
Medical Knowledge Graph Completion Based on Word Embeddings

Abstract
:1. Introduction
2. Related Works
3. Methods
3.1. Problem Statement
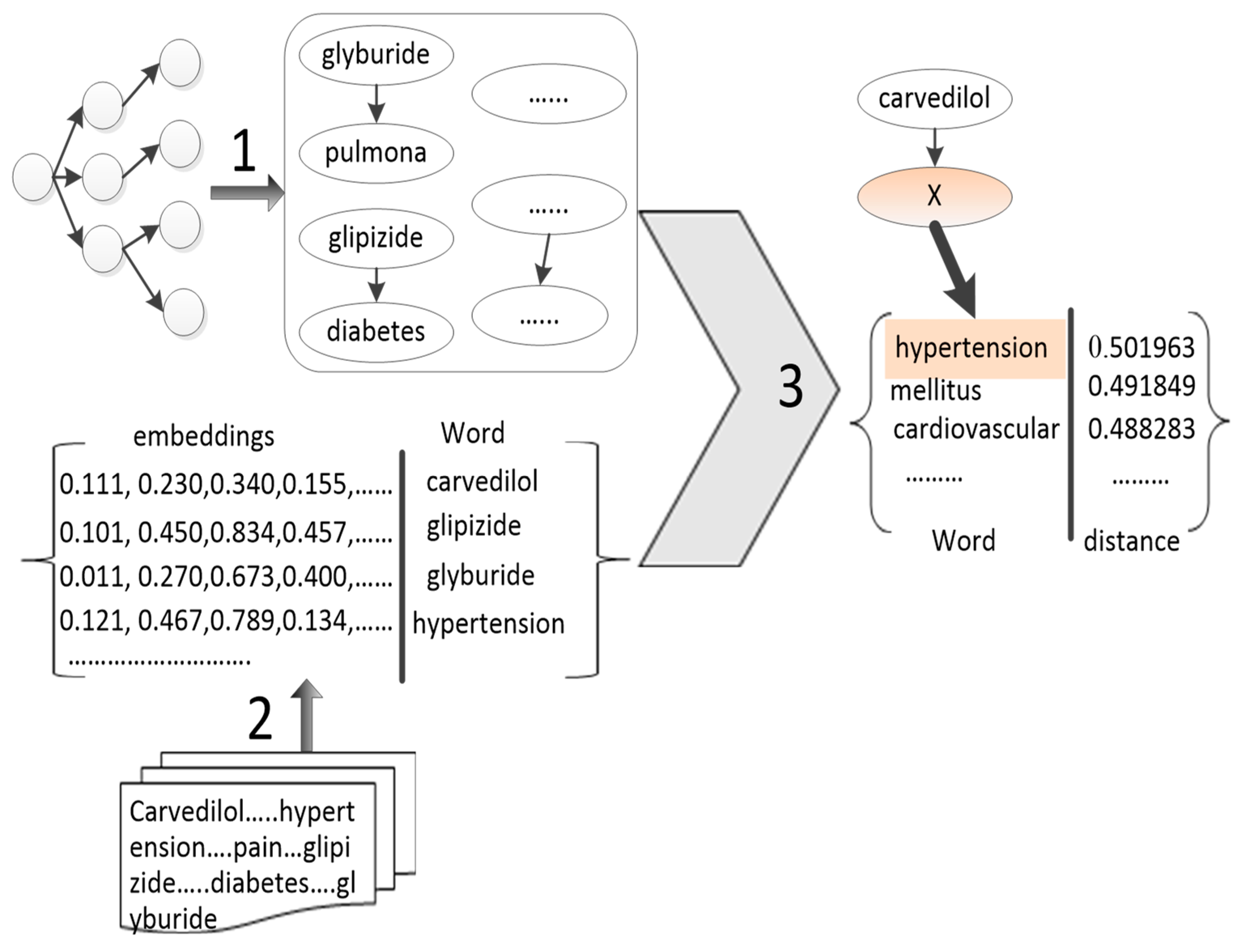
3.2. Prior Knowledge Acquiring
3.3. Word Embeddings Trained by Word2vec
3.4. Triples Predicting
| Algorithm 1 Predicting Triples Algorithm |
| Input: a given entity C; word embeddings ; a set of triples related to a relationship R ; the number of candidate words TopN; the number of clusters ; the number of iterations ;
Output: a set of candidate words ; |
| *** 1. Refining relationships by clustering ***
if T≠ null {for (j = 1, j + +, k) {Acquiring embeddings from for and ; ;} K-means (}, , );} *** 2. Refining relationships by mean *** for (j = 1, j + +, CN) {if ≠ null {n = ||; ; Acquiring from ; ; *** 3. Acquiring candidates *** Acquiring the top TopN words from ;}} *** clustering by K-means *** Input: a set of clustering elements R; the number of clusters ; the number of iterations ; Output: clustering results doing K-means; |
4. Experiments
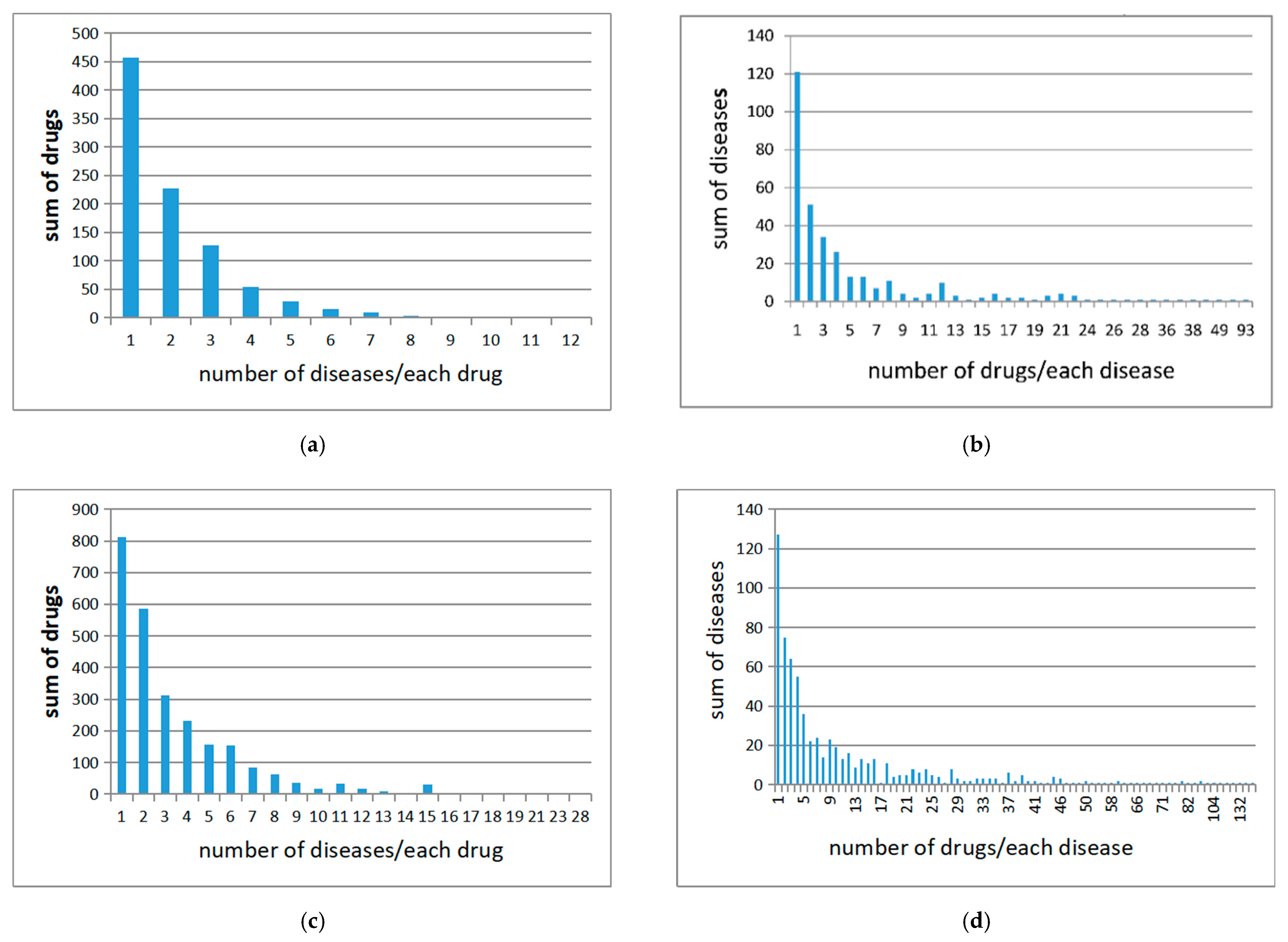
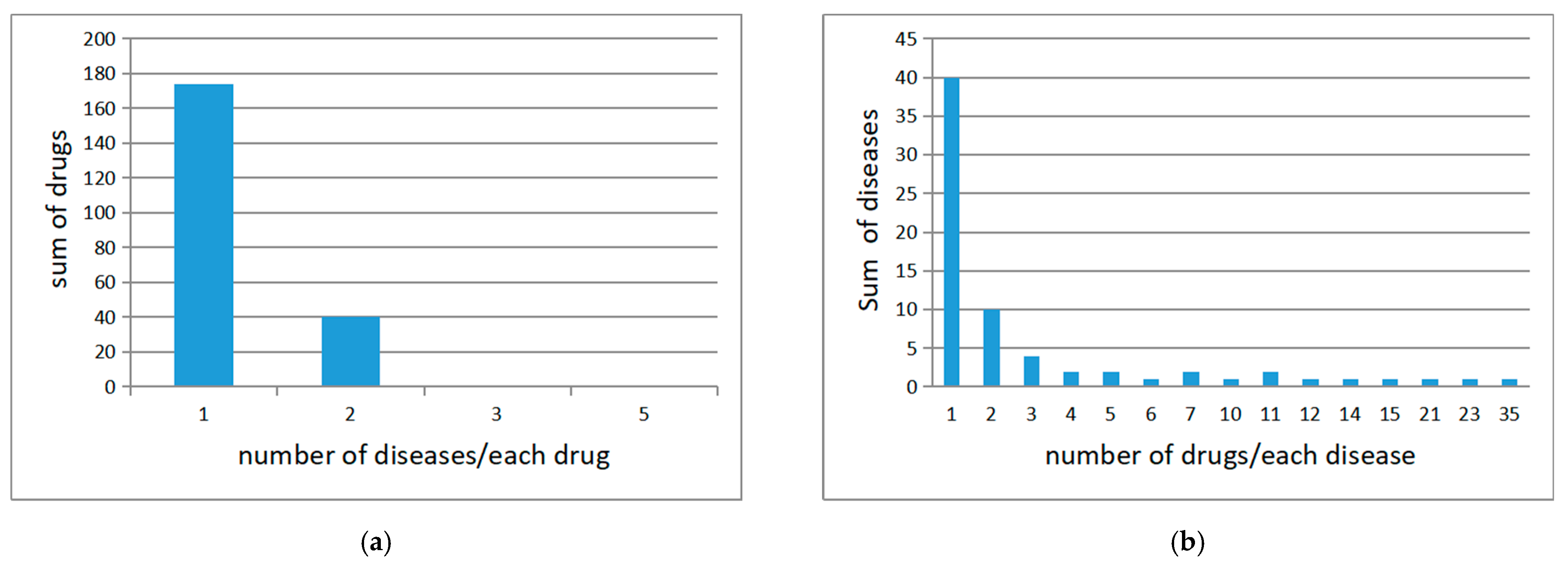
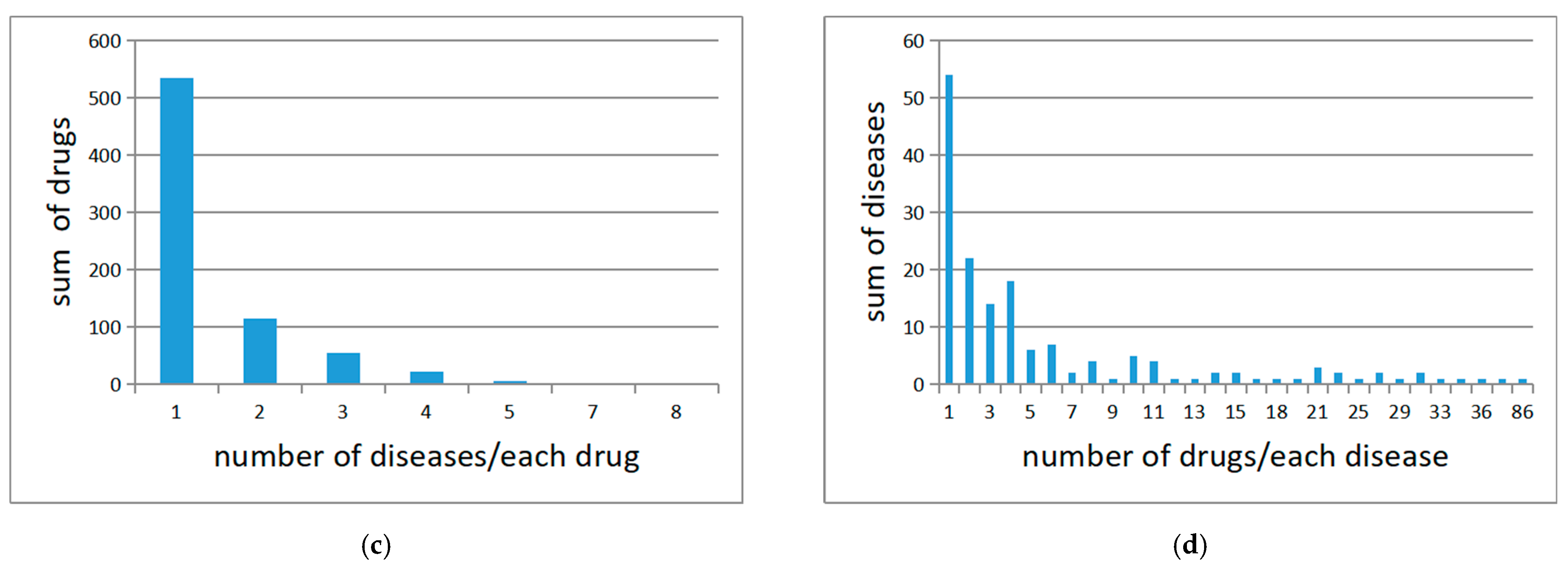
4.1. Medical Knowledge Graphs and Preprocessing
4.2. Data Collecting and Preprocessing
4.3. Experimental Setup
4.4. Experimental Results
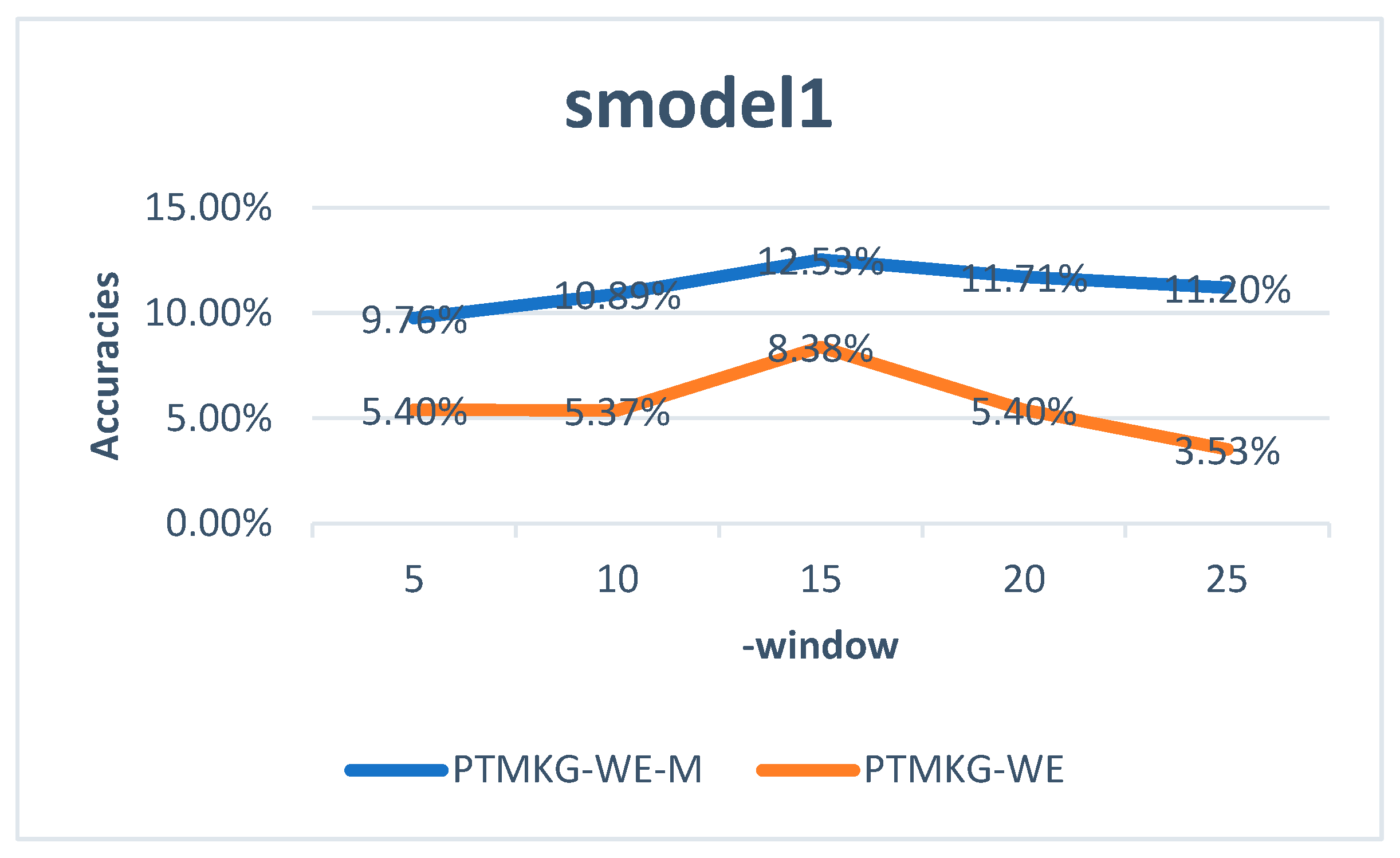
4.4.1. Models Trained by Word2vec
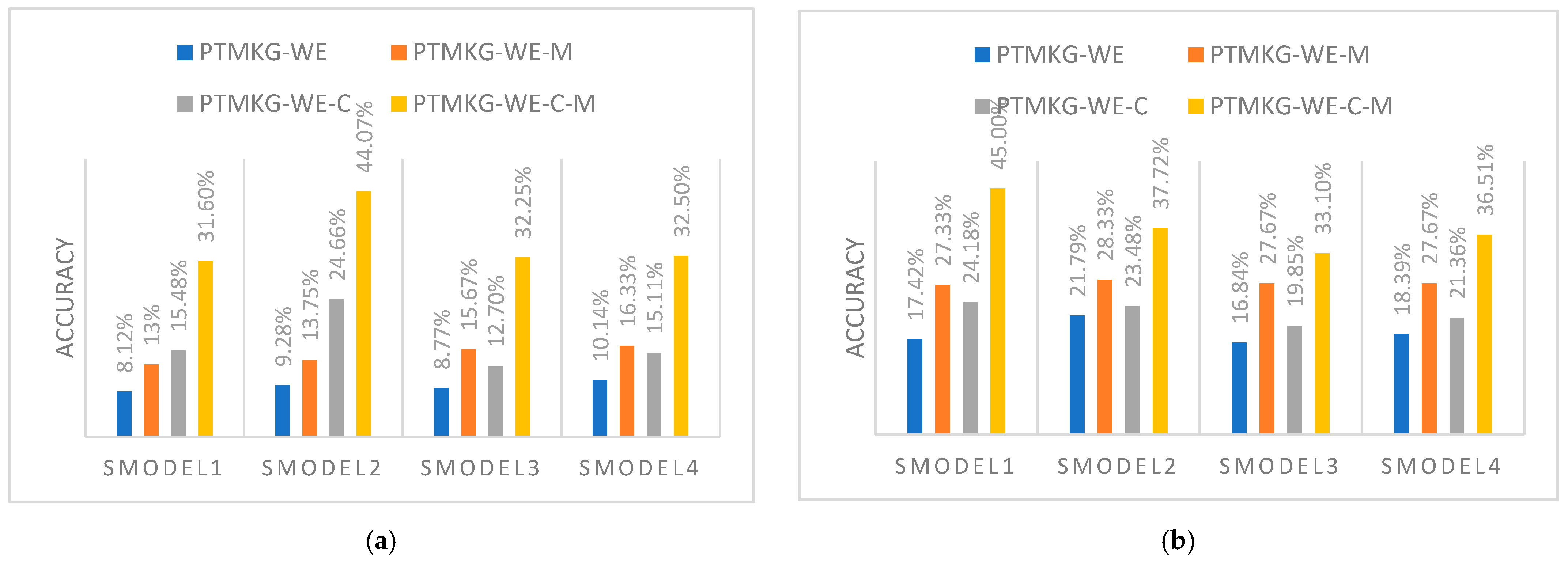
4.4.2. Experimental Results for Single Words
