1. Introduction
Currently, there is an increasing number of information systems that produce large amounts of data continuously, such as Web systems (e.g., digital libraries, knowledge graphs, and e-commerce), social media (e.g., Twitter and Facebook), and the Internet of Things (e.g., mobiles, sensors, and devices) [
1]. These applications have become a valuable source of heterogeneous data [
2,
3]. These kinds of data present a schema-free behavior and can be represented in different formats (e.g., XML, RDF, and JSON). Commonly, data are provided by different data sources and may have overlapping knowledge. For instance, different types of social media will report the same event and generate similar mass data. In this sense, Entity Resolution (ER) emerges as a fundamental step to support the integration of multiple knowledgebases or identify similarities between entities. The ER task aims to identify records (i.e., entity profiles) from several data sources (i.e., entity collections) that refer to the same real-world entity (i.e., similar/correspondent entities) [
4,
5,
6].
The ER task commonly includes four steps: blocking, comparison, classification, and evaluation [
7]. In the former, to avoid the quadratic cost of the ER task (i.e., comparisons guided by the Cartesian product), blocking techniques are applied to group similar entities into blocks and perform comparisons within each block. In the comparison step, the actual entity pair comparison occurs, i.e., the entities of each block are pairwise compared using a variety of comparison functions to determine the similarity between them. In the classification step, based on the similarity level, the entity pairs are classified into matches, non-matches, and potential matches (depending on the decision model used). In the evaluation step, the effectiveness of the ER results and the efficiency of the process are evaluated. This work focuses on the blocking step.
The heterogeneity of the data compromises the block generation (by the blocking techniques) since the entity profiles hardly share the same schema. Therefore, traditional blocking techniques (e.g., sorted neighborhood and adaptive window) do not possess satisfactory effectiveness because blocking is based on a fixed entity profile schema [
8]. In turn, the heterogeneous data challenge is addressed by schema-agnostic blocking techniques, which disregard attribute names and consider the values related to the entity attributes to perform blocking [
5]. Furthermore, we tackle three other challenges related to the ER task and, consequently, the blocking techniques: streaming data, incremental processing, and noisy data [
9,
10,
11].
Streaming data are related to dynamic data sources (e.g., from Web systems, social media, and sensors), which are continuously updated. When blocking techniques receive streaming data, we assume that not all data (from the data sources) are available at once. Therefore, blocking techniques need to group the entities as they arrive, also considering the entities already blocked previously.
Incremental blocking is related to receiving data continuously over time and re-processing only the portion of the generated blocks (i.e., that store similar entities) that were affected by the data increments. For this reason, it commonly suffers from resource consumption issues (e.g., memory and CPU) since ER approaches need to maintain a large amount of data in memory [
9,
10,
12]. This occurs due to the fact that incremental processing consumes information processed in previous increments. Considering this behavior, it is necessary to develop strategies that manage computational resources. In this sense, when blocking techniques face these scenarios, memory consumption tends to be the biggest challenge that is handled by incremental techniques [
13,
14]. Considering that streaming data are frequently processed in an incremental way [
2], the challenges are strengthened when the ER task deals with heterogeneous data, streaming data, and incremental processing simultaneously. For this reason, the development of efficient incremental blocking techniques able to handle streaming data appears as an open problem [
13,
15]. To improve efficiency and provide resources for incremental blocking techniques, parallel processing can be applied [
16]. Parallel processing distributes the computational costs (i.e., to block entities) among the various resources (e.g., computers or virtual machines) of a computational infrastructure to reduce the overall execution time of blocking techniques.
Concerning noisy data, in practical scenarios, people are less careful with the lexical accuracy of content written in informal virtual environments (e.g., social networks) or when they are under some kind of pressure (e.g., business reports) [
17]. For these reasons, real-world data often present noise that can impair data interpretations, data manipulation tasks, and decision making [
18]. As stated, in the ER context, noisy data enhance the challenge of determining the similarities between entities. This commonly occurs in scenarios where the similarity between entities is based on the lexical aspect of their attribute values, which is the case in a vast number of blocking techniques [
19,
20,
21,
22,
23,
24]. In this sense, the two most common types of noise in the data are considered in this work: typos and misspelling errors [
17].
Considering the challenges described above, this research proposes a parallel-based blocking technique able to process streaming data incrementally. The proposed blocking technique is also able to process noisy data without a considerable impact on the effectiveness of the blocking results. Moreover, we propose two strategies to be applied in the blocking technique: attribute selection and top-n neighborhood. Both strategies intend to enhance the efficiency of the blocking technique by quickly processing entities (sent continuously) and preventing the blocking from consuming resources excessively. Therefore, the general hypothesis of our work is to evaluate whether (or not) the application of the proposed blocking technique is able to improve the efficiency of the ER task without decreasing the effectiveness in streaming data scenarios.
Although the proposed blocking technique follows the idea behind token-based techniques such as those in [
21,
22], the latter are neither able to handle streaming data nor perform blocking incrementally. Since they were originally developed for batch data, they do not take into account the challenges related to incremental processing and streaming data. To the best of our knowledge, there is a lack of blocking techniques that address all the challenges faced in this work. Among the recent works, we can highlight the work in [
19], which proposes a schema-agnostic blocking technique to handle streaming data. However, this work presents several limitations related to blocking efficiency and excessive resource consumption. Therefore, as part of our research, we propose an enhancement of the technique proposed in [
19], by offering an efficient schema-agnostic blocking technique able to incrementally process streaming data. Overall, the main contributions of our work are:
An incremental and parallel schema-agnostic blocking technique able to deal with streaming and incremental data, as well as minimize the challenges related to both scenarios;
An attribute selection algorithm, which discards the superfluous attributes of the entities, to enhance efficiency and minimize resources consumption;
A top-n neighborhood strategy, which maintains only the n most similar entities (i.e., neighbor entities) of each entity, improving the efficiency of the proposed technique;
A noise-tolerant algorithm, which generates hash values from the entity attributes and allows the generation of high-quality blocks even in the presence of noisy data;
An experimental evaluation applying real-world data sources to analyze the proposed technique in terms of efficiency and effectiveness;
A real-world case study involving data from Twitter and Google News to evaluate the application of the attribute selection and top-n neighborhood strategies over the proposed technique in terms of effectiveness.
The rest of the paper is structured as follows:
Section 2 formalizes the problem statement related to the understanding of this work. In
Section 3, we present the most relevant works available in the literature related to the field addressed in this paper.
