1. Introduction
Modern machine learning techniques such as, in particular, deep learning approaches, are successfully applied in many data regression and data classification applications. However, in some application contexts, where it is not possible to have a large set of labeled data points, the use of a supervised classifier built using a deep learning model can determine the results with an unsatisfactory level of accuracy. A solution to the problem of the scarcity of labeled data can be found by using a semi-supervised approach that also makes use of unlabeled data [
1,
2,
3]. Some researchers propose self-training methods in which the classifier is initially trained on a reduced set of labeled data points to classify unlabeled data points [
4,
5].
Other approaches use co-training techniques in which the set of features is divided into two related subsets to allow the evaluation of the label to be assigned to an unlabeled data point. [
6,
7,
8].
Semi-supervised generative methods are used by some authors to capture and better model data distributions. In [
9], a deep generative semi-supervised approach in which is applied a variational optimization algorithm for approximate Bayesian inference is presented. In [
10], a categorical generative adversarial network model is constructed in which is used an objective function to take into account the relation between the measured data and their predicted class distributions. In [
11] is added an encoder to a categorical generative adversarial network to extract bidirectional mapping of the data distribution.
Some research has been recently aimed at the development of soft computing semi-supervised methods aimed at increasing the classification accuracy. In [
12] is proposed a semi-supervised method using an evolutionary learning algorithm to construct a massive training set with large amounts of unlabeled data and a small quantity of labeled data. A semi-supervised hybrid sentiment classification model using a genetic algorithm and a logistic regression is applied on Twitter data in [
13]. Type-2 fuzzy classifiers are proposed in [
14,
15] for managing uncertainty in labeling data.
One of the main criticalities of these models is their computational complexity, which can limit their use in the management of massive data. To overcome this criticality, in [
16] is proposed a new unsupervised classification model applied to sentiment classification of social data, called fuzzy relevance emotional document classification (for short, FREDoC). FREDoC performs a fuzzy-based multiclassification of documents into prevailing emotional categories, evaluating the relevance of an emotional category in a document based on the use of the term frequency-inverse document frequency index.
The classification of areas of an urban fabric based on the impressions and reports of users represents a function to support decision makers and urban planners to evaluate the relationships between citizens and the services offered, or to analyze any situations of urban hardship or instability. In [
17], a semi-supervised classification model proposed in [
18] and based on the extended fuzzy C-means fuzzy clustering algorithm [
19] was built to classify urban areas based on citizens’ moods. This model was used to evaluate the livability of the neighborhood perceived by citizens residing in the districts of the municipality of Bologna (Italy).
In this work, a GIS-based framework was built that implements the FREDoC model to classify urban areas based on user information extracted in social media posts or interview reports. The main drawback of this approach is given by the iterative process of the partitive clustering algorithm. In addition, this approach requires creating mapping between the class and the corresponding cluster. In [
17,
18], this mapping was generated by associating to the class the cluster to which the majority of data points in the training set assigned to that class belong. Finally, this model does not perform the multiple classification of data points by assigning a data point to the class corresponding to the cluster to which the data point belongs with the highest membership degree, even if the membership degrees to other clusters are not negligible. These drawbacks are overcome in FREDoC, in which a fuzzy partition of the emotional relevance measure is constructed to evaluate the incidence of an emotional category in a document and a multiclassification of a document is performed assigning it to the more relevant emotional categories.
We generalize the FREDoC classification model, extending the concept of emotional categories to characteristics or entities that identify a problem. In particular, we have implemented the FREDoC model in a GIS-based framework to classify subzones in which an urban area is partitioned; the framework was tested on an urban study area to classify the subzones by relevance of reported failures on categories of urban subsystems, such as roads, residential buildings, public buildings and transport infrastructures, lighting networks, and public green areas. The data points consist of reports made over time by citizens through the use of different channels in a deconstructed or semi-structured way. A thematic map of the relevance of the category in the subzones of the study area is produced for each category and for each time frame.
Aims and Advantages of This Research
The specific aims of this research are the following:
- -
Implementing a GIS-based model to classify the subzones into which an urban area is partitioned in terms of relevance of a specific category and analyze its temporal evolution.
- -
Analyzing the temporal evolution of the relevance of a category in a subzone, dividing the period in which citizens’ reports are entered into time frames.
- -
Provide a GIS-based framework to support the decision maker for the analysis and monitoring of problems in urban contexts reported on different channels by citizens and residents.
The main advantages of this approach are the following:
- -
The use of a light approach of multiclassification of urban areas on user information, eliminating the obstacle of the high computational complexity of semi-supervised classification soft computing models and allowing the processing of massive data extracted in social media posts or interview reports.
- -
An interpretation of the results close to the decision maker’s reasoning. In fact, the proposed framework allows the user to obtain a clear linguistic interpretation of the final classification of the relevance of a specific feature in an urban area and to analyze how this relevance has varied over time.
