
Weakly Supervised Learning Approach for Implicit Aspect Extraction †


Abstract
:1. Introduction
- S1
- The battery of the phone lasts many hours, so it does not need to charge frequently.
- S2
- I don’t use it anymore, as I get tired of always recharging after using just for a few hours.
- We propose a novel weakly supervised method to construct a dataset automatically labeled with implicit aspects. To the best of our knowledge, no prior work has been performed on the automatic construction of such a dataset.
- We train a model for implicit aspect extraction by fine-tuning a pre-trained language model using the above dataset coupled with existing review sentences including explicit aspects.
- We empirically evaluate the constructed dataset as well as the performance of implicit aspect extraction achieved by our proposed model.
2. Related Work
2.1. Implicit Aspect Extraction
2.2. Dataset of Implicit Aspects
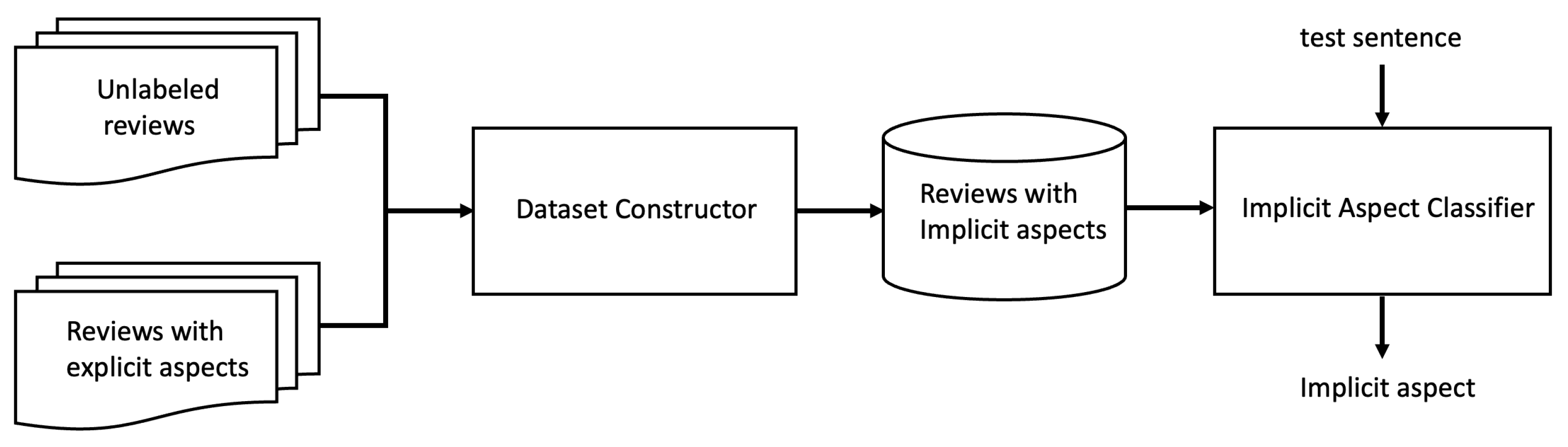
3. Proposed Method
3.1. Overview
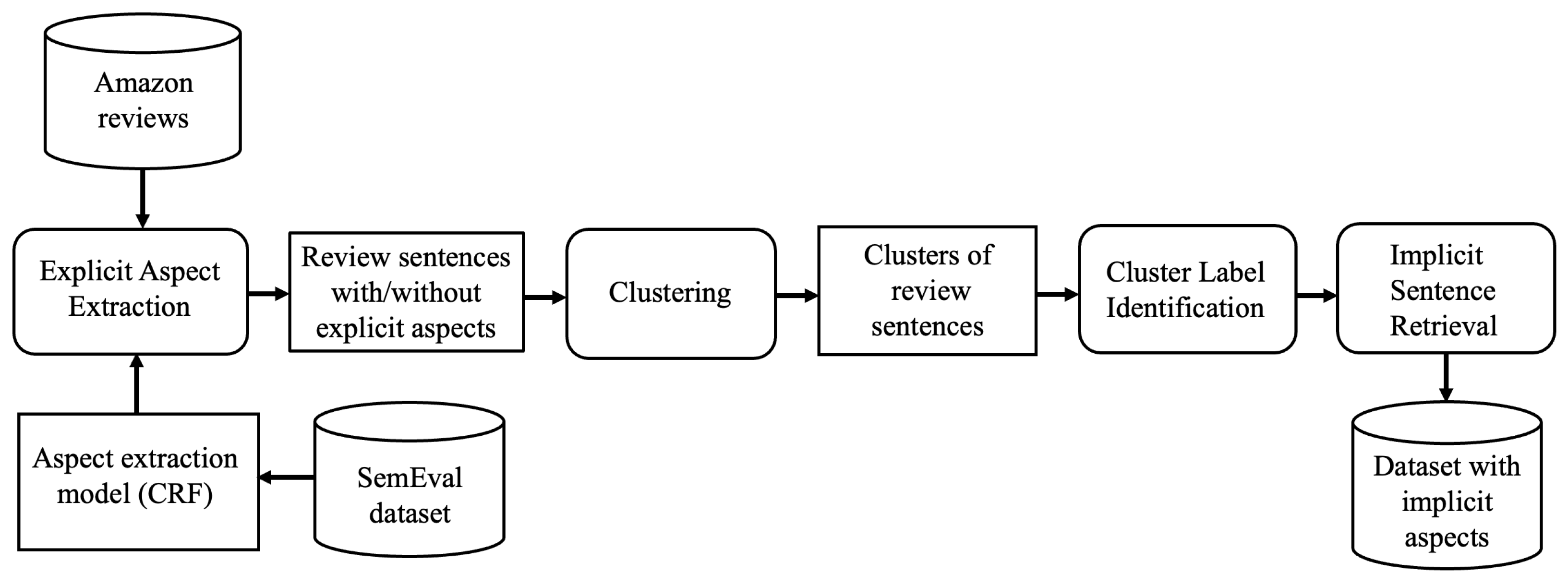
3.2. Construction of Dataset Annotated with Implicit Aspects
3.2.1. Explicit Aspect Extraction
3.2.2. Clustering
3.2.3. Cluster Label Identification
| Algorithm 1: Algorithm for cluster label identification |
 |
3.2.4. Implicit Sentence Retrieval
3.3. Implicit Aspect Classification Using BERT
4. Evaluation
4.1. Evaluation of Dataset Annotated with Implicit Aspects
4.1.1. Experimental Setup of the Construction of the Dataset
4.1.2. Results of Constructing the Dataset
4.1.3. Error Analysis
4.2. Evaluation of Implicit Aspect Classification
4.2.1. Experimental Setup of Implicit Aspect Classification
- A set of review sentences with explicit aspects. This was made from the SemEval-2014 dataset as described in Section 3.3.
- A set of review sentences with implicit aspects. This was constructed using our proposed method as described in Section 3.2.
- A set of both sentences with explicit and implicit aspects.
4.2.2. Results of Implicit Aspect Classification
5. Conclusions
- Currently, our method supposes that there is only one implicit aspect in a sentence. It is necessary to extend our method of constructing the dataset as well as implicit aspect classification to handle sentences including multiple implicit aspects. One of the possible solutions is as follows. Instead of a hard clustering, a soft clustering could be applied to allow a sentence to belong to multiple clusters. This would enable us to add multiple implicit aspects for one sentence in the dataset. Then, we could train the model for multi-class classification that could identify multiple implicit aspects in one sentence.
- The explicit aspects were automatically extracted, but some of them may have been incorrect. On the other hand, the sentences including the explicit aspects can be obtained from the existing dataset for ABSA. These sentences can be mixed with unlabeled sentences for the clustering. Such an approach may improve the performance of the clustering.
