

Spot Welding Parameter Tuning for Weld Defect Prevention in Automotive Production Lines: An ML-Based Approach



Abstract
:1. Introduction
2. Background
3. Methodology
3.1. Welding Process Parameters and Data Explanation
- (a)
- Concerning the welding current, the basic principle of spot resistance welding refers to providing a large enough current in a sufficient time from the point to be welded. A small electrical current may cause a point not to melt adequately and thus to not be welded, while a large current can cause melting at the welding point and explosions or electrode distortions. The current continuously increases until expulsion is formed between the metal sheets. When determining the current to be used, the current temporal changes should be taken into account, and a gradual increase in current is preferred [23].
- (b)
- Resistance welding processes are utilized to combine metals and contain spot welding and seam welding, where resistance is a factor characteristic associated with the material between the weld surfaces, with dynamic interaction with other parameters such as current and force [24].
- (c)
- Welding time is a directly proportional variable to heat generation. Generally, the theoretical minimum current and time required for welding are insufficient to weld materials due to various losses; thus, the determination of weld time is one of the most challenging stages in the welding process [6]. As the welding time is related to the welding point requirements, it is not easy to provide exact values for optimum welding [25].
- (d)
- The surface coating protects the material from corrosion or other reactions; however, it makes the welding of the resistance more difficult and facilitates ordinarily tricky processes in which separate electrode and welding parameter settings exist for each coating type [26].
- (e)
- Electrode force compresses the metal sheets to be joined. If the welding quality is low, a large electrode force is required, causing other problems [6]. There is an inverse relationship between heat energy and electrode force, meaning that higher electrode strength requires a higher welding current [23].
- (f)
- Holding time refers to the time for which the electrodes are applied to cool the source after welding (the welding ingot must solidify, making the cooling time necessary before releasing the welded parts). A long hold time and a higher proportion of carbon content elements may result in the weld becoming brittle [23].
- (g)
- Welding voltage is a parameter developed together with the heat development formula and determines the phase mode of the welding process without significantly affecting the heat [27].
3.2. Predicting the Expulsion in the Welding Process Outputs of Automotive Production Line
3.2.1. Variable Setting and Feature Selection
- ID: The values which are assigned for each row.
- Çapak (Expulsion): “Çapak” is actually a dependent variable which was to be related throughout the project. In each observation, the categories of expulsion or not expulsion categories were assigned. Being assigned to the “expulsion” class meant that an observation was a problematic observation. By using this model, we aimed to make predictions and analyses on this variable (“Çapak”) by using independent variables which had high explanation power over the dependent variables. The categories were entirely assigned by the robot. The categorization of the robot was controlled, concluding with the 100% correct prediction rate of the robot. The “Çapak” class was assigned to the observations if a sudden change in resistance was seen, as can be seen in Figure 5, which was taken from the robot education document.
- Timer: The name of robot that was used for the analysis.
- Date/Time: The exact time that the operation was carried out.
- Program: One of the categorical variables in which each program referred to a different point where the welding occurred, meaning that each program represented a different category. The difference between programs varied depending on factors such as where the welding occurred, the thickness of the material, and the type of material, such as aluminum.
- Spot: Each different spot type actually corresponds to each program type which has one spot number. Spot is also one of the categorical variables, like “program”.
