
A Review of Tabular Data Synthesis Using GANs on an IDS Dataset

 , , and
, , and
Abstract
:1. Introduction
2. GAN Models
2.1. Wasserstein GAN (WGAN)
2.2. WGAN-GP
3. GAN Models and Evaluation Metrics for Tabular Data Generation
3.1. GANs for Synthesizing Tabular Data
3.1.1. TableGAN
3.1.2. CTGAN
3.1.3. CopulaGAN
3.2. Evaluation Metrics
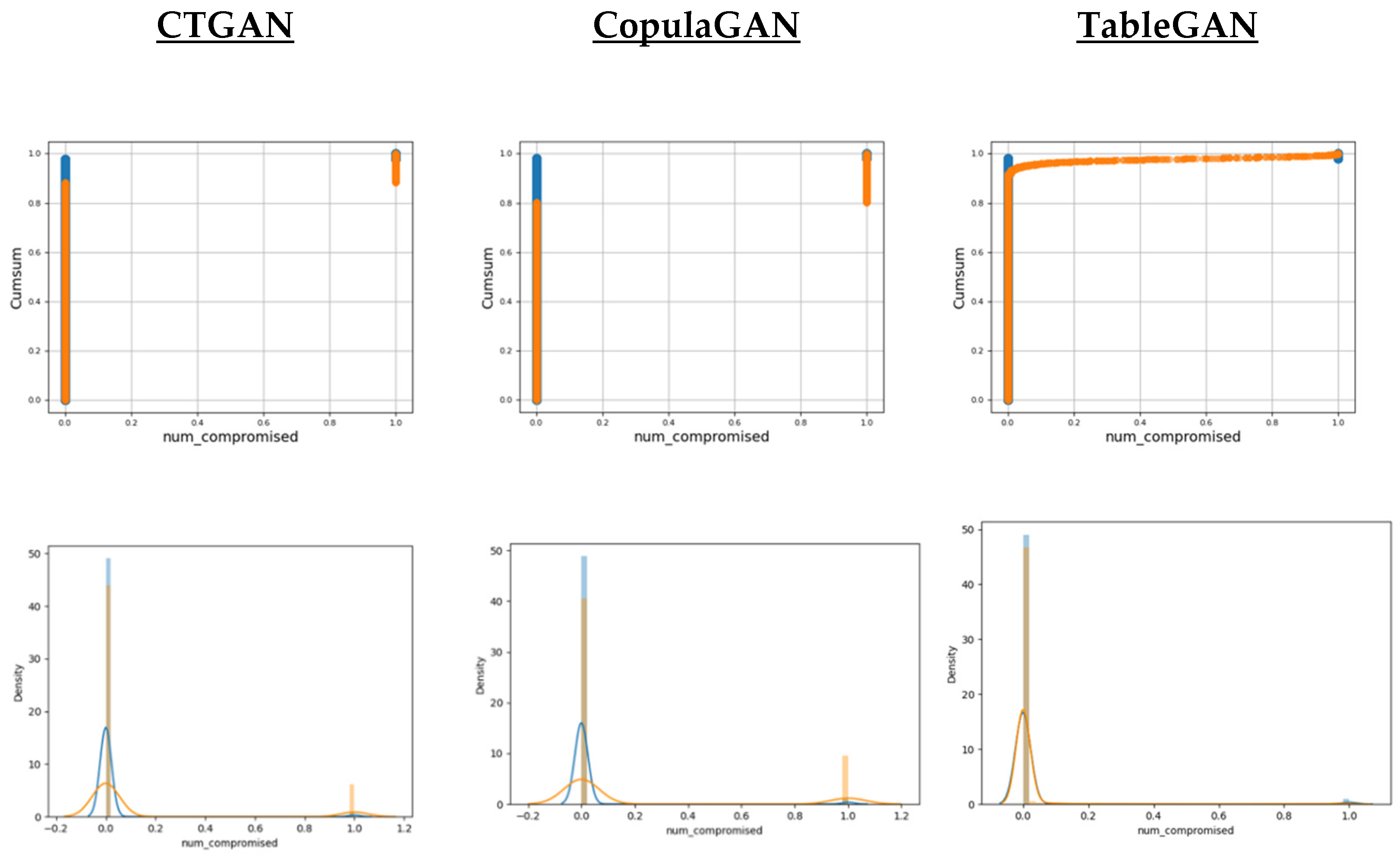
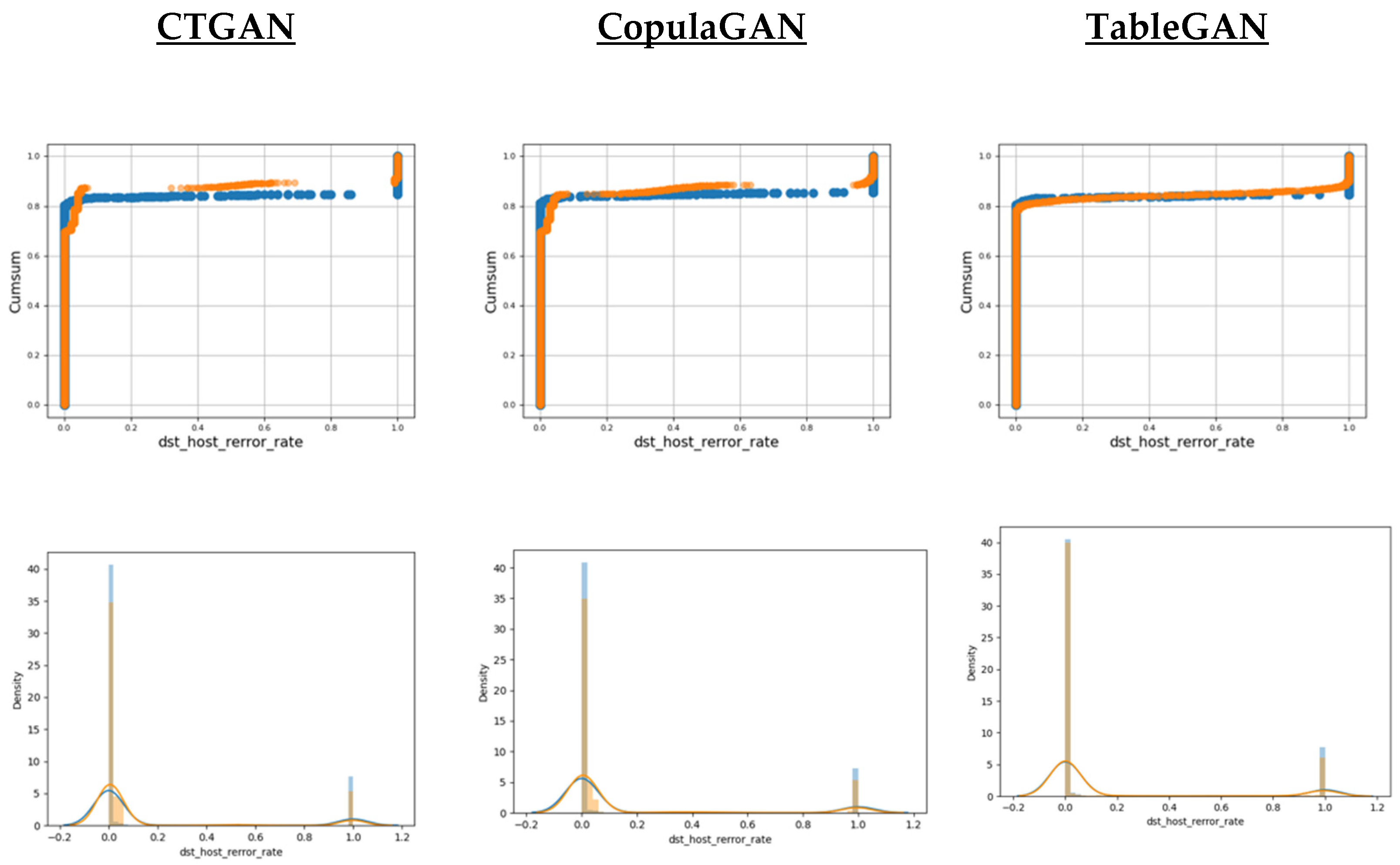
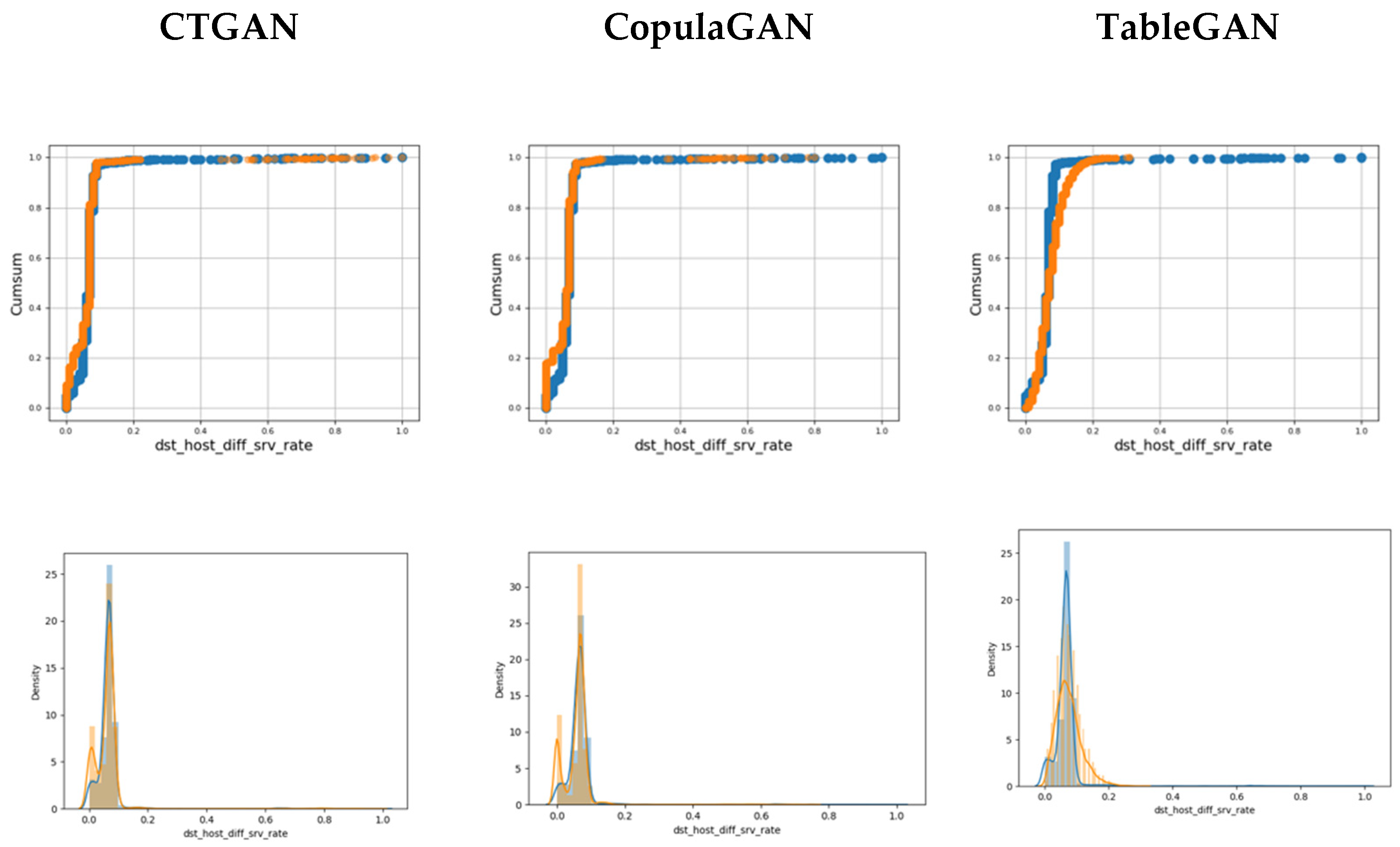
3.2.1. Visual Evaluation
3.2.2. Statistical Metrics
3.2.3. Machine Learning-Based Metrics
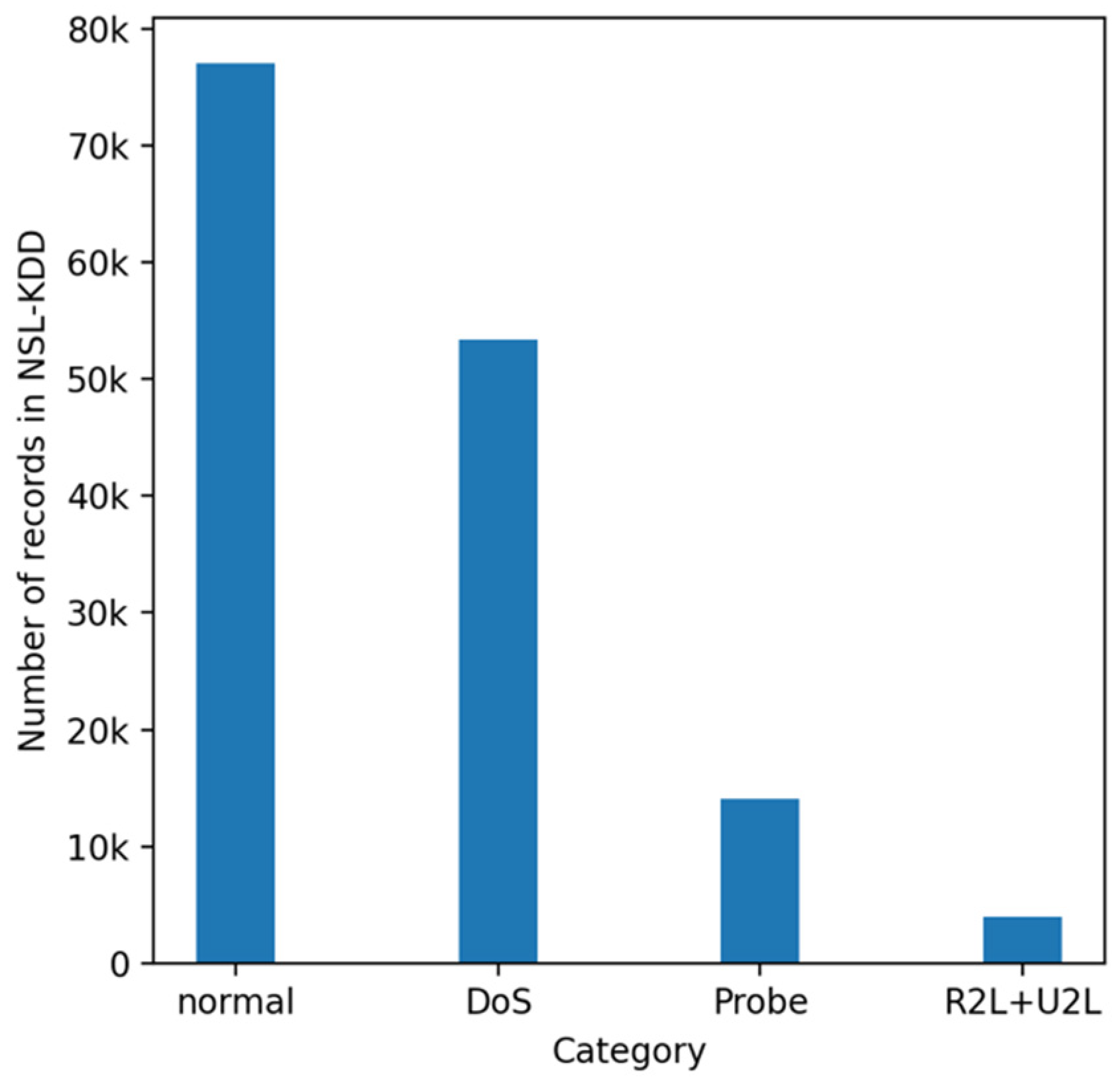
4. NSL-KDD Dataset
- Intrinsic features (9): includes necessary information of the record, such as protocol, service, and duration.
- Content features (13): comprise information about the content, such as the login activities. Those features demonstrate if there are behaviors related to attacks.
- Time-based features (9): contains the number of connections to the same destination host or service as the current connection in the past two seconds.
- Host-based features (10): checks the 100 past connections, which have the same destination host or service with the current connection.
