1. Introduction
Academic institutions invest relevant resources in collecting, organizing and preserving their intellectual output in institutional repositories. Among the digital artifacts hosted therein, publications are the most relevant and the standard organisation of their metadata is fundamental not only for evaluation and dissemination, but also for improving the search, given the quantity of research papers published every year. In addition to traditional search, harnessing metadata for modeling information in a semantic way is a new highly demanded requirement which cannot be met by traditional search engines. This feature is increasingly relevant in a context of global challenges for modern science, as the covid-19 pandemic clearly showed [
1,
2,
3].
Semantic technologies and Knowledge Graphs (KGs) can be helpful for these purposes, given the capability of KGs to capture the relational dimension of information and of its semantic properties. In fact, Scholarly Knowledge Graphs (SKGs) have been recently experimented by academic institutions. One of the most prominent examples is Wiser [
4], a search engine system developed by the University of Pisa, which is built upon an SKG composed of approximately 65,000 publications. Another well-known success case is the Open Academic Graph (
https://www.openacademic.ai/oag/ (accessed on 3 September 2021)), a publicly released SKG built by Microsoft and AMiner that supports the study of citation networks and publication contents.
Compared to traditional data sources (e.g., relational databases) for the storage and retrieval of publications, SKGs enable more advanced features [
5], such as recommendations based on the semantic properties of texts and of their metadata. This novel type of recommendation engine makes use of Graph Representation Learning (GRL) techniques, among which Graph Neural Networks (GNNs) have received particular attention [
6], as they are able to learn latent representations without any prior knowledge, other than the graph structure. However, their use for recommendation purposes is in a prototypal phase and still has to be properly investigated.
We contribute to this pioneering research field and we present Geranium, a semantic platform built on top of the Polito Knowledge Graph (PKG), a new SKG—built by us—that offers semantic search and recommendations of semantically affine publications and researchers at Politecnico di Torino. While the semantic search is provided with state-of-the-art Natural Language Processing (NLP) techniques in combination with the well-established DBpedia, the recommendations are enabled by a novel combination of KG embedding (KGE) techniques with GNN methods. In our contribution, we formally investigate and validate the performance of this combination in a real application scenario. In particular, our analysis focuses on the performance of the link prediction mechanism that is exploited to enable the recommendation features. The results show that the fusion of KGs and GNNs represents a promising approach to creating recommendations in the scholarly domain.
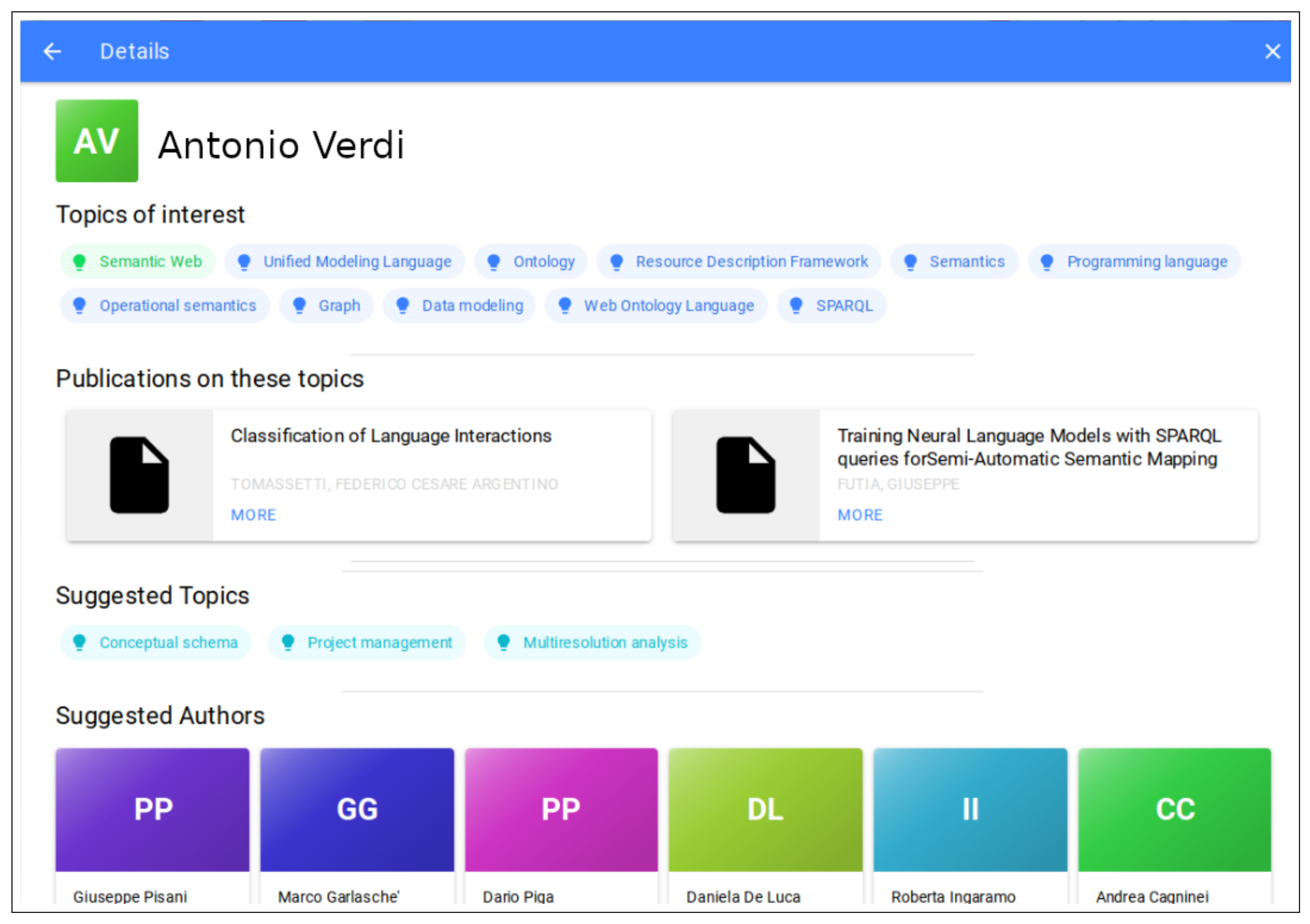
Through the Geranium platform, different stakeholders, such as researchers, policymakers, and enterprises, have available an interactive tool for exploring the activities and research results of the Politecnico while fostering new opportunities for collaboration with researchers. The PKG can be explored and visualized through a public web application or by querying an open SPARQL endpoint. The Geranium source code and datasets are openly available on GitHub (
https://github.com/geranium-project, accessed on 26 August 2021).