4.4.3. Experimental Results for Double Words
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gu, P.; Chen, H.; Yu, T. Ontology-oriented diagnostic system for traditional Chinese medicine based on relation refinement. Comput. Math. Methods Med. 2013, 57, 317803. [Google Scholar] [CrossRef] [PubMed]
- Jalali, V.; Matash Borujerdi, M.R. Mohammad. A unified architecture for biomedical search engines based on semantic web technologies. J. Med. Syst. 2011, 35, 237–249. [Google Scholar] [CrossRef] [PubMed]
- Midhunlal, M.; Gopika, M. Xmqas—An ontology based medical question answering system. Int. J. Adv. Res. Comput. Commun. Eng. 2016, 5, 829–832. [Google Scholar]
- Coulet, A.; Shah, N.H.; Garten, Y.; Musen, M.; Altman, R.B. Using text to build semantic networks for pharmacogenomics. J. Biomed. Inform. 2010, 43, 1009–1019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ben Abacha, A.; Zweigenbaum, P. Automatic extraction of semantic relations between medical entities: A rule based approach. J. Biomed. Semant. 2011, 2 (Suppl. 5), 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781v3. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Jevlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Su, M.; Su, H. Deep learning for knowledge graph completion with XLNET. In Proceedings of the ICDLT 2021, Qingdao, China, 23–25 July 2021. [Google Scholar]
