
Populating Web-Scale Knowledge Graphs Using Distantly Supervised Relation Extraction and Validation


Abstract
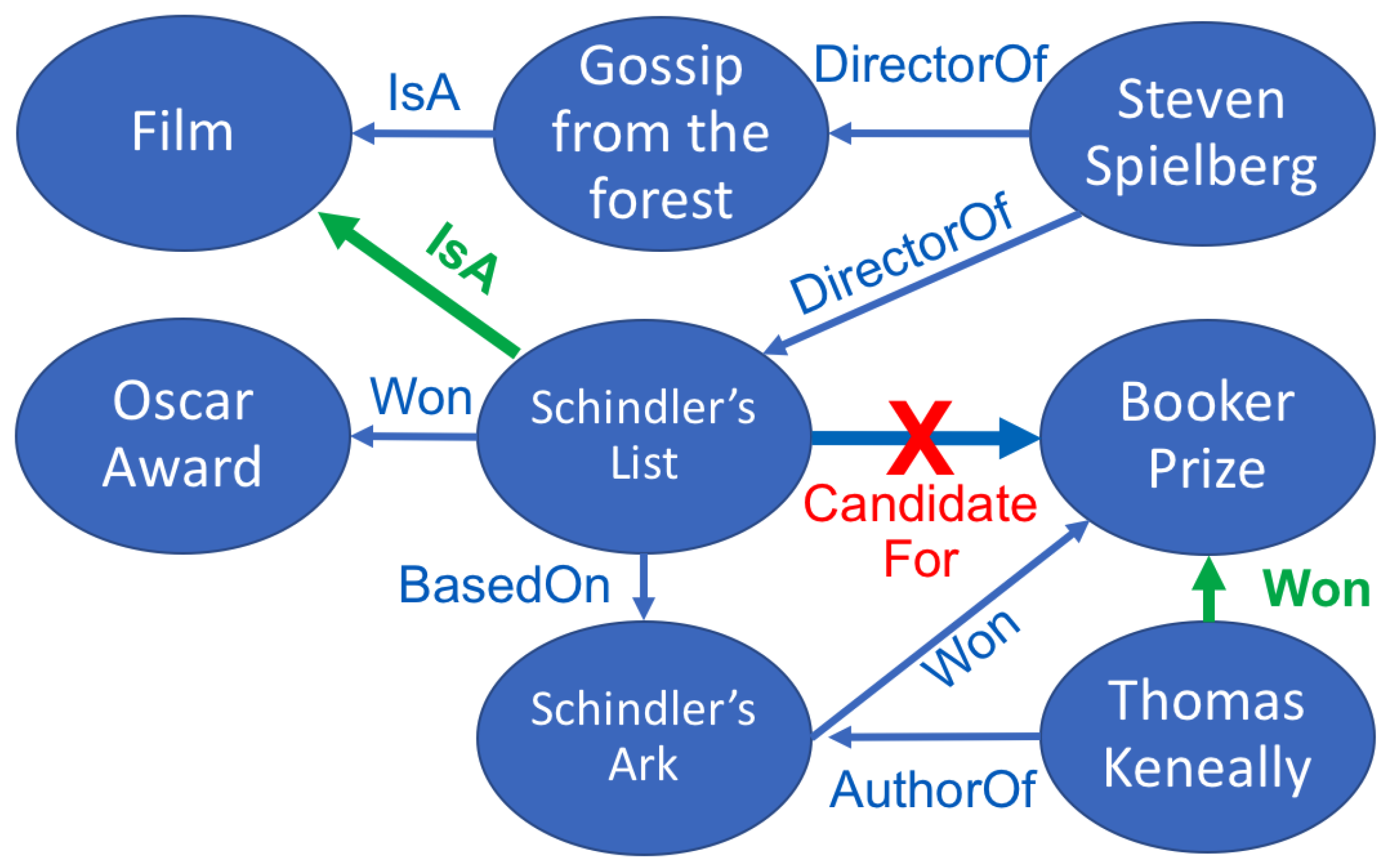
:1. Introduction
2. Related Work
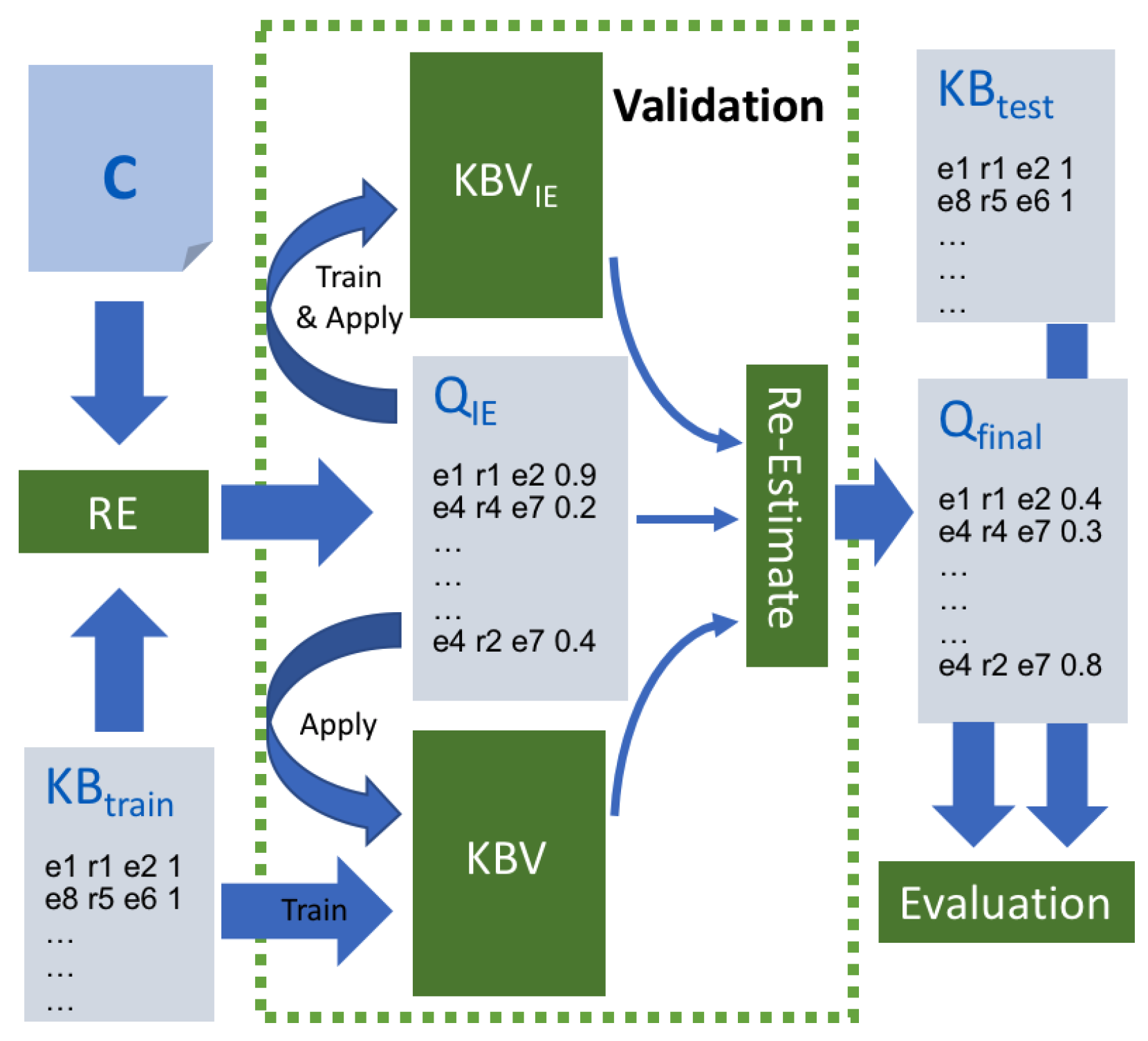
3. Distantly Supervised Relation Extraction and Validation
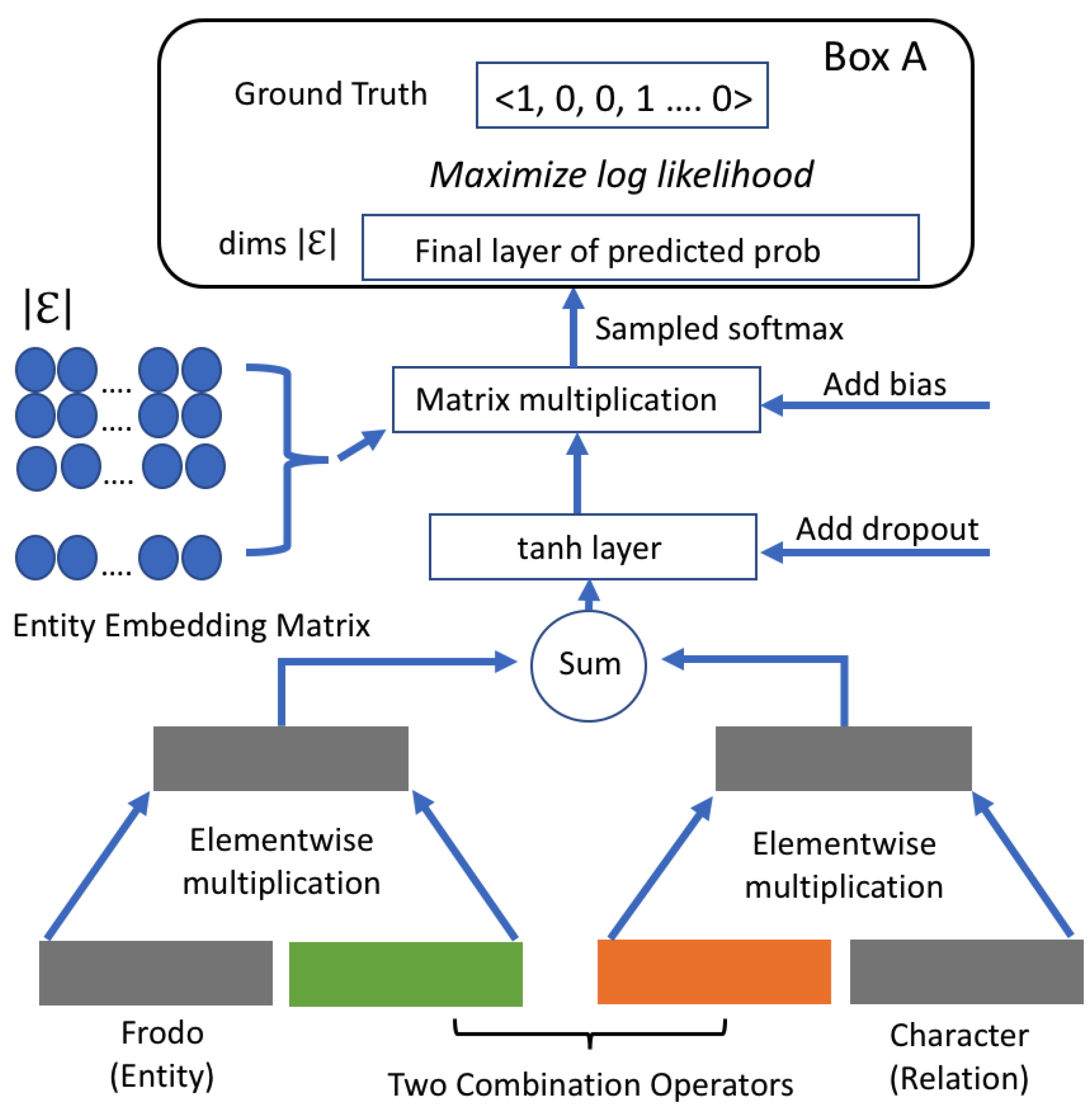
3.1. Relation Extraction
3.2. Relation Validation
3.3. Confidence Re-Estimation
4. Evaluation
4.1. Benchmarks
- NYT-FB:
- Extending Freebase with New York Times articles is a standard benchmark for distantly supervised RE, developed by [23] and used in many subsequent works [7,24,25]. The text of the New York Times was processed with the Stanford NER system and the identified entities linked by name to Freebase. The task is to predict the instances of 56 relations from the sentences mentioning two arguments. The state of the art for this dataset is the NRE’s (neural relation extraction) PCNN+ATT model (piecewise convolutional neural network with attention) [8].
