2. Related Work
In early named entity recognition tasks, the main goal was to automatically identify named entities from a pile of textual data. A system for automatic recognition of company names was introduced by Rau [
3] and others at the 1991 Conference on Applications of Artificial Intelligence, where the main approach used heuristics and manual rules. In 1996, the term named entity recognition was formally introduced by R. Grishman and Sundheim [
4] at the MUC-6 conference, which led to an increasing interest in the field, and thus it entered a period of rapid development.
In recent years, deep learning techniques based on neural network models have become mainstream in NER tasks due to the rapid development of deep learning techniques, and the features of the method that do not rely on manual feature extraction have become an important reason for this being the main choice. The neural network-based method simply converts text information into vector form by learning the embedded model, and then the text information represented by the vector form is input into the neural network model, and the neural network encodes the information by modeling the text sequence, and finally decodes it in the decoding layer to obtain the final annotated sequence [
5].
Currently, among the generative models of word vectors, there is the Word2Vec model proposed by Mikolov et al. [
6]. This is a method of word embedding, which allows the natural language space and mathematical space to be connected. Based on the previous work, Pennington et al. proposed the Glove model [
7]. One of the main advantages of Glove is that it uses uniformly distributed squared loss, which is better adapted to the cross-entropy loss function and has better expressiveness, and from the point of view of model training, Glove can obtain a more reliable set of word vectors faster. However, both models produce the same word vectors in the corpus of the text, which leads to the problem of multiple meanings in both of them, which leads to an impact on the results of subsequent tasks. Devlin et al. [
8], in 2018, proposed the BERT (bidirectional encoder representation from transformers) model, which has been proven after extensive experiments to have better performance in pre-trained language models for NLP, which can capture the features of long texts and can dynamically generate word vectors in different contexts with better computing power, and has become the main pre-processing model in the field of NLP.
In sequence annotation tasks, the commonly used encoding methods are RNN (recurrent neural networks), and variants of RNN, LSTM [
9] (long short-term memory) and CNN [
10,
11] (convolutional neural networks). The first feature extractor that was used for named entity recognition tasks was CNN, and the algorithm achieved good recognition results in the image domain, so researchers started using CNN for NLP. CNNs are effective in extracting local features by using a convolution kernel of the same dimension as the character vector to convolve with a matrix composed of character vectors. The advantage of CNN networks is that in addition to local extraction, the parallelism of GPUs can be used to extract local features quickly, but the disadvantage is that it is difficult to ensure that the extracted character features contain global information. However, even so, CNN is still a very effective processing model. Collobert and Weston et al. [
12]. First proposed the application of convolutional neural networks in natural language processing in their 2008 publication, proposing that each input word corresponds to a word vector. Collobert et al. [
13] proposed a generalized CNN framework in 2011, and using this generalized CNN framework, many NLP-type problems can be solved. Inspired by Collobert, many scholars started to study CNNs more deeply. However, due to the shortcomings of CNN in feature extraction of global information, academics proposed the RNN model. RNN cuts the input information into multiple tasks, and the output at a certain time is not only related to this input but also to the output of the previous time series. For each input of temporal information, it is sent to a place called a recurrent neural unit and then outputs a vector with pre-set dimensions [
14]. Because the output of a recurrent neural unit is not only related to the input but also to the output of the previous recurrent unit, people figuratively call recurrent neural networks memorable. Once the recurrent neural network was introduced, it achieved good results. As researchers studied RNNs more deeply, it was found that RNNs gradually lose their learning ability as the sequence length increases, and the problem of ‘gradient disappearance’ and gradient explosion will occur. To address this problem, scholars have improved the traditional RNN and obtained an improved version of RNN, LSTM [
15]. LSTM adds a ‘gate’ structure to the recurrent neural network, which controls the input at each time node and solves the gradient disappearance and gradient explosion problems to some extent. The problem of in-paragraph utterance is that the before-and-after relationship of text is often correlated, but LSTM can only capture text features in a single direction, thus ignoring the before-and-after relationship of the utterance, therefore, the BiLSTM model has been proposed [
16]. BiLSTM does not change much from LSTM in structure, and BiLSTM can capture features from both directions of text, which greatly improves the recognition rate of named entities. Although RNNs have more efficient feature extraction capability compared to CNNs, the inability of RNNs to use GPUs for parallelism computation leads to RNNs being less efficient than CNNs in terms of usage. In 2017, Google proposed the Transformer encoder model with more powerful corpora extraction capability [
17]. Each word in the Transformer encoder is compared to the other words in the sentence, the attention of the other words in the sentence is calculated, so that the true attention weight of the words in the whole sentence can be calculated more accurately. It has been experimentally demonstrated that the Transformer model achieves better results in NLP tasks, but because the structure of the Transformer model is fully connected, its computational and memory overheads are squared by a number of times determined by the sentence length, and the reference volume is larger, requiring a longer training time.