- Jaradeh, M.Y.; Singh, K.; Stocker, M.; Auer, S. Triple classification for scholarly knowledge graph completion. In Proceedings of the K-CAP’21, Virtual Event, 2–3 December 2021. [Google Scholar]
- Minarro-Gimenez, J.A.; Marın-Alonso, O.; Samwald, M. Applying deep learning techniques on medical corpora from the world wide web: A prototypical system and evaluation. arXiv 2015, arXiv:1502.03682. [Google Scholar]
- Casteleiro, M.A.; Demetriou, G.; Read, W.J.; Prieto, M.J.F.; MasedaFernandez, D.; Nenadic, G.; Klein, J.; Keane, J.A.; Stevens, R. Deep learning meets semantic web: A feasibility study with the cardiovascular disease ontology and pubmed citations. In Proceedings of the 7th Workshop on Ontologies and Data in Life Sciences 2016, Halle (Saale), Germany, 29–30 September 2016. [Google Scholar]
- Lan, Y.; He, S.; Liu, K.; Zeng, X.; Liu, S.; Zhao, J. Path-based knowledge reasoning with textual semantic information for medical knowledge graph completion. BMC Med. Inform. Decis. Mak. 2021, 21, 1–10. [Google Scholar] [CrossRef] [PubMed]
- He, B.; Zhou, D.; Xiao, J.; Jiang, X.; Liu, Q.; Yuan, N.J.; Xu, T. BERT-MK: Integrating graph contextualized knowledge into pre-trained language models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Hong Kong, China, 16–20 November 2020. [Google Scholar]
- Arnaud, É.; Elbattah, M.; Gignon, M.; Dequen, G. Learning embeddings from free-text triage notes using pretrained transformer models. In Proceedings of the 15th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2022), Vienna, Austria, 9–11 February 2022. [Google Scholar]
