
CNMF: A Community-Based Fake News Mitigation Framework


Abstract
:1. Introduction
2. Related Work
- -
- The cold-start problem [15] of news propagators posted less than three fact-checking URLs.
- -
- Recommending all fact-checking articles produces many recommendations, while some of FN are unnecessary to mitigate.
- -
- The author observed that only active news propagators (that is considered a small set of users) respond frequently to mitigation requests limiting MN spreading.
3. Preliminaries
3.1. Entities and Facts Discovery
3.2. Tweet Popularity
3.3. Topic Hierarchy
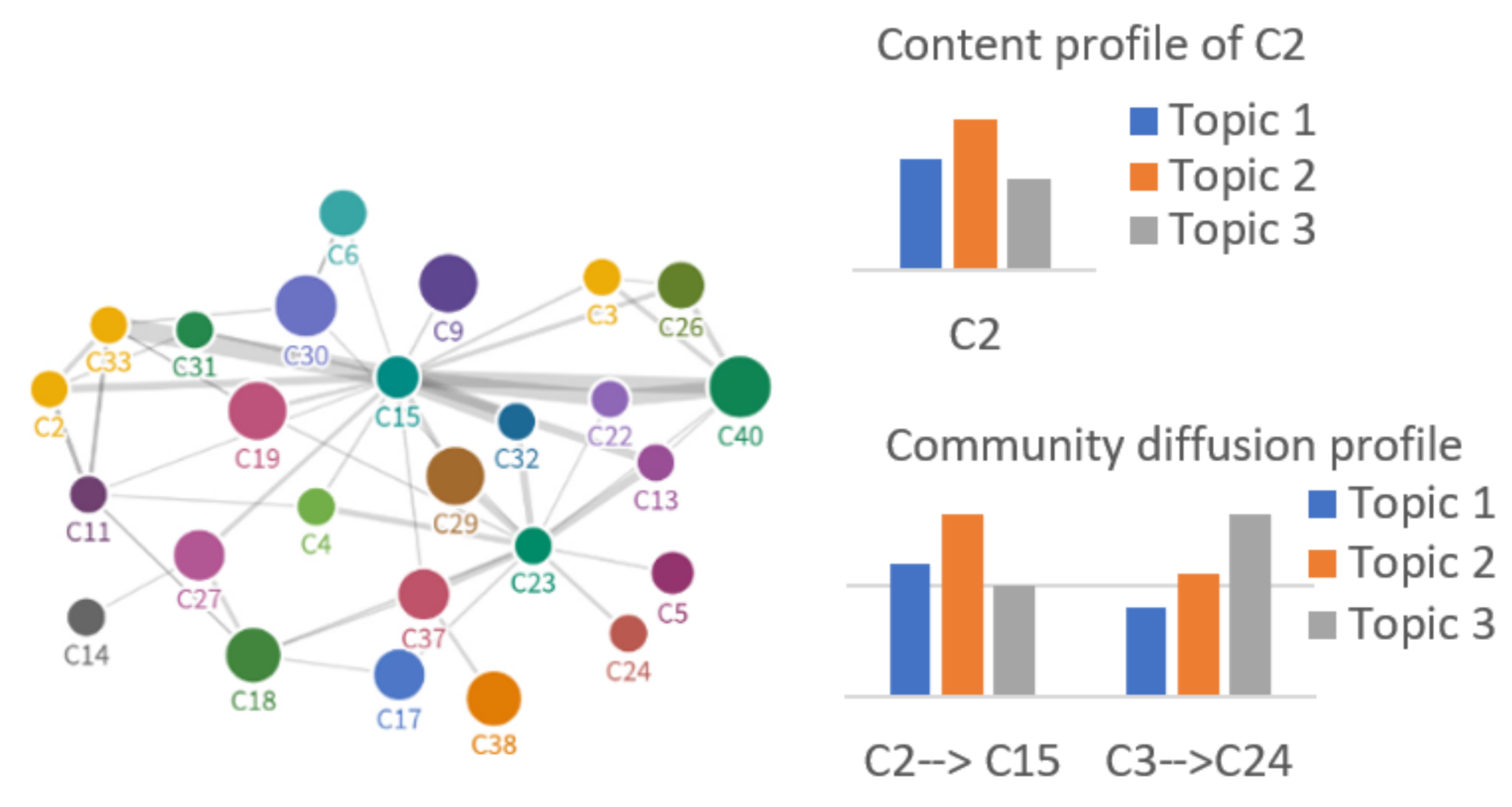
3.4. Community Profiling (CP)
3.5. Sentiment Analysis and Stance Detection
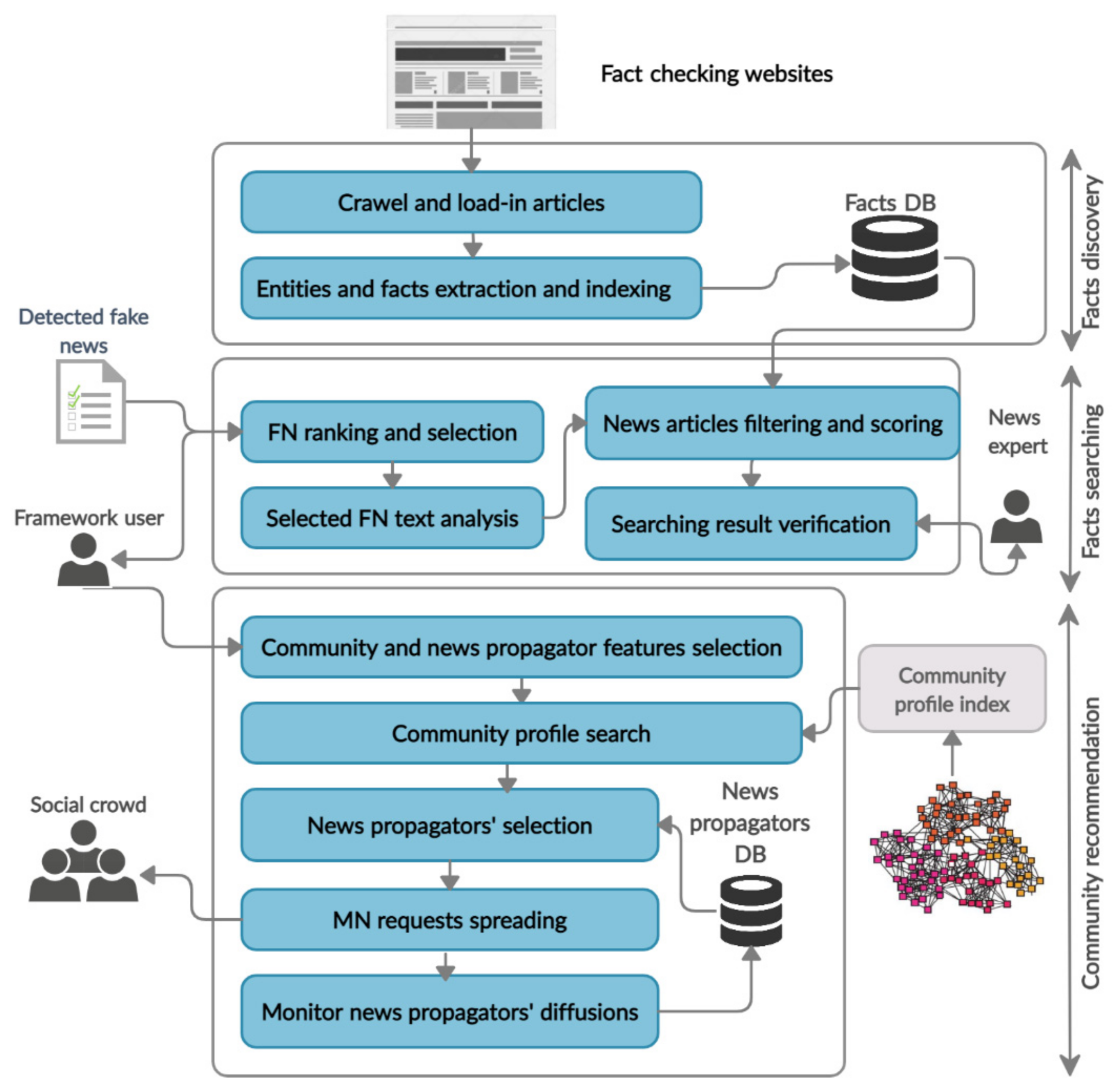
4. The Community-Based News Mitigation Framework (CNMF)
4.1. Phase (1): Facts Discovery
4.2. Phase (2): Facts Searching
4.2.1. FN Ranking and Selection
- -
- FN popularity: FN posts targeting valuable events present high popularity in most cases. Mitigation campaigns based on high current tweet/post popularity is a reactive method to combat FN influence while, following future tweet popularity are considered a proactive combating method.