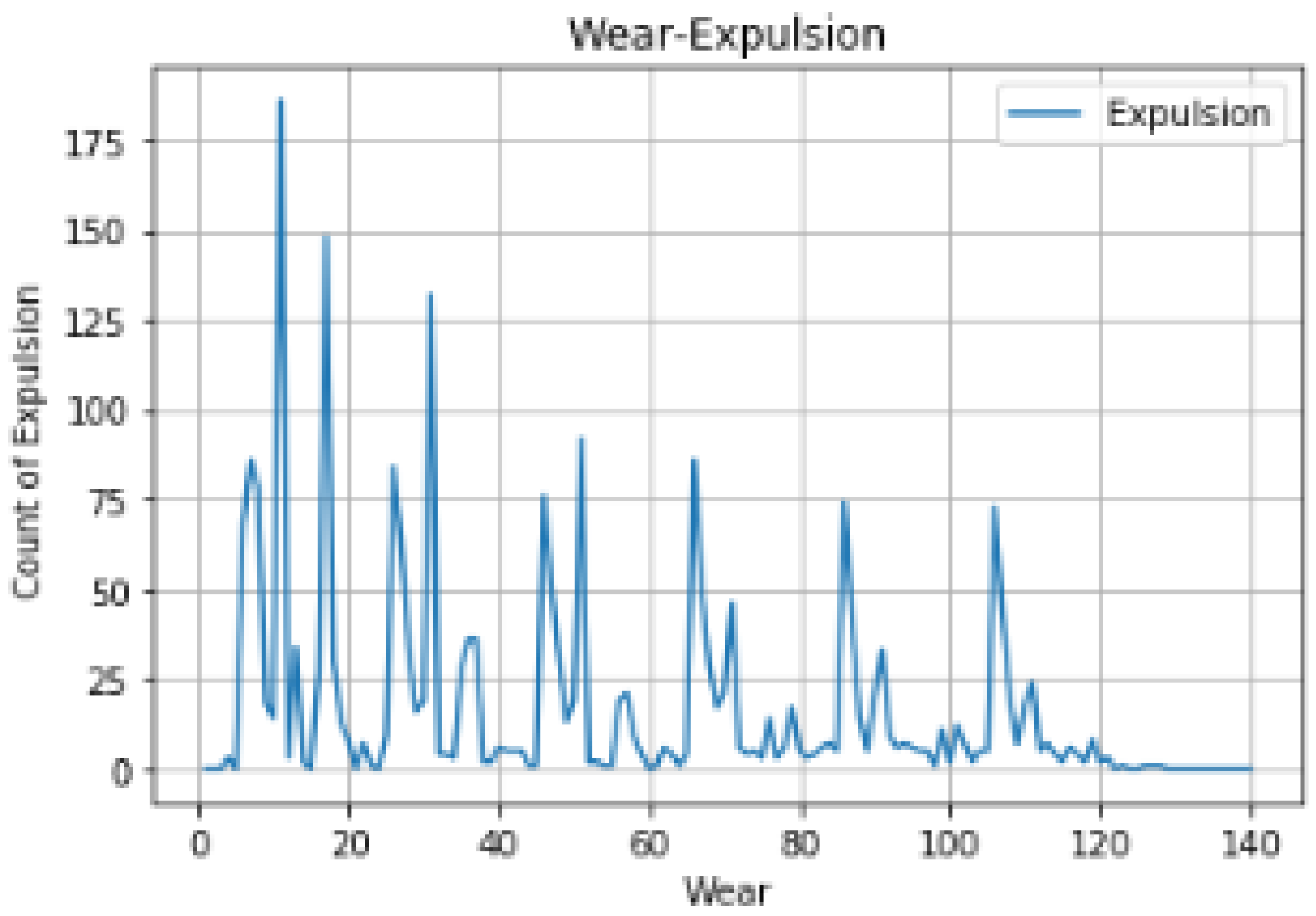
- Wear: In which order the spot welding is observed in each cycle. In time, the wear variable increases as it indicates the number of point shots that the welding made in that cycle.
- Actual Voltage (Act. Volt.): The amount of voltage the robot provides during the welding period for each observation unit. This is a parameter developed together with the heat development formula and does not have a significant effect on heat.
- Reference voltage (Ref. Volt.): Decided through previous studies, the reference voltage value actually indicates the optimum voltage value for each observation, aiming to complete the process without encountering any spatter problems. These reference values are given to the robot to work with during the process.
- Actual current (Act. Curr.): The amount of current the robot provides for the duration of the welding for each observation unit. If a welding current is excessive, cracks may occur due to difficulties in the flow of the current from the electrodes to the material.
- Reference current (Ref. Curr.): Decided through previous studies, the reference current value actually indicates the optimum current value for each observation, aiming to complete the process without encountering any expulsion-related problems. These values are also given to the robot to work with during the process.
- Actual welding time (Act. Weld time): The duration of the welding process for each observation. Heat production is directly proportional to the welding time. Determining the welding time is one of the most difficult stages of the welding process.
- Reference weld time (Ref. Weld Time): Decided through previous studies, this value actually indicates the optimum current value for each observation. The aim is to complete the process without encountering any expulsion-related problems. These values are also given to the robot to work with during the process.
- Actual energy (Act. Energy): The amount of energy given during the process for each observation. This value is taken from the welding robot with formulations based on other variables.
- Reference energy (Ref. Energy): Decided through previous studies, the reference energy value actually indicates the optimum current value for each observation. The aim is to complete the process without encountering any expulsion-related problems. These values are calculated using the formulations, and the energy values are dependent on the other variables.
- Actual heat (Act. Heat.): These heat values are given for each observation while welding is carried out, aiming to bring these values as close to the optimum as possible.
