
Dynamic Optimal Travel Strategies in Intelligent Stochastic Transit Networks



Abstract
:1. Introduction
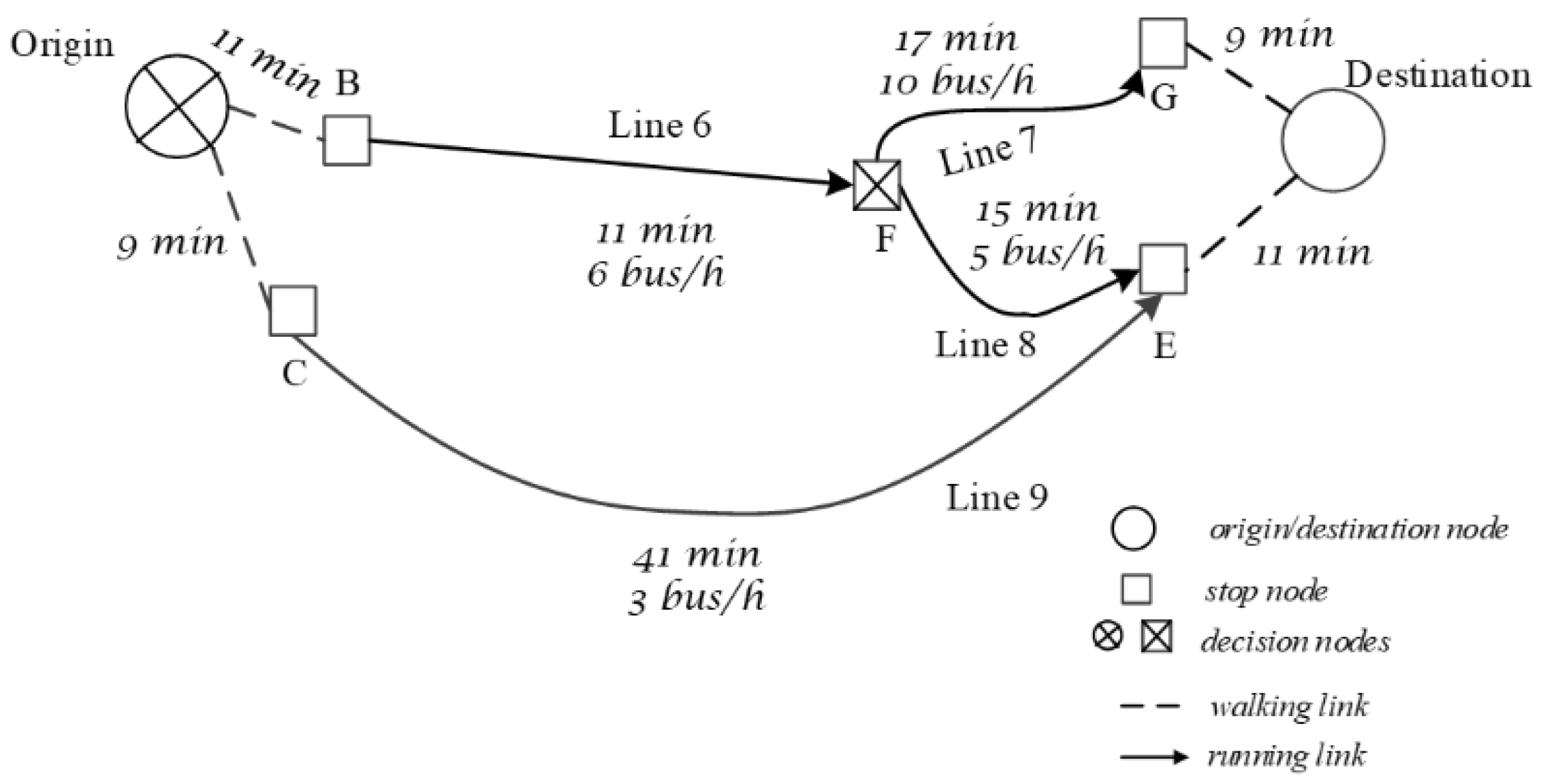
2. The Line-Based Search of an Optimal Travel Strategy
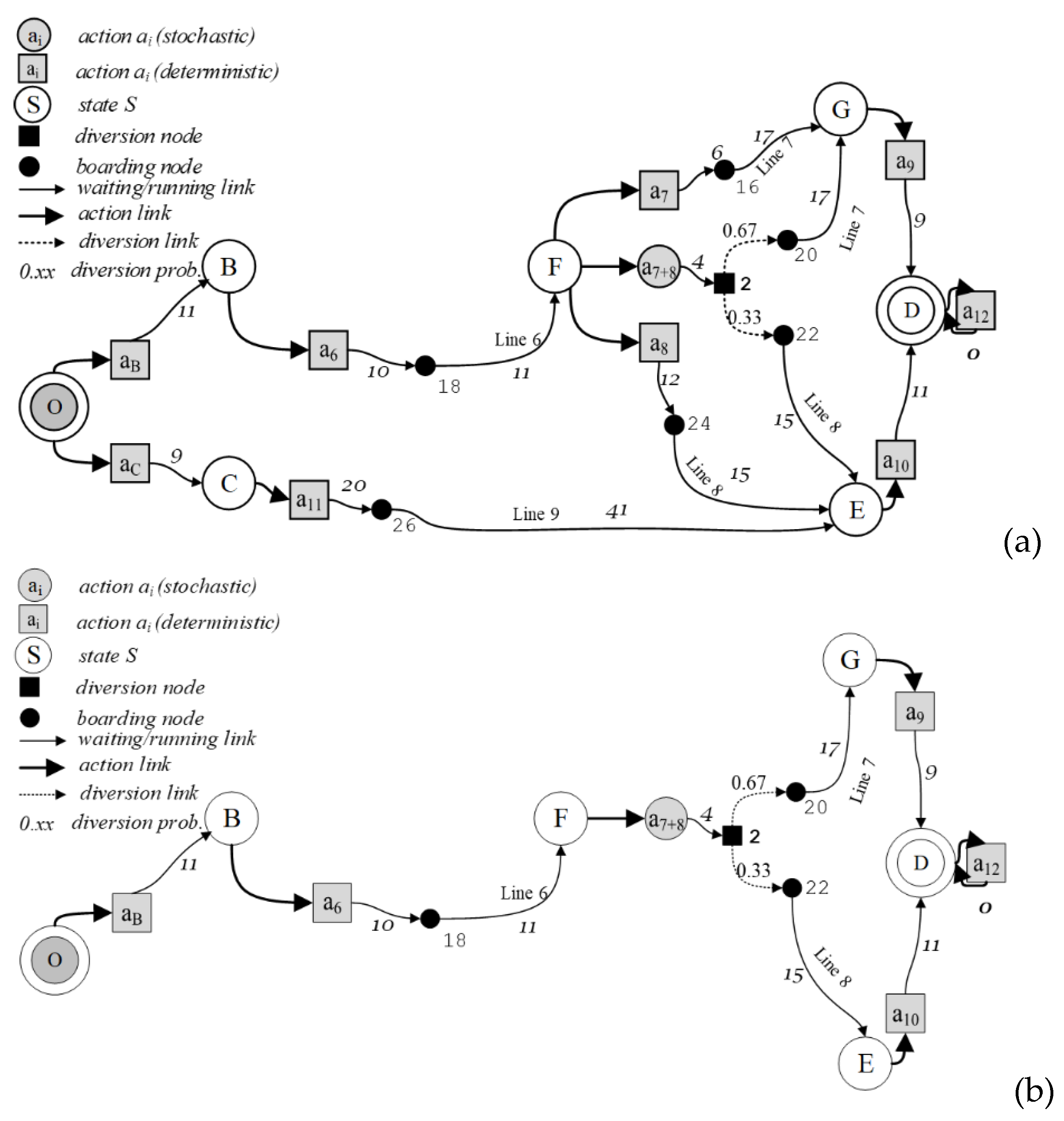
