

Image Retrieval Algorithm Based on Locality-Sensitive Hash Using Convolutional Neural Network and Attention Mechanism


Abstract
:1. Introduction
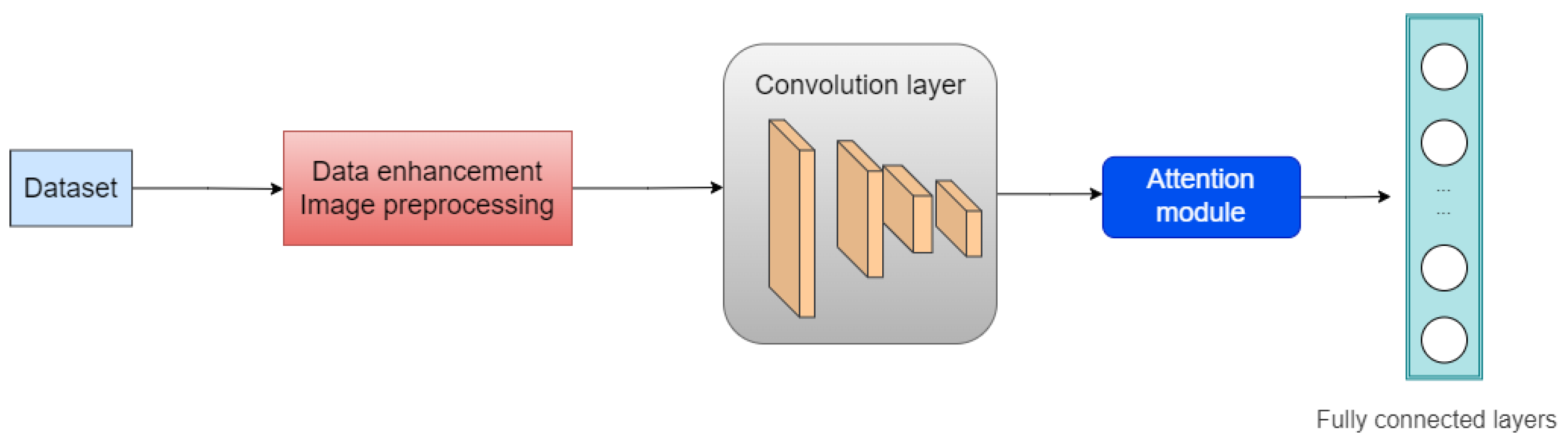
- Preprocessing before CNN training. Adopting standard data enhancement methods for existing training data, such as random scaling, rotation, clipping, noise addition and color contrast change, to increase the sample size, avoiding overfitting and promoting the robustness of the model.
- By adding a simple and effective attention module (CBAM) to the Convolutional Neural Network, it can be extensively adopted to promote the representation ability of CNN and improve image retrieval accuracy to a certain extent.
- According to the features extracted by CNN, a locality-sensitive hashing dimension reduction method is designed to build a hash index, which solves the problem of large-scale and high-dimensional images and greatly shortens the retrieval time.