Section 4 presents the parallel-based blocking technique and describes the workflow to process streaming data.
Section 5 describes the time-window strategy, which is applied in the proposed technique to avoid the excessive consumption of computational resources.
Section 6 presents the attribute selection strategy, which discards superfluous attributes in order to improve efficiency. In
Section 7, we discuss the experimental evaluation and in
Section 8, the results of the case study are addressed. Finally,
Section 9 concludes the paper along with directions for future works.
2. Problem Statement
Given two entity collections
and
, where
and
represent two data sources, the purpose of ER is to identify all matches among the entities (
e) of the data sources [
5,
7]. Each entity
or
can be denoted as a set of key-value elements that models its attributes (
a) and the values (
v) associated with each attribute
. Given that
is the function that determines the similarity between the entities
and
, and
is the threshold (
) that determines whether the entities
and
are considered a match (i.e., truly similar entities), the task of identifying similar entities (ER) can be denoted as
.
In traditional ER, entity comparisons are guided by the Cartesian product (i.e., ). For this reason, blocking techniques are applied to avoid the quadratic asymptotic complexity of ER. Note that the blocking output is a set of blocks containing entities such that, . Thus, each block b can be denoted as , where is the threshold of the blocking criterion.
Since this work considers that the data are sent incrementally, the blocking is divided into a set of increments , where is the number of increments and each contains entities from and . Given that the sources provide data in streams, each increment is associated with a time interval . Thus, the time interval between two increments is , i.e., , where returns the timestamp that the increment was sent and is the index of the increment . For instance, in a scenario where data sources provide data every 30 s, we can assume that = 30 s.
For each
, each data source sends an entity collection
. Thus,
=
, where
contains the entities of
and
contains the entities of
for the specific increment
i. Since the entities can follow different loose schemes, each
has a specific attribute set and value associated with each attribute denoted by
such that
is the number of attributes associated with
e. When an entity
e does not present a value for a specific attribute, it implies the absence of this attribute. For this reason,
can be different for a distinct
e. As stated in
Section 1, an attribute selection algorithm, which discards the superfluous attributes from the entities, is proposed in this work. Hence, when the attribute selection algorithm is applied, the attributes in
may be removed, as discussed later in
Section 6. In this sense, the set of attributes after the application of the attribute selection is given by
, where
represents the attribute selection algorithm that returns true if the attribute (as well as its value) should be removed and
false otherwise.
In order to generate the entity blocks, tokens (e.g., keywords) are extracted from the attribute values. Note that the blocking techniques aim to group similar entities (i.e., ) to avoid the quadratic cost of the ER task, which compares all entities of with all entities of . To group similar entities, blocking techniques such as token-based techniques can determine the similarity between entities based on common tokens extracted from the attribute values. For token extraction, all tokens associated with an entity e are grouped into a set , i.e., , such that is a function to extract the tokens from the attribute value v. For instance, can split the text of v using whitespace and remove stop words (e.g., “and”, “is”, “are”, and “the”). The set of the remaining words is considered the set of tokens. Stop words are not useful as tokens because they are common words and hardly determine a similarity between entities. In scenarios involving noisy data, we apply LSH algorithms to generate a hash value for each token. Therefore, a hash function H should be applied to , i.e., , to generate the set of hash values instead of the set of tokens . In summary, when noisy data are considered, should be replaced with .
To generate the entity blocks, a similarity graph
is created in which each
is mapped to a vertex
and a non-directional edge
is added. Each
l is represented by a triple
such that
and
are the vertices of
G and
is the similarity value between the vertices. Thus, the similarity value between two vertices (i.e., entities)
and
is denoted by
. In this work, the similarity value between
and
is given by the average of the common tokens between them
. This similarity function is based on the functions proposed in [
11,
21]. In scenarios involving noisy data, the similarity value between
and
is given by the average of the common hash values between them. Since the idea is not to compare (or link) two entities from the same data source,
and
must be from different data sources. Therefore,
is a vertex generated from an entity
and
is a vertex generated from another entity
.
The attribute selection algorithm aims to discard superfluous attributes in the sense of providing tokens that will hardly assist the blocking task to find similar entities. For instance, consider two general entities (i.e., ) and (i.e., ). Let and ; if only the attributes and have the same meaning (i.e., contain attribute values regarding the same content), the tokens generated from , , and will hardly result in blocking keys that truly represent the similarity between the entities. To this end, the attribute selection strategy is applied.
The idea behind attribute selection is to determine the similarity among attributes based on their values. After that, the attributes (and, consequently, their values) that do not have similarities with others are discarded. Formally, all attributes associated with the entities belonging to data sources and are extracted. Moreover, all values associated with the same attribute () are grouped into a set . In turn, the pair represents the set of values associated with a specific attribute . Let R be the list of discarded attributes, which contains the attributes that do not have similarities with others. Formally, given two attributes and , , where calculates the similarity between the sets and and is a given threshold. In this work, we compute the value for based on the similarity value of all attribute pairs provided by and . From the mean of the similarity between the attributes, assumes the value of the first quartile. Then, all attribute pairs whose similarities are in the first quartile (i.e., comprise 25% of the attribute pairs with the lowest similarities) are discarded. The choice of the value was based on previous experiments, which indicates a negative influence on the effectiveness results when the value is given after the first quartile. For this reason, assumes the value of the first quartile to avoid significantly impacting the effectiveness results. Then, the token extraction considering attribute selection is given by . Similarly, when noisy data are considered, the token extraction considering attribute selection is given by .
In ER, a blocking technique aims to group the vertices of G into a set of blocks denoted by
. In turn, a pruning criterion
is applied to remove entity pairs with low similarities, resulting in a pruned graph
. For pruning, a criterion is applied to
G (i.e.,
) so that the triples
whose
are removed, generating the pruned graph
. Thus, the vertices of
are grouped into a set of blocks denoted by
, such that
and
, where
is a similarity threshold defined by a pruning criterion
. In
Section 4.2.3, how a pruning criterion
determines the value for
in practice is presented.
However, when blocking techniques deal with streaming and incremental challenges, other theoretical aspects need to be considered. Intuitively, each data increment, denoted by , also affects G. Thus, we denote the increments over G by . Let be a set of data increments on G. Each is directly associated with an entity collection , which represents the entities in the increment . The computation of for each is performed on a parallel distributed computing infrastructure composed of multiple nodes (e.g., computers or virtual machines). Note that to compute for a specific , previous are considered, following the incremental behavior of G. In this context, it is assumed that is the set of nodes used to compute . The execution time using a single node is denoted by . On the other hand, the execution time using the whole computing infrastructure N is denoted by .
