
What Attracts the Driver’s Eye? Attention as a Function of Task and Events


Abstract
:1. Introduction
2. Methods
2.1. Participants
2.2. Experimental Setup
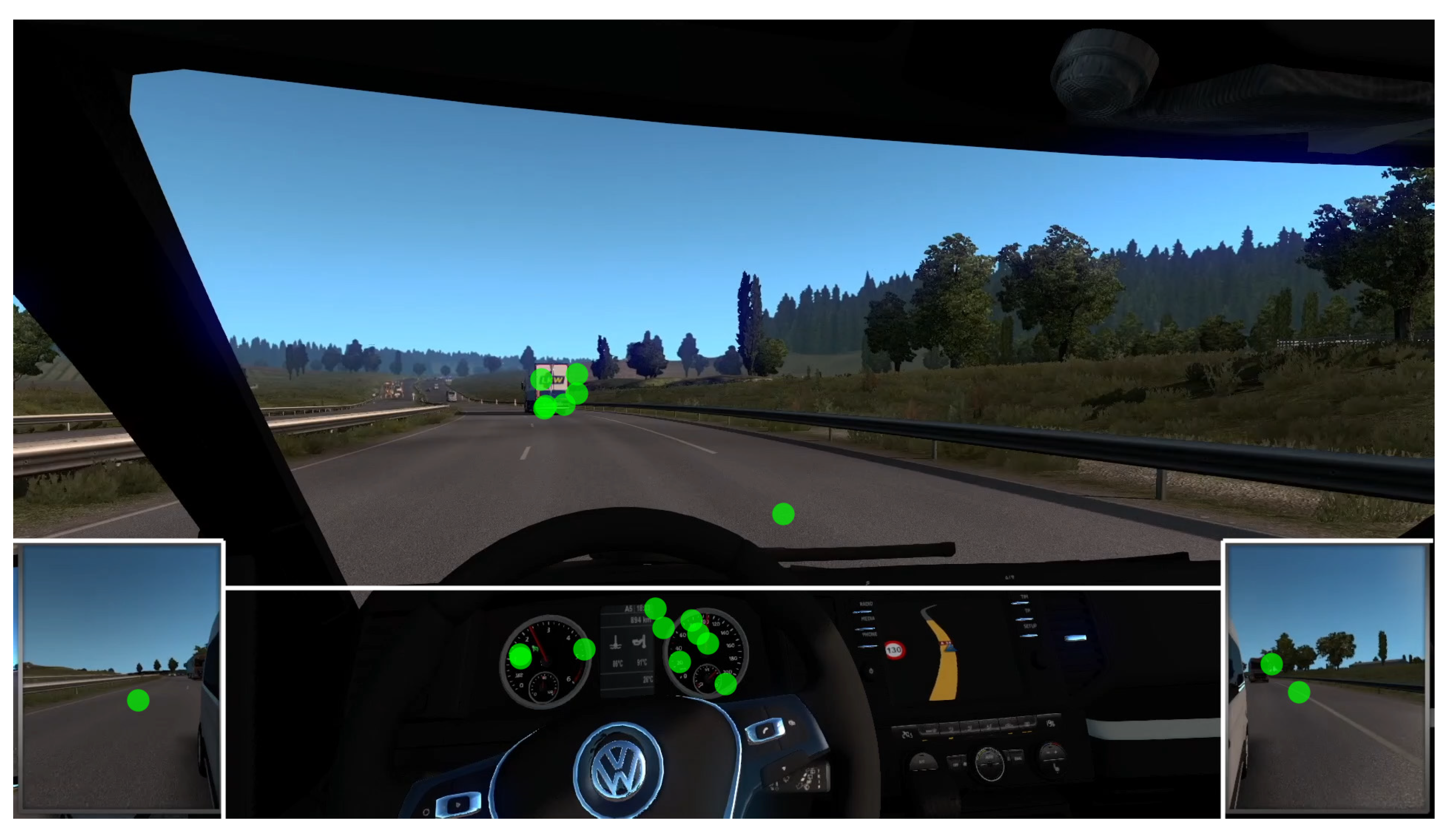
2.3. Stimuli
- In Video 1, the ego-vehicle overtook six vehicles and was overtaken by one vehicle. The speed of the ego-vehicle crossed the 100 km/h mark six times, and the vehicle changed lanes six times.
- In Video 2, the ego-vehicle overtook two vehicles and was overtaken by five vehicles. The speed of the ego-vehicle crossed the 100 km/h mark 13 times, and the vehicle changed lanes four times.
- In Video 3, the ego-vehicle overtook eight vehicles and was overtaken by two vehicles. The 100 km/h mark was crossed six times, and six lane changes occurred.
2.4. Experimental Task and Procedures
- Baseline: You do not have any secondary tasks to perform.
- Speed Task: You should shortly press the spacebar every time the speed dial crosses the 100 km/h mark. This works two ways around, i.e., when the car is braking or accelerating. As soon as the dial is on the 100 km/h mark, you should press; as soon as the pointer has passed the mark, you should release the spacebar.
- Hazard Task: You will have to indicate whether a car or truck is driving in the lane next to you. As long as this is the case, you have to press the arrow key. Press the right arrow key when someone is driving on your right side and the left arrow key when someone is driving on your left. When there is nothing on your left or right, you have to release the arrow key.