2. Related Work
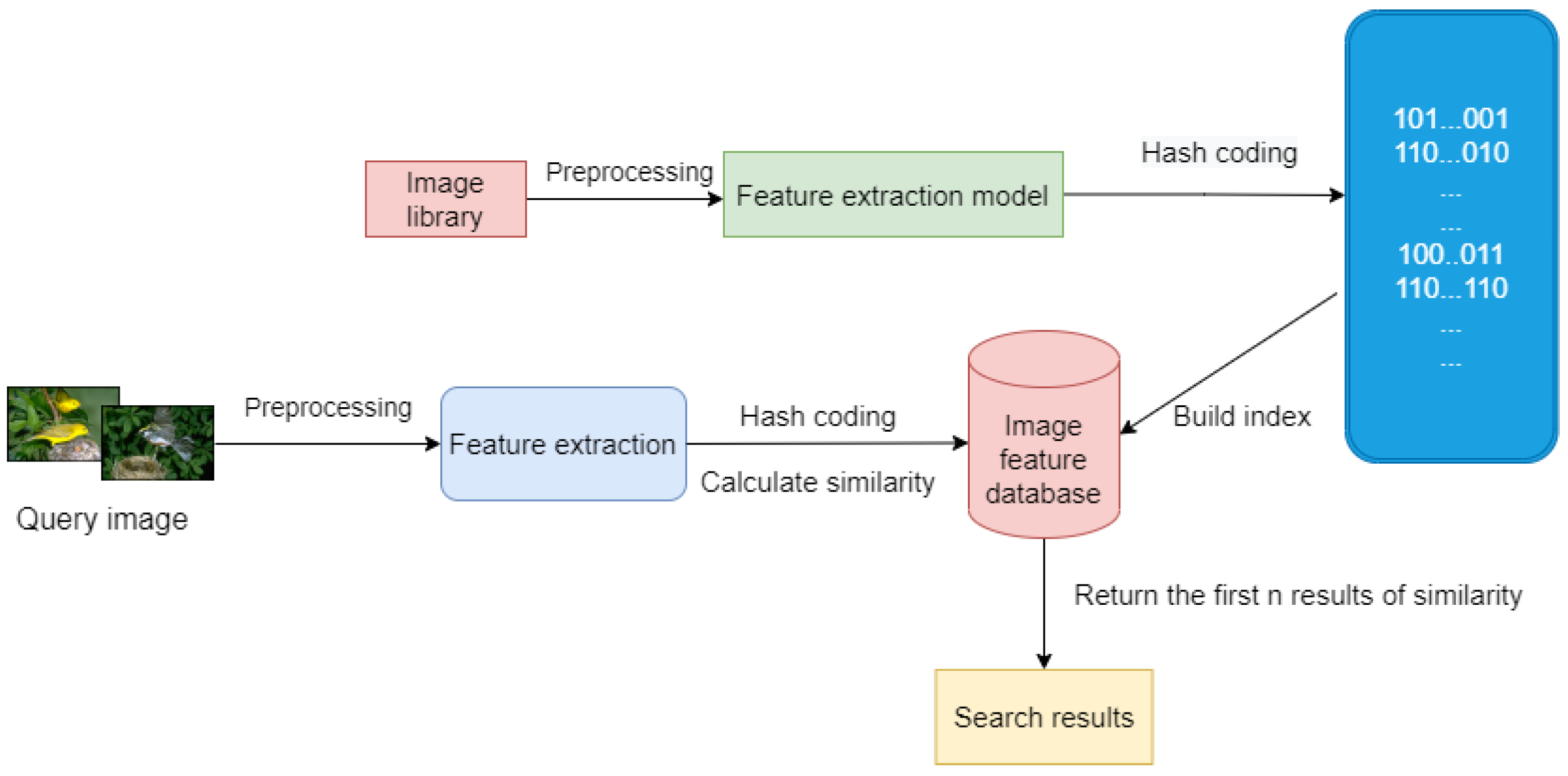
3. Image Retrieval Framework Based on Locality-Sensitive Hash Using CNN and Attention Mechanism
3.1. Feature Extraction
Image Preprocessing
- (1)
- Image size processing. The image dimension of the image database used in this study is 192 × 128 and 128 × 192, and the size is inconsistent. The size is processed as 192 × 192 to maintain the original characteristics.
- (2)
- Mean and normalization. In the mean removal process, the mean value is subtracted from the RGB 3D, and the image data is centered to 0 to prevent overfitting, see Formula (1). For normalization processing, calculate the RGB maximum value, and compress the image data between 0–1. After normalization processing, the data can better respond to the activation function and improve its expressiveness of the data. The conversion function of the data is shown in Formula (2).