- CC-DBP:
- Extending DBpedia with Web Crawls. This is a web-scale knowledge base population benchmark that was introduced by [26] and has been made publicly available.It combines the text of Common Crawl with the triples from 298 frequent relations in DBpedia [27]. Mentions of DBpedia entities are located in text by gazetteer matching of the preferred label. This task is similar to NYT-FB, but it has a much larger number of relations, triples, and textual contexts.
- NELL:
- Never-ending language learning (NELL) [11] is a system that starts from a few “seed instances” of each type and relation, which it then uses to extract candidate instances from a large web corpus, using the current facts in the knowledge base as training examples. The NELL research group released a snapshot of its accumulated knowledge at the 165th iteration, hereby referred to as NELL-165 consisting of a set of triples with associated confidence scores coming from different extractors. Later, [28] provided a manually validated set of triples divided into train and test.
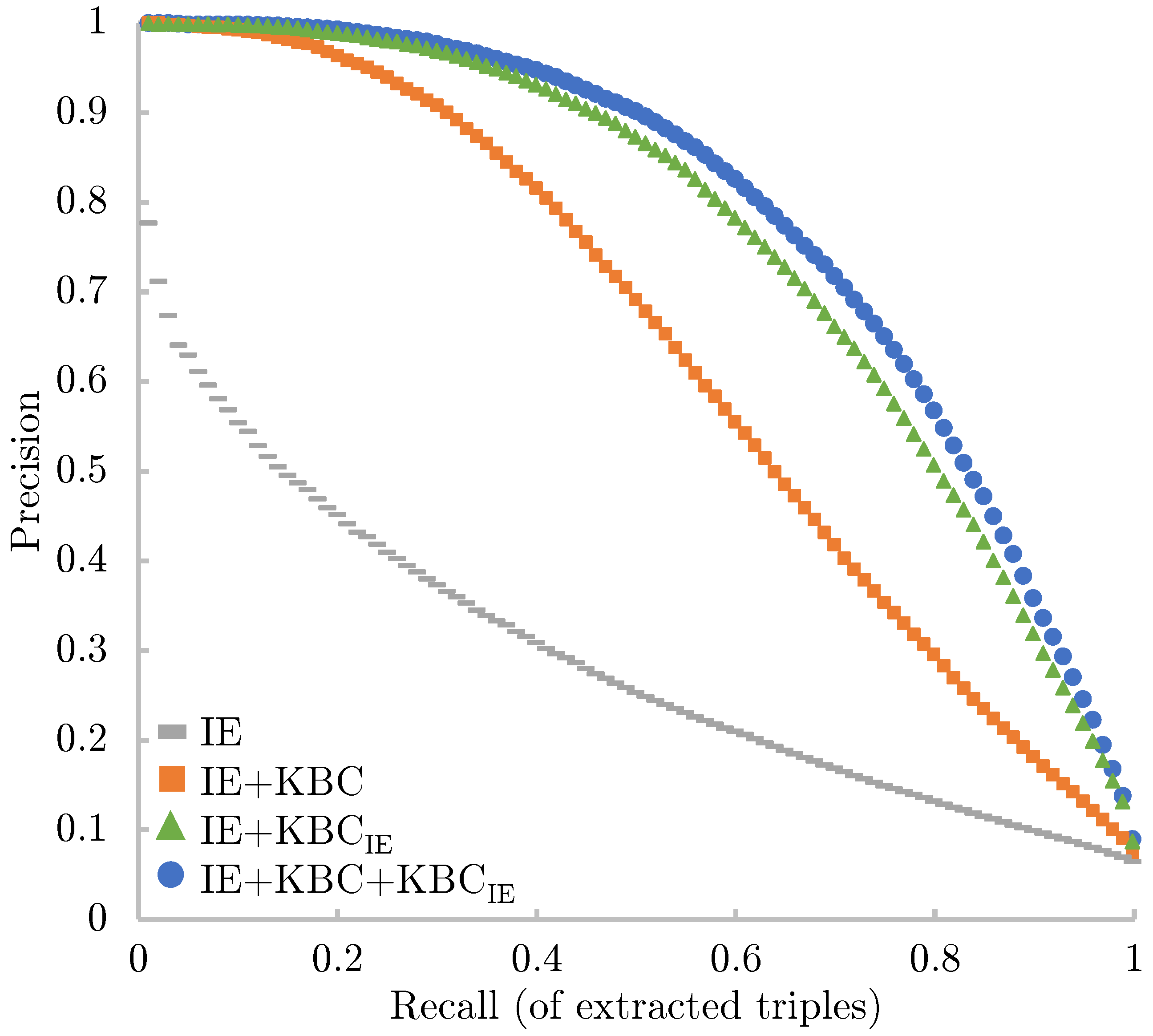
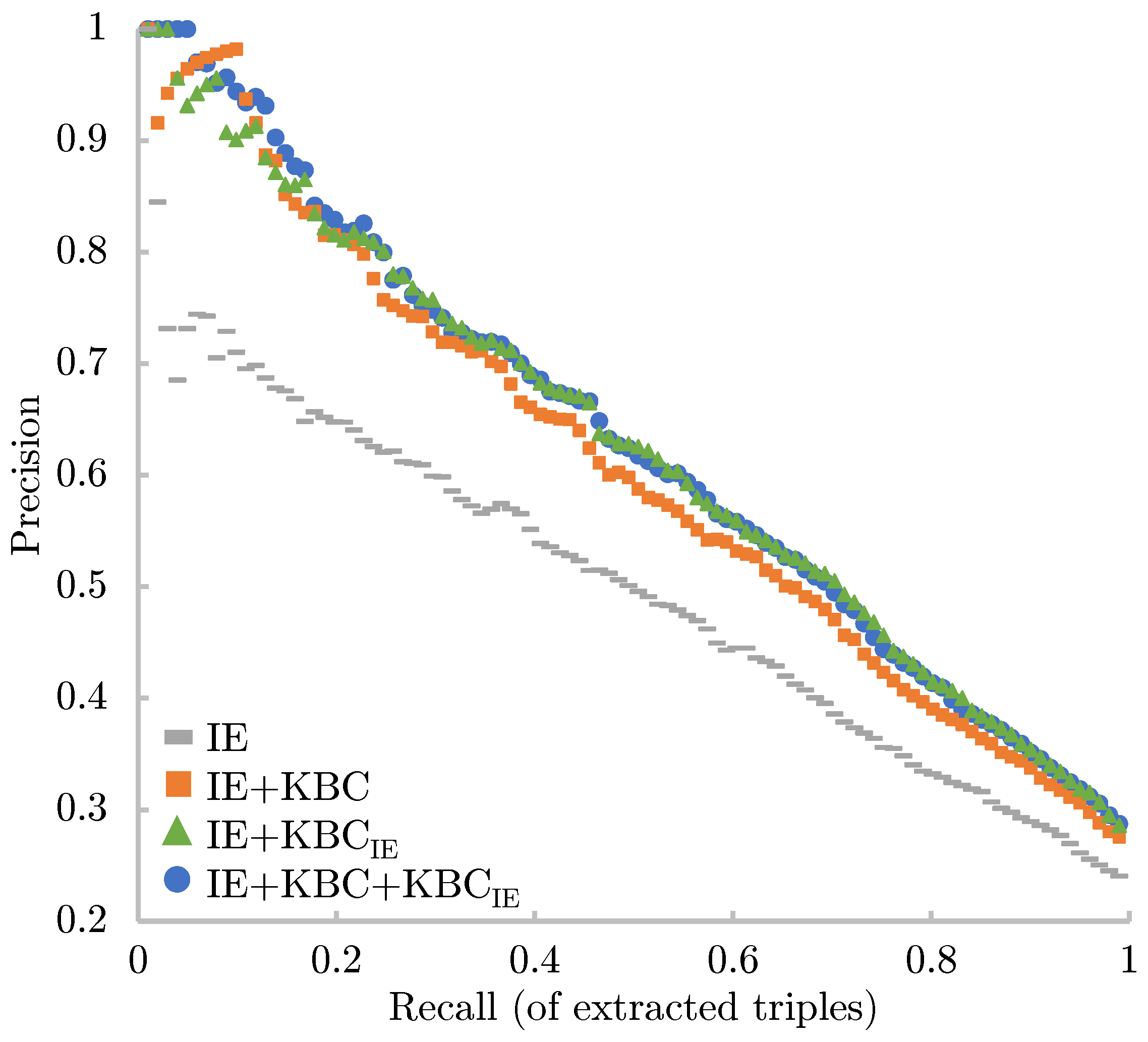
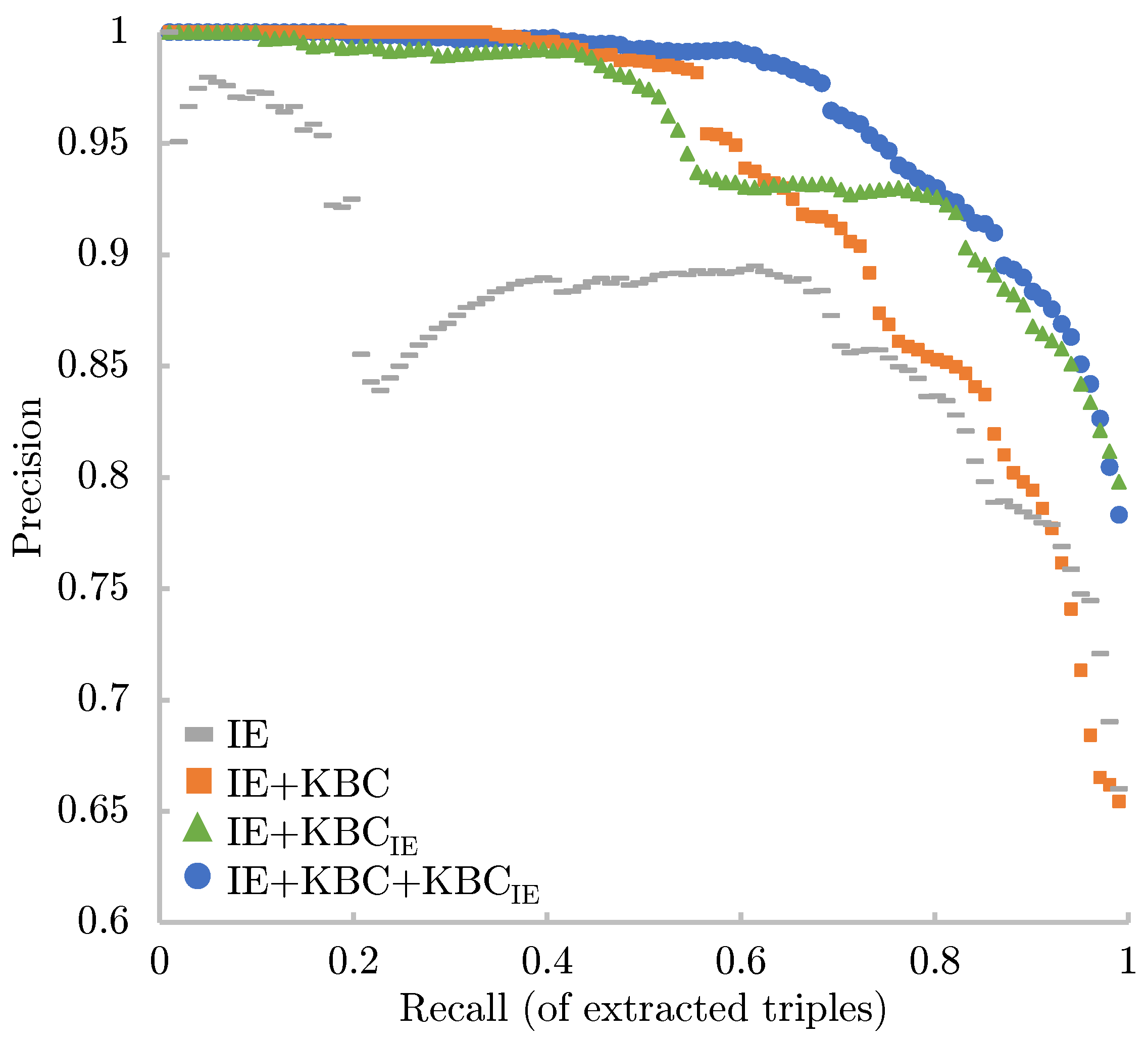
4.2. Results
4.3. Analysis
5. Conclusion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Niu, F.; Zhang, C.; Ré, C.; Shavlik, J.W. DeepDive: Web-scale Knowledge-base Construction using Statistical Learning and Inference. In Proceedings of the Second International Workshop on Searching and Integrating New Web Data Sources, Istanbul, Turkey, 31 August 2012; Brambilla, M., Ceri, S., Furche, T., Gottlob, G., Eds.; CEUR-WS.org: Istanbul, Turkey, 2012; Volume 884, pp. 25–28. [Google Scholar]