- Reference heat (Ref. Heat): Determined by the previous experiments, the reference heat value actually indicates the optimum current value for each observation. The aim is to complete the process without encountering any expulsion-related problems.
- Actual resistance (Act. Res.): The resistance force that occurs when the electrodes join together and perform the welding process. There is also a formulation connection between actual resistance values and actual volt values.
- Reference resistance (Ref. Res.): Determined by the previous experiments, the reference resistance value actually indicates the optimum current value for each observation. The aim is to complete the process without encountering any spatter-related problems.
3.2.2. Data Preparation and Selection for ML Application
3.2.3. ML Application: Models Selection and Findings
4. Results
4.1. Logistic Regression
4.2. Support Vector Machine (SVM) Model
- Here, x1 and x2 are data points, ‖x1 − x2‖ denotes the Euclidean distance, and ɣ (gamma) is a parameter that controls the Gaussian width kernel.
- When building the SVM algorithm, important parameter optimization is carried out to increase the success of the model. The best parameter values, which can be seen below, are the values that are decided before the SVM model is created.
- {‘c’: 10, ‘gamma’: 5, ‘kernel’: ‘rbf’}.
- The confusion matrix for the SVM model is shown in Table 10. The recall rate was found to be 0.42, and the F1 score was 0.57 for the SVM model, with a precision rate of 0.86. Depending on the precision and recall values of Expulsion = 1, it was observed that the model success did not reach the desired level, which may have caused quality-related problems.
4.3. GBM Algorithms
- {‘learning_rate’: 0.2,
- ‘max_depth’: 5,
- ‘min_samples_split’: 2,
- ‘n_estimators’: 500}
4.4. Decision Tree Model and Random Forest Model
- {‘min_samples_split’: 3,
- ‘n_estimators’: 200}
4.5. XG Boost
- {‘eval_metric’: ‘auc’,
- ‘learning_rate’: 0.5,
- ‘max_depth’: 5,
- ‘min_samples_split’: 2,
- ‘n_estimators’: 500,
- ‘reg’: ‘logistic’}
4.6. Evaluation of the Results from All Models
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Escobar, C.; Morales-Menendez, R. Machine learning techniques for quality control in high conformance manufacturing environment. Adv. Mech. Eng. 2018, 10, 1687814018755519. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.; Sheng, B.; Luo, R.; Jia, P. A parallel strategy for predicting the quality of welded joints in automotive bodies based on machine learning. J. Manuf. Syst. 2022, 62, 636–649. [Google Scholar] [CrossRef]
- Romero-Hdz, J.; Saha, B.; Toledo-Ramirez, G.; Beltran-Bqz, D. Welding Sequence Optimization Using Artificial Intelligence Techniques, an Overview. Int. J. Comput. Sci. Eng. 2016, 3, 90–95. [Google Scholar] [CrossRef] [Green Version]
- Restecka, M.; Wolniak, R. IT systems in aid of welding processes quality management in the automotive industry. Arch. Metall. Mater. 2016, 61, 1785–1792. [Google Scholar] [CrossRef] [Green Version]
- Asif, K.; Zhang, L.; Derrible, S.; Indacochea, J.E.; Ozevin, D.; Ziebart, B. Machine learning model to predict welding quality using air-coupled acoustic emission and weld inputs. J. Intell. Manuf. 2020, 33, 881–895. [Google Scholar] [CrossRef]
- Hwang, I.; Kanga, M.; Kima, D. Expulsion Reduction in Resistance Spot Welding by Controlling of welding Current Waveform. Procedia Eng. 2011, 10, 2777–2880. [Google Scholar] [CrossRef] [Green Version]
- Gujre, S.; Anand, R. Machine learning algorithms for failure prediction and yield improvement during electric resistance welded tube manufacturing. J. Exp. Theor. Artif. Intell. 2019, 32, 601–622. [Google Scholar] [CrossRef]
- Gyasi, E.A.; Handroos, H.; Kah, P. Survey on artificial intelligence (AI) applied in welding: A future scenario of the influence of AI on technological, economic, educational and social changes. Procedia Manuf. 2019, 38, 702–714. [Google Scholar] [CrossRef]
