
Towards Flexible Retrieval, Integration and Analysis of JSON Data Sets through Fuzzy Sets: A Case Study



Abstract
:1. Introduction
2. Background
2.1. Brief Introduction to Fuzzy Sets
2.2. Related Work
2.3. Genesis of the J-CO Framework
3. The J-CO Framework
- Web Data Sources. Web sites, Open Data portals and Social Media can be accessed to obtain JSON data sets. In particular, end points of Open Data portals and Social Media can be easily contacted through an HTTP call. All together, these sources constitute an immense mine of potentially useful data.
- JSON Document Stores. Several NoSQL DBMSs have been built in order to natively store and manage JSON documents. For this reason, they are called “JSON Document Stores”. The most famous one is MongoDB, which is currently integrated within the J-CO environment. This category encompasses also tools that are not properly DBMSs but are able to store and provide JSON data sets. One of them is ElasticSearch, which is an information-retrieval tool; it is not a DBMS because it provides neither a query language nor the usual capabilities expected for a DBMS.
- J-CO-DS. JSON Document Stores can suffer for significant limitations in managing JSON documents. For example, MongoDB is unable to store very large documents because it has been designed to manage a very large number of small documents (thinking about operational processing). On the opposite side, ElasticSearch has to index documents, so it cannot be used as a pure storage system because it would be highly inefficient.For this reason, we designed J-CO-DS [73]: it is a component of the J-CO Framework that can be used to build JSON databases able to store very large JSON documents. It does not provide a query language because computational capabilities are provided by the framework. However, it can be a valuable tool to easily build flexible JSON stores.
- J-CO-QL Engine. This is the component of the framework that actually provides the computational capabilities. It executes J-CO-QL queries by accessing external data sources, JSON document stores and J-CO-DS databases to retrieve source data and to store output data.
- J-CO-UI. This is the current user interface provide by the J-CO Framework. It allows analysts to write J-CO-QL complex queries (or scripts, for simplicity) in a step-by-step way. In fact, the user can write one single instruction at a time, execute it and inspect temporary results. At this point, the user can decide either to submit another instruction or to roll back the last executed one (this way, a trial-and-error approach typical of investigation tasks can be adopted).
3.1. The J-CO-QL Language
3.1.1. Data Model
3.1.2. Execution Model
3.1.3. Features of J-CO-QL Instructions
- Adaptability to heterogeneity. Collections of documents could contain documents with heterogeneous structures. Instructions are designed to allow users to deal with documents with different structures in one single instruction.
- Spatial operations. The data model natively encompasses geometries within documents. Consequently, the language provides spatial operations, which rely on the ~geometry field, if present. Furthermore, these operations can be made “on the fly”, with no need to build persistent spatial indexes in advance.
- Orientation to analysts. Instructions are not oriented to programmers, while they are oriented to analysts. This means that the language is not imperative and does not provide any instruction to control the execution flow, such as conditional instruction or cycles. The execution semantics presented in Definition 9 are clear and intuitive; instructions are thought to be declarative, since each of them allows for specifying a specific transformation in a high-level way, i.e., a way that does not require strong skills in computer programming.
4. Case Study: Overview
- Part 1. This part of the script, reported in Listing 1, Listing 2, Listing 3, Listing 4, Listing 5 and Listing 6, is in charge of (i) obtaining the data from Regione Lombardia Open Data portal in the time window of interest and (ii) selecting only data related to the city of Milan describing the sensors that provide the desired measures. The final goal of this sub-script is to create documents that represent measure triplets, i.e., associations of three measurements of nitric oxide, solar radiation and rain precipitation, occurring at the same time and that are spatially close each other. Section 5 extensively discusses this part of the script by introducing non-fuzzy J-CO-QL instructions while presenting the script.
- Part 2. This part of the script, reported in Listing 7, contains the definitions of specific fuzzy operators to be used to analyze measure triplets that are obtained at the end of Part 1. Fuzzy operators allow for expressing linguistic predicates that allow for imprecise matching. Defining fuzzy operators is the preliminary step to actually use them to query measure triplets. Section 6 explains how it is possible to create fuzzy operators in J-CO-QL.
- Part 3. This part of the script, reported in Listing 8, applies the fuzzy operators defined in Part 2 to query the measure triplets produced by Part 1 on the basis of source data gathered from the Open Data portal. In order to solve Problem 1, we exploit linguistic predicates specified by means of the fuzzy operators defined in Part 3 so as to capture triplets that only partially match the condition as well; the membership degree is used to rank triplets, if necessary. Remember that we want to discover those areas in the city of Milan where high levels of nitric oxide are registered when there is either low solar radiation or persistent rain. Section 7 extensively explains the third part of the script in order to show how fuzzy sets can be successfully applied to analyze data sets represented as JSON documents.
5. Case Study Part 1: Retrieving Data about Sensors and Measurements
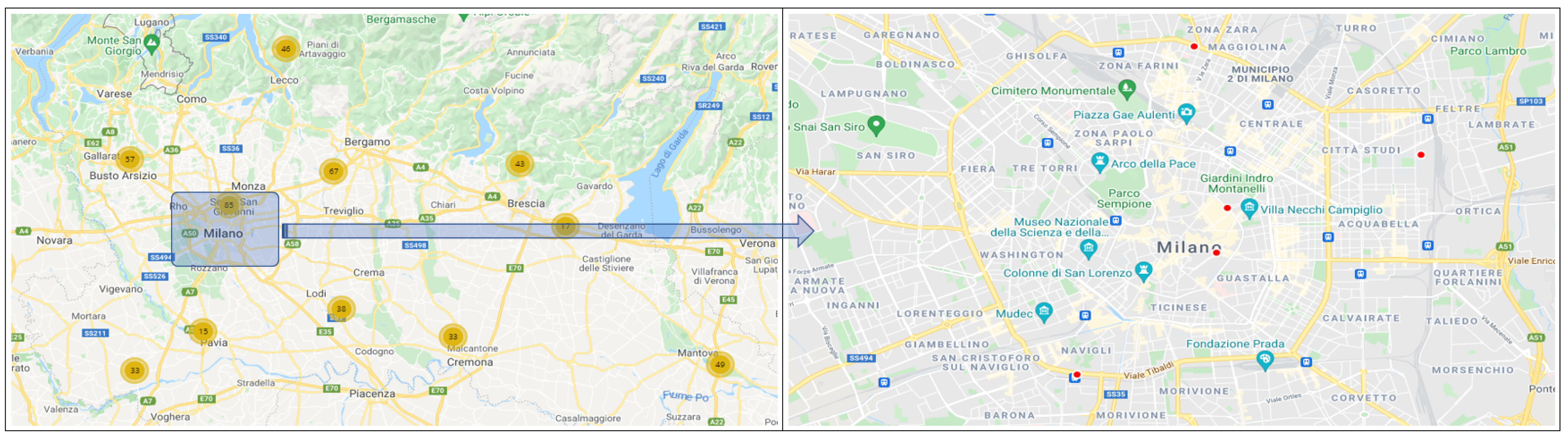
- Listing 1 retrieves all weather sensors located in Lombardia from Regione Lombardia Open Data portal [77]. Then, it selects sensors located in the area of Milan that measure either levels of solar radiation (expressed in W/m) or rain precipitation (expressed in mm). The left-hand side of Figure 2 shows the map [78] of weather sensors in Lombardia, while the right-hand side shows their precise positions within the city of Milan.
