

Efficient Dynamic Reconfigurable CNN Accelerator for Edge Intelligence Computing on FPGA


Abstract
:1. Introduction
2. CNN Model and Dynamic Reconfigurable Technology
2.1. Convolutional Neural Networks
2.2. Dynamic Reconfigurable Technology for FPGAs
3. Design of Dynamic Reconfigurable CNN Accelerator
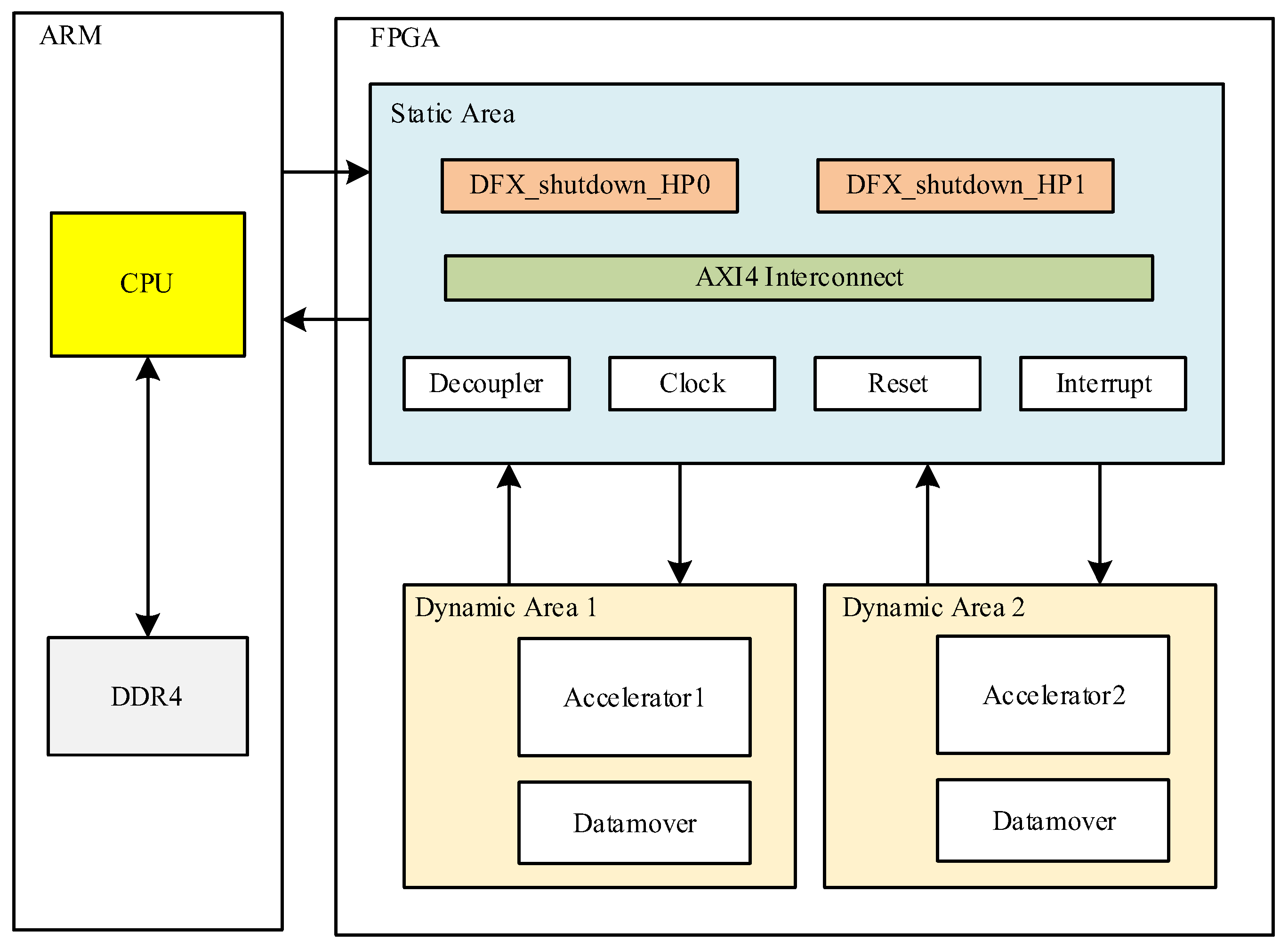
3.1. Hardware Design
| Algorithm 1. Convolutional activation unit parallel acceleration algorithm pseudocode |
| INPUT InputFeature[too][trr][tcc], Weighs[Tcout][Tcin][H][W]; OUTPUT OutFeature[Tcout][Tcout][Tyout]; 1.FOR(i = 0; i < H; i++){ 2. FOR(j = 0; j < W; j++){ 3. FOR(trr = row; trr < min(row + Tr,R); trr++){ 4. FOR(tcc = col; tcc < min(col + Tm,C); tcc++){ 5.#PRAGMA HLS PIPELINE // Pipeline 6. FOR(too = to; too < min(to + Tn,M); tii++){ 7.#PRAGMA HLS UNROLL // Full Parallelization Operations 8. FOR(tii = ti; tii < min(ti + Tn,N); tii++){ 9.#PRAGMA HLS UNROLL // Full Parallelization Operations 10.LOOP: OutFeature[too][trr][tcc] +=\ 11. Weights[too][tii][i][j] * InputFeature [tii][S*trr+i][S*tcc+j]; 13.}}}}}} |
3.2. Reconfigurable Modules
3.3. Optimized Configuration Sequence Method
| Algorithm 2: Layer Clustering Pseudocode |
| Input: Set of layers, D = {X1, X2, X3, ..., Xm} Output: Set of classes, C = {C1, C2, C3, ..., Ci} 1. Group the layers of the same type into set D 2. Set class count, I = 1 3. REPEAT 4. Find the fastest layer X in set D 5. Place X into a new set, Ci 6. Calculate the execution time overhead of other layers using the same configuration as X 7. IF the redundant time overhead is less than the reconfiguration time overhead THEN 8. Add the layer to set Ci 9. END IF 10. IF all other layers have been processed THEN 11. Remove set Ci from the total set C 12. END IF 13. Increment class count, i++ 14. UNTIL the current set D is empty 15. Return set Ci |