Execution time for parallel blocking. Since blocking is performed in parallel over the infrastructure N, the whole execution time is given by the execution time of the node that demanded the longest time to execute the task for a specific increment : .
Time restriction for streaming blocking. Considering the streaming behavior, where each increment arrives in each time interval, it is necessary to determine a restriction on the execution time to process each increment, given by .
This restriction aims to prevent the blocking execution time from overcoming the time interval of each data increment. Note that the time restriction is related to streaming behavior, where data are produced continuously. To achieve this restriction, blocking must be performed as quickly as possible. As stated previously, one possible solution to minimize the execution time of the blocking step is to execute it in parallel over a distributed infrastructure.
Blocking efficiency in distributed environments. Given the inputs , N, , , , , and , the blocking task aims to generate over a distributed infrastructure N in an efficient way. To enhance the efficiency, the blocking task needs to minimize the value of . For instance, considering a distributed infrastructure with N = 10 nodes and 10 s as the required time to perform the blocking task using only one node (i.e., ), the ideal execution time using all nodes (i.e., ) should be one second. Thus, ideally, the best minimization is . Due to the overhead required to distribute the data in each node and the delay in the communication between the nodes, is practically unreachable. However, the minimization of is important to provide efficiency to the blocking task.
Table 1 highlights the goals regarding the stated problems, which are exploited throughout this paper. Furthermore,
Table 2 summarizes the symbols used throughout the paper.
6. Attribute Selection
Real-world data sources can present superfluous attributes, which can be ignored by the blocking task [
5]. Superfluous attributes are attributes whose tokens will generate low-quality blocks (i.e., with entities with low chances of matching) and, consequently, increase the number of false matches. To prevent the blocking task from handling unnecessary data, which consumes computational resources (processing and memory), we propose the attribute selection algorithm to remove the superfluous attributes.
Although some works [
11,
20,
31,
32] exploit attribute information to enhance the quality of blocks, none of them proposes the disposal of attributes. Therefore, in these works, the tokens from superfluous attributes are also considered in the blocking task and, consequently, they consume computational resources. On the other hand, the discarding of attributes may negatively affect the identification of matches since tokens from discarded attributes can be decisive in the detection of these matches. Therefore, the attribute selection should be performed accurately, as discussed in
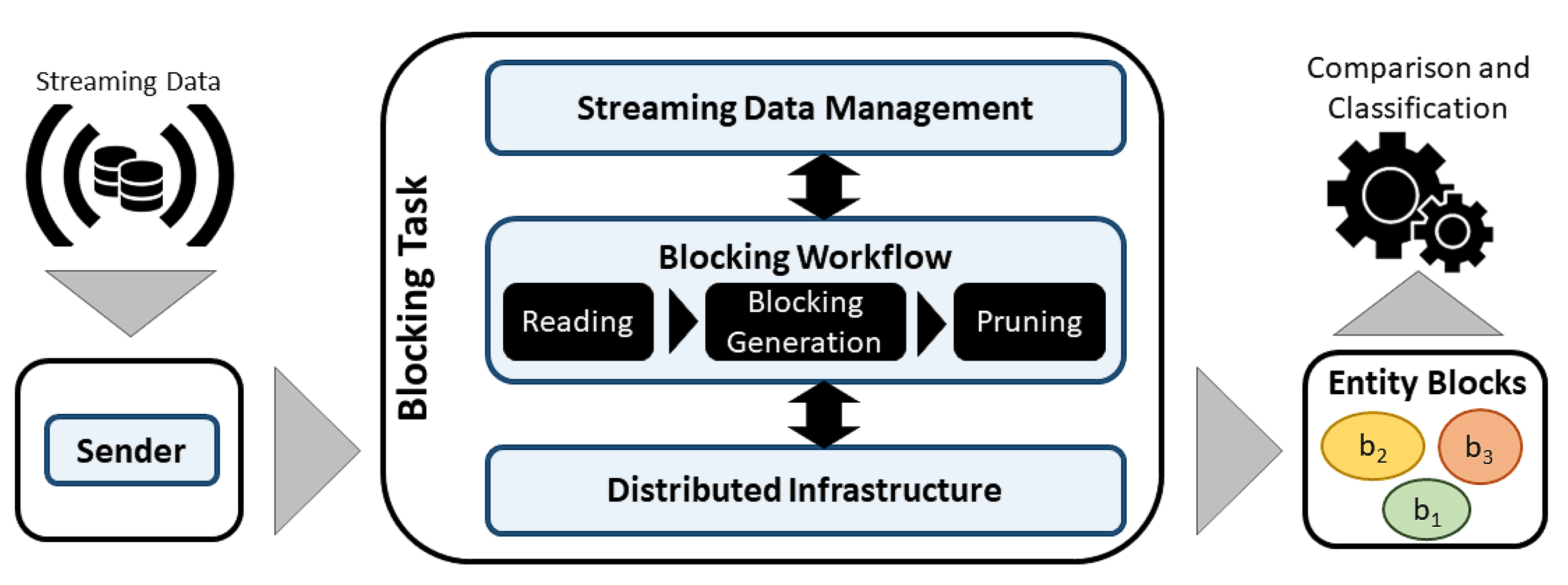
Section 7. To handle the superfluous attributes, we developed an attribute selection strategy, which is applied to the sender component (see
Figure 2). Note that, the sender component is executed in a standalone way.
For each increment received by the sender component, the entity attributes are evaluated and the superfluous ones are discarded. Thus, the entities sent by the sender are modified by removing the superfluous attributes (and their values). As stated, discarding attributes may negatively impact effectiveness, since the discarded attributes for a specific increment can become relevant in the next increment. To avoid this problem, the attribute selection strategy takes the attributes into account globally, i.e., the attributes are evaluated based on the current increment and the previous ones. Moreover, the applied criterion to discard attributes focuses on attributes whose tokens have a high chance of generating low-quality blocks, which is discussed throughout this section. Based on these two aspects, the discarded attributes tend to converge as the increments are processed and do not significantly impact the effectiveness results, as highlighted in
Section 7.2. Note that even if a relevant attribute is discarded for a specific increment it can return (not be discarded) for the next increments.