We detail the work as follows.
Section 2 gives a brief introduction to KGs and GNNs.
Section 3 presents the related work.
Section 4 introduces the building blocks of the Geranium platform.
Section 5 goes into the details of the provision of the PKG. In
Section 6 are presented the advanced services and tools built upon the PKG.
Section 7 explains the validation process of the link prediction algorithm employed for the recommendation task. In
Section 8, we discuss our conclusions, and the path for future work is outlined.
2. Background and Notation
Knowledge Graphs (KGs) have become effective tools for capturing and organizing a large amount of structured and multi-relational data that can be explored by employing query mechanisms. A KG can be formalized as follows:
, where
G is a labeled and directed multigraph and
are the set of entities, relations, and triples, respectively. In the semantic regime, a fact is formalized as a triple
, where
are two entities—the subject and the object of the fact, respectively—while
is the relation that connects
s and
o. In the Semantic Web field, the KG facts are modeled using the Resource Description Framework (RDF) [
7]. The RDF data model exploits web technologies, such as Uniform Resource Identifiers (URIs), to define entities and their relationships, and it provides a formal notion of meaning (semantics) that sets up the basis for founded deductions.
Knowledge Graph Embeddings (KGEs) are the result of specific representation learning models applied to KGs. The goal of KGE models is to embed the KG components—entities and relations—into a continuous and low-dimensional vector space. The latent factors projected into KGEs have an essential role in analyzing and mining additional
soft-knowledge in KGs. In fact, for each entity pair
and any relation
, it is possible to determine if a statement
is true according to the embeddings learned by the KGE techniques. The KGE approaches define a
scoring function for each KG statement
. In general, KGs comprise only true statements, while non-existing statements can be considered either missing or false. For these reasons, a closed-world assumption (the closed-world assumption (CWA) in the KG context means that lack of knowledge does imply falsity; in other words, missing facts in the KG are automatically considered false; the opposite perspective is the open-world assumption (OWA), according to which missing knowledge does not automatically imply falsity) is deemed to address this ambiguity in categorizing non-existing statements. As a consequence, the scoring function
returns a higher score for existing statements and a lower score otherwise. DistMult [
8] is one of the most common and simple factorization methods used as a scoring function. DistMult allows one to compute a statement score via the following transformation:
, in which
and
are the embeddings of the source and the destination node, and
is a relation-specific linear transformation.
KGE techniques encode the interactions between entities and relations through models that are not natively built for encoding the local graph structure. However, a novel family of neural architectures has been proposed to address this limitation. In this context, Graph Neural Networks (GNNs) are becoming the key framework for learning the latent representation of graph-structured data. GNNs are based on neural architectures that are designed by following a graph data topology, where the weighted connections of the neural network match the edges available in the graph structure. The most-adopted class of GNNs is known as Graph Convolutional Networks (GCNs).
The major novelty of GCNs is the use of self-learnt filters that aggregate the representation of adjacent nodes to obtain the embeddings and update them from one layer to the other: The embeddings obtained at the end of the network are the result of the node neighbors’ features that are accumulated through the previous layers. GCNs have proved to work well with graph data in which the neighbors’ characteristics are fundamental for a meaningful representation of nodes, such as in social graphs or molecular networks [
9]. In a GCN, the representation of nodes at each layer is updated via the following transformation:
, in which:
is the hidden representation of the nodes in the l-th layer;
is the hidden representation of the nodes in the -th layer;
includes all of the hidden representations of the neighbors of node i in the l-th layer;
is an aggregation function that establishes how to accumulate the representations of into the node i.