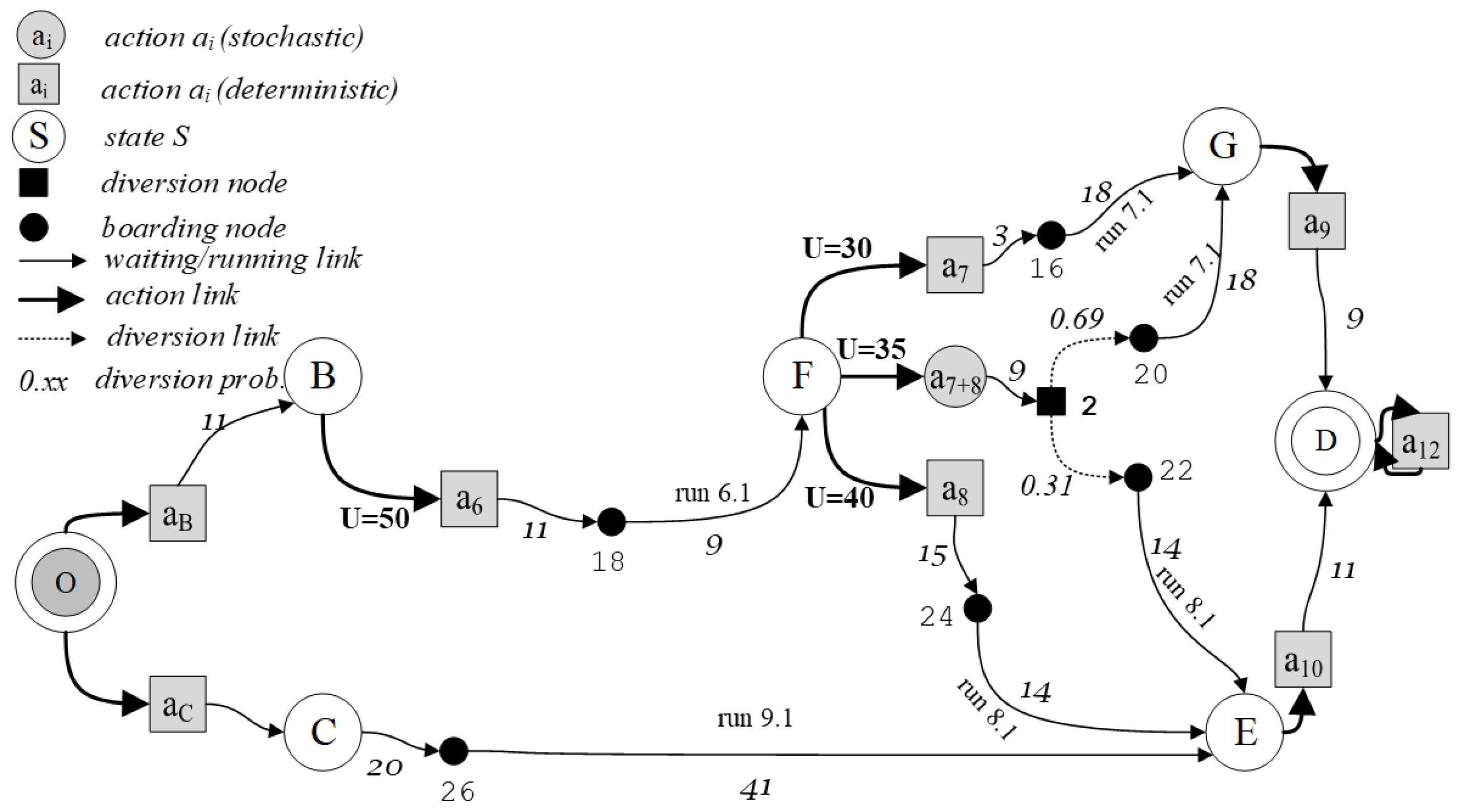
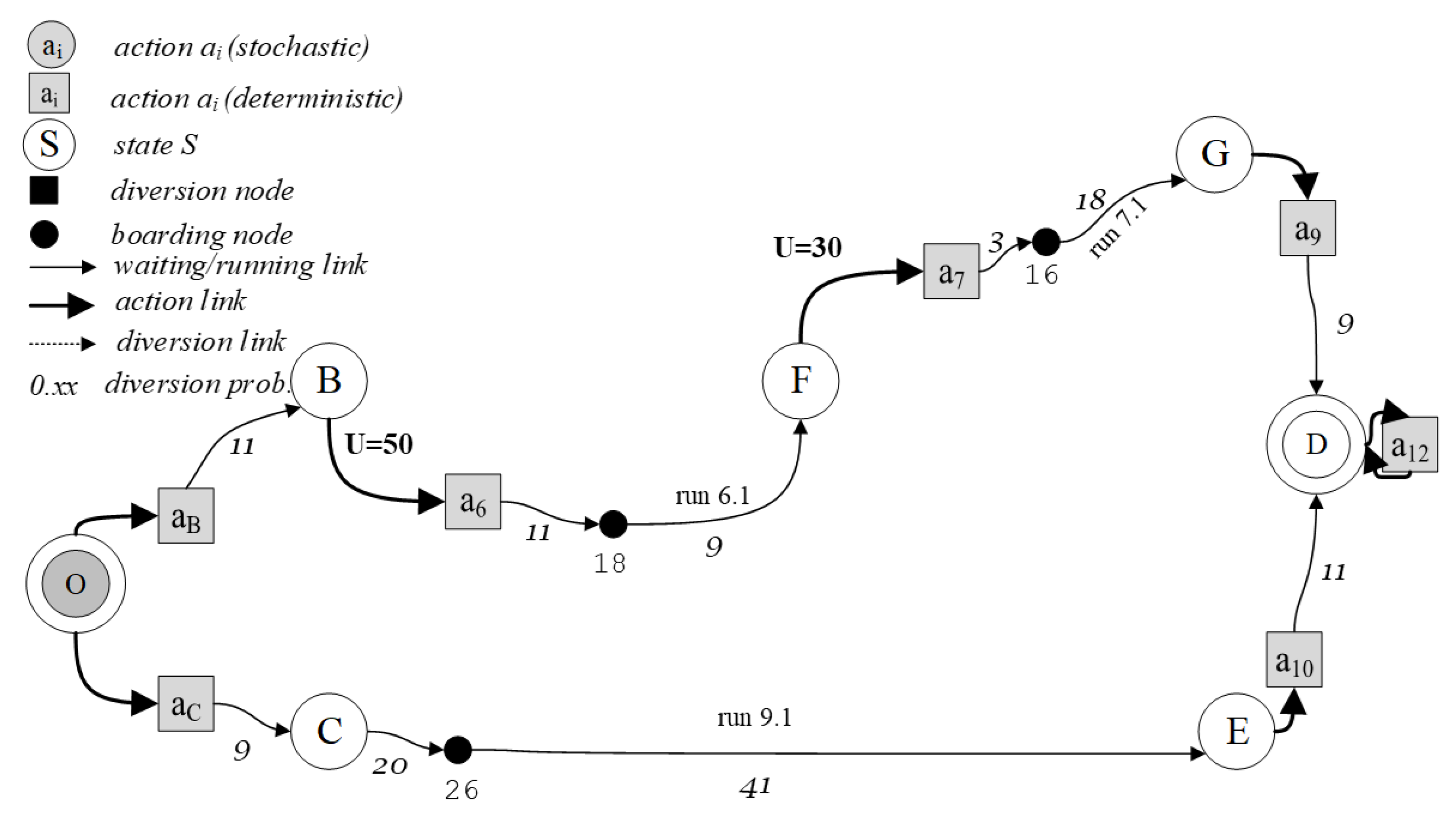
2.1. State–Action Tree Representation of a Decision Process (DP)
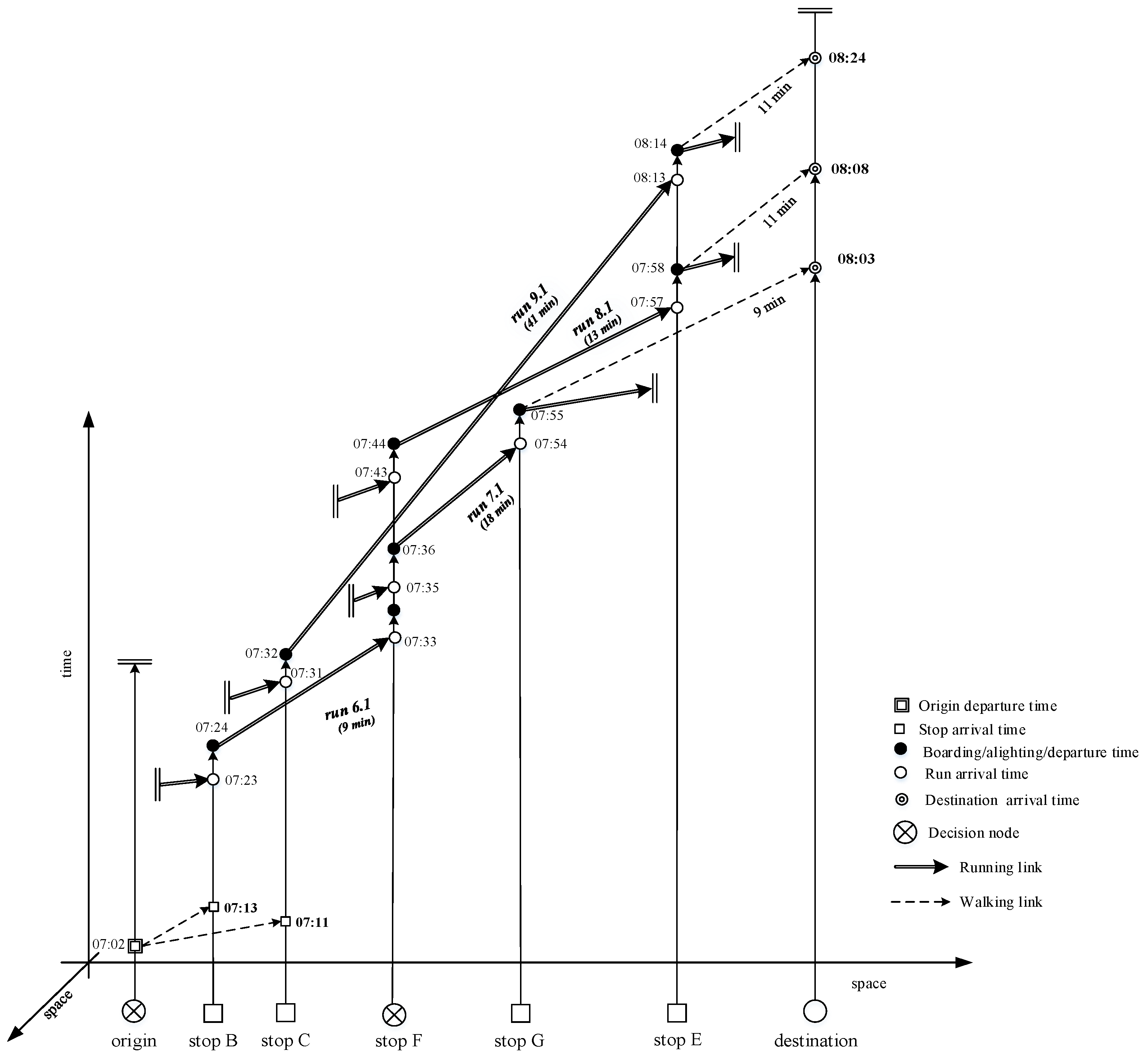
- (B, a6); (F, a7); (G, a9); (D, a12);
