
Sign Language Avatars: A Question of Representation

 , , , ,
, , , ,
Abstract
:1. Introduction
1.1. Background
1.2. Language Quality
1.3. Challenges to Signed Language Display
1.4. Modality
1.5. Display Technology
For something like film or television, I could create a kickass animation of a monster jumping off a building and landing on the street below, but to do the same thing in a game, the movement has to be broken up into separate parts. This is because he probably won’t do the exact same action every time. There may be buildings of different heights in the game, so I can’t hard-code the height of the jump into the animation. I have to create an initial jump animation, then an idle hang-time animation to play while he’s in the air, and then a landing animation. The programmer then strings the jump, hang-time, and landing together and decides the timing and trajectory of the hang-time part procedurally. That takes artistic control away from the animator and can result in some fugly animation.
2. Representation Considerations
2.1. Digital Availability
2.2. Anonymity
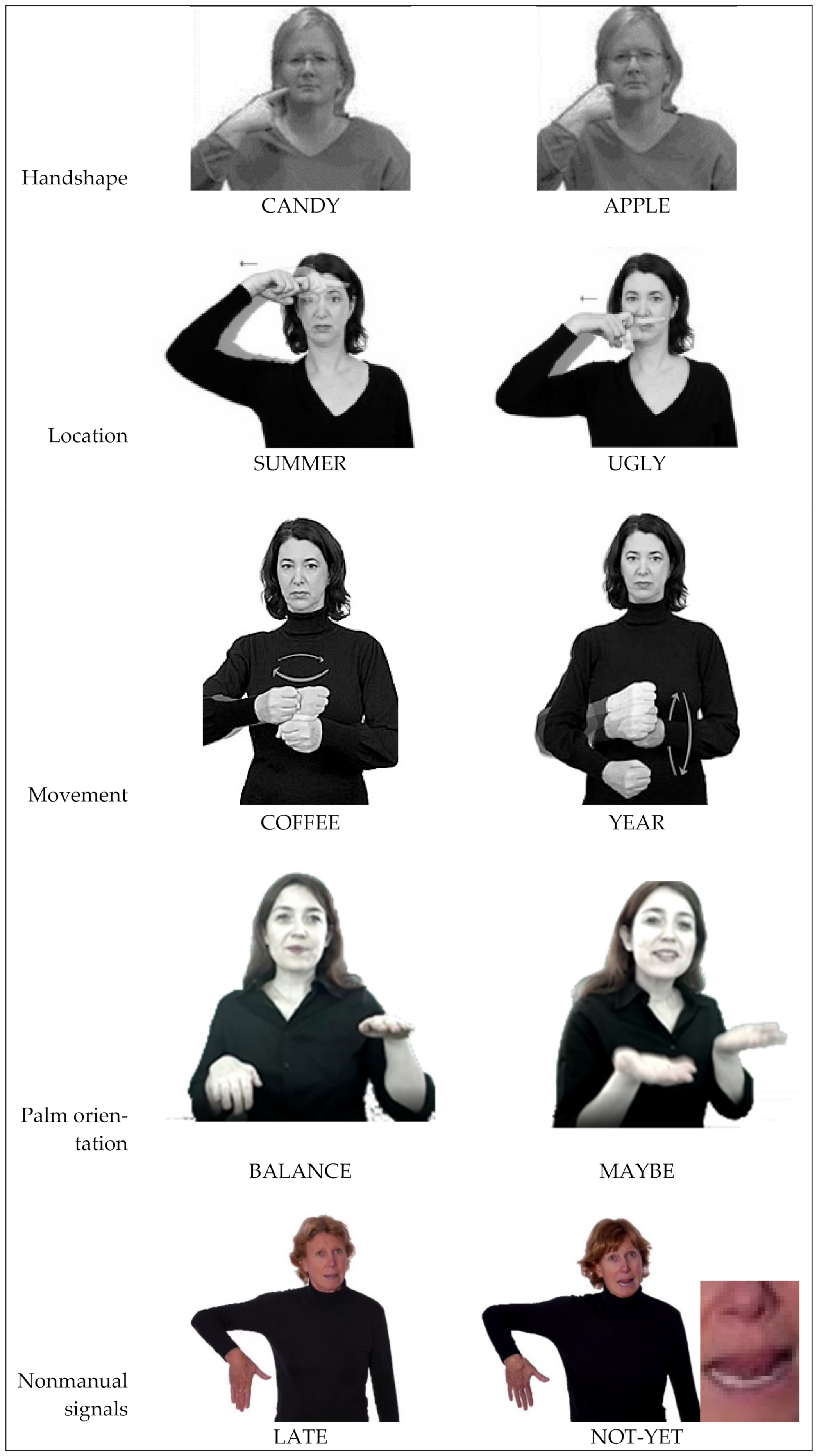
2.3. Specifying Full 3D Information
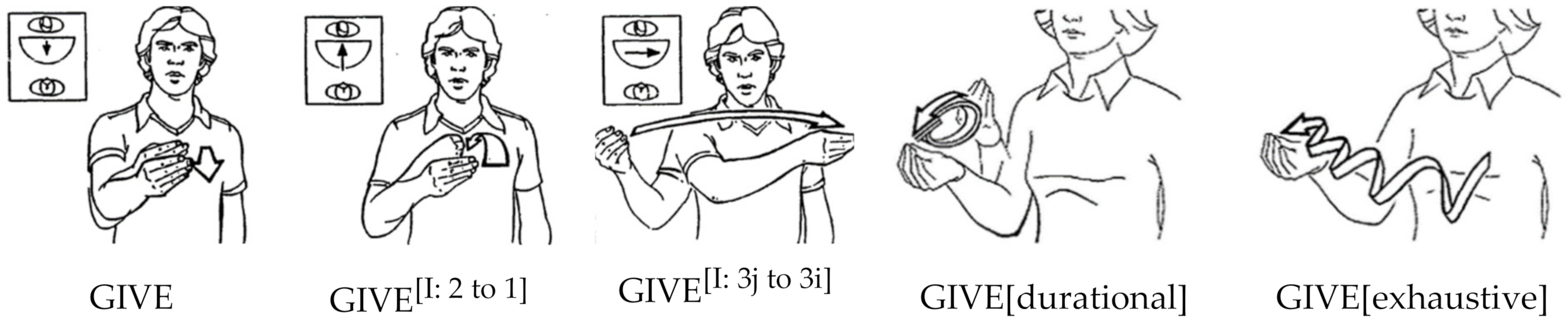
2.4. Specifying Motion
2.5. Self-Evident
2.6. Incorporates Nonmanual Channels
2.7. Level of Detail
2.7.1. Motion Capture and Video Tracing
2.7.2. Key Frame Animation
2.7.3. Phonemic and Phonetic Representation
2.7.4. Lexical and Morphological Considerations
2.7.5. Phrasal Level
2.8. Asynchrony
2.9. Corpora Availability
2.10. Easy Authoring
3. Comparing Representations
4. Conclusions and Future Directions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hassan, H.; Aue, A.; Chen, C.; Chowdhary, V.; Clark, J.; Federmann, C.; Huang, X.; Junczys-Dowmunt, M.; Lewis, W.; Li, M.; et al. Achieving Human Parity on Automatic Chinese to English News Translation. 2018. Microsoft.com. Available online: https://www.microsoft.com/en-us/research/uploads/prod/2018/03/final-achieving-human.pdf (accessed on 24 March 2022).
