1. Introduction
In today’s rapidly evolving digital age, social media platforms, particularly X (previously known as Twitter), have become formidable forces in shaping public opinion and influencing electoral outcomes [
1]. The sheer immediacy and virality of X messages have transformed political communication, making it more direct, candid, and often confrontational. But along with its potential for democratizing political discourse, X has inadvertently provided a breeding ground for echo chambers and polarization. Challenges such as the spread of misinformation, the blurring lines between facts and opinions, and the difficulty in discerning genuine sentiments from orchestrated campaigns make this a critical area of study. It is against this backdrop that this research becomes particularly relevant. By understanding these dynamics, the authors of this paper aim to shed light on the interplay between social media discourse and real-world political outcomes, potentially offering insights for future electoral strategies and counter-polarization efforts.
According to Wakefield and Wakefield [
2], social media platforms support the gathering of like-minded users, and polarization in this context occurs when users prefer to interact with like-minded users, which reinforces one group’s prevailing ideas and beliefs, creating so-called echo chambers. Polarization within American politics is intensifying over a wide range of issues. While traditional battles over the size and role of the government remain, sociocultural battles over religious freedom, gun control, immigration, gay marriage and abortion have increased. Polarization is not a new phenomenon, nor is it unique to the American political landscape; however, it is increasingly prevalent in the U.S. context [
3]. X posts also have an impact on other media outlets, as Shapiro and Hemphill [
4] note in their research, where they demonstrated that X is a legitimate political communication platform for elected officials that journalists consider in their media coverage. This approach can amplify media reporting based on X posts reaching far beyond their organic scope within the X platform, where they would otherwise only be shown to followers associated with the X (Twitter) accounts sharing a particular tweet.
