
A Personalized Compression Method for Steady-State Visual Evoked Potential EEG Signals


Abstract
:1. Introduction
2. Materials and Methods
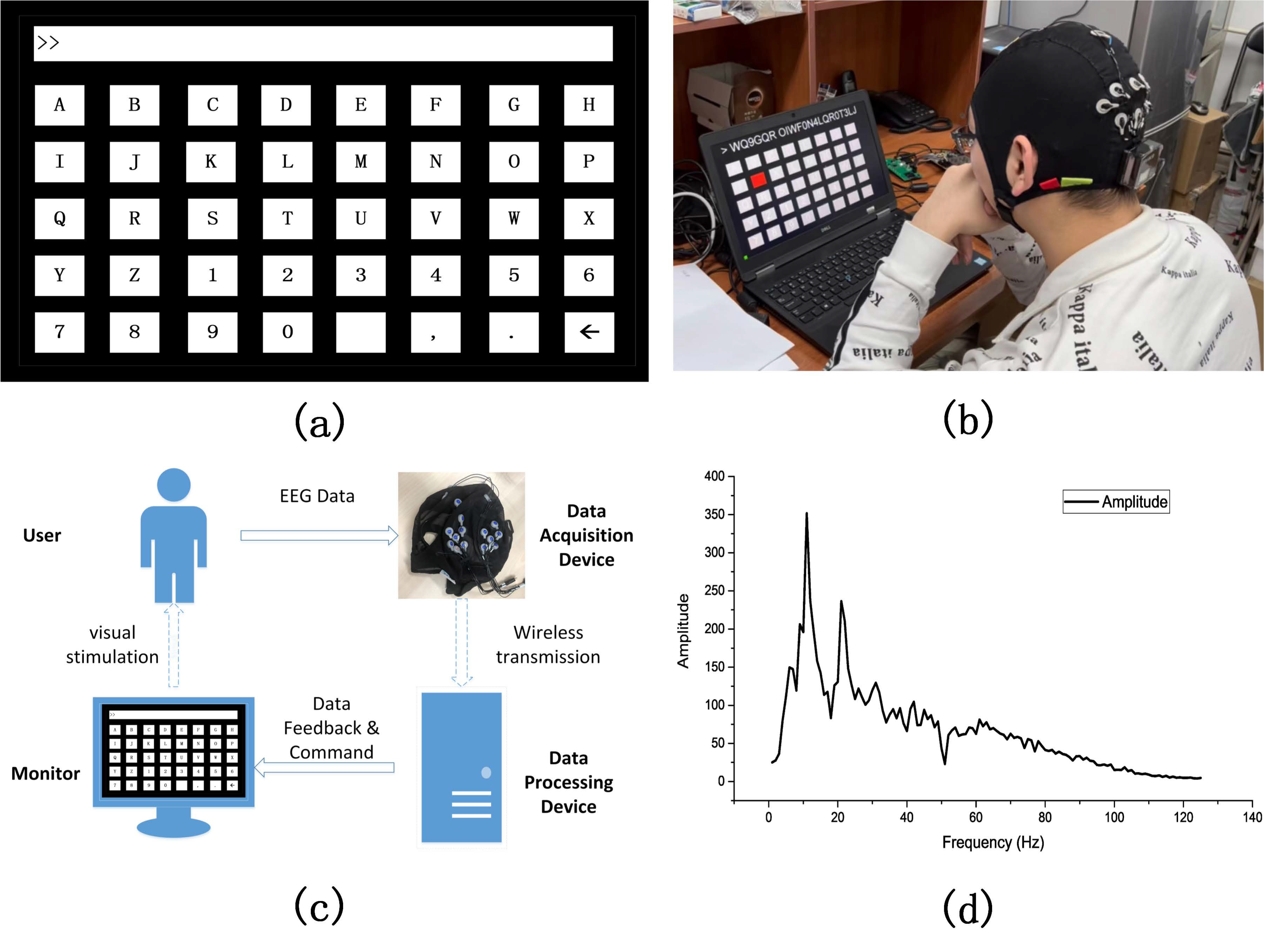
2.1. Dataset
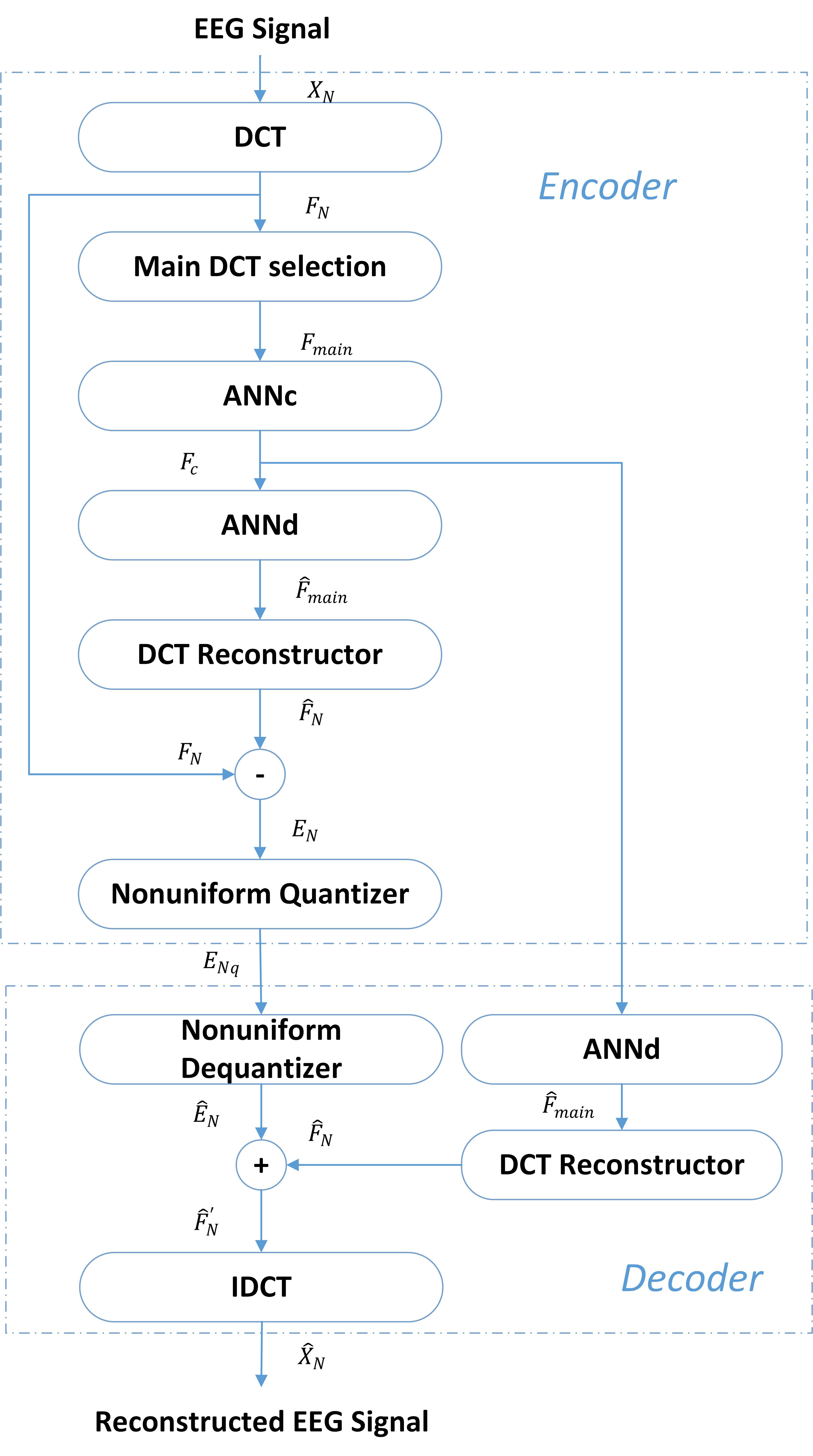
2.2. Overall Structure
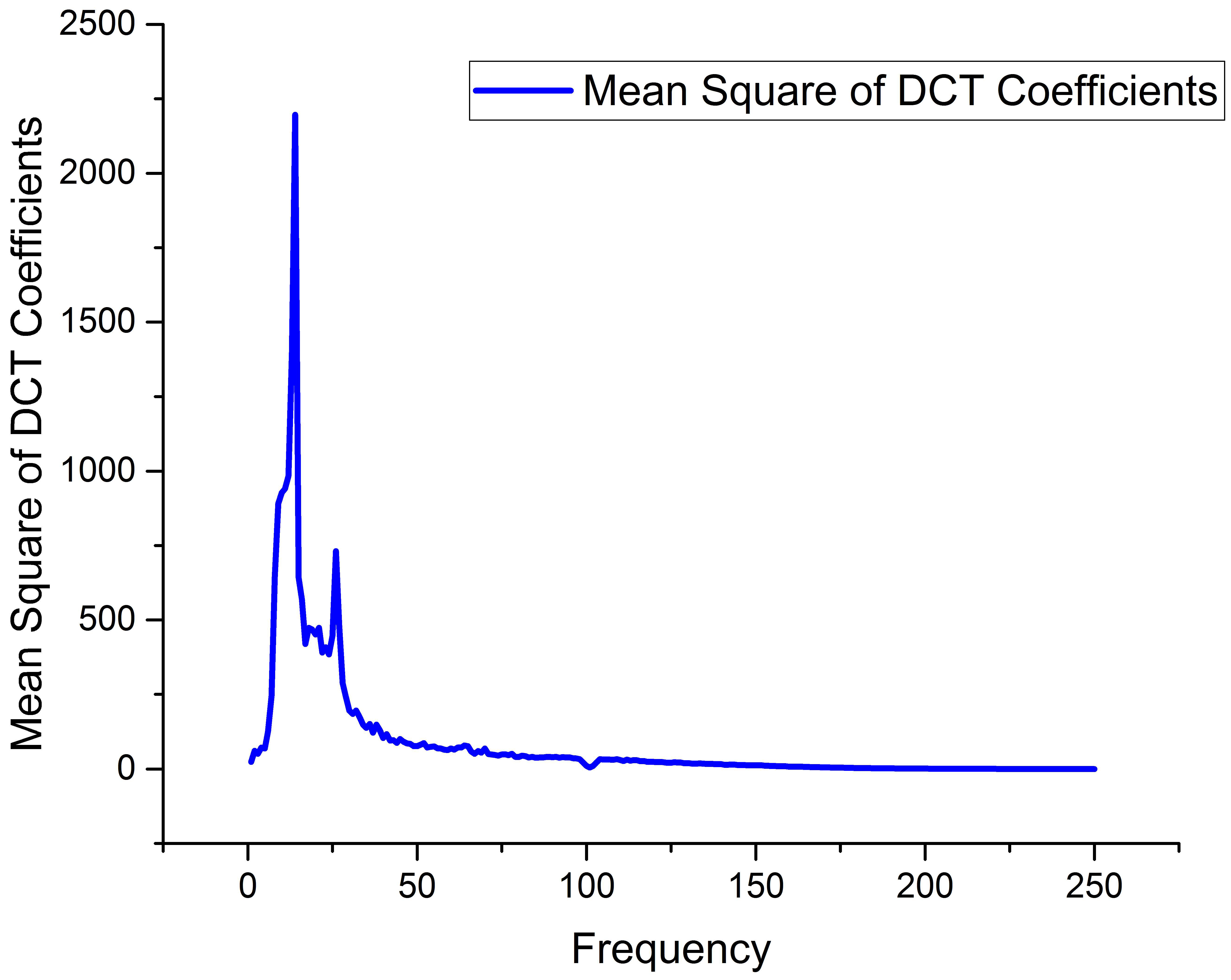
2.3. DCT Main Component Compression Using ANN
2.4. Quantization Table
2.5. Summary
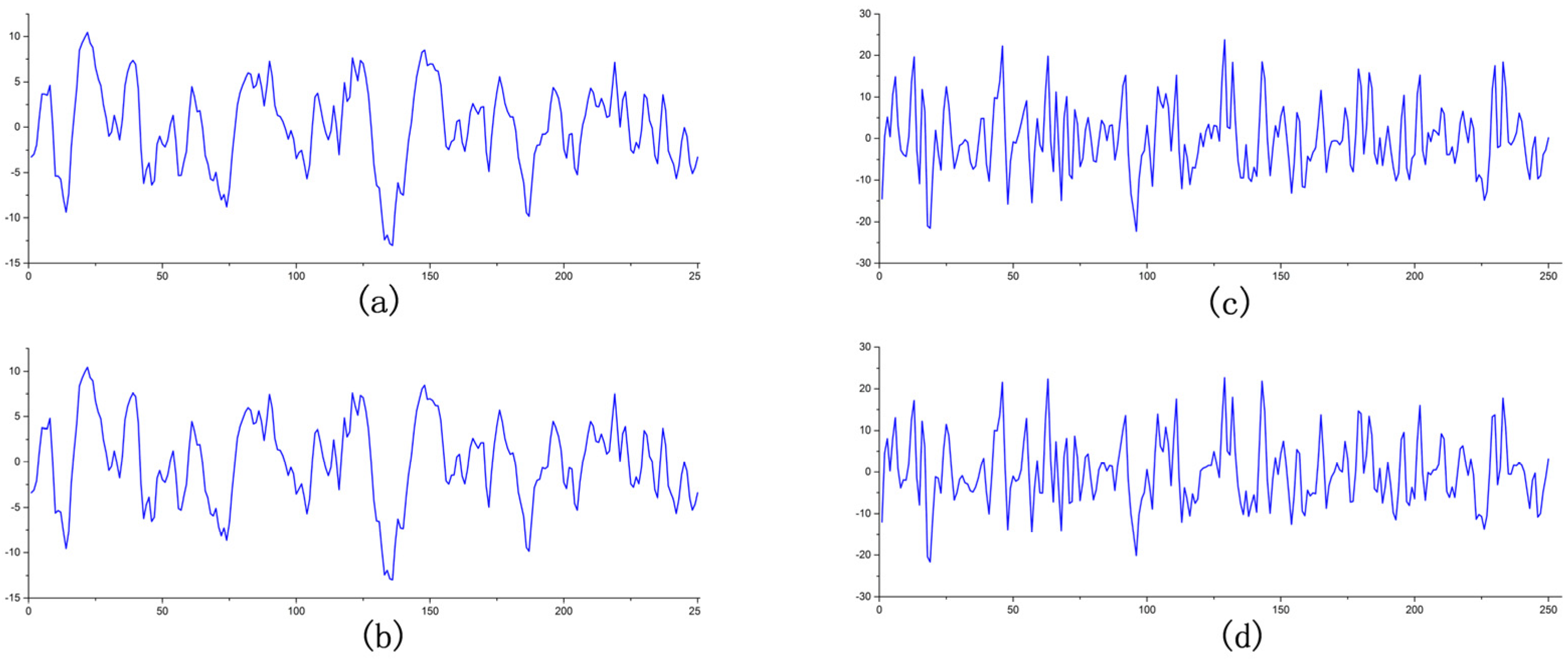
3. Results
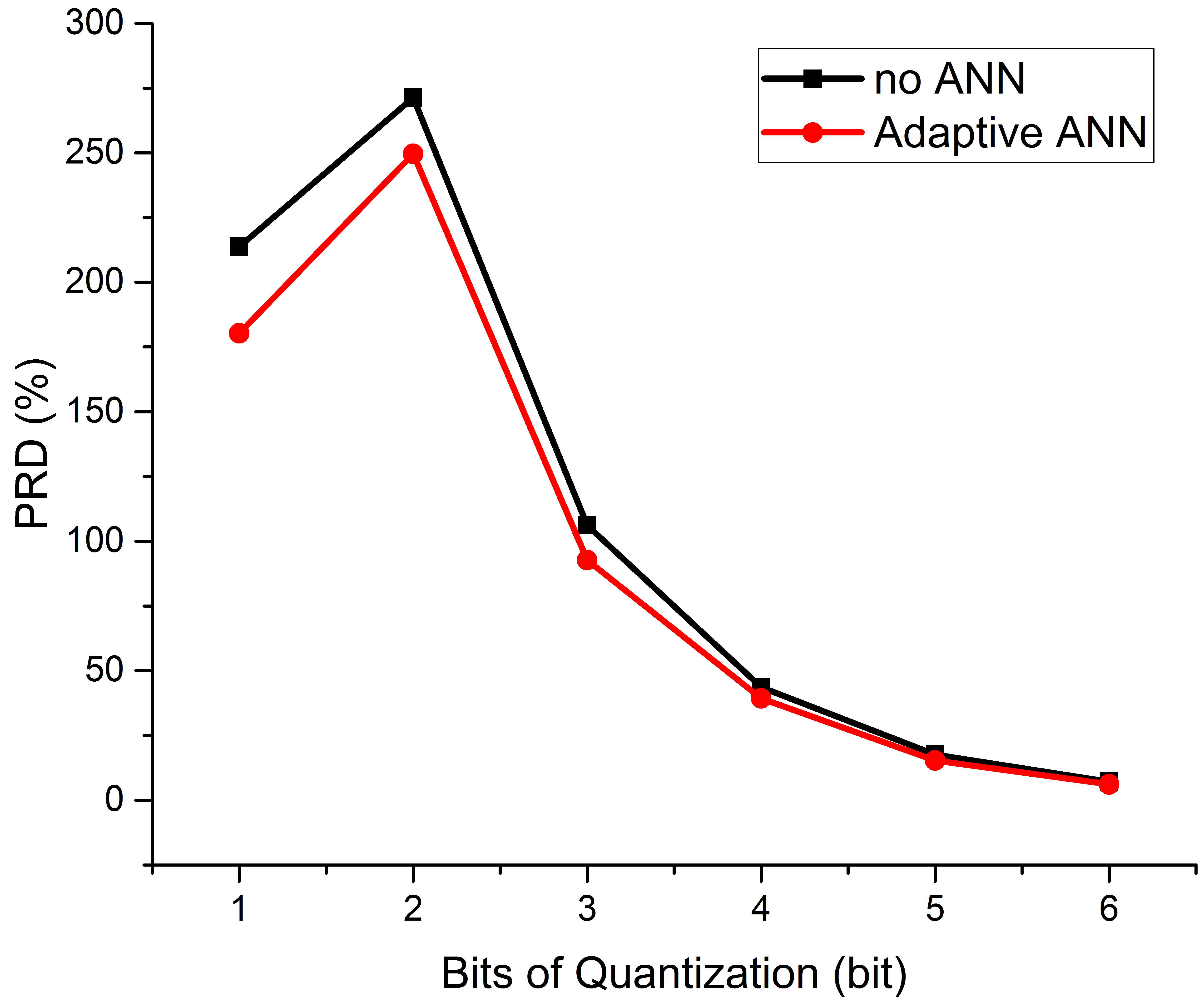
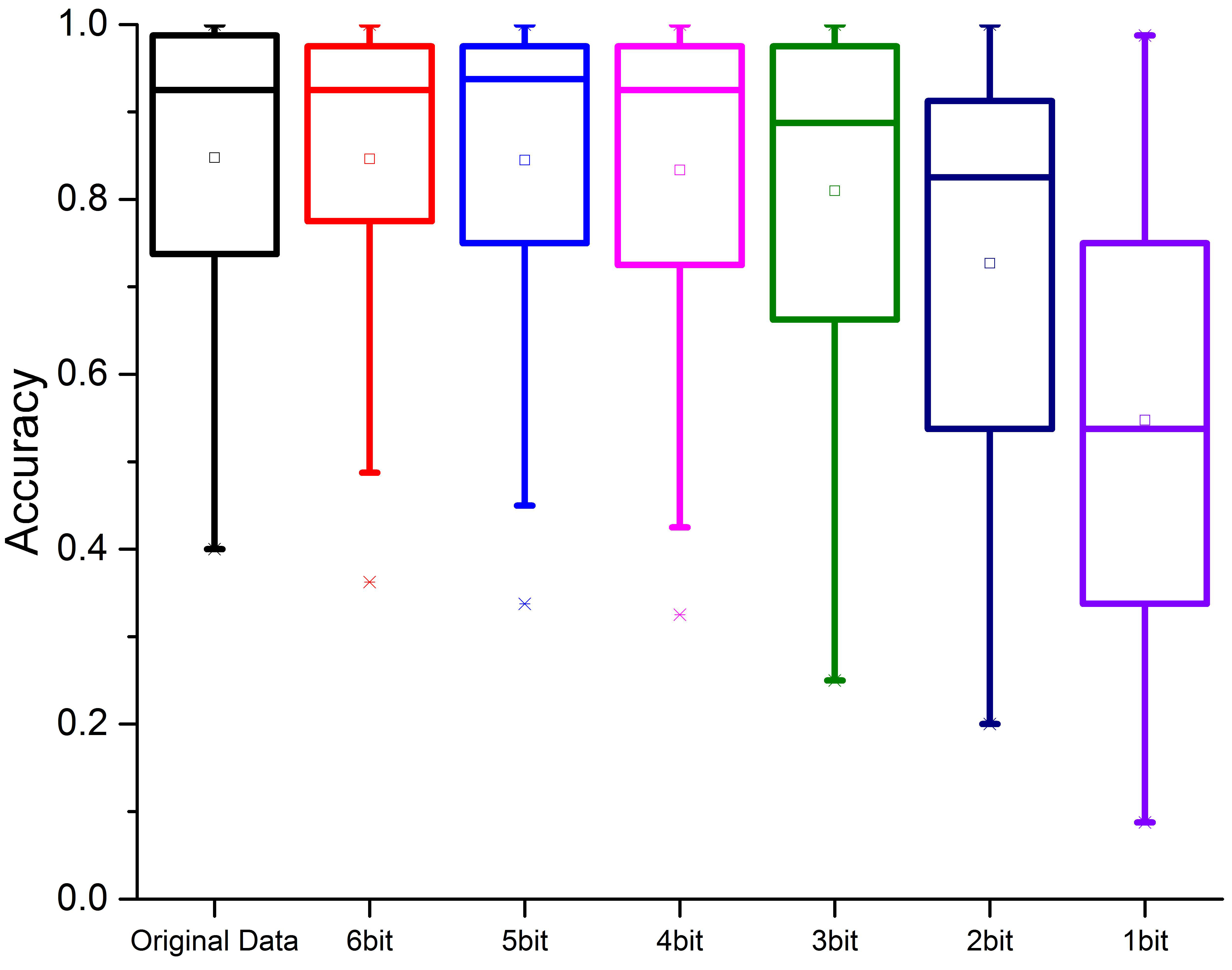
3.1. Influence of Adaptive Neural Network on Results
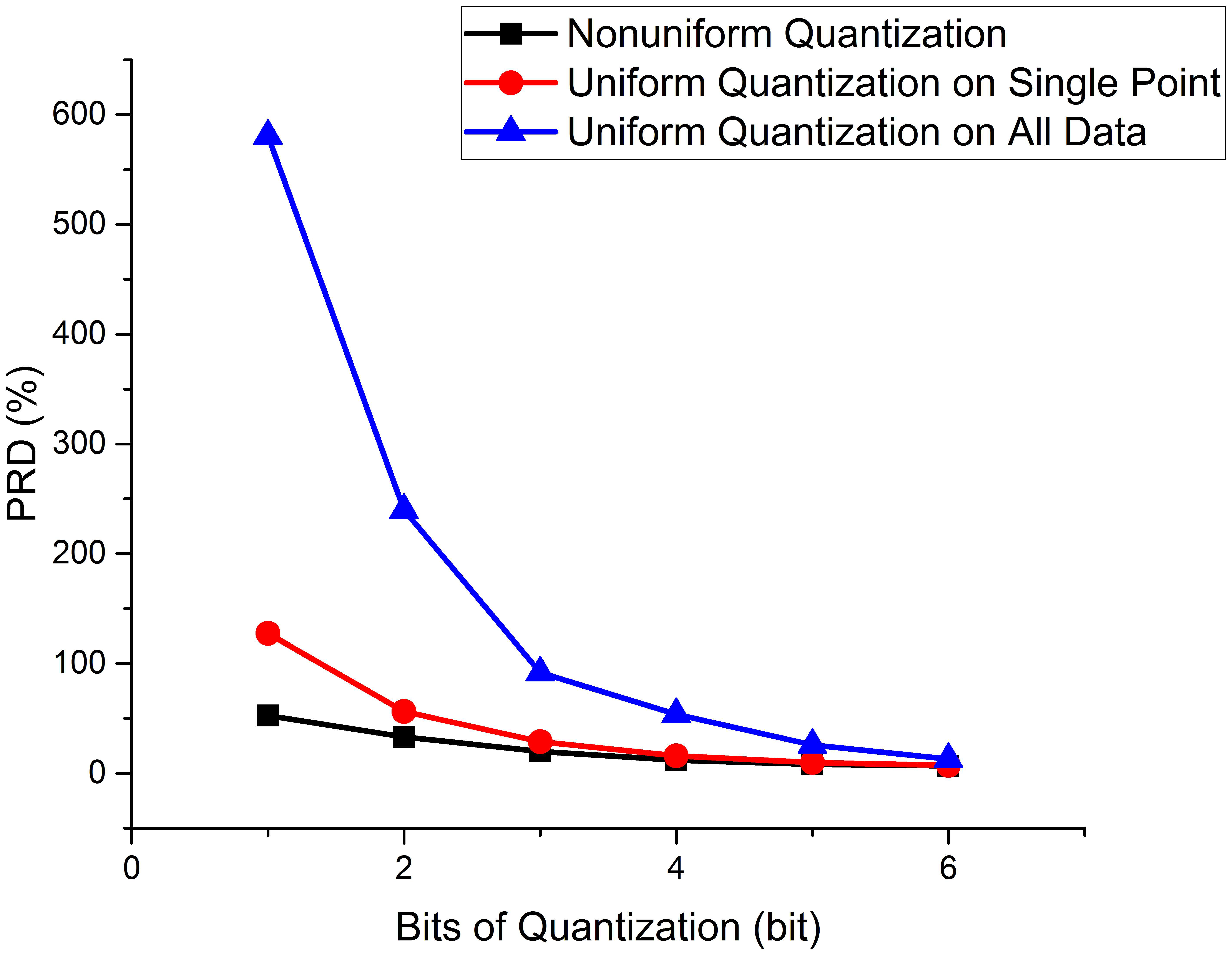
3.2. Influence of Non-Uniform Single Point Quantization on Results
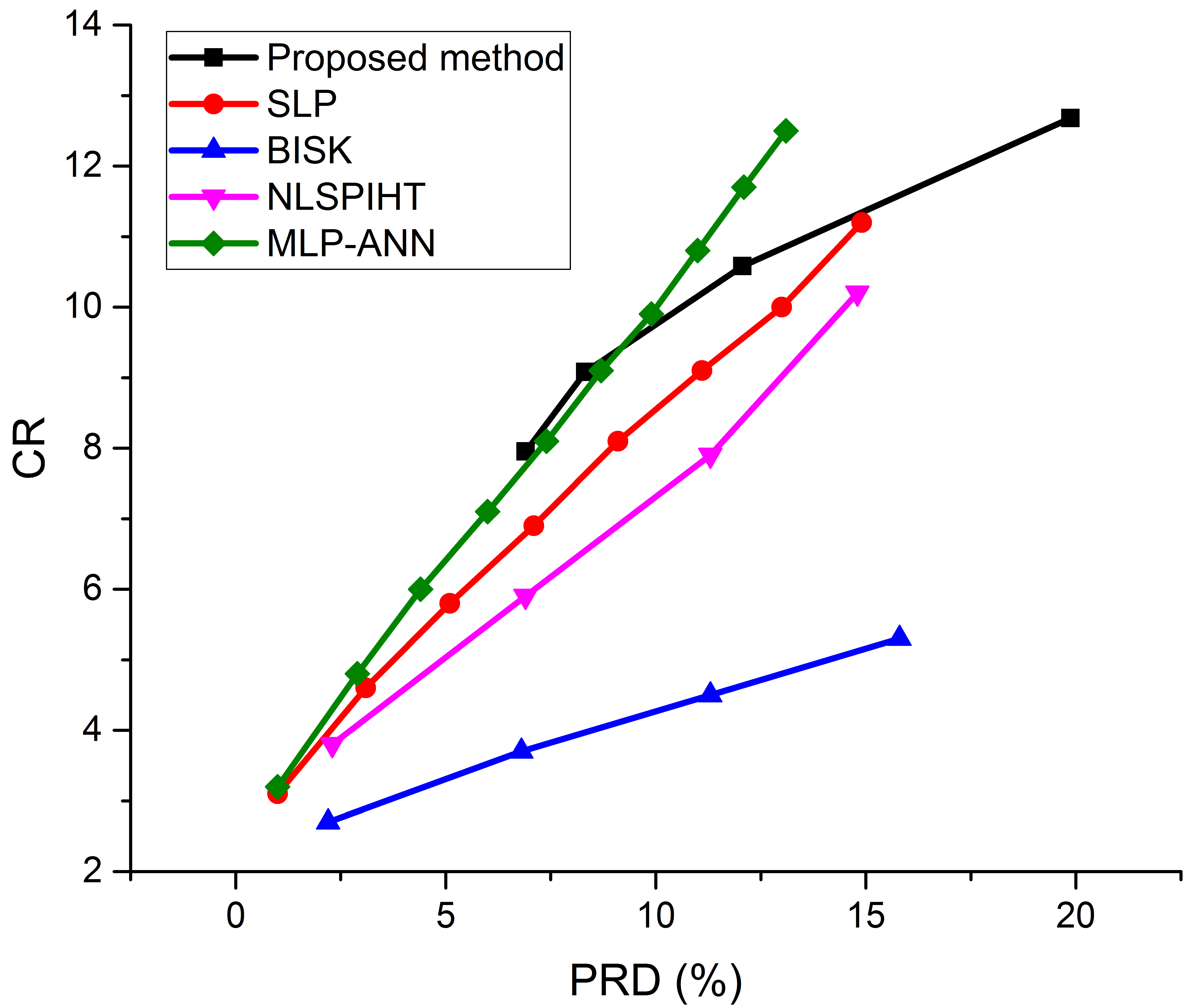
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Landhuis, E. Neuroscience: Big brain, big data. Nature 2017, 541, 559–561. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lalos, A.S.; Alonso, L.; Verikoukis, C. Model based compressed sensing reconstruction algorithms for ECG telemonitoring in WBANs. Digit. Signal Process. 2014, 35, 105–116. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Jung, T.