
The Effect of the Ransomware Dataset Age on the Detection Accuracy of Machine Learning Models


Abstract
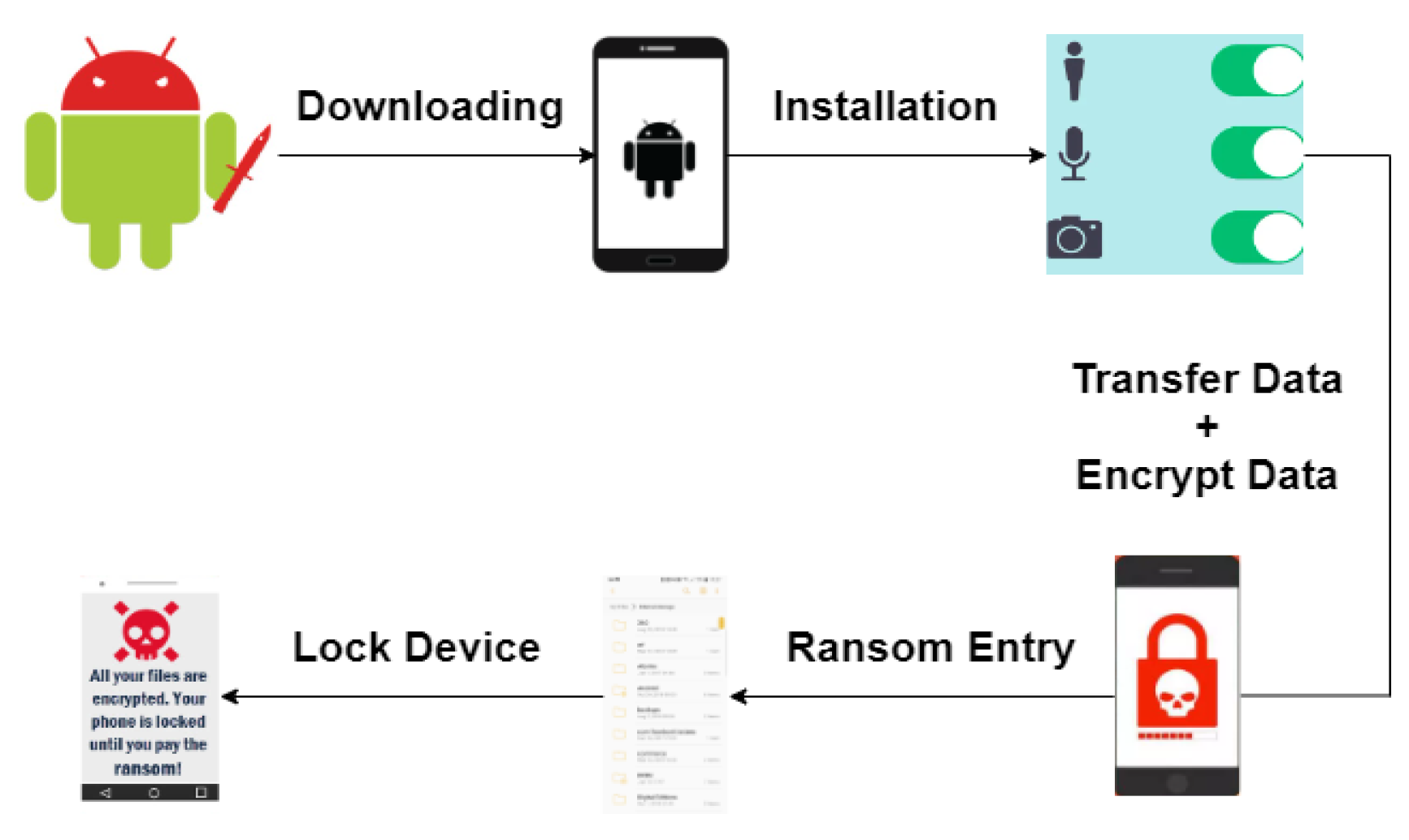
:1. Introduction
- The paper evaluates the efficiency of features extracted from old ransomware applications in detecting new ransomware applications.
- The paper evaluates the efficiency of features extracted from new ransomware applications in detecting old ransomware applications.