- (B, a6); (F, a8); (E, a10); (D, a12);
- (B, a6); (F, a7+8); (G, a9); (E, a10); (D, a12).
2.2. Line-Based Transition Probabilities
2.3. Transition Probability Determination in the Line-Based Approach
3. Optimal Travel Strategy Search in a Run-Based Approach
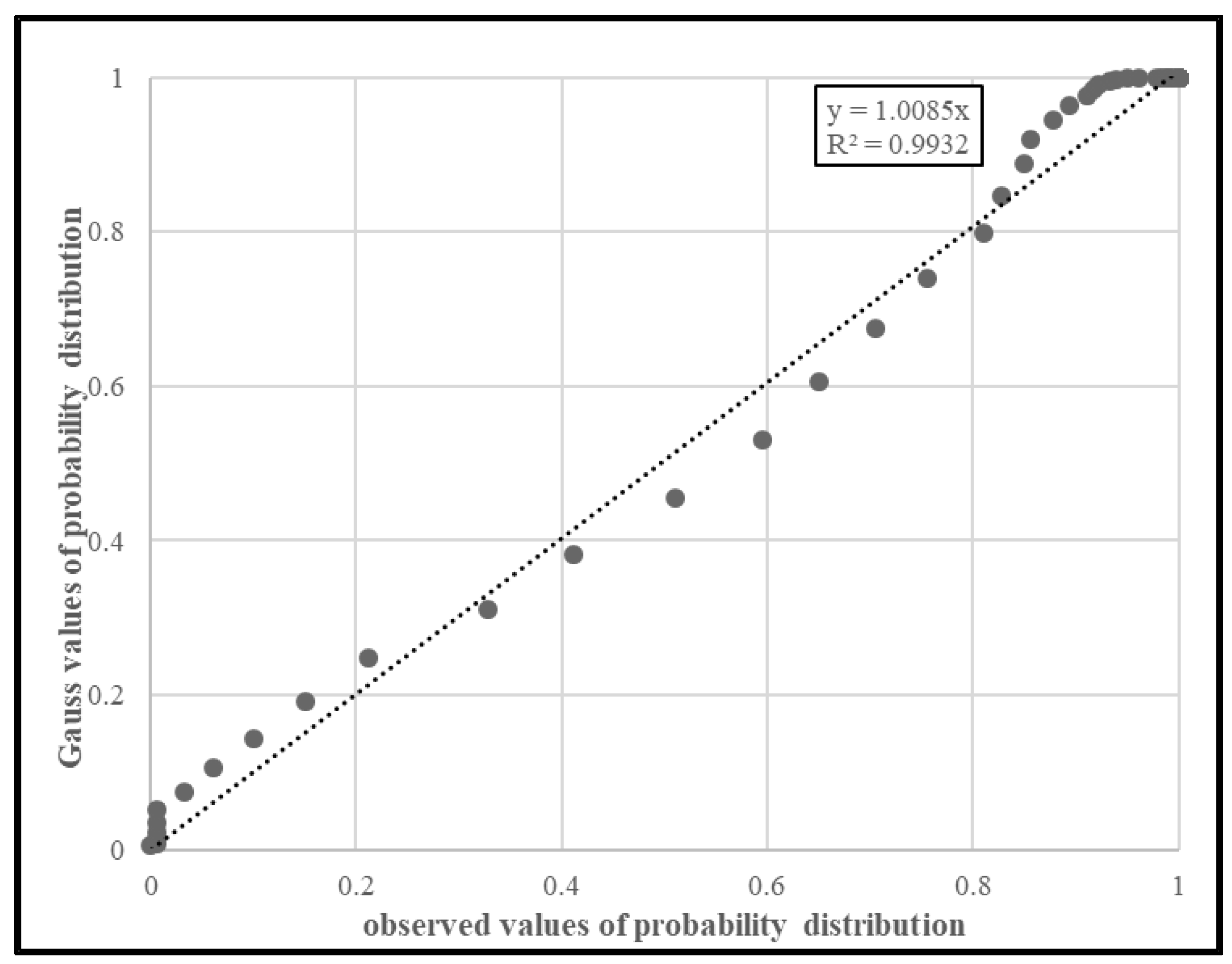
4. Analysis of the Forecasting Error of Bus At-Stop Arrival Times
- is the standard deviation (in seconds) of random forecasting error ε;
- FH is the forecasting horizon (in minutes).