- Chang, D.; Hong, W.S.; Taylor, R.A. Generating contextual embeddings for emergency department chief complaints. JAMIA Open 2020, 3, 160–166. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Examples |
|---|---|
| 1 | v(fentanyl) − v(pain) = v(polymyxin) − v(urinary) |
| 2 | v(interferon) − v(purpura) = v(rifampin) − v(leprosy) |
| 3 | v(fluocinolone) − v(facial)/ = v(topiramate) − v(spasms) |
| Relationship | Type of Triples | Triples | Head | Tail |
|---|---|---|---|---|
| may_treat | original triples | 51,248 | 11,655 | 956 |
| single word | 1915 | 930 | 334 | |
| double word | 8677 | 2566 | 680 | |
| may_prevent | original triples | 6292 | 4076 | 215 |
| single word | 262 | 216 | 70 | |
| double word | 1094 | 742 | 162 |
| Name | Source | Articles | Size | Title | Abstract | Body |
|---|---|---|---|---|---|---|
| data1 | PMCOAS | 1.3 M | 1.21 G | Y | Y | N |
| data2 | 19.8 G | Y | Y | Y | ||
| data3 | PubMed | 26 M | 2.2 G | Y | N | N |
| data4 | 15.12 G | Y | Y | N | ||
| data5 | 22.06 G | Y | Y | N | ||
| C34dd1 | PMCOAS | 1.3 M | 1.21 G | Y | Y | N |
| C34dd2 | 19.8 G | Y | Y | Y | ||
| C34dd3 | PubMed | 26 M | 2.2 G | Y | N | N |
| C34dd4 | 15.12 G | Y | Y | N | ||
| C38dd1 | PMCOAS | 1.3 M | 1.21 G | Y | Y | N |
| C38dd2 | 19.8 G | Y | Y | Y | ||
| C38dd3 | PubMed | 26 M | 2.2 G | Y | N | N |
| C38dd4 | 15.12 G | Y | Y | N |
| Name | Source | -Windows | Size (G) | Words |
|---|---|---|---|---|