- Nakashole, N. Automatic Extraction of Facts, Relations, and Entities for Web-Scale Knowledge Base Population. Ph.D. Thesis, Saarland University, Saarbrücken, Germany, 2013. [Google Scholar]
- Glass, M.; Gliozzo, A.; Hassanzadeh, O.; Mihindukulasooriya, N.; Rossiello, G. Inducing Implicit Relations from Text using Distantly Supervised Deep Nets. In Proceedings of the International Semantic Web Conference, Monterey, CA, USA, 8–12 October 2018; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying relations via long short term memory networks along shortest dependency paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Zeng, W.; Lin, Y.; Liu, Z.; Sun, M. Incorporating Relation Paths in Neural Relation Extraction. arXiv 2016, arXiv:1609.07479. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the EMNLP, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural relation extraction with selective attention over instances. In Proceedings of the ACL, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A.; Marlin, B.M. Relation extraction with matrix factorization and universal schemas. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 74–84. [Google Scholar]
- Richardson, M.; Domingos, P. Markov Logic networks. Mach. Learn. 2006, 62, 107–136. [Google Scholar] [CrossRef] [Green Version]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R., Jr.; Mitchell, T.M. Toward an architecture for never-ending language learning. In Twenty-Fourth AAAI Conference on Artificial Intelligence; AAAI: Menlo Park, CA, USA, 2010; Volume 5, p. 3. [Google Scholar]
- Pujara, J.; Miao, H.; Getoor, L.; Cohen, W. Knowledge graph identification. In Proceedings of the International Semantic Web Conference, Sydney, Australia, 21–25 October 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 542–557. [Google Scholar]