The remainder of the paper is organized as follows. In
Section 2 the FREDoC model proposed in [
16] and generalized for the multiple classification of documents is presented.
Section 3 focuses on the presentation of the proposed GIS-based framework through the description of its architecture and all its functional components.
Section 4 describes the results of the GIS framework experimentation carried out on the study area of the city of Naples (Italy), in which the subzones are made up of the ten municipalities into which the city is divided and the problem concerns the instability of urban subsystems reported by citizens. Finally,
Section 5 is devoted to a final discussion and future developments.
2. The FREDoC Document Classification Method
The FREDoC model (fuzzy relevance emotions document classification) [
16] is a fuzzy-based multiple document classification model that has been applied for the classification of emotional categories expressed by users in social media posts.
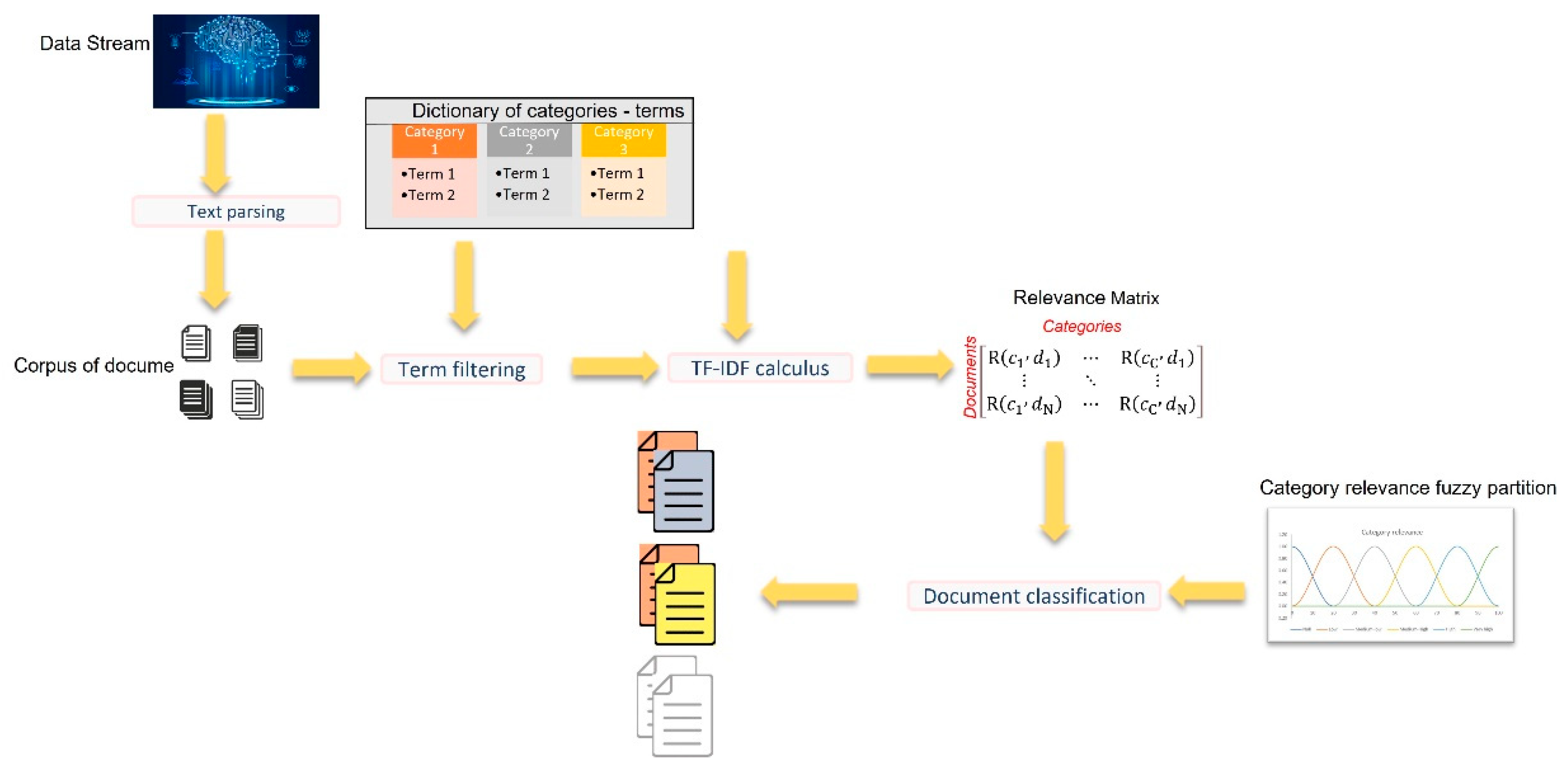
In our framework, we apply FREDoC in general application contexts, to classify documents based on a set of C categories characterizing a specific topic or problem.