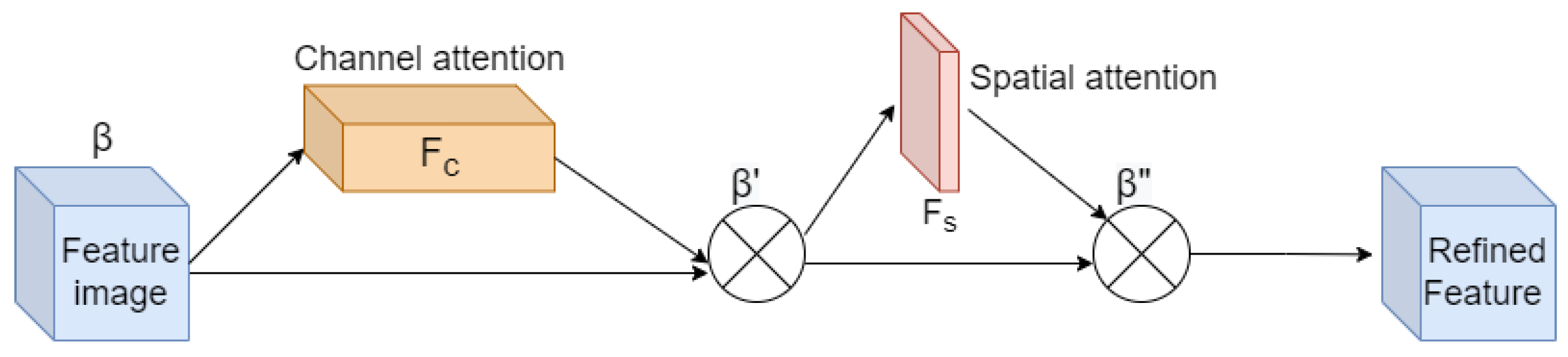
3.2. Using Attention Mechanism (CBAM) to Improve Retrieval Accuracy
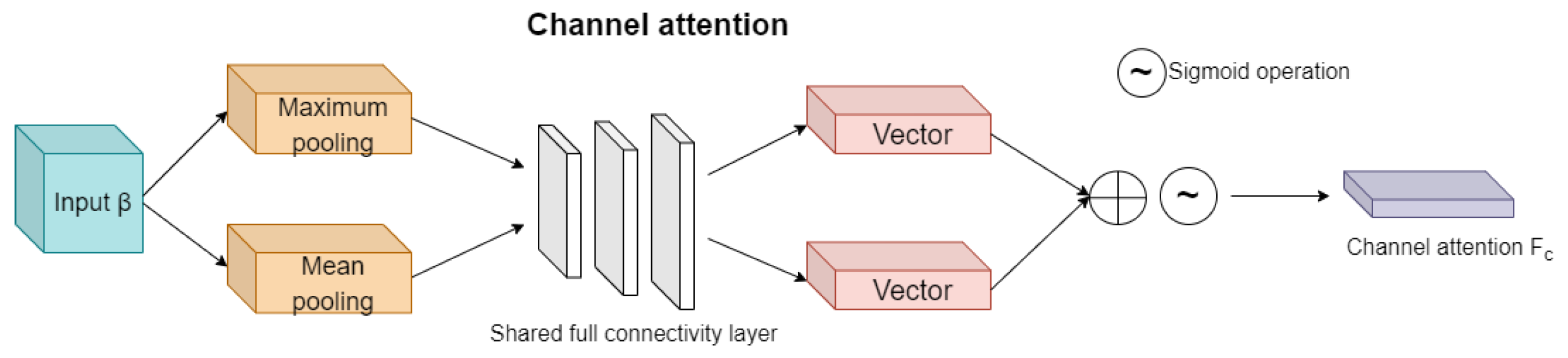
3.2.1. Channel Attention Module