- Gerber, D.; Esteves, D.; Lehmann, J.; Bühmann, L.; Usbeck, R.; Ngomo, A.C.N.; Speck, R. Defacto—temporal and multilingual deep fact validation. J. Web Semant. 2015, 35, 85–101. [Google Scholar] [CrossRef] [Green Version]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A Three-Way Model for Collective Learning on Multi-Relational Data. Available online: https://openreview.net/forum?id=H14QEiZ_WS (accessed on 6 August 2021).
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning with Neural Tensor Networks for Knowledge Base Completion. Available online: http://papers.nips.cc/paper/5028-reasoning-with-neural-tenten-sor-networks-for-knowledge-base-completion.pdf (accessed on 6 August 2021).
- Nickel, M.; Rosasco, L.; Poggio, T.A. Holographic Embeddings of Knowledge Graphs; AAAI: Menlo Park, CA, USA, 2016; pp. 1955–1961. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. arXiv 2017, arXiv:1707.01476. [Google Scholar]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. arXiv 2017, arXiv:1712.02121. [Google Scholar]
- Cai, L.; Wang, W.Y. KBGAN: Adversarial Learning for Knowledge Graph Embeddings. arXiv 2017, arXiv:1711.04071. [Google Scholar]
- Shi, B.; Weninger, T. ProjE: Embedding Projection for Knowledge Graph Completion; AAAI: Menlo Park, CA, USA, 2017; pp. 1236–1242. [Google Scholar]
- Gong, Y.; Jia, Y.; Leung, T.; Toshev, A.; Ioffe, S. Deep convolutional ranking for multilabel image annotation. arXiv 2013, arXiv:1312.4894. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2010; pp. 148–163. [Google Scholar]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 541–550. [Google Scholar]
- Surdeanu, M.; Tibshirani, J.; Nallapati, R.; Manning, C.D. Multi-instance Multi-label Learning for Relation Extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 455–465. [Google Scholar]
