This section is divided into four main sections.
Section 5.1 describes the experiment results of the trained model on the Sabah Food Dataset and VIREO-Food172 Dataset, followed by
Section 5.2, which describes the comparison of feature dimensions, using CNN as the classifier. Finally,
Section 5.3 demonstrates the deployment of the food recognition model through a prototype web application.
5.1. Experiments Results
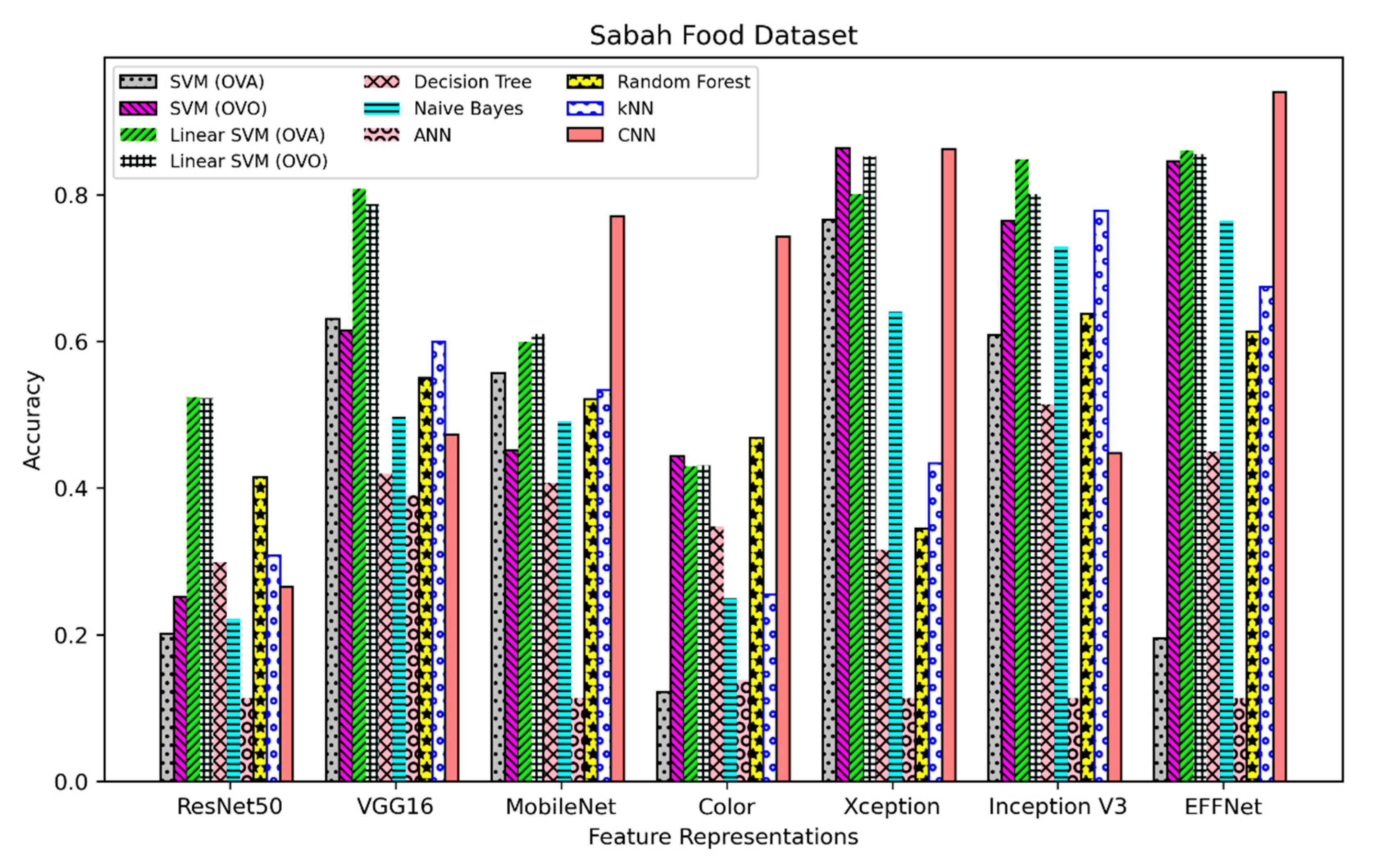