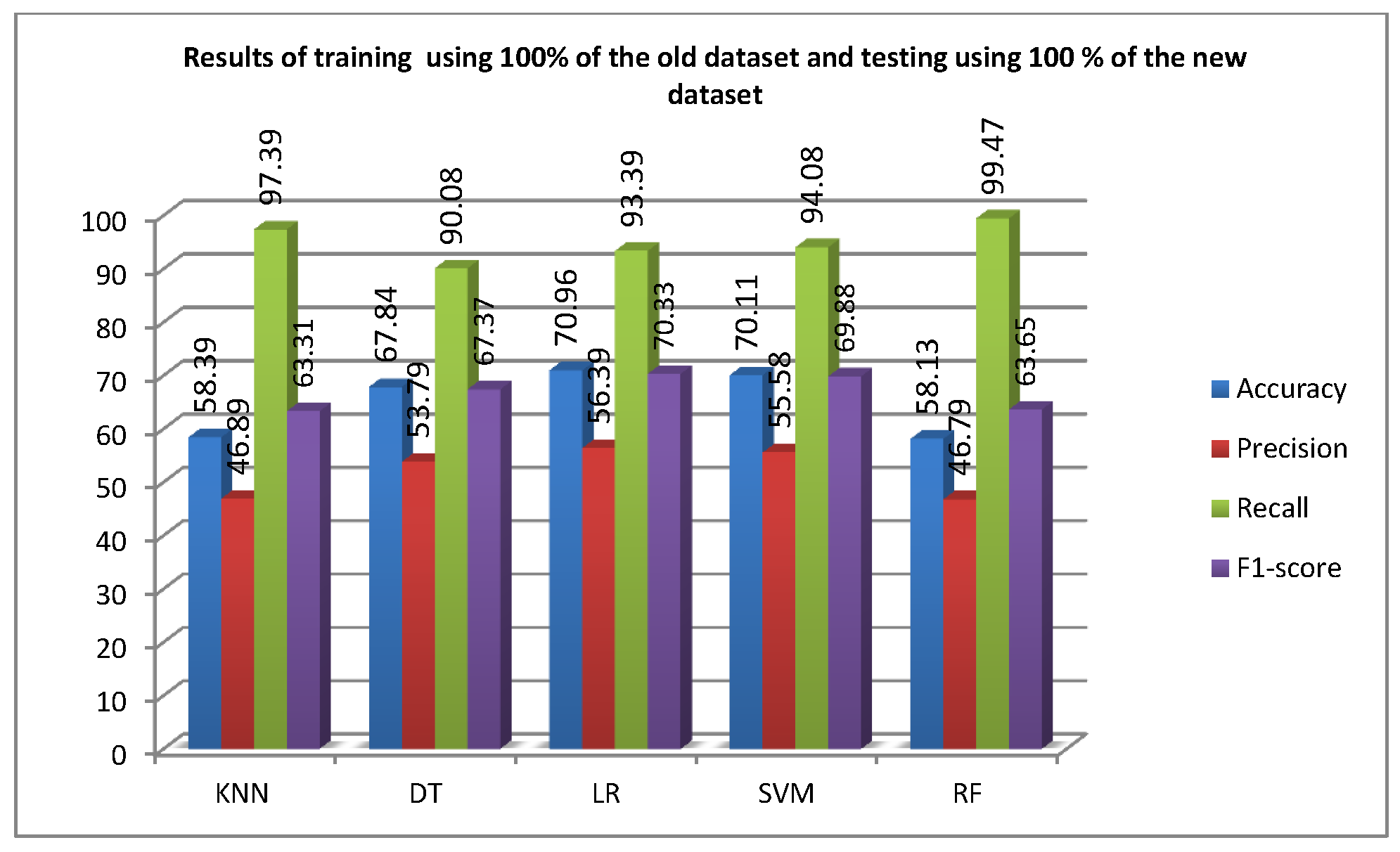
- The paper proves that supervised machine learning classifiers only trained by the old ransomware dataset is not effective in detecting new ransomware. Moreover, the paper proves that supervised machine learning classifiers trained by the new ransomware dataset only is not effective in detecting old Android ransomware.
- The paper creates a balanced and mixed dataset of old and new ransomware to effectively train supervised machine learning classifiers.
- The paper proposes a permission-based Android ransomware detection model that can detect the ransomware applications of different ages. It used the top most supervised machine learning models, which are SVM, decision tree (DT), logistic regression (LG), K-near neighbor (K-NN) and random forest (RF) [19]. Moreover, it shows how the proposed model outperforms the state-of-the-art approaches in detecting Android ransomware applications.
2. Related Work
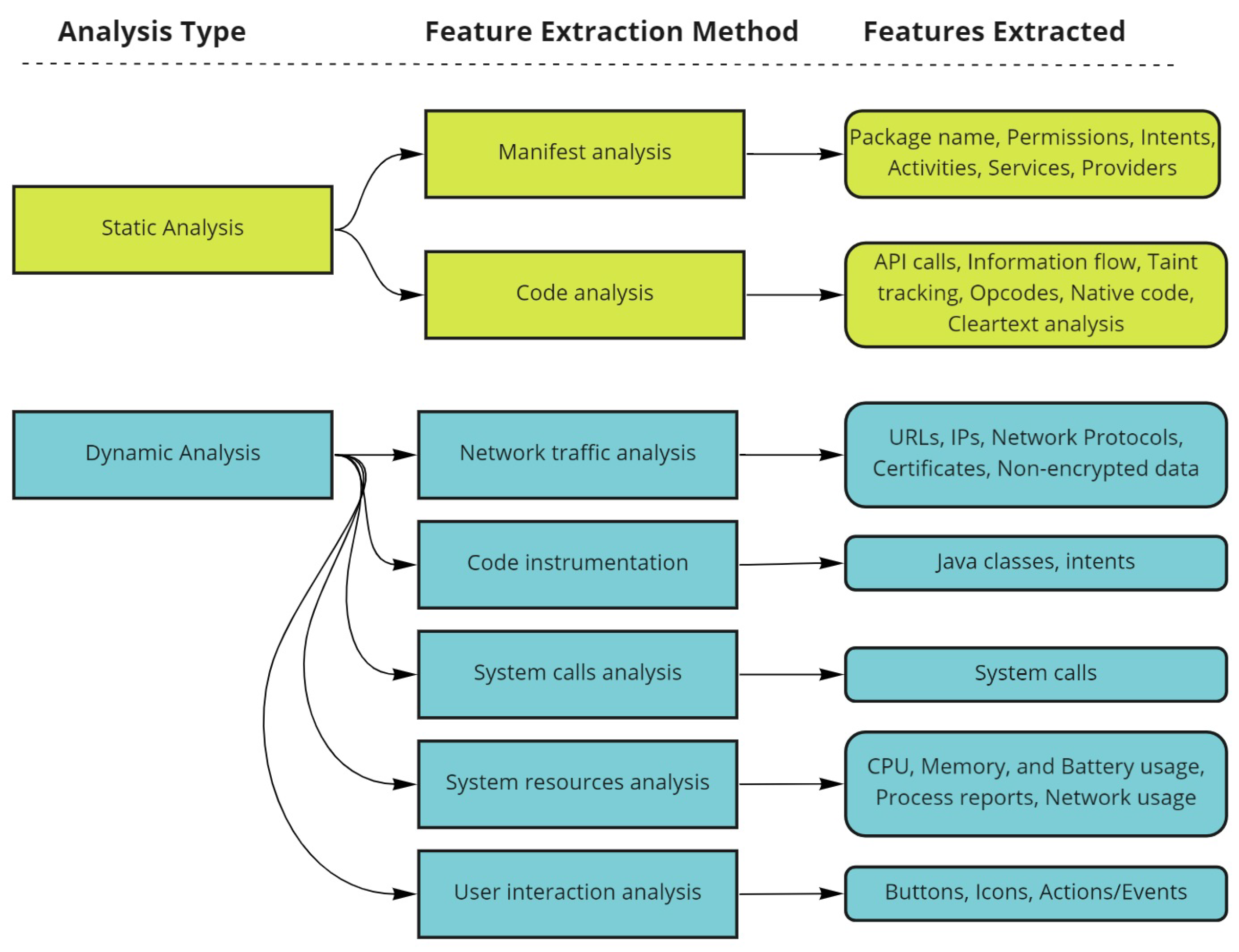
2.1. Static Analysis
2.2. Dynamic Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Year | Analysis | Feature(s) | Dataset(s) | Algorithms | Accuracy | Ransomware Dataset Age |
|---|---|---|---|---|---|---|---|
| Gaur et al. [27] | 2021 | Static | Structural features such as imported dlls, opcode | Virusshare [18] | KNN, SVM, RF, DBSCAN, and neural networks | 99.68% | Virusshare: Unknown |
| Alsoghyer and Almomani [24] | 2019 | Static | API calls and their frequencies | VirusTotal [28], RProber [29], and Koodous [30] | NB, DT, SMO, and RF | 97% | RProper:HelDroid 2010–2014, HelDroid: collected 2010–2014, VirusTotal: Submitted 2017–2018, Koodous: Unknown |
| Su et al. [31] | 2019 | Static | Text, system operations, admin operations, permissions | Ransomware-transaction QQ groups [33] | LR, SVM, RF, and DT | 99.98% | Ransomware-transaction QQ groups: Collected 2019 |
| Kim et al. [39] | 2019 | Static | API calls, Permissions, opcodes, and environment | Malgenome [40] VirusShare [18] | SVM, RF, and multimodal deep learning | 98% | Malgenome: 2010–2011, VirusShare: unknown |