2.5. Data Processing
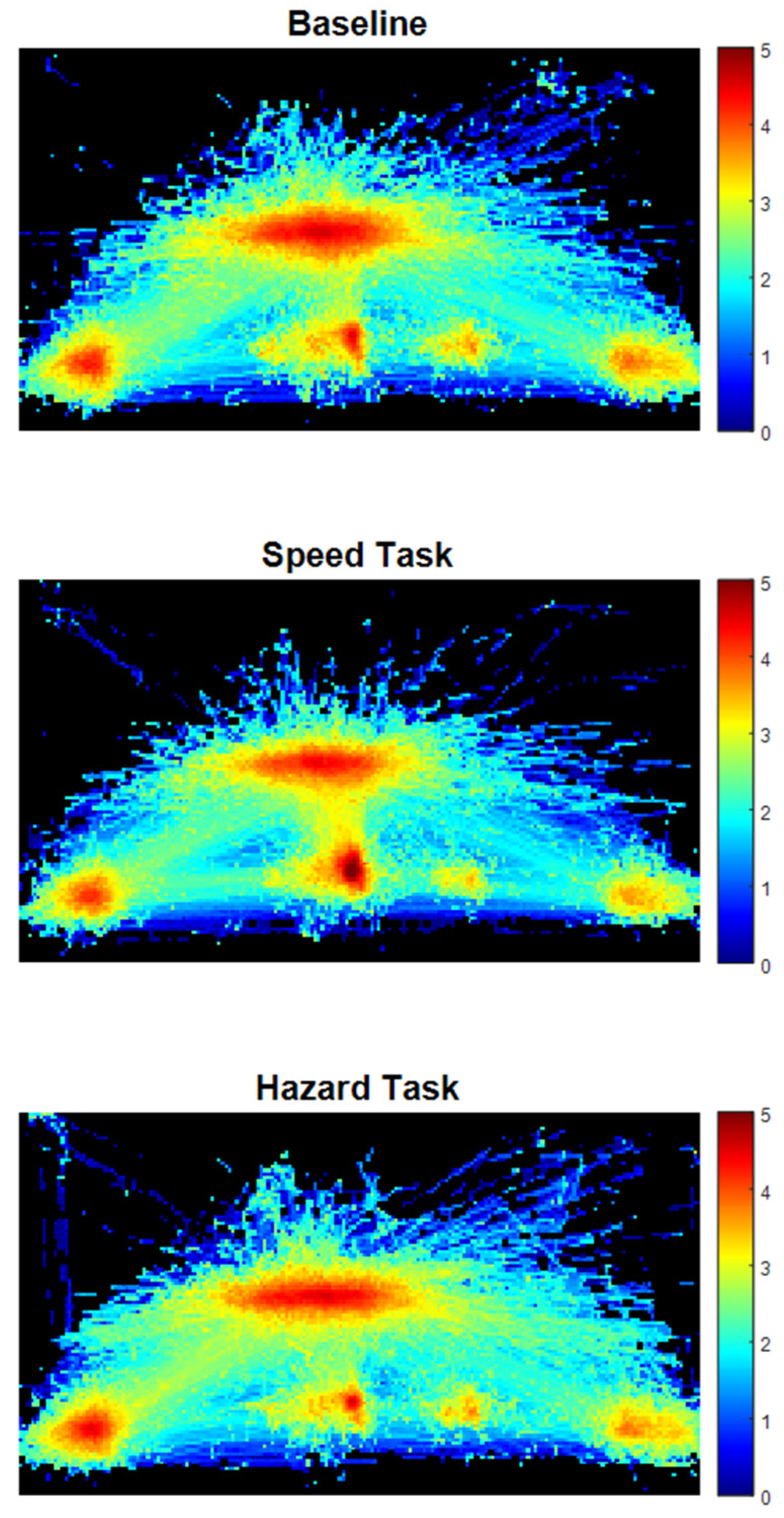
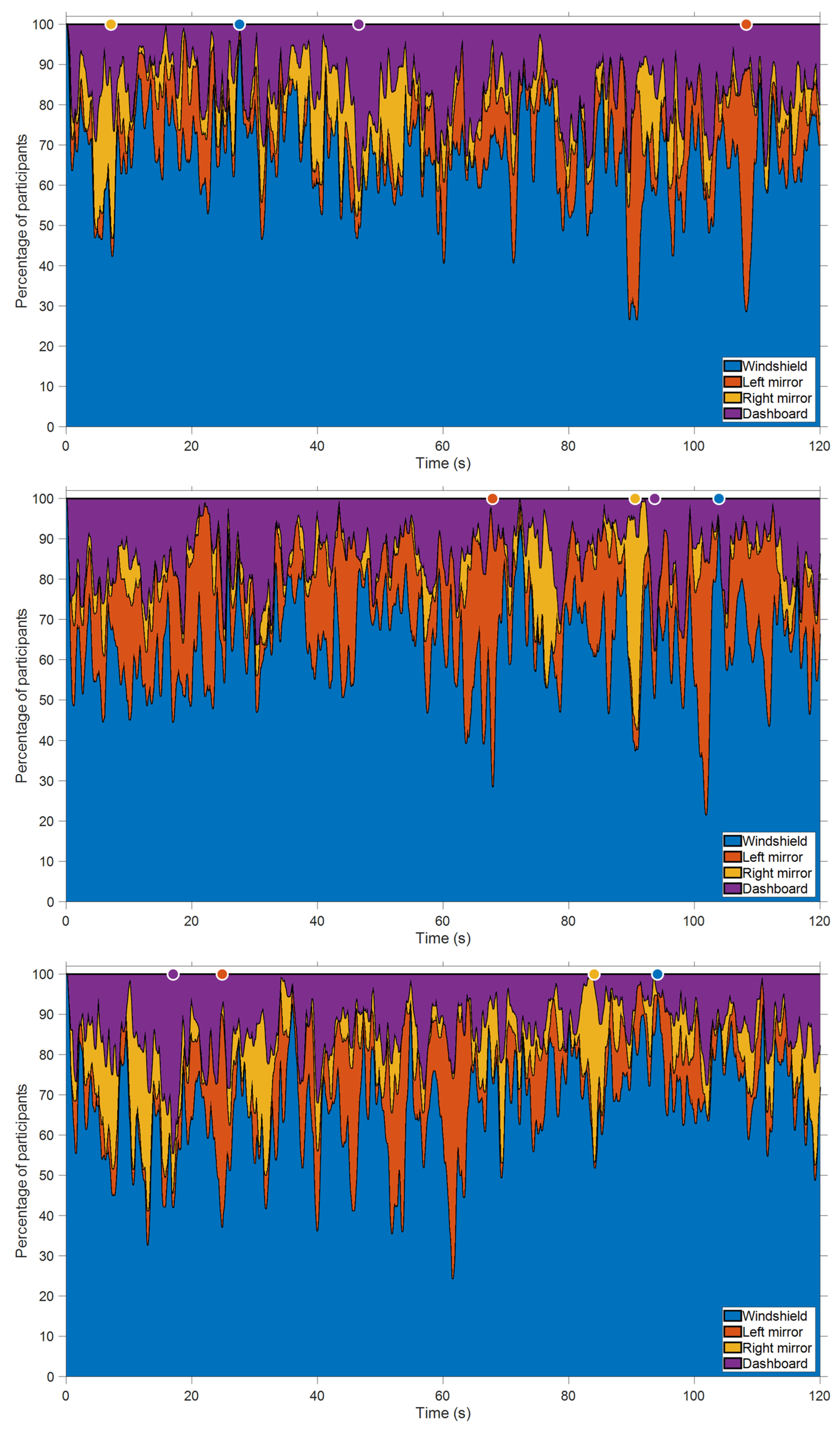
3. Results
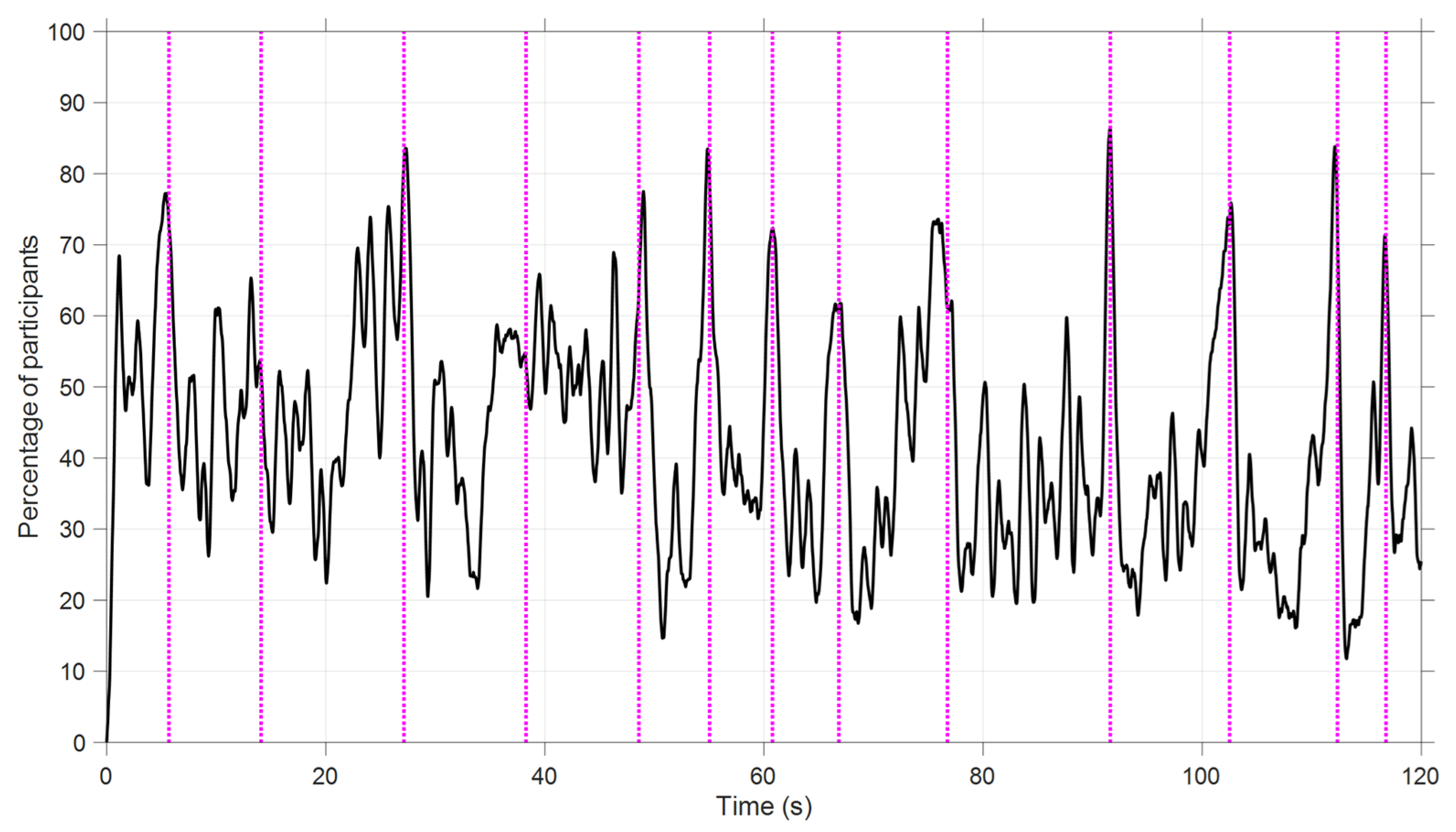
- The windshield attracted attention when events (e.g., car in front, curve, road signs) were happening in that AOI (Figure 4).
