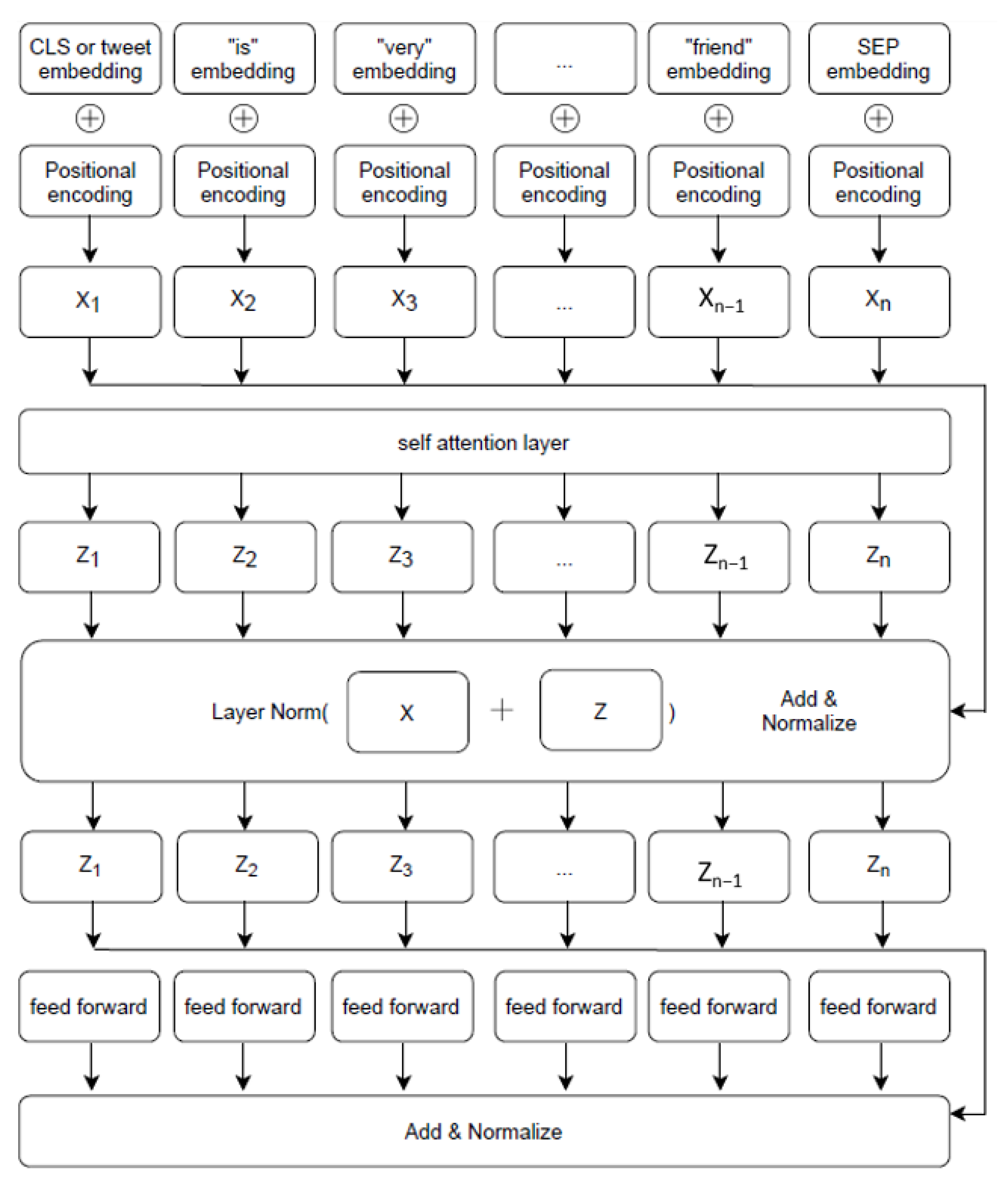
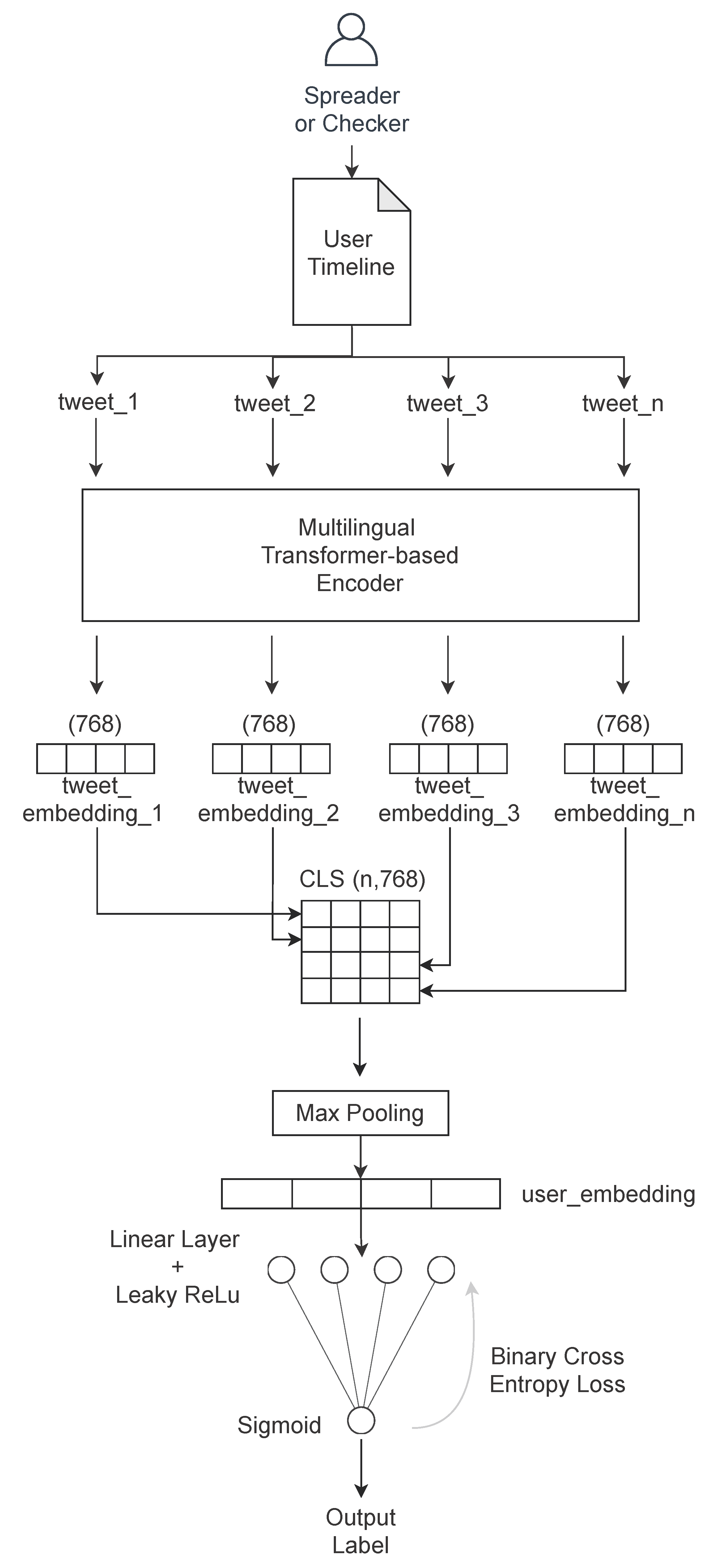
In this paper, we present the FNSC (Fake News Spreader Classifier), a stacked and transformer-based neural network that combines the transformer [
8] capabilities of computing sentence embeddings with our deep learning model to classify users sharing fake news about COVID-19. This model transforms batches of tweets into sentence embeddings and processes them to classify users in a supervised approach. Starting from the dataset produced by Limeng and Dongwon [
9], we collected tweet authors and their timelines to extensively inspect what they shared about COVID-19 and if they support the news they shared through a stance detection model. We show that our model has state-of-the-art results with the linguistic features. We also checked our model results using social media metrics alone, obtaining lower scores than the linguistic ones. The code we built is available in a publicly accessible repository:
https://github.com/D2KLab/stopfaker (accessed on 7 May 2021). The CoAID dataset is also available in a publicly accessible repository:
https://github.com/cuilimeng/CoAID (accessed on 16 January 2021). We shared the extended version of CoAID on Figshare,
https://doi.org/10.6084/m9.figshare.14392859 (accessed on 7 May 2021).