GCNs fall short when dealing with graph data where different relations are used to connect nodes, as in knowledge graphs. The Relational Graph Convolutional Network [
10] (R-GCN) is a new kind of GCN that is focused on modeling multi-relational graphs composed of labeled and directed edges, and it is thus particularly capable of embedding both the nodes and relations of a KG. In an R-GCN, different sets of parameters are learned for different relations. At each step inside the network, the feature vector of a node is updated by convolving its first neighbors’ features with a convolutional filter that is different based on the kind of relation that connects the nodes. The transformation used to update the representation of a node at the
l-th layer is the following:
, where:
is the hidden representation of the nodes in the l-th layer;
is the learned kernel for the self-loop relation;
is the set of indices of the neighbors of node i under the relation , with being the set of all of the relations present in the graph;
is the learned filter for the relation r;
is a non-linear activation function and is a normalization constant, commonly initialized to .
GNN models and KGE techniques can be incorporated into an end-to-end architecture. Such kinds of architectures are referred to as Graph Auto-Encoders (GAE). The GNN models play the role of the encoder, which produces an enriched representation of all entities within the KG, accumulating the neighborhood features; the KGE techniques play the role of the decoder, exploiting this enriched representation to reconstruct the edges within the KG. We introduce the GAE architecture used in this paper in
Section 5.2.
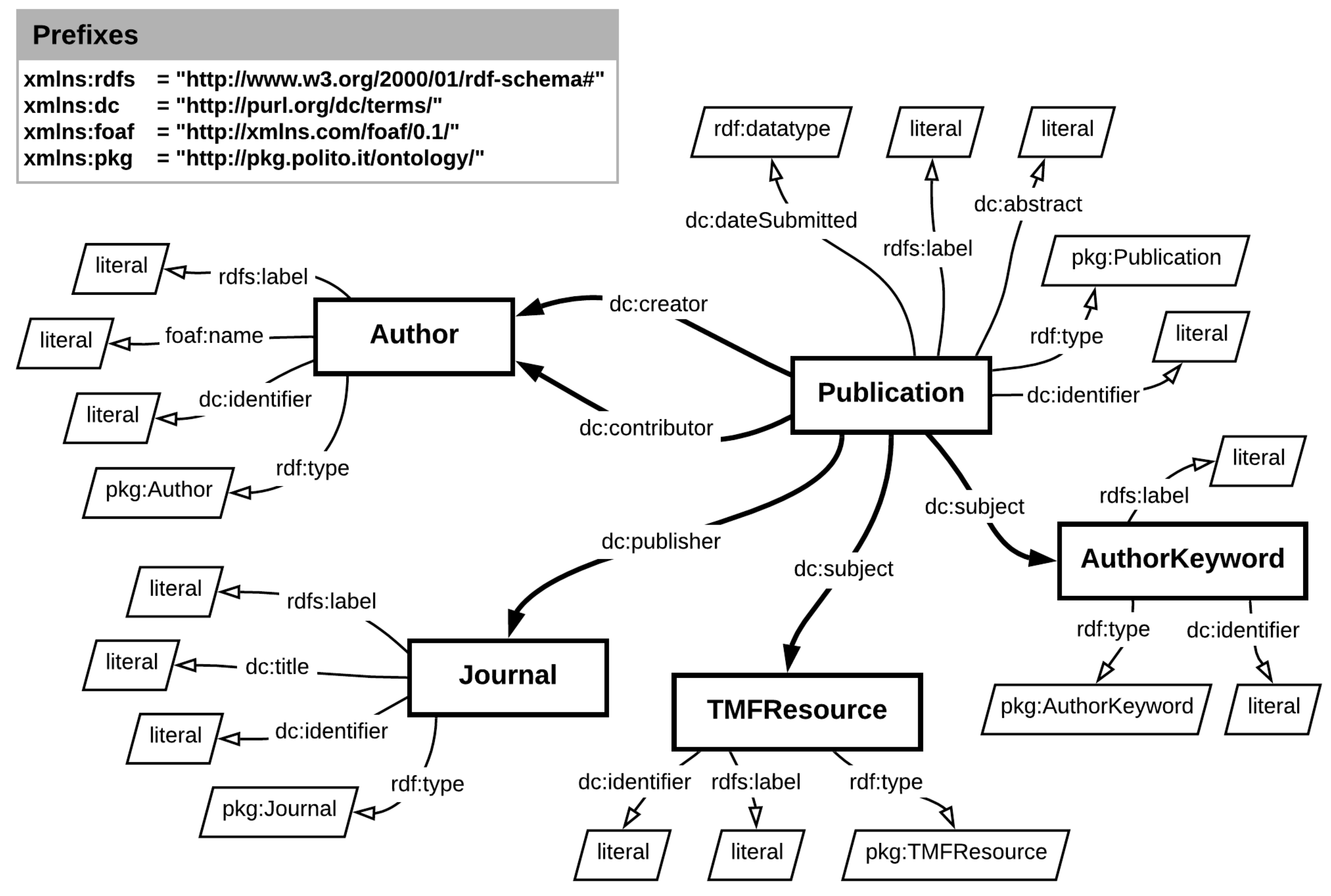
4. The Geranium Platform
The Geranium platform is based on specific components for ingesting, integrating, enriching, and publishing scholarly data, including information on publications, authors, and journals. The original data are mapped into RDF with respect to an ontology network in order to build the Polito Knowledge Graph (PKG). In the following subsections, we describe the main ingredients of the platform.