4.1. Constraints for the Generating Adversarial Examples
5. Experiments and Results
5.1. Experimental Setup
5.2. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Anderson, J.P. Computer security threat monitoring and surveillance. In Technical Report; James, P., Ed.; Anderson Company, Fort: Washington, PA, USA, Technical Report 98-17; April 1980. [Google Scholar]
- Rai, K.; Devi, M.S.; Guleria, A. Decision tree based algorithm for intrusion detection. Int. J. Adv. Netw. Appl. 2016, 7, 2828. [Google Scholar]
- Li, Z.; Qin, Z.; Huang, K.; Yang, X.; Ye, S. Intrusion detection using convolutional neural networks for representation learning. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; Springer: Cham, Switzerland, 2017; pp. 858–866. [Google Scholar]
- Teng, S.; Wu, N.; Zhu, H.; Teng, L.; Zhang, W. SVM-DT-based adaptive and collaborative intrusion detection. IEEE/CAA J. Autom. Sin. 2018, 5, 108–118. [Google Scholar] [CrossRef]
- Bringas, P.G.; Grueiro, I.S. Bayesian Networks for Network Intrusion Detection. 2010. Available online: https://intechopen.com/books/bayesian-network/bayesian-networks-for-network-intrusion-detection (accessed on 10 September 2021).
- Zhang, J.; Cormode, G.; Procopiuc, C.M.; Srivastava, D.; Xiao, X. PrivBayes: Private data release via bayesian networks. Acm Trans. Database Syst. 2014, 42, 1423–1434. [Google Scholar]
- Aviñó, L.; Ruffini, M.; Gavaldà, R. Generating Synthetic but Plausible Healthcare Record Datasets. arXiv 2018, arXiv:1807.01514. [Google Scholar]
- Dong, Q.; Elliott, M.R.; Raghunathan, T.E. A nonparametric method to generate synthetic populations to adjust for complex sampling design features. Surv. Methodol. 2014, 40, 29. [Google Scholar]
- Oliva, J.B.; Dubey, A.; Wilson, A.G.; Póczos, B.; Schneider, J.; Xing, E.P. Bayesian nonparametric kernel-learning. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 1078–1086. [Google Scholar]
- Nowok, B.; Raab, G.M.; Dibben, C. synthpop: Bespoke creation of synthetic data in R. J. Stat. Softw. 2016, 74, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Reiter, J.P. Using CART to generate partially synthetic public use microdata. J. Off. Stat. 2005, 21, 441. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. 2014. Available online: https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf (accessed on 10 September 2021).
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International conference on machine learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein GANs. 2017. Available online: http://papers.nips.cc/paper/7159-improved-training-of-wasserstein-gans.pdf (accessed on 10 September 2021).
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Denton, E.; Chintala, S.; Szlam, A.; Fergus, R. Deep generative image models using a Laplacian pyramid of adversarial networks. arXiv 2015, arXiv:1506.05751. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Liu, S.; Wang, T.; Bau, D.; Zhu, J.-Y.; Torralba, A. Diverse image generation via self-conditioned gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14286–14295. [Google Scholar]
- Lin, Z.; Shi, Y.; Xue, Z. Idsgan: Generative adversarial networks for attack generation against intrusion detection. arXiv 2018, arXiv:1809.02077. [Google Scholar]
- Charlier, J.; Singh, A.; Ormazabal, G.; State, R.; Schulzrinne, H. SynGAN: Towards generating synthetic network attacks using GANs. arXiv 2019, arXiv:1908.09899. [Google Scholar]
- Hu, W.; Tan, Y. Generating adversarial malware examples for black-box attacks based on GAN. arXiv 2017, arXiv:1702.05983. [Google Scholar]
- Xu, L.; Veeramachaneni, K. Synthesizing Tabular Data using Generative Adversarial Networks. arXiv 2018, arXiv:1811.11264. [Google Scholar]
- Xu, L.; Skoularidou, M.; Infante, A.C.; Veeramachaneni, K. Modeling Tabular Data Using Conditional GAN. 2019. Available online: https://nips.cc/conferences/2019/acceptedpapersinitial (accessed on 10 September 2021).