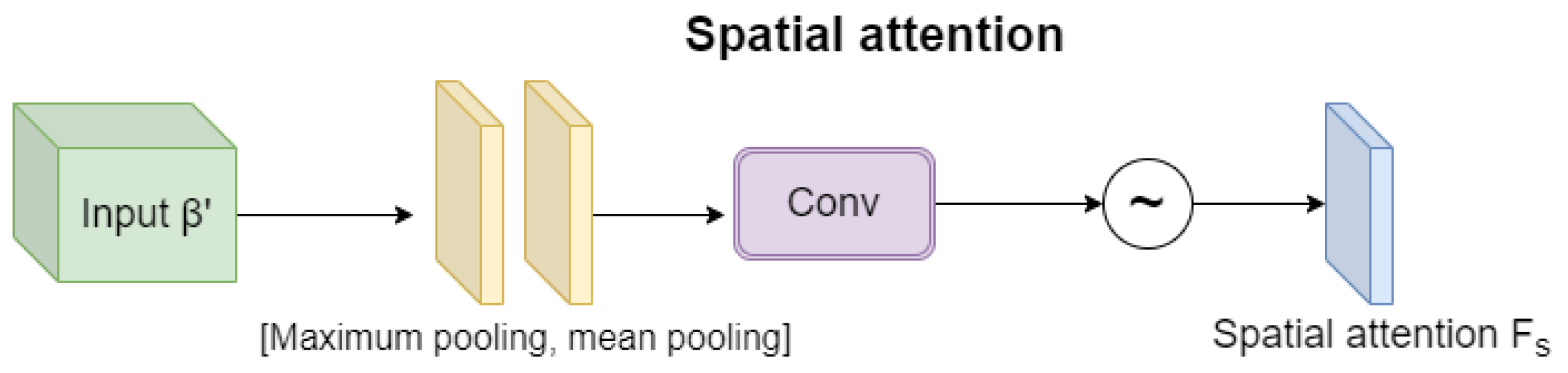
3.2.2. Spatial Attention Module
3.3. Using Local-Sensitive Hash Algorithm to Improve Retrieval Speed
- (1)
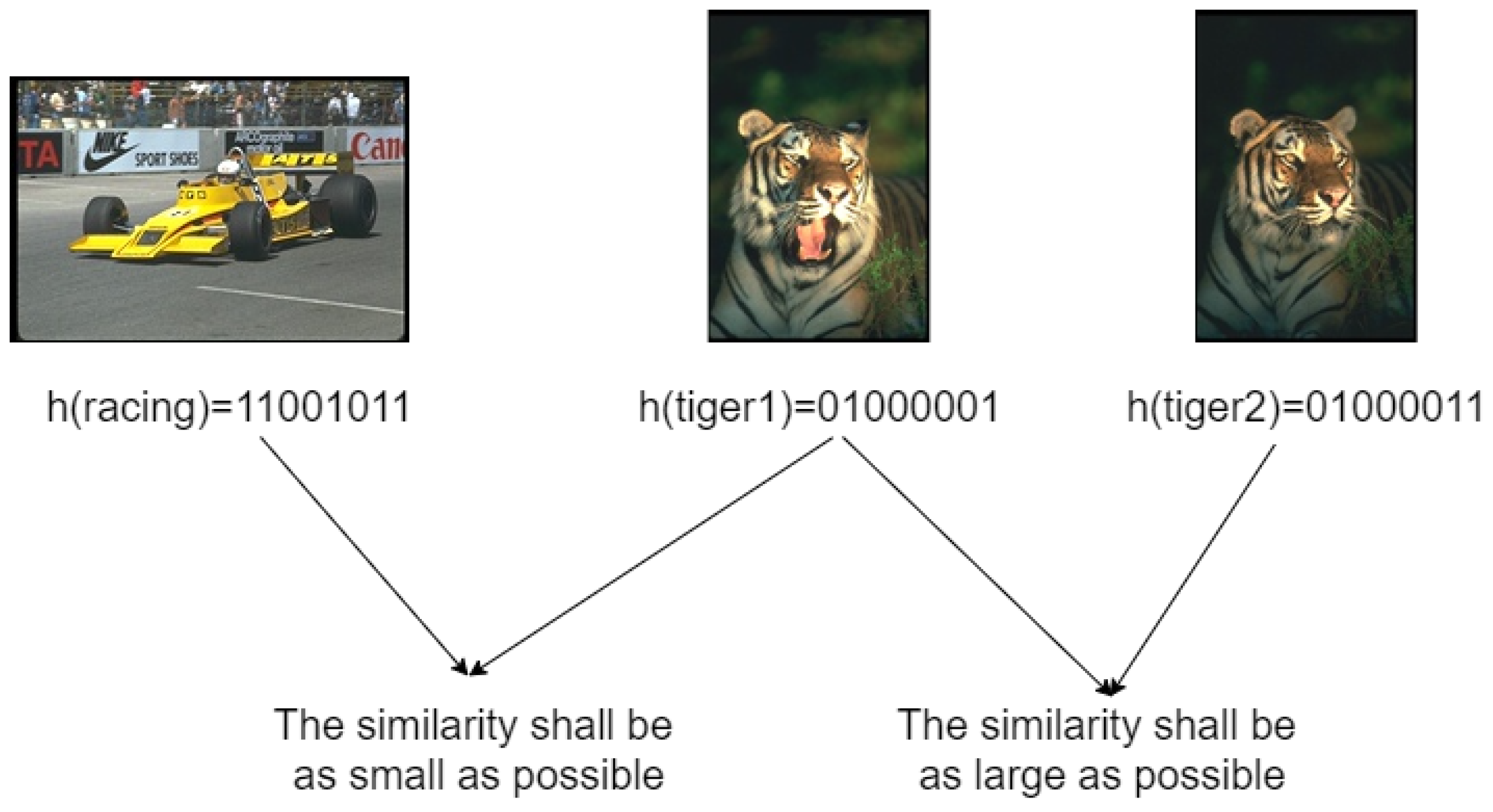