Figure 3 and
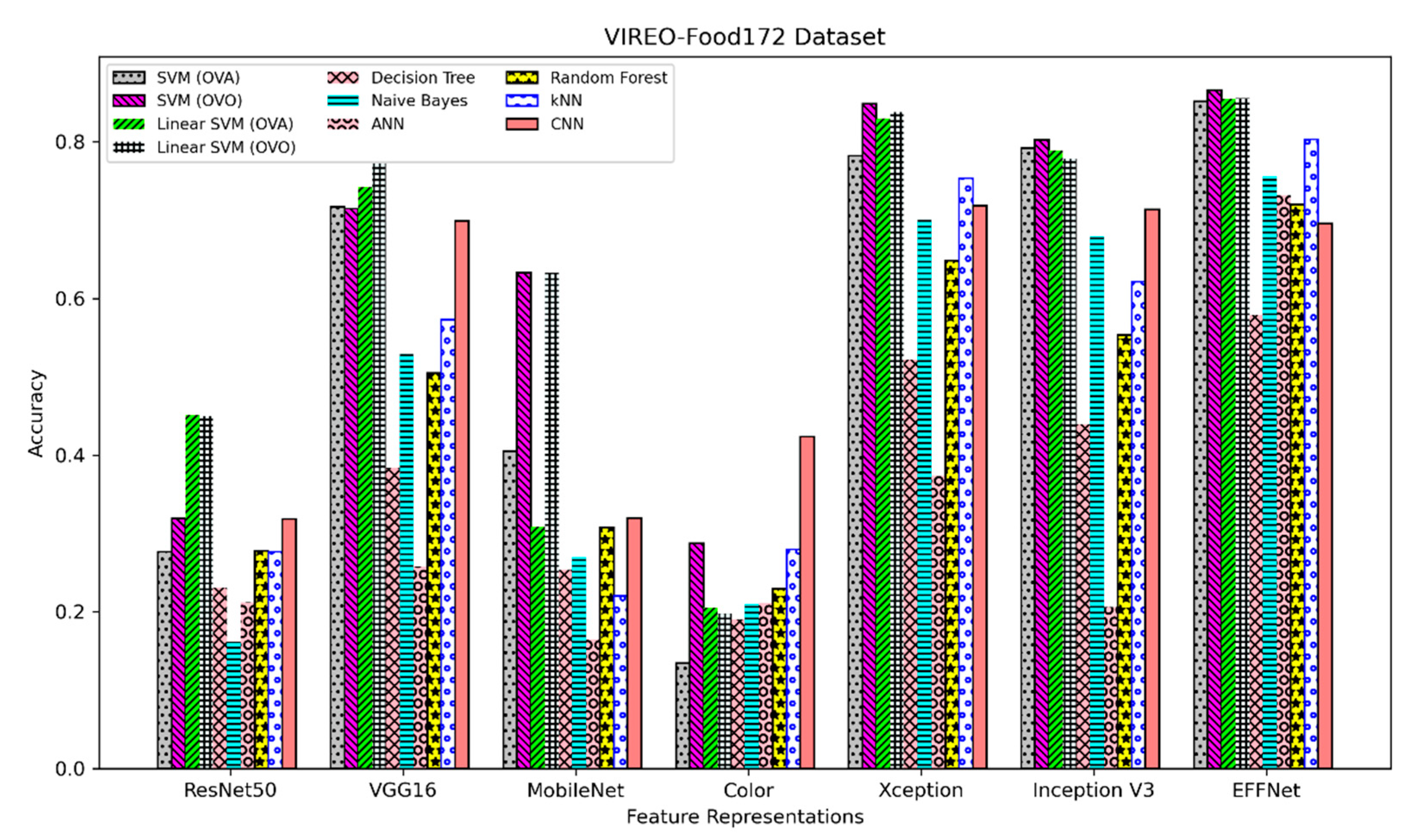
Figure 4 shows the classification accuracy of six CNN-based features derived from the transfer-learning process and one color feature over seven different traditional machine learning classifiers and one CNN-based classifier, tested on the Sabah Food Dataset and VIREO-Food172 Dataset, respectively. As seen in
Figure 3 and
Figure 4, this paper evaluates a total of 56 combinations of machine-learning approaches.