In the decoding stage, the commonly used models are SoftMax [
18] and the CRF model [
19], among which thenCRF model is the most classical model to solve the sequence labeling problem. In the entity recognition task, the input is a sentence text, and if the correlation information of the upper neighboring tags can be used to decode the best prediction result, the CRF model takes the relationship between the tags and the preceding and following text annotations into full consideration, so it can better solve the sequence annotation problem.
Since LSTM deals with the problem of gradient disappearance and gradient explosion occurring in time series data and can capture and preserve the contextual relationship of sequences well, the LSTM-CRF model has now become one of the basic network frameworks for NER tasks, and many scholars improve on it to improve the recognition of named entities. For example, Lample et al. [
20], in 2016, proposed the BiLSTM-CRF model, which performs feature extraction in the front and back directions of the text to ensure the connection between contextual features, and thus obtained a more desirable recognition effect at that time. Huang et al. [
21] added manual spelling features to BiLSTM-CRF in order to enrich its input feature representation. Wu et al. [
22] proposed a CNN-LSTM-CRF model to obtain short- and long-range content dependencies, and proposed to jointly learn NER and word separation tasks and explore the intrinsic connection between these two tasks. Santo et al. [
23] added a convolutional layer to the CNN-CRF model to extract character-level features. Strubell et al. [
24] first proposed a null convolutional network (IDCN) to extract features, which expands the perceptual field of view with a reduced number of parameters. However, the model with CNN as the basic structure cannot fully obtain the global information, so the recognition effect is lower than the joint model of CNN and RNN.
Since BERT can fully characterize syntactic and semantic information in different contexts, the BERT model has started to be used as a preprocessing model for solving the problem of multiple meanings of words. For example, Straková et al. [
25] applied the BERT model to nested named entity recognition and improved the recognition effect. Gao et al. [
26] used the BERT-BiLSTM-CRF model for named entity recognition in Chinese and in the publicly released dataset of EMR named entity recognition evaluation task in the CCKS2020 competition, the named entity recognition for drug type entities reached an F1 value of 96.82%.
In recent years, after the continuous efforts of researchers, the recognition of named entities has become more and more effective, so the method of named entity recognition has been applied to some specific fields. For example, Liu et al. [
27] used named entity recognition for named entities in geological texts. Yang et al. [
28] used a medical named entity recognition method with weakly supervised learning to perform experiments on the CCKS2017 official test set. The experimental results show that the weakly supervised learning methods proposed in this paper achieve the satisfactory performance as the supervised methods under comparable conditions. Zhuang et al. [
29] used a model based on the BiLSTM method to apply the named entity recognition task to the field of journalism.