4. Experiments and Results
4.1. Experimental Settings
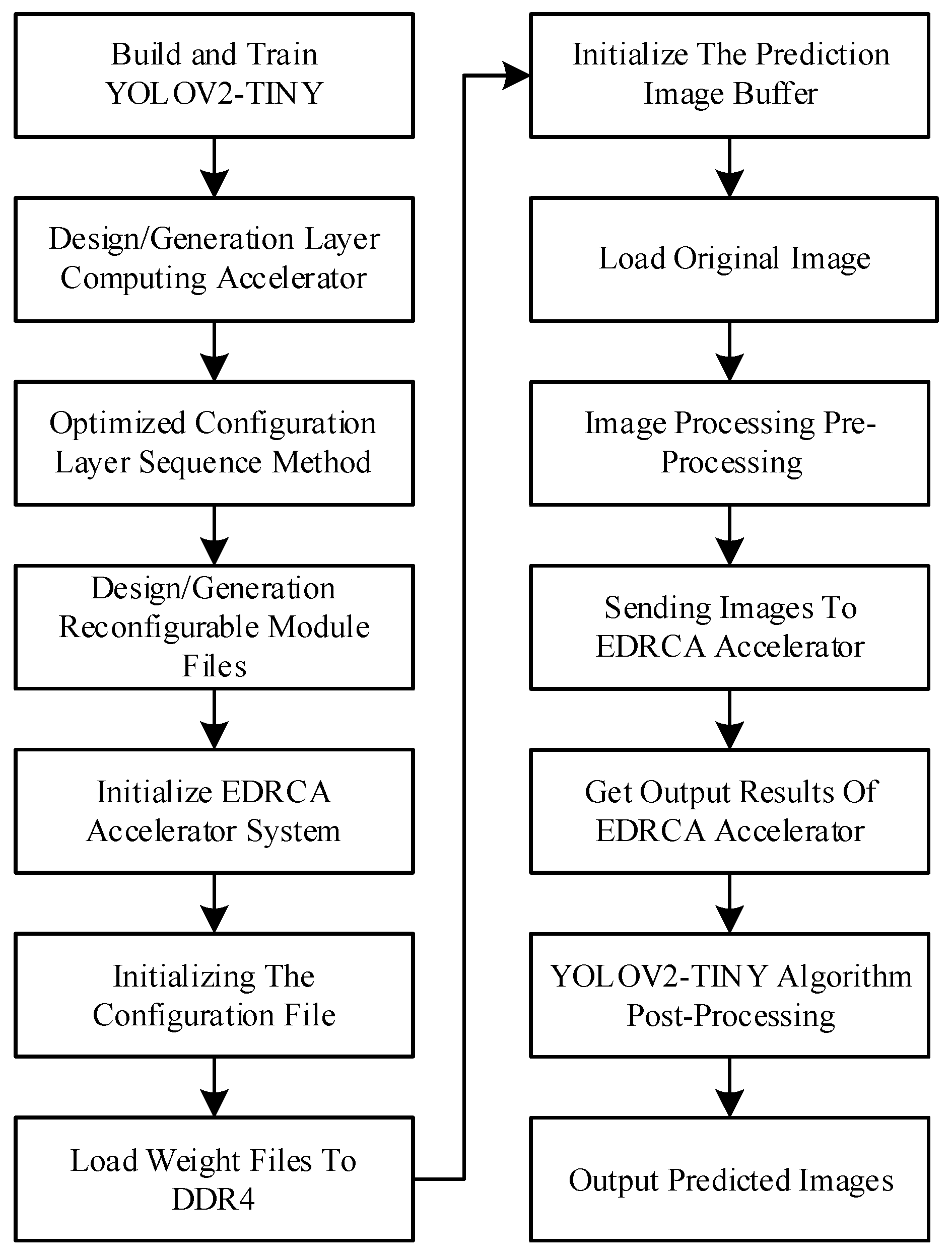
4.2. Experimental Flow
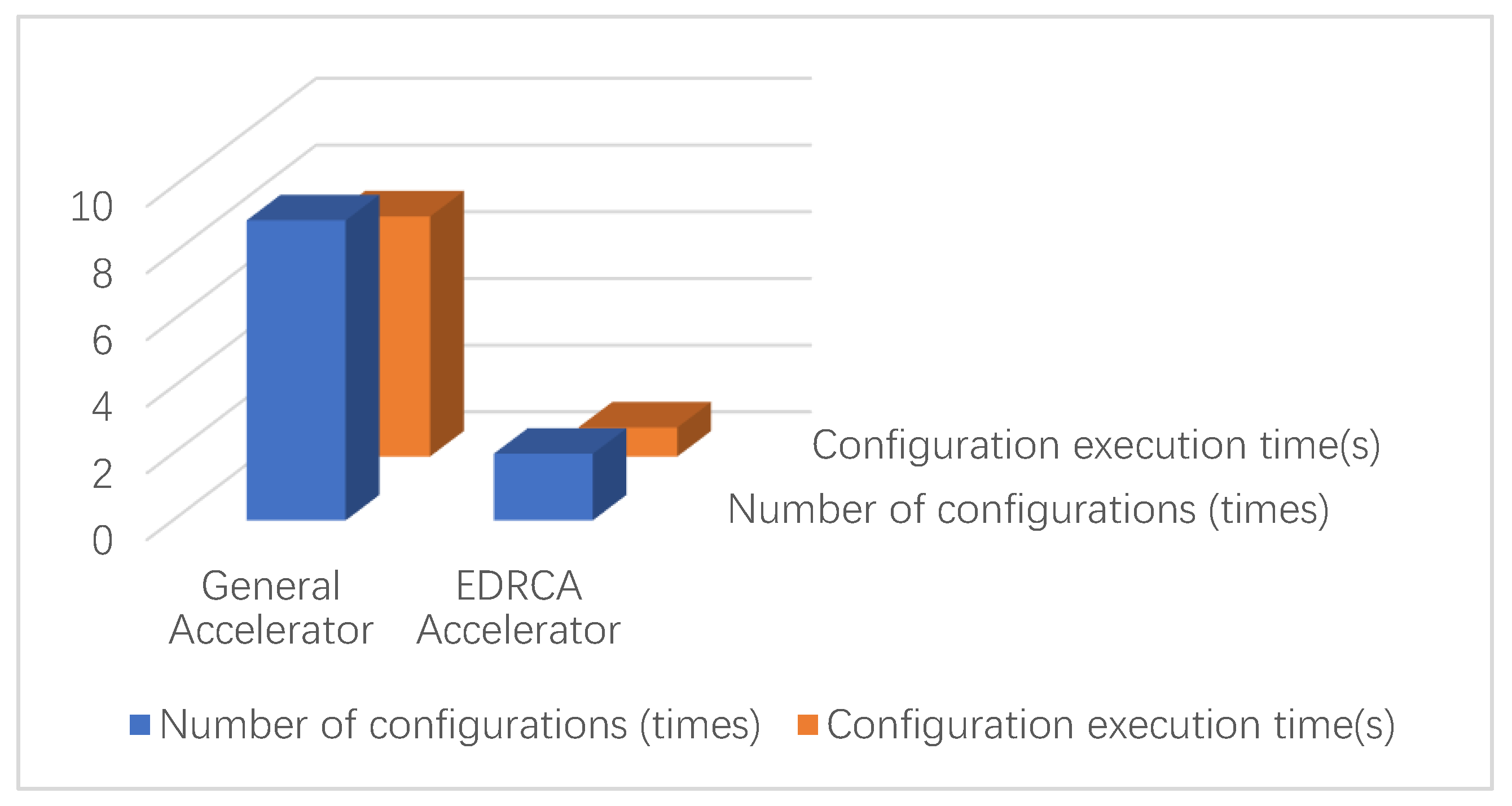
4.3. Results
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nisar, A.; Nehete, H.; Verma, G.; Kaush, B.K. Hybrid Multilevel STT/DSHE Memory for Efficient CNN Training. IEEE Trans. Electron. Devices 2023, 70, 1006–1013. [Google Scholar] [CrossRef]
- Ding, L.; Li, H.; Hu, C.; Zhang, W.; Wang, S. Alexnet feature extraction and multi-kernel learning for object-oriented classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Cheng, C. Real-Time Mask Detection Based on SSD-MobileNetV2. In Proceedings of the 2022 IEEE 5th International Conference on Automation, Electronics and Electrical Engineering, Shenyang, China, 18–20 November 2022; pp. 761–767. [Google Scholar]
- Zhang, J.H.; Zhang, F.; Xie, M.; Liu, X.Y.; Feng, T.Y. Design and Implementation of CNN Traffic Lights Classification Based on FPGA. In Proceedings of the 2021 IEEE 4th International Conference on Electronic Information and Communication Technology, Xi’an, China, 18–20 August 2021; pp. 445–449. [Google Scholar]
- Pestana, D.; Mirand, P.R.; Lopes, J.D.; Duarte, R.P.; Vestias, M.P.; Neto, H.C.; Sousa, J.T. A Full Featured Configurable Accelerator for Object Detection With YOLO. IEEE Access 2021, 9, 75864–75877. [Google Scholar] [CrossRef]
- Chen, Y.H.; Fan, C.P.; Chang, R.C. Prototype of Low Complexity CNN Hardware Accelerator with FPGA-based PYNQ Platform for Dual-Mode Biometrics Recognition. In Proceedings of the 2020 International SoC Design Conference, Yeosu, Republic of Korea, 21–24 October 2020; pp. 189–190. [Google Scholar]