A schema of FREDoC is shown in
Figure 1.
Initially, the user produces a dictionary of categories—terms, in which all terms falling into a category are collected and assigned to that category.
The user defines the set of categories that characterize the problem to be analyzed. Just to give an example, let us imagine that the set of categories referring to transport services most used in a tourist area are: subway, bus, tram, and private taxi. For each category, all the terms corresponding to it are collected by the user. For example, some terms associated with the subway category are: subway station, subway line, tunnel, track, quay, wagon, conductor, and train manager. A term in the dictionary is subsequently reduced to its stemmed form.
The extracted data are grouped by the text parsing component according to a set of keywords, and transformed into N documents. For example, if the data stream is given by Twitter messages, they can be grouped based on the hashtag, the time period in which the message was created, and the place from which it was sent. The content of each grouped set of data is cleaned by all the irrelevant noise information.
The
term filtering component compresses each word in the document in its stemmed form, preserving its root. Then, the stemmed word is compared to the terms enclosed in the
dictionary of categories. If a match is found, the word in the document is associated with its category. Then, the
term filtering component produces a matrix called
relevance matrix, whose elements represent the relevance of a category in a document, measured by computing the term frequency–inverse document frequency index (for short,
TF-IDF), an index used to evaluate the importance of the terms of a category with respect to a document. The relevance matrix elements are given by the formula:
where
is the relevance of the
jth category in the
ith document and the term
is the
TF-IDF of the terms of the
jth category in the
ith document.
If
