
Trademark Similarity Evaluation Using a Combination of ViT and Local Features




Abstract
:1. Introduction
2. Related Work
3. Pipeline Enhancement
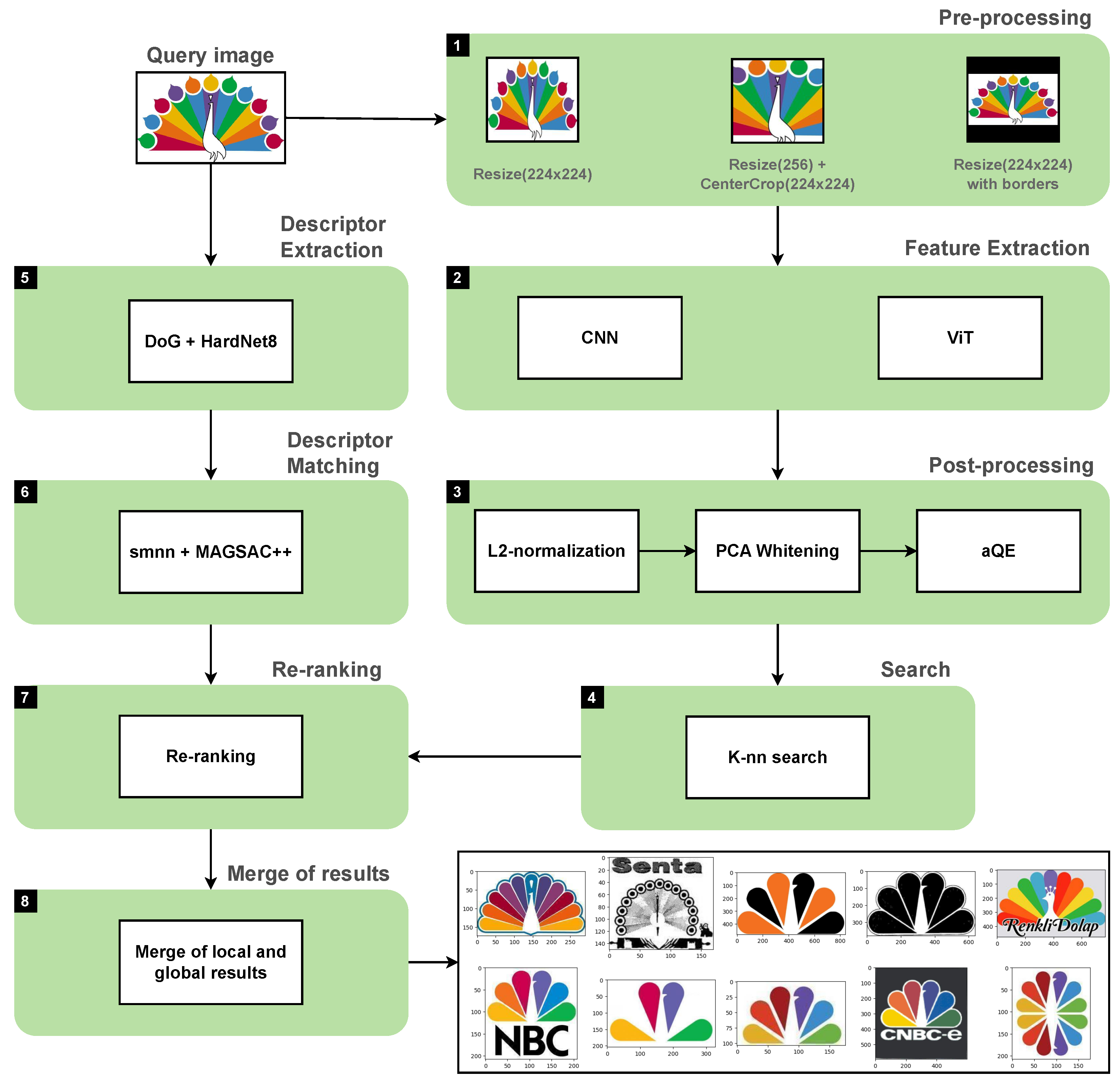
- Scaling to 224 × 224 without preserving the aspect ratio (Resize (224 × 224)).