- Maarif, M.R.; Listyanda, R.F.; Kang, Y.-S.; Syafrudin, M. Artificial Neural Network Training Using Structural Learning with Forgetting for Parameter Analysis of Injection Molding Quality Prediction. Information 2022, 13, 488. [Google Scholar] [CrossRef]
- Haapalainen, E.; Laurinen, P.; Junno, H.; Tuovinen, L.; Roning, J. Feature Selection For Identification of Spot Welding Processes. In Informatics in Control Automation and Robotics; Lecture Notes Electrical Engineering; Cetto, J.A., Ferrier, J.L., Costa dias Pereira, J., Filipe, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 15. [Google Scholar] [CrossRef]
- Chokkalingham, S.; Chandrasekhar, N.; Vasudevan, M. Predicting the depth of penetration and weld bead width from the infrared thermal image of the weld pool using artificial neural network modelling. J. Intell. Manuf. 2012, 23, 1995–2001. [Google Scholar] [CrossRef]
- Sumesh, A.; Rahmeshkumar, K.; Mohandas, K.; Shyam, R. Use of Machine Learning Algorithms for Weld Quality Monitoring using Acoustic Signature. In Proceedings of the 2nd International Symposium on Big Data and Cloud Computing (ISBCC’15), Coimbatorei, India, 12–13 March 2015. [Google Scholar]
- Khumaidi, A.; Yuniarno, M.E.; Purnomo, H.M. Welding defect classification based on convolution neural network (CNN) and Gaussian kernel. In Proceedings of the International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 28–29 August 2017. [Google Scholar] [CrossRef]
- Selvi, V.K.; Aravindar, D.J. An Industrial Inspection Approach for Weld Defects Using Machine Learning Algorithm. Int. J. Adv. Signal Image Sci. 2019, 5, 15–21. [Google Scholar]
- Ayvaz, S.; Alpay, K. Predictive Maintenance System for Production Lines in Manufacturing: A Machine Learning Approach Using Iot Data in Real-Time. Expert Syst. Appl. 2020, 173, 114598. [Google Scholar] [CrossRef]
- Rahmatov, N.; Paul, A.; Saeed, F.; Hong, W.; Seo, H.; Kim, J. Machine Learning–Based Automated Image Processing for Quality Management in Industrial Internet of Things. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719883551. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.J.; Wu, H.; Yun, H.; Kim, H.; Jun, M.B.; Sutherland, J.W. Predictive Maintenance of Machine Tool Systems Using Artificial Intelligence Techniques Applied to Machine Condition Data. In Proceedings of the 26th CIRP Life Cycle Engineering (LCE) Conference, West Lafayette, IN, USA, 7–9 May 2019. [Google Scholar] [CrossRef]
- Wuest, T.; Irgens, C.; Thoben, K.D. An approach to monitoring quality in manufacturing using supervised machine learning on product state data. J. Intell. Manuf. 2014, 25, 1167–1180. [Google Scholar] [CrossRef]
- Chen, S.; Wu, N.; Xiao, J.; Li, T.; Lu, Z. Expulsion Identification in Resistance Spot Welding by Electrode Force Sensing Based on Wavelet Decomposition with Multi-Indexes and BP Neural Networks. Appl. Sci. 2019, 9, 4028. [Google Scholar] [CrossRef] [Green Version]
- Pereverzev, A.E.; Ivanova, I.V.; Maestro, A.; Zarubind, I.A.; Panfaye, W. The use of artificial intelligence to control the processes of welding and direct arc growth under the influence of disturbing factors. IOP Conf. Ser. Mater. Sci. Eng. 2019, 666, 012013. [Google Scholar] [CrossRef]
- Afroz, A.S.; Digiacomo, F.; Pelliccia, R.; Inglese, F.; Stefanini, C.; Milazzo, M. Optimization of a wearable speed monitoring device for welding applications. Int. J. Adv. Manuf. Technol. 2020, 110, 1285–1293. [Google Scholar] [CrossRef]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-based defect detection and classification approaches for industrial applications—A survey. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef]