- -
- Re-share time lag: defines the period between frequent post re-shares. Short time lag exposes viral posts. Re-share time lag interval is specified by the framework user. However, averaging sampled previous viral pieces of FN re-share time lag can provide a convenient indicator to use.
4.2.2. Selected FN Text Analysis
4.2.3. News Articles Filtering and Scoring
4.2.4. Searching Result Verification
4.3. Phase (3): Community Recommendation
4.3.1. Community Selection Features
- Community discussion topics: a FN topic filters communities of interest. Moreover, selecting communities discussing relevant topics widens the circle of news propagation. For example, a FN with ‘Coronavirus’ topic, is relevant to communities discussing ‘viruses’ (i.e., super-topic of ‘Coronavirus’).
- Common community geographic location: this location can be either extracted from the FN post or specified by the framework user. For example, the Coronavirus is a worldwide discussion, meanwhile, the community geographic location helps to mitigate news in specific locations.
- Community topic popularity: quantifies how popular an under discussion topic in a community. Community size: number of community members. Community diffusions: diffusions to other communities of the same or relevant interests.
4.3.2. Community Profile Search
| Algorithm 1. Top-k community selection method. |
| Input: CPI: community profile index, E: set of entities for a given FN, t: time span, T: set of FN main topic, super, and sub-topics, L: geographic location(s), k: number of communities to select. |
| Output: top-k communities with highest topic popularity, geographic location commonality, community size, and community diffusions. |
| 1. Search and filter CPI to find communities mentioning E, and T. |
| 2. Sample community users’ posts over time t, users’ location. |
| 3. |
| 4. Select community size (CS) // number of community members. |
| 5. // topic popularity. |
| 6. then |
| 7. // commonality of geographic location. |
| 8. |
| //Community diffusions, is the diffusion prob. from community to community (relevant community), where |
| 9. End for |
| 10. Rank according to . |
| 11. Select Top-k community. |
4.3.3. News Propagator Selection Features
4.3.4. News Propagators Selection
| Algorithm 2. Greedy budget-based community user selection. |
| Input: Top-k community list, B: mitigation campaign budget, I: a user incentive to distribute a piece of news, t: time span, T: set of FN main topic, super, and sub topics, : previous campaigns news propagators matrix with components () as is the user Id, is the profiled user score, and is the user diffusion in the previous campaign, : diffusion threshold. |