-P.; Makeig, S.; Rao, B.D. Compressed sensing of EEG for wireless telemonitoring with low energy consumption and inexpensive hardware. IEEE Trans. Biomed. Eng. 2012, 60, 221–224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gurve, D.; Delisle-Rodriguez, D.; Bastos-Filho, T.; Krishnan, S. Trends in Compressive Sensing for EEG Signal Processing Applications. Sensors 2020, 20, 3703. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; He, D.; Li, C.; Qi, S. Brain-Computer Interface Speller Based on Steady-State Visual Evoked Potential: A Review Focusing on the Stimulus Paradigm and Performance. Brain Sci. 2021, 11, 450. [Google Scholar] [CrossRef]
- Tello, R.G.; Pant, J.K.; Mueller, S.M.; Krishnan, S.; Bastos-Filho, T.F. An Evaluation of Performance for an Independent SSVEP-BCI Based on Compressive Sensing System. In Proceedings of the World Congress on Medical Physics and Biomedical Engineering, Toronto, ON, Canada, 7–12 June 2015; pp. 982–985. [Google Scholar]
- Ingel, A.; Vicente, R. Information Bottleneck as Optimisation Method for SSVEP-Based BCI. Front. Hum. Neurosci. 2021, 15, 352. [Google Scholar] [CrossRef]