4.1. Data Providers
Two different data providers serve the content of the PKG. The main content is based on the information available from the Institutional Research Information System (IRIS) (
https://www.cineca.it/sistemi-informativi-universita/ricerca/iris-la-gestione-della-ricerca (accessed on 3 September 2021, available in italian)) instance available at Polito, which collects all metadata and contents of the publications released by the university’s researchers. This main content is enriched by means of a second data provider, the DBpedia repository, which is available as the RDF. Considering its encyclopedic and generalist vocation, DBpedia is particularly suitable for integrating publications coming from different scientific disciplines.
Currently, IRIS is the research repository that is the most frequently used by the Italian universities and research centers. The system was developed by the CINECA Consortium, which is made up of 69 Italian universities and 23 research institutions. Thus, IRIS represents the de-facto standard for archiving, managing, and publishing the research output in the Italian research landscape. At the time of writing, the Polito instance contains 108,077 publications (of which approximately 38% are available in open access), 8328 authors, 190,903 keywords, and 7581 journals. We have chosen IRIS as the primary data provider because of its wide adoption, thus allowing the Geranium platform to ingest new data sources from different research institutions other than Polito. Moreover, IRIS uses the DublinCore ontology and terms to describe its content, thus giving us a standard knowledge description about a publication and its metadata.
Here, we list the most useful IRIS publication metadata, which we selected as input data for the generation of the Geranium ontology:
- 1.
The title, abstract, date, and identifier: Information related to the publication, including an alphanumeric code that identifies a publication in the IRIS system and more traditional textual data related to the content of the publication and the publication date. Moreover, multiple keywords can be included by the authors in order to label the publication.
- 2.
The author’s name, surname, and identifier: If an author is part of the Polito staff, they are identified by an ID in the IRIS system, in addition to their name and surname. In the case of external authors, the identification code is not available.
- 3.
The co-authors’ names, surnames, and identifiers: IRIS allows one to distinguish the first author from the other contributors of the publication. As with the first author’s metadata, only the Polito staff has a unique identifier in the management system.
- 4.
The journal title and the ISSN: A specific conference venue or journal is connected to the publication. National and international conferences do not have a unique code associated with them, while in many cases, journals are identified by a unique ISSN code.
To overcome some of the limitations of IRIS, we used DBpedia, which represents structured information from Wikipedia. DBpedia is built and maintained by an open community; it provides a query service for its data and creates links to external datasets on the web. We took particular advantage of the latter characteristic: Using DBpedia, we were able to work with even more metadata than were made available by IRIS.
The DBpedia ontology is composed of 685 classes described by 2795 different properties, and currently, it contains about 4,233,000 instances. The most common classes by number of instances are:
- 1.
Person, with 1,450,000 instances;
- 2.
Place, with 735,000 instances;
- 3.
Work, with 411,000 instances;
- 4.
Species, with 251,000 instances;
- 5.
Organisation, with 241,000 instances.
4.4. Implementation Details and Code Availability
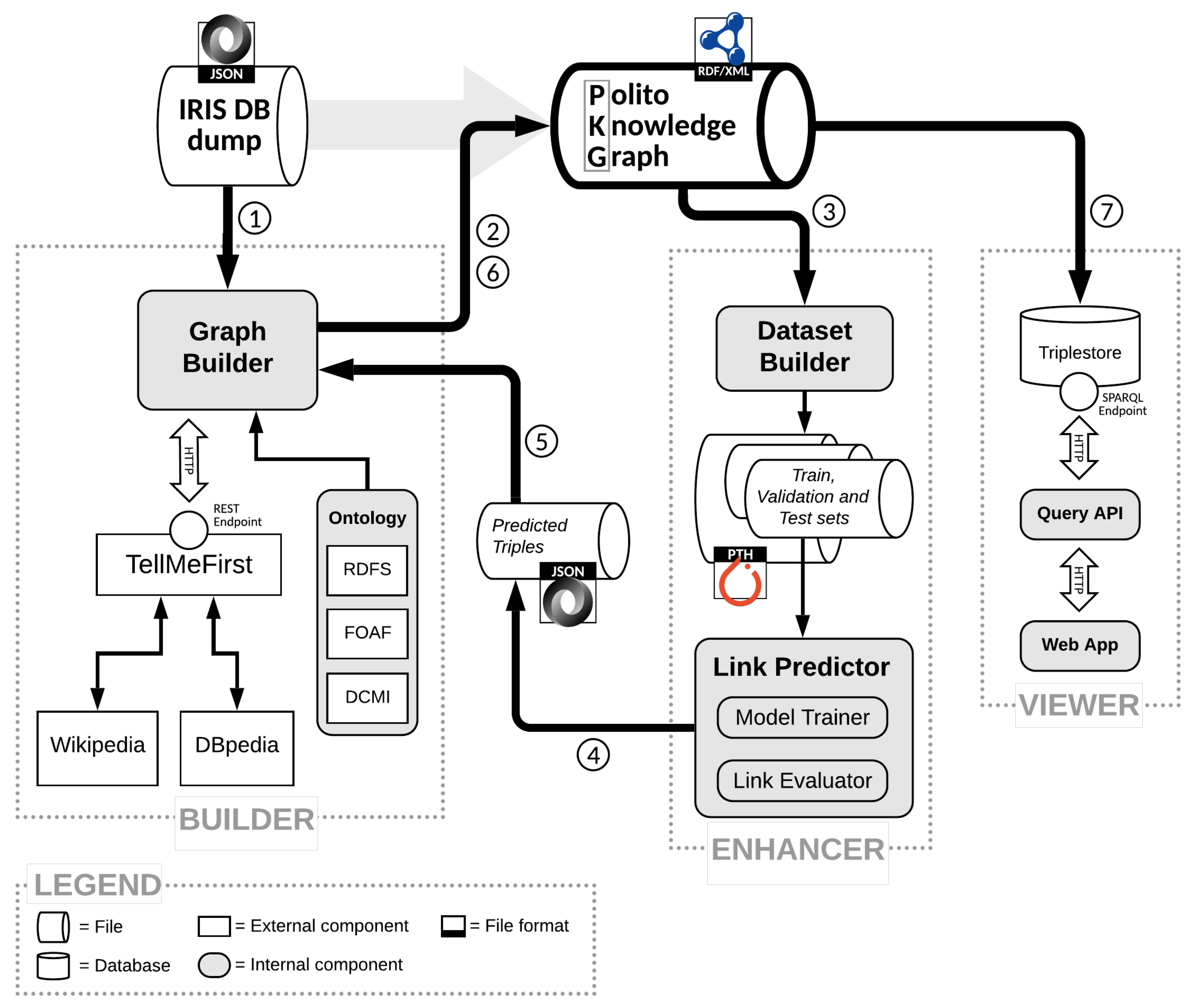
We implemented the architecture pipeline depicted in
Figure 2 using the following languages, frameworks, and technologies.