Trj is the set of the terms assigned to the
jth category, the term
is given by the sum of the formula:
where
is the
TF-IDF index of the term
tr, in the
ith document.
The component
document classification evaluates the relevance of the
jth category in the ith document using a Ruspini fuzzy partition [
20] constructed initially on the domain [0, 1] of the TF-IDF relevance matrix measures and called
category relevance fuzzy partition. For each document and category, this component computes the membership degree of the category relevance fuzzy sets, assigning as relevance of the
jth category in the
ith document the linguistic label of the fuzzy set to which the relevance measure
R(cj,di) belongs with a higher membership degree.
The document is classified assigning it to the categories whose relevance is greater than or equal to a specific threshold.
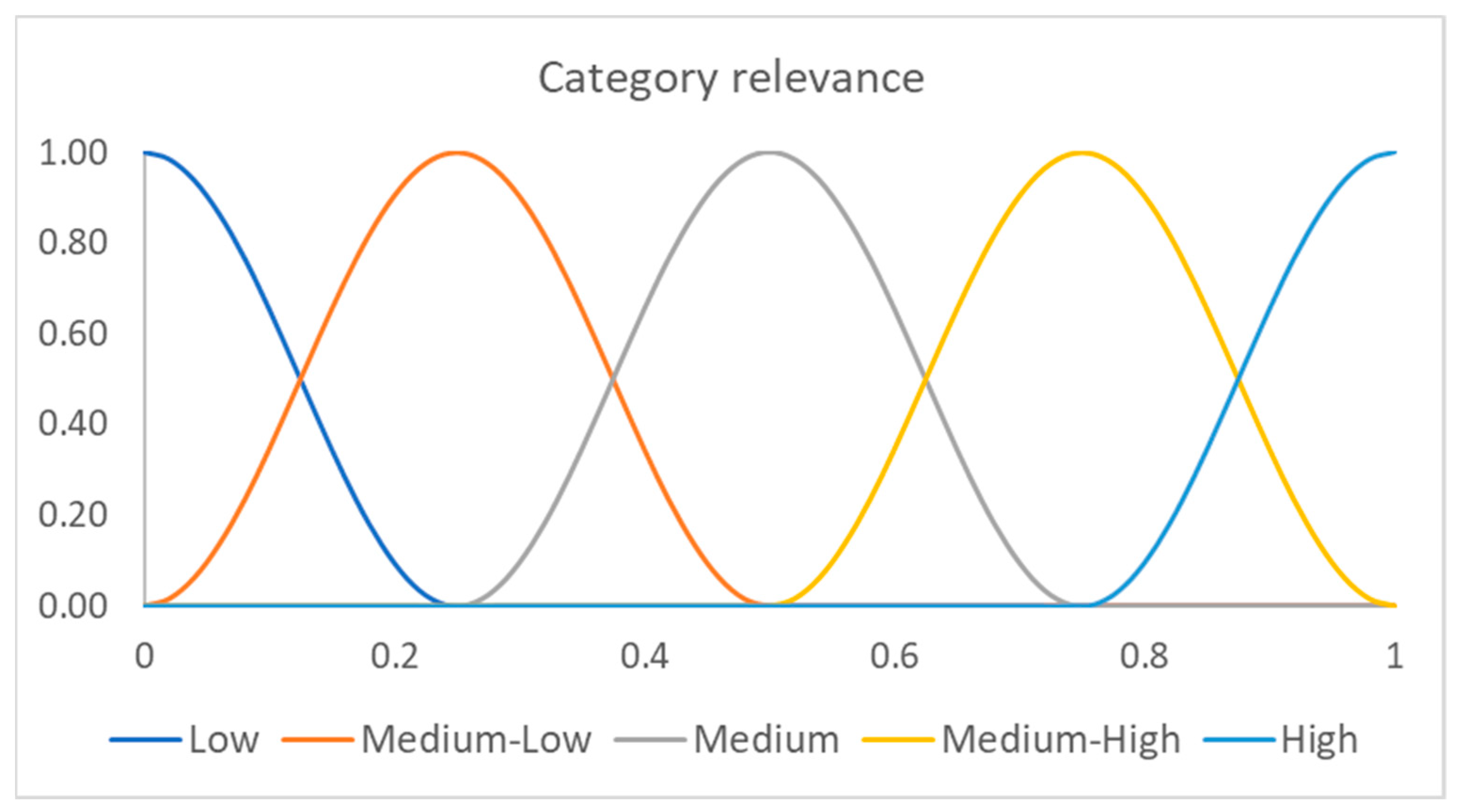
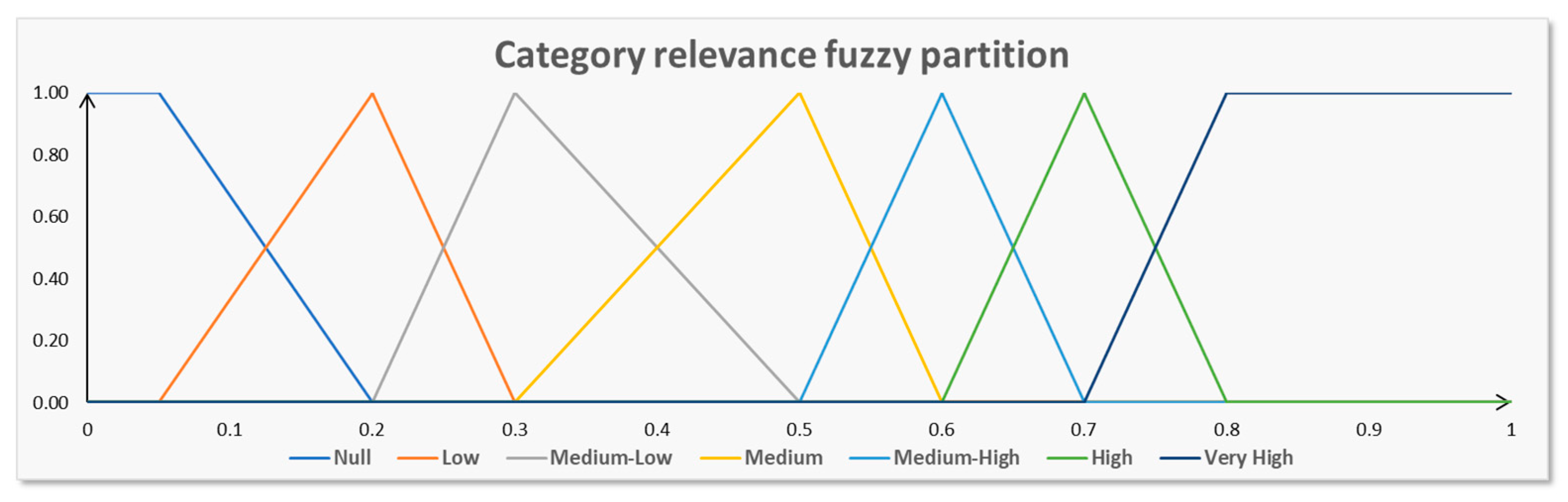
For example, let the category relevance fuzzy partition be composed by the following five ordered fuzzy sets:
low, medium-low, medium, medium-high, high, constructed as in
Figure 2, in which cosinusoidal fuzzy sets are generated.
The fuzzy sets are ordered according to the relevance value in which the membership function has the maximum value. In this example, the order sequence is: low → medium-low → medium → medium-high → high.
Let the fixed threshold be medium. If to a category is attributed a relevance in a document greater than or equal to medium, it is considered, otherwise it is discarded.
As an example, let us assume that the relevance in the ith document of each of the four categories has been calculated on the basis of Formula (1), as reported in
Table 1. These relevance values are the values in the ith row of the relevance matrix.
The highest membership degrees are highlighted in bold in
Table 1.
The only category whose relevance in the document will be considered negligible is tram, as its relevance (low) is below the threshold (medium).