- Glass, M.; Gliozzo, A. A Dataset for Web-scale Knowledge Base Population. In Proceedings of the 15th Extended Semantic Web Conference, Heraklion, Greece, 3–7 June 2018. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In Proceedings of the 6th Int’l Semantic Web Conference, Busan, Korea, 11–15 November 2017; Springer: Berlin/Heidelberg, Germany, 2007; pp. 11–15. [Google Scholar]
- Jiang, S.; Lowd, D.; Dou, D. Learning to Refine an Automatically Extracted Knowledge Base Using Markov Logic. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 912–917. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NYT-FB | CC-DBP | NELL-165 | |
|---|---|---|---|
| 23,687 | 6,067,377 | 1,030,600 | |
| 15,417 | 381,046 | 2928 | |
| 17,122 | 545,887 | 820,003 | |
| 13 | 298 | 222 |
| Approach | NYT-FB | CC-DBP | NELL |
|---|---|---|---|
| 0.499 | 0.294 | 0.872 | |
| 0.609 | 0.636 | 0.931 | |
| 0.629 | 0.760 | 0.951 | |
| 0.630 | 0.785 | 0.966 |
| Relation Type | False Negative | False Positive |
|---|---|---|
| odp:coparticipatesWith | 2447 | 575 |
| odp:hasLocation | 1834 | 109 |
| odp:sameSettingAs | 1248 | 315 |
| dbo:country | 354 | 260 |
| odp:isMemberOf | 373 | 233 |
| dbo:starring | 472 | 122 |
| dbo:birthPlace | 334 | 233 |
| dbo:location | 417 | 144 |
| odp:hasMember | 371 | 174 |
| dbo:artist | 353 | 186 |
| Relation Type | False Negative | False Positive |
|---|---|---|
| /location/location/contains | 242 | 201 |
| /people/person/place_lived | 168 | 13 |
| /people/person/nationality | 37 | 126 |
| /people/person/place_of_birth | 101 | 9 |
| /business/person/company | 27 | 69 |
| /people/deceased_person/place_of_death | 37 | 14 |