The remainder of this paper is structured as follows. In
Section 2, we illustrate how various studies approached the problem of fake news detection and the associated user classification task through machine learning and natural language processing and how our work differs from them and contributes to the progress in this field. In
Section 3, we describe how we extend the CoAID dataset and we explain the gold standard for the Spreader and Checker classification challenge. In
Section 4, we explain our approach and our deep learning model. In
Section 5, we report the experimental results we achieved in Spreader and Checker classification when applying our architecture on the CoAID extended dataset. In
Section 6, we discuss the results obtained with our approach and we explain the choices made for baseline comparison and linguistic model. Finally, we conclude with insights and planned future works in
Section 7.
2. Related Work
Since the 2016 U.S. presidential election, the spread of online misinformation on social media platforms such as Twitter and Facebook has produced many publications in this field [
10,
11,
12,
13,
14,
15,
16]. In [
10], Alcott et al. described fake news as articles that are verified as false with certainty and that mislead readers. An example of fake news is an affirmation of a false birth place. This information is verified as false thanks to the data from public registries. In [
11], Shu et al. described fake news from a data-mining perspective. In this survey, they explained the existing differences in fake news and related data from traditional media, having stronger psychological and sociological foundations, and from social media platforms, mainly driven by malicious accounts and echo chambers. Once collected, these fake news have been grouped by their textual content and by their social context. In fact, they are characterized by news checked as false, by the use of a specific linguistic style, by their support or denial expressed explicitly beside the news content, and finally by their diffusion behavior through the social community. In [
12], Lazer et al. suggested that social media platforms and their content diffusion mechanism are natural habitats for fake news. They advised researching a solution to this problem by creating bot (software-controlled account) and automatic content detection tools to support human supervision to avoid either government or corporate censorship. In [
13], Stella et al. addressed the problem of bot detection and effect on social media communities in the case of the Catalan referendum for independence in 2017. They explored the social graph metrics, such as the source and destination of messages between groups as well as sentiment analysis. They found that social bot and humans have different behaviors and that the former tends to stimulate inflammatory reactions in humans. The approaches in the work of Grinberg et al. [
14], Guess et al. [
15], and Pennycook et al. [
16] were all lead by social media user characteristics and related social graph metrics in the context of political elections.
In parallel, the viral content diffusion mechanism through social media has been studied to understand recurrent patterns [
7,
17,
18,
19]. In [
17], Shao et al. developed Hoaxy, a monitoring tool on Twitter to understand differences in the diffusion behavior between fake news and fact-checked news. They discovered that social media bots were at the core of the diffusion network and that fact-checked news affects just the peripheral of the same network. Their work is completely based on social media graph metrics such as in and out degree, PageRank, and network diffusion steps. In [
18], Dhamal found that exploiting highly influential nodes of a social network community to spread information on a multiple phase scenario does not increase the diffusion effectiveness, while using lesser influential nodes in subsequent phases keeps the pace of the diffusion process high. In [
19], Goyal et al. described how social media users are influenced by neighbors in performing actions such as sharing news. They developed a mathematical model based on social media graphs to predict the probability that information is spread through certain nodes of the social media community. In [
7], Vosoughi et al. analyzed true and fake news diffusion behavior on Twitter, and they found that social media bots spread true and fake news at the same rate, implying that humans have a major contribution to the phase of cascading the distribution of fake news.
At the same time, other research projects analyzed the impact of network topologies and influence characteristics of certain nodes of the social media communities in the information diffusion mechanism [
20,
21,
22,
23]. In [
20], Zhang et al. developed a new metric called social influence locality to compute the probability that an information is spread by a node in a social media graph based on the behavior of surrounding nodes. They reinforced the concept that not only the typologies of connection between nodes but also how these nodes behave independently are important. In [
21], Guo et al. compared the impact of major influences in a social network graph between global influencers and local influencers, finding that the local ones have an higher probabilistic footprint on a node action. In [
22], Mansour et al. highlighted the role played by interpersonal influences between people sharing the same experience in the context of information spreading online. This result suggests that the analysis of users’ features contributes to a better precision in prediction of users’ sharing action on social media platforms. In [
23], Borges et al. investigated what motivates users to share viral communications on the web communities. They observed that users involved in the sharing action of viral contents prefer not to participate in the discussion of the content itself. They classified users in three categories based on their reactions to viral contents. These categories are heavy, social-driven, and search-driven. Heavy users are impacted by content meaningfulness because they interact and produce content heavily on the social media platforms. Social-driven users interact with content mainly by sharing it without adding information, while search-driven does not interact or share the content. The last two categories are more interested in the impact that the information has on how the surrounding users perceive them as a person rather than the meaningfulness of the news content.
