


Segmentation Method of Magnetoelectric Brain Image Based on the Transformer and the CNN


Abstract
:1. Introduction
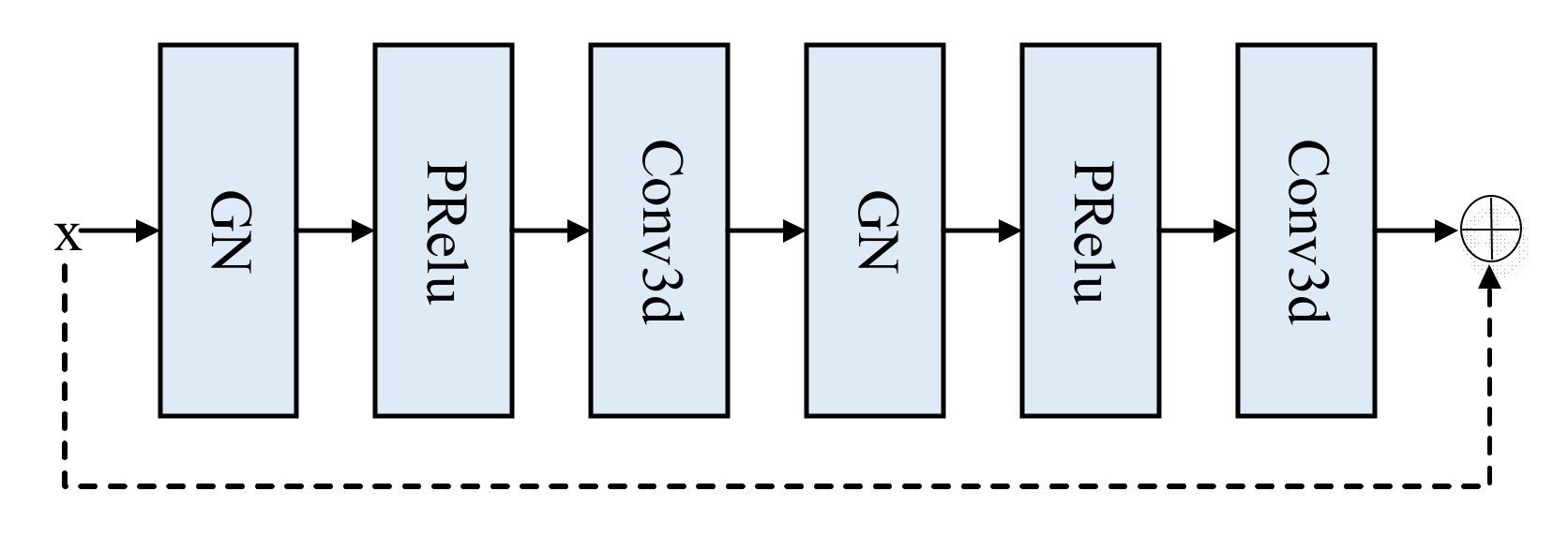
- The residual basis block replaces the traditional stepwise convolution operation, effectively performing deep feature extraction on the original features and maximizing the retention of more learnable feature information.
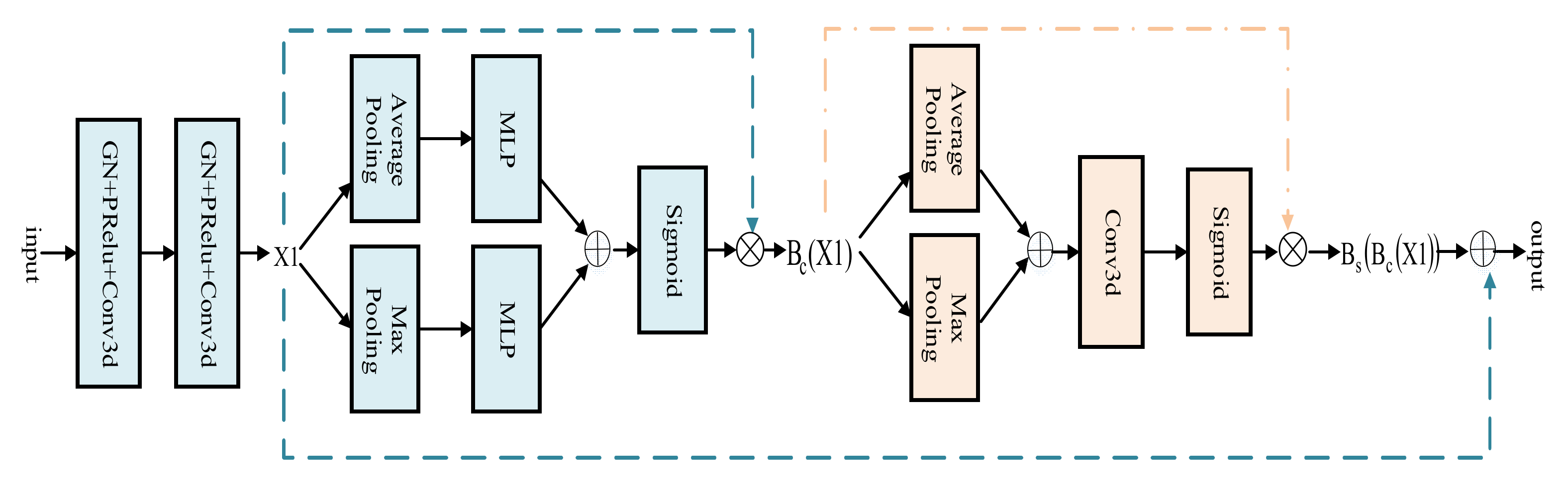
- The 3D BCS channel of the spatially mixed domain attention mechanism module suppresses the tumor irrelevant region information in MRI images, enables more targeted feature extraction, and improves the segmentation limit.