| smodel1 | data1 | 15 | 0.5 | 155,407,624 |
| smodel2 | data2 | 15 | 2.09 | 2,634,263,510 |
| smodel3 | data3 | 5 | 1.20 | 307,063,987 |
| smodel4 | data4 | 15 | 2.14 | 1,924,072,604 |
| smodel5 | data5 | 15 | 6.30 | 3,390,842,792 |
| c34dmodel1 | c34dd1 | 15 | 0.5 | 155,192,660 |
| c34dmodel2 | c34dd2 | 15 | 2.09 | 2,631,795,611 |
| c34dmodel3 | c34dd3 | 5 | 1.2 | 155,192,660 |
| c34dmodel4 | c34dd4 | 15 | 2.14 | 2,631,795,611 |
| c38dmodel1 | c38dd1 | 15 | 0.5 | 155,192,660 |
| c38dmodel2 | c38dd2 | 15 | 2.09 | 2,631,795,611 |
| c38dmodel3 | c38dd3 | 5 | 1.2 | 155,192,660 |
| c38dmodel4 | c38dd4 | 15 | 2.14 | 2,631,795,611 |
| Models | Methods | Accuracies |
|---|---|---|
| smodel4 | PTMKG-WE | 10.14% |
| PTMKG-WE-M | 16.33% | |
| smodel5 | PTMKG-WE | 5.66% |
| PTMKG-WE-M | 9.67% |
| Relationship | No./Triples | Methods | Accuracies | |||
|---|---|---|---|---|---|---|
| smodel1 | smodel2 | smodel3 | smodel4 | |||
| may_treat | c1/19 | PTMKG-WE-C | 45.61% | 60.8% | 17.5% | 23.4% |
| PTMKG-WE-C-M | 89.47% | 89.5% | 78.9% | 89.5% | ||
| c2/121 | PTMKG-WE-C | 74.02% | 64.1% | 20.7% | 35.7% | |
| PTMKG-WE-M | 89.24% | 90.7% | 90.3% | 88.7% | ||
| c3/599 | PTMKG-WE-C | 10.81% | 16.6% | 11.2% | 14.6% | |
| PTMKG-WE-M | 18.67% | 24% | 22.3% | 20.3% | ||
| c4/73 | PTMKG-WE-C | 70.83% | 58.4% | 52.9% | 28.8% | |
| PTMKG-WE-C-M | 89.04% | 97.3% | 89% | 91.8% | ||
| c5/29 | PTMKG-WE-C | 89.16% | 88.2% | 77.8% | 74.3% | |
| PTMKG-WE-C-M | 86.21% | 79.3% | 79.3% | 82.8% | ||