| Scalas et al. [26] | 2019 | Static | API calls, classes, and methods | VirusTotal [28] and HelDroid [23] | RF | 97% | VirusTotal:Unknown, HelDroid 2010–2014. |
| Zhang et al. [25] | 2019 | Static | Opcode sequences | VirusTotal [28] | DT, RF, K-NN, naïve Bayes, and GBD | 99.3% | VirusTotal: 2012–2017 |
| Zakaria et al. [34] | 2022 | Dynamic | API, registration key, embedded strings | RISS [35,41] | Naïve Bayes, kNN, SVM, RF, and J48 | 97.05% | RISS: 2016 |
| Abdullah et al. [36] | 2020 | Dynamic | System calls | VirusTotal [28] | NB, J48 and RF | 98.31% | VirusTotal: Unknown |
| Bibi et al. [37] | 2019 | Dynamic | Packets information and headers | CIC-ANDMal2017 [38] | LSTM | 97.08% | CIC-ANDMal2017: 2017 |
| Chen et al. [29] | 2018 | Dynamic | widget, activity, texts, buttons | HelDroid [23] and private dataset | User interface UI analysis technique to judge the legality of encryption operations. | 99% | HelDroid 2010–2014, private dataset: 2013–2015 |
| Aurangzeb et al. [42] | 2022 | Hybrid | DLLs, strings, and PE header, | VirusShare [18], EldeRan [43] | SVM, RF, KNN, XGBoost, and neural network | 98.7% | VirusShare: unknown, EldeRan: 2016 |
| Deepa et al. [15] | 2019 | Hybrid | System calls | Koodous [30] and Drebin [44] | RF, AdaBoost | 99.9% | Koodous: unknown, Drebin: 2010–2012 |
| Gharib et al. [45] | 2017 | Hybrid | Permissions, text, and API calls | R-PackDroid [46], HelDroid [23] and Contagio [47] Koodous [30] | NB, SVM, RF, and DNN | 97.5% | R-PackDroid: 2015–2016, HelDroid: 2014–2015, Contagio: unknown, Koodous: Unknown |
| Ferrante et al. [48] | 2017 | Hybrid | Opcodes, CPU usage, and network traffic | HelDroid [23] | DT, LR, NB | 100% | HelDroid: 2014–2015 |
2.3. Hybrid Analysis
2.4. Issues in Related Work
3. The Proposed Framework
3.1. Dataset Acquisition
- Use the up-to-date compressed CSV file provided by AndroZoo to create two lists of sha256 hash code for benign and malicious APKs.