- Ebling, S. Automatic Translation from German to Synthesized Swiss German Sign Language. Ph.D. Dissertation, University of Zurich, Zurich, Switzerland, 2016. [Google Scholar]
- Naert, L.; Larboulette, C.; Gibet, S. A survey on the animation of signing avatars: From sign representation to utterance synthesis. Comput. Graph. 2020, 92, 76–98. [Google Scholar] [CrossRef]
- Traxler, C.B. The Stanford Achievement Test, 9th Edition: National norming and performance standards for deaf and hard-of-hearing students. J. Stud. Deaf. Educ. 2000, 5, 337–348. [Google Scholar] [CrossRef] [PubMed]
- Gutjahr, A.E. Lesekompetenz Gehörloser: Ein Forschungsüberblick. Ph.D. Thesis, Universität Hamburg, Hamburg, Germany, 2006. [Google Scholar]
- Hennies, J. Lesekompetenz Gehörloser und Schwerhöriger SchülerInnen Ein Beitrag zur Empirischen Bildungsforschung in der Hörgeschädigtenpädagogik. Ph.D. Thesis, Humboldt University of Berlin, Berlin, Germany, June 2010. [Google Scholar]
- Konrad, R. Die Lexikalische Struktur der Deutschen Gebärdensprache im Spiegel Empirischer Fachgebärdenlexikographie; Gunter Narr Verlag: Tübingen, Germany, 2011. [Google Scholar]
- De Meulder, M.; Krausneker, V.; Turner, G.; Conama, J.B. Sign Language Communities. In The Palgrave Handbook of Minority Languages and Communities; Hogan-Burn, G., O’Rourke, B., Eds.; Palgrave Macmillan: London, UK, 2019; pp. 207–232. [Google Scholar]
- Branson, J.; Miller, D. Nationalism and the linguistic rights of Deaf communities: Linguistic imperialism and the recognition and development of sign languages. J. Socioling 1998, 2, 3–34. [Google Scholar] [CrossRef]
- World Federation of the Deaf. WFD and WASLI Statement of Use of Signing Avatars. 2018. World Federation of the Deaf. Available online: https://wfdeaf.org/news/resources/wfd-wasli-statement-use-signing-avatars/ (accessed on 24 March 2022).