- Raut, M.; Achwal, V. Optimization of Spot Welding Process Parameters for Maximum Tensile Strength. Int. J. Mech. Eng. Robot. Res. 2014, 3, 506–517. [Google Scholar]
- Hashmi, S. Comprehensive Materials Processing, 1st ed.; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Mikno, Z.; Pilarczyk, A.; Korzeniowski, M.; Kustron, P.l.; Ambroziak, A. Analysis of resistance welding processes and expulsion of liquid metal from the weld nugget. Arch. Civ. Mech. Eng. 2018, 18, 522–531. [Google Scholar] [CrossRef]
- Wan, X.; Wang, Y.; Fang, C. Welding Defects Occurrence and Their Effects on Weld Quality in Resistance Spot Welding of AHSS Steel. ISIJ Int. 2014, 54, 1883–1889. [Google Scholar] [CrossRef] [Green Version]
- Sedani, C.; Gawai, B. Optimization of Process Parameters for Resistance Spot Welding Process of HR E-34 Using Response Surface Method. Int. J. Sci. Res. 2016, 3, 2002–2008. [Google Scholar]
- Aidun, D.K.; Bennett, R.W. Effect of resistance welding variables on the strength of spot welded 6061-T6 aluminum alloy. Weld. J. 1985, 64, 15–22. [Google Scholar]
- Dai, H.; Wang, L.; Dong, B.; Miao, J.; Lin, S.; Chen, S. Microstructure and high-temperature mechanical properties of new-type heat-resisting aluminum alloy Al6.5Cu2Ni0.5Zr0.3Ti0.25V under the T7 condition. Mater. Lett. 2023, 332, 133503. [Google Scholar] [CrossRef]
- Reitermanovȃ, Z. Data Splitting. In Proceedings of the 19th Annual Conference of Doctoral Students, Prague, Czech Republic, 1–4 June 2010. [Google Scholar]
- McLoone, S.; Pampuri, S.; Schirru, A.; Susto, G. Machine Learning for Predictive Maintenance: A Multiple Classifier Approach. IEEE Trans. Ind. Inform. 2015, 11, 812–820. [Google Scholar] [CrossRef] [Green Version]
- Moisen, G.G. Classification and regression trees. In Encyclopedia of Ecology; Jorgensen, E.S., Fath, B.D., Eds.; Elsevier: Oxford, UK, 2008; Volume 1, pp. 582–588. [Google Scholar]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists; O’Reilly: Beijing, China, 2017. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R; Springer Texts in Statistics; Springer Science and Business Media: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Wang, C.; Deng, C.; Wang, S. Imbalance-XGBoost: Leveraging Weighted and Focal Losses for Binary Label-Imbalanced Classification with XGBoost. Pattern Recognit. Lett. 2019, 136, 190–197. [Google Scholar] [CrossRef]
- Zhang, L. Machine Learning in Rock Facies Classification: An Application of XGBoost. In Proceedings of the International Geophysical Conference, Qingdao, China, 17–20 April 2017; pp. 1371–1374. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Problem Definition | Approach to Solve Problem | Limitation | Result |
|---|---|---|---|---|
| Haapalainen et al. (2006) [10] | Reducing welding feature dimension space and selection of welding parameters | Detecting similarity between observations with KNN algorithm | Detection of outlier observations | Improvement in spot welding process identification system |
| Chokkalingham et al. (2012) [11] | Predicting the depth of penetration and weld bead width from the infrared thermal image of the weld pool | Using artificial neural network modeling | Manipulation of numeric data | Predicting bead width and depth of penetration with good accuracy |
| Sumesh et al. (2015) [12] | Studying the root cause of weld defects | Extracting features from sound signals and using them as input in the classification algorithm | Data governance | Using arc sound for effective signature in weld quality monitoring |
| Wuest et al. (2014) [18] | Clustering undesired product states, increasing product quality in the production line | VM for classification and Agglomerative Cluster Analysis | Desired accuracy via VM | |
| Khumaidi et al. (2017) [13] | Examining the welding defect types through image processing and automation of the manual examinations | CNN algorithm to classify defect images | Only one algorithm | Solved the welding defect problem with a multiple classification approach and achieved 95.83% accuracy |