- The encoder operation of Vision Transformer enhances the feature fusion capability to obtain more meaningful information, thus further improving the segmentation accuracy of the algorithm.
- The coupling of two loss functions can enhance the segmentation accuracy of small targets and improve the problem of extreme imbalances in lesion classes.
- The recently released BraTS2021 dataset is used as a benchmark. The advantages of the 3D BCS_T algorithm model are demonstrated through a series of comparison experiments and ablation experiments, which provide more robust diagnostic results.
2. Network Model Construction
2.1. TransBTS Network Architecture
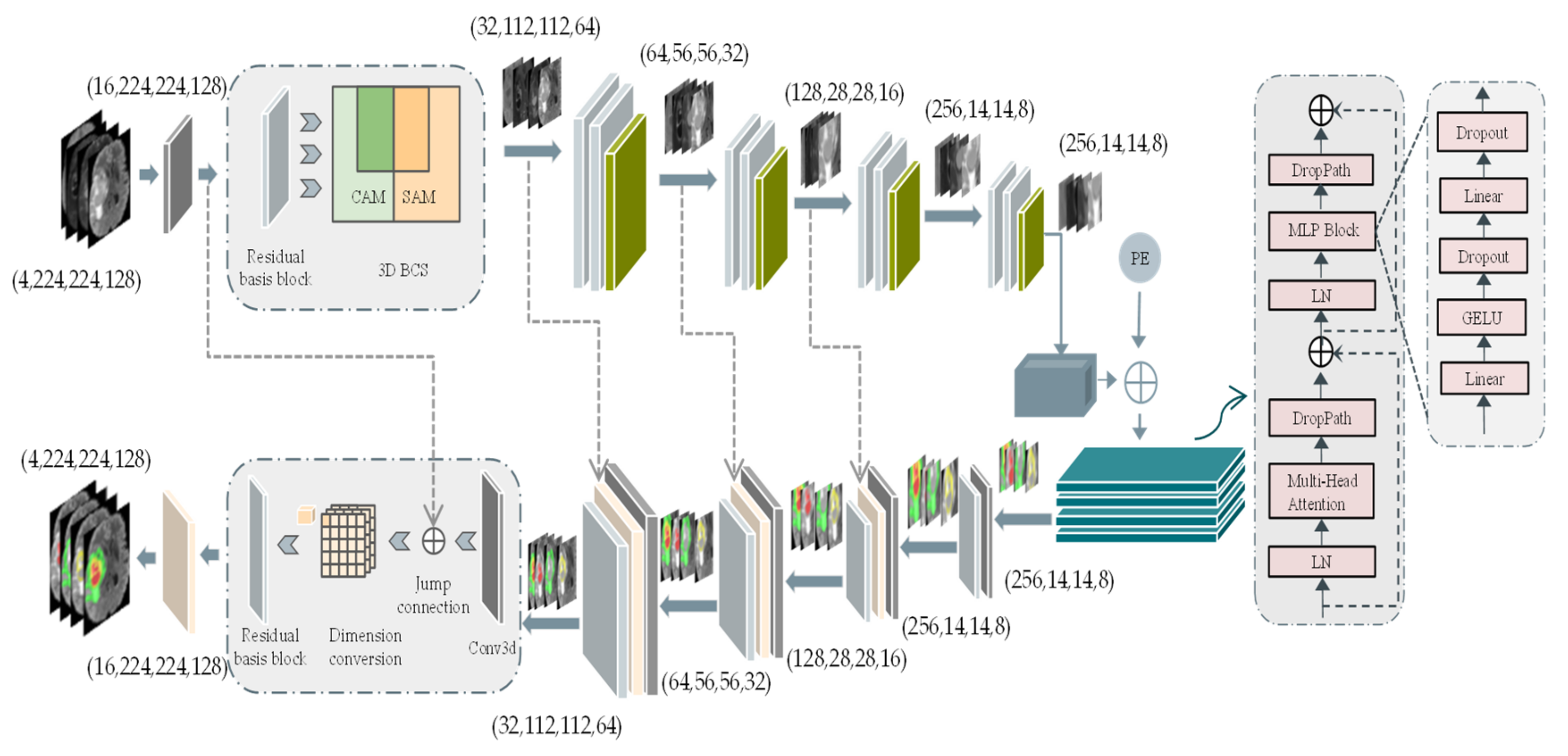
2.2. 3D BCS_T Network Architecture
3. Related Work
3.1. Fundamentals of the Improved Algorithm
3.1.1. 3D BCS Hybrid Domain Attention Mechanism
3.1.2. Mixed Loss Functions
3.2. Multimodal Fusion on MRI Data
3.2.1. MRI Datasets
3.2.2. Data Enhancement
4. Experimental Results and Analysis
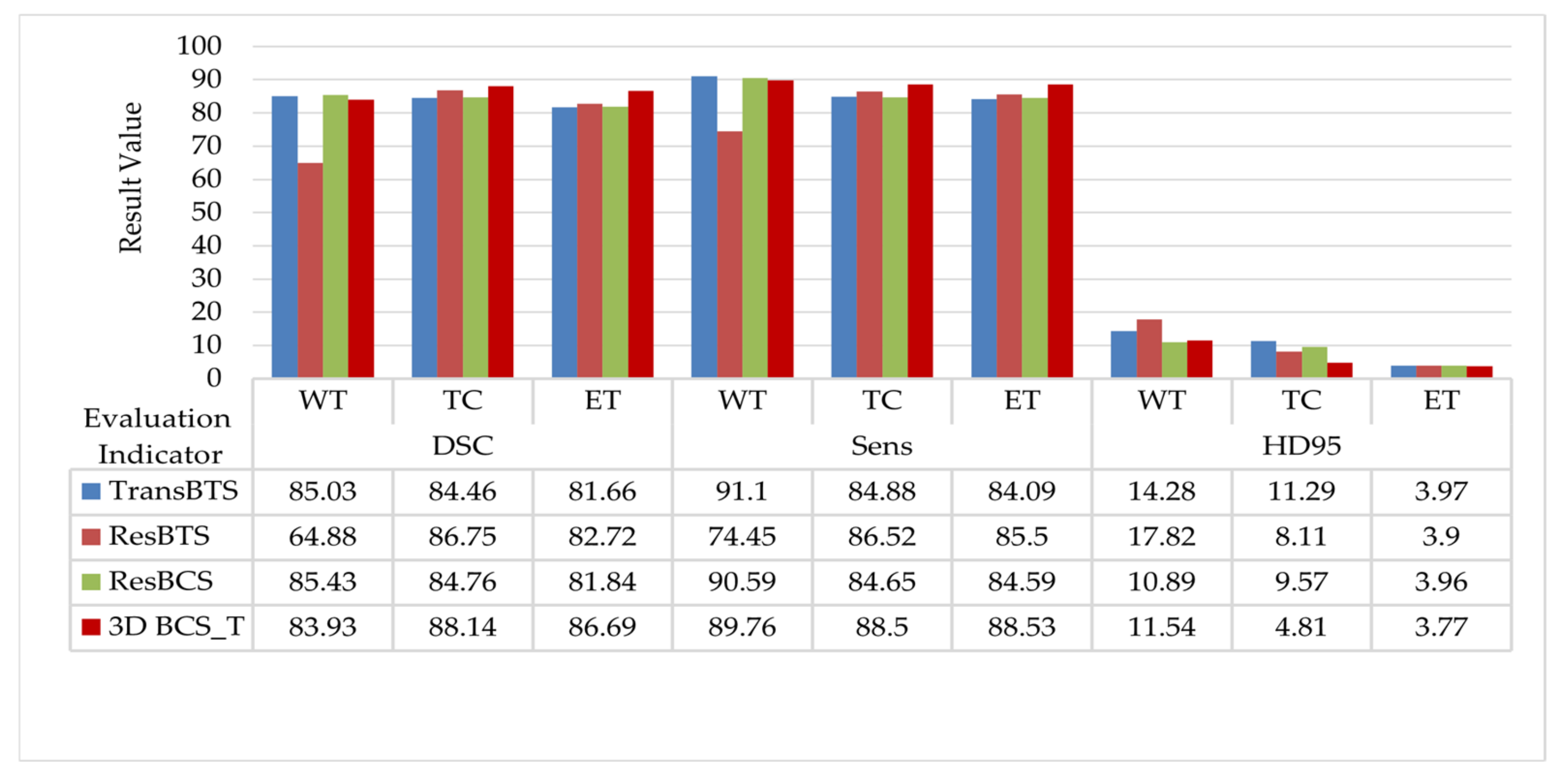
4.1. Experimental Environment and Evaluation Indicators
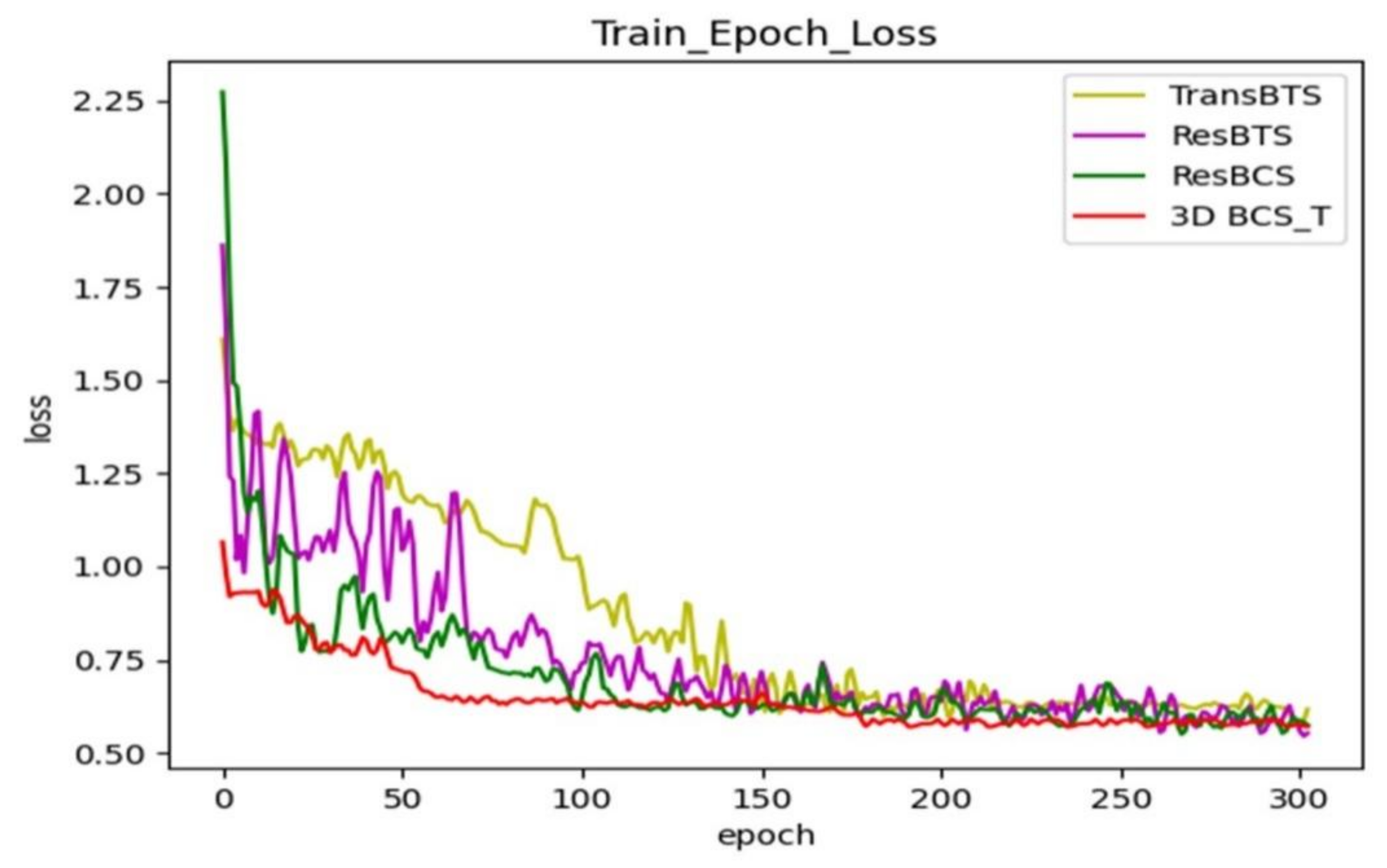
4.2. Analysis of the Ablation Experiments
4.3. Analysis of the Comparative Experiments
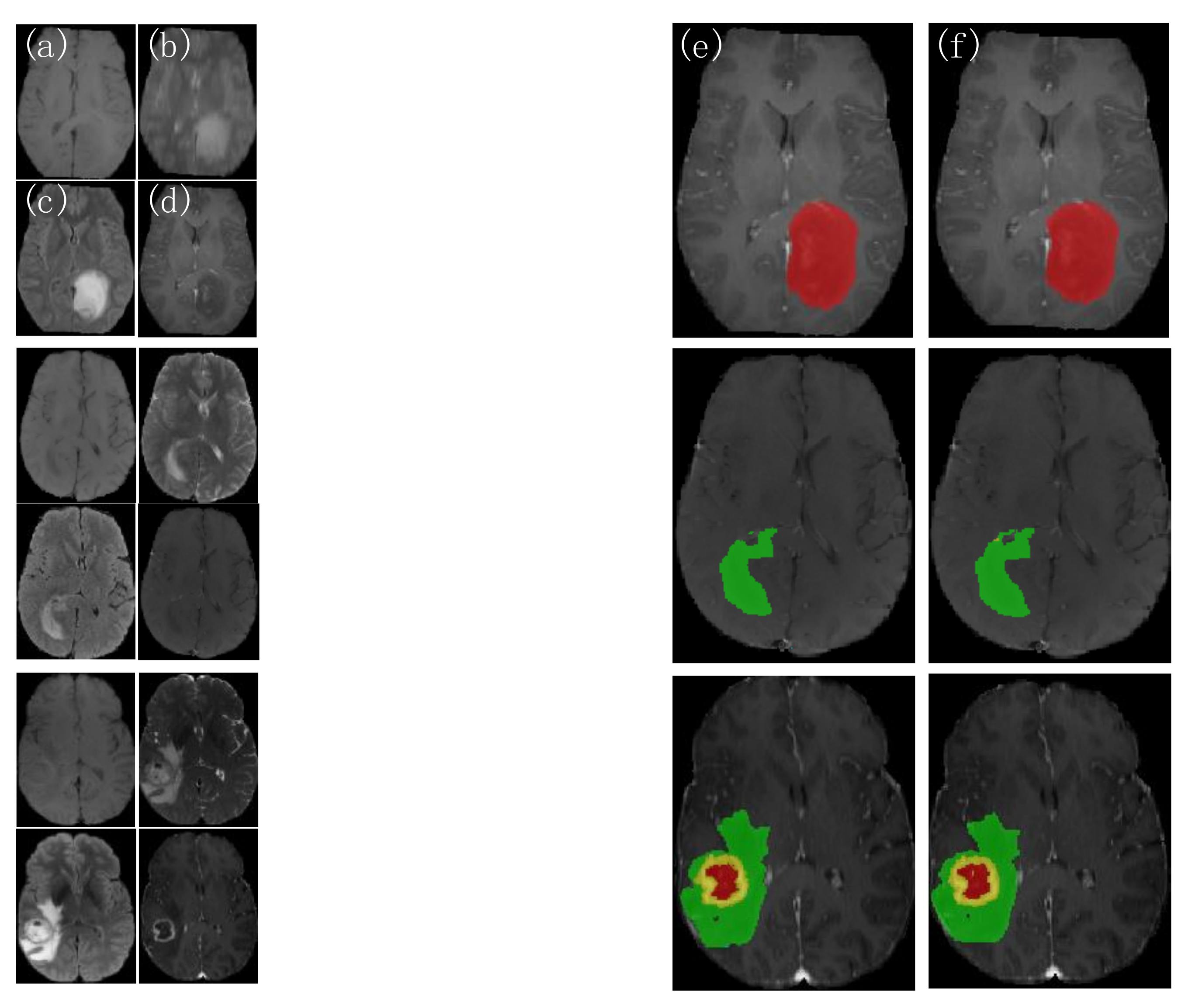
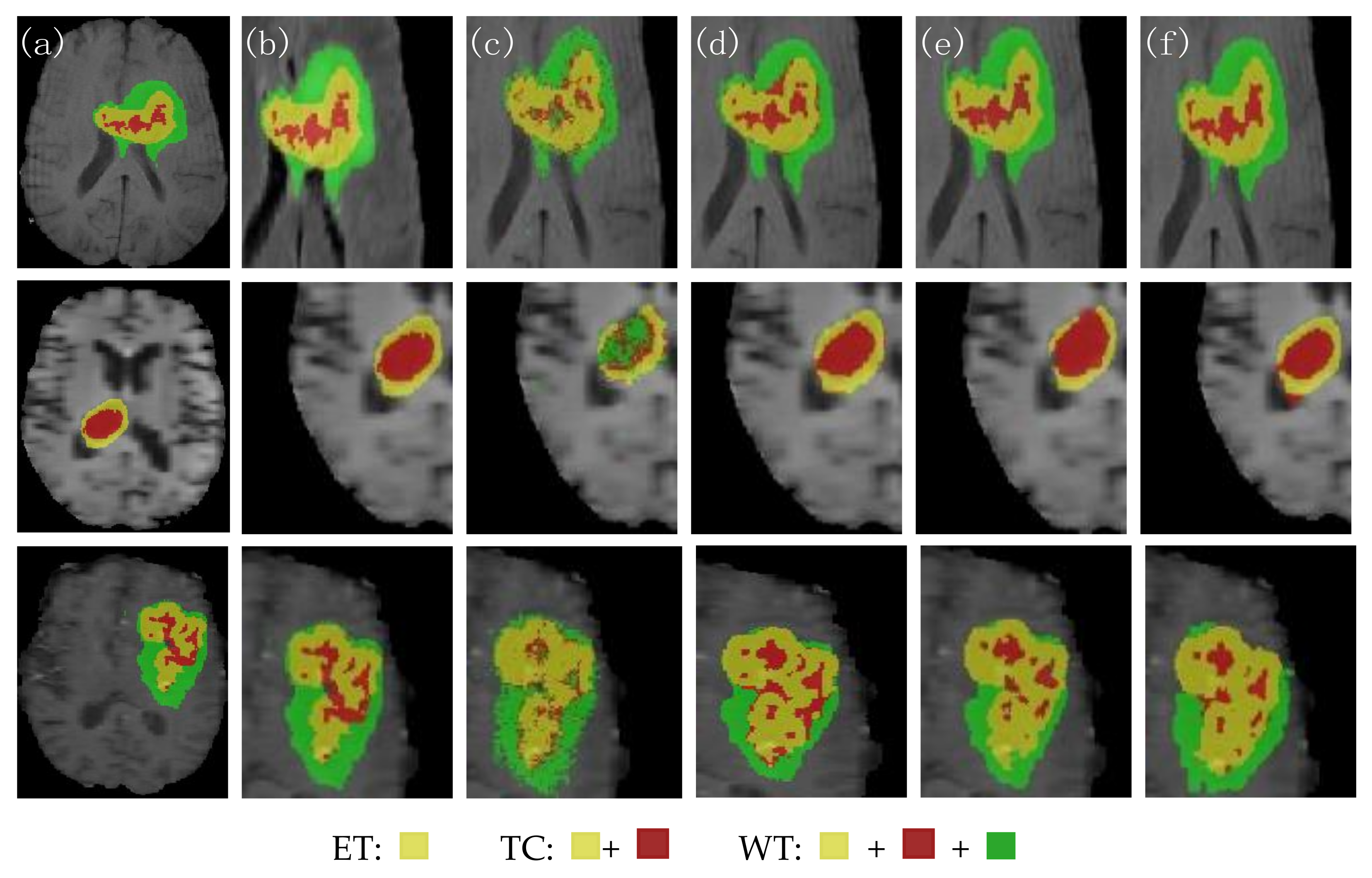
4.3.1. Analysis of the Visualization Results
4.3.2. Analysis of the Datasets Results