In this work, we explore two types of superfluous attributes: attributes of low representativeness and unmatched attributes between the data sources. The attributes of low representativeness are related to attributes whose contents do not contribute to determining the similarity between entities. For example, the attribute gender has a low impact on the similarity between entities (such as two male users from different data sources) since its values are commonly shared by a huge number of entities. Note that the tokens extracted from this attribute will generate huge blocks that consume memory unnecessarily since these tokens are shared by a large number of entities. Hence, this type of attribute is discarded by our blocking technique to optimize memory consumption without a significant impact on the effectiveness of the generated blocks.
To identify the attributes of low representativeness, the attribute selection strategy measures the attribute entropy. The entropy of an attribute indicates the significance of the attribute, i.e., the higher the entropy of an attribute, the more significant the observation of a particular value for that attribute [
11]. We apply the Shannon entropy [
60] to represent the information distribution of a random attribute. Assume a random attribute
X with alphabet
and the probability distribution function
. The
Shannon entropy is defined as
. The attributes with low entropy values (i.e., low representativeness) are discarded. In this work, we removed the attributes whose entropy values were in the first percentile (i.e., 25%) of the lowest values. As stated in
Section 2, the use of this condition was based on previous experiments.
Unmatched attributes between the data sources are attributes that do not have a corresponding attribute (i.e., with similar content) in the other data source. For instance, assume two data sources and , where contains the attributes full name and age, and the attributes name and surname. Since full name, name, and surname address the same content, it is possible to find several similar values provided by these attributes. However, does not have any attributes related to age. That is, age will generate blocks from its values but these blocks will hardly be relevant to determining the similarities between entities. It is important to highlight that even though some metablocking-based techniques remove blocks with only one entity, the blocks are generated and consume resources until the blocking filter removes them. For this reason, this type of attribute is discarded by our blocking technique before the block generation.
Regarding the unmatched attributes, attribute selection extracts and stores the attribute values. Hence, for each attribute, a set of attribute values is generated. Based on the similarity between the sets, a similarity matrix is created denoting the similarity between the attributes of
and
. To avoid expensive computational costs for calculating the similarity between attributes, we apply Locality-Sensitive Hashing (LSH) [
61]. As previously discussed, LSH is commonly used to approximate near-neighbor searches in high-dimensional spaces, preserving the similarity distances and significantly reducing the number of attribute values (or tokens) to be evaluated. In this sense, for each attribute, a hash function converts all attribute values into a probability vector (i.e., hash signature).
Since the hash function preserves the similarity of the attribute values, it is possible to apply distance functions (e.g., Jaccard) to efficiently determine the similarity between the sets of attribute values [
56]. Then, the hash function can generate similarity vectors that will feed the similarity matrix and guide the attribute selection algorithm. This similarity matrix is constantly updated as the increments arrive. Therefore, the similarity between the attributes is given by the mean of the similarity per increment. The matrix is evaluated and the attributes with no similarity to attributes from the other data source are discarded. After removing the superfluous attributes (and their values), the entities are sent to the blocking task. Note that instead of only generating hash signatures as in the noise-tolerant algorithm, LSH is applied in the attribute selection to reduce the high-dimensional space of the attribute values and determine the similarity between attributes based on a comparison of their hash signatures.
8. A Real-World Case Study: Twitter and News
Streaming data are present in our daily lives in different contexts including personal devices (mobile phones and wearable devices such as smartwatches), vehicles (intelligent transportation systems, navigation, theft prevention, and remote vehicle control), day-to-day living (tracking systems, various meters, boilers, and household appliances), and sensors (weather data temperature, humidity, air pressure, and measured data) [
10]. Particularly, for social data, in a single minute, 456,000 tweets are posted, 2,460,000 pieces of content are shared on Facebook, Google conducts 3,607,080 searches, the weather channel receives 18,055,555 forecast requests, Uber riders take 45,787.54 trips, and 72 h of new videos are uploaded to YouTube and 4,146,600 videos are watched [
66]. Streaming data can be utilized in various areas of study as they are linked with a large amount of information (oil price, exchange rate, social data, music, videos, and articles) that is found on the Web. Such data may also provide crucial information about product prices, consumer profiles, criminality, diseases, and disasters for companies, government agencies, and research agencies in real time [
54]. For example, a company can evaluate (in real time) the public perception of its products through streaming data provided by social networks. In this context, ER becomes a fundamental task to integrate and provide useful information to companies and government agencies [
4]. Particularly, blocking techniques should be used to provide efficiency to the ER task since it is necessary to handle a large amount of data in a short period of time.
News can be easily found on websites or through RSS feeds. For instance, RSS (Really Simple Syndication) feeds have emerged as an important news source since this technology provides real-time content distribution using easily consumable data formats such as XML and JSON. In this sense, social media (e.g., Twitter, Facebook, and Instagram) have become a valuable data source of news for journalists, publishers, stakeholders, and consumers. For journalists, social networks are an important channel for distributing news and engaging with their audiences [
67]. According to the survey in [
68], more than half of all journalists stated that social media was their preferred mode of communication with the public.
Over social networking services, millions of users share information on different aspects of everyday life (e.g., traffic jams, weather, and sporting events). The information provided by these services commonly addresses personal points of view (e.g., opinions, emotions, and pointless babble) about newsworthy events, as well as updates and discussions of these events [
69]. For instance, journalists use social media frequently for sourcing news stories since the data provided by social media are easy to access by elites, regular people, and people in regions of the world that are otherwise isolated [
70]. Since semantic standards enable the web to evolve from information uploaded online, this kind of data can benefit Web systems by aggregating additional information, which empowers semantic knowledge and the relationships between entities [
71].
Among the social networking sites, we can highlight Twitter. Twitter is a popular micro-blogging service with around 310 million monthly active users, where users can post and read short text messages (known as tweets), as well as publish website links or share photos. For this reason, Twitter has emerged as an important data source, which produces content from all over the world continually, and an essential host for sensors for specific events. An event, in the context of social media, can be understood as an occurrence of interest in the real world that instigates a discussion-associated topic at a specific time [
72]. The occurrence of an event is characterized by a topic and time and is often associated with entities such as news. Hot-topic events are grouped by Twitter and classified as trending topics, which are the most commented topics on Twitter. Twitter provides the trending topics list on its website and API, where it is possible to filter the trending topics by location (for instance, a specific city or country).