- Xiao, Q.; Liang, Y. Fune: An FPGA Tuning Framework for CNN Acceleration. IEEE Des. Test 2019, 37, 46–55. [Google Scholar] [CrossRef]
- Zeng, T.H.; Li, Y.; Song, M.; Zhong, F.L.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Anwar, S.; Hwang, K.; Sung, W. Structured pruning of deep convolutional neural networks. ACM J. Emerg. Technol. Comput. Syst. (JETC) 2017, 13, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Fan, A.; Stock, P.; Graham, B.; Grave, E.; Gribonval, R.; Jegou, H.; Joulin, A. Training with Quantization Noise for Extreme Model Compression. arXiv 2020, arXiv:2004.07320. [Google Scholar]
- Zhang, C.; Sun, G.; Fang, Z.; Zhou, P.P.; Pan, P.C.; Cong, J.S. Caffeine: Towards Uniformed Representation and Acceleration for Deep Convolutional Neural Networks. Trans. Comput. Aided Des. Integr. Circuits Syst. 2019, 38, 2072–2085. [Google Scholar] [CrossRef]
- Sharma, H.; Park, J.; Mahajan, D.; Amaro, E.; Kim, J.K.; Shao, C.; Mishra, A.; Esmaeilzadeh, H. From High-Level Deep Neural Models to FPGAs. In Proceedings of the ACM International Symposium on Microarchitecture, Taipei, Taiwan, 15–19 October 2016; pp. 1–16. [Google Scholar]
- Wang, J.; Gu, S. FPGA Implementation of Object Detection Accelerator Based on Vitis-ai. In Proceedings of the 2021 11th International Conference on Information Science and Technology (ICIST), IEEE, Chengdu, China, 21–23 May 2021; pp. 571–577. [Google Scholar]
- Zhang, S.; Cao, J.; Zhang, Q.; Zhang, Q.; Zhang, Y.; Wang, Y. An FPGA-Based Reconfigurable CNN Accelerator for YOLO. In Proceedings of the 2020 IEEE 3rd International Conference on Electronics Technology, Chengdu, China, 8–12 May 2020; pp. 74–78. [Google Scholar]
