1. Introduction
The advancements in the internet of things (IoT), artificial intelligence (AI), and Cyber-Physical Systems (CPS) are leading the manufacturing sector towards a fourth industrial revolution [
1]. Part of this technological leap, named “Industry 4.0”, involves the development of smart factories, i.e., production systems capable of self-organizing, predicting, and correcting their own faults, and that can adapt to variable human needs [
2]. The increasing availability of pervasive sensors makes AI and, specifically, machine learning (ML) pivotal for the Industry 4.0 transition, enabling the operation of industries in a flexible, efficient, and green way [
3]. In fact, data-driven methodologies based on ML and deep learning (DL) are emerging in several Industry 4.0 applications, such as anomaly detection [
4], predictive maintenance [
5,
6], inventory management [
7], sensory and productivity measurements [
8,
9], aided design [
10], quality control [
11], security [
12], smart working [
13], digital twin development [
14], healthcare [
15,
16], and many others [
17].
Plastic injection molding is a manufacturing process widely used in the industry [
18], as it allows for the production of plastic objects characterized by complex geometries with high precision and productivity [
19]. Specifically, the process includes four phases, i.e., plasticization, injection, packing, and cooling [
20], during which the polymer is melted, injected and compressed in the mold, and, eventually, cooled. Given that the quality of a molded product depends on the process parameters, as optimal values reduce the cycle time and increase the quality of the final product [
21], extensive research has been devoted to predict the quality of products from the value of the production process parameters. Whilst early research works are dated back to the first decade of 2000, using techniques such as support vector machine (SVM) [
22] and neural networks [
20,
23], the advent of Industry 4.0 and its focus on extracting knowledge from machine sensors have boosted interest about the application of ML methods for the prediction of product quality from the parameters of the production process [
24,
25,
26,
27].
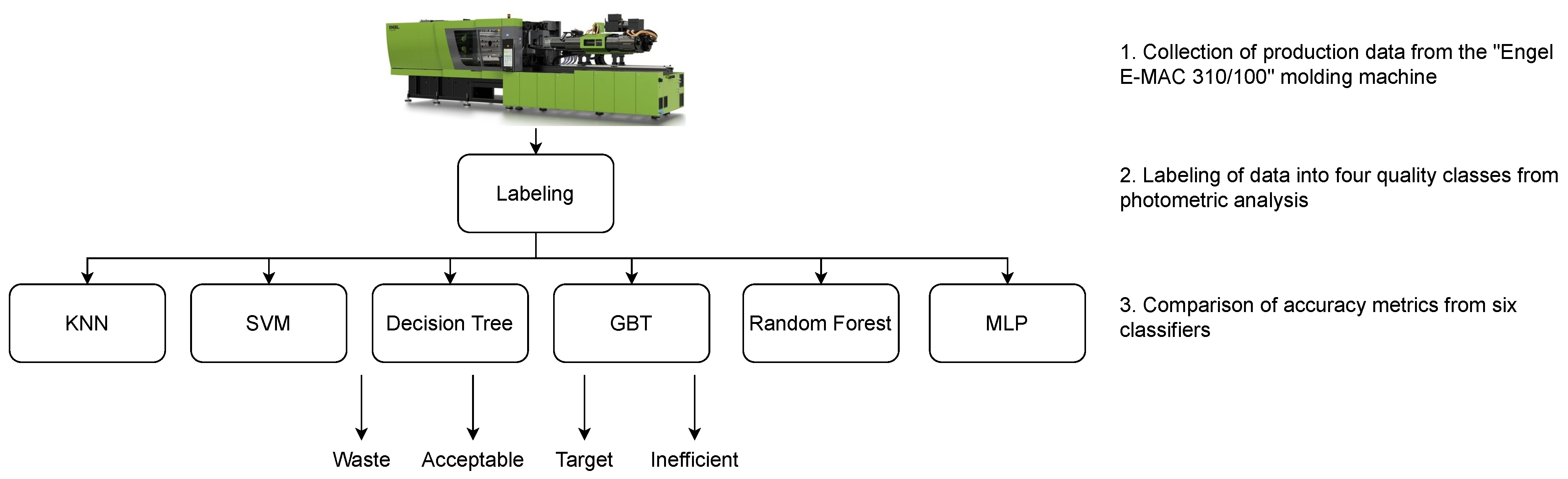
In this regard, this paper investigates the effectiveness of ML techniques to predict the quality of molded plastic products from the production process parameters, using real data from in-line industrial measurements. Specifically, the data comes from the production of plastic road lenses of “iGuzzini Illuminazione”, a company located in Recanati, Italy, which specializes in providing plastic components for lighting devices. In fact, road lenses are regulated by the standard “UNI EN 13201-2:2016”, which sets threshold values for the lighting uniformity (). Currently, controlling the quality of the lenses, i.e., their lighting uniformity, requires a lens-by-lens photometric analysis conducted by specialized personnel in lab settings, demanding significant resources. Therefore, our aim is to understand if this control can be automated or, at least, integrated by using ML methods to estimate the level of the lighting uniformity of a lens from its process parameters collected by the sensors of the injection molding machine during the production.