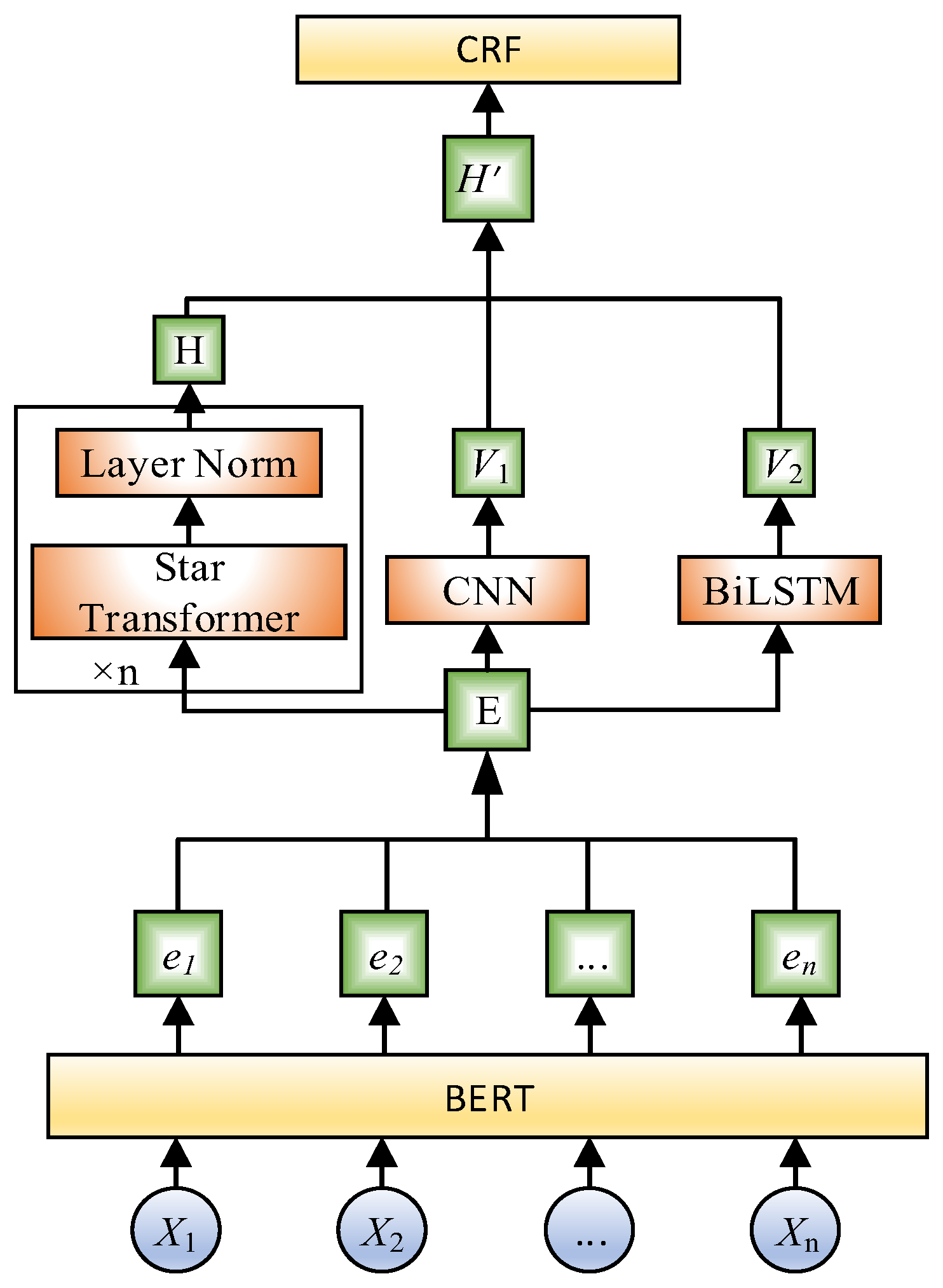{