The multiple classification of a document is completed by assigning the relevance of each category it is labeled with. The ith document is classified as in
Table 2.
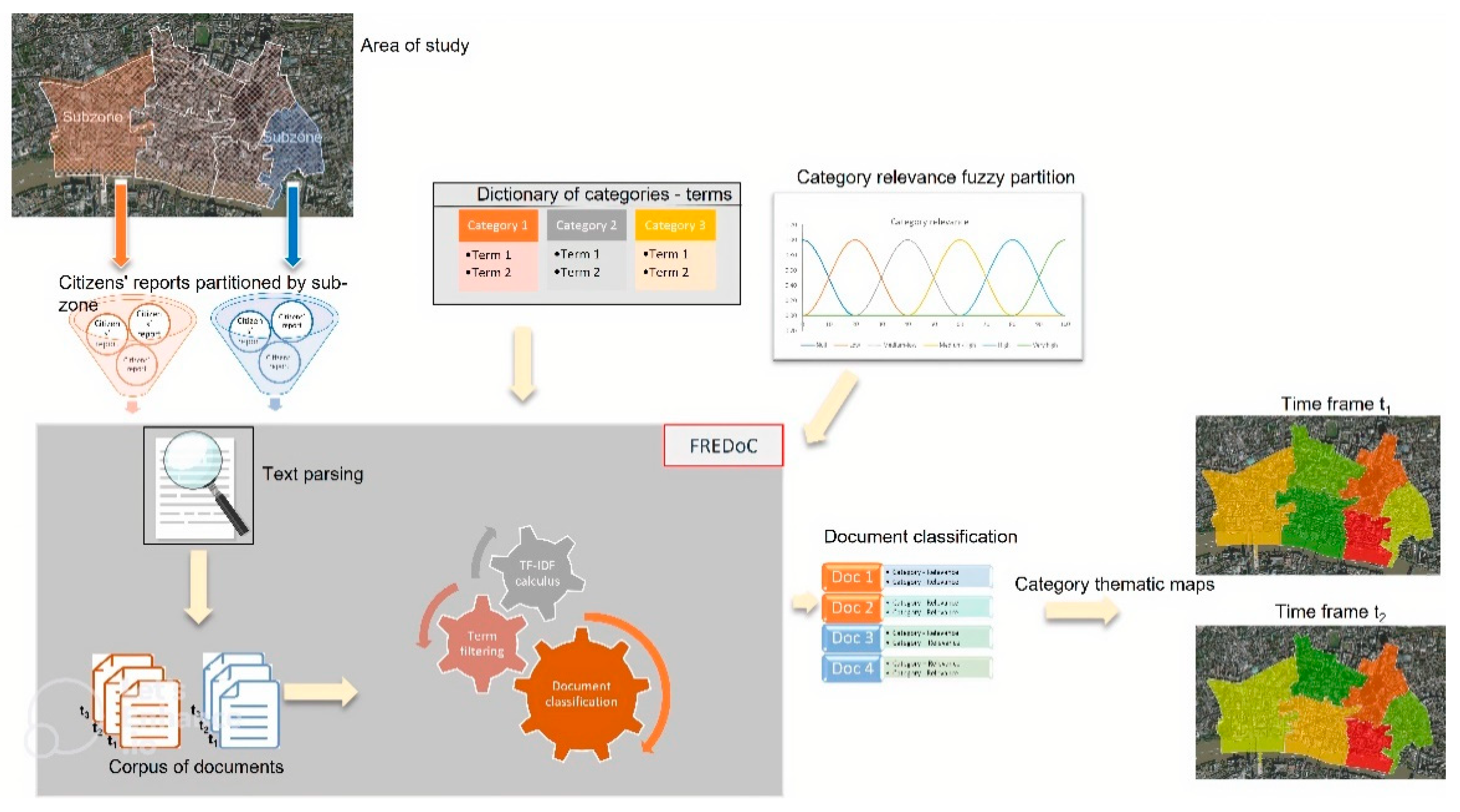
3. The Proposed GIS-Based Framework
In our framework, the FREDoC model is encapsuled in a GIS-based platform.
In
Figure 3 is schematized the proposed GIS-based framework.
The user of the framework is a decision maker who intends to analyze the distribution in the study area of the relevance of each category and its evolution over time. To analyze its evolution over time, he sets a unitary time interval, the time frame, dividing the survey period of the information into time frames.
The urban study area is partitioned into subzones by the user, who aims to obtain for each time frame a thematic map of the subzones classified by relevance of a specific category.