The research conducted on the “iGuzzini Illuminazione” case study and that is described in this paper adds the following contributions to the state of the art of quality prediction in injection molding:
A real application of Industry 4.0 is demonstrated, proposing the use of ML to automate the quality control of molded plastic products;
A new dataset is presented. It includes the real data about the production of road lenses by injection molding and is publicly available in the source code repository. As such, the dataset can be used to benchmark other techniques.
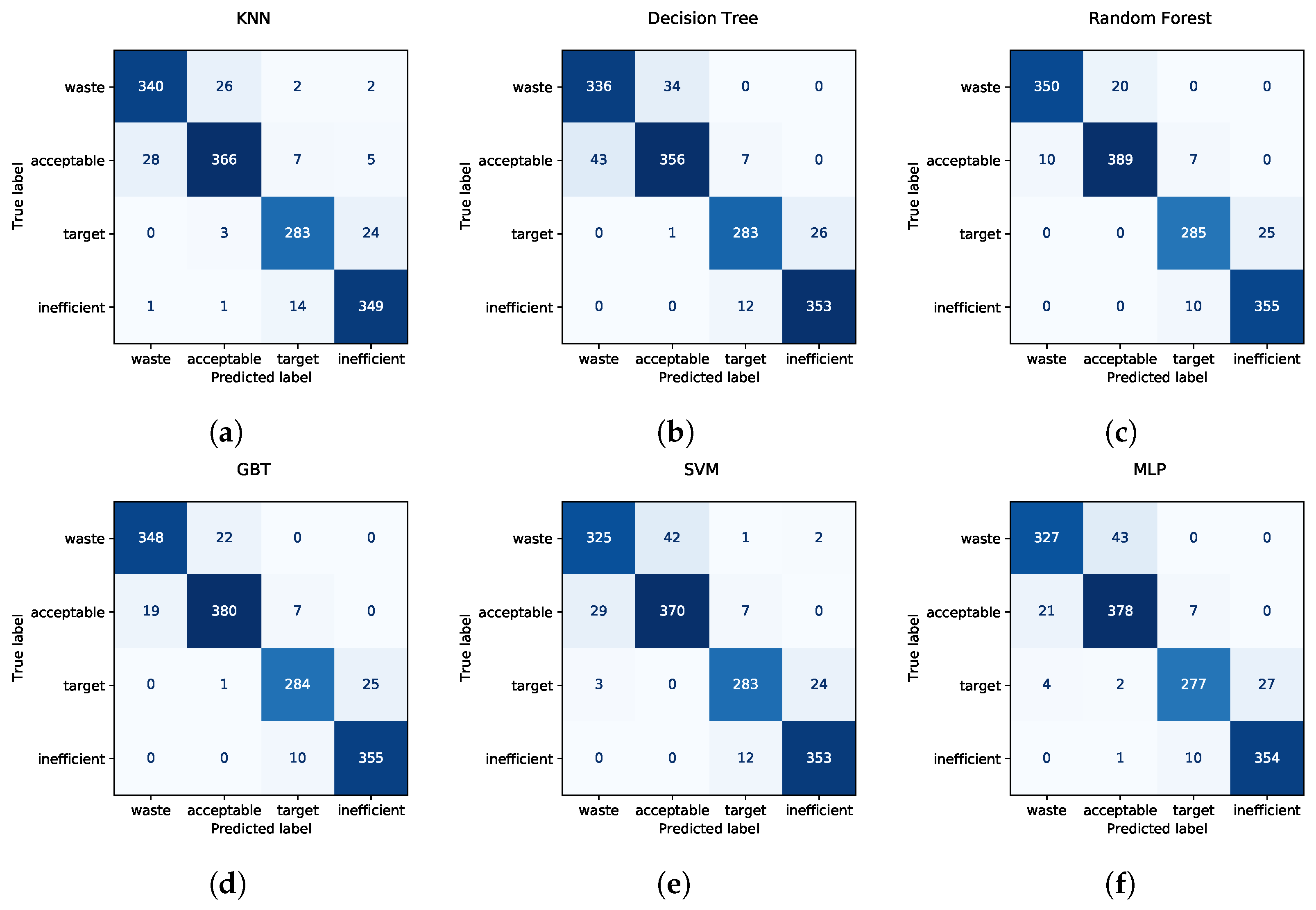
Despite the number of research works about quality prediction in plastic injection molding available, most of the papers compare few techniques (one or two) on often-unbalanced datasets with few samples, as explained in the literature review included in
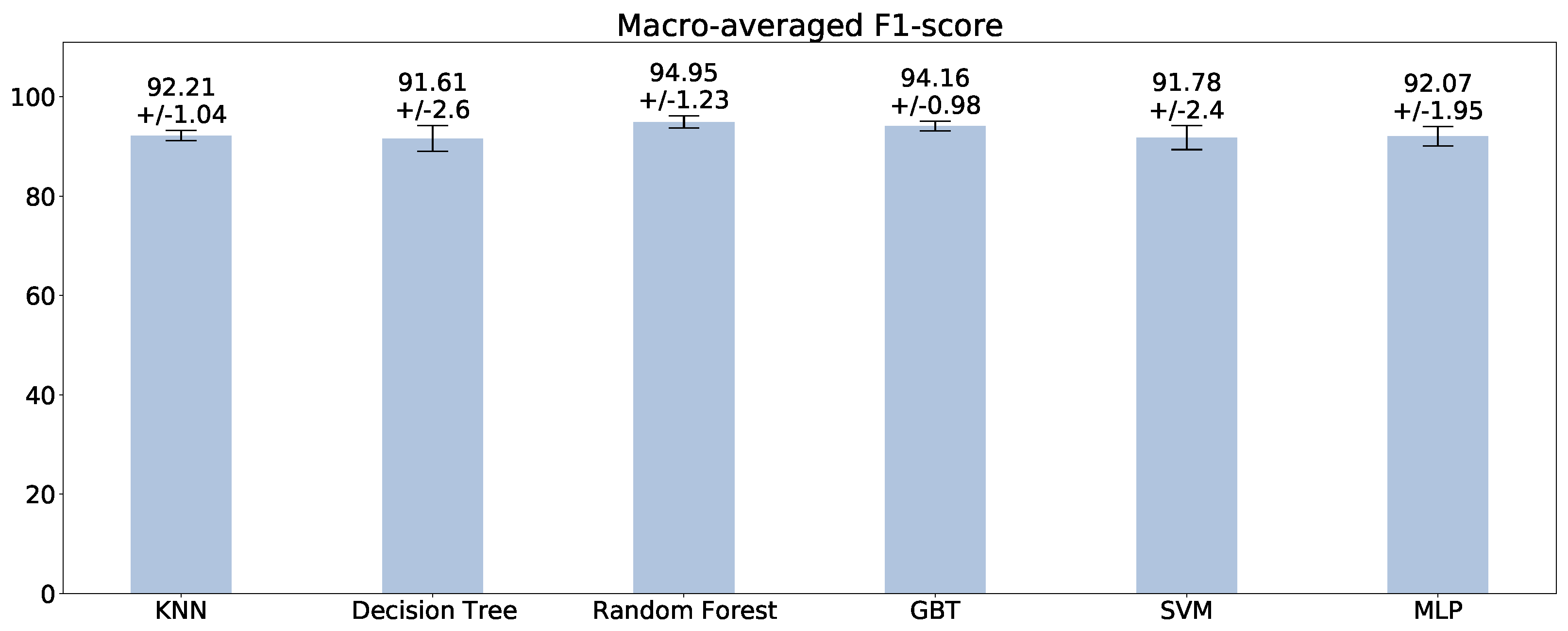