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
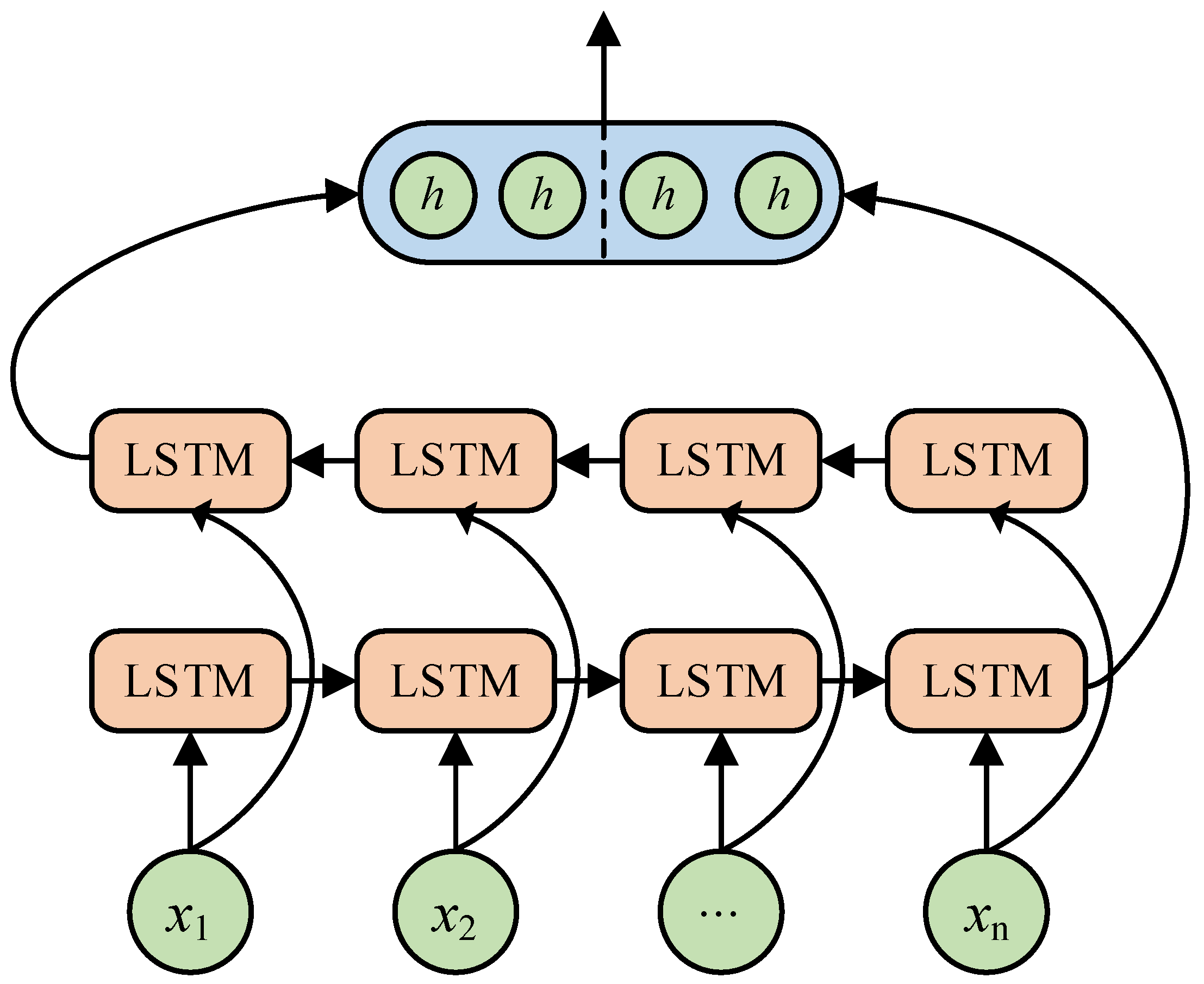