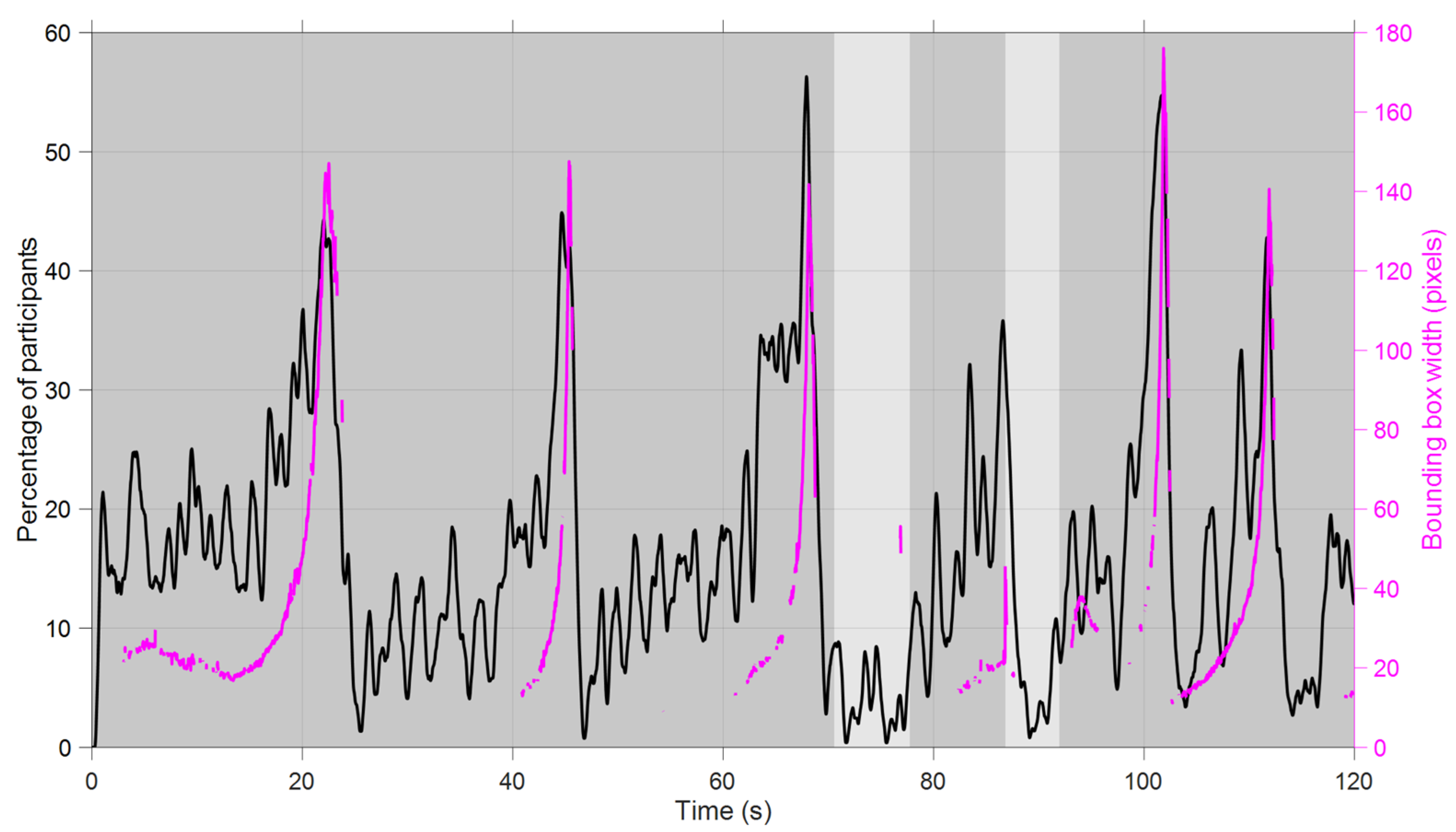
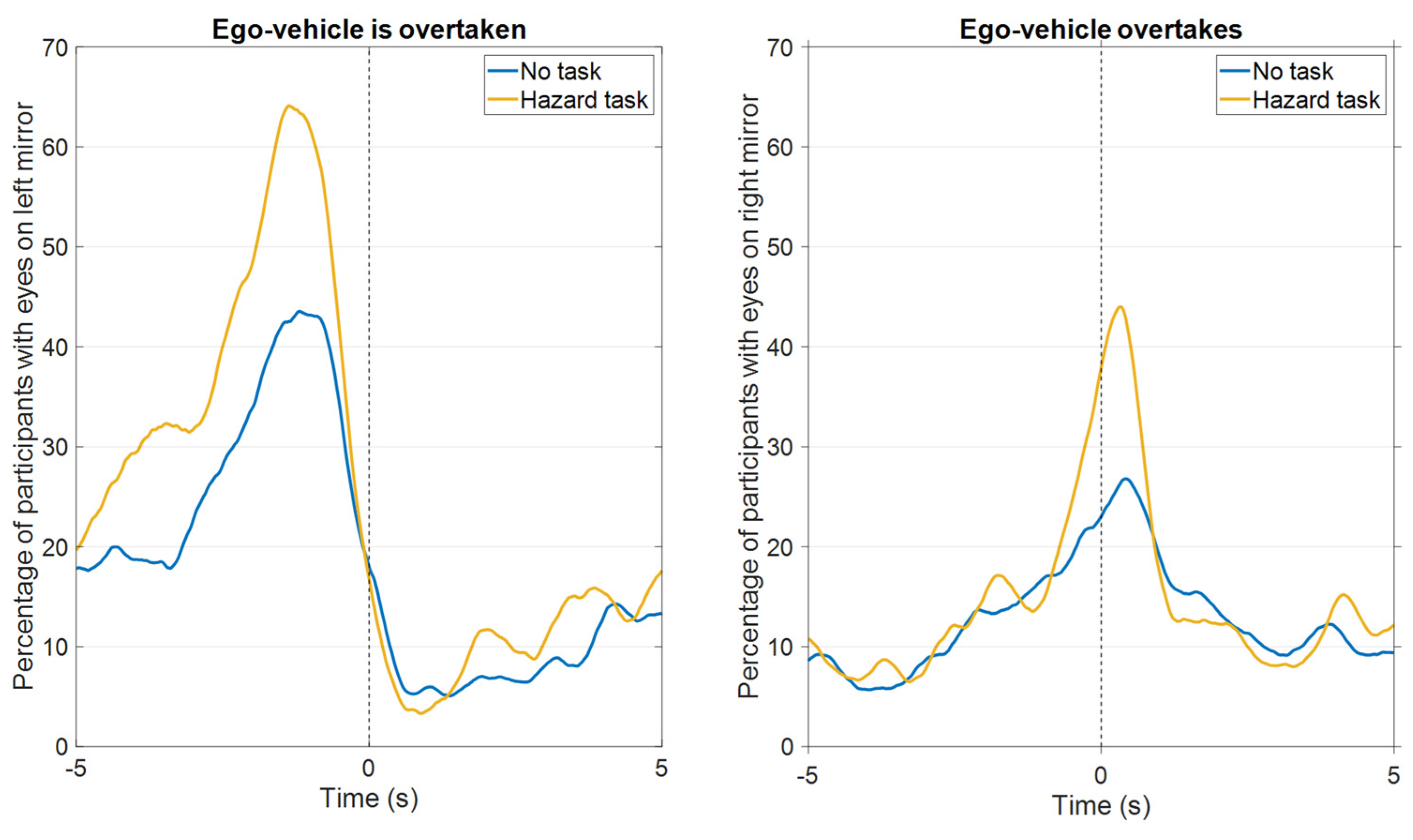
- The left mirror attracted attention right before a lane change to the left lane and while a vehicle was visible in the left mirror (Figure 5). The participants may have anticipated that a lane change was about to happen based on the proximity of other vehicles as well as the turn indicator usage visible on the dashboard.