The ten highest accuracies of those machine-learning approaches for the Sabah Food Dataset and VIREO-Food172 Dataset shown in
Figure 3 and
Figure 4 are presented in
Table 16 and
Table 17. The bold formatted machine learning approaches and accuracy in
Table 16 and
Table 17 indicate the best machine learning approaches in that table. Additionally,
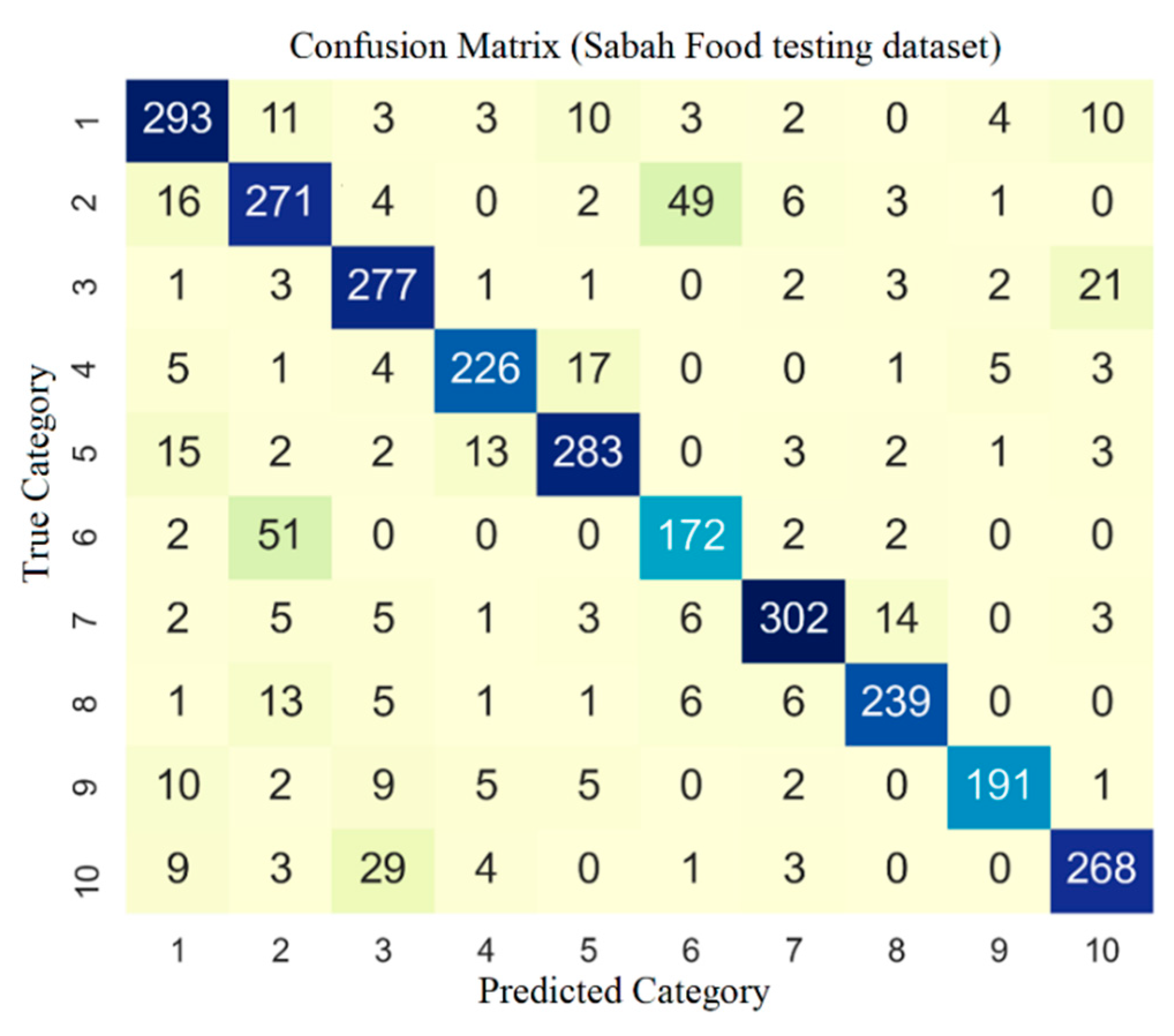
Figure 5 and
Figure 6 present the confusion matrix for the CNN configuration that performs the best on the Sabah Food and VIREO-Food172 testing sets, respectively.