- Listing 2 retrieves data about air quality sensors located in Lombardia from Regione Lombardia Open Data portal [79]. Then, it selects sensors located in the area of Milan that measure levels of nitric oxide (expressed in mg/m). The left-hand side of Figure 3 shows the map [80] of air quality sensors in Lombardia, while the right-hand side shows their position within the city of Milan.
- Listing 3 builds virtual sensor stations, i.e., groups of nitric oxide, solar radiation and rain precipitation sensors that are close each other.
- Listing 4 retrieves all of the measurements produced by weather sensors during the time window from 08 April 2021 to 15 April 2021 from Regione Lombardia Open Data portal. Each measurement is described by a specific JSON document that reports the sensor identifier and the date and time in which the measurement was performed. The value of the measurement is provided by the portal as a pure number, with no information about the measure unit.
- Listing 5 retrieves all of the measurements produced by air quality sensors during the time window from 08 April 2021 to 15 April 2021 from Regione Lombardia Open Data portal. Again, each measurement is described by a JSON document that reports the sensor identifier and the date and time in which the measurement was performed. The value of the measurement is reported as a pure number, as it is for weather measurements.
- Listing 6 exploits the set of virtual sensor stations built by Listing 3 to create a collection of JSON documents describing measure triplets, where each document contains the levels of nitric oxide, solar radiation and rain precipitation measured at the same time by sensors grouped in the same virtual station.
5.1. Retrieving Data about Sensors for Solar Radiation and Rain Precipitation
- On line 1, USE DB instructs the system to connect to the database managed by the MongoDB server installed on the computer where the J-CO-QL Engine runs. The database is called INFORMATION_2021 and will contain the final JSON documents obtained by the script. Notice that this instruction alters the component of the query-process state (see Definition 7), containing descriptors of databases to which the process is connected.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
- The GET COLLECTION instruction on line 2 retrieves data about the weather sensors from Regione Lombardia Open Data portal by sending the request to the dedicated end point [77]. This is performed by specifying the URL which to send the HTTP request. In the URL, notice the parameters after the question mark: the first parameter ($limit=1000000) specifies the maximum number of documents to return; the second parameter ($where=storico<>"S") is written according to Socrata query language [76] (remember that Regione Lombardia Open Data portal is powered by the Socrata platform) selects only active weather sensors. The data are provided in JSON format as a unique array of documents, one for each sensor; the connector converts this array into a unique document containing an array field named data, which contains all documents provided by the portal. There are different kinds of sensor, each one providing a different measurement type. As an example, measurement types could be levels of solar radiation or rain precipitation, temperature, wind speed, and so on.Figure 4a shows an excerpt of the beginning of the document that constitutes the initial temporary collection (see Definitions 7 and 9). Notice that most of the field names are in Italian and that all of their values are reported as string values.We just introduced the capability of the GET COLLECTION instruction to send HTTP requests to web portals; in our previous publication [3], the instruction was able to retrieve collections from JSON databases only. With this minor extension, the entire World-Wide Web can be seen as a giant JSON store by the J-CO Framework.
- The EXPAND instruction on line 3 generates a new temporary collection by unnesting documents within array fields. Specifically, we want to generate one single document for each weather sensor obtained from the portal. The UNPACK clause selects all documents that satisfy the condition: in this case, by means of the WITH predicate, the UNPACK clause selects the lonely document in the input temporary collection because it has the data field. The ARRAY sub-clause specifies the field to expand (the data field) and the TO keyword precedes the field to generate into the new documents by unnesting an item in the source array. In fact, the instruction behaves this way: given a document to expand, for each item in the array, a novel document is generated; all fields in the source document are kept, except for the expanded array, while a new field is added. In this case, since the input document has only the data array field (to expand), the output documents have only the sensor field. Figure 4b shows an example of document generated by the instruction: notice that the sensor field is a sub-document with the item field, which contains the unnested document, and the position field, which denotes the position of the unnested item in the source array. Finally, the DROP OTHERS option discards all of those documents in the input temporary collection that is not selected by the UNPACK clause; clearly, in this case, it is ineffective.
- The FILTER instruction on line 4 filters and transforms documents in the temporary collection. It is an example of the feature we call adaptability to heterogeneity in Section 3.1.3.In the CASE clause, there are two distinct WHERE conditions that select documents from the input temporary collection. The evaluation policy is the following: for each document d in the input temporary collection, (i) if d matches the condition expressed in the first WHERE condition, then (ii) the following GENERATE action is applied to d and the subsequent WHERE condition(s) is ignored; (iii) if d does not match the first WHERE condition, then (iv) the second WHERE condition is evaluated on d and, if d matches it, the following GENERATE action is applied; otherwise, (v) d is discarded according to the final DROP OTHERS option.Notice that a FILTER instruction can have multiple WHERE conditions, each one with its own GENERATE action; this way, it can manage heterogeneous collections.
- −
- In this case, the first WHERE condition selects documents that have the fields that are listed in the WITH predicate and for which the values identify solar radiation sensors (.sensor.item.tipologia = "Radiazione Globale") in the province of Milan (.sensor.item.provincia = "MI"). Notice that a “province” is an administrative body that administers a territory smaller than a region). The following GENERATE action generates a new output document in place of the selected one; the structure described in the GENERATE action can be quite complex, but in this case, a simple flat document is generated (for ease of use). A field value can be: (i) a constant value (e.g., .sensorType : "Global Radiation"); (ii) a value taken as is from a source field (e.g., .sensorId : .sensor.item.idsensore); or (iii) a value obtained by converting the value of a source field from one data type to another (e.g., .latitude:TO_FLOAT (.sensor.item.lat), which converts a string into a floating-point number). The remaining source fields are discarded.
- −
- The second WHERE condition and the following GENERATE action work similarly to the previous ones; they select and rebuild only documents that describe rain precipitation sensors (.sensor.item.tipologia = "Precipitazione") in the province of Milan.Notice that documents that describe other types of sensor are discarded because they are not relevant to the case study.
Figure 5a shows an example of an output document. Notice that now all of the fields have an English name and their values are numerical if they represent a numerical property (e.g., the latitude field). - The FILTER instruction on line 5 selects those documents with the latitude and longitude fields (in this case, all of the documents) and the following GENERATE action specifies the SETTING GEOMETRY option, which creates and adds a geometry to the document by deriving the ~geometry field (according to Definition 4) from the latitude and longitude fields, which denote the position of the sensor. This new special field enables spatial operations on documents.
- The SET INTERMEDIATE AS instruction on line 6 saves the current temporary collection into the Intermediate Results database (as defined in Definition 7), naming it Weather_Sensors. This way, this key intermediate result is saved for subsequent use.
5.2. Retrieving Data about Sensors for Level of Nitric Oxide
- The GET COLLECTION instruction on line 7 obtains the data about active sensors for air quality from Regione Lombardia Open Data portal by sending the request to the dedicated end point [79]. As for the GET COLLECTION instruction on line 2 (in Listing 1), the data are received in JSON format as a unique document containing an array field (named data) where each item represents a single air-quality sensor. There are different kinds of sensor, each one performing a different measurement type; they can be (i) level of nitric oxide, (ii) level of ozone, (iii) level of carbon monoxide, and so on.