5. The Proposed Run-Based Search Method of Dynamic Optimal Strategies
5.1. General Description of the Method
- the traveller state space includes only decision nodes;
- when the traveller moves on the next decision node, a new optimal strategy is searched, considering the new forecasts of at-stop bus arrival time (FATS) and at-destination arrival times (FATD) available in real time. Therefore, each new optimal strategy is conditional upon the forecasts available at the current decision node;
- the bus state space is not considered, as better analysed in the following part of the paper, and hence the transition probabilities concern only transitions of the traveller between decision nodes;
- as an expected reward, the forecasted travel time (or, in general, the forecasted travel disutility) is used. Thus the optimal policy determines the combination of actions with minimum forecasted travel time up to destination. Therefore forecasting methods have to be used with expected value of FAT:E[FAT] = AT;
- considering the analysis results reported in Section 4, the forecasted arrival times FSxATSx at stop Sy forecasted when the traveler is at stop Sx can be expressed as follows:where is the true value of the arrival time at Sy and εSy is the forecasting error vector with known MVN probability density functions;
- all the buses are assumed to have unlimited capacity.
5.2. Run-Based Transition Probabilities
- be the true value of the arrival time at destination D using run ;
- be the arrival time at destination D using , forecasted at JY:where is the forecasting error;
- be the arrival time at destination D using run , forecasted at origin O:where is the forecasting error.
- is the probability of boarding run at node I for reaching stop JY;
- is the arrival time at node JY using run at stop I forecasted at origin O;
- is the arrival time at node JY using run at stop I forecasted at origin O;
- are the forecasted errors.
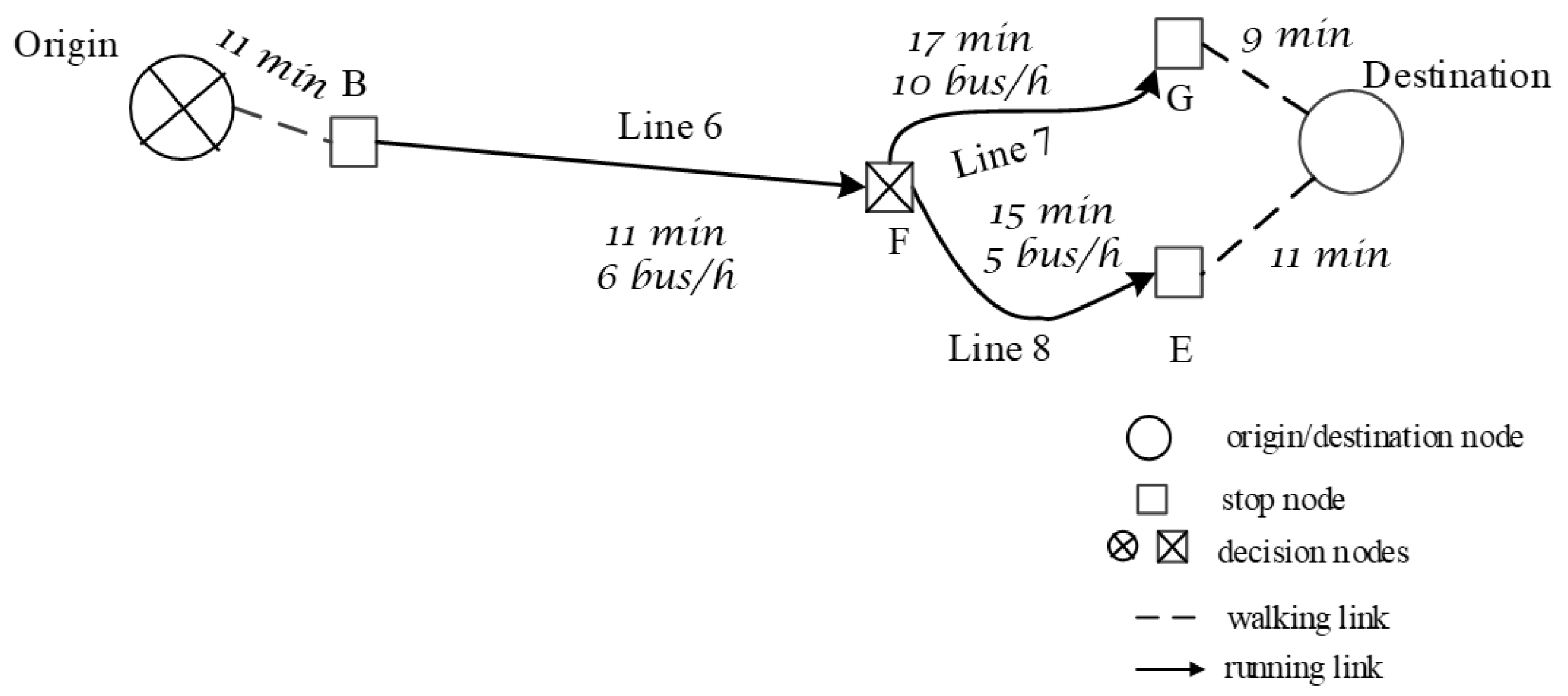
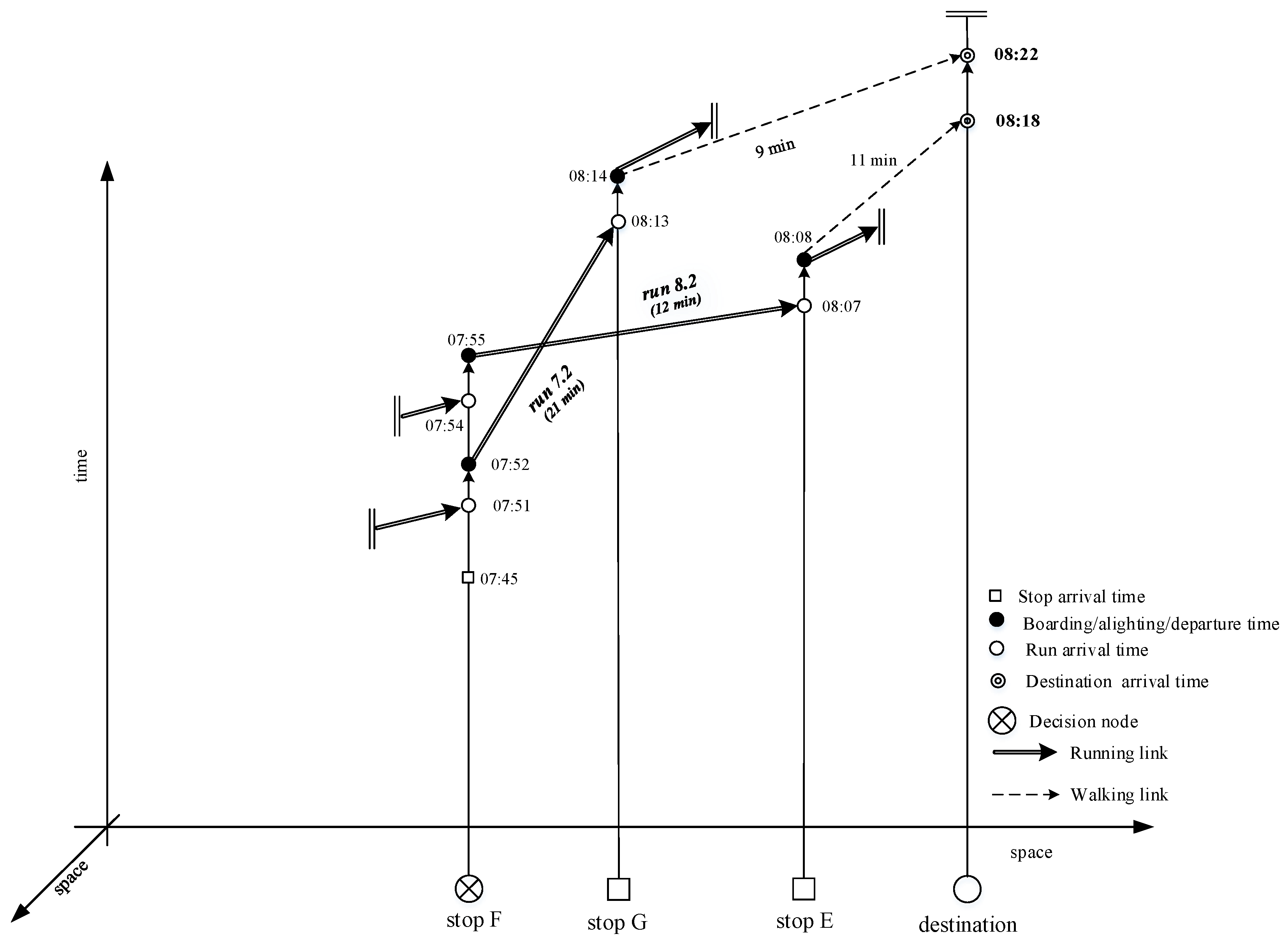
6. An Example of Dynamic Strategy Search Applying the Proposed Method
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gentile, G.; Nguyen, S.; Pallottino, S. Route choice on transit networks with online information at stops. Transp. Sci. 2005, 39, 289–297. [Google Scholar] [CrossRef] [Green Version]
- Fonzone, A.; Schmöcker, J.-D. Effects of transit real-time information usage strategies. Transp. Res. Rec. 2014, 2417, 121–129. [Google Scholar] [CrossRef]
- Paulsen, M.; Rasmussen, T.K.; Nielsen, O.A. Impacts of real-time information levels in public transport: A large-scale case study using an adaptive passenger path choice model. Transp. Res. Part A Policy Pract. 2021, 148, 155–182. [Google Scholar] [CrossRef]