- The right mirror attracted attention right before changing lanes to the right after having overtaken another vehicle (Figure 6).
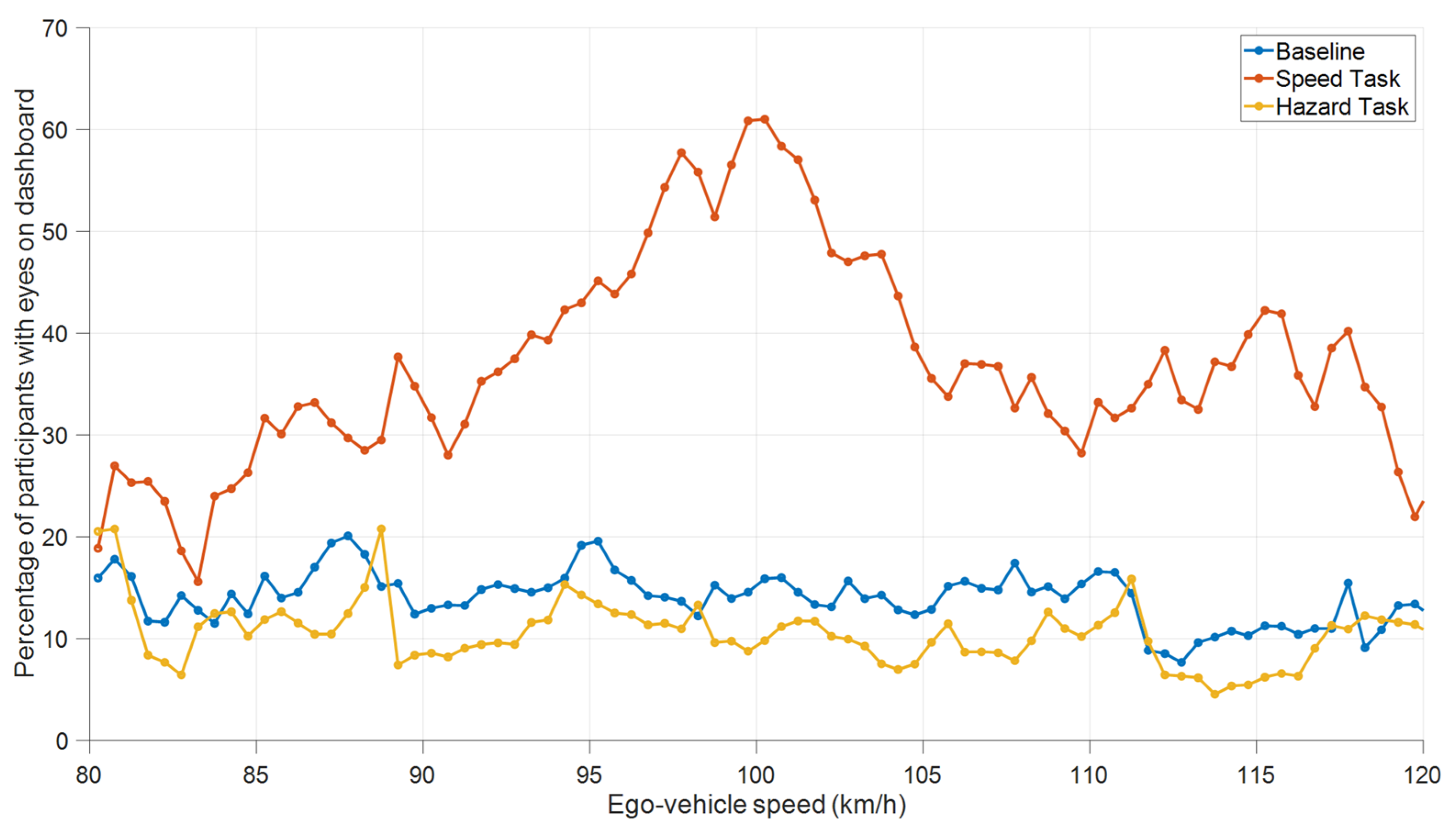
- Finally, the speedometer attracted attention in otherwise uneventful conditions while the road was relatively empty (Figure 7).
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- European Commission. Regulation (EU) 2019/2144. Type-approval requirements for motor vehicles and their trailers 2019, and systems, components and separate technical units intended for such vehicles, as regards their general safety and the protection of vehicle occupants and vulnerable road users. Off. J. Eur. Union 2019, L 325, 1–40. [Google Scholar]
- Cabrall, C.D.D.; Happee, R.; De Winter, J.C.F. From Mackworth’s clock to the open road: A literature review on driver vigilance task operationalization. Transp. Res. Part F Traffic Psychol. Behav. 2016, 40, 169–189. [Google Scholar] [CrossRef] [Green Version]
- Hecht, T.; Feldhütter, A.; Radlmayr, J.; Nakano, Y.; Miki, Y.; Henle, C.; Bengler, K. A review of driver state monitoring systems in the context of automated driving. In Proceedings of the 20th Congress of the International Ergonomics Association, Florence, Italy, 26–30 August 2018; Bagnara, S., Tartaglia, R., Albolino, S., Alexander, T., Fujita, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 398–408. [Google Scholar] [CrossRef]
- Cabrall, C.D.D.; Janssen, N.; De Winter, J.C.F. Adaptive automation: Automatically (dis)engaging automation during visually distracted driving. PeerJ. Comput. Sci. 2018, 4, e166. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cadillac. CT6 (Owner’s Manual). 2020. Available online: https://www.cadillac.com/content/dam/cadillac/na/us/english/index/ownership/technology/supercruise/pdfs/2020-cad-ct6-owners-manual.pdf (accessed on 1 May 2022).
- Tesla. About Autopilot. 2022. Available online: https://www.tesla.com/ownersmanual/models/en_us/GUID-EDA77281-42DC-4618-98A9-CC62378E0EC2.html (accessed on 17 June 2022).