From
Table 16, it can be seen that the EFFNet + CNN approach gives the best performance, yielding 0.9401 accuracy for the Sabah Food Dataset. This is followed by Xception + SVM (OVO) (0.8632) and Xception + CNN (0.8620). Additionally, as shown in
Table 16, performance decreases significantly from EFFNet + CNN to Xception + SVM (OVO) (the accuracy drops with 0.0769 difference) before gradually decreasing from Xception + SVM (OVO) and the rest of the top 10 highest performing approaches (with differences ranging from 0.0012 to 0.0377). The results suggest that the EFFNet + CNN may only work well on a specific training and testing dataset of the Sabah Food Dataset rather than representing the overall best approach. Nevertheless, EFFNet + CNN is the best performing approach on the Sabah Food Dataset.
On the other hand, for the VIREO-Food172 Dataset, it is observed that the EFFNet + SVM (OVO) provides the best performance (0.8657), as shown in
Table 17. However, compared to the top ten performing machine-learning approaches in the Sabah Food Dataset, the differences between each machine-learning approach on the VIREO-Food172 Dataset are more stable (with differences ranging from 0.0007 to 0.0269). In contrast to the best performing approach on the Sabah Food Dataset (
Table 16), there is no significant drop in accuracy from the highest to the second-highest accuracy on the VIREO-Food172 Dataset. Additionally, both the Sabah Food Dataset and the VIREO-Food172 Dataset demonstrate that EFFNet provides the best performance when used as a feature representation.
As previously stated, there are seven different feature representations. Therefore,
Table 18 and
Table 19 present seven machine-learning approaches for the Sabah Food Dataset and VIREO-Food172 Dataset, with the best one selected from each group of feature representations and ranked from best to worst accuracy. In
Table 18 and
Table 19, the bold formatted machine learning approaches and accuracy denote the best machine learning approaches in that table.
Table 18 and
Table 19 are similar in that EFFNet is the best feature representation, followed by Xception, Inception V3, and VGG16. Further examination of
Table 18 reveals that the accuracy falls precipitously between Color + CNN (0.7422) and ResNet50 + LSVM (OVA) (0.5236), yielding 0.2186 differences. On the other hand, examining
Table 19 reveals a gradual decline in accuracy within the first four machine-learning approaches before a significant decrease from VGG16 + LSVM (OVO) (0.7725) to MobileNet + LSVM (OVO) (0.6332), yielding a 0.1393 difference. This drop in accuracy is significant because it tells us which machine-learning approaches should be considered for any future work or subsequent experiments if accuracy is the most important factor in the food recognition model development.
When the similarities between
Table 18 and
Table 19 are compared, it is seen that EFFNet, Xception, Inception V3, and VGG16 provide more stable performance, with EFFNet feature representation being the best. As a result, an ensemble-based approach based on these four feature representation methods can be considered for future work.
Additionally,
Table 20 and
Table 21 present ten machine-learning approaches for the Sabah Food Dataset and VIREO-Food172 Dataset. The best one was selected from each classifier group and ranked from best to worst accuracy. In
Table 20 and
Table 21, the bold formatted machine learning approaches and accuracy represent the best machine learning approaches in that table.
Table 20 and
Table 21 are then subjected to a similar analysis. From
Table 20 and
Table 21, it can be seen that the EFFNet-based feature representation appears most frequently.
Table 20 shows four occurrences of EFFNet, whereas
Table 21 shows eight occurrences. Although this is a minor point, it is worth noting that the SVM (OVO) classifier (Xception + SVM (OVO) in the Sabah Food Dataset and EFFNet + SVM (OVO) in the VIREO-Food172 Dataset) appears in the top two of
Table 20 and
Table 21.
In a subsequent analysis of the Sabah Food Dataset and the VIREO-Food172 Dataset, the overall performance of each feature representation is compared in
Table 22. The value in the second row and second column in
Table 22 (EFFNet) is produced by calculating the average of all machine-learning approaches that use EFFNet as a feature representation technique for the Sabah Food Dataset. This calculation is repeated for all feature representations and both datasets to fill in the second and third columns in
Table 22. The value in the fourth column of
Table 22 is filled with a value produced by the
defined in (2). The
is calculated by averaging the Mean Accuracy of the Sabah Food Dataset and the Mean Accuracy of the VIREO-Food172 Dataset from the second and third columns of
Table 22. Equation (2) is applied to all of the feature representations listed in
Table 22 to complete the fourth column.
where
The
in (2) indicates the performance of a feature representation on both proposed datasets. Following that, the
calculated in (2) is used to facilitate the comparison of all feature representations. The bold formatted Feature Representation and Overall Score in
Table 22 represent the best Feature Representation.