- Wang, Z.; Xu, K.; Wu, S.X.; Liu, L.Z.; Wang, D. Sparse-YOLO: Hardware/Software Co-Design of an FPGA Accelerator for YOLOv2. IEEE Access 2020, 8, 116569–116585. [Google Scholar] [CrossRef]
- Aloysius, N.; Geetha, M. A Review on Deep Convolutional Neural Networks. In Proceedings of the 2017 International Conference on Communication and Signal Processing, Chennai, India, 6–8 April 2017; pp. 588–592. [Google Scholar]
- Wang, X.; Deng, J.Y.; Xie, X.Y. Design and implementation of reconfigurable CNN accelerator. Transducer Microsyst. Technol. 2022, 41, 82–85, 89. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. 2, 5. Available online: http://www.pascalnetwork.org/challenges/VOC/voc2012/workshop/index.html (accessed on 2 February 2023).
- Yuan, F.L.; Gong, L.; Lou, W.Q. Performance Cost Modeling in Dynamic Reconfiguration Hardware Acceleration. Comput. Eng. Appl. 2022, 58, 69–79. [Google Scholar]
- Chong, W.; Ogata, S.; Hariyama, M.; Kameyama, M. Architecture of a Multi-Context FPGA Using Reconfigurable Context Memory. In Proceedings of the 19th IEEE International Parallel and Distributed Processing Symposium, Denver, CO, USA, 4–8 April 2005; p. 7. [Google Scholar]
- Sunkavilli, S.; Chennagouni, N.; Yu, Q. DPReDO: Dynamic Partial Reconfiguration enabled Design Obfuscation for FPGA Security. In Proceedings of the 2022 IEEE 35th International System-on-Chip Conference, Belfast, UK, 5–8 September 2022; pp. 1–6. [Google Scholar]
- Yuan, F.L. Convolutional Neural Network Accelerator Based on Dynamic Hardware Reconfiguration; University of Science and Technology of China: Hefei, China, 2021. [Google Scholar]
- Xu, H.D. Research and Implementation of Target Detection Algorithm Based on Zynq Platform; School of Information and Communication Engineering: Chengdu, China, 2021. [Google Scholar]