Similarly, the linguistic tools and the machine learning methods adopted to extract information from social media posts and text in general have seen an exponential increment in computational power and effectiveness. Since 2018, when the BERT model by Google [
24] and the transformer-based architecture combined with the attention mechanism by Vaswani et al. [
8] were published, the NLP (Natural Language Processing) methodology has been applied to the misinformation field to inspect this phenomenon [
5,
25]. In [
25], Stieglitz et al. found a positive relationship between the quantity of words containing both positive and negative sentiments rather than the neutral tweets and the probability the social media post will be shared. This result means that sentiment is also spread through social media networks alongside the content of the news itself. In a political context, this concept is validated by the work of Jiang et al. [
5].
As for linguistic signals, the user’s personality also has an impact on the action of sharing fake news. A number of researchers have employed those features to find the relation between personality traits and the use of social media [
26,
27,
28]. In [
26], Burbach et al. developed an agent-based simulation of a social media interaction. They created these agents modeling answers given by an online questionnaire. The information retrieved were about age; gender; level of education; dimensions of personal social network; and the personality scores from the Five Factor Model, the Dark Triad, and Regulatory Emotional self-efficacy. They used Netlogo,
https://ccl.northwestern.edu/netlogo/ (accessed on 16 January 2021), to create the virtual environment and to test the interaction of agents and the diffusion of fake news inside the network. They found that social media graphs, the number of interconnections, and the centrality of nodes have a greater impact than personality scores. Even if this project was tested in a simulated scenario, it suggests that the solution to the problem of fake news diffusion comes from a multi-facets approach both from the psychology of the users and from the structure of the social networks. In [
27], Ross et al. described how the user’s personality changes their behavior during an interaction with Facebook. Similarly, in [
28], Heinstrom et al. described how personality dimensions influence the information diffusion in social media platforms. In this field, Giachanou et al. developed a user-centered CNN model to deal with misinformation spreaders and fact checkers [
29]. They developed a multi-input CNN with linguistic features associated with personality traits from the Five Factor Model and the LIWC (Linguistic Inquiry Word Count) [
30] dictionary. Their model is word based, and it uses the 300-dimensional pretrained GloVe embeddings [
31] to transform textual tweets into a 2D embeddings matrix. These embeddings are the input of a convolutional layer; then, they are processed to compute personality traits and finally merged with manual extracted LIWC features. This approach is innovative because it uses both the personality traits of a user and their linguistic patterns in the context of fake news. It also proposes a solution that leverages the actions and the motivations of the social media users. On the other hand, this work presents some major limitations; in fact, the computed personality traits have not been validated with a ground truth dataset or with the support of a questionnaire so this initial error is further spread in the successive layers of their neural network. This research project has also some drawbacks in the labeling procedure because it heavily relies on the presence of specific words associated with fact checks or false claims such as hoax, fake, false, fact check, snopes, politifact leadstories, and lead stories, while tweets are labeled as fake if they are a retweet of original fake news. Even if this labeling procedure is manually checked over five hundreds tweets, it is not fully error proof. In addition, stance classification to assess the support or denial of the fake news is not considered at all. Finally, the final number of users analyzed is less than three thousands, and the final
is below 0.6, meaning that the binary classifier has room to be improved.
