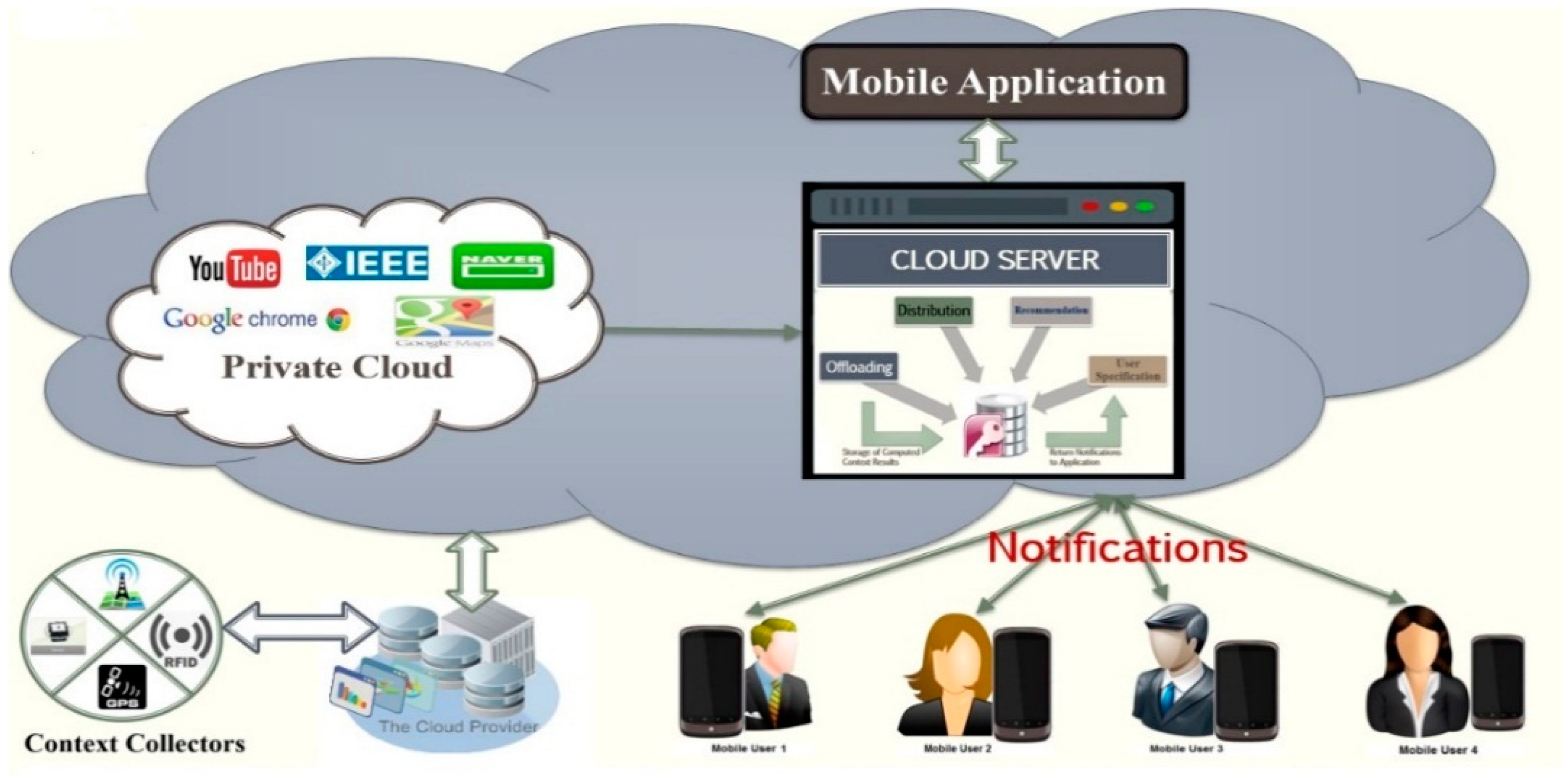
In this section, we present an architecture of CIMS with mechanisms such as recommendation, distribution, offloading, and design of the systems. We discuss a service scenario and efficiency analyses for CIMS in detail.