The Builder (see
Section 5.1) is implemented as a Python module using the
rdflib (
https://github.com/RDFLib/rdflib (accessed on 3 September 2021)) library to create and manage an in-memory RDF representation of the graph. The module takes as input the path to the JSON dump of IRIS, the ontology, and the JSON responses received by the TellMeFirst REST API in order to produce an RDF graph as output. The module supports some options that allow specific functionalities to be triggered, such as:
- 1.
The update of an already existing RDF graph with new statements that are used, for example, to add the predicted triples.
- 2.
The number of topics that must be extracted from each abstract by the TMF.
- 3.
In order to increase the performance of the KG generation process, the Builder implementation is based on a ThreadPoolExecutor and AsyncIO coroutines.
The Enhancer (see
Section 5.2) is composed if three submodules—the Dataset Builder, the Model Trainer, and the Link Evaluator. Like the Graph Builder, the Dataset Builder is also implemented as a Python module that processes the RDF graph triples with
rdflib. The Model Trainer is implemented using Pytorch and the Deep Graph Library (DGL) [
26], which implements the message-passing paradigm generalized for GNNs, allowing one to define the two basic operations for the construction of the per-edge messages and the per-node aggregation. The Encoder component of the Model Trainer is built upon an R-GCN [
10] composed of two hidden layers, with the first-layer convolutional filters being
, where
N is the number of nodes in the training graph, and the second-layer filters being
. The embeddings obtained as the output of the forward pass are shaped as
row vectors. For the input layer, one-hot encoded feature vectors are used, acting as a mask for the selection of the corresponding column in the per-relation convolutional filters. The per-node normalization constants are initialized to the inverse of the nodes’ indegree. The Link Evaluator is implemented as a Python module that loads the trained model (used as the Auto-Encoder) and computes the predictions, which are exported as JSON files and added to the graph by the Graph Builder.
Regarding the Viewer Module (see
Section 5.3), the API microservice was developed using Flask, a Python web micro-framework based on the WSGI transmission protocol. The API is publicly available through a reverse proxy that acts as a TLS termination endpoint and WSGI adaptation layer.
Each of the endpoints are based on the same workflow:
- 1.
checks the received query parameters;
- 2.
uses these parameters to build a, SPARQL query on the fly;
- 3.
sends a request to the correct SPARQL endpoint and waits for the response;
- 4.
returns the response (JSON) to the client that sent the request.
In the current version, the requests to the SPARQL endpoints are made by blockinq HTTP requests. We leave the implementation of asynchronous I/O for this task for future releases.
The triplestore of choice for Geranium is Blazegraph. The triplestore can be queried through Blazegraph’s built-in SPARQL endpoint, which we made publicly available using the same Apache2 reverse proxy used for the Geranium REST API.
The Geranium web frontend is implemented as a Progressive Web App (PWA) built upon the Angular and Ionic Framework that follows the Model–View–Controller pattern. We chose to implement the frontend as a PWA to create a responsive UI with a mobile-app-like user experience. In order to speed up the development process, we used the pre-built UI components made available by the Ionic Framework. We embedded in the application a reference to a self-hosted Matomo Analytics [
27] instance, which we used to gather fully anonymous statistics about the PWA usage.
The source code of all of the components of the Geranium platform is publicly available on GitHub with the following link:
https://github.com/geranium-project (accessed on 3 September 2021).
7. Validation and Results
The main goal of our validation process is to evaluate the link prediction used for the recommendation service by employing an entity-ranking approach, which is a well-known technique in the context of knowledge base completion. This step allows the measurement of the model’s capability of identifying the triples that correctly belong to the KG with respect to a set of synthetic negative examples.