The main objective of this experimental evaluation was to validate (in terms of effectiveness) the application of the top-n neighborhood strategy, attribute selection strategy, and noise-tolerant algorithm to the proposed blocking technique in real-world streaming scenarios. More specifically, the real-world scenarios considered in this study were related to tweets and news. In this sense, it is important to note that the idea of this case study was to apply the proposed technique in order to group tweets that presented similarities regarding news published by media sites. In other words, given a set of news records provided (in a streaming way) by a news data source, the proposed technique should identify and group into the same block the tweets that address the same topic as a news record. In this aspect, our technique can be useful for journalists and publishers who are searching for instant information provided by tweets related to a specific event. Moreover, stakeholders, digital influencers, and consumers can benefit from the application of the proposed technique in the sense of analyzing tweets (for instance, applying a sentiment analysis approach) related to a specific topic described in a news article such as a novel product, the reputation of a brand, or the impact of media content.
8.1. Configuration and Experimental Design
Concerning the news data, we collected data provided by the Google News RSS feed (
https://news.google.com/rss/, accessed on 28 September 2022), whereas the tweets were collected from the Twitter Developer API (
https://developer.twitter.com/, accessed on 28 September 2022). For both data sources (a copy of the collected data is available in the project repository.), the data were filtered for the USA location (i.e., tweets and news in English) to avoid cross-language interference in the experiment. Considering that tweets and news can provide a huge number of tokens and since the number of tokens is directly related to the efficiency of the blocking technique (as discussed in
Section 7), the framework Yake! [
73] was applied as a keyword extractor. Yake! is a feature-based system for multi-lingual keyword extraction, which presents high-quality results in terms of efficiency and effectiveness compared to the competitors [
73]. The application of Yake! is also useful in the sense of removing useless words (e.g., stop words) and extracting relevant words (i.e., keywords) from long texts such as a news item. Note that the words extracted from tweets and news items become tokens during the blocking task.
One of the challenges of this real-world experiment was computing the effectiveness results since the generation of the ground truth was practically unfeasible. In this scenario, for each news item, the ground truth consisted of a set containing all tweets that were truly related to the news item in question. To produce the ground truth regarding tweets and news, it was necessary to use a group of human reviewers to label the hundreds of thousands of tweets for the hundreds of news items collected during the experiment, which represents a high-cost and error-prone demand task in terms of time and human resources.
To minimize the stated challenge, we applied the strategy used in [
74,
75], which generates the ground truth based on the hashtags contained in the tweets. In this sense, we collected the trending topic hashtags from the Twitter Developer API that referred to the most commented topics on Twitter at a specific time. From the trending topic hashtags, a search was performed on the Google News RSS feed using each hashtag as the search key. In turn, Google News returned a list of news related to the hashtag topic. To avoid old versions of the news items, we considered news published on the same day the experiment was conducted. In this way, it was possible to define a link between the news and the hashtags (topics). When the tweets were collected, the hashtags were extracted in the sense of correlating the tweet with one of the trending topic hashtags. Hence, based on the trending topic hashtags as a connection point, it was possible to link tweets and news that addressed the same topic. For instance, from the hashtag “#BlackLivesMatter”, it was possible to link tweets that contained this hashtag to news related to this topic provided by the Google News search using the hashtag as the search key. By doing this, we generated a ground truth that was able to support the effectiveness evaluation of the proposed blocking technique.
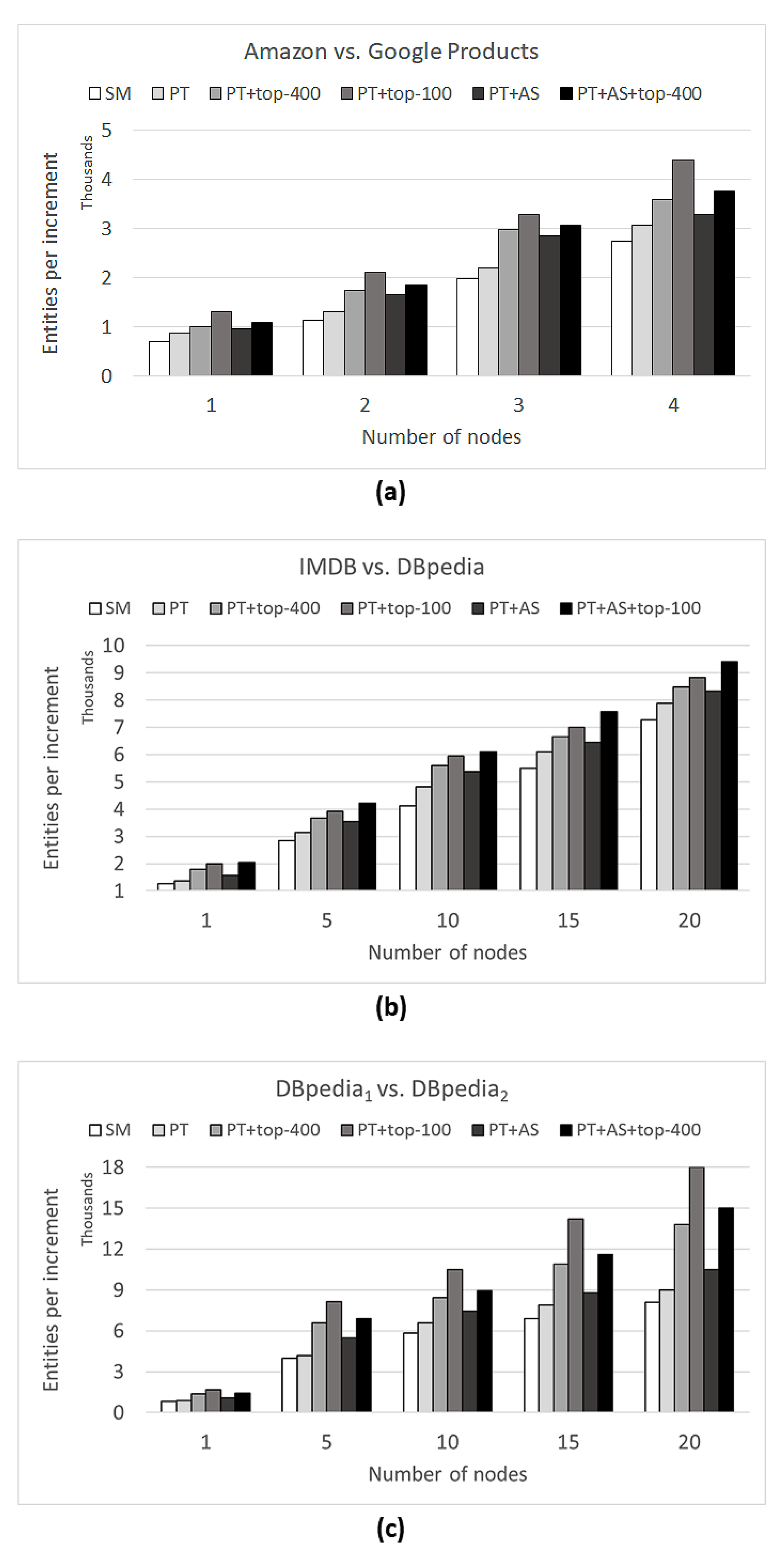
Regarding the computational infrastructure, we ran our experiments in a cluster with six nodes (one master and five slaves), each with one core. Each node had an Intel(R) Xeon(R) 2.10 GHz CPU, 3 GB memory, running on a 64-bit Windows 10 OS with a 64-bit JVM, Apache Kafka 2.1.0, and Apache Flink 1.7.1. This experiment was conducted between May 12 and May 16 2021 and was divided into 15 different moments at 3 different times each day. During this experiment, 483,811 tweets and 776 news items were collected and processed using the proposed technique. We applied a time window of 20 min with two minutes of sliding. These parameters were chosen to maximize the effectiveness results without back pressure problems (as discussed in
Section 7.2).