- The 3D BCS hybrid domain attention mechanism module helps to improve the model’s recognition of the important feature information, and the residual connectivity enhances the segmentation ability. The hybrid loss function can further improve the segmentation accuracy of small targets and optimize the network performance.
- Our model has a low average deviation and a low dispersion, which allows for the further segmentation of the detailed contour of the model.
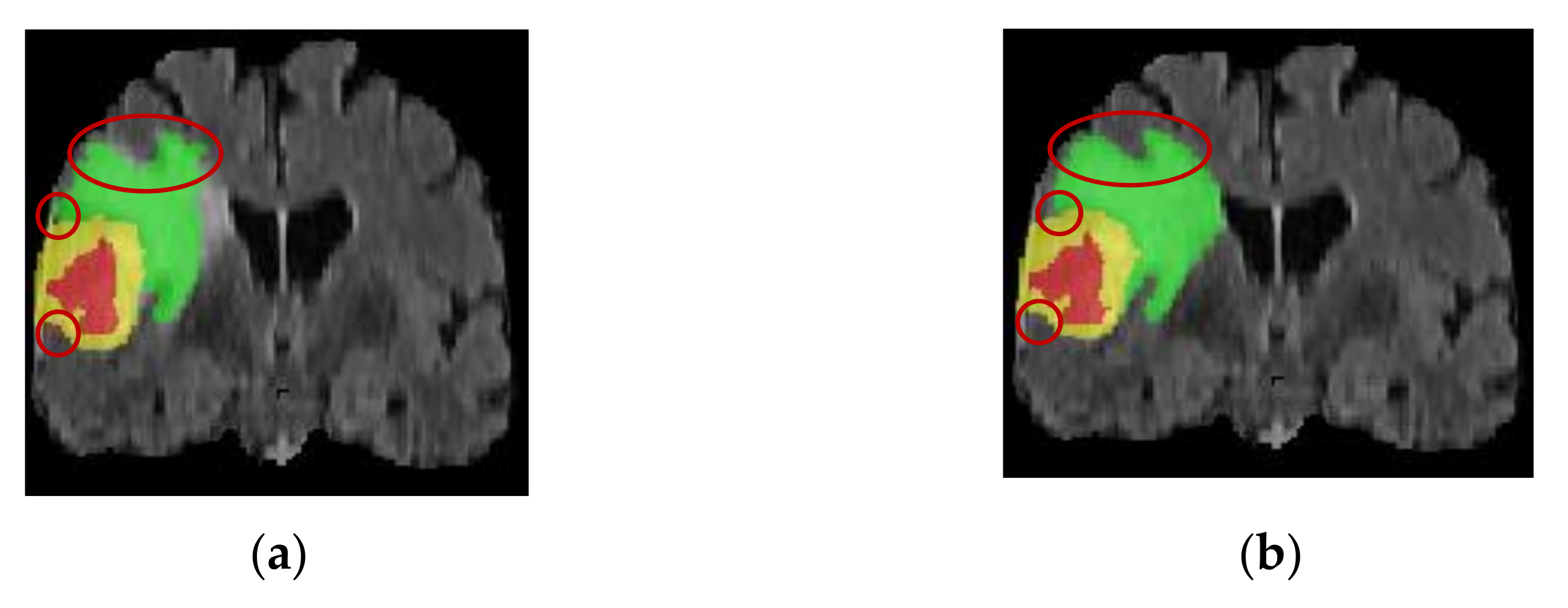
- In terms of the edge determination and accuracy of the ET and TC tumor areas, the model is superior to other SOTA models, which can help doctors accurately determine the precise location of the incision in surgery and protect patients’ healthy tissues from being removed.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MRI | Magnetic resonance imaging |
| T1 | T1-weighted imaging |
| T2 | T2-weighted imaging |
| FLAIR | Fluid attenuated inversion Recovery |
| T1ce | T1-weighted imaging with contrast medium |
| CNN | Convolutional neural network |
| MRFCM | Modified robust fuzzy c-means |
| PRelu | Parametric rectified linear unit |
| MLP | Multilayer perceptron |
| Relu | Reasonable satisfaction linear units |
| WCE | Weighted cross-entropy loss |
| GDL | Generalized Dice loss |
| DSC | Dice similarity coefficient |
| HD95 | Hausdorff 95 |
| CBAM | Convolutional block attention module |
| GT | Ground truth |
References