- Sharma, S.; Chaudhury, S.; Jayadeva. Block Sparse Variational Bayes Regression Using Matrix Variate Distributions With Application to SSVEP Detection. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 351–365. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Xie, S.Q.; Wang, H.; Zhang, Z. Data Analytics in Steady-State Visual Evoked Potential-Based Brain-Computer Interface: A Review. IEEE Sens. J. 2021, 21, 1124–1138. [Google Scholar] [CrossRef]
- Bonci, A.; Fiori, S.; Higashi, H.; Tanaka, T.; Verdini, F. An Introductory Tutorial on Brain–Computer Interfaces and Their Applications. Electronics 2021, 10, 560. [Google Scholar] [CrossRef]
- Bin, G.; Gao, X.; Yan, Z.; Hong, B.; Gao, S. An online multi-channel SSVEP-based brain–computer interface using a canonical correlation analysis method. J. Neural Eng. 2009, 6, 046002. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Yang, C.; Chen, X.; Wang, Y.; Gao, X. A novel training-free recognition method for SSVEP-based BCIs using dynamic window strategy. J. Neural Eng. 2021, 18, 036007. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Wang, Y.; Gao, S.; Jung, T.-P.; Gao, X. Filter bank canonical correlation analysis for implementing a high-speed SSVEP-based brain–computer interface. J. Neural Eng. 2015, 12, 046008. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Wang, Y.; Nakanishi, M.; Gao, X.; Jung, T.-P.; Gao, S. High-speed spelling with a noninvasive brain–computer interface. Proc. Natl. Acad. Sci. USA 2015, 112, E6058–E6067. [Google Scholar] [CrossRef] [Green Version]