- Start scanning each malicious APK using the VirusTotal website.
- Clean malicious list by excluding APKs which was not detected by at least one scanner as a ransomware.
- Split the malicious list based on the dex date into two lists; the first one is the new list of ransomware APKs with a dex date after 2016–2020, whereas the remaining APKs are in the second list of old ransomware APKs.
- Start downloading the APKs of the three lists, which are benign, new ransomware, and old ransomware datasets, and store them in distinct folders, where the downloading process is conducted using the official link provided by AndroZoo.
3.2. Feature Engineering
3.3. Detection Models
3.3.1. Decision Tree
3.3.2. Logistic Regression
3.3.3. K-Nearest Neighbor
3.3.4. Support Vector Machine
3.3.5. Random Forest
4. Experimental Results
4.1. The Effect of the Ransomware Age on the Detection Accuracy
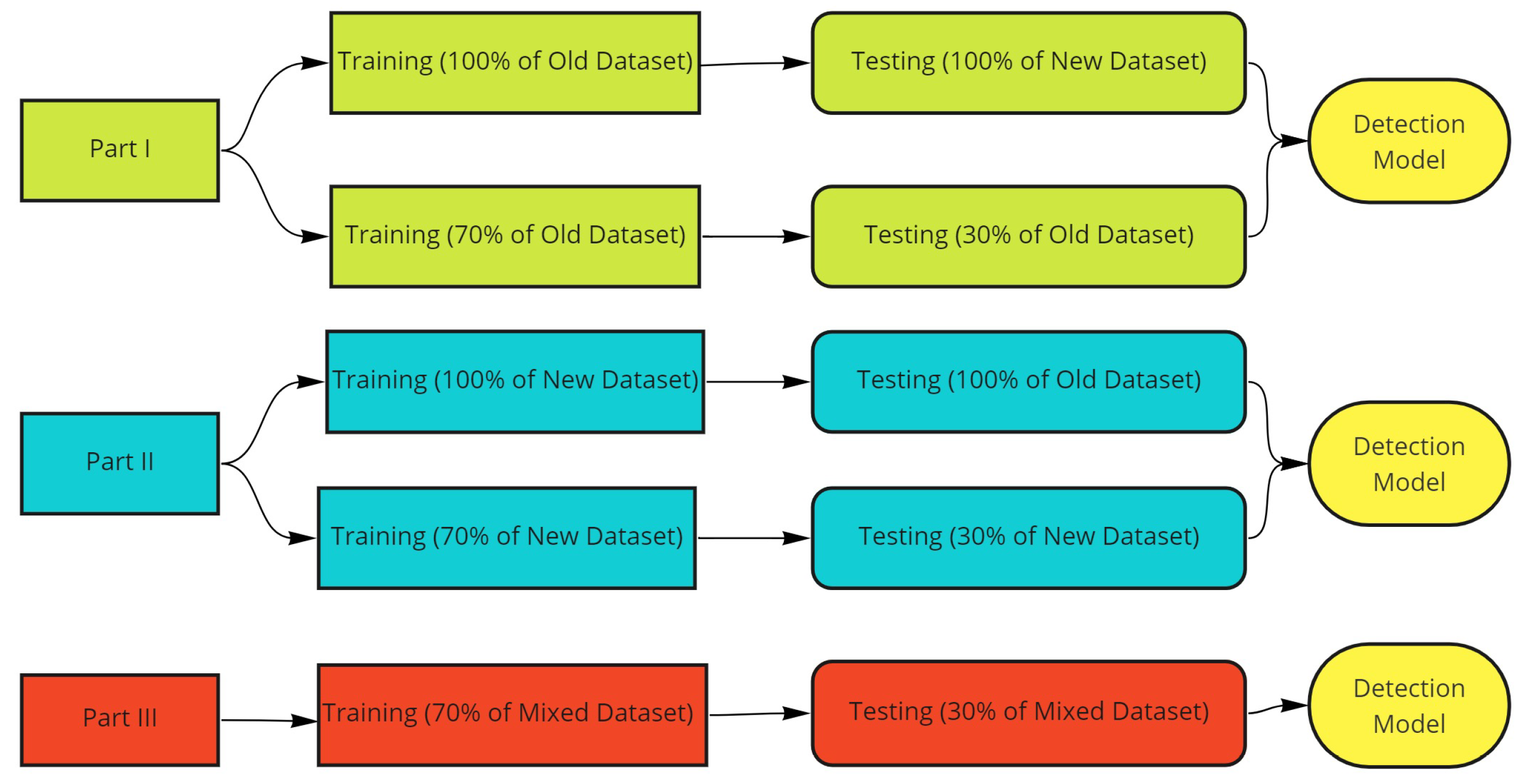
4.1.1. Part I: Training Models Using Old Ransomware Dataset