| Escobar et al. (2018) [1] | Welding quality—defective detection problem | L1-regularized logistic regression learning algorithm and pattern recognition method | - | 100% accuracy in detecting defective products |
| Gujre & Anand, (2019) [7] | Predicting weak-weld-quality tubes | Using model true negative outputs via intelligent classifier algorithm | Model adaptivity | Finding safe operating ranges |
| Lee et al. (2019) [17] | Determining cutting tools’ correct replacement time in the production line. | SVM algorithm | Only observed the maintenance times | SVM could precisely predict the correct replacement time |
| Chen et al. (2019) [19] | Improving defect detection accuracy | Backpropagation (BP) feature of neural networks | Only NNs applied | Improved defect detection accuracy |
| Pereverzev et al. (2019) [20] | The quality of welded joints and process performance | Artificial intelligence to arc welding processes and direct arc growth under disruptive conditions. | The welding process’s non-linearity and time-varying nature challenged a clear mathematical relationship between system’s input and output parameters | Intelligent control algorithms on the quality of welded joints and process performance. Nature of welding process required various approaches |
| Selvi et al. (2019) [14] | Reduction in welding defects with image classification by selecting the variables that can distinguish the weld defects most effectively | SURF (Speeded-up Robust Features) method; solving the classification problem with AEC (Auto-Encoder Classifier) | AEC classified the weld images differentiating the number of neurons in hidden layers at a rate of 98 per cent accuracy | |
| Rahmatov et al. (2019) [16] | Detection of the abnormal products through image classification | Machine-learning-based approaches | Obtained 92 % accuracy from the model | |
| Ayvaz et al. (2020) [15] | Detection and prediction of signals of potential failures using real-time data | Tree-based machine learning methods such as XGBoost and Random Forest algorithm | The factory production line efficiency can be increased by telling the operators to take preventive actions | |
| Asif et al. (2020) [5] | Acoustic emission (AE) system designed to cover a wide range of frequencies as a real-time monitoring method for gas metal arc weld defects | Sequence tagging and logistic regression algorithms | Integration among different software systems | Deployment of real-time weld quality monitoring |
| Chen et al. (2022) [2] | To examine the operating status of the welding robot under the current parameter settings and to assess the welding quality of electrode caps under different types of plates in real time with large data sizes | PCA and K-means-based dynamic classification | Proposal of an adaptive parallel machine learning strategy for solder joint quality prediction, relying on noise reduction and classification of the weld process feature value data set |
| Variables | ||||
|---|---|---|---|---|
| Expulsion | Act. Res. | Energy Diff. | Ref. Heat | Spot |
| ac.pr.st | Act. Volt. | Energy Excd. | Ref. Res. | Time Diff. |
| Act. Curr. | Act. Weld Time | Product Type | Ref. Volt. | Time Exclusive |
| Act. Energy | Date/Time | Ref. Curr | Ref. Weld Time | Timer |
| Act. Heat | Date/Time. 1 | Ref. Energy | ref.pr.st | Wear |
| Variables | ||||
|---|---|---|---|---|
| Expulsion | Act. Res. | Energy Diff. | Ref. Heat | Spot |
| ac.pr.st | Act. Volt. | Energy Excd. | Ref. Res. | Time Diff. |
| Act. Curr. | Act. Weld Time | Product Type | Ref. Volt. | Time Exclusive |
| Act. Energy | Date/Time | Ref. Curr | Ref. Weld Time | Timer |
| Act. Heat | Date/Time. 1 | Ref. Energy | ref.pr.st | Wear |