In this paper, the focus was on the 2022 United States midterm elections that were held on November 8 with three separate elections—United States Senate elections (shorter: Senate), United States House of Representatives elections (shorter: House) and United States Gubernatorial elections (shorter: Gubernatorial). In the race during the Senate elections, there was a change by one seat in favor of Democrats in Pennsylvania. Out of a total of 435 seats, the Republican Party did take control of the House, earning a slim majority of 222 seats, whereas the Democratic Party took 213 seats. In the race for governors, Democrats picked up three seats—in Arizona, Maryland and Massachusetts—while losing one seat in Nevada [
5]. The vast majority of candidates from the Republican and Democratic Party actively used the X platform to post announcements and to state political views during their campaigns, covering various topics in their political communication to the potential electorate. Tweets from Democratic and Republican candidates that were part of these elections were collected and processed for this research.
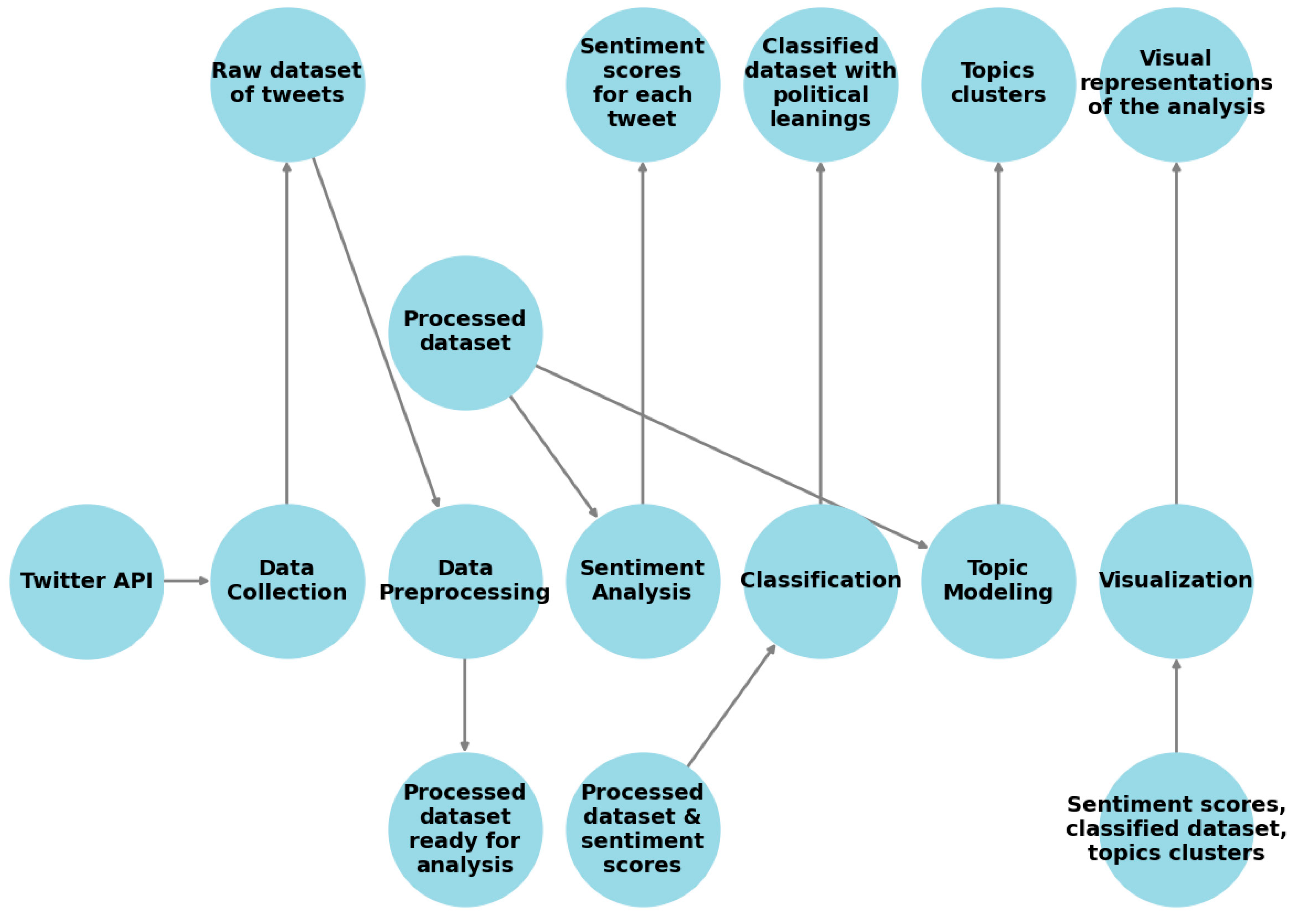
The aim of this research was to detect and identify the polarizing topics on X (formerly known as Twitter) based on a collected dataset, and by using various machine learning (ML) and natural language processing (NLP) techniques, such as topic modeling, sentiment analysis and text classification.
This paper is structured as follows. The introductory section highlights the motivation for this research and provides initial information regarding the 2022 United States elections. Related work that focuses on polarization in politics is presented in
Section 2. This research is discussed in
Section 3, whereas the research methodology is described in
Section 3.1. The process of data collection together with an analysis of the collected tweets is presented in
Section 3.2. Party affiliation classification is explored in
Section 3.3, whereas sentiment analysis for each of the elections is presented and visualized by displaying the states in
Section 3.4. Topic modeling, along with the detection of polarizing topics, is analyzed in
Section 3.5, while elections topics for flipped seats are presented in
Section 3.6. This study’s findings are presented and discussed in detail in
Section 4, and the conclusions are given in
Section 5, along with ideas for future research.