{kind=link}
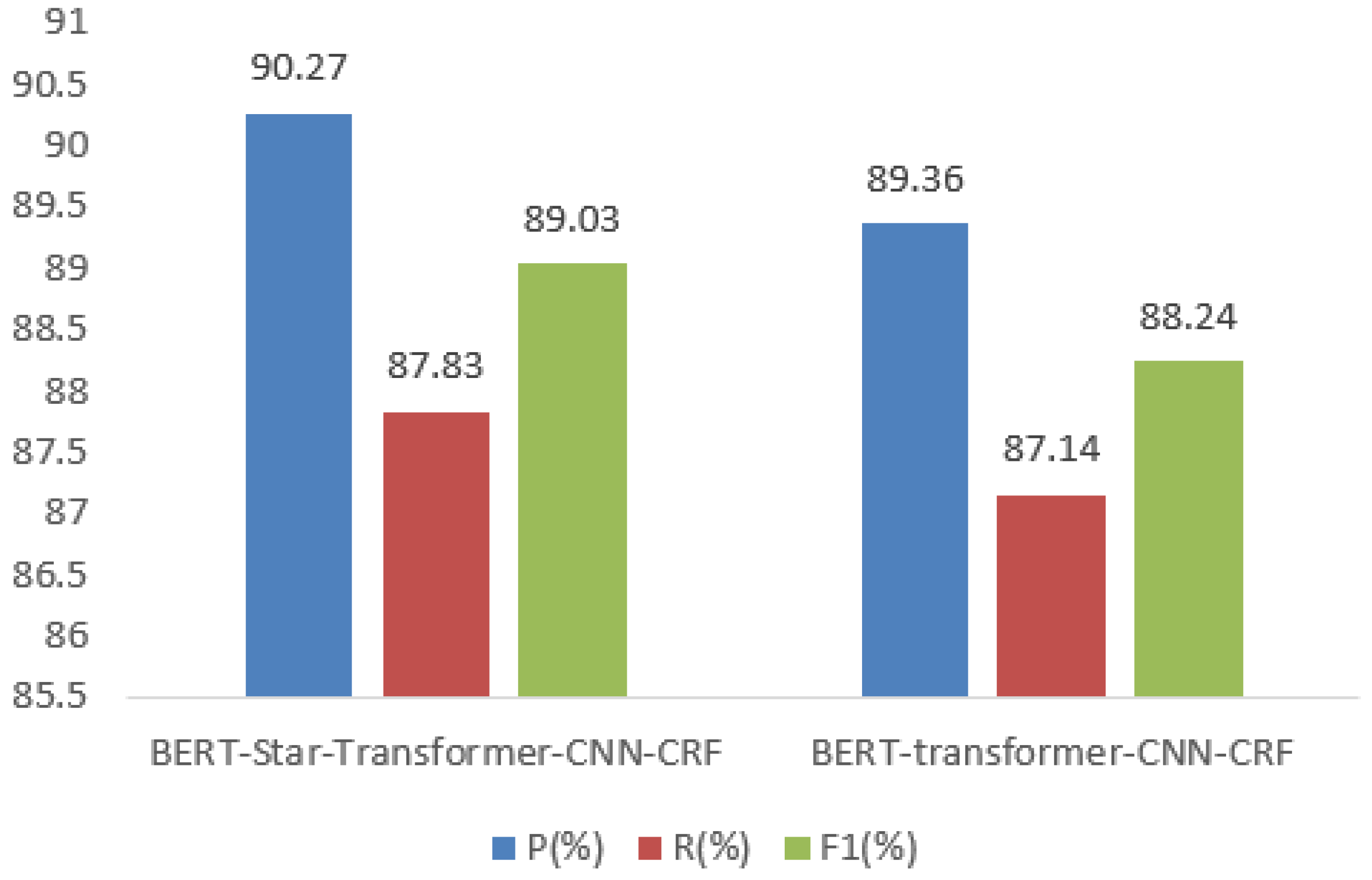{kind=link}
{kind=link}