- Ming, C.; Xiaorong, G.; Shangkai, G.; Dingfeng, X. Design and implementation of a brain-computer interface with high transfer rates. IEEE Trans. Biomed. Eng. 2002, 49, 1181–1186. [Google Scholar] [CrossRef]
- Belouadah, E.; Popescu, A.; Kanellos, I. A comprehensive study of class incremental learning algorithms for visual tasks. Neural Netw. 2021, 135, 38–54. [Google Scholar] [CrossRef] [PubMed]
- Delange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A Continual Learning Survey: Defying Forgetting in Classification Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Huang, X.; Wang, Y.; Chen, X.; Gao, X. BETA: A Large Benchmark Database Toward SSVEP-BCI Application. Front. Neurosci. 2020, 14, 627. [Google Scholar] [CrossRef] [PubMed]
- Lay, J.A.; Ling, G. Image retrieval based on energy histograms of the low frequency DCT coefficients. In Proceedings of the 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings. ICASSP99 (Cat. No.99CH36258), Phoenix, AZ, USA, 15–19 March 1999; Volume 3006, pp. 3009–3012. [Google Scholar]
- Tjahyadi, R.; Liu, W.; Venkatesh, S. Application of the DCT Energy Histogram for Face Recognition. In ICITA 2004: Proceedings of the Second International Conference on Information Technology and Applications, Harbin, China, 9–11 January 2004; [Macquarie Scientific Publishing] IEEE: Sydney, Australia, 2012; pp. 314–319. [Google Scholar]
- Sriraam, N.; Eswaran, C. Context Based Error Modeling for Lossless Compression of EEG Signals Using Neural Networks. J. Med. Syst. 2006, 30, 439–448. [Google Scholar] [CrossRef] [PubMed]
- Sutanto, A.R.; Kang, D.-K. A Novel Diminish Smooth L1 Loss Model with Generative Adversarial Network. In International Conference on Intelligent Human Computer Interaction; Springer: Cham, Switzerland, 2021; pp. 361–368. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zhonghai, W. Statistics-based Arithmetic of JPEG Quantization Table. J. Huazhong Agric. 2003, 22, 415–418. [Google Scholar]
- Zhu, F.; Jiang, L.; Dong, G.; Gao, X.; Wang, Y. An Open Dataset for Wearable SSVEP-Based Brain-Computer Interfaces. Sensors 2021, 21, 1256. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Chen, X.; Gao, X.; Gao, S. A Benchmark Dataset for SSVEP-Based Brain–Computer Interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1746–1752. [Google Scholar] [CrossRef] [PubMed]