4. Research Results and Discussion
Democrats were more active in all elections with significantly more tweets, 31,272 compared to 21,416. While there was a notable difference in tweet activity between Democrats and Republicans, it is essential to consider the broader socio-political context during the 2022 elections. Factors such as party strategies, key events, and campaign focal points might have influenced the X activity and should be explored further. The biggest difference was observed in the Gubernatorial elections, during which Democrats published 6000 tweets compared to 2852 Republican tweets. The evident disparity in tweet volumes during the Gubernatorial elections prompts questions about campaign strategies. Were Democrats actively leveraging X as a platform to engage with a younger audience, or did Republicans shift their attention to other communication channels? All in all, the elections were slightly positive with an average polarity of 0.16341 and highly subjective with an average score of 0.37944. The sentiment scores provide a snapshot of the prevailing emotions and attitudes during the election cycle. Delving deeper, one can analyze whether external events, policy announcements, or significant campaign milestones influenced these sentiment scores. Classification of tweets based on their content showed that within the Senate and House elections, over 20% of Republican tweets were classified as Democrat tweets, while for the Gubernatorial elections, 6.67% of Democrat tweets were classified as Republican tweets. The classification discrepancies, where a significant portion of Republican tweets were classified as Democrat and vice versa, highlight the complexities of political narratives. This blurring of party lines suggests that topics and narratives, while rooted in party ideology, often transcend party boundaries due to the dynamic nature of the political landscape. The Senate elections showed polarization based on major conflicting topics where Democrats’ call to action for the Senate revolved around topics such as fight, state and help, while Republicans were represented with conservative values, such as work, family and community. Priorities in economy and security for the Senate elections show a wide difference where the economy is the third biggest topic cluster for Republicans, compared to eighth for Democrats, and security is the fifth and seventh largest topic cluster for Democrats and eighth for Republicans. Within the Gubernatorial elections, the main topic clusters of both parties were mostly related to local topics including investments, tax and education. Differences in the Gubernatorial elections were observed for women’s reproductive rights, where Democrats had a greater focus, while Republicans, on the other hand, had a greater focus on the cost of energy. For the House elections, general campaigning topics made up the largest topic cluster with topics such as voter, change, election and win. When observing other topics, there was a sharp divide with the second largest topic cluster for Republicans, which was related to family values (family, home, kid), while for Democrats, the second largest topic cluster was related to community values (gratitude, friendship and sharing). In other topic clusters, Democrats were focused on national security (border, nation and cartel), while Democrats were much more focused on internal problems (policy, healthcare, schools). The authors’ observation of polarized topics illuminates the ever-evolving strategy of political campaigns. The shifting priorities based on regional concerns, national narratives, and global contexts underscore the multifaceted nature of political discourse. Across these interactions, it is evident that while both sides occasionally touched on similar broad topics, their framing, emphasis, and proposed solutions often diverged significantly. The ongoing engagement and counter-engagement in these tweets not only highlight the depth of current party polarization, but also underscore how each side’s narrative is shaped, in part, by its interactions with the other.
Evans et al. [
73], in their research on House candidates on X in the two months before the 2012 elections, also show results that reflect a higher number of tweets for Democrats than Republicans in House elections. Comparing their research to this one, it is observable that in the 10 years after the 2012 elections, the gap has widened significantly, with Democrats publishing 27.62% more tweets in the 2022 House elections compared to just 3.57% in 2012. The high subjectivity that was observed through sentiment analysis in all elections can be attributed, as noted by Just [
74], to people’s political orientations and behavior, which are more strongly shaped by their subjective rather than objective political environment.
5. Conclusions and Future Work
The aim of this paper was to uncover polarizing topics between Democrats and Republicans during their X campaign for the 2022 United States midterm elections. This research was based on 52,688 tweets sent by Republican and Democratic candidates. Using sentiment analysis, classification and topic modeling, the authors presented clear polarizing topics that permeated the elections. The results of the sentiment analysis show that communication during the X campaign was conducted with high subjectivity with an average score of 0.37944 and in a slightly positive way with an average polarity of 0.16341. Democrats displayed greater polarity and subjectivity in the Senate and House elections, while, on the other hand, Republicans showed greater polarity and subjectivity in the Gubernational elections. The Gubernatorial elections were also the elections with the highest subjectivity and polarity compared to other elections. This trend can be observed for the Senate election race between Patty Murray (Democrat) and Tiffany Smiley (Republican) in Washington, which had the highest overlap of subjectivity and polarity in the Senate elections, where the Democratic candidate won the election. For the Gubernatorial election race, the highest overlap of subjectivity and polarity was scored between Kay Ivey (Republican) and Yolanda Flowers (Democrat) in Alabama, where the Republican candidate won the election. For the House elections, there was no overlap of subjectivity and polarity. The highest subjectivity for the House elections was observed between Gabe Vasquez (Democrat) and Yvette Herrell (Republican) in the 2nd congressional district election in New Mexico, where the Democratic candidate won the election. The only place where a general sentiment trend of the corresponding party was not observed was for the House elections, with the highest polarity in Idaho, where the Republican candidates won both seats.