| Count | Mean | std | Min | 25% | 50% | 75% | Max | |
|---|---|---|---|---|---|---|---|---|
| Time Diff | 32,609 | 0.00035 | 0.00059 | −0.004 | 0.000067 | 0.00015 | 0.000433 | 0.005017 |
| Energy Diff | 32,609 | 269.979985 | 323.483262 | −639.5281 | 53.60913 | 177.9087 | 418.9768 | 2585.665 |
| Act. Volt. | 32,609 | 1.218594 | 0.112988 | 0.88 | 1.13 | 1.22 | 1,3 | 1.61 |
| Ref. Volt. | 32,609 | 1.21599 | 0.107169 | 1.04 | 1.1 | 1.2 | 1,3 | 1.56 |
| Act. Curr. | 32,609 | 7.782808 | 0.567765 | 5.96 | 7.42 | 7.84 | 8,14 | 9.62 |
| Ref. Curr. | 32,609 | 7.584849 | 0.421653 | 6.66 | 7.35 | 7.7 | 7,89 | 9 |
| Act. Weld Time | 32,609 | 445.757521 | 77.636114 | 260 | 377 | 450 | 497 | 749 |
| Ref. Weld Time | 32,609 | 424.754914 | 73.38584 | 260 | 370 | 440 | 460 | 700 |
| Act. Energy | 32,609 | 4232.302812 | 691.65053 | 2714.884 | 3811.024 | 4188.688 | 4518.706 | 8230.167 |
| Ref. Energy | 32,609 | 3962.322801 | 654.567956 | 2713.692 | 3584.036 | 3988.157 | 4215.521 | 6559.188 |
| Act. Heat | 32,609 | 9480.890787 | 1095.57221 | 6261.675 | 8887.01 | 9338.058 | 10,201.37 | 14,127.79 |
| Ref. Heat | 32,609 | 9260.637848 | 1038.939809 | 7263.215 | 8627.472 | 9063.936 | 10,314.32 | 12,918.02 |
| Act. Res. | 32,609 | 161.933209 | 17.734518 | 108 | 150 | 165 | 175 | 209 |
| Ref. Res. | 32,609 | 162.574228 | 14.739853 | 132 | 149 | 164 | 176 | 197 |
| Act. Proc. Stab. | 32,609 | 87.541722 | 9.052932 | 44 | 84 | 90 | 94 | 99 |
| Ref. Proc. Stab. | 32,609 | 100 | 0 | 100 | 100 | 100 | 100 | 100 |
| Capak | Timer | Program | Spot | Wear | |
|---|---|---|---|---|---|
| count | 32,609 | 32,609 | 32,609 | 32,609 | 32,609 |
| unique | 2 | 1 | 61 | 61 | 140 |
| top | No Expulsion | UNB0160WB02 | 7 | 11693_00_1 | 1 |
| freq | 30,192 | 32,609 | 2781 | 2781 | 276 |
| Program | Mean Wear | Capak | Program | Mean Wear Expulsion | Program | Capak |
|---|---|---|---|---|---|---|
| 1 | 69.806729 | 0 | 1 | 20 | 1 | 8 |
| 2 | 50.836559 | 1 | 2 | 70.6 | 2 | 5 |
| 3 | 51.829023 | 2 | 3 | 63.428571 | 3 | 14 |
| 4 | 52.857245 | 3 | 4 | 67 | 4 | 15 |
| 7 | 54.302769 | 4 | 7 | 68.416667 | 7 | 36 |
| Act. Volt. | Act. Curr. | Act. Weld Time | Act. Energy | Act. Heat | Act. Res. | |
|---|---|---|---|---|---|---|
| Act. Volt. | 1 | −0.0486259 | −0.284968 | 0.1444119 | 0.798258 | 0.784336 |
| Act. Curr. | −0.0486259 | 1 | −0.441936 | −0.159323 | 0.560379 | −0.5922 |
| Act. Weld time | −0.284968 | −0.441936 | 1 | 0.840589 | −0.494969 | −0.00686755 |
| Act. Energy | 0.1444119 | −0.159323 | 0.840589 | 1 | 0.0292443 | 0.155015 |
| Act. Heat | 0.798258 | 0.560379 | −0.494969 | 0.0292443 | 1 | 0.289094 |
| Act. Res. | 0.784336 | −0.5922 | −0.00686755 | 0.155015 | 0.289094 | 1 |
| Ref. Volt. | Ref. Curr. | Ref. Weld time | Ref. Energy | Ref. Heat | Ref. Res. | |
|---|---|---|---|---|---|---|
| Ref. Volt. | 1 | 0.0584367 | −0.205209 | 0.267899 | 0.870679 | 0.79766 |
| Ref. Curr. | 0.0584367 | 1 | −0.522035 | −0.310667 | 0.516001 | −0.498392 |
| Ref. Weld time | −0.205209 | −0.522035 | 1 | 0.831765 | −0.410598 | 0.0584696 |
| Ref. Energy | 0.267899 | −0.310667 | 0.831765 | 1 | 0.0918778 | 0.319594 |
| Ref. Heat | 0.870679 | 0.516001 | −0.410598 | 0.0918778 | 1 | 0.412025 |
| Ref. Res. | 0.79766 | −0.498392 | 0.0584696 | 0.319594 | 0.412025 | 1 |
| OLS Regression Results | |||||
|---|---|---|---|---|---|
| Dep. Variable: | Capak | R−squared: | 0.309 | ||
| Model: | OLS | Adh. R−squared: | 0.309 | ||
| Method: | Least Squares | F−statistic: | 3404 | ||
| Date: | Monday, 22 Junuary 2020 | Prob (F−statistic): | 0 | ||
| Time: | 23:27:47 | Log−Likelihood: | 2407.8 | ||
| No. Observations: | 22,826 | AIC: | −4808 | ||
| Df Residuals: | 22,822 | BIC: | −4775 | ||
| Df Model: | 3 | ||||
| Covariance Type: | nonrobust | ||||
| coef | std err | t | P > |t| | [0.025, 0.975] | |
| const | 0.0219 | 0.02 | 10.533 | 0 | 0.018, 0.026 |