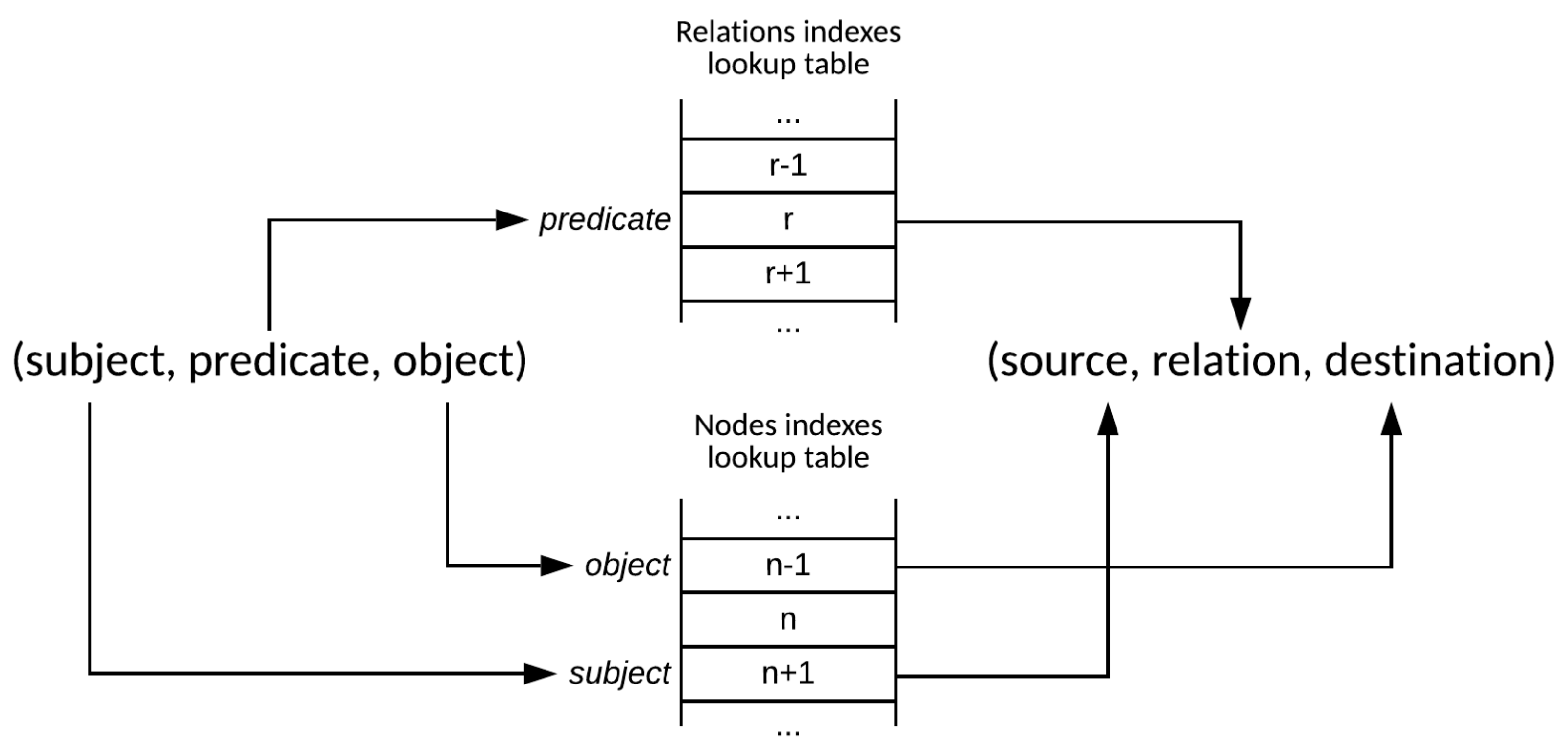
Our validation approach compares the prediction scores achieved by the facts available in the PKG (true facts) and the synthetic facts that are not available in the PKG (false facts). These score values are computed by employing the DistMult factorization method. These negative examples are based on the generation of two sets of perturbed facts for each triple inside the PKG. The first set includes facts in which the source nodes have been perturbed, while the second set includes facts where the destination nodes have been perturbed. Source and destination nodes are perturbed using all possible entity nodes that are included in the initial version of the PKG (see
Section 5.1).
More formally, starting from the i-th evaluation fact or edge , the new sets of synthetic edges include edges such as and , with . An ideal model should be able to rank all of the triples in the evaluation set in the first position. However, this scenario never happens in real cases; for these reasons, we will exploit metrics that are well known in the literature in order to evaluate the capability of the model of setting a true fact in the highest position.
In our analysis, we used the following metrics:
The Reciprocal Rank (RR): This is computed for a single evaluated edge as , where the rank is obtained as explained above.
The Mean Reciprocal Rank (MRR): This is the average of the RRs of all of the evaluation edges. The value obtained is representative of the accuracy of the entire model.
