1. Introduction
Since 2018, the European Union (EU) has placed regulations on personal data usage and algorithmic decision making systems [
1]. As a result, EU citizens are entitled to explanations of algorithmic decisions and are able to contest them [
1]. In the United States (US), regulatory bodies have begun investigating the widespread usage of artificial intelligence (AI). In 2014 and 2016, the executive office of the National Science and Technology Committee published two reports related to the ethical usage of AI and its regulatory recommendations [
2]. This was followed by the introduction of the National Security Commission Artificial Intelligence Act of 2018 that established a formal committee to review the usage of AI and recommend necessary regulations [
3].
Laws that regulate the use of machine learning (ML) applications are difficult to draft since they require extensive technical knowledge to accurately assess the outcomes produced by the underlying algorithms. However, these laws are needed to prevent misuse and decision failures. For instance, recidivism prediction instruments are widely used but are also the subject of controversy because they can inherit biases from the training data [
4]. In the US, the judiciary presiding over State of Wisconsin vs. Eric. L. Loomis used an algorithm, COMPASS, to recommend sentencing. It sentenced the accused to 6 years in prison [
5]. The defense argued that the usage of a black-box algorithm violated Mr. Loomis’s right to due process since the algorithm was a trade secret. On appeal to the Wisconsin supreme court, the judgment was upheld [
5]. The court’s decision was heavily criticized by law scholars as having “failed to protect due process rights” [
6]. These systems may perpetuate a cycle of incarceration [
4]. In order to overcome some of these legal and ethical pitfalls, ML models need to be interpretable and open to auditing [
7].
In response to this concern, the IEEE published the “The IEEE Global Initiative on Ethics of Autonomous and Intelligent Systems”, a set of guiding principles for ethical AI usage [
8]. These principles formed the foundation of the IEEE P7000 series of standards addressing AI standardization. Subsequently, the P7001 and P7003 standards required transparency and algorithmic bias considerations for autonomous systems, highlighting the need for interpretability for all ML models.
In general, ML models can be classified into two main categories in terms of interpretability. The first category consists of easily interpretable models, such as Bayesian networks [
9], decision trees [
10] and random forests [
11]. The second category includes more complex models such as neural networks [
12] and support vector machines [
13]. This second category of models is often more accurate and generalizes better to new data [
14]. However, it suffers from reduced interpretability [
15]. In fact, the more complex the model, the less interpretable it becomes. More examples of this category include deep neural networks [
12], convolution neural networks [
16] and recurrent networks [
17]. Similarly, the interpretability of SVM decreases with higher-order SVMs, which rely on RBF or polynomial kernels as opposed to the simpler linear kernels.
In [
15], Lipton divides the notion of interpretability into two main categories: transparency and post hoc explanation. Transparency aims to deliver model- or global-level interpretability, whereas post hoc explanation is a per input “after the fact” explanation that provides a local level of interpretability. Both the local and the global interpretability of ML models have been investigated in previous studies. These studies propose a translation mechanism, where a non-interpretable model is translated to an interpretable model. For instance, the local interpretable model-agnostic explanations (LIME) technique translates a non-interpretable model to a locally interpretable one by sampling data around a query from the non-interpretable model [
18]. The sampled data are labeled using the non-interpretable model and then are used to train a simple linear separator. The weights of the linear separator are provided as the explanation. An example of a global interpretation technique is TRE-PAN [
19], which translates a neural network by training a decision tree model using data generated from the original model. These two approaches treat the target model as a black-box where only the outcome produced for a given input is available. A different type of global translation techniques relies on the complete knowledge of the architecture and parameters of the target model. For instance, the internal structure of a neural network was used to generate rules from an induced decision tree in CRED [
20].