| c6/210 | PTMKG-WE-C | 8.2% | 15.2% | 5.3% | 7.5% | |
| PTMKG-WE-C-M | 26.67% | 42% | 17% | 34.3% | ||
| c7/355 | PTMKG-WE-C | 10.19% | 14.5% | 7% | 10.7% | |
| PTMKG-WE-C-M | 17.33% | 21.7% | 15% | 17% | ||
| c8/16 | PTMKG-WE-C | 62.92% | 42.5% | 14.6% | 0 | |
| PTMKG-WE-C-M | 50% | 37.5% | 43.8% | 43.8 | ||
| c9/99 | PTMKG-WE-C | 17.73% | 13.1% | 6.5% | 9.3% | |
| PTMKG-WE-C-M | 37.37% | 43.4% | 35.4% | 39% | ||
| c10/64 | PTMKG-WE-C | 15.25% | 21.3% | 6.2% | 10.9% | |
| PTMKG-WE-C-M | 25% | 43.8% | 21.9% | 26.6% | ||
| c1-c10/1585 | PTMKG-WE-C | 15.26% | 24.02% | 13.33% | 19.86% | |
| PTMKG-WE-C-M | 31.87% | 38.7% | 31.47% | 32.33% | ||
| may_prevent | c1/35 | PTMKG-WE-C | 50.17% | 57.9% | 41.5% | 29.2% |
| PTMKG-WE-C-M | 88.57% | 97.1% | 81.7% | 91.4% | ||
| c2/160 | PTMKG-WE-C | 19.59% | 18.9% | 16.4% | 22.5% | |
| PTMKG-WE-C-M | 31.00% | 26.3% | 26.7% | 31% | ||
| c1-c2/195 | PTMKG-WE-C | 25.13% | 25.9% | 20.87% | 23.75% | |
| PTMKG-WE-C-M | 45.32% | 39.07% | 37.3% | 41.9% | ||
| No./Triples | Methods | MRR | MRR+ |
|---|---|---|---|
| c1/19 | PTMKG-WE-C | 0.27 | 0.28 |
| PTMKG-WE-C-M | 0.374 | 0.5 | |
| c2/121 | PTMKG-WE-C | 0.355 | 0.383 |
| PTMKG-WE-C-M | 0.734 | 0.742 | |
| c3/599 | PTMKG-WE-C | 0.16 | 0.169 |
| PTMKG-WE-C-M | 0.195 | 0.213 | |
| c4/73 | PTMKG-WE-C | 0.327 | 0.327 |
| PTMKG-WE-C-M | 1 | 1 | |
| c5/29 | PTMKG-WE-C | 0.596 | 0.616 |
| PTMKG-WE-C-M | 0.816 | 1 | |
| c6/210 | PTMKG-WE-C | 0.168 | 0.177 |