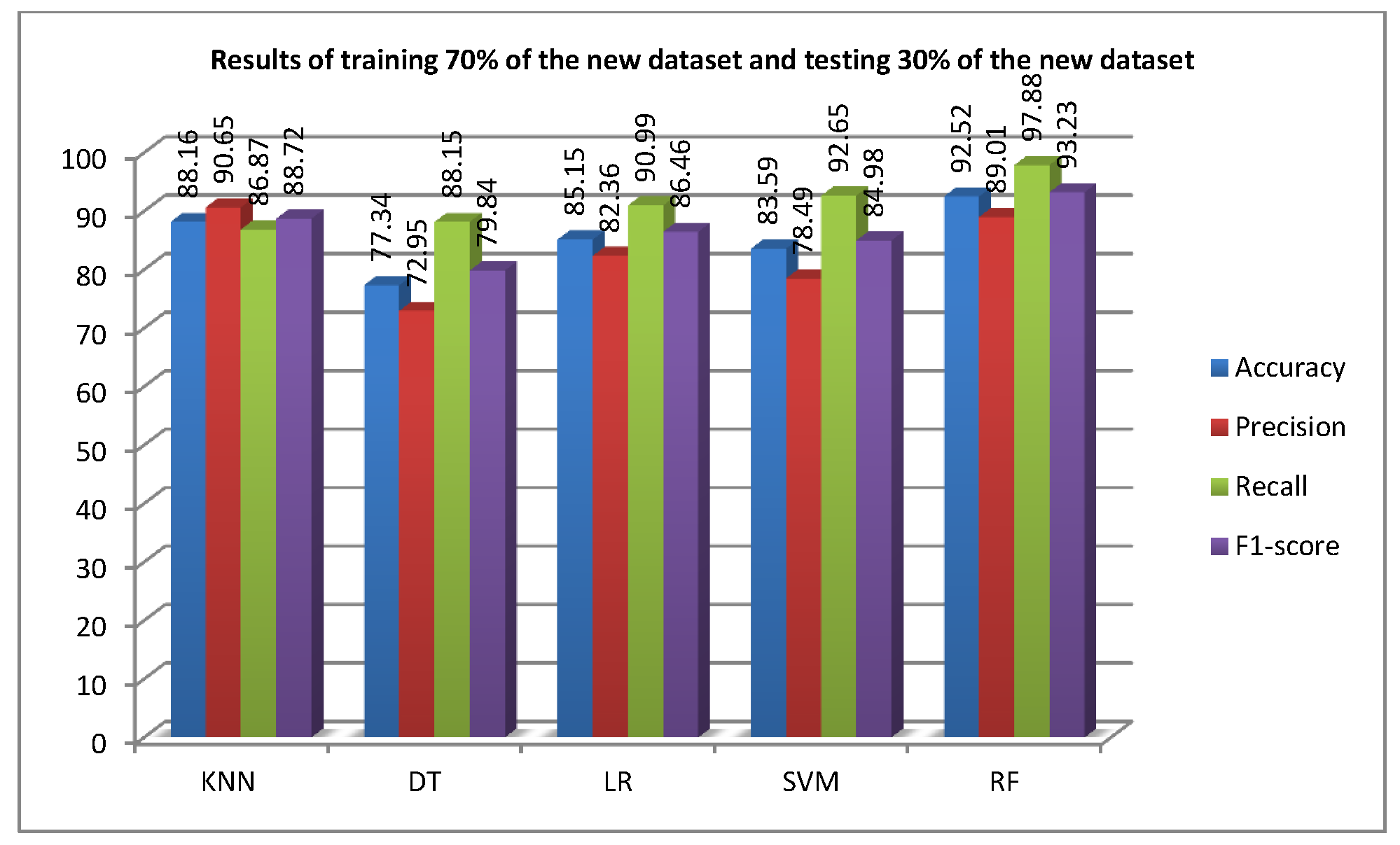
4.1.2. Part II: Training Models Using New Ransomware Dataset
4.2. Building an Effective Model Using Old and New Ransomware Datasets
4.3. Comparing the Proposed Approach with the State of Art Models
4.4. Recommendations and Work Limitations
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Becker, J. Standards for Automotive Operating Systems. ATZelectron. Worldw. 2022, 17, 58. [Google Scholar] [CrossRef]
- Almahmoud, M.; Alzu’bi, D.; Yaseen, Q. ReDroidDet: Android Malware Detection Based on Recurrent Neural Network. Procedia Comput. Sci. 2021, 184, 841–846. [Google Scholar] [CrossRef]
- Sharma, S.; Kumar, R.; Rama Krishna, C. A survey on analysis and detection of Android ransomware. Concurr. Comput. Pract. Exp. 2021, 33, e6272. [Google Scholar] [CrossRef]
- Shishkova, T. The Mobile Malware Threat Landscape in 2022. 2022. Available online: https://securelist.com/mobile-threat-report-2022/108844/ (accessed on 4 March 2022).