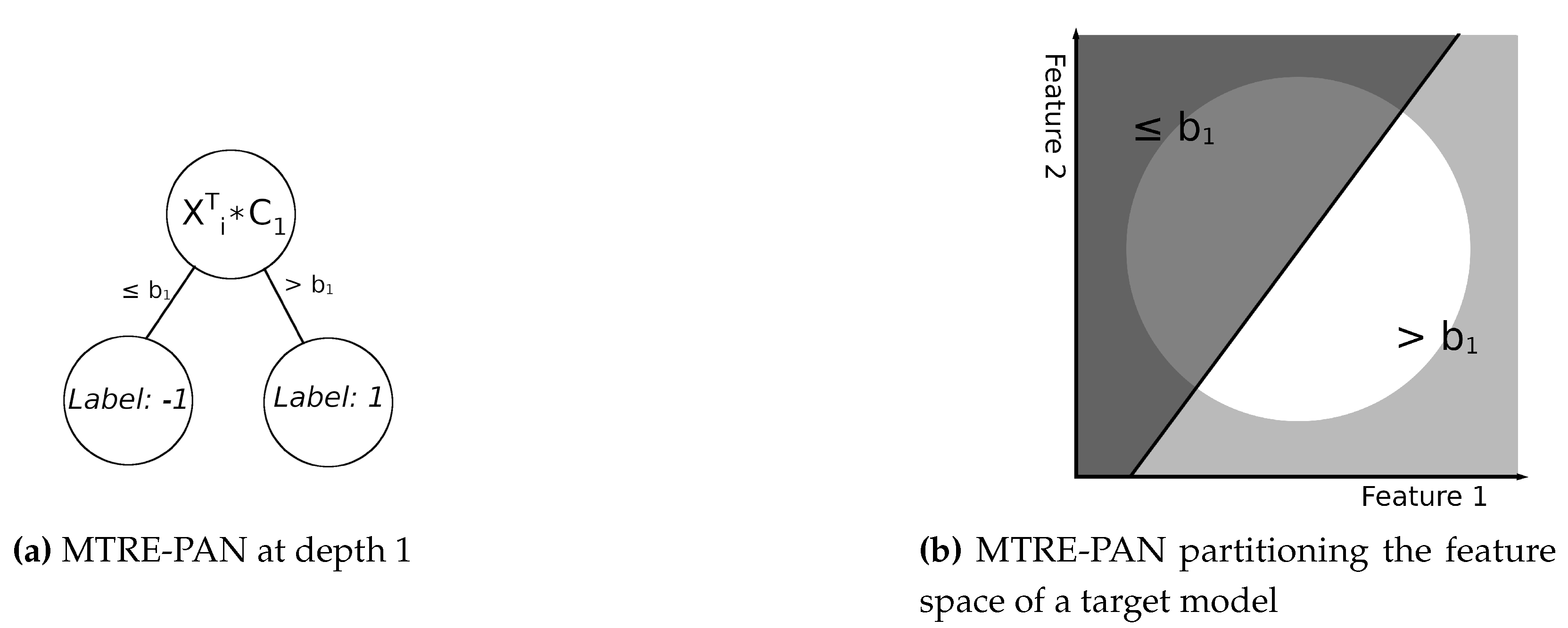
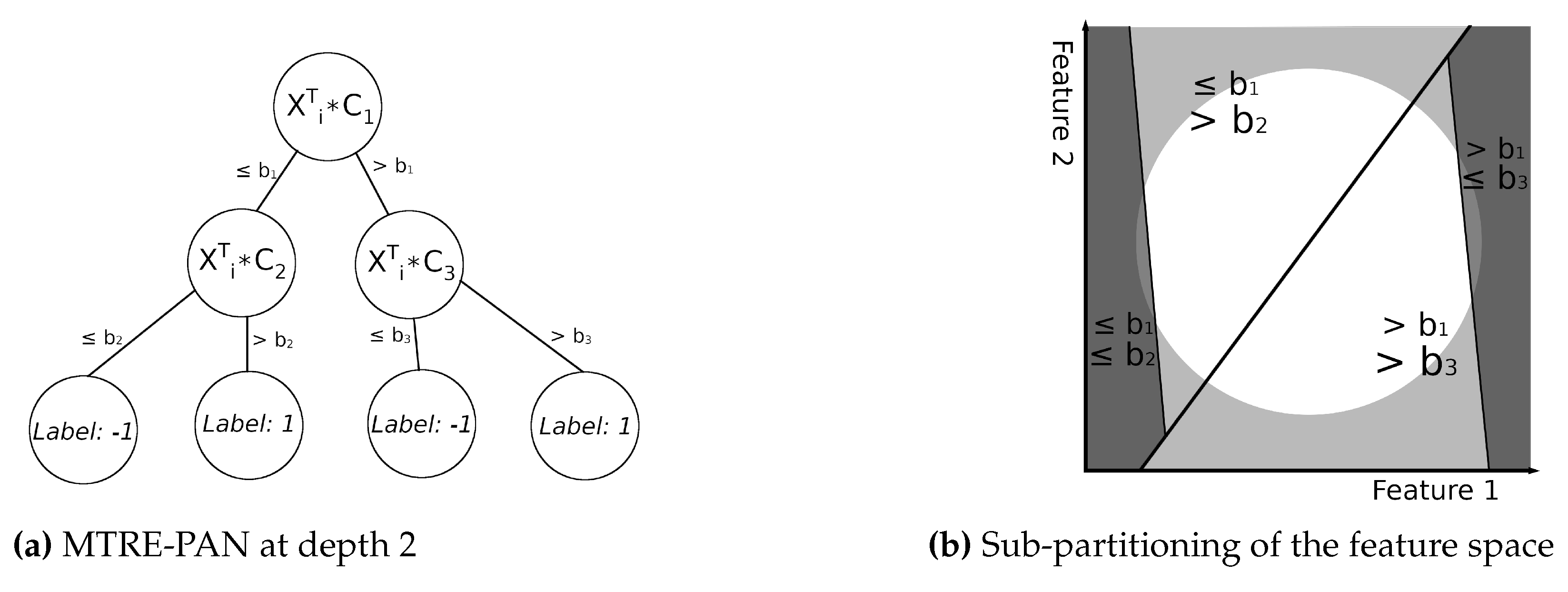
Global interpretation is the focus of this paper. A decision tree that relies on linear hyperplanes as separators is used to provide global interpretability for a target neural network model. The target model is considered to be a black-box. The present paper also introduces two metrics that can more accurately compare the target model and the interpretable model, specifically around the decision boundaries. Agreement between the target model and the interpretable model near the decision boundaries is critical since these regions delineate between different outcomes of the target model.
4. Results
Multiple experiments were conducted to assess the efficacy of MTRE-PAN and compare it to that of TRE-PAN [
16,
17]. In its proposed implementation, TRE-PAN generates an interpretable decision tree for each target model using a two out of three split as described in
Section 2.1. In order to simplify the comparison with MTRE-PAN with respect to the depth of the resulting interpretable models, the C4.5 binary implementation of TRE-PAN was used [
33]. MTRE-PAN, the model proposed in the present paper, consists of a hybrid combination of a binary decision tree and a linear SVM classifier at each node of the tree. Both TRE-PAN and MTRE-PAN were used to generate interpretable models with varying tree depths for several target models.
The first target model is a simple function with a circular boundary delineating the negative and positive samples. This model was used earlier to illustrate the methodology. The remaining target models are feed forward neural networks, which were trained using three public domain datasets.
The hyperparameters of MTRE-PAN and TRE-PAN include the maximum depth, the cutoff entropy, the cutoff variance and the margin as described in
Table 1. All the ML target models follow the same general architecture that consists of the following:
- -
An input layer and two hidden layers, each with a number of nodes equal to the number of input variables in the dataset.
- -
An output layer consisting of a single node.
- -
All the nodes use a sigmoid activation function.
This architecture is trained with 70% of the original data over 100 epochs. The remaining 30% are held-out samples that are used for validation and testing. The data are normalized to [−1,1]. After training, the model that achieved the highest accuracy on the validation data across all the epochs is retained.
Four metrics are used to compare MTRE-PAN and TRE-PAN in this study:
- -
Model parity: The agreement in classification between the decision tree and the target model
f. It is measured as the ratio of matching labels between
f and either the decision tree generated by MTRE-PAN or TRE-PAN over the total number of samples in the validation set. Model parity is calculated as
- -
Certain model parity: This metric is similar to the model parity, except, in this case, the sample in the validation dataset that is assigned to uncertain nodes (i.e., nodes with entropy below the cutoff entropy) are labeled uncertain. These samples cannot match any label from
f and as such are considered misses. This metric is calculated as
and takes into consideration uncertain nodes that require further expansion.