- The EXPAND instruction on line 8 generates a new temporary collection where each document represents a single air-quality sensor; similar to the EXPAND instruction on line 3; these documents are obtained by unnesting items in the data array field of the lonely and giant document provided by the GET COLLECTION instruction on line 7.
|
- The FILTER instruction on line 9 works in a simpler way to the FILTER instruction on line 4. Its WHERE condition selects documents that describe sensors for nitric oxide (predicate .sensor.item.tipologia = "Ossidi di Azoto") located in Milan (predicate .sensor.item.comune = "Milano"). We decided to select sensors in Milan instead of in the province of Milan because the documents in this collection have an extra field called comune, which identifies the municipality in which the sensor is located.The following GENERATE action operates in the same way as in line 4; in addition, it adds the extra city field to output documents.Figure 7a shows an example of one document in the new temporary collection. Notice that the document structure is identical to the document shown in Figure 5a apart from the extra city field. Original string values are converted into numerical floating-point values, and field names are translated into English from Italian.
- The FILTER instruction on line 10, similar to the FILTER instruction on line 5, creates the ~geometry field from the latitude and longitude fields.
- Finally, the SET INTERMEDIATE AS instruction on line 11 saves the current temporary collection into the Intermediate Results database with name NitricOxide_Sensors.
5.3. Building Virtual Sensor Stations
- The SPATIAL JOIN instruction on line 12 shows how J-CO-QL performs spatial operations; remember that this capability is one of the distinctive features of J-CO-QL that we mentioned in Section 3.1.3.
- −
- −
- Each document l in the left NO collection is coupled to each document r in the right WS collection so as to create a document d that describes a sensor for nitric oxide and a generic weather sensor.By exploiting the geometries that are present in the l and r documents, the spatial-join condition specified by the ON clause is evaluated; specifically, the DISTANCE function provides the distance between geometries in Km. If the distance is less than 2 Km, the condition is satisfied and the new d document is kept for further processing.
- −
- The d document contains three fields: (i) a field named NO, which contains the source l document; (ii) a field named WS, which contains the source r document; and (iii) the ~geometry field, which contains the geometry of the source left l document, as specified by the SET GEOMETRY LEFT specification.
- −
- Each d document is filtered by the WHERE condition in order to select only those documents in which the WS field describes a sensor for solar radiation. If the d document satisfies the WHERE condition, the following GENERATE action builds a new document o that is included in the output temporary collection; the o document has only three fields: (i) the NOsensorId field identifies the sensor for nitric oxide; (ii) the GRsensorId field identifies the sensor for solar radiation; and (iii) the NOsensorName field is a human readable field that denotes the address of the station containing the sensor for nitric oxide (it makes it easy for a user to locate the sensor in the city).
- −
- The KEEPING GEOMETRY option maintains the geometry in d (that we set to be the one provided by the l source document describing the sensor for nitric oxide before) for o, while the DROP OTHERS option discards all d documents that do not satisfy the WHERE condition (i.e., documents that do not describe a sensor for solar radiation).
Figure 8a shows an example of documents in the new temporary collection produced by line 12. Notice the few fields and the presence of the ~geometry field.
|
- The SET INTERMEDIATE AS instruction on line 13 saves the current temporary collection into the Intermediate Results database , with name SensorPairs.
- The SPATIAL JOIN instruction on line 14 works very similarly to the SPATIAL JOIN instruction on line 12.In this case, the instruction couples each document in the intermediate collection generated by the previous SPATIAL JOIN, named SensorPairs and aliased as SP, to each document in the intermediate collection Weather_Sensors (the documents describe weather sensors), aliased as WS.Again, the spatial-join condition is satisfied by geometries for which the distance is less than 2 Km from the nitric oxide sensor; the WHERE condition selects only the d documents for which the new WS field describes a sensor for rain precipitation. The output o documents generated by the GENERATE action have all of the fields already present in the source left documents (i.e., sensor pairs) plus the RPsensorId field that denotes the identifier of the sensor for rain precipitation. Again, the KEEPING GEOMETRY option maintains the geometry in d in o, which represents the position of the sensor for nitric oxide, while the DROP OTHERS option discards all d documents that do not satisfy the WHERE condition (i.e., documents that do not describe the desired triplets of sensors).
- The SET INTERMEDIATE AS instruction on line 15 saves the current temporary collection into the Intermediate Results database , with name SensorTriplets. The name is motivated by the fact that each document describes a triplet of sensors.
5.4. Retrieving Measurements Made by Weather Sensors
- The GET COLLECTION instruction on line 16 obtains all of the measurements made by weather sensors from Regione Lombardia Open Data portalby sending the request to the dedicated end point [81]. This time, the Socrata query (included in the URL after the question mark) is more complex than the ones reported on line 2 and line 7, since we have to retrieve only measurements taken during the time window from 08 April 2021 to 15 April 2021.As usual, the data are obtained in JSON format as a unique document containing the data array, where each item is a document that represents a single measurement.Figure 9a shows an excerpt of the obtained document that constitutes the new temporary collection.
- As for line 3 and line 8, the EXPAND instruction on line 17 generates a new temporary collection where each document represents a single weather measurement; documents are obtained by unnesting them from the data field in the unique document obtained from the portal.Figure 9b shows an example of documents in the new temporary collection. Notice that all field names are in Italian and that the numerical values are reported as strings.
- As for line 4 and line 9, the FILTER instruction on line 18 transforms the documents in the input temporary collection in order to translate field names into English and convert string values into numerical floating-point values, where necessary. The final structure of documents contains fields that denote (i) the identifier of the sensor (the sensorId field), (ii) the dateTime of the acquisition and (iii) the value of the measurement (recall that the unit of measure is within sensor descriptions).Figure 9c shows an example of documents in the new temporary collection.
- The SET INTERMEDIATE AS instruction on line 19 saves the current temporary collection into the Intermediate Results database , with name WeatherMeasures.
|
5.5. Retrieving Measurements Made by Air-Quality Sensors
- The GET COLLECTION instruction on line 20 retrieves all air-quality measurements made in the time window from 08 April 2021 to 15 April 2021 from Regione Lombardia Open Data portal, by sending the request to the dedicated end point [82]. Again, a unique document with an array field named data that contains all retrieved measurements is obtained.
- The EXPAND instruction on line 21 unnests items in the data field of the unique document provided by the GET COLLECTION instruction. This way, the new temporary collection contains one document for each single retrieved measurement. Figure 10b shows an example document. Notice that the document structure is identical to the structure of the document shown in Figure 9b.
- The FILTER instruction on line 22 translates field names into English and converts string values into numerical floating-point values, where necessary.
- The SET INTERMEDIATE AS instruction on line 23 saves the current temporary collection into the Intermediate Results database , with name AirQualityMeasures.
|
5.6. Aggregating Measurements
|
- The goal of the JOIN instruction on line 24 is to join documents in the SensorTriplets collection, saved on line 15, with documents in the AirQualityMeasurements collection, saved on line 23; the two collections are aliased, respectively, as S and as M. Consequently, the intermediate d documents contain two fields, named S and M.The documents produced by line 24 extends documents describing virtual sensor stations with measurements of nitric oxide. In fact, as the reader can see, the GENERATE action generates documents with the identifiers of the three grouped sensors, the date and time of measurement, and the nitric oxide measurement (the NOmeasure field).Figure 11a shows an example of documents generated by the first JOIN instruction.