- Chen, T.S. Design and Implementation of a Reconfigurable Convolutional Neural Network Accelerator Based on FPGA; Guangdong University of Technology: Guangzhou, China, 2021. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Number of Convolution Kernels | Convolution Kernel Size/Step/Fill | Input Feature Maps | Input Feature Maps |
|---|---|---|---|---|
| Conv1 | 16 | 3 × 3/1/1 | 416 × 416 × 3 | 416 × 416 × 16 |
| Pool1 | 2 × 2/2/0 | 416 × 416 × 16 | 208 × 228 × 16 | |
| Conv2 | 32 | 3 × 3/1/1 | 208 × 208 × 16 | 208 × 208 × 32 |
| Pool2 | 2 × 2/2/0 | 208 × 208 × 32 | 104 × 104 × 32 | |
| Conv3 | 64 | 3 × 3/1/1 | 104 × 104 × 32 | 104 × 104 × 64 |
| Pool3 | 2 × 2/2/0 | 52 × 52 × 64 | 52 × 52 × 128 | |
| Conv4 | 128 | 3 × 3/1/1 | 52 × 52 × 128 | 26 × 26 × 128 |
| Pool4 | 2 × 2/2/0 | 26 × 26 × 128 | 26 × 26 × 256 | |
| Conv5 | 256 | 3 × 3/1/1 | 26 × 26 × 256 | 13 × 13 × 256 |
| Pool5 | 2 × 2/2/0 | 13 × 13 × 256 | 13 × 13 × 256 | |
| Conv6 | 512 | 3 × 3/1/1 | 13 × 13 × 256 | 13 × 13 × 512 |
| Pool6 | 2 × 2/2/0 | 13 × 13 × 512 | 13 × 13 × 512 | |
| Conv7 | 1024 | 3 × 3/1/1 | 13 × 13 × 512 | 13 × 13 × 1024 |
| Conv8 | 1024 | 3 × 3/1/1 | 13 × 13 × 1024 | 13 × 13 × 1024 |
| Conv9 | 125 | 1 × 1/1/0 | 13 × 13 × 1024 | 13 × 13 × 125 |
| Resource Type | FF | LUT | BRAM | DSP | URAM |
|---|---|---|---|---|---|
| Static Area | 65,280 | 32,640 | 0 | 384 | 0 |
| Dynamic Area 1 | 84,480 | 41,888 | 72 | 432 | 32 |
| Dynamic Area 2 | 84,480 | 41,888 | 72 | 432 | 32 |
| Resource Utilization | 234,240 | 116,416 | 144 | 1248 | 64 |
| Total Resource Volume | 234,240 | 117,120 | 144 | 1248 | 64 |
| Resource Utilization Rate (%) | 100 | 99.4 | 100 | 100 | 100 |
| Category | EDRCA | CPU | GPU |
|---|---|---|---|
| Hardware Platform | XCK26-SFVC784 | AMD Ryzen7 4800 H | NVIDIA GeForce RTX2060 |