- Volvo. Pilot Assist. 2020. Available online: https://www.volvocars.com/en-th/support/manuals/v60/2018w46/driver-support/pilot-assist/pilot-assist (accessed on 1 May 2022).
- Lappi, O.; Rinkkala, P.; Pekkanen, J. Systematic observation of an expert driver’s gaze strategy—An on-road case study. Front. Psychol. 2017, 8, 620. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garay-Vega, L.; Fisher, A.L. Can novice drivers recognize foreshadowing risks as easily as experienced drivers? In Proceedings of the Third Driving Assesment Conference, Rockport, ME, USA, 27–30 June 2005; Volume 3, pp. 471–477. [Google Scholar] [CrossRef]
- Malone, S.; Brünken, R. The role of ecological validity in hazard perception assessment. Transp. Res. Part F Traffic Psychol. Behav. 2016, 40, 91–103. [Google Scholar] [CrossRef]
- Falkmer, T.; Gregersen, N.P. A comparison of eye movement behavior of inexperienced and experienced drivers in real traffic environments. Optom. Vis. Sci. 2005, 82, 732–739. [Google Scholar] [CrossRef] [PubMed]
- Mourant, R.R.; Rockwell, T.H. Strategies of visual search by novice and experienced drivers. Hum. Factors 1972, 14, 325–335. [Google Scholar] [CrossRef] [Green Version]
- Underwood, G.; Crundall, D.; Chapman, P. Driving simulator validation with hazard perception. Transp. Res. Part F Traffic Psychol. Behav. 2011, 14, 435–446. [Google Scholar] [CrossRef]
- Van Leeuwen, P.M.; Happee, R.; De Winter, J.C.F. Changes of driving performance and gaze behavior of novice drivers during a 30-min simulator-based training. Procedia Manuf. 2015, 3, 3325–3332. [Google Scholar] [CrossRef] [Green Version]
- Cerezuela, G.P.; Tejero, P.; Chóliz, M.; Chisvert, M.; Monteagudo, M.J. Wertheim’s hypothesis on ‘highway hypnosis’: Empirical evidence from a study on motorway and conventional road driving. Accid. Anal. Prev. 2004, 36, 1045–1054. [Google Scholar] [CrossRef] [PubMed]
- Wertheim, A.H. Explaining highway hypnosis: Experimental evidence for the role of eye movements. Accid. Anal. Prev. 1978, 10, 111–129. [Google Scholar] [CrossRef]
- Herslund, M.B.; Jørgensen, N.O. Looked-but-failed-to-see-errors in traffic. Accid. Anal. Prev. 2003, 35, 885–891. [Google Scholar] [CrossRef]
- Damböck, D.; Weißgerber, T.; Kienle, M.; Bengler, K. Requirements for cooperative vehicle guidance. In Proceedings of the 16th International IEEE Annual Conference on Intelligent Transportation Systems, Hague, The Netherlands, 6–9 October 2013; pp. 1656–1661. [Google Scholar] [CrossRef]
- Goncalves, R.C.; Louw, T.L.; Quaresma, M.; Madigan, R.; Merat, N. The effect of motor control requirements on drivers’ eye-gaze pattern during automated driving. Accid. Anal. Prev. 2020, 148, 105788. [Google Scholar] [CrossRef]
- Louw, T.; Merat, N. Are you in the loop? Using gaze dispersion to understand driver visual attention during vehicle automation. Transp. Res. Part C Emerg. Technol. 2017, 76, 35–50. [Google Scholar] [CrossRef]
- Mackenzie, A.K.; Harris, J.M. Eye movements and hazard perception in active and passive driving. Vis. Cogn. 2015, 23, 736–757. [Google Scholar] [CrossRef] [Green Version]
- Miyajima, C.; Yamazaki, S.; Bando, T.; Hitomi, K.; Terai, H.; Okuda, H.; Hirayama, T.; Egawa, M.; Suzuki, T.; Takeda, K. Analyzing driver gaze behavior and consistency of decision making during automated driving. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium, Seoul, Korea, 28 June 2015; pp. 1293–1298. [Google Scholar] [CrossRef]
- Navarro, J.; Lappi, O.; Osiurak, F.; Hernout, E.; Gabaude, C.; Reynaud, E. Dynamic scan paths investigations under manual and highly automated driving. Sci. Rep. 2021, 11, 3776. [Google Scholar] [CrossRef]
- Lu, Z.; Happee, R.; de Winter, J.C. Take over! A video-clip study measuring attention, situation awareness, and decision-making in the face of an impending hazard. Transp. Res. Part F Traffic Psychol. Behav. 2020, 72, 211–225. [Google Scholar] [CrossRef]
- Gold, C.; Körber, M.; Lechner, D.; Bengler, K. Taking over control from highly automated vehicles in complex traffic situations: The role of traffic density. Hum. Factors 2016, 58, 642–652. [Google Scholar] [CrossRef] [PubMed]
- Yarbus, A.J. Eye Movements and Vision; Plenum Press: New York, NY, USA, 1967. [Google Scholar]
- Borji, A.; Itti, L. Defending Yarbus: Eye movements reveal observers’ task. J. Vis. 2014, 14, 29. [Google Scholar] [CrossRef]
- DeAngelus, M.; Pelz, J.B. Top-down control of eye movements: Yarbus revisited. Vis. Cogn. 2009, 17, 790–811. [Google Scholar] [CrossRef]
- Greene, M.R.; Liu, T.; Wolfe, J.M. Reconsidering Yarbus: A failure to predict observers’ task from eye movement patterns. Vis. Res. 2012, 62, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Tatler, B.W.; Wade, N.J.; Kwan, H.; Findlay, J.M.; Velichkovsky, B.M. Yarbus, eye movements, and vision. i-Perception 2010, 1, 7–27. [Google Scholar] [CrossRef] [Green Version]
- Pomarjanschi, L.; Dorr, M.; Rasche, C.; Barth, E. Safer driving with gaze guidance. In Bio-Inspired Models of Network, Information, and Computing Systems; Suzuki, J., Nakano, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 581–586. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef] [PubMed]
- Large, D.R.; Crundall, E.; Burnett, G.; Harvey, C.; Konstantopoulos, P. Driving without wings: The effect of different digital mirror locations on the visual behaviour, performance and opinions of drivers. Appl. Ergon. 2016, 55, 138–148. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- sbairagy-MW. Pretrained-Deeplabv3plus. 2021. Available online: https://github.com/matlab-deep-learning/pretrained-deeplabv3plus (accessed on 1 May 2022).