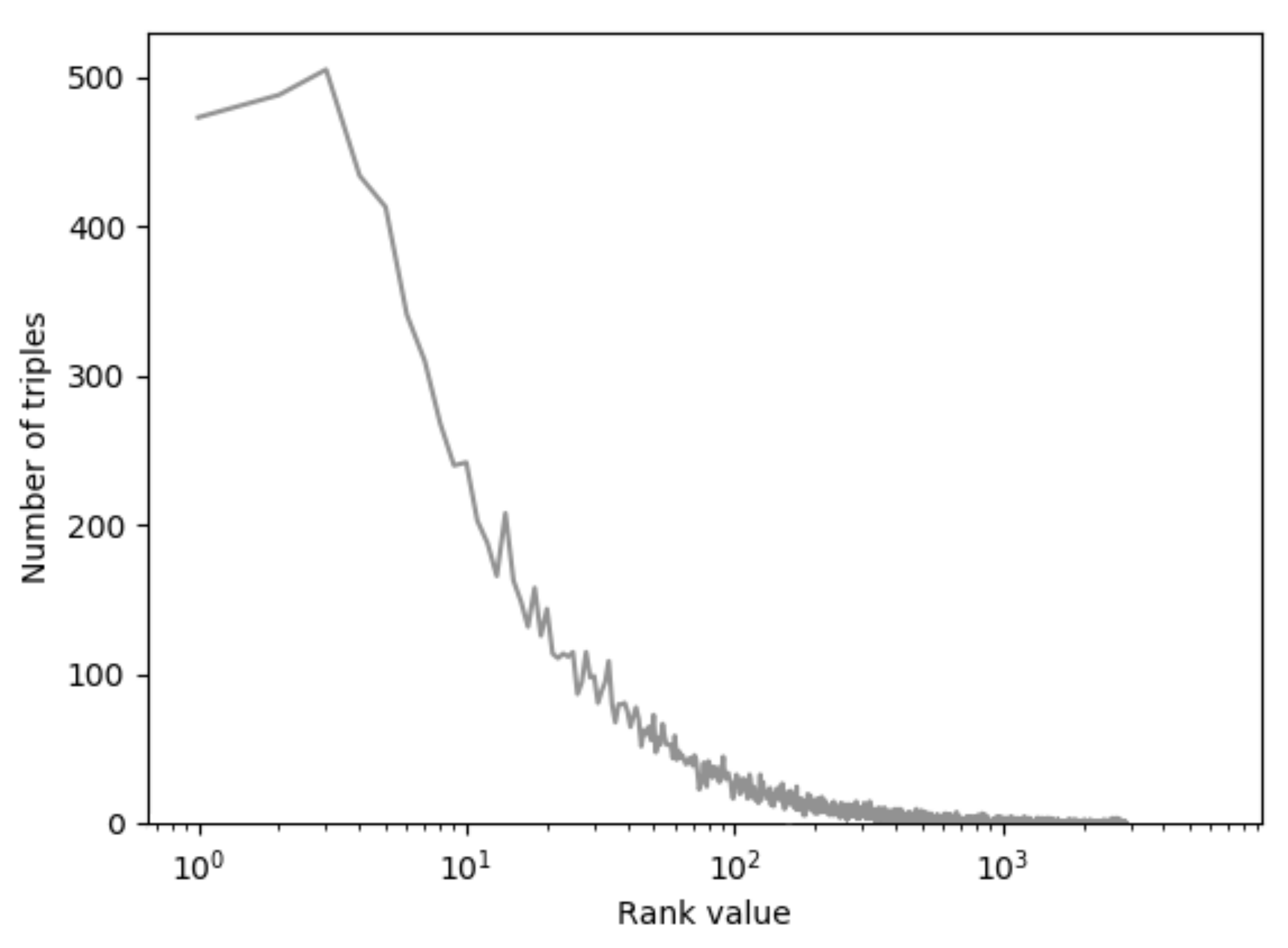
The Hits-at-N (HITS@N): This is the number of triples for which the computed rank is between 0 and N.
To clarify these metrics, we consider the following example. A triple ranked in the tenth position of the sorted list of scores obtains an RR value of . If the facts in the evaluation set are 100, with half of them ranked in the first position and the other half in the tenth, the MRR obtained is , while the HITS@1 is equal to 50, and the HITS@10 is equal to 100.