| PTMKG-WE-C-M | 0.364 | 0.37 | |
| c7/355 | PTMKG-WE-C | 0.357 | 0.357 |
| PTMKG-WE-C-M | 0.361 | 0.361 | |
| c8/16 | PTMKG-WE-C | 0.183 | 0.188 |
| PTMKG-WE-C-M | 1 | 1 | |
| c9/99 | PTMKG-WE-C | 0.31 | 0.313 |
| PTMKG-WE-C-M | 0.487 | 0.563 | |
| c10/64 | PTMKG-WE-C | 0.116 | 0.116 |
| PTMKG-WE-C-M | 0.279 | 0.281 |
| Relationship | No./Triples | Methods | Accuracies | |||
|---|---|---|---|---|---|---|
| dd1 | dd2 | dd3 | dd4 | |||
| may_treat | c1/762 | PTMKG-WE-C | 4.64% | 6.00% | 2.22% | 6.44% |
| PTMKG-WE-C-M | 7.67%8 | 11.00% | 5.0% | 11.67% | ||
| c2/278 | PTMKG-WE-C | 10.61% | 12.6% | 10.60% | 16.67% | |
| PTMKG-WE-C-M | 17% | 19.00% | 19.00% | 23.00% | ||
| c3/466 | PTMKG-WE-C | 16.24% | 17.5% | 17.37% | 17.29% | |
| PTMKG-WE-C-M | 33.33% | 37.7% | 43.00% | 27.67% | ||
| c4/342 | PTMKG-WE-C | 2.83% | 5.30% | 2.0% | 3.31% | |
| PTMKG-WE-C-M | 11.67% | 23.00% | 5.7% | 19.00% | ||
| c5/429 | PTMKG-WE-C | 2.77% | 8.30% | 2.00% | 4.61% | |
| PTMKG-WE-C-M | 8% | 18.3% | 5.7% | 12.33% | ||
| c6/324 | PTMKG-WE-C | 2.01% | 3.70% | 1.88% | 4.64% | |
| PTMKG-WE-C-M | 4.33% | 12.7% | 7.3% | 9.67% | ||
| c7/794 | PTMKG-WE-C | 8.01% | 11.8% | 8.45% | 12.79% | |
| PTMKG-WE-C-M | 15.33% | 19.3% | 15.7% | 19.67% | ||
| c8/301 | PTMKG-WE-C | 13.65% | 19.26% | 11.44% | 7.31% | |
| PTMKG-WE-C-M | 31.67% | 37.00% | 29.7% | 18.33% | ||
| c9/152 | PTMKG-WE-C | 8.33% | 16.93% | 7.47% | 13.96% | |
| PTMKG-WE-C-M | 12.67% | 24.3% | 17.3% | 21.67% | ||