- The SET INTERMEDIATE AS instruction on line 25 saves the current temporary collection with name AirQualityMeasures_Enriched into the Intermediate Results database .
- The goal of the JOIN instruction on line 26 is to further extend documents produced by line 24 with measurements of solar radiation.In fact, the reader can see that documents generated by the GENERATE action have the novel GRmeasure field in comparison with documents generated by line 24.Figure 11b shows an example of documents generated by the second JOIN instruction.
- The SET INTERMEDIATE AS instruction on line 27 saves the current temporary collection into the Intermediate Results database , with name MeasurePairs.
- The last JOIN instruction on line 28 further extends documents produced by line 26 with the measurement of rain precipitation.This way, as specified by the GENERATE action, we obtain the final documents to be analyzed with fuzzy sets. Specifically, we have (i) the dateTime field, denoting the date and time the measurements were acquired; (ii) the NOstationName field, which denotes the name of the station containing the sensor for nitric oxide; (iii) the NOmeasure and NOsensorId fields, denoting the measurement of nitric oxide and the identifier of the sensor; (iv) the GRmeasure and GRsensorId fields, which denote the measurement of solar radiation and the identifier of the sensor; and (v) the RPmeasure and RPsensorId fields, denoting the measurement of rain precipitation and the identifier of the sensor. We call these documents measure triplets.Figure 12a shows an example document.
6. Case Study Part 2: Defining Fuzzy Operators
|
- Let us consider the instruction that defines the Has_Low_Radiation operator on line 29.
- −
- The PARAMETERS clause defines the list of formal parameters needed by the fuzzy operator to provide a membership degree. Specifically, the Has_Low_Radiation operator receives one formal parameter, named radiation, which denotes a measured level of solar radiation.
- −
- The PRECONDITION clause specifies a precondition that must be met in order to correctly evaluate the membership degree. In line 29, the radiation parameter is considered valid if its value is no less than 0 (negative values of radiation are not meaningful).
- −
- The EVALUATE clause defines the mathematical function whose resulting value is used to get the actual membership degree. In line 29, the evaluation function is the radiation parameter itself.
- −
- The value returned by the function specified in the EVALUATE clause is used as x-value for the membership function, which provides the corresponding y-value. The membership function is defined as a polyline function, declared by means of the POLYLINE clause. The polyline is described by a list of points , with , and . When , the corresponding y-value is assumed to be equal to ; when , the corresponding y-value is assumed to be equal to .
The polyline function defined in line 29 is depicted in Figure 13a: if the level of radiation is 100 W/m, the membership degree is ; if the radiation is 800 W/m, the membership degree is ; if the radiation is 1200 W/m, the membership degree is 0 because the radiation is grater than the maximum x-axis value specified in the polyline. - The second fuzzy operator, defined at line 30, is named Has_High_Pollution. Similarly to the definition of the Has_Low_Radiation operator, it receives one single parameter, named NO_Concentration, which is considered valid by the precondition if its value is no less than 0. The membership polyline function is defined as depicted in Figure 13b.
- The third fuzzy operator, defined on line 31, is called Has_Persistent_Rain. It receives one single parameter, named Precipitation, which is considered valid by the precondition if its value is no less than 0. The membership polyline function is defined as depicted in Figure 13c.
7. Case Study Part 3: Detecting Highly Polluted Areas with Low Solar Radiation or Persistent Rain
|
- The behavior of the FILTER instruction on line 32 is a bit different from what has been shown previously. It receives the temporary collection with measure triplets generated on line 28 in Listing 6, which has remained unchanged by the instructions in Part 2 (Listing 7). The WHERE condition selects those documents with the fields NOmeasure, GRmeasure and RPmeasure.Since there is no GENERATE action, the selected documents remain unchanged. The following CHECK FOR FUZZY SET clauses allow for adding membership degrees to fuzzy sets to each document that is selected by the WHERE condition. All membership degrees are grouped together inside the special root-level field named ~fuzzysets , as reported in Definition 5.Let us discuss the instruction in details. First, remember that the input documents are structured as the sample document reported in Figure 12a.
- −
- Given a document d selected by the WHERE condition, the first CHECK FOR FUZZY SET clause evaluates its membership degree to a fuzzy set named HighPollution. The evaluation is performed by means of the fuzzy condition specified after the USING keyword: the fuzzy operator Has_High_Pollution is used to evaluate if the level of nitric oxide (the NOmeasure field) is actually high. Since this is a fuzzy condition, it is not true or false but it has a membership degree: in this case, this is the value returned by the fuzzy operator. Since this is the first fuzzy set for which a membership degree is evaluated for d, the ~fuzzysets field is not present yet in d; thus, the ~fuzzysets field is added to d with the HighPollution nested field within, for which the value is the membership degree that results from the evaluation of the USING soft condition. Even in the case the membership degree is 0, the field is created, meaning that the degree of membership to the fuzzy set is known.
- −
- Similarly, the second CHECK FOR FUZZY SET clause evaluates the degree of membership to the fuzzy set named LowRadiation; the fuzzy operator Has_Low_Radiation is applied on the level of solar radiation (denoted by the GRmeasure field) in the USING soft condition.Since now d already has the ~fuzzysets field, within it, a novel field named LowRadiation is added, for which the value is the membership degree resulting from the evaluation of the USING condition.
- −
- The third CHECK FOR FUZZY SET clause evaluates the degree of membership to the fuzzy set named PersistentRain; the USING soft condition applies the fuzzy operator named Has_Persistent_Rain to the level of rain precipitation (denoted by the RPmeasure field).A new nested field is added to the ~fuzzysets field at the root level of d: this field is named PersistentRain (as the name of the evaluated fuzzy set) and its value is the result of the evaluation of the USING soft condition.
- −
- The fourth CHECK FOR FUZZY SET clause evaluates the membership degree of d to the fuzzy set named Wanted; the name was chosen since it expresses whether the documents are actually the documents wanted by the user. In fact, the higher the membership degree, the closer they are to what the user wanted.What actually does the user want? Recalling Problem 1, the user wants the measure triplets that denote a high-level of pollution in conjunction with either low solar radiation or persistent rain. Since the three membership degrees for the fuzzy sets named HighPollution, LowRadiation and PersistentRain have already been evaluated, the USING soft condition is expressed by composing these three fuzzy sets:HighPollution AND (LowRadiation OR PersistentRain)The AND and OR operators are redefined according to their semantics for fuzzy sets (see Section 2.1): the AND operator returns the minimum membership degree of operands, while the OR operator returns the maximum.Notice how the fuzzy-set names play the role of “linguistic predicates”, i.e., they express the desired documents in a soft way; the underlying membership degrees allow for imprecise matching, tolerant to incomplete satisfaction.The new Wanted field is added to the root-level ~fuzzysets field in d; its value is the membership degree resulting from the evaluation of the USING soft condition.
- −
- The user is interested only in documents that are close enough to the wanted ones, thus documents that belong to the Wanted fuzzy set with a too low membership degree are not of interest. The ALPHA-CUT action discards all documents for which the degree of membership to the Wanted fuzzy set is less than the threshold of . This way, only documents that represent measure triplets that are sufficiently close to the desired ones are put into the output temporary collection.