To evaluate the top-n neighborhood, attribute selection, and noise-tolerant algorithm, we conducted experiments combining the application (or not) of these strategies to the proposed technique. Regarding the top-n neighborhood, we applied the top-400 and top-1600, since these parameters achieved better effectiveness results without back pressure problems. Concerning the attribute selection strategy, we performed experiments with and without its application. In terms of the noise-tolerant algorithm, we applied it to the scenario where the top-1600 and attribute selection were applied since this combination achieved the best effectiveness results. Note that from the Twitter data, the attributes were text, user name, user screen name, hashtags, cited users, and created at. The attributes from Google News included title, text, published at, and list of links. When the attribute selection was ignored, all the stated attributes were considered during the blocking. On the other hand, when attribute selection was applied, only the attributes text and hashtags from tweets and title and text from news items were considered. In all scenarios in the study case, the results of the attribute selection converged in the sense of achieving the same discarded attributes.
8.2. Results and Discussion
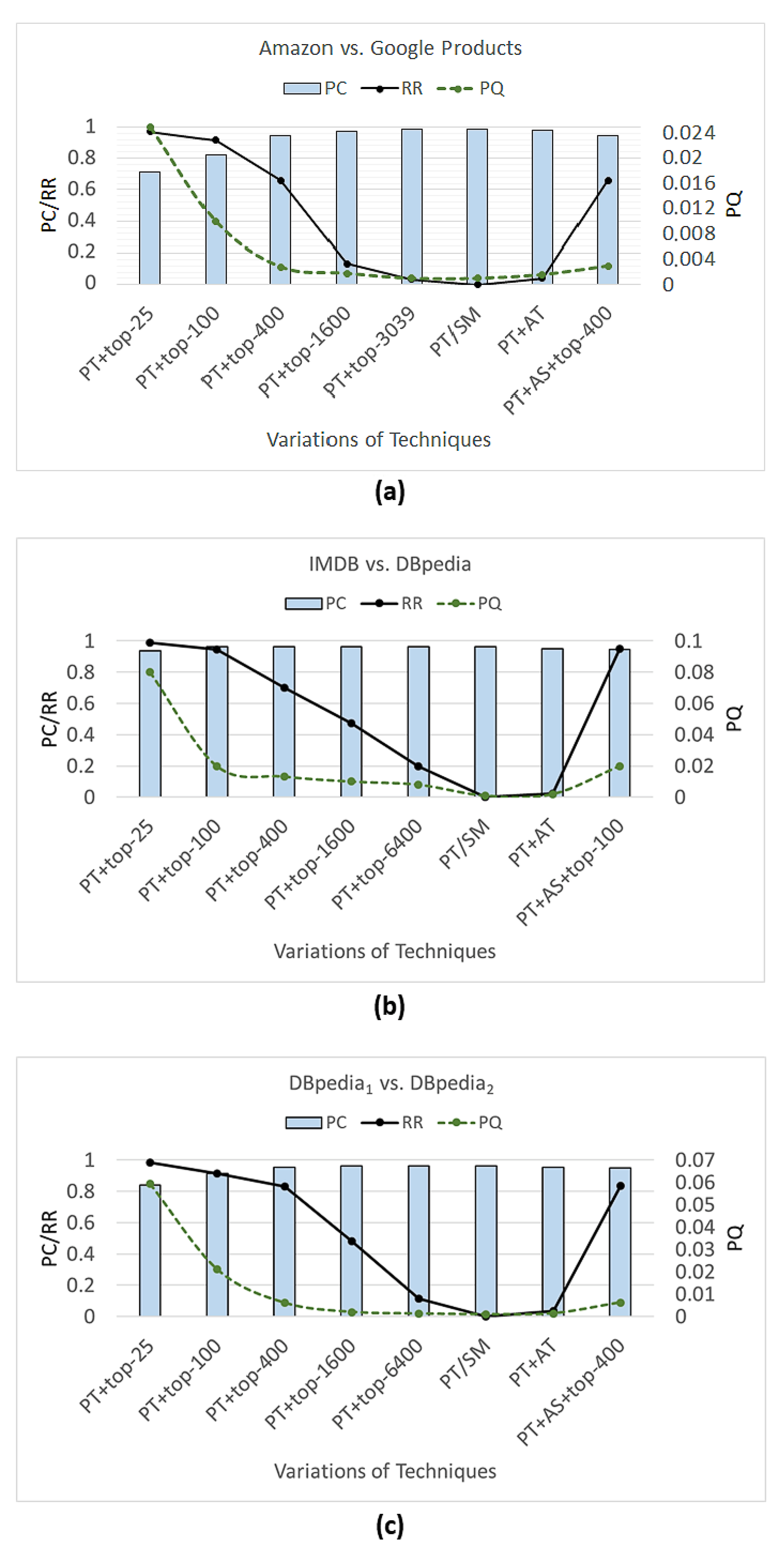
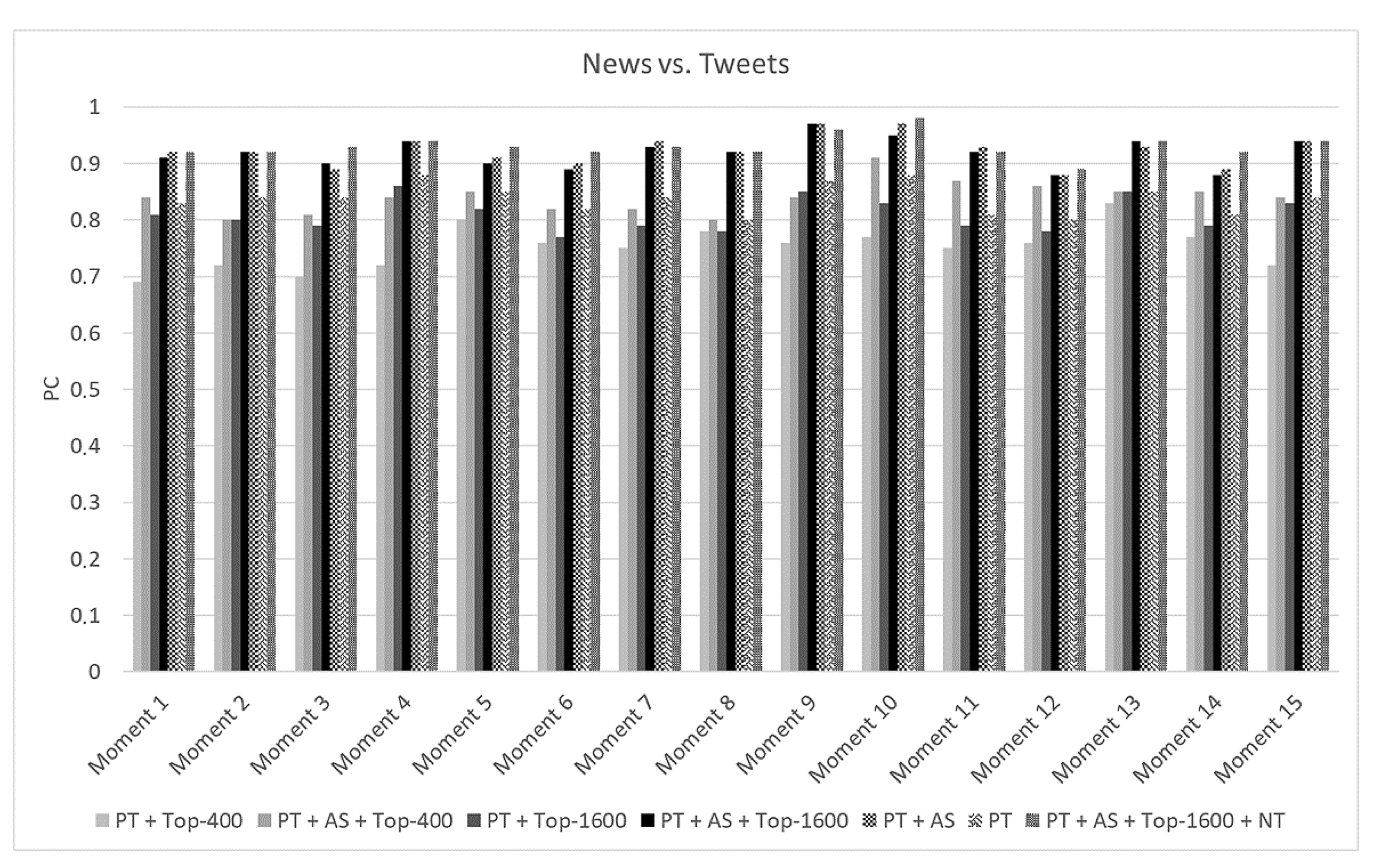
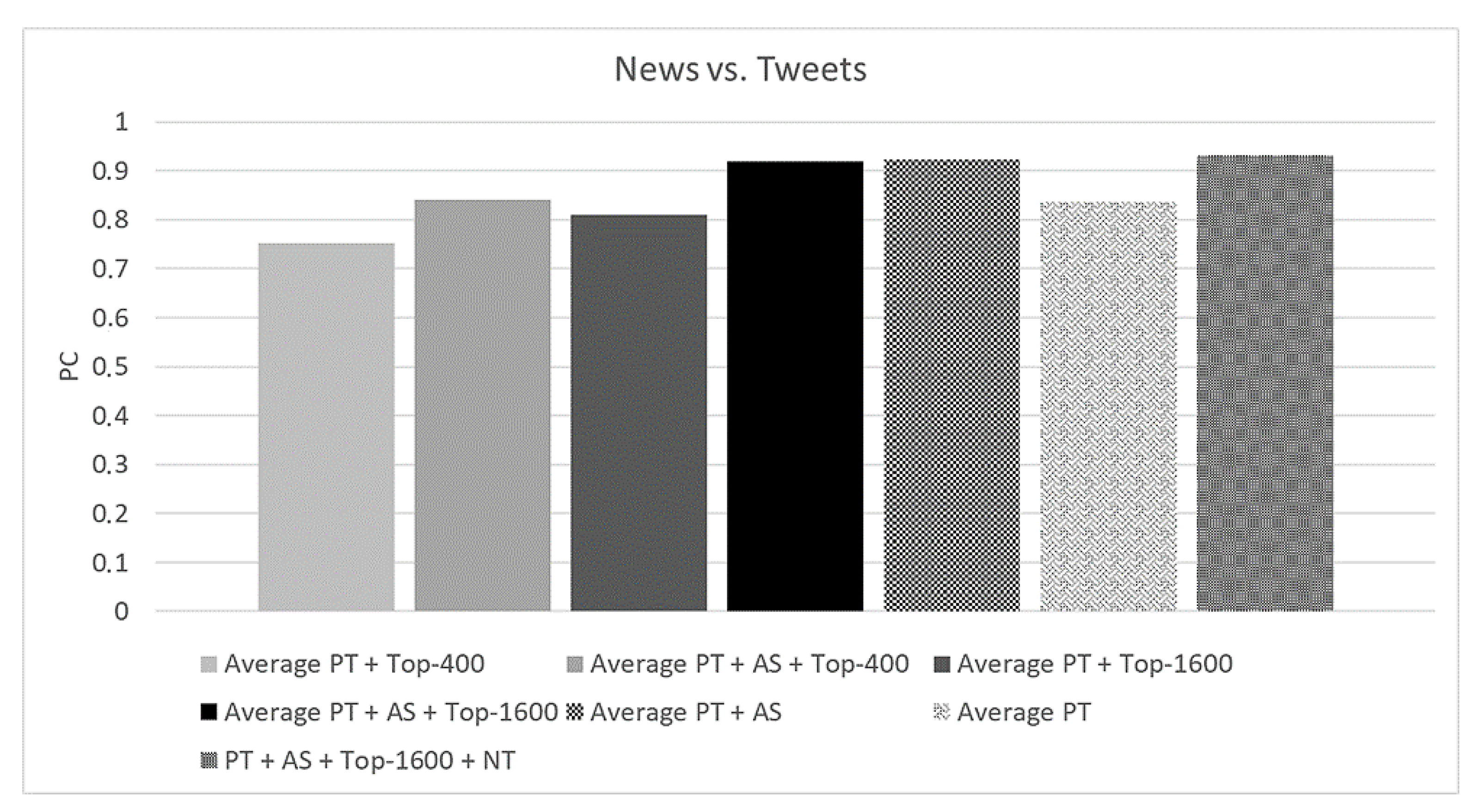
Assuming the configuration set previously described, we evaluated the effectiveness of the proposed technique (PT) when the top-n neighborhood strategy, attribute selection (AS) strategy, and noise-tolerant algorithm (NT) were applied, resulting in seven different combinations: PT, PT + AS, PT + Top-400, PT + AS + Top-400, PT + Top-1600, PT + AS + Top-1600, and PT + AS + Top-1600 + NT. Note that to evaluate the PQ metric, it was necessary to conduct a human evaluation. This occurred due to the fact that, even when applying the strategy to generate a ground truth based on the hashtags, the proposed technique can correlate tweets and news that truly address the same topic. However, these correlations may not have been included in the ground truth because the tweets did not present hashtags. Therefore, due to the challenges of generating the ground truth, only the PC metric was applied during the experiment.
Overall, based on the results illustrated in
Figure 8, the PT combination achieved an average of 84% for the PC (considering all the moments). Moreover, the PC value was enhanced when the AS was applied. Specifically, as depicted in
Figure 9, the PT + AS presented a PC value of 92% and the PT + AS + Top-1600 achieved a PC value of 91%, on average. In