| Dif.weld time.prop | 2.0697 | 0.024 | 87.28 | 0 | 2.023, 2.116 |
| Dif.Curr.prop | −1.9644 | 0.055 | −35.549 | 0 | −2.073, −1.856 |
| Dif.Res.prop | −0.7303 | 0.026 | −28.25 | 0 | −0.781, −0.680 |
| Omnibus: | 9474.822 | DurbinWatson: | 1.964 | ||
| Prob(Omnibus): | 0 | Jarque–Bera(JB): | 60,064.871 | ||
| Skew: | 1.884 | Prob(JB) | 0 | ||
| Kurtosis: | 9.996 | Cond. No. | 40.1 | ||
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 0.96 | 0.99 | 0.97 | 9058 |
| 1 | 0.86 | 0.42 | 0.57 | 725 |
| accuracy | 0.95 | 9783 | ||
| macro avg | 0.91 | 0.71 | 0.77 | 9783 |
| weightedavg | 0.95 | 0.95 | 0.94 | 9783 |
| SVM References | ||||
| Prediction | FALSE | TRUE | ||
| No Expulsion | 9010 | 48 | ||
| Expulsion | 420 | 35 | ||
| Count of Trainset Observation | 22,826 | |||
| Count of Testset Observation | 9783 | |||
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 0.99 | 1 | 1 | 9058 |
| 1 | 0.97 | 0.93 | 0.95 | 725 |
| accuracy | 0.99 | 9783 | ||
| macro avg | 0.98 | 0.96 | 0.97 | 9783 |
| weightedavg | 0.99 | 0.99 | 0.99 | 9783 |
| GBM References | ||||
| Prediction | No Expulsion | FALSE | TRUE | |
| 9037 | 21 | |||
| Expulsion | 50 | 675 | ||
| Count of Trainset Observation | 22,826 | |||
| Count of Testset Observati on | 9783 | |||
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 0.99 | 0.99 | 0.99 | 9058 |
| 1 | 0.91 | 0.88 | 0.9 | 725 |
| accuracy | 0.98 | 9783 | ||
| macro avg | 0.95 | 0.94 | 0.94 | 9783 |
| weightedavg | 0.98 | 0.98 | 0.98 | 9783 |
| Decision Tree References | ||||
| Prediction | FALSE | TRUE | ||
| No Expulsion | 8992 | 66 | ||
| Expulsion | 84 | 641 | ||
| Count of Trainset Observation | 22,826 | |||
| Count of Testset Observati on | 9783 | |||
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 0.99 | 1 | 0.99 | 9058 |
| 1 | 0.94 | 0.89 | 0.92 | 725 |
| accuracy | 0.99 | 9783 | ||
| macro avg | 0.97 | 0.94 | 0.96 | 9783 |
| weightedavg | 0.99 | 0.99 | 0.99 | 9783 |
| Random Forest | ||||
| References | ||||
| FALSE | TRUE | |||
| No Expulsion | 9017 | 41 | ||
| Expulsion | 77 | 648 | ||
| Count of Trainset Observation | 22,826 | |||
| Count of Testset Observation | 9783 | |||
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 9058 |
| 1 | 1 | 1 | 1 | 725 |
| accuracy | 1 | 9783 | ||
| macro avg | 1 | 1 | 1 | 9783 |
| weightedavg | 1 | 1 | 1 | 9783 |
| XGBoost References | ||||
| FALSE | TRUE | |||
| No Expulsion | 9058 | 0 | ||
| Expulsion | 0 | 725 | ||
| Count of Trainset Observation | 22,826 | |||
| Count of Testset Observati on | 9783 | |||
| Model | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|
| Logistic Regression | 0.65 | 0.30 | 0.41 | 0.94 |
| KNN | 0.86 | 0.79 | 0.83 | 0.98 |
| SVM | 0.86 | 0.42 | 0.57 | 0.95 |
| Decision Tree | 0.91 | 0.88 | 0.90 | 0.98 |
| Random Forest | 0.94 | 0.89 | 0.92 | 0.99 |
| GBM | 0.97 | 0.93 | 0.95 | 0.99 |
| XGBoost | 0.94 | 0.93 | 0.92 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bayır, M.; Yücel, E.; Kaya, T.; Yıldırım, N. Spot Welding Parameter Tuning for Weld Defect Prevention in Automotive Production Lines: An ML-Based Approach. Information 2023, 14, 50. https://doi.org/10.3390/info14010050
Bayır M, Yücel E, Kaya T, Yıldırım N. Spot Welding Parameter Tuning for Weld Defect Prevention in Automotive Production Lines: An ML-Based Approach. Information. 2023; 14(1):50. https://doi.org/10.3390/info14010050
Chicago/Turabian StyleBayır, Musa, Ertuğrul Yücel, Tolga Kaya, and Nihan Yıldırım. 2023. "Spot Welding Parameter Tuning for Weld Defect Prevention in Automotive Production Lines: An ML-Based Approach" Information 14, no. 1: 50. https://doi.org/10.3390/info14010050
APA StyleBayır, M., Yücel, E., Kaya, T., & Yıldırım, N. (2023). Spot Welding Parameter Tuning for Weld Defect Prevention in Automotive Production Lines: An ML-Based Approach. Information, 14(1), 50. https://doi.org/10.3390/info14010050