- European Union of the Deaf. Accessibility of Information and Communication. 2018. European Union of the Deaf. Available online: https://www.eud.eu/about-us/eud-position-paper/accessibility-information-and-communication/ (accessed on 24 March 2022).
- Erard, M. Why Sign-Language Gloves Don’t Help Deaf People. 2017. The Atlantic. Available online: https://www.theatlantic.com/technology/archive/2017/11/why-sign-language-gloves-dont-help-deaf-people/545441/ (accessed on 24 March 2022).
- Austrian Association of Applied Linguistics. Position Paper on Automated Translations and Signing Avatars. 2019. Verbal; Verband für Angewandte Linguistik Österreich. Available online: https://www.verbal.at/stellungnahmen/Position_Paper-Avatars_verbal_2019.pdf (accessed on 24 March 2022).
- Sayers, D.; Sousa-Silva, R.; Höhn, S.; Ahmedi, L.; Allkivi-Metsoja, K.; Anastasiou, D.; Beňuš, Š.; Bowker, L.; Bytyçi, E.; Catala, A.; et al. The Dawn of the Human-Machine Era: A Forecast of New and Emerging Language Technologies. 2021. LITHME. Available online: https://lithme.eu/wp-content/uploads/2021/05/The-dawn-of-the-human-machine-era-a-forecast-report-2021-final (accessed on 24 March 2022).
- Crasborn, O.A. Nonmanual Structures in Sign Language. In Encyclopedia of Language and Linguistics, 2nd ed.; Brown, K., Ed.; Elsevier: Oxford, UK, 2006; pp. 668–672. [Google Scholar]
- Shumaker, C. NMS Facial Expression. 2016. YouTube. Available online: https://www.youtube.com/watch?v=NbbNwVwdfGg (accessed on 24 March 2022).
- Lepic, R.; Occhino, C. A Construction Morphology Approach to Sign Language Analysis. In The Construction of Words; Springer: Berlin, Germany, 2018; pp. 141–172. [Google Scholar]
- Dudis, P.G. Body partitioning and real-space blends. Cogn. Linguist. 2004, 15, 223–238. [Google Scholar] [CrossRef]
- Wolfe, R.; McDonald, J.C. A survey of facial nonmanual signals portrayed by avatar. Grazer Linguist. Stud. 2021, 93, 161–223. [Google Scholar]
- Stewart, J. The Forest—A story in ASL. 2008. Youtube. Available online: https://www.youtube.com/watch?v=oUclQ10BsH8 (accessed on 24 March 2022).
- Fundación Fesord CV. World Federation of the Deaf 2007. 2007. Youtube. Available online: https://www.youtube.com/watch?v=wW2KBXrPEdM (accessed on 24 March 2022).
- Tinwell, A. The Uncanny Valley in Games and Animation; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Trentskiroonie. Let’s Talk about Animation Quality! 2015. Reddit.com. Available online: https://www.reddit.com/r/truegaming/comments/2x4fqy/lets_talk_about_animation_quality/ (accessed on 24 March 2022).