- Xiong, C.; Shahabi, M.; Zhao, J.; Yin, Y.; Zhou, X.; Zhang, L. An integrated and personalized traveler information and incentive scheme for energy efficient mobility systems. Transp. Res. Part C Emerg. Technol. 2020, 113, 57–73. [Google Scholar] [CrossRef]
- Hickman, M.D.; Wilson, N.H. Passenger travel time and path choice implications of real-time transit information. Transp. Res. Part C 1995, 3, 211–226. [Google Scholar] [CrossRef]
- Wahba, M.M. MILATRAS: MIcrosimulation Learning-Based Approach to TRansit ASsignment. Ph.D. Thesis, Department of Civil Engineering, University of Toronto, Toronto, ON, Canada, 2008. [Google Scholar]
- Comi, A.; Nuzzolo, A.; Crisalli, U.; Rosati, L. A New Generation of Individual Real-time Transit Information Systems. In Modelling Intelligent Multi-Modal Transit Systems; Nuzzolo, A., Lam, W.H.K., Eds.; CRC Press: Boca Raton, FL, USA, 2017; Chapter 3; pp. 80–107. [Google Scholar]
- Nuzzolo, A.; Crisalli, U.; Comi, A.; Rosati, L. A mesoscopic transit assignment model including real-time predictive information on crowding. J. Intell. Transp. Syst. 2016, 20, 316–333. [Google Scholar] [CrossRef]
- Cats, O.; Jenelius, E. Dynamic Vulnerability Analysis of Public Transport Networks: Mitigation Effects of Real-Time Information. Netw. Spatial. Econ. 2014, 14, 435–463. [Google Scholar] [CrossRef]
- Cats, O.; Koutsopoulos, H.N.; Burghout, W.; Toledo, T. Effect of Real-Time Transit Information on Dynamic Path Choice of Passengers. Transp. Res. Rec. J. Transp. Res. Board 2011, 2217, 46–54. [Google Scholar] [CrossRef] [Green Version]
- Estrada, M.; Giesen, R.; Mauttone, A.; Nacelle, E.; Segura, L. Experimental evaluation of real-time information services in transit systems from the perspective of users. In Proceedings of the Conference on Advanced Systems in Public Transport (CAPST), Rotterdam, The Netherlands, 19–23 July 2015; pp. 1–20. [Google Scholar]
- Leng, N.; Corman, F. The role of information availability to passengers in public transport disruptions: An agent-based simulation approach. Transp. Res. Part A 2020, 133, 214–236. [Google Scholar] [CrossRef]
- Ceder, A.; Jiang, Y. Route guidance ranking procedures with human perception consideration for personalized public transport service. Transp. Res. Part C Emerg. Technol. 2020, 118, 102667. [Google Scholar] [CrossRef]
- Jenelius, E. Personalized predictive public transport crowding information with automated data sources. Transp. Res. Part C Emerg. Technol. 2020, 117, 102647. [Google Scholar] [CrossRef]