- Wickens, C.D.; McCarley, J.S. Visual attention control, scanning, and information sampling. In Applied Attention Theory; CRC Press: Boca Raton, FL, USA, 2008; pp. 41–61. [Google Scholar]
- Lappi, O. Gaze strategies in driving–An ecological approach. Front. Psychol. 2022, 13, 821440. [Google Scholar] [CrossRef] [PubMed]
- Kandil, F.I.; Rotter, A.; Lappe, M. Driving is smoother and more stable when using the tangent point. J. Vis. 2009, 9, 11. [Google Scholar] [CrossRef]
- Land, M.F.; Lee, D.N. Where we look when we steer. Nature 1994, 369, 742–744. [Google Scholar] [CrossRef]
- Wann, J.P.; Swapp, D.K. Why you should look where you are going. Nat. Neurosci. 2000, 3, 647–648. [Google Scholar] [CrossRef]
- Wilkie, R.M.; Kountouriotis, G.K.; Merat, N.; Wann, J.P. Using vision to control locomotion: Looking where you want to go. Exp. Brain Res. 2010, 204, 539–547. [Google Scholar] [CrossRef]
- Deng, T.; Yang, K.; Li, Y.; Yan, H. Where does the driver look? Top-down-based saliency detection in a traffic driving environment. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2051–2062. [Google Scholar] [CrossRef]
- Palazzi, A.; Abati, D.; Solera, F.; Cucchiara, R. Predicting the driver’s focus of attention: The DR (eye) VE project. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1720–1733. [Google Scholar] [CrossRef] [Green Version]
- Lethaus, F.; Rataj, J. Do eye movements reflect driving manoeuvres? IET Intell. Transp. Syst. 2007, 1, 199–204. [Google Scholar] [CrossRef]
- Martin, S.; Trivedi, M.M. Gaze fixations and dynamics for behavior modeling and prediction of on-road driving maneuvers. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium, Los Angeles, CA, USA, 11–14 June 2017; pp. 1541–1545. [Google Scholar] [CrossRef]
- Abbasi, J.A.; Mullins, D.; Ringelstein, N.; Reilhac, P.; Jones, E.; Glavin, M. An analysis of driver gaze behaviour at roundabouts. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]
- Ahlstrom, C.; Kircher, K. Changes in glance behaviour when using a visual eco-driving system–A field study. Appl. Ergon. 2017, 58, 414–423. [Google Scholar] [CrossRef]
- Lehtonen, E.; Malhotra, N.; Starkey, N.J.; Charlton, S.G. Speedometer monitoring when driving with a speed warning system. Eur. Transp. Res. Rev. 2020, 12, 16. [Google Scholar] [CrossRef]
- Morando, A.; Victor, T.; Dozza, M. Drivers anticipate lead-vehicle conflicts during automated longitudinal control: Sensory cues capture driver attention and promote appropriate and timely responses. Accid. Anal. Prev. 2016, 97, 206–219. [Google Scholar] [CrossRef] [Green Version]
- Louw, T.; Kuo, J.; Romano, R.; Radhakrishnan, V.; Lenné, M.G.; Merat, N. Engaging in NDRTs affects drivers’ responses and glance patterns after silent automation failures. Transp. Res. Part F Traffic Psychol. Behav. 2019, 62, 870–882. [Google Scholar] [CrossRef]
- Petermeijer, S.M.; Cieler, S.; De Winter, J.C.F. Comparing spatially static and dynamic vibrotactile take-over requests in the driver seat. Accid. Anal. Prev. 2017, 99, 218–227. [Google Scholar] [CrossRef]
- Goncalves, R.C.; Louw, T.L.; Madigan, R.; Quaresma, M.; Romano, R.; Merat, N. The effect of information from dash-based human-machine interfaces on drivers’ gaze patterns and lane-change manoeuvres after conditionally automated driving. Accid. Anal. Prev. 2022, 174, 106726. [Google Scholar] [CrossRef]
- Kircher, K.; Ahlstrom, C. Evaluation of methods for the assessment of attention while driving. Accid. Anal. Prev. 2018, 114, 40–47. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.E.; Klauer, S.G.; Olsen, E.C.; Simons-Morton, B.G.; Dingus, T.A.; Ramsey, D.J.; Ouimet, M.C. Detection of road hazards by novice teen and experienced adult drivers. Transp. Res. Rec. 2008, 2078, 26–32. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Senders, J.W. Visual Sampling Processes. Ph.D. Thesis, Catholic University, Tilburg, The Netherlands, 1983. [Google Scholar]
- Eisma, Y.B.; Cabrall, C.D.D.; De Winter, J.C.F. Visual sampling processes revisited: Replicating and extending Senders (1983) using modern eye-tracking equipment. IEEE Trans. Hum. Mach. Syst. 2018, 48, 526–540. [Google Scholar] [CrossRef] [Green Version]
- Horrey, W.J.; Wickens, C.D.; Consalus, K.P. Modeling drivers’ visual attention allocation while interacting with in-vehicle technologies. J. Exp. Psychol. Appl. 2006, 12, 67–78. [Google Scholar] [CrossRef]
- Bos, A.J.; Ruscio, D.; Cassavaugh, N.D.; Lach, J.; Gunaratne, P.; Backs, R.W. Comparison of novice and experienced drivers using the SEEV model to predict attention allocation at intersections during simulated driving. In Proceedings of the Eighth International Driving Symposium on Human Factors in Driver Assessment, Training and Vehicle Design, Salt Lake City, UT, USA, 22–25 June 2015; pp. 120–126. [Google Scholar]
- Cassavaugh, N.D.; Bos, A.; McDonald, C.; Gunaratne, P.; Backs, R.W. Assessment of the SEEV model to predict attention allocation at intersections during simulated driving. In Proceedings of the Seventh International Driving Symposium on Human Factors in Driver Assessment, Training and Vehicle Design, Bolton Landing, NY, USA, 17–20 June 2013; pp. 334–340. [Google Scholar]