- Similarity measure and LSH hash function
- (2)
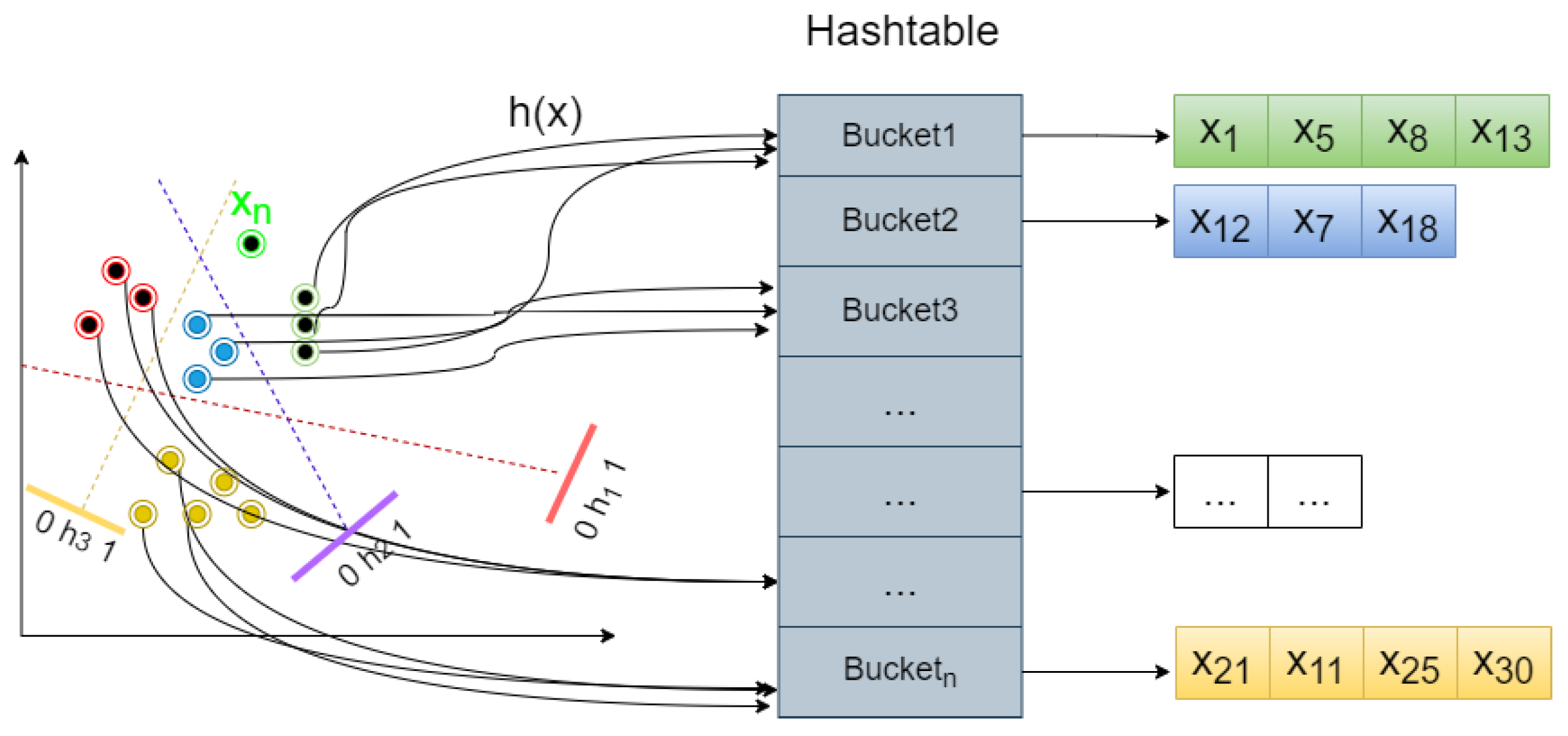
- Building Index
- Calculate a hash function to store similar points in the same bucket.