| Output: A set of users users. |
| 1: , // is the influenced users set (neighbors) |
| 2: . |
| 3: matrix of users with components (,,) // : user Id, : user score, and : Influenced users set |
| 4: for from do |
| 5: Set // initialize community users’ matrix |
| 6: { users >= } |
| 7: || = n continue; |
| 8: Sample users’ posts over time t excluding users < , |
| and users with denied requests. |
| 9: Score, and prune users according to selected behavior features. |
| 10: Fill with users, scores, and influenced users. |
| 11: j = 0 |
| 12: while j < n do |
| 13: // |
| 14: |
| 15: |
| 16: |
| 17: Update by deducting influenced users’ instances in |
| 18: j = j + 1 |
| 19: else Delete from |
| 20: end while |
| 21: end for |
4.3.5. Mitigation News Requests Spreading
4.3.6. Monitor News Propagators’ Diffusions
5. Experiments and Discussion
5.1. Mitigation Articles’ Scoring Experiment
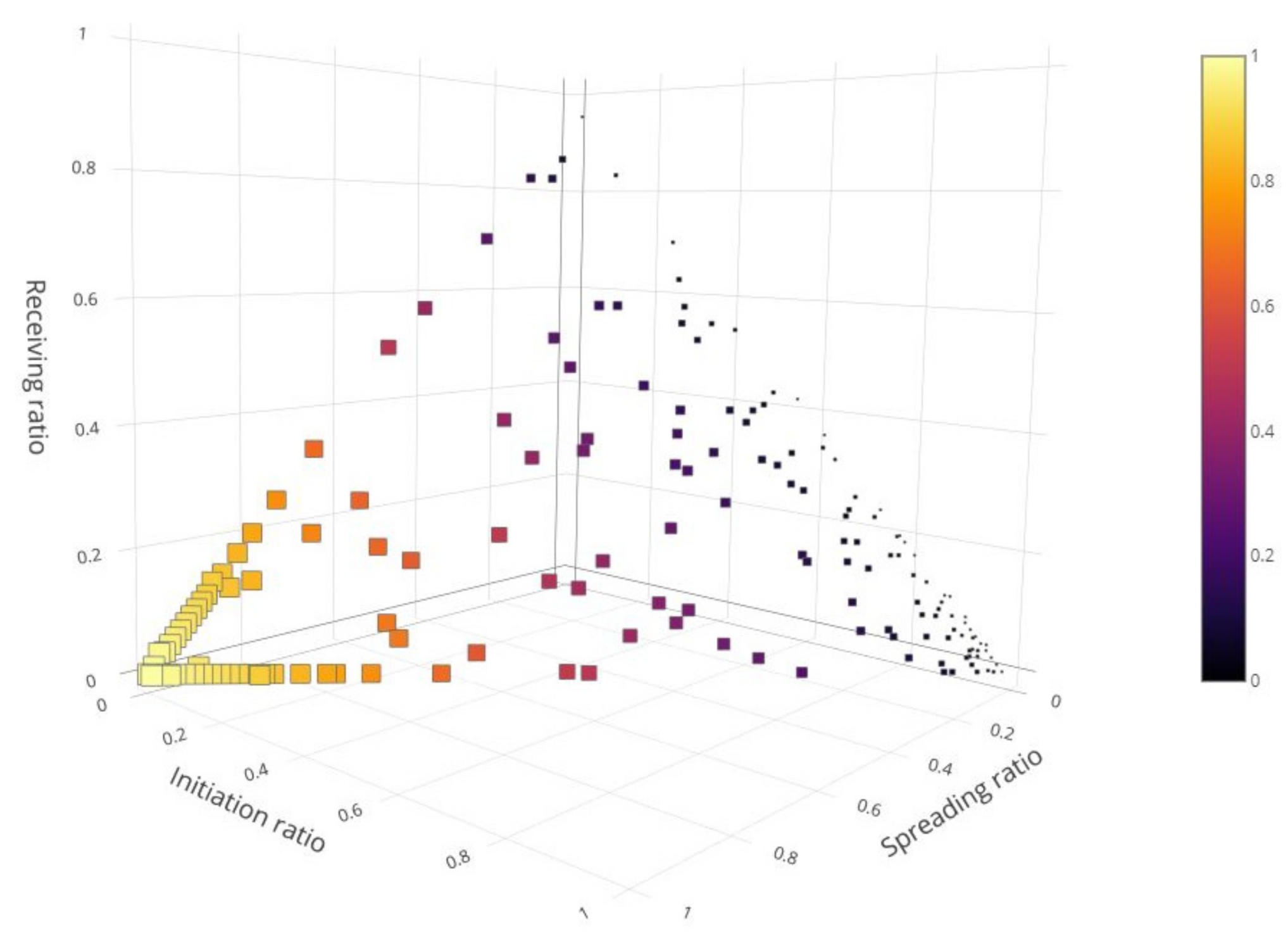
5.2. News Propagators’ Selection Features Experiment
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Farajtabar, M.; Yang, J.; Ye, X.; Xu, H.; Trivedi, R.; Khalil, E.; Li, S.; Song, L.; Zha, H. Fake News Mitigation via Point Process Based Intervention. In Proceedings of the International Conference on Machine Learning, Sydney, Austria, 17 July 2017; pp. 1097–1106. [Google Scholar]
- Duradoni, M.; Collodi, S.; Perfumi, S.C.; Guazzini, A. Reviewing Stranger on the Internet: The Role of Identifiability through “Reputation” in Online Decision Making. Future Internet 2021, 13, 110. [Google Scholar] [CrossRef]
- Pierri, F.; Ceri, S. False News On Social Media: A Data-Driven Survey. SIGMOD Record. 2019, 48, 18–27. [Google Scholar] [CrossRef]
- Gupta, A.; Kumaraguru, P.; Castillo, C.; Meier, P. Tweetcred: Real-time credibility assessment of content on twitter. In Proceedings of the International Conference on Social Informatics, Barcelona, Spain, 11–13 November 2014; Volume 8851, pp. 228–243. [Google Scholar]
- Tschiatschek, S.; Singla, A.; Gomez Rodriguez, M.; Merchant, A.; Krause, A. Fake News Detection in Social Networks via Crowd Signals. In Proceedings of the The Web Conference, Lyon, France, 23–27 April 2018; pp. 517–524. [Google Scholar]
- Facebook. How is Facebook Addressing False News. Available online: https://www.facebook.com/help/1952307158131536 (accessed on 25 January 2021).