According to the research projects listed so far, this field of investigation is split into two macro areas. The first one detects fake news contents with the adoption of natural language processing models. The second area monitors the social network topologies to compute how the misinformation spreads among social media users. According to the RQ1, our work inspects the intersection of these two fields with the creation of a linguistic model, focused on COVID-19, to classify fake news spreaders and real news checkers increasing the recall, precision and
of the existing baseline by Giachanou et al. [
29]. In fact, Limeng and Dongwon [
9] already labeled fake news and real news in their CoAID dataset. We collected users sharing misinformation about COVID-19 from the CoAID dataset, and we downloaded the related Twitter timelines they authored. We transformed this source of information into user embeddings, encoding their tweets, and we exploited their linguistic signals for classification. We released our dataset on Figshare,
https://doi.org/10.6084/m9.figshare.14392859 (accessed on 7 May 2021), and the code of our Fake News Spreader Classifier on Github,
https://github.com/D2KLab/stopfaker (accessed on 7 May 2021). In addition, we built the RF Fake News Spreader Classifier, a random forest model that exploits a list of features from each Twitter account reaching scores comparable to the ones obtained with the linguistic model. We also developed another deep learning model that receives both tweet embedding and Twitter information as inputs, obtaining lower results in precision, recall, and
with respect to the baseline by Giachanou et al. [
29]. In the following section, we describe how we collected the data and how we created the gold standard for this research field to answer our RQ2.
3. Dataset and Gold Standard Creation
The CoAID dataset [
9] contains two main resources. The first one is a table storing information about fake news and real news about COVID-19 such as the news URL, the link to the fact checking agency that checked it, the title, the content, the abstract, the publish date, and keywords, as listed in
Table 1.
The second one is a list of tweet IDs containing fake and real news and a masked reference ID of the related author. Tweet IDs are divided into four categories: fake and real claims, and fake and real news. The former are just opinions with no URLs inside, and the latter, instead, have an explicit URL redirecting to news. We decided to work with the last ones because we need both the content of the article and the content of the tweet to perform the stance classification. The CoAID dataset includes 4251 fact-checked news and 296,000 related user engagements about COVID-19. The checked fake news are contents that have already been demonstrated as false by fact-checking agencies. In this project, six of these agencies are considered: LeadStories
https://leadstories.com/hoax-alert/ (accessed on 13 November 2020), PolitiFact
https://www.politifact.com/coronavirus/ (accessed on 13 November 2020), FactCheck.org
https://www.factcheck.org/fake-news/ (accessed on 13 November 2020), CheckYourFact
https://checkyourfact.com/ (accessed on 13 November 2020), AFP Fact Check
https://factcheck.afp.com/ (accessed on 13 November 2020), and Health Feedback
https://healthfeedback.org/ (accessed on 13 November 2020). The publishing dates of the collected information range from 1 December 2019 to 1 November 2020. We used tweets containing fake news or real news URLs, and from them, we extracted the social media users who authored them. The CoAID dataset lists the real tweet ID, but for privacy constraints, the user ID of each author is masked, so we need to query the Twitter API to retrieve them. We built an extended version of CoAID by retrieving each user’s entire timeline from 1 December 2019. Our extended version of the CoAID dataset is publicly available on Figshare
https://doi.org/10.6084/m9.figshare.14392859 (accessed on 13 November 2020), and it is one of the two main contributions of this research project along with the linguistic model to classify fake news spreaders. The retrieval pipeline is described in
Figure 1. We collected 11,465 users with an average timeline of 2012 tweets per user. Our text preprocessing phase and data cleaning includes an initial phase of URL extensions because the downloaded tweets contain the Twitter shortened version of the original posted links. As an example, the shortened URL
https://t.co/3g8dLgoDOf (accessed on 13 November 2020) has to be extended to
https://www.dailymail.co.uk/health/article-9225235/Rare-COVID-arm-effect-leaves-people-got-Modernas-shot-itchy-red-splotch.html (accessed on 13 November 2020). The now extended link was searched inside the CoAID dataset, and if there was a match, we performed the stance detection using the text contained in the original tweet and the abstract of the news from CoAID as input. The stance classification model is an adapted version of the one by Aker et al. [
32] in the context of our use case scenario. It is a word-based Random Forest that features Bag of Words, Part of Speech Tagging, Sentiment Analysis, and Named Entity Recognition to classify the source tweet with respect to another one. The entire pipeline was further tuned to work with pretrained multilingual BERT embeddings by the Gate Cloud community,
https://cloud.gate.ac.uk/ (accessed on 13 November 2020), and the source code is available in a publicly accessible repository,
https://github.com/GateNLP/StanceClassifier (accessed on 13 November 2020). The stance classification output defines whehter the tweet supports, denies, queries, or comments on the linked news. We discard the query and comment cases while counting support and deny ones. If a user supports more fake news than real news, they are labeled as a spreader, and for vice versa, they are labeled as a checker. In the case of an equal number for real and fake news, the user is discarded. The pipeline describing this process is presented in
Figure 2. The stance classification algorithm avoids labeling a user as a spreader while they try to refute the fake news spotted. After the data retrieval, data cleaning, and user labeling, we obtained an extended version of the original CoAID dataset to be used as a gold standard. The statistics of this dataset are listed in
Table 2. There are 5333 spreaders and 6132 checkers, with an average of 19 tweets supporting fake news per spreader and 55 tweets supporting real news per checker.