- For a new query point , calculate that should belong to a certain slot.
- (3)
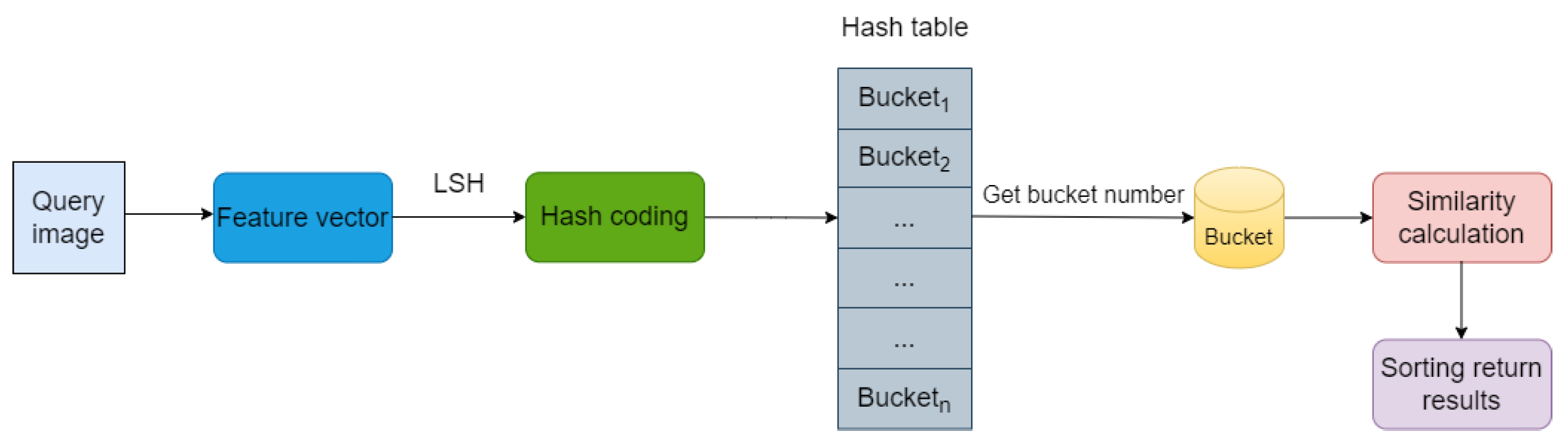
- Online Searching
4. Experimental Results and Analysis
4.1. Experimental Environment
4.2. Data Sets
4.3. Evaluating Indicator
4.4. Performance Evaluation
4.4.1. Performance Comparison
4.4.2. Comparison of Retrieval Time of Different Methods
4.4.3. Model Robustness
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Qu, H.; Xu, J.; Wang, J. Texture image retrieval based on fusion of local and global features. Multimed. Tools Appl. 2022, 81, 14081–14104. [Google Scholar] [CrossRef]
- Mohite, N.B.; Gonde, A.B. Deep features based medical image retrieval. Multimed. Tools Appl. 2022, 81, 11379–11392. [Google Scholar] [CrossRef]
- Xiong, B.; Lou, L.; Meng, X.; Ma, H.; Wang, Z. Short-term wind power forecasting based on Attention Mechanism and Deep Learning. Electr. Power Syst. Res. 2022, 206, 107776. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, R.; Huang, Q. Weakly supervised information fine-grained image recognition based on deep neural network. J. Electron. Meas. Instrum. 2020, 32, 8. [Google Scholar]
- Qin, J.; Pan, W.; Xiang, X.; Tan, Y.; Hou, G. A biological image classification method based on improved CNN. Ecol. Inform. 2020, 58, 101093. [Google Scholar] [CrossRef]
- Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Large-Scale Image Retrieval with Attentive Deep Local Features. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, Z.; Li, S.; Liu, Y.; Li, H. Hand-drawn image retrieval method based on attention model. Comput. Sci. 2020, 47, 6. [Google Scholar]
- Ng, T.; Balntas, V.; Tian, Y.; Mikolajczyk, K. SOLAR: Second-Order Loss and Attention for Image Retrieval. arXiv 2020, arXiv:2001.08972. [Google Scholar]
- Sutskever, I.; Hinton, G.E.; Krizhevsky, A. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural Codes for Image Retrieval; Springer International Publishing: Berlin, Germany, 2014. [Google Scholar]
- Wang, W.; Jiao, P.; Liu, H.; Ma, X.; Shang, Z. Two-stage content based image retrieval using sparse representation and feature fusion. Multimed. Tools Appl. 2022, 81, 16621–16644. [Google Scholar] [CrossRef]
- Xia, R.; Pan, Y.; Lai, H.; Liu, C.; Yan, S. Supervised Hashing for Image Retrieval via Image Representation Learning. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lai, H.; Pan, Y.; Ye, L.; Yan, S. Simultaneous Feature Learning and Hash Coding with Deep Neural Networks. In Proceedings of the IEEE International Conference on Pattern Recognition and Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 3270–3278. [Google Scholar]