- Poizner, H.; Bellugi, U.; Lutes-Driscoll, V. Perception of American sign language in dynamic point-light displays. J. Exp. Psychol. Hum. Percept. Perform. 1981, 7, 430. [Google Scholar] [CrossRef]
- Crasborn, O.; Sloetjes, H.; Auer, E.; Wittenburg, P. Combining Video and Numeric Data in the Analysis of Sign Languages Within the ELAN Annotation Software. In Proceedings of the LREC Workshop on Representation and Processing of Sign Language, Paris, France, 24–26 May 2006; pp. 82–87. [Google Scholar]
- Hanke, T.; Storz, J. iLex–A Database Tool for Integrating Sign Language Corpus Linguistics and Sign Language Lexicography. In Proceedings of the Workshop on the Representation and Processing of Sign Language, at the Sixth International Conference on Language Resources and Evaluation (LREC 08), Marrakech, Morocco, 1 June 2008; pp. 64–67. [Google Scholar]
- Stewart, G.; Cooley, D.A. The Skeletal and Muscular Systems; Infobase Publishing: New York, NY, USA, 2009; p. 106. [Google Scholar]
- Lu, P.; Huenerfauth, M. Accessible Motion-Capture Glove Calibration Protocol for Recording Sign Language Data from Deaf Subjects. In Proceedings of the 11th International ACM SIG Conference on Computers and Accessibility, Pittsburgh, PA, USA, 25–28 October 2009; pp. 83–90. [Google Scholar]
- Mündermann, L.; Corazza, S.; Andriacchi, T.P. The evolution of methods for the capture of human movement leading to markerless motion capture for biomechanical applications. J. Neuroeng. Rehabil. 2006, 3, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fyffe, G.; Graham, P.; Tunwattanapong, B.; Ghosh, A.; Debevec, P. Near-Instant Capture of High-Resolution Facial Geometry and Reflectance. Comput. Graph. Forum 2016, 35, 353–363. [Google Scholar] [CrossRef]
- Failes, I. What Mocap Suit Suits You? Vfxvoice. 2022. Available online: https://www.vfxvoice.com/what-mocap-suit-suits-you/ (accessed on 24 March 2022).
- Ahmed, M.A.; Zaidan, B.B.; Zaidan, A.A.; Salih, M.M.; Lakulu, M.M.B. A review on systems-based sensory gloves for sign language recognition state of the art between 2007 and 2017. Sensors 2018, 18, 2208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Failes, I. “Computer pajamas”: The History of ILM′s IMocap. 2019. Befores & Afters. Available online: https://beforesandafters.com/2019/09/10/computer-pajamas-the-history-of-ilms-imocap/ (accessed on 24 March 2022).
- Nakano, N.; Sakura, T.; Ueda, K.; Omura, L.; Kimura, A.; Iino, Y.; Fukashiro, S.; Yoshioka, S. Evaluation of 3D markerless motion capture accuracy using OpenPose with multiple video cameras. Front. Sports Act. Living 2020, 2, 50. [Google Scholar] [CrossRef] [PubMed]
- Moryossef, A.; Tsochantaridis, I.; Dinn, J.; Camgoz, N.C.; Bowden, R.; Jiang, T.; Rios, A.; Muller, M.; Ebling, S. Evaluating the Immediate Applicability of Pose Estimation for Sign Language Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 3434–3440. [Google Scholar]
- Vakunov, A.; Lagun, D. MediaPipe Iris: Real-time Iris Tracking and Depth Estimation. 2020. Google AI Blog. Available online: https://ai.googleblog.com/2020/08/mediapipe-iris-real-time-iris-tracking.html (accessed on 24 March 2022).