What happens if the precondition of the fuzzy operators is not satisfied? The evaluation of the USING soft condition is stopped and the document is no longer modified, i.e., it remains either as the WHERE condition selected it or as the GENERATE action (if present) restructured it.Figure 12b shows the same document reported in Figure 12a after the evaluation of all the four fuzzy sets: notice the presence of the ~fuzzysets field and, within it, the four fields corresponding to each single fuzzy set; their value is the membership degree of the document. Notice that the document does not completely match the soft condition; however, its membership degree for the Wanted fuzzy set is , meaning that it could be still of interest for the user, in that it can be considered sufficiently close to the user needs. - The FILTER instruction on line 33 slightly restructures the documents coming from the previous FILTER instruction in order to generate the final data set.
- −
- The WHERE condition makes use of the KNOWN FUZZY SETS predicate: this is a Boolean predicate that is true if, for the evaluated document, the degree of membership to the specified fuzzy set(s) is known (i.e., a field with the same name appears in the root-level ~fuzzysets field). In this case, documents for which the membership to the Wanted fuzzy sets has been evaluated are selected. Recall that the WHERE condition is still a Boolean condition; thus, the KNOWN FUZZY SETS predicate is a kind of bridge between the Boolean world and the fuzzy world.
- −
- For each selected document, the GENERATE action builds a new document reporting the station name (the stationName field) and the date and time of the measurements (the dateTime field); furthermore, the membership degree to the Wanted fuzzy set becomes the value of the new rank field. In this regard, notice the expression rank : MEMBERSHIP_OF(Wanted), in which the MEMBERSHIP_OF function is used to obtain the membership degree of the specified fuzzy set. The goal of the rank field is to provide a rank for each single document in relation to the soft selection condition.
- −
- Finally, the DROPPING ALL FUZZY SETS option removes the special ~fuzzysets field. This way, documents are completely “de-fuzzified”, i.e., they become traditional crisp documents again; the only trace of the fuzzy process is the rank field.
- Finally, the SAVE AS instruction on line 34 persistently saves the current temporary collection into the MongoDB database named INFORMATION_2021 (that was declared for use on line 1 of Listing 1); the collection is saved and named DetectedEvents.
- Instead of considering a Boolean condition as a particular case of a soft condition, we propose a solution where the Boolean world (the WHERE Boolean condition) and the fuzzy world (the USING soft condition) are clearly separated.
- To be more precise, the Boolean world has a higher priority than the fuzzy world, i.e., (i) the Boolean condition selects documents to work on; then, (ii) the fuzzy world evaluates their belonging to fuzzy sets.
- The key point is exactly our view that a document can belong to many fuzzy sets. Necessarily, evaluating the belonging to fuzzy sets moves from fields in the documents.
- The adaptability to heterogeneity feature that characterizes J-CO-QL instructions is the reason why the CASE clause admits more than one WHERE condition: the language must be able to deal with many different structures of documents at the same time.
- However, documents structured in different ways should be treated differently as far as the evaluation of their belonging to fuzzy sets is concerned. Consequently, the list of CHECK FOR FUZZY SET clauses possibly followed by the ALPHA-CUT action must be necessarily considered conditioned by the WHERE condition: first, documents of interest are selected, in a traditional way, by the WHERE Boolean condition; then, on these documents, their belonging to as many fuzzy sets as necessary is evaluated; in practice, we further extend the documents by adding or updating the special ~fuzzysets field.
- The KNOWN FUZZY SETS predicate we added to the WHERE condition is, in some sense, the bridge between the two worlds because it allows for selecting documents (on which to possibly further evaluate their belonging to other fuzzy sets) by accessing the fuzzy side of documents in a Boolean way.
8. What Would Happen without J-CO?
- We treated the documents provided by the Open Data portal as if they were flat documents. In this sense, it could be the correct thinking that a data set provided in the CSV (Comma Separated Values) format, instead of JSON format, would be easier to manage. However, if the reader pays attention to the example documents provided by the Open Data portal in Figure 4a and Figure 6a, he/she can notice that documents are not actually flat, since they both have a structured field named location, holding geographic information. In these cases, we avoided access to its field called longitude and latitude (denoted as .location.longitude and .location.latitude), since there were the lng and lat fields at the root level, reporting the same values for longitude and latitude. Thus, the issue is as follows: what if the data sets are a set of structured documents? Would a CSV format be (more) suitable for a complex manipulation?
- Could a relational DBMS be used to integrate data about sensors and to build measure triplets, once data are provided as CSV files?
- Are fuzzy sets and soft querying really necessary? At the end, data are provided as crisp values, without uncertainty. Why should they be treated by means of fuzzy sets?
- Open Data provided by the portal as CSV files are saved into files on the analyst’s PC.
- By means of wizards provided by the specific relational DBMS, CSV files are uploaded into tables within the relational database.
- Cleaning and pre-processing activities are performed by writing SQL queries that create other tables. The alternative option could be to create “views” in place of novel tables.
- Triplets should be built by performing INNER JOIN operations in which the join conditions are based on the geodetic distance between points. If the DBMS used is not equipped with extensions to deal with spatial data, it is necessary to write a “User Defined Function” (UDF) with the procedural code to compute the distance.
- Once a table containing the measure triplets is built (and made persistent in the database), it is necessary to write another SQL query that somehow ranks them. In fact, simply cutting values of attributes based on a crisp comparison is not equivalent to the J-CO-QL script so far presented because this approach does not give a relevance to tuples based on attribute values.For example, if we write NOmeasure >= 30, we give equal importance to values 30 and 220; however, 30 denotes a low level of pollution while 220 denotes a very high level of pollution.
- Finally, an SQL query adds a novel attribute by computing an expression that exploits the User Defined Functions; the resulting value should be the rank of each single row with respect to the wishes of the user; a final selection filters only relevant rows.
- The process based on CSV and SQL is quite cumbersome. In particular, the need to create persistent tables within the database to store temporary results creates confusion.Part 1 of the J-CO-QL script (presented in Section 5) performs exactly the same activities but in a homogeneous way and working directly on the data sets received from the portal, with no need to save them on disk and importing them in another system. Therefore, activities are performed in a more natural way.
- In the relational setting, the geodetic distance can be computed by writing a specific User Defined Function; this fact asks for skills in procedural programming.The SPATIAL JOIN instruction provided by J-CO-QL performs this operation in a native way; no skills in procedural programming are needed.
- In the relational setting, User Defined Functions can be written in place of fuzzy operators. Apart from the need for skills in procedural programming, this approach makes what the analyst is called to do semantically unclean.In fact, the declarative approach provided by the CREATE FUZZY OPERATOR instruction in J-CO-QL lets the analyst focus on the actual semantics to provide single linguistic predicates.
- The adoption of fuzzy sets and soft conditions to rank data in J-CO-QL allows analysts to focus on specifying what they actually wish to look for.
- Finally, if portals provide non-flat data possibly containing arrays of documents, as often occurs with Social Media APIs, the relational setting becomes no longer practicable (see, for example, [22]).
9. Conclusions and Future Work
9.1. Conclusions
- We showed the capability of J-CO-QL in directly retrieving data from Open Data portals and in processing them, performing complex cross-analysis and data integration tasks, in a totally integrated way. Part 1 demonstrated that there is no need to rely on a JSON document store such as MongoDB to acquire data and to perform complex transformations on them.
- The fuzzy extension of J-CO-QL provides a specific construct to define “fuzzy operators”, i.e., operators to be used to evaluate the degree of membership to fuzzy sets of JSON documents. Part 2 showed that fuzzy operators can be defined by users; they are provided with a powerful tool that allows them to define complex ways to compute membership degrees. Our proposal significantly improves previous proposals, usually limited to simpler trapezoidal functions.