The results of the party classification analysis show that for the Senate and House elections, over 20% of tweets from Republicans were classified as tweets from Democrats. Within the Gubernational elections, there was a slight increase in Republicans tweets, by 6.67%. These results show that within the elections for the Senate and the House, Republicans tend to take over the narrative of Democrats, while in the Gubernational elections, Democrats take over statements from Republicans. Adopting the opposing party’s narrative reflects the competitive nature of elections and the constant efforts of parties to position themselves favorably in the eyes of voters.
The results of topic modeling show that, for each election, Democrats and Republicans focused their priorities on different topics, which, combined with high subjectivity, can create an election environment conducive to polarization. Within the Senate elections, the biggest topics for Republicans were local topics related to family and community, while for Democrats, the most important topics were related to a call to action related to fight and help. The largest Gubernatorial topics were related to the state (local) level, with major difference between Democrats, who were focused on investment, while Republicans were focused on leadership. Within the House elections, the largest topics for both Democrats and Republicans were related to general topics of voting and elections, while other topics such as national security were more of a focus for Democrats, while Republicans focused more on community topics.
The topics of the Senate elections that flipped Pennsylvania to Democrats were related to community values, as opposed to the Republican candidate, who was more focused on the cost of living. The Gubernatorial election topics in Maryland, which switched to the Democratic side, were related to general campaigning (Democrats) and family values (Republicans). For Massachusetts, the flip to Democrats in the Gubernatorial elections showed a focus on the economy (Democrats) and personal finances (Republicans). Topics of the House elections in New York’s 3rd congressional district, where a flip was observed, showed that the Republicans focused on topics related to the cost of living, while the Democrats were more focused on community values. The swing to Democrats in the House elections was observed in Ohio’s 1st congressional district, where the Democrats focused on general campaigning topics, while the Republicans focused on the cost of living.
High subjectivity was observed for all elections where polarizing topics were created. Topics such as elections, the cost of living, jobs, gas, future, etc., are used by candidates as a platform to promote their agenda and to create a polarized voting bloc based on these topics. This trend has been particularly evident with the questioning of the legitimacy of the 2020 presidential election in the Alabama Gubernatorial election race. Fears of potential job losses by transitioning to renewable energy were also used as a polarizing topic for the House election in New Mexico. Party lines are blurred in all three elections, with each party taking over the narrative for the other, and this is especially evident on the Republican side, where a significant number of tweets were classified as Democratic within the Senate and House elections. Topics that have been part of the campaign and their prioritization show a deep entrenchment within the political dialog in the U.S., where common topics are rare, and when they occur, they tend to have a vastly different priority during campaigning.
On the basis of this work, it is possible to apply the methodology of this research to previous U.S. elections, as well as to future U.S. elections, so that polarizing topics can be observed over a longer period of time. Time series for sentiment analysis and party classification, as well as for emerging and trending topics, can be plotted for each day leading up to election day to show campaign dynamics. Future research could, for instance, explore other social platforms and not just X because some of the candidates did not have an X account or were not active on X during the 2022 United States elections. Transcribing the political video advertising of each candidate, as well as those of their respective party, should also be considered. Such research could contribute to a better understanding of candidates’ topics and communication due to potentially longer messages, as these are limited to 280 characters on X.
In light of the advancements with multi-level granulation embeddings for text information extraction [
75], further research could explore the integration of deep learning models to enhance extraction precision. Exploring its scalability and efficacy in areas with vast textual content, like social media platforms, might uncover new potential uses. Further studies are needed to find polarizing topics from historical data based on previous elections to establish causal relationships over a longer time span.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}