- Scaling to 256 with the aspect ratio preserved, then cropping out a 224 × 224 square from the center of the image (Resize (256) + CenterCrop (224 × 224)).
- Scaling to 224 × 224 with the aspect ratio preserved, where black bars appear (Resize (224 × 224) with borders).
- Resize (256) + CenterCrop (224 × 224) is a standard transformation used in classification. Its disadvantage is that part of the image is cropped, and thus information is lost.
- Resize (224 × 224) loses aspect ratio information, which makes the image look very different visually.
- Resize (224 × 224) with borders preserves the aspect ratio information but reduces the effective resolution.
4. Experimental Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ViT | Vision transformer |
| CNN | Convolutional neural network |
| CBIR | Content-based image retrieval |
| mAP | Mean average precision |
| NAR | Normalized average rank |
| MR | Multi-resolution |
| SMAC | Sum and max activation of convolution |
| URA | Unsupervised regional attention |
| AQE | Average query expansion |
| QE | -weighted query expansion |
| K-NN | K nearest neighbors |
| SMNN | Second mutual nearest neighbors |
References
- World Intellectual Property Organization. World Intellectual Property Indicators 2021. 2021. Available online: https://www.wipo.int/edocs/pubdocs/en/wipo_pub_941_2021.pdf (accessed on 31 May 2023).
- Tursun, O.; Aker, C.; Kalkan, S. A large-scale dataset and benchmark for similar trademark retrieval. arXiv 2017, arXiv:1701.05766. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Perez, C.A.; Estévez, P.A.; Galdames, F.J.; Schulz, D.A.; Perez, J.P.; Bastías, D.; Vilar, D.R. Trademark image retrieval using a combination of deep convolutional neural networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Babenko, A.; Lempitsky, V. Aggregating local deep features for image retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1269–1277. [Google Scholar]
- Kalantidis, Y.; Mellina, C.; Osindero, S. Cross-dimensional weighting for aggregated deep convolutional features. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 685–701. [Google Scholar]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. Fine-tuning CNN image retrieval with no human annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1655–1668. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tursun, O.; Denman, S.; Sivapalan, S.; Sridharan, S.; Fookes, C.; Mau, S. Component-based attention for large-scale trademark retrieval. IEEE Trans. Inf. Forensics Secur. 2019, 17, 2350–2363. [Google Scholar] [CrossRef] [Green Version]
- Cao, J.; Huang, Y.; Dai, Q.; Ling, W.K. Unsupervised trademark retrieval method based on attention mechanism. Sensors 2021, 21, 1894. [Google Scholar] [CrossRef] [PubMed]
- Tursun, O.; Denman, S.; Sridharan, S.; Fookes, C. Learning test-time augmentation for content-based image retrieval. Comput. Vis. Image Underst. 2022, 222, 103494. [Google Scholar] [CrossRef]
- Tursun, O.; Denman, S.; Sridharan, S.; Fookes, C. Learning regional attention over multi-resolution deep convolutional features for trademark retrieval. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2393–2397. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 806–813. [Google Scholar]
- Chum, O.; Philbin, J.; Sivic, J.; Isard, M.; Zisserman, A. Total recall: Automatic query expansion with a generative feature model for object retrieval. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–8. [Google Scholar]