- O’Kane, P.; Sezer, S.; Carlin, D. Evolution of ransomware. IET Netw. 2018, 7, 321–327. [Google Scholar] [CrossRef]
- Al-Asli, M.; Ghaleb, T.A. Review of Signature-based Techniques in Antivirus Products. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Shatnawi, A.S.; Yaseen, Q.; Yateem, A. An Android Malware Detection Approach Based on Static Feature Analysis Using Machine Learning Algorithms. Procedia Comput. Sci. 2022, 201, 653–658. [Google Scholar] [CrossRef]
- Odat, E.; Alazzam, B.; Yaseen, Q.M. Detecting Malware Families and Subfamilies Using Machine Learning Algorithms: An Empirical Study. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 761–765. [Google Scholar] [CrossRef]
- Almomani, I.M.; Khayer, A.A. A Comprehensive Analysis of the Android Permissions System. IEEE Access 2020, 8, 216671–216688. [Google Scholar] [CrossRef]
- Singh, J.; Thakur, D.; Gera, T.; Shah, B.; Abuhmed, T.; Ali, F. Classification and Analysis of Android Malware Images Using Feature Fusion Technique. IEEE Access 2021, 9, 90102–90117. [Google Scholar] [CrossRef]
- Li, L.; Bissyandé, T.F.; Papadakis, M.; Rasthofer, S.; Bartel, A.; Octeau, D.; Klein, J.; Traon, L. Static analysis of android apps: A systematic literature review. Inf. Softw. Technol. 2017, 88, 67–95. [Google Scholar] [CrossRef] [Green Version]
- Andersson, K.; Shim, J.; Lim, K.; je Cho, S.; Han, S.; Park, M. Static and Dynamic Analysis of Android Malware and Goodware Written with Unity Framework. Secur. Commun. Netw. 2018, 2018. [Google Scholar] [CrossRef]
- Aung, Z.; Zaw, W. Permission-Based Android Malware Detection. Int. J. Sci. Technol. Res. 2013, 2, 228–234. [Google Scholar]
- Ceschin, F.; Botacin, M.; Gomes, H.M.; Pinagé, F.; Oliveira, L.S.; Grégio, A. Fast & Furious: On the modelling of malware detection as an evolving data stream. Expert Syst. Appl. 2023, 212, 118590. [Google Scholar]
- Kumar, D.; Radhamani, G.; Vinod, P.; Shojafar, M.; Kumar, N.; Conti, M. Identification of Android malware using refined system calls. Concurr. Comput. Pract. Exp. 2019, 31, e5311. [Google Scholar] [CrossRef]
- Androzoo. Available online: https://androzoo.uni.lu/ (accessed on 30 July 2022).
- Kouliaridis, V.; Kambourakis, G.; Geneiatakis, D.; Potha, N. Two Anatomists Are Better than One—Dual-Level Android Malware Detection. Symmetry 2020, 12, 1128. [Google Scholar] [CrossRef]
- Virusshare. Available online: https://virusshare.com/ (accessed on 30 July 2022).
- Gong, D. Top 6 Machine Learning Algorithms for Classification. 2022. Available online: https://towardsdatascience.com/top-machine-learning-algorithms-for-classification-2197870ff501 (accessed on 4 December 2022).
- AlJarrah, M.N.; Yaseen, Q.M.; Mustafa, A.M. A Context-Aware Android Malware Detection Approach Using Machine Learning. Information 2022, 13, 563. [Google Scholar] [CrossRef]
- Massarelli, L.; Aniello, L.; Ciccotelli, C.; Querzoni, L.; Ucci, D.; Baldoni, R. AndroDFA: Android Malware Classification Based on Resource Consumption. Information 2020, 11, 326. [Google Scholar] [CrossRef]
- Berman, D.S. DGA CapsNet: 1D Application of Capsule Networks to DGA Detection. Information 2019, 10, 157. [Google Scholar] [CrossRef] [Green Version]
- Andronio, N.; Zanero, S.; Maggi, F. HelDroid: Dissecting and Detecting Mobile Ransomware. In RAID 2015: Research in Attacks, Intrusions, and Defenses, Proceedings of the International Symposium on Recent Advances in Intrusion Detection, Kyoto, Japan, 2–4 November 2015; Bos, H., Monrose, F., Blanc, G., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 382–404. [Google Scholar]
- Alsoghyer, S.; Almomani, I. Ransomware Detection System for Android Applications. Electronics 2019, 8, 868. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Xiao, X.; Mercaldo, F.; Ni, S.; Martinelli, F.; Sangaiah, A.K. Classification of ransomware families with machine learning based onN-gram of opcodes. Future Gener. Comput. Syst. 2019, 90, 211–221. [Google Scholar] [CrossRef]
- Scalas, M.; Maiorca, D.; Mercaldo, F.; Visaggio, C.A.; Martinelli, F.; Giacinto, G. On the effectiveness of system API-related information for Android ransomware detection. Comput. Secur. 2019, 86, 168–182. [Google Scholar] [CrossRef] [Green Version]
- Gaur, K.; Kumar, N.; Handa, A.; Shukla, S.K. Static Ransomware Analysis Using Machine Learning and Deep Learning Models. In ACeS 2020: Advances in Cyber Security, Proceedings of the International Conference on Advances in Cyber Security, Penang, Malaysia, 8–9 December 2020; Anbar, M., Abdullah, N., Manickam, S., Eds.; Springer: Singapore, 2021; pp. 450–467. [Google Scholar]
- VirusTotal. Available online: https://www.virustotal.com/ (accessed on 30 July 2022).
- Chen, J.; Wang, C.; Zhao, Z.; Chen, K.; Du, R.; Ahn, G.J. Uncovering the Face of Android Ransomware: Characterization and Real-Time Detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1286–1300. [Google Scholar] [CrossRef]
- Koodous: Collective Intelligence against Android Malware. Available online: https://koodous.com/ (accessed on 30 July 2022).
- Su, D.; Liu, J.; Wang, X.; Wang, W. Detecting Android Locker-Ransomware on Chinese Social Networks. IEEE Access 2019, 7, 20381–20393. [Google Scholar] [CrossRef]
- Anzhi Market. Available online: http://www.anzhi.com/ (accessed on 30 July 2022).
- HaboMalHunter. Available online: https://github.com/Tencent/HaboMalHunter (accessed on 30 July 2022).