- Shu, K.; Bernard, H.R.; Liu, H. Studying Fake News via Network Analysis: Detection and Mitigation. Emerg. Res. Chall. Oppor. Comput. Soc. Netw. Anal. Min. Springer 2019, 8, 43–65. [Google Scholar]
- Sharma, K.; Qian, F.; Jiang, H.; Ruchansky, N.; Zhang, M.; Liu, Y. Combating fake news: A survey on identification and mitigation techniques. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–42. [Google Scholar] [CrossRef]
- Amoruso, M.; Anello, D.; Auletta, V.; Cerulli, R.; Ferraioli, D.; Raiconi, A. Contrasting the spread of misinformation in online social networks. J. Artif. Intell. Res. 2020, 69, 847–879. [Google Scholar] [CrossRef]
- Pham, C.V.; Phu, Q.V.; Hoang, H.X. Targeted misinformation blocking on online social networks. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Dong Hoi City, Vietnam, 19–21 March 2018. [Google Scholar]
- Song, C.; Hsu, W.; Lee, M.L. Temporal influence blocking: Minimizing the effect of misinformation in social networks. In Proceedings of the International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017. [Google Scholar]
- Saxena, A.; Saxena, H.; Gera, R. Competitive Influence Propagation and Fake News Mitigation in the Presence of Strong User Bias. arXiv 2020, arXiv:2011.04857. [Google Scholar]
- Vicario, M.D.; Quattrociocchi, W.; Scala, A.; Zollo, F. Polarization and fake news: Early warning of potential misinformation targets. ACM Trans. Web 2019, 13, 1–22. [Google Scholar] [CrossRef]
- Horne, B.D.; Gruppi, M.; Adali, S. Trustworthy misinformation mitigation with soft information nudging. In Proceedings of the 2019 First IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Los Angeles, CA, USA, 12–14 December 2019. [Google Scholar]
- Vo, N.; Lee, K. The Rise of Guardians. In Proceedings of the The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 275–284. [Google Scholar]
- Zhao, Q.; Erdogdu, M.A.; He, H.Y.; Rajaraman, A.; Leskovec, J. SEISMIC: A self-exciting point process model for predicting tweet popularity. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1513–1522. [Google Scholar]
- Nguyen, N.P.; Yan, G.; Thai, M.T.; Eidenbenz, S. Containment of misinformation spread in online social networks. In Proceedings of the 4th Annual ACM Web Science Conference, WebSci’12, Evanston, IL, USA, 22–24 June 2012; Volumes 213–222. [Google Scholar]
- Kempe, D.; Kleinberg, J.; Tardos, É. Maximizing the spread of influence through a social network. Theory Comput. 2015, 11, 105–147. [Google Scholar] [CrossRef]
- Simpson, M.; Srinivasan, V.; Alex, T. Reverse Prevention Sampling for Misinformation Mitigation in Social Networks. arxiv 2018, arXiv:1807.01162. [Google Scholar]
- Rajabi, Z.; Shehu, A.; Purohit, H. User behavior modelling for fake information mitigation on social web. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation, Washington, WA, USA, 9–12 July 2019; pp. 234–244. [Google Scholar]
- Yosef, M.A.; Hoffart, J.; Bordino, I.; Spaniol, M.; Weikum, G. AIDA: An online tool for accurate disambiguation of named entities in text and tables. PVLDB 2011, 4, 1450–1457. [Google Scholar] [CrossRef]
- Yosef, M.A.; Hoffart, J.; Bordino, I.; Spaniol, M.; Weikum, G. AIDA. Available online: https://gate.d5.mpi-inf.mpg.de/webaida/ (accessed on 25 January 2021).