- Zhao, Z.; Kunar, A.; van der Scheer, H.; Birke, R.; Chen, L.Y. CTAB-GAN: Effective Table Data Synthesizing. arXiv 2021, arXiv:2102.08369. [Google Scholar]
- Mottini, A.; Lheritier, A.; Acuna-Agost, R. Airline passenger name record generation using generative adversarial networks. arXiv 2018, arXiv:1807.06657. [Google Scholar]
- Yahi, A.; Vanguri, R.; Elhadad, N.; Tatonetti, N.P. Generative adversarial networks for electronic health records: A framework for exploring and evaluating methods for predicting drug-induced laboratory test trajectories. arXiv 2017, arXiv:1712.00164. [Google Scholar]
- Choi, E.; Biswal, S.; Malin, B.; Duke, J.; Stewart, W.F.; Sun, J. Generating multi-label discrete patient records using generative adversarial networks. In Proceedings of the Machine Learning for Healthcare Conference, Boston, MA, USA, 18–19 August 2017; pp. 286–305. [Google Scholar]
- Park, N.; Mohammadi, M.; Gorde, K.; Jajodia, S.; Park, H.; Kim, Y. Data synthesis based on generative adversarial networks. arXiv 2018, arXiv:1806.03384. [Google Scholar] [CrossRef] [Green Version]
- CopulaGAN Model. Available online: https://sdv.dev/SDV/user_guides/single_table/copulagan.html (accessed on 15 July 2021).
- SDV—The Synthetic Data Vault. Available online: https://sdv.dev/SDV/user_guides/benchmarking/synthesizers.html (accessed on 15 July 2021).
- Patki, N. The Synthetic Data Vault: Generative Modeling for Relational Databases. 2016. Available online: https://dspace.mit.edu/handle/1721.1/109616 (accessed on 10 September 2021).
- NSL-KDD Dataset. Available online: https://www.unb.ca/cic/datasets/index.html (accessed on 15 July 2021).
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep learning methods on network intrusion detection using NSL-KDD dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. A network forensic scheme using correntropy-variation for attack detection. In Proceedings of the IFIP International Conference on Digital Forensics, New Delhi, India, 3–5 January 2018; Springer: Cham, Switzerland, 2018; pp. 225–239. [Google Scholar]
- Zhang, T.; Zhu, Q. Distributed privacy-preserving collaborative intrusion detection systems for VANETs. IEEE Trans. Signal Inf. Process. Netw. 2018, 4, 148–161. [Google Scholar] [CrossRef]
- Xevgenis, M.; Kogias, D.G.; Karkazis, P.; Leligou, H.C.; Patrikakis, C. Application of Blockchain Technology in Dynamic Resource Management of Next Generation Networks. Information 2020, 11, 570. [Google Scholar] [CrossRef]
- Short, R.; Leligou, H.C.; Theocharis, E. Execution of a Federated Learning process within a smart contract. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–12 January 2021; pp. 1–4. [Google Scholar]
- Svensén, M.; Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Cham, Switzerland, 2007. [Google Scholar]
- Borji, A. Pros and Cons of GAN Evaluation Measures: New Developments. arXiv 2021, arXiv:2103.09396. [Google Scholar]
- Theis, L.; Oord, A.V.d.; Bethge, M. A note on the evaluation of generative models. arXiv 2015, arXiv:1511.01844. [Google Scholar]
- Salimans, T.; Ian, G.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6629–6640. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- KDD Cup 1999 Data. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 11 May 2021).