- Zakaria, W.Z.A.; Abdollah, M.F.; Mohd, O.; Yassin, S.M.W.M.S.M.M.; Ariffin, A. RENTAKA: A Novel Machine Learning Framework for Crypto-Ransomware Pre-encryption Detection. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 378–385. [Google Scholar] [CrossRef]
- Kok, S.; Abdullah, A.; Zaman, N.; Supramaniam, M. Prevention of Crypto-Ransomware Using a Pre-Encryption Detection Algorithm. Computers 2019, 8, 79. [Google Scholar] [CrossRef] [Green Version]
- Abdullah, Z.; Muhadi, F.W.; Saudi, M.M.; Hamid, I.R.A.; Foozy, C.F.M. Android Ransomware Detection Based on Dynamic Obtained Features. In Recent Advances on Soft Computing and Data Mining, Proceedings of the International Conference on Soft Computing and Data Mining, Melaka, Malaysia, 22–23 January 2020; Ghazali, R., Nawi, N.M., Deris, M.M., Abawajy, J.H., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 121–129. [Google Scholar]
- Bibi, I.; Akhunzada, A.; Malik, J.; Ahmed, G.; Raza, M. An Effective Android Ransomware Detection through Multi-Factor Feature Filtration and Recurrent Neural Network. In Proceedings of the 2019 UK/ China Emerging Technologies (UCET), Glasgow, UK, 21–22 August 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Lashkari, A.H.; Kadir, A.F.A.; Taheri, L.; Ghorbani, A.A. Toward Developing a Systematic Approach to Generate Benchmark Android Malware Datasets and Classification. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Kim, T.; Kang, B.; Rho, M.; Sezer, S.; Im, E.G. A Multimodal Deep Learning Method for Android Malware Detection Using Various Features. IEEE Trans. Inf. Forensics Secur. 2019, 14, 773–788. [Google Scholar] [CrossRef] [Green Version]
- MalGenome Project. Available online: http://www.malgenomeproject.org (accessed on 30 July 2022).
- Alqahtani, A.; Gazzan, M.; Sheldon, F.T. A proposed Crypto-Ransomware Early Detection(CRED) Model using an Integrated Deep Learning and Vector Space Model Approach. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 0275–0279. [Google Scholar] [CrossRef]
- Aurangzeb, S.; Wang, C.; Anwar, H.; Naeem, M.A.; Aleem, M. BigRC-EML: Big-data based ransomware classification using ensemble machine learning. Clust. Comput. 2022, 25, 3405–3422. [Google Scholar] [CrossRef]
- Sgandurra, D.; Muñoz-González, L.; Mohsen, R.; Lupu, E.C. Automated Dynamic Analysis of Ransomware: Benefits, Limitations and use for Detection. arXiv 2016, arXiv:1609.03020. [Google Scholar] [CrossRef]
- Arp, D.; Spreitzenbarth, M.; Hübner, M.; Gascon, H.; Rieck, K. DREBIN: Effective and Explainable Detection of Android Malware in Your Pocket. In Proceedings of the 2014 Network and Distributed System Security (NDSS) Symposium, San Diego, CA, USA, 23–26 February 2014. [Google Scholar] [CrossRef] [Green Version]
- Gharib, A.; Ghorbani, A. DNA-Droid: A Real-Time Android Ransomware Detection Framework. In NSS 2017: Network and System Security, Proceedings of the International Conference on Network and System Security, Helsinki, Finland, 21–23 August 2017; Yan, Z., Molva, R., Mazurczyk, W., Kantola, R., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 184–198. [Google Scholar]
- R-PackDroid Dataset. Available online: https://goo.gl/RVxfxL (accessed on 30 July 2022).
- Parkour, M. Contagio Mini-Dump. Available online: http://contagiominidump.blogspot.it/ (accessed on 30 July 2022).
- Ferrante, A.; Malek, M.; Martinelli, F.; Mercaldo, F.; Milosevic, J. Extinguishing Ransomware—A Hybrid Approach to Android Ransomware Detection. In FPS 2017: Foundations and Practice of Security, Proceedings of the International Symposium on Foundations and Practice of Security, Nancy, France, 23–25 October 2017; Imine, A., Fernandez, J.M., Marion, J.Y., Logrippo, L., Garcia-Alfaro, J., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 242–258. [Google Scholar]
- Sun, M.; Li, X.; Lui, J.C.S.; Ma, R.T.B.; Liang, Z. Monet: A User-Oriented Behavior-Based Malware Variants Detection System for Android. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1103–1112. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Zheng, C.; Zeng, J.; Zhou, W.; Zhu, S.; Liu, P.; Chari, S.; Zhang, C. Android malware development on public malware scanning platforms: A large-scale data-driven study. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 1090–1099. [Google Scholar] [CrossRef]
- Martín García, A.; Lara-Cabrera, R.; Camacho, D. A new tool for static and dynamic Android malware analysis. In Proceedings of the FLINS 2018: The 13th International FLINS Conference on Data Science and Knowledge Engineering for Sensing Decision Support, Belfast, UK, 21–24 August 2018; pp. 509–516. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar] [CrossRef]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar] [CrossRef]