- Suchanek, F.; Kasneci, G.; Weikum, G.; Suchanek, F.; Kasneci, G.; Weikum, G.; Core, Y.A.; Suchanek, F.M.; Weikum, G. Yago: A Core of Semantic Knowledge. In Proceedings of the World Wide Web conference, Banff, AB, Canada, 8–12 May 2017; pp. 697–706. [Google Scholar]
- Magdy, A.; Wanas, N. Web-based statistical fact checking of textual documents. Int. Conf. Inf. Knowl. Manag. 2010, 103–109. [Google Scholar]
- Hassan, N.; Sultana, A.; Wu, Y.; Zhang, G.; Li, C.; Yang, J.; Yu, C. Data in, fact out: Automated monitoring of facts by FactWatcher. PVLDB 2014, 7, 1557–1560. [Google Scholar] [CrossRef] [Green Version]
- Wikipedia. Wikipedia Topics Hierarchy. Available online: https://en.wikipedia.org/wiki/Portal:Contents/Categories# (accessed on 25 January 2021).
- Tweet Classifier. Available online: https://app.monkeylearn.com/ (accessed on 25 January 2021).
- Han, X.; Wang, L.; Farahbakhsh, R.; Cuevas, Á.; Cuevas, R.; Crespi, N.; He, L. CSD: A multi-user similarity metric for community recommendation in online social networks. Expert Syst. Appl. 2016, 53, 14–26. [Google Scholar] [CrossRef]
- Royy, S.B.; Lakshmanan, L.V.S.; Liuy, R. From group recommendations to group formation. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 31 May–4 June 2015; pp. 1603–1616. [Google Scholar]
- Cai, H.; Zheng, V.W.; Zhu, F.; Chang, K.C.C.; Huang, Z. From community detection to community profiling. PVLDB 2017, 10, 817–828. [Google Scholar] [CrossRef]
- Nakov, P.; Ritter, A.; Rosenthal, S.; Sebastiani, F.; Stoyanov, V. SemEval-2016 task 4: Sentiment analysis in twitter. In Proceedings of the SemEval 2016-10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 1–18. [Google Scholar]
- Sobhani, P.; Mohammad, S.M.; Kiritchenko, S. Detecting stance in tweets and analyzing its interaction with sentiment. In Proceedings of the SEM 2016-5th Joint Conference on Lexical and Computational Semantics, Berlin, Germany, 11–21 August 2016; pp. 159–169. [Google Scholar]
- Rajaraman, A.; Ullman, J. Data Mining: Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2011; pp. 1–17. [Google Scholar]
- Ask FactCheck. 2020. Available online: https://www.factcheck.org/ask-factcheck/ask-us-a-question/ (accessed on 25 January 2021).
- Weiss, N.A.; Hassett, M.J. Introductory Statistics; Pearson Education: London, UK, 2012. [Google Scholar]
- Duradoni, M.; Paolucci, M.; Bagnoli, F.; Guazzini, A. Fairness and Trust in Virtual Environments: The Effects of Reputation. Future Internet 2018, 10, 50. [Google Scholar] [CrossRef] [Green Version]
- Yan, S.; Tang, S.; Pei, S.; Jiang, S.; Zhang, X.; Ding, W.; Zheng, Z. The spreading of opposite opinions on online social networks with authoritative nodes. Phys. A Stat. Mech. Appl. 2013, 392, 3846–3855. [Google Scholar] [CrossRef]
- Hassan, N.; El-sharkawi, M.E.; El-tazi, N. Measuring User ’s Susceptibility to Influence in Twitter. In Proceedings of the Social Data Analytics and Management Workshop, co-located with VLDB, New Delhi, India, 9 September 2016. [Google Scholar]
- Gao, Z.; Shi, Y.; Chen, S. Identifying influential nodes for efficient routing in opportunistic networks. J. Commun. 2015, 10, 48–54. [Google Scholar] [CrossRef] [Green Version]
- Twitter Developer API. Available online: https://developer.twitter.com/en (accessed on 25 January 2021).