- -
Boundary model parity: This metric is also similar to the certain model parity. However, the validation dataset is limited to the samples that are near the decision boundary within a predefined margin (
Table 1). The boundary model parity measures the progress of the interpretable model toward replicating the behavior of the target model near the decision boundaries. It identifies an interpretable model that may have a high certain model parity but may not fare well around the decision boundaries.
- -
Leaf count: The number of leaves in the interpretable decision tree generated by either MTRE-PAN or TRE-PAN.
4.1. Synthetic Data
MTRE-PAN makes use of linear separators at each node of the tree. This is similar to LIME [
18]. However unlike LIME, MTRE-PAN uses multiple separators whose constraints define a hyper-polygon at each leaf node. As the tree grows, the set of polygons from the root to a leaf node decrease in entropy after every split. This corresponds to a decrease in the total area of the uncertain polygons. Therefore, the certain polygons start to approach the boundaries of the target model.
In order to illustrate this aspect, MTRE-PAN was applied to a simple function
f consisting of a circle with a radius of 1 introduced earlier. The samples that fall inside the circle are positive and those outside are negative. TRE-PAN was also applied to the same synthetic function. Results for both MTRE-PAN and TRE-PAN are provided in
Table 2 and
Table 3, respectively.
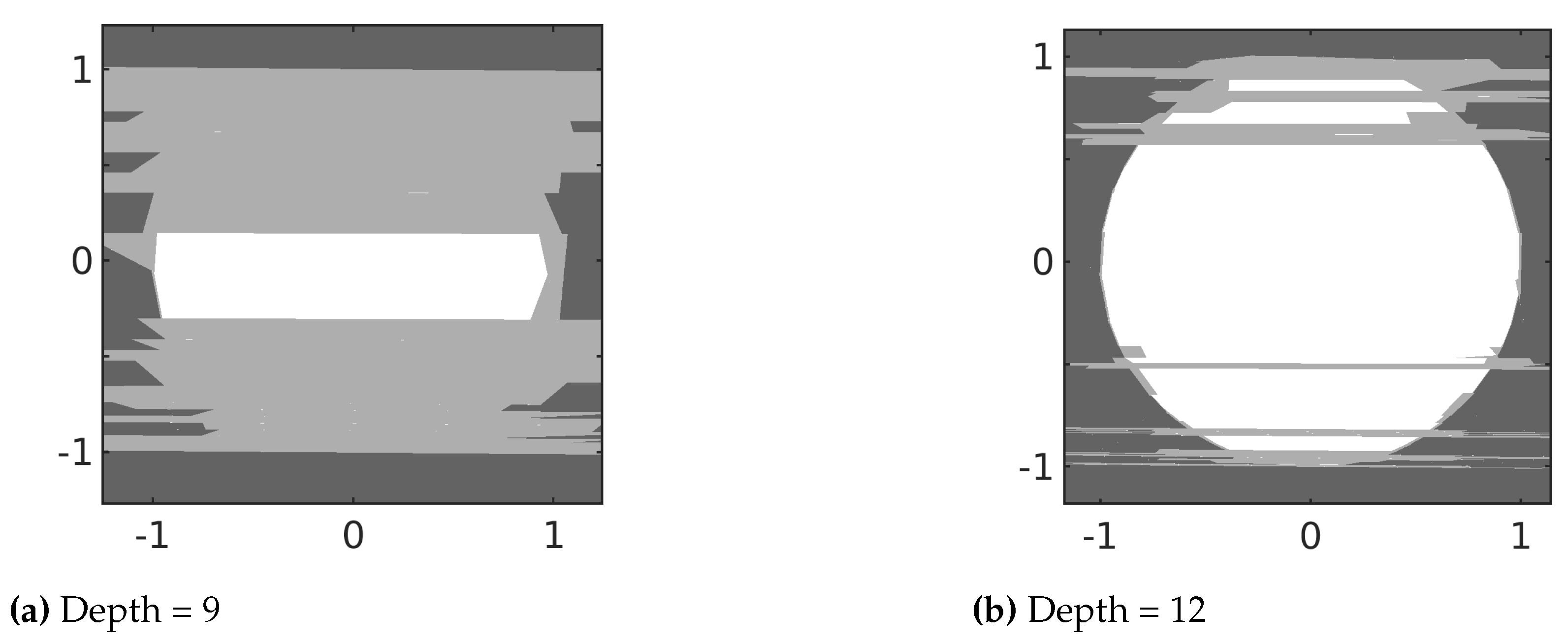
Figure 3 is a visualization of the polygons generated by MTRE-PAN for
f at depths 9 and 12. It illustrates the convergence of the polygons to
f. That is, the collective area of the uncertain polygons becomes smaller at depth 12 compared to depth 9. Moreover, as expected, the figure shows that the uncertain polygons always contain the decision boundaries of
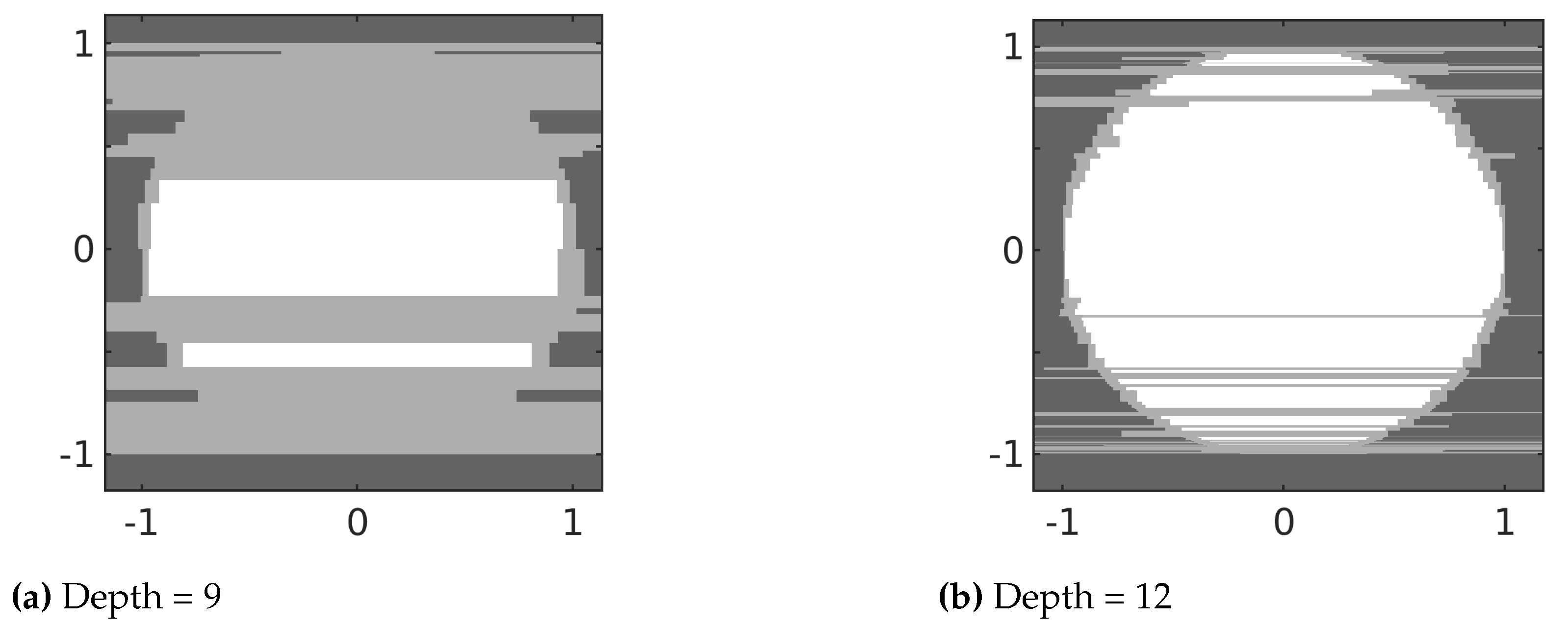
f. Otherwise, the polygon will not include both positive and negative labels and would have an entropy of 0. This behavior is also seen in
Figure 4 for TRE-PAN. The uncertain polygons (i.e., hyper-rectangles in this case) also contain the decision boundaries of
f.