- Louis, D.N.; Perry, A.; Wesseling, P.; Brat, D.J.; Cree, I.A.; Figarella-Branger, D.; Hawkins, C.; Ng, H.K.; Pfister, S.M.; Reifenberger, G.; et al. The 2021 WHO Classification of Tumors of the Central Nervous System: A summary. Neuro Oncol. 2021, 23, 1231–1251. [Google Scholar] [CrossRef] [PubMed]
- Li, H.Z.; Wu, Y.B.; Sun, W.D.; Guo, Z.Y.; Xie, J.J. Design and implement low field magnetic resonance main Magnet based on Halbach structure. J. Instrum. 2022, 43, 46–56. [Google Scholar]
- He, C.E.; Xu, H.J.; Wang, Z.; Ma, L.P. Automatic segmentation of brain tumor images by multimodal magnetic resonance imaging. Acta Opt. Sin. 2020, 40, 66–75. [Google Scholar]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.F.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Med. Image Anal. 2017, 36, 61–78. [Google Scholar] [CrossRef] [PubMed]
- Song, J.H.; Zhang, Z. A Modified Robust FCM Model with Spatial Constraints for Brain MR Image Segmentation. Information 2019, 10, 74. [Google Scholar] [CrossRef]
- Dvořák, P.; Menze, B. Local Structure Prediction with Convolutional Neural Networks for Multimodal Brain Tumor Segmentation. In Proceedings of the International MICCAI Workshop on Medical Computer Vision, Medical Computer Vision: Algorithms for Big Data, Cham, Switzerland, 1 July 2016; pp. 59–71. [Google Scholar]