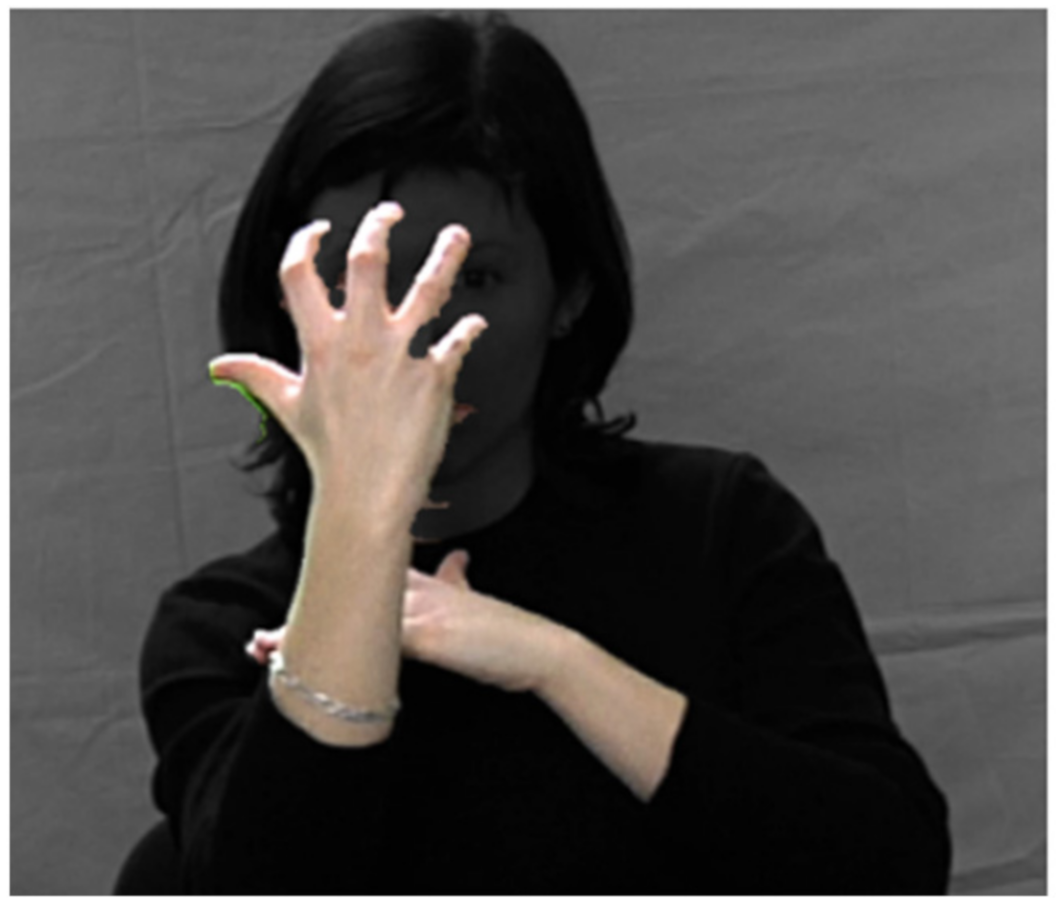
- Gonzalez, M.; Collet, C.; Dubot, R. Head Tracking and Hand Segmentation During Hand Over Face Occlusion in Sign Language. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 234–243. [Google Scholar]
- Shi, B.; Rio, A.M.D.; Keane, J.; Brentari, D.; Shakhnarovich, G.; Livescu, K. Fingerspelling Recognition in the Wild with Iterative Visual Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5400–5409. [Google Scholar]
- Naert, L. Capture, Annotation and Synthesis of Motions for the Data-Driven Animation of Sign Language Avatars; Université de Bretagne Sud: Vannes, France, 2020. [Google Scholar]
- McDonald, J.; Wolfe, R.; Wilbur, R.B.; Moncrief, R.; Malaia, E.; Fujimoto, S.; Baowidan, S.; Stec, J. A New Tool to Facilitate Prosodic Analysis of Motion Capture Data and a Data-Driven Technique for the Improvement of Avatar Motion. In Proceedings of the Language Resources and Evaluation Conference (LREC), Portorož, Slovenia, 23–28 May 2016; pp. 153–159. [Google Scholar]
- Stokoe, W.C.; Casterline, D.C.; Croneberg, C.G. A Dictionary of American Sign Language on Linguistic Principles; Gallaudet College Press: Washington, DC, USA, 1965. [Google Scholar]
- Battison, R.M. Lexical Borrowing in American Sign Language; Linstok Press: Silver Spring, MD, USA, 1978. [Google Scholar]
- Bellugi, U.; Fischer, S. A comparison of sign language and spoken language. Cognition 1972, 1, 173–200. [Google Scholar] [CrossRef]
- Baker-Shenk, C. A Microanalysis of the Nonmanual Components of Questions in American Sign Language. Ph.D. Thesis, University of California, Berkeley, CA, USA, 1983. Available online: https://escholarship.org/uc/item/7b03x0tz (accessed on 24 March 2022).