- Rege, M. Machine Learning for Cyber Defense and Attack. In Proceedings of the DATA ANALYTICS 2018: The Seventh International Conference on Data Analytics, Porto, Portugal, 26–28 July 2018. [Google Scholar]
- Pirjatullah; Kartini, D.; Nugrahadi, D.T.; Muliadi; Farmadi, A. Hyperparameter Tuning using GridsearchCV on The Comparison of The Activation Function of The ELM Method to The Classification of Pneumonia in Toddlers. In Proceedings of the 2021 4th International Conference of Computer and Informatics Engineering (IC2IE), Depok, Indonesia, 14–15 September 2021; pp. 390–395. [Google Scholar] [CrossRef]
- Sharma, S.; Krishna, C.R.; Kumar, R. Android Ransomware Detection using Machine Learning Techniques: A Comparative Analysis on GPU and CPU. In Proceedings of the 2020 21st International Arab Conference on Information Technology (ACIT), Giza, Egypt, 28–30 November 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Alsoghyer, S.; Almomani, I. On the Effectiveness of Application Permissions for Android Ransomware Detection. In Proceedings of the 2020 6th Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 4–5 March 2020; pp. 94–99. [Google Scholar] [CrossRef]










| Mobile Operating Systems | Percentage Market Share |
|---|---|
| Android | 72.11% |
| IOS | 27.22% |
| Samsung | 0.42% |
| Machine Learning Algorithm | Hyperparameter | Values |
|---|---|---|
| SVM | Kernel | ‘Linear’ |
| C | (1, 0.25, 0.5, and 0.75) | |
| gamma | 1, 2, 3, and ‘auto’ | |
| DT | max_features | ‘auto’, ‘sqrt’, and ’log2’ |
| ccp_alpha | (0.1, 0.01, and 0.001) | |
| max_depth | (5, 6, 7, 8, and 9) | |
| Criterion | ‘Gini’ and ‘entropy’ | |
| LG | C | log(−3,3, and 7) |
| Penalty | l1 and l2 | |
| KNN | K | [1–30] |
| RF | n_estimators | (10, 100, 1000, 2000) |
| Criterion | ‘Gini’ and ‘entropy’ |
| Dataset | Year | Num. of Samples |
|---|---|---|
| Old Ransomware | 2008 | 212 |
| 2009 | 3 | |
| 2010 | 3 | |
| 2011 | 110 | |
| 2012 | 288 | |
| 2013 | 201 | |
| 2014 | 1412 | |
| 2015 | 2222 | |
| New Ransomware | 2016 | 1001 |
| 2017 | 490 | |
| 2018 | 232 | |
| 2019 | 325 | |
| 2020 | 46 |
| Dataset | Num. of Extracted Features | Num. of Selected Features |
|---|---|---|
| Old Ransomware | 2521 | 161 |
| New Ransomware | 2083 | 274 |
| Old Ransomware | New Ransomware |
|---|---|
| INSTALL_PACKAGES | MMOAUTH_CALLBACK |
| READ_GSERVICES | READ_COARSE_LOCATION |
| ACCESSORY_FRAMEWORK | WRITE_APN_STORAGE |
| ENABLE_NOTIFICATION | MAPS_RECEIVE |
| CHANGE_CONFIREAD_PHONE_STATEGURATION | RECEIVE_KEAT |
| RECEIVE_ADM_MESSAGE | GET_DETAILED_TASKS |
| UA_DATA | LOCAL_MAC_ADDRESS |
| SYSTEM_ALERT_WINDOW | HKBC_SEND |
| REMOVE_TASKS | UNINSTALL_SHORTCUT |
| QUICKBOOT_POWERON | INSTALL_SHORTCUT |
| Experiment | Training Set | Testing Set |
|---|---|---|
| Experiment I | Old dataset (100%) | New dataset (100%) |
| Experiment II | Old dataset (70%) | Old Dataset (30%) |
| Experiment | Training Set | Testing Set |
|---|---|---|
| Experiment I | New dataset (100%) | Old dataset (100%) |
| Experiment II | New dataset (70%) | New dataset (30%) |
| Work | Year | Ransomware Samples | Benign Samples | Features | Number of Selected Features | Classification Algorithm | Accuracy | Dataset Age |
|---|---|---|---|---|---|---|---|---|
| [24] | 2019 | 500 | 2959 | API calls | 173 | Random forest | 96.5% | HelDroid: collected 2010–2014; VirusTotal: submitted 2017–2018; Koodous: unknown |
| [25] | 2019 | 1787 | NA | Opcode sequences | 695,945 | Random forest | 99.3% | VirusTotal: 2012–2017 |
| [57] | 2020 | 500 | 500 | Permissions | 115 | Random forest | 96.9% | HelDroid: collected 2010–2014; VirusTotal: submitted 2017–2018; Koodous: unknown |
| [56] | 2020 | 2721 | 2000 | Permissions | 1045 | Logistic regression | 99.5% | RansomProber: collected from HelDroid 2010–2014 |
| The Proposed Work | 2022 | 6340 | 2300 | Permissions | 241 | Random forest | 97.5% | AndroZoo: 2008–2020 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yaseen, Q.M. The Effect of the Ransomware Dataset Age on the Detection Accuracy of Machine Learning Models. Information 2023, 14, 193. https://doi.org/10.3390/info14030193
Yaseen QM. The Effect of the Ransomware Dataset Age on the Detection Accuracy of Machine Learning Models. Information. 2023; 14(3):193. https://doi.org/10.3390/info14030193
Chicago/Turabian StyleYaseen, Qussai M. 2023. "The Effect of the Ransomware Dataset Age on the Detection Accuracy of Machine Learning Models" Information 14, no. 3: 193. https://doi.org/10.3390/info14030193
APA StyleYaseen, Q. M. (2023). The Effect of the Ransomware Dataset Age on the Detection Accuracy of Machine Learning Models. Information, 14(3), 193. https://doi.org/10.3390/info14030193