The dictionary of categories is prepared by the user dividing the entities that characterize the problem to be analyzed into categories. For example, in an analysis problem of the reported instability in urban areas, a possible subdivision into categories could be the following:
- -
Disruption on the road
- -
Failure to buildings
- -
Disruption on public green areas
- -
Malfunctions in public lighting
- -
Malfunctions to the sewer system
Terms that refer to a specific category are assigned in the dictionary to that category. Examples of terms related to the disruption on the road category are: pothole, chasm, landslide, pavement, etc. Examples of terms related to the failure to buildings category are: plaster, cornice, gutter, roof, balcony, etc.
Furthermore, the user constructs the fuzzy partition of the relevance of a category, called category relevance fuzzy partition, assigning the number of fuzzy sets and, for each fuzzy set, its membership function and linguistic label.
After constructing the category relevance fuzzy partition, the FREDoC model is executed in order to classify documents constructed by acquiring the reports made by citizens. These reports are made by citizens using institutional or social channels and are connected to the problem to be analyzed; they are collected and grouped by subzone and time frame.
To assign a report to a sub-zone, a geocoding process can be performed in order to georeference the report as a point on the map and assign it to the sub-zone in which it is included. For example, if the report refers to a street address, the geocoding process is implemented by acquiring the toponymic dataset of the study area.
FREDoC creates the corpus of documents, filters the terms in the documents, and computes the TF-IDF index values of each category in each document. Then, it classifies the documents, assigning to each category its fuzzy relevance in the document, as in the example in
Table 1.
Unlike the FREDoC framework proposed in [
16], we do not use a relevance threshold, as the aim of our framework is to create thematic maps of the subzones relating to a category and a time frame in which all relevance levels are considered.
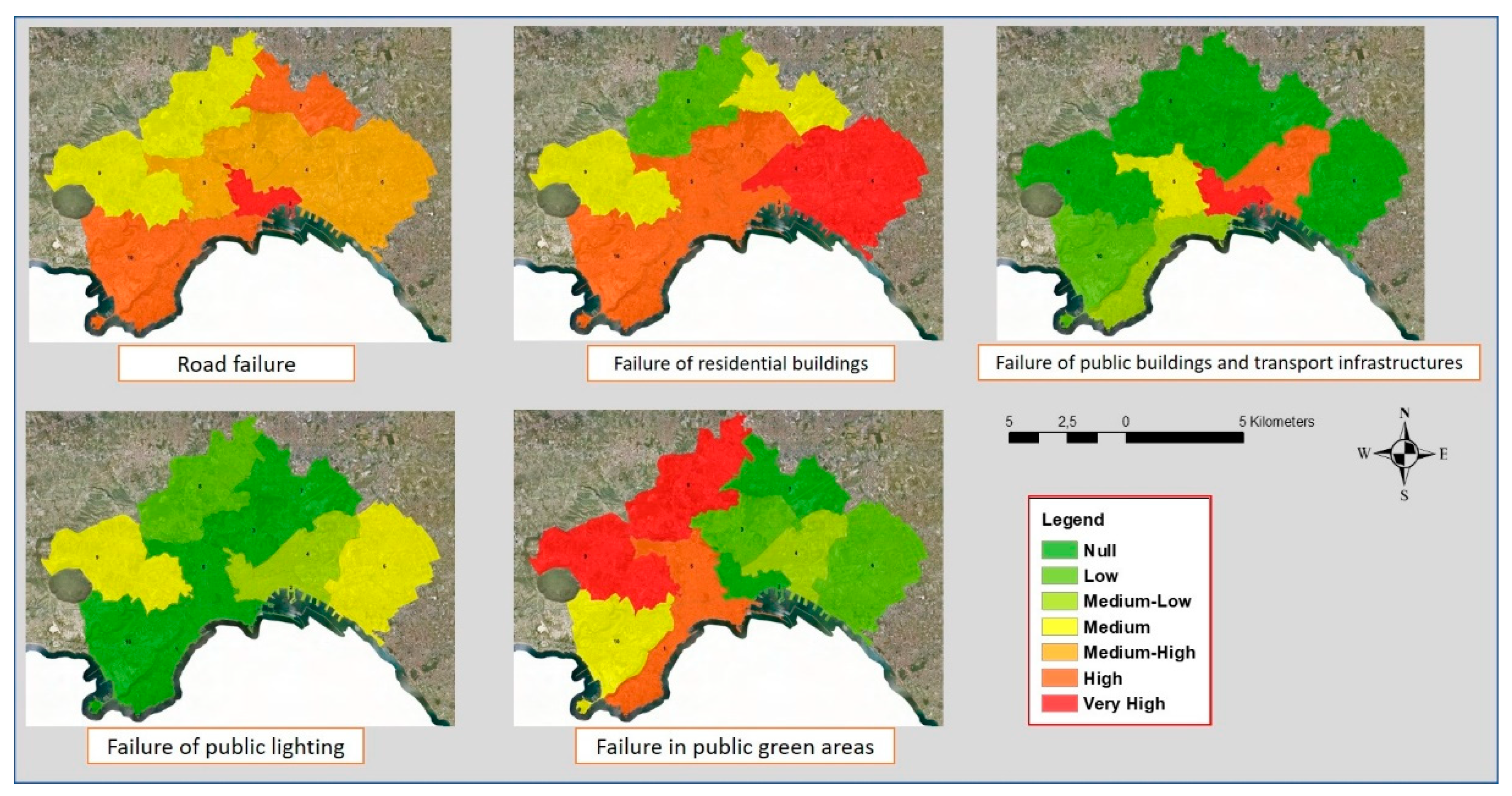
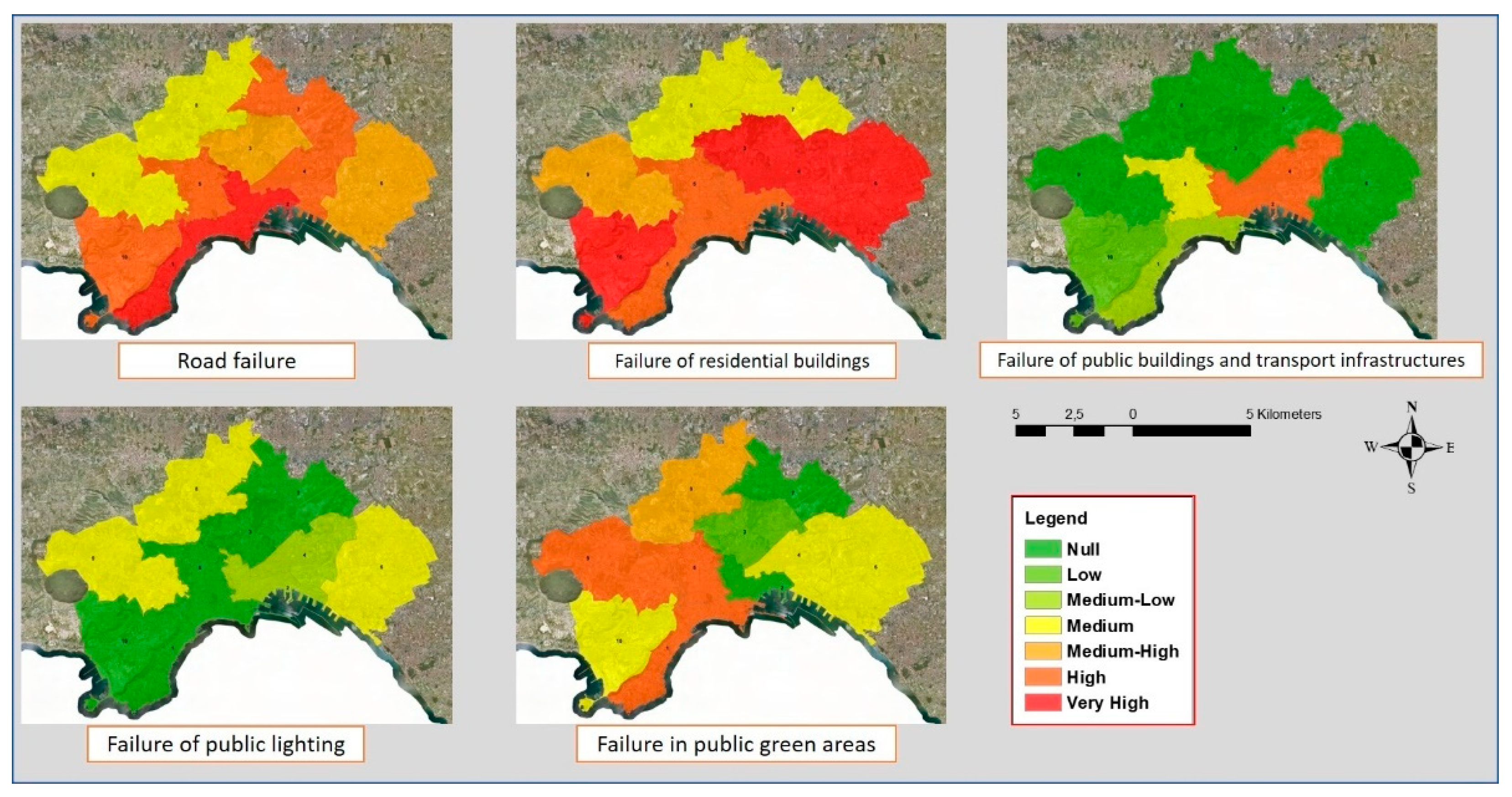
Finally, thematic maps of the classified subzones are constructed for each time frame.