- Henry, T.; Carré, A.; Lerousseau, M.; Estienne, T.; Robert, C.; Paragios, N.; Deutsch, E. Brain tumor segmentation with self-ensembled, deep-ly-supervised 3D U-net neural networks: A BraTS 2020 challenge solution. arXiv 2020, arXiv:2011.01045. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.H.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, J.N.; Lu, Y.L.; Yu, Q.H.; Luo, X.D.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y.Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102. 04306. [Google Scholar]
- Wang, W.X.; Chen, C.; Ding, M.; Li, J.Y.; Yu, H.; Zha, S. TransBTS: Multimodal Brain Tumor Segmentation Using Transformer. arXiv 2021, arXiv:2103. 04430. [Google Scholar]
- Chen, H.; Dou, Q.; Yu, L.; Qin, J.; Heng, P.A. VoxResNet: Deep voxelwise residual networks for brain segmentation from 3D MR images. Neuroimage 2018, 170, 446–455. [Google Scholar] [CrossRef]
- Hou, F.Z.; Zou, B.J.; Liu, Z.B.; Zhou, Z.Y. Multi-modal brain MR image tumor segmentation algorithm based on gray distribution matching. Appl. Res. Comput. 2017, 34, 3869–3872. [Google Scholar]
- Chu, J.H.; Li, X.C.; Zhang, J.Q.; Lv, W. Fine segmentation of 3d brain tumor based on cascade convolution network. Laser Optoelectron. Prog. 2019, 56, 75–84. [Google Scholar]
- Ge, T.; Zhan, T.M.; Mou, S.X. Brain tumor segmentation algorithm based on multi-core synergy said classification. J. Nanjing Univ. Sci. Technol. Lancet 2019, 43, 578–585. [Google Scholar]
- Feng, Y.; Li, J.; Zhang, X. Research on Segmentation of Brain Tumor in MRI Image Based on Convolutional Neural Network. BioMed Res. Int. 2022, 2022, 7911801. [Google Scholar] [CrossRef]