- We presented the extension made to the FILTER instruction, specifically the fuzzy clauses that follow a WHERE clause, to evaluate the degrees of membership to fuzzy sets of documents. Part 3 showed the flexibility of the language in dealing with multiple fuzzy sets at the same time so as to express soft selection conditions on documents; furthermore, the membership degree can be used to rank documents, where the rank represents how close a document is in relation to the situation desired by the user.
9.2. Future Work
- As far as the J-CO-QL language is concerned, we are going to further improve the support for fuzzy concepts. First, we will consider the JOIN and SPATIAL JOIN instructions; this latter one, in particular, has to apply fuzzy concepts to deal with geometrical properties.
- As far as the J-CO-QL Engine is concerned, we will explore the adoption of indexes and spatial indexes computed on the fly to improve computationally heavy operations such as JOIN and SPATIAL JOIN, towards the possible application of the J-CO Framework to manage Big Data.
- The need to continuously gather data from Open Data portals, which are data sets that could disappear from the portals, inspired us the notion of “virtual database”, i.e., a tool that provides a database view of data sets provided by Open Data portals. We only have an idea, but we are going to develop that idea.
- Another family of tools that can be added to the framework encompasses domain-specific languages and processors for managing specific JSON formats, such as GeoJSON; we performed the first step in this direction in [71], but we plan to complete that proposal and to extend the approach to other formats. The goal is to exploit J-CO-QL as the basis for implementing high-level tools.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, M.A.; Uddin, M.F.; Gupta, N. Seven V’s of Big Data understanding Big Data to extract value. In Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, Bridgeport, CT, USA, 3–5 April 2014; pp. 1–5. [Google Scholar]
- Bray, T. The Javascript Object Notation (JSON) Data InterchangeFormat. 2014. Available online: https://www.rfc-editor.org/rfc/rfc7159.txt (accessed on 22 April 2021).
- Psaila, G.; Fosci, P. J-CO: A Platform-Independent Framework for Managing Geo-Referenced JSON Data Sets. Electronics 2021, 10, 621. [Google Scholar] [CrossRef]
- Bordogna, G.; Psaila, G. Customizable flexible querying in classical relational databases. In Handbook of Research on Fuzzy Information Processing in Databases; IGI Global: Hershey, Pennsylvania, USA, 2008; pp. 191–217. [Google Scholar]
- Psaila, G.; Marrara, S. A First Step Towards a Fuzzy Framework for Analyzing Collections of JSON Documents. In Proceedings of the 16th IADIS International Conference on Applied Computing 2019, Cagliari, Italy, 7–9 November 2019; pp. 19–28. [Google Scholar]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inform. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- MongoDb. 2021. Available online: https://www.mongodb.com/ (accessed on 22 April 2021).
- Chodorow, K. MongoDB: The Definitive Guide: Powerful and Scalable Data Storage; O’Reilly Media, Inc.: Newton, MA, USA, 2013. [Google Scholar]
- CouchDb. 2021. Available online: https://couchdb.apache.org/ (accessed on 22 April 2021).
- Anderson, J.C.; Lehnardt, J.; Slater, N. CouchDB: The Definitive Guide: Time to Relax; O’Reilly Media: Newton, MA, USA, 2010. [Google Scholar]
- Bringas, P.G.; Pastor, I.; Psaila, G. Can BlockChain technology provide information systems with trusted database? The case of HyperLedger Fabric. In Proceedings of the International Conference on Flexible Query Answering Systems, Amantea, Italy, 2–5 July 2019; Springer: Cham, Switzerland, 2019; pp. 265–277. [Google Scholar]
- Garcia Bringas, P.; Pastor-López, I.; Psaila, G. BlockChain Platforms in Financial Services: Current Perspective. Bus. Syst. Res. Int. J. Soc. Adv. Innov. Res. Econ. 2020, 11, 110–126. [Google Scholar]
- Nayak, A.; Poriya, A.; Poojary, D. Type of NOSQL databases and its comparison with relational databases. Int. J. Appl. Inf. Syst. 2013, 5, 16–19. [Google Scholar]
- Ong, K.W.; Papakonstantinou, Y.; Vernoux, R. The SQL++ unifying semi-structured query language, and an expressiveness benchmark of SQL-on-Hadoop, NoSQL and NewSQL databases. arXiv 2014, arXiv:1405.3631. [Google Scholar]
- Florescu, D.; Fourny, G. JSONiq: The history of a query language. IEEE Internet Comput. 2013, 17, 86–90. [Google Scholar] [CrossRef]
- Cattell, R. Scalable SQL and NoSQL data stores. ACM Sigmod Rec. 2011, 39, 12–27. [Google Scholar] [CrossRef] [Green Version]
- Beyer, K.S.; Ercegovac, V.; Gemulla, R.; Balmin, A.; Eltabakh, M.; Kanne, C.C.; Ozcan, F.; Shekita, E.J. Jaql: A scripting language for large scale semistructured data analysis. Proc. VLDB Endow. 2011, 4, 1272–1283. [Google Scholar] [CrossRef]
- Chamberlin, D. SQL++ For SQL Users: A Tutorial. 2018. Available online: http://asterixdb.apache.org/files/SQL_Book.pdf (accessed on 22 April 2021).