From
Table 22, it can be seen that the EFFNet has the best overall performance, followed by Xception, Inception V3, and VGG16 before the
drops significantly for MobileNet, ResNet50, and Color. Therefore, a combination of the EFFNet, Xception, Inception V3, and VGG16 approaches can be considered as components of an ensemble-based approach.
Table 23 shows the overall performance of each classifier. The
in the fourth column of
Table 23 is calculated based on (2), which is obtained by averaging the Mean Accuracy of the Sabah Food Dataset and the Mean Accuracy of the VIREO-Food172 Dataset from the second and third columns of
Table 23. Similar to the analysis conducted in
Table 22, the
calculated in (2) is used to facilitate the comparison of all classifiers. The bold formatted Classifier and Overall Score in
Table 23 represent the best Classifier.
From
Table 23, it can be seen that the LSVM (OVO) classifier gives the best overall performance (0.6704), followed by LSVM (OVA) (0.6465), SVM (OVO) (0.6219), and CNN (0.5993) as the classifier. After the CNN classifier, there is a significant drop of
from CNN to kNN, yielding 0.914 difference. As a result, if one is considering a classifier, LSVM (OVO) and LSVM (OVA) are the best options. Additionally, for future work, LSVM (OVO), LSVM (OVA), and SVM (OVO) can be considered as components of an ensemble-based approach.
Finally,
Table 24 compares the accuracy of the other methods in
Table 1 as well as the accuracy of the food recognition reported in [
32] to our work. However, a direct comparison between our model and their model is not possible, due to the differences in the training and testing conditions. Nonetheless, our best performance of 94.01% is comparable to that of [
20], which has a 98.16% accuracy. Additionally, our EFFNet + CNN model outperformed the CNN and InceptionV3+CNN models in terms of overall accuracy.
5.2. A comparison of Feature Dimension Using CNN as the Classifier