- Jin, Y.; Mishkin, D.; Mishchuk, A.; Matas, J.; Fua, P.; Yi, K.M.; Trulls, E. Image matching across wide baselines: From paper to practice. Int. J. Comput. Vis. 2021, 129, 517–547. [Google Scholar] [CrossRef]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. MAGSAC++, a fast, reliable and accurate robust estimator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1304–1312. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Kotenko, I.; Kalameyets, M.; Chechulin, A.; Chevalier, Y. A visual analytics approach for the cyber forensics based on different views of the network traffic. J. Wirel. Mob. Netw. Ubiquitous Comput. Dependable Appl. 2018, 9, 57–73. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Pre-Training Dataset |
|---|---|
| Resnet18_in1k | ResNet18 pre-trained on ImageNet-1K |
| Resnet50_in1k | ResNet50 pre-trained on ImageNet-1K |
| resnetv2_50x1_bitm_in21k | ResNet50V2 pre-trained on ImageNet-21K |
| Model Name | Pre-Training Dataset |
|---|---|
| ViT B/16 in 1k | ViT B/16 pre-trained on ImageNet-1K |
| ViT B/16 in 21k | ViT B/16 pre-trained on ImageNet-21K |
| BEiT ViT B/16 in 21k | BEiT ViT B/16 pre-trained on ImageNet-21K |
| Neural Network | Dimensions | Resizing Technique | mAP@100 |
|---|---|---|---|
| Resnet18_in1k | 512 | Resize (256) + CenterCrop (224 × 224) | 11.05 |
| Resize (224 × 224) | 12.23 | ||
| Resize (224 × 224) with borders | 11.25 | ||
| Resnet50_in1k | 2048 | Resize (256) + CenterCrop (224 × 224) | 11.55 |
| Resize (224 × 224) | 13.19 | ||
| Resize (224 × 224) with borders | 13.62 | ||
| resnetv2_50x1_bitm_in21k | 2048 | Resize (256) + CenterCrop (224 × 224) | 14.02 |
| Resize (224 × 224) | 14.93 | ||
| Resize (224 × 224) with borders | 15.17 | ||
| ViT B/16 in 1k | 768 | Resize (256) + CenterCrop (224 × 224) | 7.44 |
| Resize (224 × 224) | 8.30 | ||
| Resize (224 × 224) with borders | 7.35 | ||
| ViT B/16 in 21k | 768 | Resize (256) + CenterCrop (224 × 224) | 14.65 |
| Resize (224 × 224) | 15.97 | ||
| Resize (224 × 224) with borders | 16.83 | ||
| BEiT ViT B/16 in 21k | 768 | Resize (256) + CenterCrop (224 × 224) | 18.01 |
| Resize (224 × 224) | 19.63 | ||
| Resize (224 × 224) with borders | 20.19 |
| Neural Network | mAP@100 before Applying PCAw | mAP@100 after Applying PCAw |
|---|---|---|
| resnetv2_50x1_bitm_in21k | 15.17 | 18.50 |
| BEiT ViT B/16 in 21k | 20.19 | 25.12 |
| Method | mAP@100 |
|---|---|
| BEiT ViT B/16 in 21k | 20.19 |
| BEiT ViT B/16 in 21k + pcaW | 25.12 |
| BEiT ViT B/16 in 21k + pcaW + aQE | 28.46 |
| BEiT ViT B/16 in 21k + pcaW + aQE + reranking | 30.62 |
| BEiT ViT B/16 in 21k + pcaW + aQE + reranking + local_features | 31.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vesnin, D.; Levshun, D.; Chechulin, A. Trademark Similarity Evaluation Using a Combination of ViT and Local Features. Information 2023, 14, 398. https://doi.org/10.3390/info14070398
Vesnin D, Levshun D, Chechulin A. Trademark Similarity Evaluation Using a Combination of ViT and Local Features. Information. 2023; 14(7):398. https://doi.org/10.3390/info14070398
Chicago/Turabian StyleVesnin, Dmitry, Dmitry Levshun, and Andrey Chechulin. 2023. "Trademark Similarity Evaluation Using a Combination of ViT and Local Features" Information 14, no. 7: 398. https://doi.org/10.3390/info14070398
APA StyleVesnin, D., Levshun, D., & Chechulin, A. (2023). Trademark Similarity Evaluation Using a Combination of ViT and Local Features. Information, 14(7), 398. https://doi.org/10.3390/info14070398