Since the uncertain polygons are mutually exclusive, they can be used as an estimate of the decision boundaries and the overall behavior of the underlying model. As mentioned above, the accuracy of the interpretable model in representing the decision boundaries depends on the values of the cutoff variance and cutoff entropy. If the cutoff variance is high, it may not be possible to generate enough data to accurately label a polygon as positive, negative, or uncertain. On the other hand if it is low, more data are needed to ensure that the sample variance of the entropy is below the cutoff variance. Similarly, if the cutoff entropy is high, it may not be possible to decide whether a leaf node is certain or uncertain. This may potentially lead to labeling polygons that contain a decision boundary as certain. A cutoff entropy close or equal to zero with a sufficiently low cutoff variance will ensure that no decision boundary is missed.
If a decision boundary falls within a certain polygon (i.e., a polygon with an entropy lower than the cutoff entropy), it is still possible to estimate the missing decision boundary. This entails finding neighboring leaves that do not have the same label since an estimated boundary is simply a shared constraint that separates neighboring polygons of different labels.
MTRE-PAN provides a global explanation of the function f in the form of a set of uncertain polygons and of polygons that have an estimated boundary as a constraint. The remaining polygons provide additional constraints that help define the limits of this estimate in the feature space. This characteristic is important, as it avoids the unbounded plane issue observed in LIME. In LIME, a plane is generated as a local estimator of the decision boundary. However, the plane is not delimited in the feature space.
Table 2 and
Table 3 show that the parity of both interpretable models of
f are high for depths greater than 3. However, MTRE-PAN produces interpretable models with a lower number of leaves and similar certain model parity and boundary model parity to those produced by TRE-PAN. At depth 12, the interpretable model generated by MTRE-PAN consists of 305 leaves, whereas the one generated by TRE-PAN includes 775 leaves.
Author Contributions
Conceptualization, M.A.-M. and Z.B.M.; methodology, M.A.-M. and Z.B.M.; software, M.A.-M.; validation, M.A.-M. and Z.B.M.; formal analysis, M.A.-M. and Z.B.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Ethical review and approval are not required because all datasets used in this study are in the public domain.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
References
- Goodman, B.; Flaxman, S. European Union Regulations on Algorithmic Decision-Making and a “Right to Explanation”. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef] [Green Version]
- The Administration’s Report on the Future of Artificial Intelligence. 2016. Available online: https://obamawhitehouse.archives.gov/blog/2016/10/12/administrations-report-future-artificial-intelligence (accessed on 21 February 2022).
- Stefanik, E.M. H.R.5356—115th Congress (2017–2018): National Security Commission Artificial Intelligence Act of 2018. 2018. Available online: https://www.congress.gov/bill/115th-congress/house-bill/5356 (accessed on 21 February 2022).
- Chouldechova, A. Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. arXiv 2016, arXiv:1610.07524. [Google Scholar] [CrossRef] [PubMed]
- Supreme Court of Wisconsin, State v. Loomis. Available online: https://scholar.google.com/scholar_case?case=3222116451721963278&hl=en&as_sdt=6&as_vis=1&oi=scholarr (accessed on 21 February 2022).