Section 2. Moreover, most of the papers distinguish between good products and faulty products. Instead, we compare six different techniques on a dataset collecting the production process parameters of 1451 samples, i.e., road lenses. Moreover, we classify the road lenses in four different quality classes, instead of dealing with a binary problem. Furthermore, to the best of our knowledge, this is the first work in quality prediction for plastic injection molding to publicly release the source code of the comparison of ML techniques and the data used for the tests, providing fully reproducible results.
The rest of the paper is organized as follows.
Section 2 lists other relevant research works on quality prediction for plastic injection molding, comparing our methodology to the related literature.
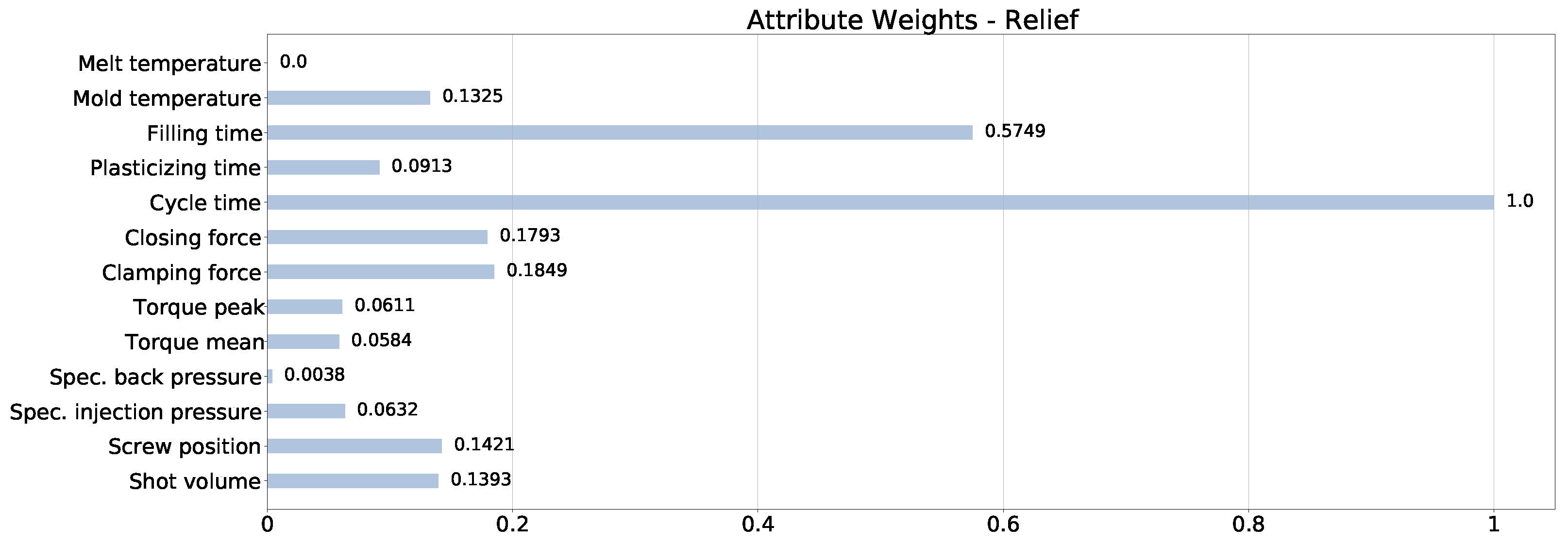
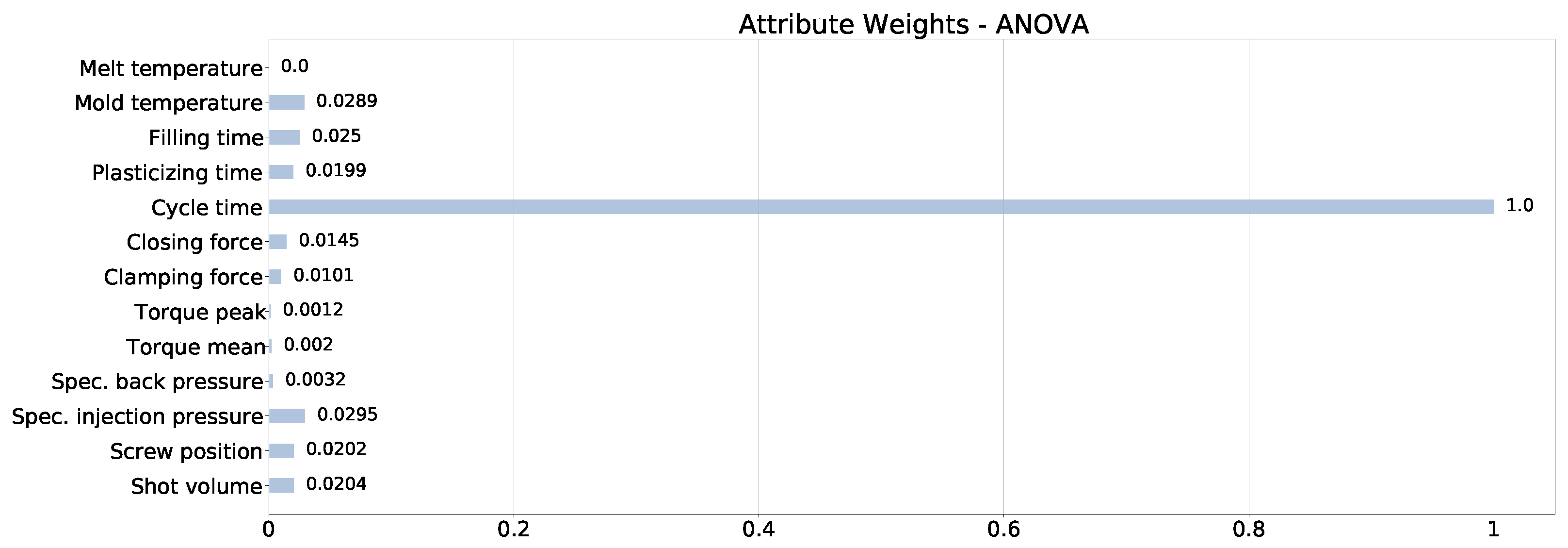
Section 3 describes the dataset built for the experiments and the compared ML techniques, providing the necessary background.