- Goldin-Meadow, S.; Brentari, D. Gesture, sign, and language: The coming of age of sign language and gesture studies. Behav. Brain Sci. 2017, 40, e46. [Google Scholar] [CrossRef] [PubMed]
- Karri, S. Classification of Hand Held Shapes and Locations in Continuous Signing. 2008. NJIT Digital Commons. Available online: https://digitalcommons.njit.edu/theses/364/ (accessed on 24 March 2022).
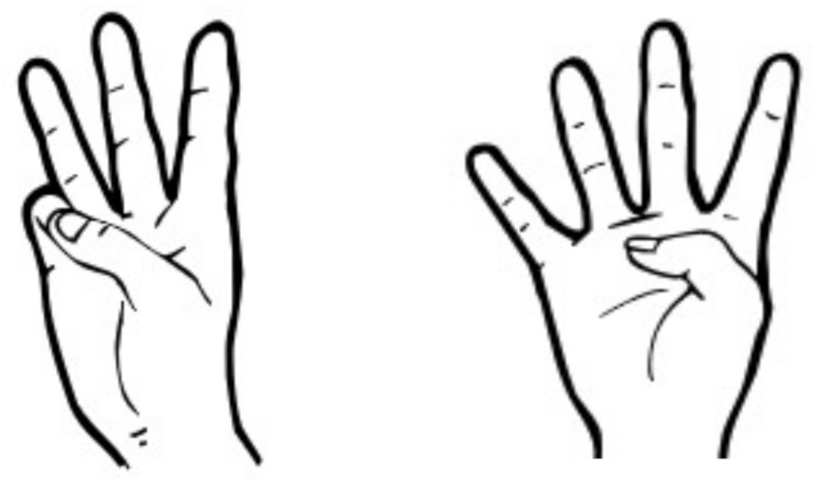
- Lapiak, J. Minimal pairs in sign language (ASL). 2022. Handspeak. Available online: https://www.handspeak.com/learn/index.php?id=109 (accessed on 24 March 2022).
- Cartwright, B. Signing Savvy. Available online: https://www.signingsavvy.com/ (accessed on 24 March 2022).
- Cuxac, C. La Langue des Signes Française, Les Voies de L’iconicité; Editions Ophrys: Paris, France, 2000. [Google Scholar]
- Boutora, L. Vers un Inventaire Ordonné des Configurations Manuelles de la Langue des Signes Française; JEP: Dinard, France, 2006; pp. 12–16. [Google Scholar]
- Hanke, T. HamNoSys—Representing Sign Language Data in Language Resources and Language Processing Contexts. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC 2004), Representation and Processing of Sign Languages Workshop, Lisbon, Portugal, 30 May 2004; pp. 1–6. [Google Scholar]
- Johnston, T. The Auslan Corpus Annotation Guidelines; Centre for Language Sciences, Department of Linguistics, Macquarie University: Sydney, Australia, 2013; Available online: https://media.auslan.org.au/attachments/AuslanCorpusAnnotationGuidelines_Johnston.pdf (accessed on 5 April 2022).
- Tkachman, O.; Hall, K.C.; Xavier, A.; Gick, B. Sign Language Phonetic Annotation meets Phonological CorpusTools: Towards a Sign Language Toolset for Phonetic Notation and Phonological Analysis. In Proceedings of the Annual Meetings on Phonology, Los Angeles, CA, USA, 21–23 October 2016. [Google Scholar]
- Johnston, T. From archive to corpus: Transcription and annotation in the creation of signed language corpora. Int. J. Corpus Linguist. 2010, 15, 106–131. [Google Scholar] [CrossRef] [Green Version]
- Aronoff, M.; Meir, I.; Sandler, W. The paradox of sign language morphology. Language 2005, 81, 301. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Slobin, D.I.; Hoiting, N.; Anthony, M.; Biederman, Y.; Kuntze, M.; Lindert, R.; Pyers, J.; Thumann, H.; Weinberg, A. Sign language transcription at the level of meaning components: The Berkeley Transcription System (BTS). Sign Lang. Linguist. 2001, 4, 63–104. [Google Scholar] [CrossRef]
- Lillo-Martin, D.; Pichler, C. Development of Sign Language Acquisition Corpora. In Proceedings of the LREC 6th International Conference on Language Resources and Evaluation(LREC 2008). 3rd Workshop on the Representation and Processing of Sign Languages: Construction and Exploitation of Sign Language Corpora, Paris, France, 1 June 2008; pp. 129–133. [Google Scholar]
- Meier, R.P. Icons, Analogues, and Morphemes: The Acquisition of Verb Agreement in American Sign Language. Ph.D. Dissertation, University of California, San Diego, CA, USA, 1982. [Google Scholar]
- Poizner, H.; Klima, E.S.; Bellugi, U. What the Hands Reveal About the Brain; MIT Press: Cambridge, MA, USA, 1990. [Google Scholar]
- Fischer, S.D. Questions and negation in American Sign Language. In Interrogative and Negative in Sign Languages; Ishara Press: Nijmegen, The Netherlands, 2006; pp. 165–197. [Google Scholar]
- Wilbur, R. Phonological and Prosodic Layering of Nonmanuals in American Sign Language. In The Signs of Language Revisited: An Anthology to Honor Ursula Bellugi and Edward Klima; Emmorey, K., Lane, H.L., Bellugi, U., Klima, E., Eds.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2000; pp. 213–241. [Google Scholar]
- TED. Christine Sun Kim. 2015. Available online: https://www.ted.com/speakers/christine_sun_kim (accessed on 24 March 2022).