- Freeman, K. Algorithmic Injustice: How the Wisconsin Supreme Court Failed to Protect Due Process Rights in State v. Loomis. N. Carol. J. Law Technol. 2016, 18, 75. [Google Scholar]
- Ferguson, A. Policing Predictive Policing. Wash. Univ. Law Rev. 2017, 94, 1109–1189. [Google Scholar]
- Chatila, R.; Havens, J.C. The IEEE Global Initiative on Ethics of Autonomous and Intelligent Systems. In Robotics and Well-Being; Aldinhas Ferreira, M.I., Silva Sequeira, J., Singh Virk, G., Tokhi, M.O., Kadar, E.E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 95, pp. 11–16. [Google Scholar] [CrossRef]
- Ben-Gal, I. Bayesian Networks. In Encyclopedia of Statistics in Quality and Reliability; Wiley Online Library: Hoboken, NJ, USA, 2008. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. Random Decision Forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Kim, Y.S. Comparison of the Decision Tree, Artificial Neural Network, and Linear Regression Methods Based on the Number and Types of Independent Variables and Sample Size. Expert Syst. Appl. 2008, 34, 1227–1234. [Google Scholar] [CrossRef]
- Lipton, Z.C. The Mythos of Model Interpretability. arXiv 2016, arXiv:1606.03490. [Google Scholar]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object Recognition with Gradient-Based Learning. In Shape, Contour and Grouping in Computer Vision; Lecture Notes in Computer Science; Forsyth, D.A., Mundy, J.L., di Gesú, V., Cipolla, R., Eds.; Springer: Berlin/Heidelberg, Germeny, 1999; pp. 319–345. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why Should I Trust You?: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar]
- Craven, M.W.; Shavlik, J.W. Extracting Tree-Structured Representations of Trained Networks. In Proceedings of the 8th International Conference on Neural Information Processing Systems, Denver, CO, USA, 27 November–2 December 1995; Volume 1, pp. 24–30. [Google Scholar]
- Sato, M.; Tsukimoto, H. Rule Extraction from Neural Networks via Decision Tree Induction. In Proceedings of the IJCNN’01. International Joint Conference on Neural Networks, Washington, DC, USA, 15–19 July 2001; Volume 3, pp. 1870–1875. [Google Scholar] [CrossRef]
- Augasta, M.; Kathirvalavakumar, T. Reverse Engineering the Neural Networks for Rule Extraction in Classification Problems. Neural Process. Lett. 2012, 35, 131–150. [Google Scholar] [CrossRef]
- Zilke, J.R.; Loza Mencía, E.; Janssen, F. DeepRED – Rule Extraction from Deep Neural Networks. In Discovery Science; Calders, T., Ceci, M., Malerba, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9956, pp. 457–473. [Google Scholar] [CrossRef]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. In Proceedings of the International conference on machine learning, PMLR, Sydney, Australia, 6–11 August 2017; p. 9. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. In Proceedings of the Workshop at the International Conference on Learning Representations, Banff, AB, Canada, 14–24 June 2014. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Slack, D.; Hilgard, S.; Jia, E.; Singh, S.; Lakkaraju, H. Fooling LIME and SHAP: Adversarial Attacks on Post Hoc Explanation Methods. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–9 February 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 180–186. [Google Scholar]
- Tabacof, P.; Valle, E. Exploring the Space of Adversarial Images. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 426–433. [Google Scholar] [CrossRef] [Green Version]
- Bennett, K.; Blue, J. A Support Vector Machine Approach to Decision Trees. In Proceedings of the 1998 IEEE International Joint Conference on Neural Networks Proceedings, IEEE World Congress on Computational Intelligence (Cat. No.98CH36227), Anchorage, AK, USA, 4–9 May 1998; Volume 3, pp. 2396–2401. [Google Scholar] [CrossRef]
- Madzarov, G.; Gjorgjevikj, D. Multi-Class Classification Using Support Vector Machines in Decision Tree Architecture. In Proceedings of the IEEE EUROCON 2009, St. Petersburg, Russia, 18–23 May 2009; pp. 288–295. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Pearson: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Craven, M. Extracting Comprehensive Models From Trained Neural Networks. Ph.D. Thesis, University of Wisconsin-Madison, Madison, WI, USA, 1996. [Google Scholar]
- UCI Machine Learning Repository: Abalone Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/abalone (accessed on 21 February 2022).
- UCI Machine Learning Repository: Census Income Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/census+income (accessed on 21 February 2022).
- Smith, J.W.; Everhart, J.; Dickson, W.; Knowler, W.; Johannes, R. Using the ADAP Learning Algorithm to Forecast the Onset of Diabetes Mellitus. In Proceedings of the Annual Symposium on Computer Application in Medical Care, Bethesda, MD, USA, 7–11 November 1988; American Medical Informatics Association: Bethesda, MD, USA, 1988; pp. 261–265. [Google Scholar]
- Joshi, R.D.; Dhakal, C.K. Predicting Type 2 Diabetes Using Logistic Regression and Machine Learning Approaches. Int. J. Environ. Res. Public Health 2021, 18, 7346. [Google Scholar] [CrossRef] [PubMed]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}