- Augenstein, I.; Lioma, C.; Wang, D.; Lima, L.C.; Hansen, C.; Hansen, C.; Simonsen, J.G. MultIFC: A real-world multi-domain dataset for evidence-based fact checking of claims. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Bangkok, Tailand, 1–6 August 2020; pp. 4685–4697. [Google Scholar]
- Augenstein, I.; Lioma, C.; Wang, D.; Lima, L.C.; Hansen, C.; Hansen, C. Evidence-Based Fact Checkinh of Claims. 2020. Available online: https://competitions.codalab.org/competitions/21163 (accessed on 25 January 2021).
- TextRazor. TextRazor. Available online: https://www.textrazor.com/ (accessed on 25 January 2021).
- Chok, N.S. Pearson’s Versus Spearman’s and Kendall’s Correlation Coefficients for Continuous Data. PhD Thesis, University of Pittsburgh, Pittsburgh, PA, USA, 2010. [Google Scholar]
- Kutner, M.H.; Nachtsheim, C.J.; Neter, J.; Li, W. Applied Linear Statistical Models, 5th ed.; Mc Graw Hill: New York, NY, USA, 2013. [Google Scholar]
- Hui, P.-M.; Shao, C.; Flammini, A.; Menczer, F.; Ciampaglia, G.L. The hoaxy misinformation and fact-checking difusion network. In Proceedings of the In Twelfth International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Hui, P.-M.; Shao, C.; Alessandro Flammini, F.M.; Ciampaglia, G.L. Hoaxy. 2018. Available online: https://hoaxy.iuni.iu.edu/ (accessed on 25 January 2021).
- Digital Marketing. Available online: https://en.wikipedia.org/wiki/Digital_marketing (accessed on 25 January 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Value |
|---|---|
| Claim ID | farg-00118 |
| Claim | GM Korea company announced today that it will cease production and close its Gunsan plant in May of 2018, and they are going to move back to Detroit |
| Claim entities | Location: Gunsan, Korea, and Detroit. Company (work): GM Korea |
| Claim facts (Form 1) | The extracted fact: [‘Detroit’, ‘Gunsan’, ‘Korea’] |