- Shan, T. Research on the Nearest Neighbor Search Algorithm Based on Image Features. Master’s Thesis, University of Science and Technology of China, Hefei, China, 2017. [Google Scholar]
- Gao, X. Research on Large-scale Image Nearest Neighbor Retrieval Algorithm Based on Hash Algorithm. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Wang, X.; Luo, G.; Qin, K.; Zhang, Y. An Image Retrieval Method Based on SVM and Active Learning. Comput. Appl. Res. 2016, 33, 3836–3846. [Google Scholar]
- Wei, Y.; Yan, Z. Research on Image Retrieval Technology Combined with Attention Convolutional Neural Network. Small Microcomput. Syst. 2021, 42, 2368–2374. [Google Scholar]
- Balasundaram, P.; Muralidharan, S.; Bijoy, S. An mproved Content Based Image Retrieval System using Unsupervised Deep Neural Network and Locality Sensitive Hashing. In Proceedings of the 2021 5th International Conference on Computer, Communication, and Signal Processing, ICCCSP 2021, Chennai, India, 24–25 May 2021; pp. 65–71. [Google Scholar]
- Qin, J.; Huang, J.; Xiang, X.; Tan, Y. Image retrieval based on convolutional neural network and attention mechanism. Telecommun. Technol. 2021, 61, 304–310. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MAP | Recall | Top-5 | Top-10 | Top-20 | Top-30 |
|---|---|---|---|---|---|---|
| Traditional SIFT | 0.7748 | 0.7024 | 0.8543 | 0.7933 | 0.7893 | 0.7693 |
| SVM Active Learning [17] | 0.7241 | 0.6512 | 0.8403 | 0.7806 | 0.7425 | 0.6916 |
| VGG-N [18] | 0.8951 | 0.7858 | 0.9304 | 0.9125 | 0.8927 | 0.8841 |
| Literature [19] | 0.9186 | 0.8192 | 1 | 0.9932 | 0.9842 | 0.9646 |
| Ours | 0.9578 | 0.842 | 1 | 1 | 1 | 0.9994 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Y.; Li, W.; Ma, X.; Zhang, K. Image Retrieval Algorithm Based on Locality-Sensitive Hash Using Convolutional Neural Network and Attention Mechanism. Information 2022, 13, 446. https://doi.org/10.3390/info13100446
Luo Y, Li W, Ma X, Zhang K. Image Retrieval Algorithm Based on Locality-Sensitive Hash Using Convolutional Neural Network and Attention Mechanism. Information. 2022; 13(10):446. https://doi.org/10.3390/info13100446
Chicago/Turabian StyleLuo, Youmeng, Wei Li, Xiaoyu Ma, and Kaiqiang Zhang. 2022. "Image Retrieval Algorithm Based on Locality-Sensitive Hash Using Convolutional Neural Network and Attention Mechanism" Information 13, no. 10: 446. https://doi.org/10.3390/info13100446
APA StyleLuo, Y., Li, W., Ma, X., & Zhang, K. (2022). Image Retrieval Algorithm Based on Locality-Sensitive Hash Using Convolutional Neural Network and Attention Mechanism. Information, 13(10), 446. https://doi.org/10.3390/info13100446