- Max Planck Institute for Psycholinguistics. ELAN. 2013. The Language Archive. Available online: http://tla.mpi.nl/tools/tla-tools/elan/ (accessed on 24 March 2022).
- Adamo-Villani, N.; Wilbur, R.B. ASL-Pro: American Sign Language Animation with Prosodic Elements. In Proceedings of the International Conference on Universal Access in Human-Computer Interaction, Los Angeles, CA, USA, 2–7 August 2015; pp. 307–318. [Google Scholar]
- Grieve-Smith, A.B. SignSynth: A Sign Language Synthesis Application Using Web3D and Perl. In Proceedings of the International Gesture Workshop, London, UK, 18–21 April 2001; pp. 134–145. [Google Scholar]
- Bouzid, Y.; Jemni, M. An Avatar Based Approach for Automatically Interpreting a Sign Language Notation. In Proceedings of the IEEE 13th International Conference on Advanced Learning Technologies, Beijing, China, 15–18 July 2013; pp. 92–94. [Google Scholar]
- Kennaway, R. Experience with and Requirements for a Gesture 5 Description Language for Synthetic Animation. In Proceedings of the International Gesture Workshop, Genova, Italy, 15–17 April 2003; pp. 300–311. [Google Scholar]
- Glauert, J.; Elliott, R. Extending the SiGML Notation–a Progress Report. In Proceedings of the Second International Workshop on Sign Language Translation and Avatar Technology (SLTAT), Dundee, UK, 23 October 2011. [Google Scholar]
- Johnson, R.E.; Liddell, S.K. A segmental framework for representing signs phonetically. Sign Lang. Stud. 2011, 11, 408–463. [Google Scholar] [CrossRef]
- Hanke, T.; Popescu, H.; Schmaling, C. eSIGN–HPSG-assisted Sign Language Composition. In Proceedings of the Gesture Workshop, Genova, Italy, 15–17 April 2003. [Google Scholar]
- Elliott, R.; Bueno, J.; Kennaway, R.; Glauert, J. Towards the Integration of Synthetic SL Annimation with Avatars into Corpus Annotation Tools. In Proceedings of the 4th Workshop on the Representation and Processing of Sign Languages: Corpora and Sign Language Technologies, Valletta, Malta, 22–23 May 2010; p. 29. [Google Scholar]
- Filhol, M. Modèle Descriptif des Signes pour un Traitement Automatique des Langues des Signes; Université Paris Sud-Paris XI: Paris, France, 2008. [Google Scholar]
- McDonald, J.; Filhol, M. Natural Synthesis of Productive Forms from structured descriptions of sign language. Mach. Transl. 2021, 35, 1–24. [Google Scholar] [CrossRef]
- Tennant, R.A.; Gluszak, M.; Brown, M.G. The American Sign Language Handshape Dictionary; Gallaudet University Press: Washington, DC, USA, 1998. [Google Scholar]
- Bailey, C.S.; Dolby, K.; Campbell, M. The Canadian Dictionary of ASL; University of Alberta: Edmonton, AB, Canada, 2002. [Google Scholar]
- Schermer, G.M.; Corline, K. (Eds.) Van Dale Basiswoordenboek Nederlandse Gebarentaal; Van Dale: Utrecht/Antwerpen, Belgium, 2009. [Google Scholar]
- Benchiheub, M.-E.-F.; Berret, B.; Braffort, A. Collecting and Analysing a Motion-Capture Corpus of French Sign Language. In Proceedings of the Workshop on the Representation and Processing of Sign Languages, Portoroz, Slovenia, 28 May 2016. [Google Scholar]
- Gibet, S. Building French Sign Language Motion Capture Corpora for Signing Avatars. In Proceedings of the Workshop on the Representation and Processing of Sign Languages: Involving the Language Community, Miyazaki, Japan, 12 May 2018. [Google Scholar]