Figure 8, it is possible to see that the application of the AS tended to increase the PC results of the PT in all evaluated moments. These results can be explained due to the discarding of superfluous attributes, which may have disturbed the effectiveness results, as discussed in
Section 6 and evaluated in
Section 7.2. Considering the collected attributes from tweets (i.e.,
text,
user name,
user screen name,
hashtags,
cited users, and
created at) and news items (i.e.,
title,
text,
published at, and
list of links), when the AS was applied, only
text and
hashtags from tweets and
title and
text from news items were considered. Regarding the discarded attributes, we observed that
created at and
published at were removed by the entropy rule since all the values presented a small variation considering that the tweets and news items were collected at similar time intervals. Regarding
user name,
user screen name, and
cited users from tweets and
list of links from news items, we observed that they were discarded based on the unmatched attribute rule since none of these attributes presented a relation among them (or with any other attribute). Thus, the application of the AS discarded the superfluous attributes and, consequently, tended to generate high-quality blocks. It also improved effectiveness, as discussed in
Section 6.
Based on the results depicted in
Figure 8, it is possible to identify a pattern regarding the application of the top-
n neighborhood and attribute selection. Notice that the application of the top-
n neighborhood tended to decrease the PC metric compared to the PT (without top-
n) results. More specifically, the application of the top-1600 decreased the PC metric by 3 percentage points on average and the top-400 decreased the PC metric by 8 percentage points on average, as depicted in
Figure 9. These results were expected since they were also obtained in the experiments presented in
Section 7.3. The top-
n neighborhood was developed to enhance efficiency without significant interference in the effectiveness results, which was achieved when the top-1600 was applied (i.e., with only a 3% decrease). In contrast, when the top-
n neighborhood and attribute selection were applied together, the PC results tended to increase and achieved similar results when only attribute selection was applied. For instance, the PT + AS achieved a PC value of only one percentage point higher than the PT + AS + Top-1600 on average, as illustrated in
Figure 9.
Regarding the application of the noise-tolerant algorithm, the combination of the PT + AS + Top-1600 + NT achieved the best results among the other combinations in 12 of the 15 moments, as described in