- Jiang, Y.; Ceder, A. Incorporating personalization and bounded rationality into stochastic transit assignment model. Transp. Res. Part C Emerg. Technol. 2021, 127, 103127. [Google Scholar] [CrossRef]
- Rambha, T.; Boyles, S.D.; Waller, S.T. Adaptive transit routing in stochastic time-dependent networks. Transp. Sci. 2016, 50, 1043–1059. [Google Scholar] [CrossRef] [Green Version]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 414. [Google Scholar]
- Bellman, R. A markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Gentile, G.; Florian, M.; Hamdouch, Y.; Cats, O.; Nuzzolo, A. The Theory of Transit Assignment: Basic Modelling Frameworks; Springer Tracts on Transportation and Traffic: Cham, Switzerland, 2016; pp. 287–386. [Google Scholar]
- Nielsen, O.A. A Large Scale Stochastic Multi-Class Schedule-Based Transit Model with Random Coefficients: Implementation and algorithms; Operations Research/Computer Science Interfaces Series; Springer: Boston, MA, USA, 2004; Volume 28, pp. 53–77. [Google Scholar]
- Nuzzolo, A.; Comi, A. Advanced Public Transport and Intelligent Transport Systems: New Modelling Challenges. Transp. A Transp. Sci. 2016, 12, 674–699. [Google Scholar] [CrossRef]
- Nuzzolo, A.; Crisalli, U.; Rosati, L. A schedule-based assignment model with explicit capacity constraints for congested transit networks. Transp. Res. Part C Emerg. Technol. 2012, 20, 16–33. [Google Scholar] [CrossRef]
- Nuzzolo, A.; Russo, F.; Crisalli, U. A doubly dynamic schedule-based assignment model for transit networks. Transp. Sci. 2001, 35, 268–285. [Google Scholar] [CrossRef]
- Xie, J.; Zhan, S.; Wong, S.C.; Lo, S.M. A schedule-based timetable model for congested transit networks. Transp. Res. Part C Emerg. Technol. 2021, 124, 102925. [Google Scholar] [CrossRef]
- Chriqui, C.; Robillard, P. Common bus lines. Transp. Sci. 1975, 9, 115–121. [Google Scholar] [CrossRef]
- Von Neumann, J.; Morgenstern, O. Theory of games and economic behavior; Princeton University Press: Princeton, NJ, USA, 1947. [Google Scholar]
- Spiess, H. On Optimal Route Choice Strategies in Transit Networks. Montreal: Centre de Recherche sur les Transports; Université de Montréal: Montréal, QC, Canada, 1983. [Google Scholar]
- Spiess, H.; Florian, M. Optimal strategies. A new assignment model for transit networks. Transp. Research. Part B Methodol. 1989, 23, 83–102. [Google Scholar] [CrossRef]
- Nguyen, S.; Pallottino, S. Equilibrium traffic assignment for large scale transit networks. Eur. J. Oper. Res. 1988, 37, 176–186. [Google Scholar] [CrossRef]
- SISTeMA. Hyperpath. Retrieved 6 September 2018. Available online: http://www.hyperpath.com/ (accessed on 13 July 2021).