- Efthimiou, E.; Fotinea, S.-E. An Environment for Deaf Accessibility to Education Content. In Proceedings of the International Conference on ICT & Accessibility, Hammamet, Tunisia, 12–14 April 2007; p. GSRT, M3. 3, id 35. [Google Scholar]
- Irving, A.; Foulds, R. A Parametric Approach to Sign Language Synthesis. In Proceedings of the 7th International ACM SIGACCESS Conference on Computers and Accessibility, Baltimore, MD, USA, 9–12 October 2005; pp. 212–213. [Google Scholar]
- Lebourque, T.; Gibet, S. A Complete System for the Specification and the Generation of Sign Language Gestures. In Proceedings of the International Gesture Workshop, Gif-sur-Yvette, France, 17–19 March 1999; pp. 227–238. [Google Scholar]
- Heloir, A.; Kipp, M. Real-Time Animation of Interactive Agents: Specification and Realization. Appl. Artif. Intell. 2010, 24, 510–529. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Representation | Digital Availability | Anonymity | Full 3D | Specifies Motion | Self-Evident | Non Manuals | Asynchrony | Level of Detail | Corpora | Easy Authoring |
|---|---|---|---|---|---|---|---|---|---|---|
| Line drawings 1 | yes | yes | Lexical | |||||||
| Video recordings | yes | yes | yes | |||||||
| Motion capture 2 | yes | yes | see 3 | yes | Fine detail | |||||
| Gloss | yes | yes | Lexical | see 4 | yes | |||||
| Stokoe/ ASCII Stokoe | yes | yes | Phonemic | see 5 | ||||||
| HamNoSys/SiGML | yes | yes | yes | see 6 | yes | Phonetic | see 7 | |||
| SignWriting/SWML | yes | yes | yes | yes | Phonetic | see 8 | yes | |||
| SLPA model/SiGML 9 | yes | yes | yes | yes | Phonetic | |||||
| Berkeley Transcription System 10 | yes | yes | yes | Morphological | ||||||
| Qualgest 11 | yes | yes | yes | yes | Phonemic | |||||
| EMBRscript 12 | yes | yes | yes | yes | yes | Key frame | ||||
| Zebedee 13 | yes | yes | yes | yes | Phonetic → Morphological | |||||
| AZee 14 | yes | yes | yes | yes | yes | yes | Phonetic → Phrasal | see 15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wolfe, R.; McDonald, J.C.; Hanke, T.; Ebling, S.; Van Landuyt, D.; Picron, F.; Krausneker, V.; Efthimiou, E.; Fotinea, E.; Braffort, A. Sign Language Avatars: A Question of Representation. Information 2022, 13, 206. https://doi.org/10.3390/info13040206
Wolfe R, McDonald JC, Hanke T, Ebling S, Van Landuyt D, Picron F, Krausneker V, Efthimiou E, Fotinea E, Braffort A. Sign Language Avatars: A Question of Representation. Information. 2022; 13(4):206. https://doi.org/10.3390/info13040206
Chicago/Turabian StyleWolfe, Rosalee, John C. McDonald, Thomas Hanke, Sarah Ebling, Davy Van Landuyt, Frankie Picron, Verena Krausneker, Eleni Efthimiou, Evita Fotinea, and Annelies Braffort. 2022. "Sign Language Avatars: A Question of Representation" Information 13, no. 4: 206. https://doi.org/10.3390/info13040206
APA StyleWolfe, R., McDonald, J. C., Hanke, T., Ebling, S., Van Landuyt, D., Picron, F., Krausneker, V., Efthimiou, E., Fotinea, E., & Braffort, A. (2022). Sign Language Avatars: A Question of Representation. Information, 13(4), 206. https://doi.org/10.3390/info13040206