| Claim facts (Form 2) | The extracted fact: [‘Detroit’, ‘Gunsan’, ‘Korea’] + [‘announce’, ‘cease’, ‘close’, ‘move’] |
| Claims # | Articles # | # of Claim Entities | # of Article Entities | # of Claim Facts | # of Article Facts |
|---|---|---|---|---|---|
| 756 | 1657 | 1413 | 20,925 | 674 | 37,832 |
| Pearson’s r coefficient 0.48 | Spearman coefficient 0.9 | ||||
| Clustering Algorithm | Silhoutte | Calinski-Harabaz | Davis-Bouldin |
|---|---|---|---|
| K-Mean | 0.89237 | 3618.65 | 0.195 |
| User Feature | Mean | F-Value | F-Critical | p-Value | ||
|---|---|---|---|---|---|---|
| I | R | P | ||||
| F1: Community Membership | 0.05 | 0.00 | 0.03 | 64.78 | 3.02 | 0.00 |
| F2: Diffusion rate | 0.79 | 0.38 | 0.89 | 58.93 | 3.04 | 0.00 |
| F3: Popularity-rate (favorites count) | 0.97 | 0.40 | 0.94 | 9.64 | 3.03 | 0.00 |
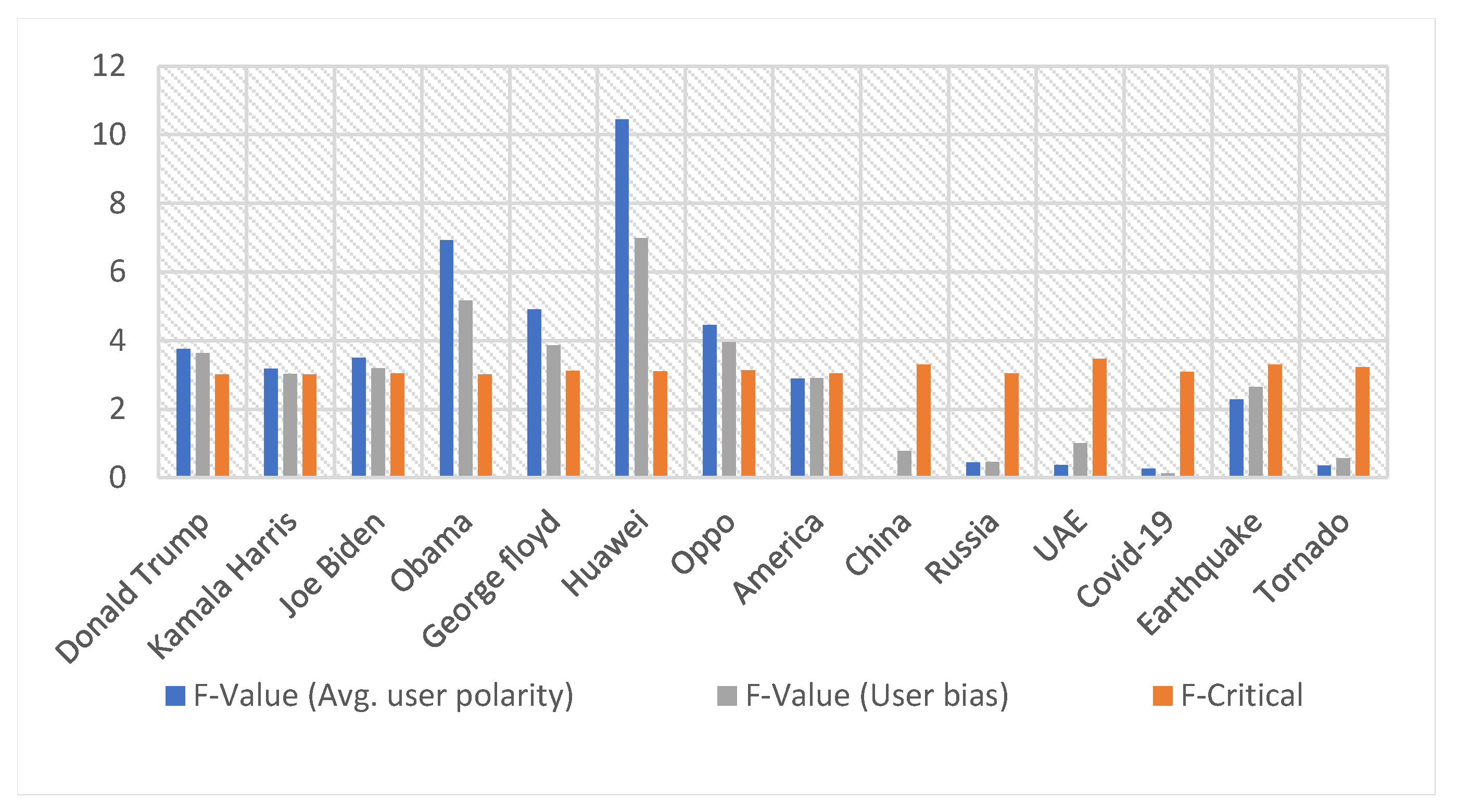
| F4: Average user polarity | 0.03 | 0.01 | 0.52 | 3.75 | 3.01 | 0.02 |
| F5: General user bias | 0.02 | 0.01 | 0.49 | 3.65 | 3.01 | 0.03 |
| F6: User local centrality | 0.01 | 0.01 | 0.03 | 1.88 | 3.17 | 0.17 |
| F7: Local user re-share frequency | 0.01 | 0.02 | 0.02 | 0.24 | 3.17 | 0.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galal, S.; Nagy, N.; El-Sharkawi, M.E. CNMF: A Community-Based Fake News Mitigation Framework. Information 2021, 12, 376. https://doi.org/10.3390/info12090376
Galal S, Nagy N, El-Sharkawi ME. CNMF: A Community-Based Fake News Mitigation Framework. Information. 2021; 12(9):376. https://doi.org/10.3390/info12090376
Chicago/Turabian StyleGalal, Shaimaa, Noha Nagy, and Mohamed. E. El-Sharkawi. 2021. "CNMF: A Community-Based Fake News Mitigation Framework" Information 12, no. 9: 376. https://doi.org/10.3390/info12090376
APA StyleGalal, S., Nagy, N., & El-Sharkawi, M. E. (2021). CNMF: A Community-Based Fake News Mitigation Framework. Information, 12(9), 376. https://doi.org/10.3390/info12090376