- Hejrati, B.; Fathi, A.; Abdali-Mohammadi, F. A new near-lossless EEG compression method using ANN-based reconstruction technique. Comput. Biol. Med. 2017, 87, 87–94. [Google Scholar] [CrossRef] [PubMed]
- Sriraam, N. Correlation dimension based lossless compression of EEG signals. Biomed. Signal Process. Control 2012, 7, 379–388. [Google Scholar] [CrossRef]
- Srinivasan, K.; Dauwels, J.; Reddy, M.R. Multichannel EEG compression: Wavelet-based image and volumetric coding approach. IEEE J. Biomed. Health Inform. 2013, 17, 113–120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, G.; Han, J.; Zou, Y.; Zeng, X. A 1.5-D Multi-Channel EEG Compression Algorithm Based on NLSPIHT. IEEE Signal Processing Lett. 2015, 22, 1118–1122. [Google Scholar] [CrossRef]
- Sayood, K. (Ed.) Introduction to Data Compression; Elsevier: Amsterdam, The Netherlands, 2000. [Google Scholar]
- Nakanishi, M.; Wang, Y.; Wang, Y.-T.; Jung, T.-P. A comparison study of canonical correlation analysis based methods for detecting steady-state visual evoked potentials. PLoS ONE 2015, 10, e0140703. [Google Scholar] [CrossRef] [Green Version]