- Chamberlin, D. XQuery: An XML query language. IBM Syst. J. 2002, 41, 597–615. [Google Scholar] [CrossRef] [Green Version]
- Arora, R.; Aggarwal, R.R. Modeling and querying data in mongodb. Int. J. Sci. Eng. Res. 2013, 4, 141–144. [Google Scholar]
- Bordogna, G.; Capelli, S.; Psaila, G. A big geo data query framework to correlate open data with social network geotagged posts. In Proceedings of the The 20th AGILE International Conference on Geographic Information Science, Wageningen, The Netherlands, 9–12 May 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 185–203. [Google Scholar]
- Bordogna, G.; Capelli, S.; Ciriello, D.E.; Psaila, G. A cross-analysis framework for multi-source volunteered, crowdsourced, and authoritative geographic information: The case study of volunteered personal traces analysis against transport network data. Geo-Spat. Inf. Sci. 2018, 21, 257–271. [Google Scholar] [CrossRef]
- Blair, D.C. Information Retrieval, 2nd ed. C.J. Van Rijsbergen. London: Butterworths; 1979: 208 pp. Price: $32.50. J. Am. Soc. Inf. Sci. 1979, 30, 374–375. [Google Scholar] [CrossRef]
- Bosc, P.; Prade, H. An introduction to the fuzzy set and possibility theory-based treatment of flexible queries and uncertain or imprecise databases. In Uncertainty Management in Information Systems; Springer: Berlin/Heidelberg, Germany, 1997; pp. 285–324. [Google Scholar]
- Medina, J.M.; Pons, O.; Vila, M.A. Gefred: A generalized model of Fuzzy Relational Databases. Inform. Sci. 1994, 76, 87–109. [Google Scholar] [CrossRef]
- Galindo, J.; Urrutia, A.; Piattini, M. Fuzzy Databases: Modeling, Design, and Implementation; IGI Global: Hershey, PA, USA, 2006. [Google Scholar]
- Galindo, J. New characteristics in FSQL, a fuzzy SQL for fuzzy databases. WSEAS Trans. Inf. Sci. Appl. 2005, 2, 161–169. [Google Scholar]
- Kacprzyk, J.; Zadrożny, S. FQUERY for Access: Fuzzy Querying for a Windows-Based DBMS. In Fuzziness in Database Management Systems; Springer: Berlin/Heidelberg, Germany, 1995; Volume 5, pp. 415–433. [Google Scholar]
- Bordogna, G.; Psaila, G. Modeling soft conditions with unequal importance in fuzzy databases based on the vector p-norm. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems (IPMU), Malaga, Spain, 22–27 June 2008. [Google Scholar]
- Bordogna, G.; Psaila, G. Soft Aggregation in Flexible Databases Querying based on the Vector p-norm. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2009, 17, 25–40. [Google Scholar] [CrossRef]
- Bosc, P.; Pivert, O. SQLf: A relational database language for fuzzy querying. IEEE Trans. Fuzzy Syst. 1995, 3, 1–17. [Google Scholar] [CrossRef]
- Bosc, P.; Pivert, O. SQLf query functionality on top of a regular relational database management system. In Knowledge Management in Fuzzy Databases; Springer: Berlin/Heidelberg, Germany, 2000; pp. 171–190. [Google Scholar]
- Galindo, J.; Medina, J.M.; Pons, O.; Cubero, J.C. A server for fuzzy SQL queries. In Proceedings of the International Conference on Flexible Query Answering Systems, Roskilde, Denmark, 13–15 May 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 164–174. [Google Scholar]
- Zadrozny, S.; Kacprzyk, J. Fquery for access: Towards human consistent querying user interface. In Proceedings of the 1996 ACM symposium on Applied Computing, Philadelphia, PA, USA, 17–19 February 1996; pp. 532–536. [Google Scholar]
- Kacprzyk, J.; Zadrozny, S. SQLf and FQUERY for Access. In Proceedings of the Joint 9th IFSA World Congress and 20th NAFIPS International Conference (Cat. No. 01TH8569), Vancouver, BC, Canada, 25–28 July 2001; Volume 4, pp. 2464–2469. [Google Scholar]
- Urrutia, A.; Tineo, L.; Gonzalez, C. FSQL and SQLf: Towards a standard in fuzzy databases. In Handbook of Research on Fuzzy Information Processing in Databases; IGI Global: Hershey, PA, USA, 2008; pp. 270–298. [Google Scholar]
- Ma, Z.M.; Yan, L. Generalization of strategies for fuzzy query translation in classical relational databases. Inform. Softw. Technol. 2007, 49, 172–180. [Google Scholar] [CrossRef]
- Galindo, J. Handbook of Research on Fuzzy Information Processing in Databases; IGI Global: Hershey, PA, USA, 2008. [Google Scholar]
- Bordogna, G.; Pasi, G. Linguistic aggregation operators of selection criteria in fuzzy information retrieval. Int. J. Intell. Syst. 1995, 10, 233–248. [Google Scholar] [CrossRef]
- Kraft, D.H.; Colvin, E.; Bordogna, G.; Pasi, G. Fuzzy information retrieval systems: A historical perspective. In Fifty Years of Fuzzy Logic and Its Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 267–296. [Google Scholar]
- Kraft, D.H.; Petry, F.E. Fuzzy information systems: Managing uncertainty in databases and information retrieval systems. Fuzzy Sets Syst. 1997, 90, 183–191. [Google Scholar] [CrossRef]
- Cheng, J.; Ma, Z.M.; Yan, L. f-SPARQL: A flexible extension of SPARQL. In Proceedings of the International Conference on Database and Expert Systems Applications (DEXA), Bilbao, Spain, 30 August–3 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 487–494. [Google Scholar]
- Lopez-Pellicer, F.J.; Silva, M.J.; Chaves, M.; Zarazaga-Soria, F.J.; Muro-Medrano, P.R. Geo linked data. In Proceedings of the International Conference on Database and Expert Systems Applications (DEXA), Bilbao, Spain, 30 August–3 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 495–502. [Google Scholar]
- Pérez, J.; Arenas, M.; Gutierrez, C. Semantics and complexity of SPARQL. ACM Trans. Database Syst. (TODS) 2009, 34, 1–45. [Google Scholar] [CrossRef] [Green Version]
- De Maio, C.; Fenza, G.; Furno, D.; Loia, V. f-SPARQL extension and application to support context recognition. In Proceedings of the 2012 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Brisbane, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Pivert, O.; Slama, O.; Thion, V. An extension of SPARQL with fuzzy navigational capabilities for querying fuzzy RDF data. In Proceedings of the 2016 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Vancouver, BC, Canada, 24–29 July 2016; pp. 2409–2416. [Google Scholar]
- Castelltort, A.; Laurent, A. Fuzzy queries over NoSQL graph databases: Perspectives for extending the cypher language. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems (IPMU), Montpellier, France, 15–19 July 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 384–395. [Google Scholar]
- Abir, B.K.; Amel, G.T. Towards fuzzy querying of NoSQL document-oriented databases. In Proceedings of the DBKDA 2015: The Seventh International Conference on Advances in Databases, Knowledge, and Data Applications, Rome, Italy, 24–29 May 2015; pp. 153–158. [Google Scholar]
- Mehrab, F.; Harounabadi, A. Apply Uncertainty in Document-Oriented Database (MongoDB) Using F-XML. J. Adv. Comput. Res. 2018, 9, 87–101. [Google Scholar]
- Almendros-Jimenez, J.M.; Becerra-Teron, A.; Moreno, G. Fuzzy queries of social networks with FSA-SPARQL. Expert Syst. Appl. 2018, 113, 128–146. [Google Scholar] [CrossRef]
- Bordogna, G.; Campi, A.; Psaila, G.; Ronchi, S. A language for manipulating clustered web documents results. In Proceedings of the 17th ACM on Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 23–32. [Google Scholar]
- Bordogna, G.; Campi, A.; Psaila, G.; Ronchi, S. An interaction framework for mobile web search. In Proceedings of the 6th International Conference on Advances in Mobile Computing and Multimedia, Linz, Austria, 24–26 November 2008; pp. 183–191. [Google Scholar]
- Fosci, P.; Psaila, G. Toward a Product Search Engine based on User Reviews. In Proceedings of the International Conference on Data Technologies and Applications (DATA-2012), Rome, Italy, 25–27 July 2012; pp. 223–228. [Google Scholar]