- More appropriate clustering algorithms other than k-means should be investigated.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Full List of Synonyms

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Synonyms for Soft-Matching with Cluster Label | Synonyms for Soft-Matching with Explicit Aspect |
|---|---|---|
| Battery | battery case, battery life, battery percentages, battery access, battery pack, battery charge, battery charger, charger, blackberry charger brand, blackberry charger, USB charger, USB adapter, cord, USB cord, USB port, USB ports, USB plugs, car charger, USB cable, USB cables, Samsung car charger, quality charger, power, power port, power loss, power light | battery life, charger, cord, usb port, usb ports, power, power light |
| Case | case quality, case cover | case design |
| Look | design, color | design, designed, color |
| Price | — | price tag, price range, cost, costing, priced, costed, shipping, budget, value |
| Screen | screen protector, screen protectors, screen cover, screen look, precut screen protectors | screen resolutions, screen resolution, 18.4 screen, screen graphics, looking, service center, seventeen inch screen, 17 inch screen, 17-inch screen, 17 ince screen, 17 inch screen, resolution of the screen, screen brightness, display, monitor, surface, stock screen, screen size, acer screen, lcd, lcd screen, screen hinges, picture quality, resolution on the screen |
| Size | — | size, sized |
| Aspect | Synonyms for SM 1 with Cluster Label | Synonyms for Soft-Matching with Explicit Aspect |
|---|---|---|
| Interface | keyboard, touchpad, touch pad, keyboard flex | keyboard, touchpad, touch pad, keyboard flex, Keyboard, KEYBOARD, touch pad, keys, mouse, trackpad, left mouse key, key bindings, 10-key, regular layout keyboard, right click key, touch-pad, mouse keys, island backlit keyboard, multi-touch mouse, multi-touch track pad, Apple keyboard, mouse on the pad, left button, shift key, mouse pointer, flatline keyboard |
| OS | windows xp home edition, windows media player, windows xp, windows xp pro, windows convert, operating system, os | windows xp home edition, windows media player, windows xp, windows xp pro, windows convert, operating system, os, Windows 7, operating system, operating systems, XP, Vista, Windows applications, Windows Vista, key pad, Mac OS, antivirus software, Windows XP SP2, Windows 7 Ultimate, OSX 16, Windows 7 Starter, Windows 7 Home Premium, Windows 7 Professional, Windows operating system, Windows operating systems, Windows update, Windows XP drivers, Window update, Windows, Windows Vista Home Premium, Win 7 |
| Price | — | price tag, price range, cost, costing, priced, costed, shipping, budget, value |
| Screen | monitor, screen size, screen real estate, screen flickers, screen distortion | monitor, screen size, screen real estate, screen flickers, screen distortion, screen resolutions, screen resolution, screen dispaly, 18.4 screen, screen graphics, looking, service center, seventeen inch screen, 17 inch screen, 17-inch screen, 17 ince screen, Screen size, resolution of the screen, screen brightness, 30 HD Monitor, display, Resolution, display, surface, stock screen, Acer screen, 17 inch screen, LCD, screen hinges, picture quality, resolution on the screen |
| Software | programs, program, isoftware, applications, software kit, software problem, itools software | programs, program, isoftware, applications, software kit, software problem, itools software, MS Applications, suite of software, system, Microsoft office for the mac, preloaded software, Microsoft office, software packages, trackpad, Software, antivirus software, Microsoft Word for Mac, MS Office, MS Office apps, Dreamweaver, Final Cut Pro 7, Photoshop, Safari, Firefox, MSN Messenger, Apple applications, music software, Office Mac applications, Word, Excel, software options, Sony Sonic Stage software, Garmin GPS software, Microsoft Office 2003, powerpoint, iMovie, iWork, Internet Explorer |
References
- Pang, B.; Lee, L. Opinion mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and Summarizing Customer Reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- Tubishat, M.; Idris, N.; Abushariah, M.A. Implicit Aspect Extraction in Sentiment Analysis: Review, Taxonomy, Oppportunities, and Open Challenges. Inf. Process. Manag. 2018, 54, 545–563. [Google Scholar] [CrossRef]