- Gentile, G. Time-dependent Shortest Hyperpaths for Dynamic Routing on Transit Networks. In Modelling Intelligent Multi-Modal Transit Systems; Nuzzolo, A., Lam, W.H.K., Eds.; CRC Press: Boca Raton, FL, USA; Taylor & Francis Group: Boca Raton, FL, USA, 2017. [Google Scholar]
- Gentile, G.; Noekel, K. Modelling Public Transport Passenger Flows in the Era of Intelligent Transport Systems: COST Action TU1004 (TransITS); Springer Tracts on Transportation and Traffic: Cham, Switzerland, 2016. [Google Scholar]
- Bérczi, K.; Jüttner, A.; Laumanns, M.; Szabó, J. Stochastic Route Planning in Public Transport. Transp. Res. Procedia 2017, 27, 1080–1087. [Google Scholar] [CrossRef]
- Comi, A.; Nuzzolo, A.; Brinchi, S.; Verghini, R. Bus travel time variability: Some experimental evidences. Transp. Res. Procedia 2017, 27, 101–108. [Google Scholar] [CrossRef]
- Comi, A.; Polimeni, A. Bus Travel Time: Experimental Evidence and Forecasting. Forecasting 2020, 2, 309–322. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Mendes-Moreira, J.; de Sousa, J.F.; Gama, J. Improving Mass Transit Operations by Using AVL-Based Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1636–1653. [Google Scholar] [CrossRef]
- Cleveland, R.B.; Cleveland, W.S.; Terpenning, I. STL: A seasonal-trend decomposition procedure based on loess. J. Stat. 1990, 6, 3–73. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: http://www.R-project.org/ (accessed on 15 June 2021).
- Bai, C.; Peng, Z.R.; Lu, Q.C.; Sun, J. Dynamic bus travel time prediction models on road with multiple bus routes. Comput. Intell. Neurosci. 2015, 2015, 63. [Google Scholar] [CrossRef] [Green Version]
- Coffey, C.; Pozdnoukhov a Calabrese, F. Time of arrival predictability horizons for public bus routes. In Proceedings of the 4th ACM SIGSPATIAL International Workshop on Computational Transportation Science, Chicago, IL, USA, 1 November 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Rahman, M.M.; Wirasinghe, S.C.; Kattan, L. Analysis of bus travel time distributions for varying horizons and real-time applications. Transp. Res. Part C 2018, 86, 453–466. [Google Scholar] [CrossRef]
- Taghipour, H.; Parsa, A.B.; Mohammadian, A. A dynamic approach to predict travel time in real time using data driven techniques and comprehensive data sources. Transp. Eng. 2020, 22, 100025. [Google Scholar] [CrossRef]
- Xu, H.; Xu, H.; Ying, J. Bus arrival time prediction with real-time and historic data. Clust. Comput. 2017, 20, 3099–3106. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A | set of actions ai |
| As,t | the set of possible actions a that can be taken at state s at time t |
| ATDRi | the true value of arrival time at destination D by run Ri |
| JRi | the error of arrival time forecast computed at downstream node J with variance using run Ri |
| IRi | the error of arrival time forecast computed at upstream node I with variance using run Ri |
| φi | frequency of line i |
| FFATDRi | arrival time at destination (D), forecasted in F, using run Ri |
| Σ | dispersion matrix of dimension equal to the number of runs n available at stop Sy |
| f(ε) | density probability of forecast error vector ε |
| FH | forecasting horizon |
| FTT | bus travel time forecast |
| p[SJYY/JY] | transition probability of moving from node JY to SJYY |
| MSTN | multiservice transit network |
| MVN (AT, Σ) | multivariate normal random variable with mean vector AT and dispersion matrix Σ |
| p[RJYY/JY] | probability of using run RJYY from node JY |
| raj[si, si−1] | reward function of state si conditional upon the previous state si−1 |
| Ri | generic run |
| SMSTN | stochastic multiservice transit network |
| SN | stochastic network |
| Si | last alighting stop |
| B | F | G | E | D | |
|---|---|---|---|---|---|
| O [aB] | 1 | 1 | p[G/O] = p[G/F] | p[E/O] = p[E/F] | 1 |
| B [a6] | 0 | 1 | p[G/B] = p[G/F] | p[E/B] = p[E/F] | 1 |
| F [a7+8] | 0 | 0 | p[G/F] | p[E/F] | 1 |
| G [a9] | 0 | 0 | 0 | 0 | 1 |
| E [a10] | 0 | 0 | 0 | 0 | 1 |
| D [a12] | 0 | 0 | 0 | 0 | 1 |
| Random Residual | Forecasted Arrival Time at Destination | When Choice Is Made | Forecasting Horizon [minutes] | Estimated Standard Deviation [seconds] | Estimated Variance [minutes2] |
|---|---|---|---|---|---|
| 08:08 | 07:02 | 66 | 402.60 | 45 | |
| 08:03 | 07:02 | 61 | 372.10 | 38 | |
| 08:08 | 07:35 | 33 | 201.30 | 11 | |
| 08:03 | 07:35 | 28 | 170.80 | 8 | |
| TOTAL | 103 (10.142) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nuzzolo, A.; Comi, A. Dynamic Optimal Travel Strategies in Intelligent Stochastic Transit Networks. Information 2021, 12, 281. https://doi.org/10.3390/info12070281
Nuzzolo A, Comi A. Dynamic Optimal Travel Strategies in Intelligent Stochastic Transit Networks. Information. 2021; 12(7):281. https://doi.org/10.3390/info12070281
Chicago/Turabian StyleNuzzolo, Agostino, and Antonio Comi. 2021. "Dynamic Optimal Travel Strategies in Intelligent Stochastic Transit Networks" Information 12, no. 7: 281. https://doi.org/10.3390/info12070281
APA StyleNuzzolo, A., & Comi, A. (2021). Dynamic Optimal Travel Strategies in Intelligent Stochastic Transit Networks. Information, 12(7), 281. https://doi.org/10.3390/info12070281