- Fosci, P.; Psaila, G. Finding the best source of information by means of a socially-enabled search engine. In Proceedings of the KES 2012-COnference on in Knowledge-Based and Intelligent Information and Engineering Systems, San Sebastian, Spain, 10–12 September 2012; IOS Press: Amsterdam, The Netherlands, 2012; Volume 243, pp. 1253–1262. [Google Scholar]
- Fosci, P.; Psaila, G.; Di Stefano, M. Hints from the Crowd: A Novel NoSQL Database. In Proceedings of the International Conference on Model and Data Engineering, Amantea, Italy, 25–27 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 118–131. [Google Scholar]
- Fosci, P.; Psaila, G.; Di Stefano, M. The hints from the crowd project. In Proceedings of the International Conference on Database and expert Systems Applications, Prague, Czech Republic, 26–29 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 443–453. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Toccu, M. Building a Query Engine for a Corpus of Open Data. In Proceedings of the 13th International Conference on Web Information Systems and Technologies (WEBIST 2017), Porto, Portugal, 25–27 April 2017; pp. 126–136. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Toccu, M. Enhanced Querying of Open Data Portals. In Proceedings of the International Conference on Web Information Systems and Technologies, Barcelona, Spain, 4–6 October 2017; Springer: Cham, Switzerland, 2017; pp. 179–201. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Toccu, M. The Challenge of using Map-reduce to Query Open Data. In Proceedings of the DATA-2017 6th International Conference on Data Science, Technology and Applications, Madrid, Spain, 24–26 July 2017; pp. 331–342. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Toccu, M. Hadoop vs. Spark: Impact on Performance of the Hammer Query Engine for Open Data Corpora. Algorithms 2018, 11, 209. [Google Scholar] [CrossRef] [Green Version]
- Marrara, S.; Pelucchi, M.; Psaila, G. Blind Queries Applied to JSON Document Stores. Information 2019, 10, 291. [Google Scholar] [CrossRef] [Green Version]
- Cuzzocrea, A.; Psaila, G.; Toccu, M. Knowledge discovery from geo-located tweets for supporting advanced big data analytics: A real-life experience. In Model and Data Engineering; Springer: Berlin/Heidelberg, Germany, 2015; pp. 285–294. [Google Scholar]
- Cuzzocrea, A.; Psaila, G.; Toccu, M. An innovative framework for effectively and efficiently supporting big data analytics over geo-located mobile social media. In Proceedings of the 20th International Database Engineering & Applications Symposium, Montreal, QC, Canada, 11–13 July 2016; pp. 62–69. [Google Scholar]
- Bordogna, G.; Cuzzocrea, A.; Frigerio, L.; Psaila, G.; Toccu, M. An interoperable open data framework for discovering popular tours based on geo-tagged tweets. Int. J. Intell. Inf. Database Syst. 2017, 10, 246–268. [Google Scholar] [CrossRef]
- Bordogna, G.; Frigerio, L.; Cuzzocrea, A.; Psaila, G. Clustering geo-tagged tweets for advanced big data analytics. In Proceedings of the 2016 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 27 June–2 July 2016; pp. 42–51. [Google Scholar]
- Burini, F.; Cortesi, N.; Gotti, K.; Psaila, G. The Urban Nexus Approach for Analyzing Mobility in the Smart City: Towards the Identification of City Users Networking. Mobile Inform. Syst. 2018, 2018. [Google Scholar] [CrossRef] [Green Version]
- Burini, F.; Cortesi, N.; Psaila, G. From Data to Rhizomes: Applying a Geographical Concept to Understand the Mobility of Tourists from Geo-Located Tweets; Multidisciplinary Digital Publishing Institute: Basel, Switzerland, 2021; Volume 8, p. 1. [Google Scholar]
- Bordogna, G.; Pagani, M.; Psaila, G. Database model and algebra for complex and heterogeneous spatial entities. In Progress in Spatial Data Handling; Springer: Berlin/Heidelberg, Germany, 2006; pp. 79–97. [Google Scholar]
- Psaila, G. A database model for heterogeneous spatial collections: Definition and algebra. In Proceedings of the 2011 International Conference on Data and Knowledge Engineering (ICDKE), Milan, Italy, 6 September 2011; pp. 30–35. [Google Scholar]
- Bordogna, G.; Ciriello, D.E.; Psaila, G. A flexible framework to cross-analyze heterogeneous multi-source geo-referenced information: The J-CO-QL proposal and its implementation. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017; pp. 499–508. [Google Scholar]
- Fosci, P.; Marrara, S.; Psaila, G. Soft Querying GeoJSON Documents within the J-CO Framework. In Proceedings of the 16th International Conference on Web Information Systems and Technologies (WEBIST 2020), Online Streaming, 3–5 November 2020; pp. 253–265. [Google Scholar]
- Bordogna, G.; Pagani, M.; Pasi, G.; Psaila, G. Evaluating uncertain location-based spatial queries. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Ceara, Brazil, 16–20 March 2008; pp. 1095–1100. [Google Scholar]
- Psaila, G.; Fosci, P. Toward an Anayist-Oriented Polystore Framework for Processing JSON Geo-Data. In Proceedings of the International Conferences on WWW/Internet, ICWI 2018 and Applied Computing 2018, Budapest, Hungary, 21–23 October 2018; pp. 213–222. [Google Scholar]
- Butler, H.; Daly, M.; Doyle, A.; Gillies, S.; Hagen, S.; Schaub, T. The GeoJSON format. Internet Engineering Task Force (IETF). 2016. Available online: https://datatracker.ietf.org/doc/html/rfc7946 (accessed on 22 April 2021).
- Regione Lombardia. Open Data Portal. 2021. Available online: https://www.dati.lombardia.it/ (accessed on 22 April 2021).
- Socrata Platform. 2021. Available online: https://dev.socrata.com/ (accessed on 22 April 2021).
- Regione Lombardia. Open Data Portal-Weather Stations. 2021. Available online: https://www.dati.lombardia.it/Ambiente/Stazioni-Meteorologiche/nf78-nj6b (accessed on 22 April 2021).
- Regione Lombardia. Open Data Portal-Weather Sensor Map. 2021. Available online: https://www.dati.lombardia.it/Ambiente/Mappa-Stazioni-Meteorologiche/8ux9-ue3c (accessed on 22 April 2021).
- Regione Lombardia. Open Data Portal-Air Quality Stations. 2021. Available online: https://www.dati.lombardia.it/Ambiente/Stazioni-qualit-dell-aria/ib47-atvt (accessed on 22 April 2021).
- Regione Lombardia. Open Data Portal-Air Quality Sensor Map. 2021. Available online: https://www.dati.lombardia.it/Ambiente/Mappa-stazioni-qualit-dell-aria/npva-smv6 (accessed on 22 April 2021).
- Regione Lombardia. Open Data Portal-Weather Measures. 2021. Available online: https://www.dati.lombardia.it/Ambiente/Dati-sensori-meteo/647i-nhxk (accessed on 22 April 2021).
- Regione Lombardia. Open Data Portal-Air Quality Measures. 2021. Available online: https://www.dati.lombardia.it/Ambiente/Dati-sensori-aria/nicp-bhqi (accessed on 22 April 2021).
- GitHub Repository of the JCO-Project. 2021. Available online: https://github.com/zunstraal/J-Co-Project (accessed on 22 April 2021).














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fosci, P.; Psaila, G. Towards Flexible Retrieval, Integration and Analysis of JSON Data Sets through Fuzzy Sets: A Case Study. Information 2021, 12, 258. https://doi.org/10.3390/info12070258
Fosci P, Psaila G. Towards Flexible Retrieval, Integration and Analysis of JSON Data Sets through Fuzzy Sets: A Case Study. Information. 2021; 12(7):258. https://doi.org/10.3390/info12070258
Chicago/Turabian StyleFosci, Paolo, and Giuseppe Psaila. 2021. "Towards Flexible Retrieval, Integration and Analysis of JSON Data Sets through Fuzzy Sets: A Case Study" Information 12, no. 7: 258. https://doi.org/10.3390/info12070258
APA StyleFosci, P., & Psaila, G. (2021). Towards Flexible Retrieval, Integration and Analysis of JSON Data Sets through Fuzzy Sets: A Case Study. Information, 12(7), 258. https://doi.org/10.3390/info12070258