| Operating Frequency (MHz) | 250 | 2900 | 7010 |
| Throughput (GOPS) | 75.1928 | 7.3926 | 100.1748 |
| Power Consumption (W) | 5.520 | 45 | 175 |
| Single Picture Inference time (s) | 0.0918 | 0.9455 | 0.0698 |
| Frames Per Second (fps) | 10.893 | 1.058 | 14.327 |
| Category | Ref. [16] | Ref. [26] | Ref. [27] | EDRCA |
|---|---|---|---|---|
| Algorithm Model | YOLOV2-TINY | YOLOV2-TINY | YOLOV2-TINY | YOLOV2-TINY |
| Hardware Platform | ZCU102 | MZ7035 | XC7Z045 | XCK26-SFVC784 |
| Operating Frequency (MHz) | 300 | 142 | 200 | 250 |
| Fixed Data Precision (bit) | 16 | 16 | 16 | 32 |
| Giga Operations Per Second (GOPS) | 102 | 25.64 | 121.2 | 75.1928 |
| Single picture inference time (s) | 11.8 | 2.754 | 19.2 | 5.520 |
| Power consumption (W) | 11.8 | 2.754 | 19.2 | 13.6219 |
| Peak Energy Efficiency (GOPS/W) | 8.6441 | 9.310 | 6.3125 | 13.6219 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, K.; Wang, M.; Tan, X.; Li, Q.; Lei, T. Efficient Dynamic Reconfigurable CNN Accelerator for Edge Intelligence Computing on FPGA. Information 2023, 14, 194. https://doi.org/10.3390/info14030194
Shi K, Wang M, Tan X, Li Q, Lei T. Efficient Dynamic Reconfigurable CNN Accelerator for Edge Intelligence Computing on FPGA. Information. 2023; 14(3):194. https://doi.org/10.3390/info14030194
Chicago/Turabian StyleShi, Kaisheng, Mingwei Wang, Xin Tan, Qianghua Li, and Tao Lei. 2023. "Efficient Dynamic Reconfigurable CNN Accelerator for Edge Intelligence Computing on FPGA" Information 14, no. 3: 194. https://doi.org/10.3390/info14030194
APA StyleShi, K., Wang, M., Tan, X., Li, Q., & Lei, T. (2023). Efficient Dynamic Reconfigurable CNN Accelerator for Edge Intelligence Computing on FPGA. Information, 14(3), 194. https://doi.org/10.3390/info14030194