- Nakanishi, M.; Wang, Y.; Chen, X.; Wang, Y.-T.; Gao, X.; Jung, T.-P. Enhancing detection of SSVEPs for a high-speed brain speller using task-related component analysis. IEEE Trans. Biomed. Eng. 2017, 65, 104–112. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Zhang, C.; Wu, W.; Gao, X. Frequency recognition based on canonical correlation analysis for SSVEP-based BCIs. IEEE Trans. Biomed. Eng. 2006, 53, 2610–2614. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L1 | L2 | Smooth L1 | ln | log10 | |
|---|---|---|---|---|---|
| MSE | 13.98 | 36.99 | 12.07 | 16.46 | 17.80 |
| Bit | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Quantization order | 2 | 4 | 8 | 16 | 32 | 64 |
| Compression ratio | 20.9974 | 15.8103 | 12.6783 | 10.5820 | 9.0806 | 7.9523 |
| Bit | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Improved performance (%) | 15.67 | 8.01 | 12.68 | 9.91 | 13.15 | 13.74 |
| Bit | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Effect improvement compared with single-point uniform quantization (%) | 58.81 | 41.21 | 30.99 | 24.24 | 15.34 | 4.33 |
| Effect improvement compared with multi-point uniform quantization (%) | 90.98 | 86.10 | 77.62 | 77.93 | 68.99 | 46.32 |