Figure 8. Only in three moments did the combinations PT + AS + Top-1600 or PT + AS outperform the PT + AS + Top-1600 + NT. However, in these three moments, the difference between the PC results was only one percentage point. Specifically, as depicted in
Figure 9, the PT + AS + Top-1600 + NT presented a PC value of 93% on average, which was one percentage point higher than the PC average for the combination of the PT + AS. Based on these results, it is important to highlight that the application of the noise-tolerant algorithm tended to enhance the effectiveness of the proposed technique. This occurred due to the fact that the noise-tolerant algorithm allowed the proposed technique to handle data in the presence of noise, which is common in real-world scenarios. In other words, the noise-tolerant algorithm enabled the proposed technique to find matches that were not identified due to the noisy data.
It is important to highlight the effectiveness results achieved by the proposed technique during the case study. Moreover, although efficiency was not the main evaluation objective, with the application of the configuration set stated in
Section 8.1, the proposed technique did not present back pressure problems. Taking into account the real-world scenario involved in this case study, the impact of superfluous attributes is clearer. As exposed by the works in [
11,
31], tokens provided by superfluous attributes tend to generate low-quality blocks. Furthermore, when data are provided by social networks, this challenge is strengthened [
72]. For instance, a tweet may be linked to a news item that addresses a topic about “Black Lives Matter” only because the tweet presents “Lives” as a value in the attribute user name (since both share the token “Lives”). This link based only on the token “Lives”, has a high chance of being a false-positive result. Although the experiments described in
Section 7 also considered the application of attribute selection, an important result of this case study is the application of attribute selection in the sense of improving the effectiveness of real-world data sources. In this sense, the case study scenario presented several superfluous attributes (i.e.,
created at,
user name,
user screen name,
cited users,
published at, and
list of links), which negatively interfered with the quality of the generated blocks. For this reason, based on the achieved results in this case study and the comparative experiments in
Section 7, the attribute selection strategy emerges as an important ally for blocking techniques in the sense of enhancing not only effectiveness but also efficiency.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}