Section 4 presents an experimental evaluation of the quality prediction applied to the production of the road lenses, discussing the results. Finally,
Section 5 draws the conclusions of this research.
2. Literature Review
Early research works for quality prediction in plastic injection molding are dated back to the early 2000s. For example, Sadeghi [
23] proposed a neural network and a multi-layer perceptron (MLP) using four features (melt flow rate, injection pressure, mold temperature, and melt temperature) to estimate actual injection pressure, filling time, and part soundness, with a hidden layer composed of two neurons. The author tested the proposed methodology on simulated data. Similarly, Chen et al. [
20] used a neural network-based approach to estimate the weight of the samples. They combined self-organizing maps (SOM), using three features as inputs (injection stroke curve, injection velocity curve, and pressure curve), and an MLP, using six features as inputs (injection time, VP switch position, packing pressure, injection velocity, packing time, and injection stroke), on 160 real samples (120 for training, 40 for testing), achieving a root mean squared error of 0.0017. Ribeiro [
22] proposed the use of support vector machine (SVM) classifiers to predict faults in automotive parts produced with injection molding. They used six features as the input (cycle time, metering time, injection time, barrel temperature before nozzle, cushion, and injection velocity) and compared their methodology with a neural network to predict six types of faults, obtaining an accuracy between 87% and 100% (depending on the type of fault to be classified). Liu et al. [
28] proposed an ensemble of neural networks to predict the shrinkage of thin shell parts as a measure of their quality. They used mold temperature, holding pressure, and holding time as inputs for the neural networks, taking 70 samples for training, 15 samples for validation, and 15 samples for testing, achieving a top root mean squared error of 0.008.