In this work, pre-processing and feature extraction is performed, using a transfer learning strategy based on a pre-trained CNN. As the pre-trained CNN is built up with several layers, there is an option to use all the layers or to pick only a few layers in order to extract the relevant features. The relevance of features is determined by the type and volume of datasets used to train CNNs. For instance, the ImageNet dataset is used to train the CNN model, as it is one of the benchmark datasets in Computer Vision. However, the types of datasets and volume of data used to train the pre-trained CNN models vary, and the effectiveness of the transfer-learning strategy is dependent on the degree to which the trained models are related to the applied problem domains. Hence, the experiments conducted in this work have revealed the compatibility between the pre-trained CNN model as the feature extractor with the food recognition domain, especially the local food dataset, based on their classification performance.
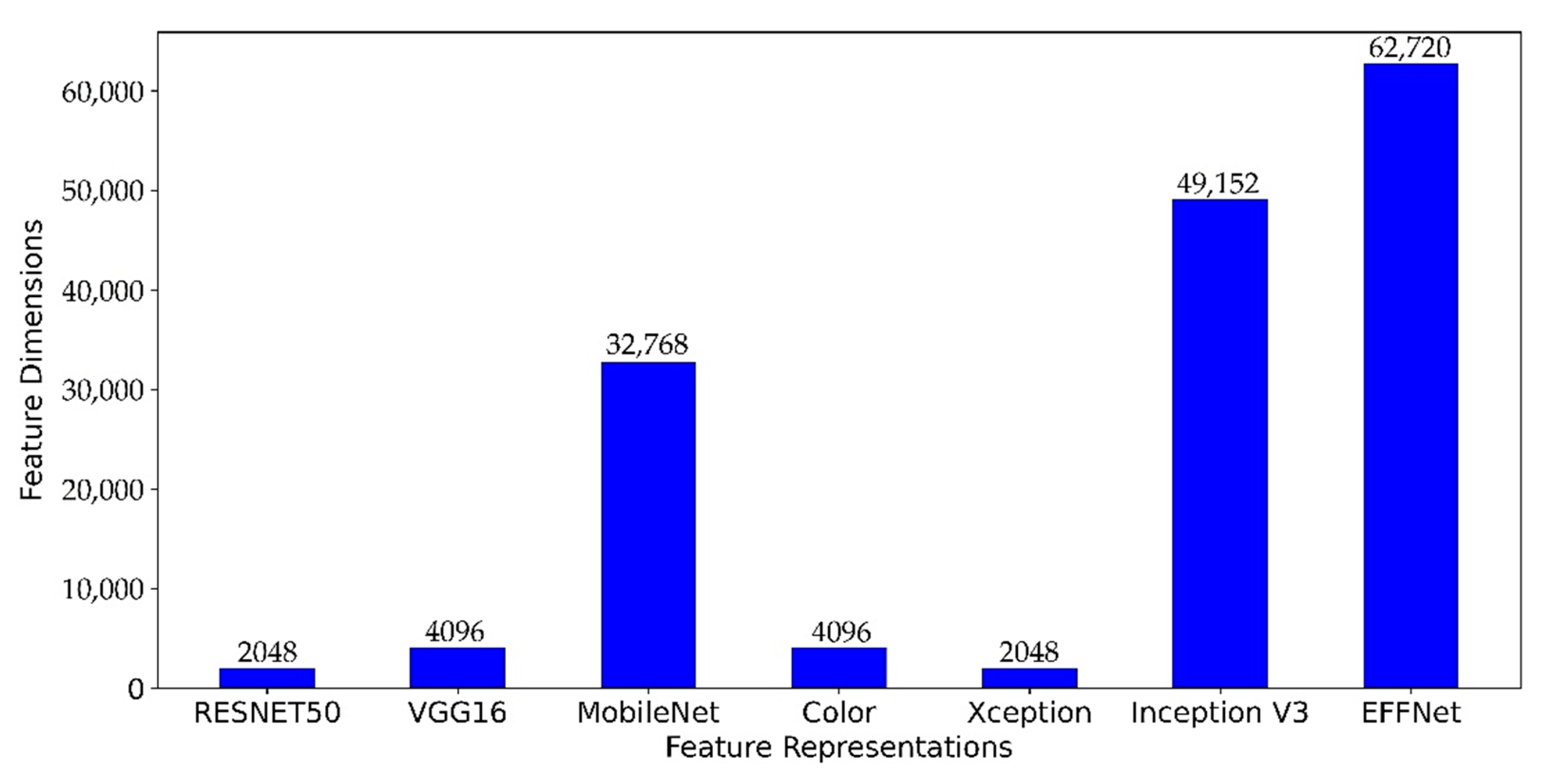
The selection of layers in the pre-trained CNN model determines not only the relevancy of features but also their feature dimension. The size of the generated features determines the efficiency of running the algorithm. A large number of features entails additional computational effort but likely result in more discriminative features. As shown in
Figure 7, the size of the generated features varies according to the final layer or the layer selection on the CNN architecture. It can be seen that the EFFnet has generated the largest feature dimensions (62,720), followed by Inception V3 (49,152), MobileNet (32,768), VGG16 (4096), Color (4096), ResNet50 (2048), and Xception (2048).
Table 25 compares the feature dimension and the
of feature representation. The bold formatted Feature Representation and Overall Score in
Table 25 represent the best Feature Representation. While EFFNet as feature representations outperforms Xception in terms of overall performance,
Table 25 shows that if computational speed is more important than performance, Xception as feature representation can be considered at the cost of some accuracy performance. The results in
Table 25 also indicate that the data used in EFFNet training potentially contain the most relevant and consistent data for extracting meaningful features from food images when compared to other CNN models.