- Rana, T.A.; Cheah, Y.N. Aspect Extraction in Sentiment Analysis: Comparative Analysis and Survey. Artif. Intell. Rev. 2016, 46, 459–483. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, W. Extracting Implicit Features in Online Customer Reviews for Opinion Mining. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 103–104. [Google Scholar]
- Cai, H.; Xia, R.; Yu, J. Aspect-Category-Opinion-Sentiment Quadruple Extraction with Implicit Aspects and Opinions. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual, 1–6 August 2021; pp. 340–350. [Google Scholar]
- Hai, Z.; Chang, K.; Kim, J.j. Implicit Feature Identification via Co-occurrence Association Rule Mining. In Proceedings of the Computational Linguistics and Intelligent Text Processing, Tokyo, Japan, 20–26 February 2011; Gelbukh, A.F., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 393–404. [Google Scholar]
- Zeng, L.; Li, F. A Classification-Based Approach for Implicit Feature Identification. In Proceedings of the Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data, Suzhou, China, 10–12 October 2013; Sun, M., Zhang, M., Lin, D., Wang, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 190–202. [Google Scholar]
- Sun, L.; Li, S.; Li, J.; Lv, J. A Novel Context-based Implicit Feature Extracting Method. In Proceedings of the 2014 International Conference on Data Science and Advanced Analytics (DSAA), Shanghai, China, 30 October–1 November 2014; pp. 420–424. [Google Scholar] [CrossRef]
- Bagheri, A.; Saraee, M.; de Jong, F. Care More about Customers: Unsupervised Domain-independent Aspect Detection for Sentiment Analysis of Customer Reviews. Knowl.-Based Syst. 2013, 52, 201–213. [Google Scholar] [CrossRef]
- Hendriyana; Huda, A.F.; Baizal, Z.A. Feature Extraction Amazon Customer Review to Determine Topic on Smartphone Domain. In Proceedings of the 13th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 20–21 October 2021; pp. 342–347. [Google Scholar] [CrossRef]
- Schouten, K.; Frasincar, F. Finding Implicit Features in Consumer Reviews for Sentiment Analysis. In Proceedings of the 14th International Conference on Web Engineering, Toulouse, France, 1–4 July 2014; Springer: Cham, Switzerland, 2014; pp. 130–144. [Google Scholar]
- Saeidi, M.; Bouchard, G.; Liakata, M.; Riedel, S. SentiHood: Targeted Aspect Based Sentiment Analysis Dataset for Urban Neighbourhoods. In Proceedings of the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 1546–1556. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 27–35. [Google Scholar] [CrossRef]
- Cruz, I.; Gelbukh, A.; Sidorov, G. Implicit Aspect Indicator Extraction for Aspect Based Opinion Mining. Int. J. Comput. Linguist. Appl. 2014, 5, 135–152. [Google Scholar]
- Tan, K.L.; Lee, C.P.; Lim, K.M. A survey of Sentiment Analysis: Approaches, Datasets, and Future Research. Appl. Sci. 2023, 13, 4550. [Google Scholar] [CrossRef]
- Giannakopoulos, A.; Antognini, D.; Musat, C.; Hossmann, A.; Baeriswyl, M. Dataset Construction via Attention for Aspect Term Extraction with Distant Supervision. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 373–380. [Google Scholar]
- Hadano, M.; Shimada, K.; Endo, T. Aspect Identification of Sentiment Sentences using a Clustering Algorithm. Procedia-Soc. Behav. Sci. 2011, 27, 22–31. [Google Scholar] [CrossRef]
- Rubtsova, Y.; Koshelnikov, S. Aspect Extraction from Reviews Using Conditional Random Fields. In Proceedings of the Knowledge Engineering and Semantic Web, Moscow, Russia, 30 September–2 October 2015; Klinov, P., Mouromtsev, D., Eds.; Springer: Cham, Switzerland, 2015; pp. 158–167. [Google Scholar]
- Mekala, D.; Gupta, V.; Paranjape, B.; Karnick, H. SCDV: Sparse Composite Document Vectors using Soft Clustering over Distributional Representations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 659–669. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- He, R.; McAuley, J. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]




| Product Type | Category of Implicit Aspect |
|---|---|
| Mobile phone | Battery, case, look, price, screen, size |
| PC | Interface, OS, price, screen, software |
| Review Sentence | Aspect |
|---|---|
| It does n’t click with the white piece at all, and it easily slides off | none |