We created the gold standard dataset for the classification of users sharing misinformation about COVID-19. The extended version of the CoAID dataset presents a list of mapped user IDs for privacy concerns, the list of real tweet IDs as retrieved from Twitter, and the label classifying the tweet author as a spreader or checker. Five randomly selected rows from the CoAID extended dataset are listed in
Table 3. This gold standard answers the RQ2 listed in
Section 1.
5. Experimental Results
In this section, we analyze the above model results to assess that we improved the actual state-of-the-art in fake news spreader classification. We compare our model with a previous one by Giachanou et al. [
29] as well as different machine learning and deep learning approaches.
The experiment was performed with the CoAID extended dataset (11,465 users and 23 M tweets). In
Table 6, we present the results of our model compared with the other configurations and the previous state-of-the-art results, adopting as validation metrics recall, precision, and
score. We used a ten fold cross validation, and we averaged the results obtained for each split. We then performed a ten-fold cross validation to verify the model is effective in each split of the CoAID extended dataset.
Validation metrics, in the binary case, compute how many candidates are well classified with respect to the expected output as described in the following.
tp (true positive) represents the number of spreaders correctly classified.
tn (true negative) represents the number of checkers correctly classified.
fp (false positive) represents the number of checkers classified as spreaders.
fn (false negative) represents the number of spreaders classified as checkers.
As shown by the Equations (
7)–(
9), where
p is the precision metric and
r is the recall metric, these metrics give insights about spreader classification effectiveness. This project’s goal is primarily to find fake news spreaders because they are the one socially dangerous rather than fact checkers that behave normally. In the binary case, precision and recall are more suitable than accuracy to address this issue. With these premises, we explain the results of each tested model.
The first line of
Table 6 reports the scores obtained with our model as described in
Section 4 that uses the sole textual information collected in the user timelines as input.
In parallel, we have in row two the results obtained with the RF Fake News Spreader Classifier, a random forest with 100 estimators, and Gini split criterion with no max depth. Random Forest is an ensemble method that operates by constructing a multitude of decision trees and by outputting the class that is the mode of the classes or mean prediction of the individual trees. In our case, there are two classes: fake news spreader or real news checker. We use 11 as the max_feature parameter, derived from the number of features listed and described in
Table 7. We collected the Twitter account information of each user found in the CoAID extended dataset. We transformed the string type features (location and created at) with one hot encoding, while the boolean features (protected, verified, default profile, default profile image) were mapped to 1 or 0. All of the features were then min–max scaled and translated individually such that they are in the given range between zero and one. It is interesting to notice that its metrics are closer to the best performing ones so that it is an index to express the great amount of information contained in social media graph features related to each Twitter user.
The third line in
Table 6 shows the final results of the model by Giachanou et al. [
29] running on our CoAID extended dataset. We considered their model as the previous state-of-the-art in this field because their work explicitly searches for spreaders and checkers considering user-related features and not just the news. They collect personality traits and psychological signals from the LIWC dictionary of each user.
In the last line, Mixed Fake News Spreader Classifier reports the results we have when we concatenate tweet embeddings and the tabular data containing Twitter user information in the penultimate layer of the FNSC stacked neural network. In the last configuration, the additional information from the users account does not improve the final score. The results presented in
Table 6 and the related comments answer the RQ1 listed in
Section 1. In fact, we demonstrate that tweet encoding based on transformers and deep learning is effective in fake news spreader classification because they obtain results above 80% in precision, recall, and
. It is also better with respect to solutions adopting standard machine learning as the RF Fake News Spreader Classifier described previously.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}