Each document refers to a specific subzone and a specific time frame. A thematic map of a category in the study area referred to a time frame is constructed, assigning to each subzone the relevance attributed to the category in the document associated with the subzone and the time frame. In this way, it is possible to analyze the evolution over time of the relevance of a category.
A pseudo-code of the algorithm is shown in Algorithm 1.
| Algorithm 1: GIS-based category classification. |
![Information 13 00248 i001]() |
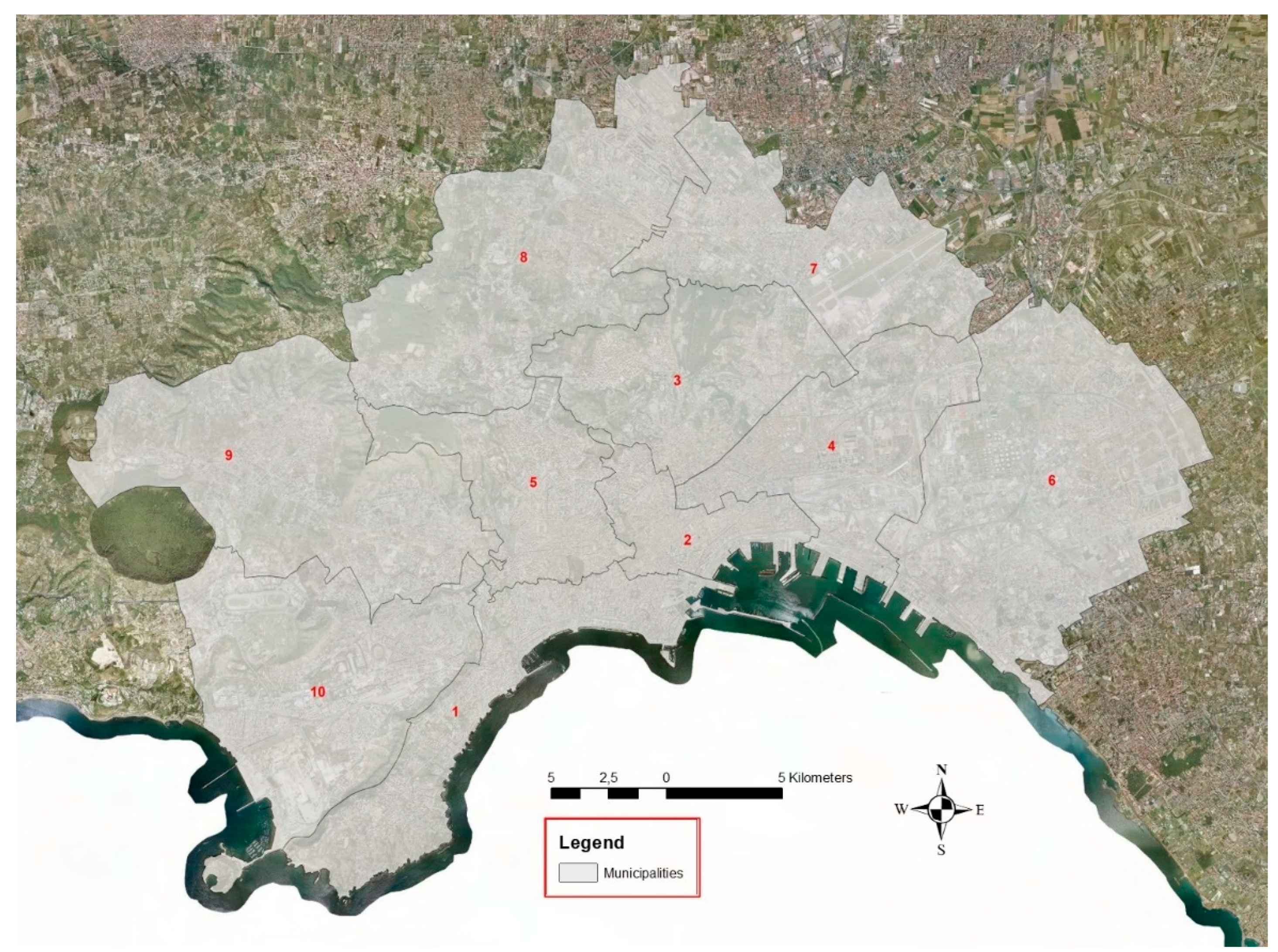
The next section shows the results of the application of our framework for the study of the major problems of instability on open spaces and the built environment identified, starting from the reports made by citizens. The study area is made up of the urban fabric of the city of Naples.
The surface of Naples is partitioned into ten municipalities, which are urban areas with functions of organizational and managerial autonomy. Municipalities are able to decide directly on matters that are important for the lives of citizens.
The dataset used in these tests is the archive of citizens’ alarm reports collected by the Civil Protection of the Campania region, a body that protects citizens from damage that may derive from natural events.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}