| c10/30 | PTMKG-WE-C | 22.99% | 40.00% | 13.9% | 38.74% | |
| PTMKG-WE-C-M | 23.33% | 50.00% | 40.00% | 40.00% | ||
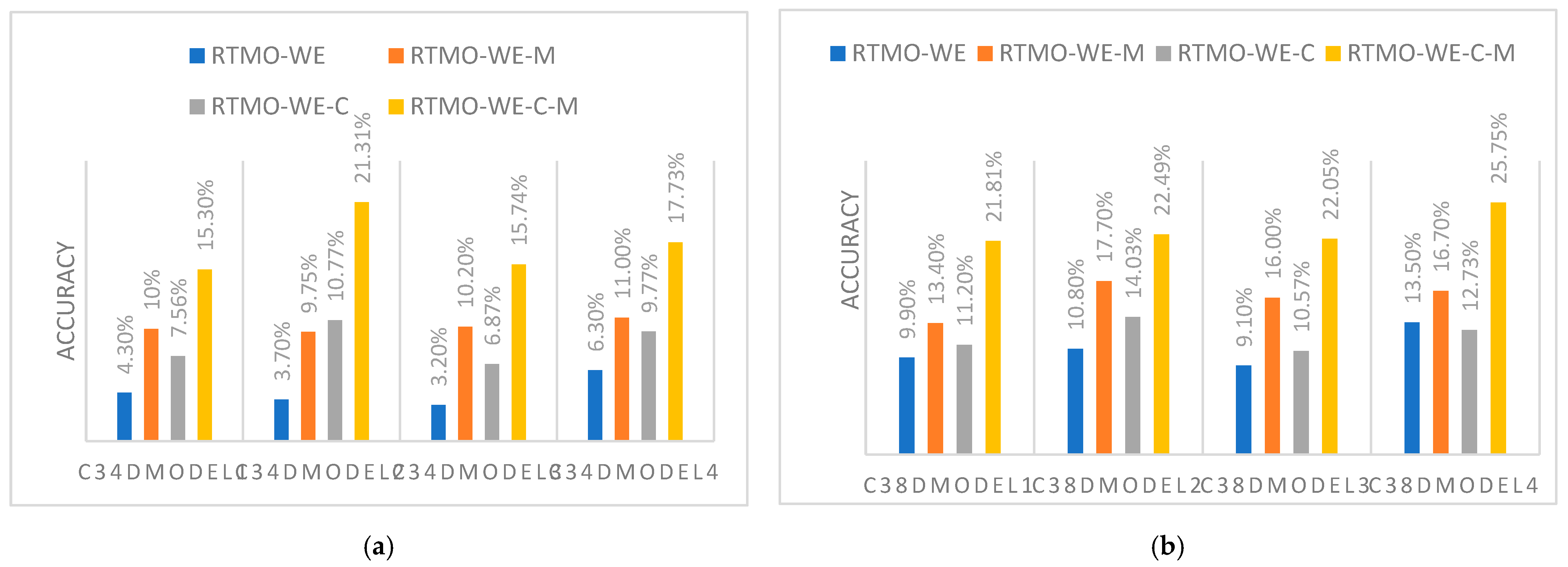
| c1-c10/3878 | PTMKG-WE-C | 7.56% | 10.77% | 6.87% | 9.77% | |
| PTMKG-WE-C-M | 15.3% | 21.31% | 15.74% | 17.74% | ||
| may_prevent | c1/466 | PTMKG-WE-C | 7.7% | 10.94% | 8.5% | 13.4% |
| PTMKG-WE-C-M | 14% | 14.33% | 16.00% | 18.7% | ||
| c2/51 | PTMKG-WE-C | 17.5% | 27.45% | 9.3% | 11.5% | |
| PTMKG-WE-C-M | 68.6% | 68.62% | 51.00% | 62.7% | ||
| c3/19 | PTMKG-WE-C | 81.3% | 54.39% | 65.8% | 0% | |
| PTMKG-WE-C-M | 89.5% | 100.00% | 94.7% | 100.00% | ||
| c1-c3/536 | PTMKG-WE-C | 11.2% | 14.03% | 10.57% | 12.73% | |
| PTMKG-WE-C-M | 21.81% | 22.49% | 22.05% | 25.75% | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, M.; Lu, J.; Chen, F. Medical Knowledge Graph Completion Based on Word Embeddings. Information 2022, 13, 205. https://doi.org/10.3390/info13040205
Gao M, Lu J, Chen F. Medical Knowledge Graph Completion Based on Word Embeddings. Information. 2022; 13(4):205. https://doi.org/10.3390/info13040205
Chicago/Turabian StyleGao, Mingxia, Jianguo Lu, and Furong Chen. 2022. "Medical Knowledge Graph Completion Based on Word Embeddings" Information 13, no. 4: 205. https://doi.org/10.3390/info13040205
APA StyleGao, M., Lu, J., & Chen, F. (2022). Medical Knowledge Graph Completion Based on Word Embeddings. Information, 13(4), 205. https://doi.org/10.3390/info13040205