| Bit | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Effect improvement compared with single-point uniform quantization with non-ANN (%) | 61.50 | 44.64 | 35.53 | 29.82 | 21.45 | 11.65 |
| Effect improvement compared with multi-point uniform quantization with non-ANN (%) | 91.61 | 87.30 | 81.08 | 75.92 | 66.01 | 50.43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Ma, K.; Yin, Y.; Ren, B.; Liu, M. A Personalized Compression Method for Steady-State Visual Evoked Potential EEG Signals. Information 2022, 13, 186. https://doi.org/10.3390/info13040186
Zhang S, Ma K, Yin Y, Ren B, Liu M. A Personalized Compression Method for Steady-State Visual Evoked Potential EEG Signals. Information. 2022; 13(4):186. https://doi.org/10.3390/info13040186
Chicago/Turabian StyleZhang, Sitao, Kainan Ma, Yibo Yin, Binbin Ren, and Ming Liu. 2022. "A Personalized Compression Method for Steady-State Visual Evoked Potential EEG Signals" Information 13, no. 4: 186. https://doi.org/10.3390/info13040186
APA StyleZhang, S., Ma, K., Yin, Y., Ren, B., & Liu, M. (2022). A Personalized Compression Method for Steady-State Visual Evoked Potential EEG Signals. Information, 13(4), 186. https://doi.org/10.3390/info13040186