- Dhanabal, L.; Shantharajah, S.P. A study on NSL-KDD dataset for intrusion detection system based on classification algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 446–452. [Google Scholar]
- Choudhary, S.; Kesswani, N. Analysis of KDD-Cup’99, NSL-KDD and UNSW-NB15 datasets using deep learning in IoT. Procedia Comput. Sci. 2020, 167, 1561–1573. [Google Scholar] [CrossRef]
- Ring, M.; Wunderlich, S.; Scheuring, D.; Landes, D.; Hotho, A. A survey of network-based intrusion detection data sets. Comput. Secur. 2019, 86, 147–167. [Google Scholar] [CrossRef] [Green Version]
- Moore, D.; Shannon, C.; Brown, D.J.; Voelker, G.M.; Savage, S. Inferring internet denial-of-service activity. ACM Trans. Comput. Syst. 2006, 24, 115–139. [Google Scholar] [CrossRef]
- Khamphakdee, N.; Benjamas, N.; Saiyod, S. Improving intrusion detection system based on snort rules for network probe attack detection. In Proceedings of the 2014 2nd International Conference on Information and Communication Technology, Bandung, Indonesia, 28–30 May 2014. [Google Scholar]
- Alharbi, A.; Alhaidari, S.; Zohdy, M. Denial-of-service, probing, user to root (U2R) & remote to user (R2L) attack detection using hidden Markov models. Int. J. Comput. Inf. Technol. 2018, 7, 204–210. [Google Scholar]
- Paliwal, S.; Gupta, R. Denial-of-service, probing & remote to user (R2L) attack detection using genetic algorithm. Int. J. Comput. Appl. 2012, 60, 57–62. [Google Scholar]
- Lee, W.; Stolfo, S.J. A framework for constructing features and models for intrusion detection systems. ACM Trans. Inf. Syst. Secur. 2000, 3, 227–261. [Google Scholar] [CrossRef]
- Table Evaluator. Available online: https://baukebrenninkmeijer.github.io/table-evaluator/ (accessed on 25 July 2021).
- Synthetic Data Evaluation-Single Table Metrics. Available online: https://sdv.dev/SDV/user_guides/evaluation/single_table_metrics.html (accessed on 25 July 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Labeled Attack |
|---|---|
| DoS | neptune, back, land, pod, smurf, teardrop, mailbomb, apache2, processtable, udpstorm, worm |
| Probe | ipsweep, nmap, portsweep, satan, mscan, saint |
| R2L | ftp_write, guess_passwd, imap, multihop, phf, spy, warezclient, warezmaster, sendmail, named, snmpgetattack, snmpguess, xlock, xsnoop, httptunnel |
| U2L | buffer_overflow, loadmodule, perl, rootkit, ps, sqlattack, xterm |
| Categorical Features | Protocol_Type, Service, Flag |
|---|---|
| Binary Features | land, logged_in, root_shell, is_host_login, is_guest_login |
| Triplets Features | su_attempted |
| Attack Category | Intrinsic | Content | Time-Based Traffic | Host-Based Traffic |
|---|---|---|---|---|
| DoS | x | x | ||
| Probe | x | x | x | |
| U2R | x | x | ||
| R2L | x | x |
| Statistical Metrics | Detection Metrics | ||
|---|---|---|---|
| CSTest | KSTest | Logistic Regression | |
| CTGAN | 0.91 | 0.84 | 0.74 |
| CopulaGAN | 0.94 | 0.83 | 0.75 |
| TableGAN | 0.89 | 0.95 | 0.76 |
| Machine Learning Efficacy Metrics | |||||
|---|---|---|---|---|---|
| Decision Tree | AdaBoost | Logistic Regression Classifier | MLP Classifier | Average | |
| CTGAN | 0.97 | 0.96 | 0.84 | 0.96 | 0.93 |
| CopulaGAN | 0.97 | 0.95 | 0.92 | 0.96 | 0.95 |
| TableGAN | 0.95 | 0.94 | 0.92 | 0.97 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bourou, S.; El Saer, A.; Velivassaki, T.-H.; Voulkidis, A.; Zahariadis, T. A Review of Tabular Data Synthesis Using GANs on an IDS Dataset. Information 2021, 12, 375. https://doi.org/10.3390/info12090375
Bourou S, El Saer A, Velivassaki T-H, Voulkidis A, Zahariadis T. A Review of Tabular Data Synthesis Using GANs on an IDS Dataset. Information. 2021; 12(9):375. https://doi.org/10.3390/info12090375
Chicago/Turabian StyleBourou, Stavroula, Andreas El Saer, Terpsichori-Helen Velivassaki, Artemis Voulkidis, and Theodore Zahariadis. 2021. "A Review of Tabular Data Synthesis Using GANs on an IDS Dataset" Information 12, no. 9: 375. https://doi.org/10.3390/info12090375
APA StyleBourou, S., El Saer, A., Velivassaki, T.-H., Voulkidis, A., & Zahariadis, T. (2021). A Review of Tabular Data Synthesis Using GANs on an IDS Dataset. Information, 12(9), 375. https://doi.org/10.3390/info12090375