Differently from the listed early research works, we compare more techniques (six), on more real data (our dataset is composed of the process parameters of 1451 samples), using more features (thirteen), and applying a cross-validation scheme to generalize the results.
After Industry 4.0 became an established paradigm exploiting IoT, AI, and CPS to increase efficiency and productivity in manufacturing, several research works devoted their efforts to predicting the quality of molded plastic products. For example, Nagorny et al. [
24] proposed the use of convolutional neural networks (CNNs) to process thermographic images of products and long short-term memory (LSTM) neural networks to process raw parameters and to run the regression of a single-quality attribute. They tested their approach on a dataset composed of 177 samples for training and 27 samples for testing. They compared their methodology with classical regression algorithms, achieving the best results with the LSTM. Instead of calculating the regression of a single variable, we use a classification approach to predict the quality classes of road lenses, and we train and test on a bigger dataset. Ogorodnyk et al. [
25] compared an MLP and a decision tree classifier (J48) using 18 features as inputs. They used a 10-fold cross-validation scheme on a dataset composed of 101 defective samples and 59 good samples. They achieved the best results with the decision tree, obtaining 95.6% accuracy. Differently from their work, our dataset is almost balanced and includes more samples. Furthermore, we classify the samples into four quality classes, instead of performing a binary classification. Obregon et al. [
29] compared different ensembles of decision trees on an imbalanced binary dataset, with the objective of inferring explainable rules for quality control. In their first experiment, they used a dataset composed of 81 normal products and 37 defective products, whereas, in the second, they had 287 normal products and 613 defective products, achieving a top accuracy of 94.98% in the first experiment, and 99.73% in the second. Ke and Huang [
26] proposed an MLP with a hidden layer to predict classes of three width measures of the molded products. As inputs, they took four parameters measured in ten different points of the injection molding process. They trained their model on 356 samples and tested on 89 samples, obtaining an accuracy around 90% (with a class scoring of 93% as the best result). Jung et al. [
27] compared an autoencoder against several classical ML techniques on a very imbalanced dataset composed of 5617 samples, using 70% of the data as the training set and 30% of the data as the test set. Specifically, the test set included 1605 good samples and only 125 defective samples. They achieved a 99% accuracy with the autoencoder on their binary problem. Differently from these research works, we tested our models on a balanced dataset and on a multi-class problem.
Deep neural networks (DNNs) and DL-based techniques demonstrate their effectiveness in pattern recognition for many different applications, such as image and video processing, object detection, speech recognition, and others [
30]. DNNs and DL-based techniques have been recognized as useful even for industrial quality prediction, providing better results than shallow networks in different applications [
31]. For example, Liu et al. [
32] proposed a novel stacked multi-manifold autoencoder for feature extraction, and successfully applied it to quality prediction in the hydrocracking process. Instead, in our research, we try to classify the quality of molded products from 1451 feature vectors with the parameters of the plastic injection molding process. As such, the amount of available data, its tabular nature, and the need of using only real data, without simulated or synthetic values, led us to the choice of applying classical ML techniques on hand-crafted features. However, DL-based techniques are emerging, even in plastic injection molding, and try to apply transfer learning to deal with the scarcity of training data, such as in [
33,
34].
Moreover, differently from all the works listed in this section, we publicly released the source code and the data of the tests, providing fully reproducible experiments.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}