- Jia, Q.; Shu, H. BiTr-Unet: A CNN-Transformer Combined Network for MRI Brain Tumor Segmentation. In Brainlesion Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries. BrainLes (Workshop); Springer: Cham, Switzerland, 2021; pp. 3–14. [Google Scholar]
- Hu, G.D.; Qian, F.Y.; Sha, L.G.; Wei, Z.L. Application of Deep Learning Technology in Glioma. J. Healthc Eng. 2022, 2022, 8507773. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Sudre, C.H.; Li, W.Q.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised Dice overlap as a deep learning loss function for highly unbalanced segmentations. arXiv 2017, arXiv:1707.03237. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing the Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Nat. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef]
- Baid, U.; Chodasara, S.; Mohan, S.; Bilello, M.; Calabrese, E.; Colak, E.; Farahani, K. The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification. arXiv 2021, arXiv:2107.02314. [Google Scholar]
- Kaur, G.; Rana, P.S.; Arora, V. State-of-the-art techniques using pre-operative brain MRI scans for survival prediction of glioblastoma multiforme patients and future research directions. Clin. Transl. Imaging 2022, 3, 355–389. [Google Scholar] [CrossRef]
- Adaloglou, M.N. Deep Learning in Medical Image Analysis: A Comparative Analysis of Multi-Modal Brain-MRI Segmentation with 3D Deep Neural Networks. Master’s Thesis, University of Patras, Patra, Greece, 2019. [Google Scholar]
- Ma, X.Z. Apollo: An Adaptive Parameter-wise Diagonal Quasi-Newton Method for Nonconvex Stochastic Optimization. arXiv 2020, arXiv:2009.13586. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Year | Technology | D.V.S | D.E. | R.C | A.M.O | L.F.O |
|---|---|---|---|---|---|---|---|
| [11] | 2016 | VoxResNet | 20 | × | √ | × | × |
| [12] | 2017 | Grayscale indexing match | 50 | × | × | × | × |
| [13] | 2018 | Vnet | 285 | √ | × | × | √ |
| [14] | 2019 | Cooperative representation | 65 | × | × | × | × |
| [7] | 2020 | 3D Unet | 369 | √ | × | √ | × |
| [10] | 2021 | TransBTS | 369 | √ | × | × | × |
| [15] | 2021 | CNN Transformer | 1251 | √ | × | × | × |
| [16] | 2022 | CNN | 65 | × | × | × | × |
| Ours | 2022 | CNN Transformer | 1251 | √ | √ | √ | √ |
| Symbol | Implication |
|---|---|
| m | Number of categories |
| w | Weighting |
| n | Number of pixel points |
| The actual value of the segmented label graph given by the data | |
| A predicted probability value of a pixel belonging to category j | |
| The actual value of category j at pixel i | |
| A predicted probability value of category j at pixel i |
| Type | Percentage | Number | Scramble Order | Data Enhancement | Total Number |
|---|---|---|---|---|---|
| Training set | 90 | 1126 | √ | √ | 4504 |