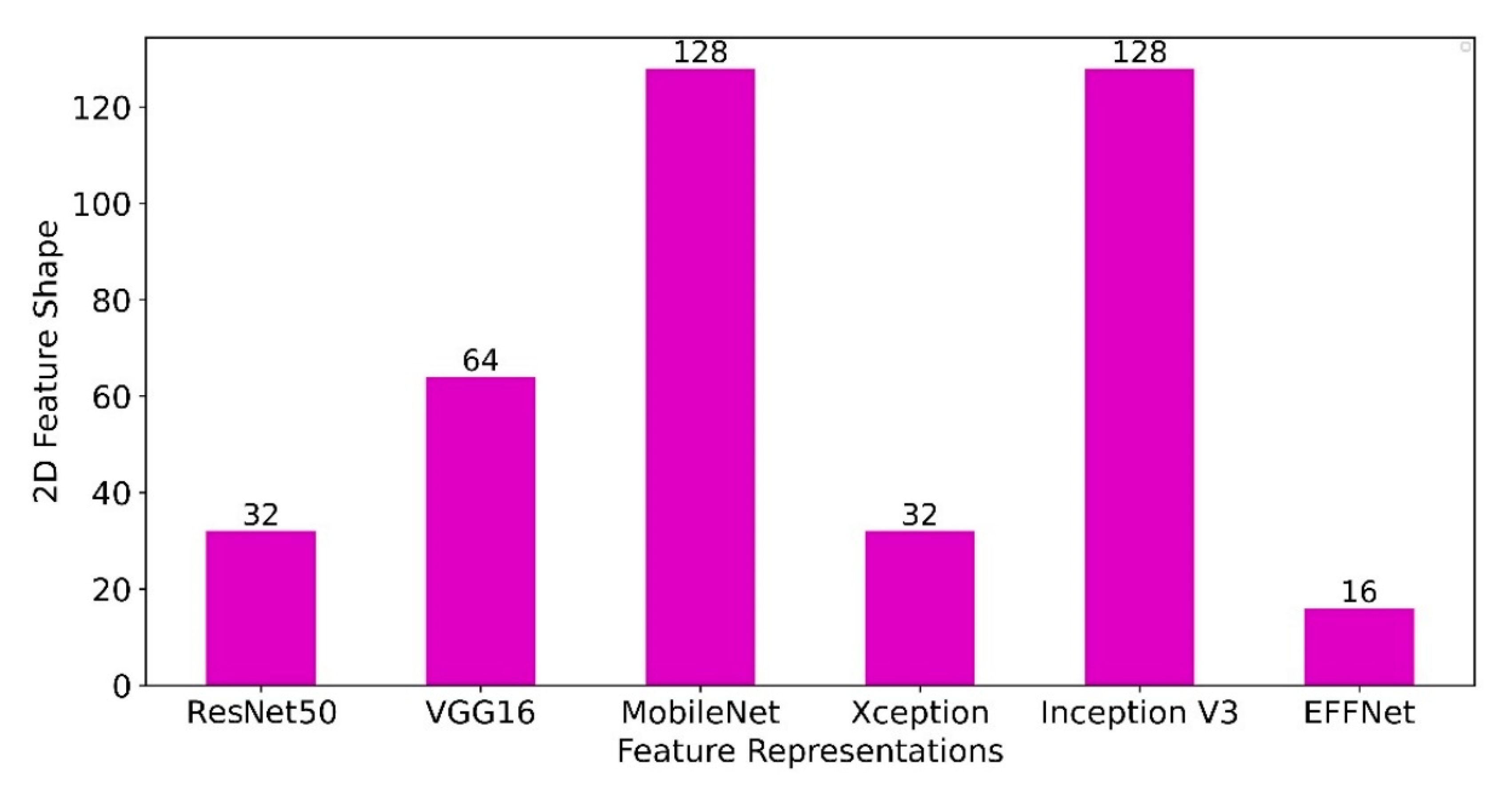
Additionally,
Figure 8 presents the length and width of features of a pre-trained CNN model for training with a CNN classifier. Each bar in
Figure 8 has a label that represents the length and width values. In this case, the length and width are equal. As seen in
Figure 8, the Conv2D features generated by EFFNet are minimal (16, 16, 245), compared to the Conv1D features. Despite the high depth of the feature dimension (245), the experiment revealed no noticeable effect of time efficiency during the training phase. Based on this finding, the model trained with EFFNet features is the best model, as it achieves the highest overall accuracy and generates highly distinctive, yet compact features. In this context, the depth level (
) of the feature’s representation determines the efficacy of the classification performance, as more insight of spatial information can be generated. Furthermore, the level of depth of features (
) are more likely have less effect on the overall classification efficiency, compared to the value of
and
axis of the features. As depicted in
Figure 8, the MobileNet- and Inception V3-based feature representations produce the highest values of
and
but cost more in terms of execution time than ResNet50, VGG16, Xception, and EFFNet based feature representations. However, in addition to the compatibility of the pre-trained CNN models with the newly developed classification model, the shape of the feature representations is another factor that must be taken into account in the experiment settings.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}