| /location/administrative_division/country | 31 | 17 |
| /location/country/administrative_divisions | 17 | 6 |
| /location/neighborhood/neighborhood_of | 11 | 10 |
| /location/country/capital | 12 | 1 |
| Relation Type | False Negative | False Positive |
|---|---|---|
| actorstarredinmovie | 136 | 3 |
| teamplaysincity | 39 | 97 |
| producesproduct | 86 | 0 |
| teamwontrophy | 60 | 20 |
| acquired | 72 | 2 |
| citycapitalofcountry | 56 | 8 |
| stadiumlocatedincity | 51 | 5 |
| teamhomestadium | 34 | 7 |
| Cat | 33 | 7 |
| teamplayssport | 13 | 11 |
| Min. Conn. | NYT-FB | CC-DBP | NELL-Cat |
|---|---|---|---|
| −0.001 | −0.002 | N/A | |
| 0.198 | 0.038 | 0.054 | |
| 0.265 | 0.210 | 0.049 | |
| 0.442 | 0.460 | 0.036 | |
| 0.377 | 0.634 | 0.084 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dash, S.; Glass, M.R.; Gliozzo, A.; Canim, M.; Rossiello, G. Populating Web-Scale Knowledge Graphs Using Distantly Supervised Relation Extraction and Validation. Information 2021, 12, 316. https://doi.org/10.3390/info12080316
Dash S, Glass MR, Gliozzo A, Canim M, Rossiello G. Populating Web-Scale Knowledge Graphs Using Distantly Supervised Relation Extraction and Validation. Information. 2021; 12(8):316. https://doi.org/10.3390/info12080316
Chicago/Turabian StyleDash, Sarthak, Michael R. Glass, Alfio Gliozzo, Mustafa Canim, and Gaetano Rossiello. 2021. "Populating Web-Scale Knowledge Graphs Using Distantly Supervised Relation Extraction and Validation" Information 12, no. 8: 316. https://doi.org/10.3390/info12080316
APA StyleDash, S., Glass, M. R., Gliozzo, A., Canim, M., & Rossiello, G. (2021). Populating Web-Scale Knowledge Graphs Using Distantly Supervised Relation Extraction and Validation. Information, 12(8), 316. https://doi.org/10.3390/info12080316