| Test set | 10 | 125 | √ | × | 125 |
| Network | DSC (%) | |||
|---|---|---|---|---|
| ET | TC | WT | AVG | |
| 3D Unet | 72.41 | 73.67 | 74.99 | 73.69 |
| CBAM Unet | 80.81 | 82.89 | 83.77 | 82.49 |
| Network | DSC (%) | Sens (%) | HD95 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | WT | TC | ET | WT | TC | ET | |
| 3D Unet | 75.60 | 72.70 | 70.19 | 88.55 | 81.62 | 84.16 | 75.6 | 72.7 | 70.19 |
| CBAM Unet | 85.18 | 81.85 | 78.03 | 90.75 | 86.24 | 85.71 | 25.49 | 8.92 | 8.52 |
| TransBTS | 85.03 | 84.46 | 81.66 | 91.10 | 84.88 | 84.09 | 14.28 | 11.29 | 3.97 |
| 3D BCS_T | 83.93 | 88.14 | 86.69 | 89.76 | 88.50 | 88.53 | 11.54 | 4.81 | 3.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Cheng, X. Segmentation Method of Magnetoelectric Brain Image Based on the Transformer and the CNN. Information 2022, 13, 445. https://doi.org/10.3390/info13100445
Liu X, Cheng X. Segmentation Method of Magnetoelectric Brain Image Based on the Transformer and the CNN. Information. 2022; 13(10):445. https://doi.org/10.3390/info13100445
Chicago/Turabian StyleLiu, Xiaoli, and Xiaorong Cheng. 2022. "Segmentation Method of Magnetoelectric Brain Image Based on the Transformer and the CNN" Information 13, no. 10: 445. https://doi.org/10.3390/info13100445
APA StyleLiu, X., & Cheng, X. (2022). Segmentation Method of Magnetoelectric Brain Image Based on the Transformer and the CNN. Information, 13(10), 445. https://doi.org/10.3390/info13100445