Author Contributions
Conceptualization, G.G., G.F. and A.V.; Data curation, G.G. and G.F.; Investigation, G.G. and G.F.; Methodology, G.G.; Project administration, G.F.; Software, G.G.; Supervision, G.G. and G.F.; Validation, G.G., G.F. and A.V.; Visualization, G.G.; Writing—original draft, G.G. and G.F.; Writing—review and editing, G.G., G.F., A.V. and J.C.D.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
The authors would like to thank Cosma Alex Vergari and Mehdi Khrichfa, interns at the Nexa Center for Internet and Society, for their contributions in the development of the Geranium platform.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Turki, H.; Hadj Taieb, M.; Shafee, T.; Lubiana, T.; Jemielniak, D.; Ben Aouicha, M. Representing COVID-19 Information in Collaborative Knowledge Graphs: The Case of Wikidata. Semantic Web J. 2021. [Google Scholar] [CrossRef]
- Kejriwal, M. Knowledge Graphs and COVID-19: Opportunities, Challenges, and Implementation. Harv. Data Sci. Rev. 2020. [Google Scholar] [CrossRef]
- Chatterjee, A.; Nardi, C.; Oberije, C.; Lambin, P. Knowledge Graphs for COVID-19: An Exploratory Review of the Current Landscape. J. Pers. Med. 2021, 11, 300. [Google Scholar] [CrossRef] [PubMed]
- Cifariello, P.; Ferragina, P.; Ponza, M. Wiser: A semantic approach for expert finding in academia based on entity linking. Inf. Syst. 2019, 82, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Dwivedi, V.P.; Joshi, C.K.; Laurent, T.; Bengio, Y.; Bresson, X. Benchmarking graph neural networks. arXiv 2020, arXiv:2003.00982. [Google Scholar]
- Lassila, O. Web metadata: A matter of semantics. IEEE Internet Comput. 1998, 2, 30–37. [Google Scholar] [CrossRef]
- Yang, B.; Yih, W.T.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; Springer: Cham, Switzerland, 2018; pp. 593–607. [Google Scholar]
- Dessì, D.; Osborne, F.; Recupero, D.R.; Buscaldi, D.; Motta, E. Generating knowledge graphs by employing Natural Language Processing and Machine Learning techniques within the scholarly domain. Future Gener. Comput. Syst. 2021, 116, 253–264. [Google Scholar] [CrossRef]
- Ronzano, F.; Saggion, H. Dr. inventor framework: Extracting structured information from scientific publications. In Proceedings of the International Conference on Discovery Science, Banff, AB, Canada, 4–6 October 2015; Springer: Cham, Switzerland, 2015; pp. 209–220. [Google Scholar]
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. arXiv 2018, arXiv:1808.09602. [Google Scholar]
- Salatino, A.A.; Osborne, F.; Thanapalasingam, T.; Motta, E. The CSO classifier: Ontology-driven detection of research topics in scholarly articles. In Proceedings of the International Conference on Theory and Practice of Digital Libraries, Oslo, Norway, 9–12 September 2019; Springer: Cham, Switzerland, 2019; pp. 296–311. [Google Scholar]
- Angeli, G.; Premkumar, M.J.J.; Manning, C.D. Leveraging linguistic structure for open domain information extraction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Beijing, China, 2015; pp. 344–354. [Google Scholar]
- Labropoulou, P.; Galanis, D.; Lempesis, A.; Greenwood, M.; Knoth, P.; Eckart de Castilho, R.; Sachtouris, S.; Georgantopoulos, B.; Anastasiou, L.; Martziou, S.; et al. OpenMinTeD: A platform facilitating text mining of scholarly content. In Proceedings of the 7th International Workshop on Mining Scientific Publications (WOSP 2018) at LREC 2018, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Rocha, O.R.; Vagliano, I.; Figueroa, C.; Cairo, F.; Futia, G.; Licciardi, C.A.; Marengo, M.; Morando, F. Semantic annotation and classification in practice. IT Prof. 2015, 17, 33–39. [Google Scholar] [CrossRef]
- Chicaiza, J.; Valdiviezo-Diaz, P. A Comprehensive Survey of Knowledge Graph-Based Recommender Systems: Technologies, Development, and Contributions. Information 2021, 12, 232. [Google Scholar] [CrossRef]
- Nayyeri, M.; Vahdati, S.; Zhou, X.; Yazdi, H.S.; Lehmann, J. Embedding-based recommendations on scholarly knowledge graphs. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 31 May–4 June 2020; Springer: Cham, Switzerland, 2020; pp. 255–270. [Google Scholar]
- Kanakaris, N.; Giarelis, N.; Siachos, I.; Karacapilidis, N. Shall I Work with Them? A Knowledge Graph-Based Approach for Predicting Future Research Collaborations. Entropy 2021, 23, 664. [Google Scholar] [CrossRef]
- Vahdati, S.; Palma, G.; Nath, R.J.; Lange, C.; Auer, S.; Vidal, M.E. Unveiling scholarly communities over knowledge graphs. In Proceedings of the International Conference on Theory and Practice of Digital Libraries, Porto, Portugal, 10–13 Septembe 2018; Springer: Cham, Switzerland, 2018; pp. 103–115. [Google Scholar]
- Liu, C.; Li, L.; Yao, X.; Tang, L. A survey of recommendation algorithms based on knowledge graph embedding. In Proceedings of the 2019 IEEE International Conference on Computer Science and Educational Informatization (CSEI), Kunming, China, 16–19 August 2019; pp. 168–171. [Google Scholar]
- Ameen, A. Knowledge based recommendation system in semantic web-a survey. Int. J. Comput. Appl 2019, 182, 20–25. [Google Scholar] [CrossRef]
- Graves, M.; Constabaris, A.; Brickley, D. Foaf: Connecting people on the semantic web. Cat. Classif. Q. 2007, 43, 191–202. [Google Scholar] [CrossRef]
- Weibel, S.L.; Koch, T. The Dublin core metadata initiative. D-Lib Mag. 2000, 6, 1082–9873. [Google Scholar] [CrossRef]
- Wang, M.; Yu, L.; Zheng, D.; Gan, Q.; Gai, Y.; Ye, Z.; Li, M.; Zhou, J.; Huang, Q.; Ma, C.; et al. Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs. arXiv 2019, arXiv:1909.01315v1. [Google Scholar]
- Quintel, D.; Wilson, R. Analytics and Privacy. Inf. Technol. Libr. 2020, 39, 3. [Google Scholar] [CrossRef]
- Zhang, Y.; Ling, G.; Yong-cheng, W. An improved TF-IDF approach for text classification. J. Zhejiang Univ.-Sci. A 2005, 6, 49–55. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}