| I wanted so much to keep this case on, but I also did n’t wan na risk my phone having a giant crack on the screen due to a case that does n’t stay on | screen |
| Or the price, it is neat, but I really doubt I ’m going to keep it on my phone | price |
| What a bummer | none |
| It is cute and light weight | none |
| (a) Phone domain | |
| Aspect | Synonym |
| Battery | battery case, battery life, power |
| Case | case quality, case cover |
| Look | design, color |
| Price | — |
| Screen | screen protector, screen cover |
| Size | — |
| (b) PC domain | |
| Aspect | Synonym |
| Interface | keyboard, touchpad |
| OS | windows, windows xp |
| Price | — |
| Screen | monitor, screen size |
| Software | program, applications |
| Aspect | # of Cluster | Average Size of Cluster | # of Explicit Sentences | # of Implicit Sentences | Accuracy | |
|---|---|---|---|---|---|---|
| Battery | 58 | 12 ± 16 | 274 | 393 | 0.82 | 0.1 |
| Case | 23 | 8.6 ± 5.5 | 104 | 94 | 0.74 | 0.1 |
| Look | 62 | 11 ± 9.2 | 303 | 353 | 0.58 | 0.1 |
| Price | 89 | 11 ± 10 | 751 | 252 | 0.78 | 0.4 |
| Screen | 31 | 8.7 ± 11 | 179 | 90 | 0.76 | 0.2 |
| Size | 27 | 8.4 ± 6.2 | 121 | 106 | 0.70 | 0.1 |
| Aspect | # of Clusters | Average size of Cluster | # of Explicit Sentences | # of Implicit Sentences | Accuracy | |
|---|---|---|---|---|---|---|
| Interface | 24 | 9.0 ± 5.4 | 117 | 100 | 0.62 | 0.1 |
| OS | 25 | 12 ± 9.0 | 145 | 163 | 0.72 | 0.1 |
| Price | 15 | 8.6 ± 5.8 | 84 | 45 | 0.56 | 0.3 |
| Screen | 44 | 11 ± 7.5 | 228 | 261 | 0.70 | 0.1 |
| Software | 41 | 10 ± 7.0 | 147 | 250 | 0.64 | 0.1 |
| (a) Phone domain | ||||
| Aspect | Dataset | Test Data | ||
| Battery | 106 | 363 | 469 | 30 |
| Case | 4 | 64 | 68 | 30 |
| Look | 21 | 323 | 344 | 30 |
| Screen | 93 | 80 | 173 | 10 |
| Size | 21 | 96 | 117 | 10 |
| Price | 82 | 222 | 304 | 30 |
| Total | 327 | 1148 | 1475 | 140 |
| (b) PC domain | ||||
| Aspect | Dataset | Test Data | ||
| Interface | 83 | 70 | 153 | 30 |
| OS | 45 | 133 | 178 | 30 |
| Price | 83 | 35 | 118 | 10 |
| Screen | 88 | 231 | 319 | 30 |
| Software | 104 | 220 | 324 | 30 |
| Total | 403 | 689 | 1092 | 130 |
| Domain | Phone | PC | ||||
|---|---|---|---|---|---|---|
| Dataset | ||||||
| Batch size | 8 | 8 | 8 | 8 | 8 | 8 |
| Learning rate | 3e | 5e | 4e | 4e | 5e | 5e |
| Number of epochs | 20 | 30 | 35 | 5 | 35 | 50 |
| Aspect | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | P | R | F | |
| Battery | 0.68 | 0.90 | 0.77 | 0.96 | 0.87 | 0.91 | 0.91 | 0.97 | 0.94 |
| Case | 0.38 | 0.30 | 0.33 | 0.79 | 0.50 | 0.61 | 0.82 | 0.47 | 0.60 |
| Look | 0.68 | 0.57 | 0.62 | 0.65 | 0.80 | 0.72 | 0.74 | 0.87 | 0.80 |
| Price | 0.92 | 0.80 | 0.86 | 0.94 | 0.97 | 0.95 | 0.94 | 0.97 | 0.95 |
| Screen | 0.39 | 0.70 | 0.50 | 0.89 | 0.80 | 0.84 | 0.62 | 0.80 | 0.70 |
| Size | 0.43 | 0.30 | 0.35 | 0.53 | 0.90 | 0.67 | 0.75 | 0.90 | 0.82 |
| Macro avg. | 0.58 | 0.59 | 0.57 | 0.79 | 0.81 | 0.78 | 0.80 | 0.83 | 0.80 |
| Accuracy | 0.62 | 0.79 | 0.82 | ||||||
| Aspect | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | P | R | F | |
| Interface | 0.95 | 0.60 | 0.73 | 1.00 | 0.67 | 0.80 | 0.83 | 0.83 | 0.83 |
| OS | 0.82 | 0.30 | 0.44 | 0.89 | 0.83 | 0.86 | 0.93 | 0.83 | 0.88 |
| Price | 0.67 | 0.40 | 0.50 | 0.86 | 0.60 | 0.71 | 0.86 | 0.60 | 0.71 |
| Screen | 0.73 | 0.80 | 0.76 | 0.89 | 0.80 | 0.84 | 0.90 | 0.90 | 0.90 |
| Software | 0.39 | 0.80 | 0.53 | 0.52 | 0.83 | 0.64 | 0.72 | 0.87 | 0.79 |
| Macro avg. | 0.71 | 0.58 | 0.59 | 0.83 | 0.75 | 0.77 | 0.85 | 0.81 | 0.82 |
| Accuracy | 0.61 | 0.77 | 0.84 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mar, A.A.; Shirai, K.; Kertkeidkachorn, N. Weakly Supervised Learning Approach for Implicit Aspect Extraction. Information 2023, 14, 612. https://doi.org/10.3390/info14110612
Mar AA, Shirai K, Kertkeidkachorn N. Weakly Supervised Learning Approach for Implicit Aspect Extraction. Information. 2023; 14(11):612. https://doi.org/10.3390/info14110612
Chicago/Turabian StyleMar, Aye Aye, Kiyoaki Shirai, and Natthawut Kertkeidkachorn. 2023. "Weakly Supervised Learning Approach for Implicit Aspect Extraction" Information 14, no. 11: 612. https://doi.org/10.3390/info14110612
APA StyleMar, A. A., Shirai, K., & Kertkeidkachorn, N. (2023). Weakly Supervised Learning Approach for Implicit Aspect Extraction. Information, 14(11), 612. https://doi.org/10.3390/info14110612