- Steelman-Allen, K.S.; McCarley, J.S.; Wickens, C.; Sebok, A.; Bzostek, J. N-SEEV: A computational model of attention and noticing. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, San Antonio, TX, USA, 19–23 October 2009; Volume 53, pp. 774–778. [Google Scholar] [CrossRef]
- Wickens, C.D.; Helleberg, J.; Goh, J.; Xu, X.; Horrey, W.J. Pilot Task Management: Testing an Attentional Expected Value Model of Visual Scanning; Technical Report No. ARL-01-14/NASA-01-7; Aviation Research Lab, Institute of Aviation: Savoy, IL, USA, 2001. [Google Scholar]
- Wickens, C.D.; Sebok, A.; Bagnall, T.; Kamienski, J. Modeling of situation awareness supported by advanced flight deck displays. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Baltimore, MD, USA, 1–5 October 2007; Volume 51, pp. 794–798. [Google Scholar] [CrossRef]
- Wortelen, B.; Lüdtke, A.; Baumann, M. Simulating attention distribution of a driver model: How to relate expectancy and task value? In Proceedings of the 12th International Conference on Cognitive Modeling, Ottawa, ON, Canada, 11–14 July 2013. [Google Scholar]
- Kotseruba, I.; Tsotsos, J.K. Behavioral research and practical models of drivers’ attention. arXiv 2021, arXiv:2104.05677. [Google Scholar]
- Wolfe, B.; Dobres, J.; Rosenholtz, R.; Reimer, B. More than the useful field: Considering peripheral vision in driving. Appl. Ergon. 2017, 65, 316–325. [Google Scholar] [CrossRef]
- Strasburger, H. Seven myths on crowding and peripheral vision. i-Perception 2020, 11, 1–45. [Google Scholar] [CrossRef]
- Bickerdt, J.; Wendland, H.; Geisler, D.; Sonnenberg, J.; Kasneci, E. Beyond the tracked line of sight—Evaluation of the peripheral usable field of view in a simulator setting. J. Eye Mov. Res. 2021, 12. [Google Scholar] [CrossRef]
- Fridman, L.; Lee, J.; Reimer, B.; Victor, T. ‘Owl’ and ‘Lizard’: Patterns of head pose and eye pose in driver gaze classification. IET Comput. Vis. 2016, 10, 308–314. [Google Scholar] [CrossRef] [Green Version]
- Scialfa, C.T.; Deschênes, M.C.; Ference, J.; Boone, J.; Horswill, M.S.; Wetton, M. A hazard perception test for novice drivers. Accid. Anal. Prev. 2011, 43, 204–208. [Google Scholar] [CrossRef]
- Vlakveld, W.P. A comparative study of two desktop hazard perception tasks suitable for mass testing in which scores are not based on response latencies. Transp. Res. Part F Traffic Psychol. Behav. 2014, 22, 218–231. [Google Scholar] [CrossRef]
- Hughes, P.K.; Cole, B.L. What attracts attention when driving? Ergonomics 1986, 29, 377–391. [Google Scholar] [CrossRef] [PubMed]
- Salthouse, T.A. When does age-related cognitive decline begin? Neurobiol. Aging 2009, 30, 507–514. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wai, J.; Lubinski, D.; Benbow, C.P. Spatial ability for STEM domains: Aligning over 50 years of cumulative psychological knowledge solidifies its importance. J. Educ. Psychol. 2009, 101, 817–835. [Google Scholar] [CrossRef]
- Fridman, L.; Langhans, P.; Lee, J.; Reimer, B. Driver gaze region estimation without use of eye movement. IEEE Intell. Syst. 2016, 31, 49–56. [Google Scholar] [CrossRef]
- Ahlstrom, C.; Kircher, K.; Kircher, A. A gaze-based driver distraction warning system and its effect on visual behavior. IEEE Trans. Intell. Transp. Syst. 2013, 14, 965–973. [Google Scholar] [CrossRef]
- Schmidt, E.A.; Hoffmann, H.; Krautscheid, R.; Bierbach, M.; Frey, A.; Gail, J.; Lotz-Keens, C. Camera-monitor systems as a replacement for exterior mirrors in cars and trucks. In Handbook of Camera Monitor Systems; Terzis, A., Ed.; Springer: Cham, Switzerland, 2016; pp. 369–435. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Number | Task | Windshield (% of Time) | Left Mirror (% of Time) | Right Mirror (% of Time) | Dashboard (% of Time) |
|---|---|---|---|---|---|
| 1 | Baseline | 67 | 10 | 8 | 15 |
| 2 | Baseline | 65 | 17 | 5 | 14 |
| 3 | Baseline | 68 | 11 | 8 | 13 |
| 1 | Speed Task | 50 | 8 | 5 | 37 |
| 2 | Speed Task | 43 | 12 | 3 | 43 |
| 3 | Speed Task | 46 | 8 | 5 | 42 |
| 1 | Hazard Task | 67 | 13 | 8 | 11 |
| 2 | Hazard Task | 62 | 21 | 5 | 12 |
| 3 | Hazard Task | 72 | 13 | 8 | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eisma, Y.B.; Eijssen, D.J.; de Winter, J.C.F. What Attracts the Driver’s Eye? Attention as a Function of Task and Events. Information 2022, 13, 333. https://doi.org/10.3390/info13070333
Eisma YB, Eijssen DJ, de Winter JCF. What Attracts the Driver’s Eye? Attention as a Function of Task and Events. Information. 2022; 13(7):333. https://doi.org/10.3390/info13070333
Chicago/Turabian StyleEisma, Yke Bauke, Dirk J. Eijssen, and Joost C. F. de Winter. 2022. "What Attracts the Driver’s Eye? Attention as a Function of Task and Events" Information 13, no. 7: 333. https://doi.org/10.3390/info13070333
APA StyleEisma, Y. B., Eijssen, D. J., & de Winter, J. C. F. (2022). What Attracts the Driver’s Eye? Attention as a Function of Task and Events. Information, 13(7), 333. https://doi.org/10.3390/info13070333