3.2. Design of Recommendation System
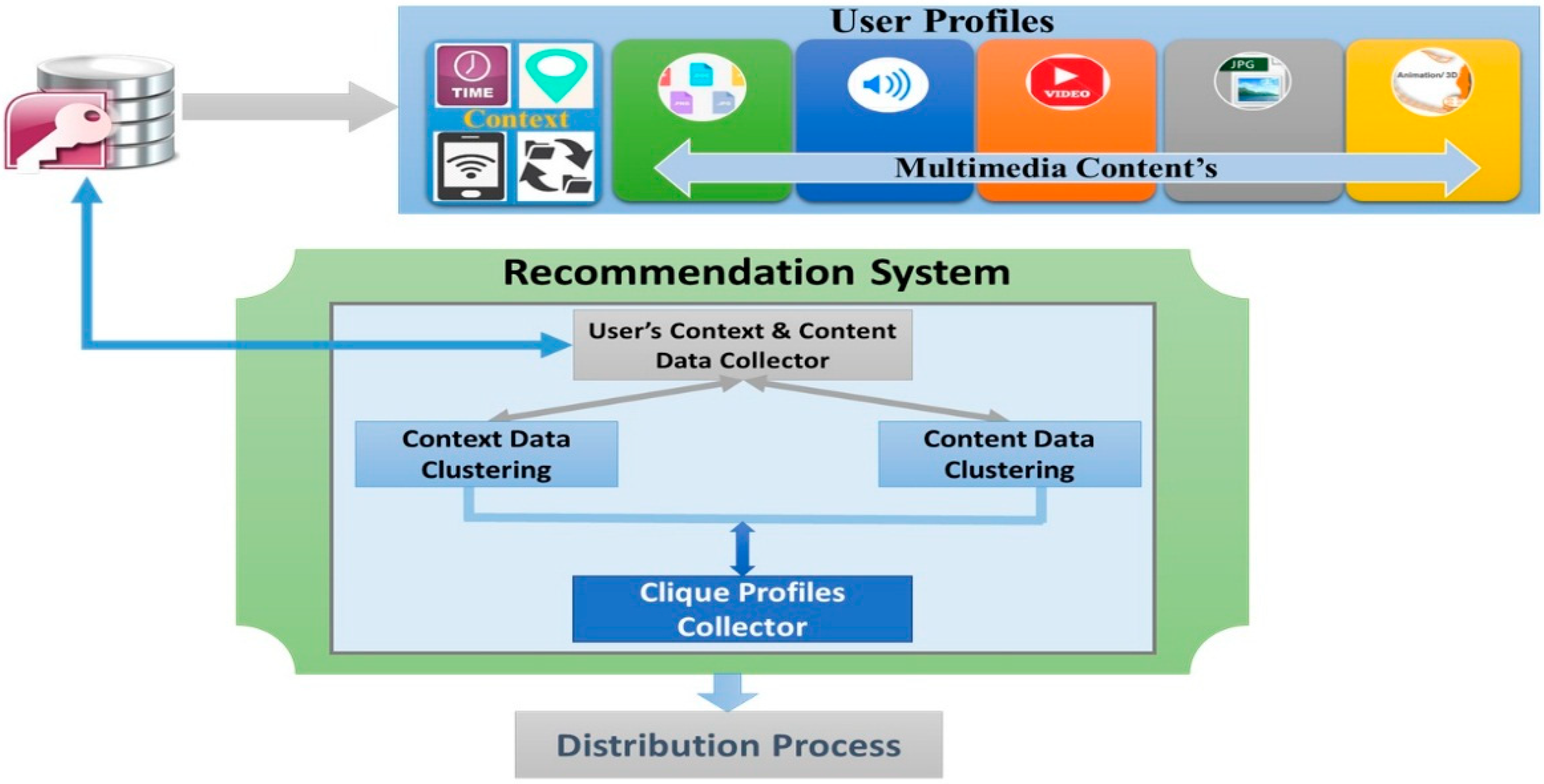
The proposed system, CIMS, is composed of a recommendation system. The dominant role behind the recommendation system is to reduce computing tasks in the mobile framework by using pervasive cloud computing. Usually mobile users depend on implicit and complete behavior models; for this we obtain a recommendation system, which includes four functions as illustrated in
Figure 2: (1) User’s Context and Content Data Collector, (2) Context Data Clustering, (3) Content Data Clustering, and (4) Clique Profiles Collector. All these functions are processed in the cloud server. A cloud server has several user profiles, which manage the user’s privacy and data (
i.e., context and multimedia contents). The user’s Context and Content Data Collector collects data from the database and divides the user’s data (context and content) for clustering evaluation process to finally form several groups of user profiles according to their similarities (between context and content) (
Figure 2). The cloud server performs recommendation processing by collecting data stated in user profiles and executing a clustering function according to the users’ relationships and similarities in context and content data. These processes minimize the storage constraints for the cloud server, offer updates to a user profile if such data is available, and impart notifications without a mobile user’s interactions, according to context entities (
i.e., location, time, network type, and user’s interests). Finally, the recommendation system forms several groups of user profiles based on their similarities in context and multimedia contents and transmits the results to a distribution process to give real-time notifications for mobile user applications. The four major recommendation system functions are described as follows:
The user’s context collectors (i.e., sensors, General packet radio service (GPRS), Radio-frequency identification (RFID), etc.) gathers the user information and transmits the context data (i.e., network types, time, and location) to the cloud server. The user’s contents of interest (i.e., audio, video files, documents) are collected from user profiles (i.e., Gmail, Yahoo, Hotmail, etc.) at the initial stage of application and continue to be updated according to the user’s browsing history. The recommendation system collects context and content data from a highly secure cloud database according to user profiles. We think it is worthwhile to develop a notification technique for mobile user applications because users spent a lot of time surfing for their interests on the Internet, and this leads to high computation and energy concerns. Our goal is to reduce computation and energy consumption for smart devices; we achieve these constraints by sending updated notifications to a mobile user’s application in real time according to his/her profile interests. Due to the daily increase of similarities in a user’s interest and context types, computing will lessen quickly. To minimize the diverse challenges for recommendation systems, we perform a clustering procedure to reduce the computing load at cloud servers. User profiles and their data (i.e., context and multimedia contents) collection are updated simultaneously to keep the recommendation process fresh at the server side.
Figure 2.
Design of Recommendation System.
As aforementioned, ubiquitous computing relies on precise context data to provide an accurate service to users. Studying users’ context (
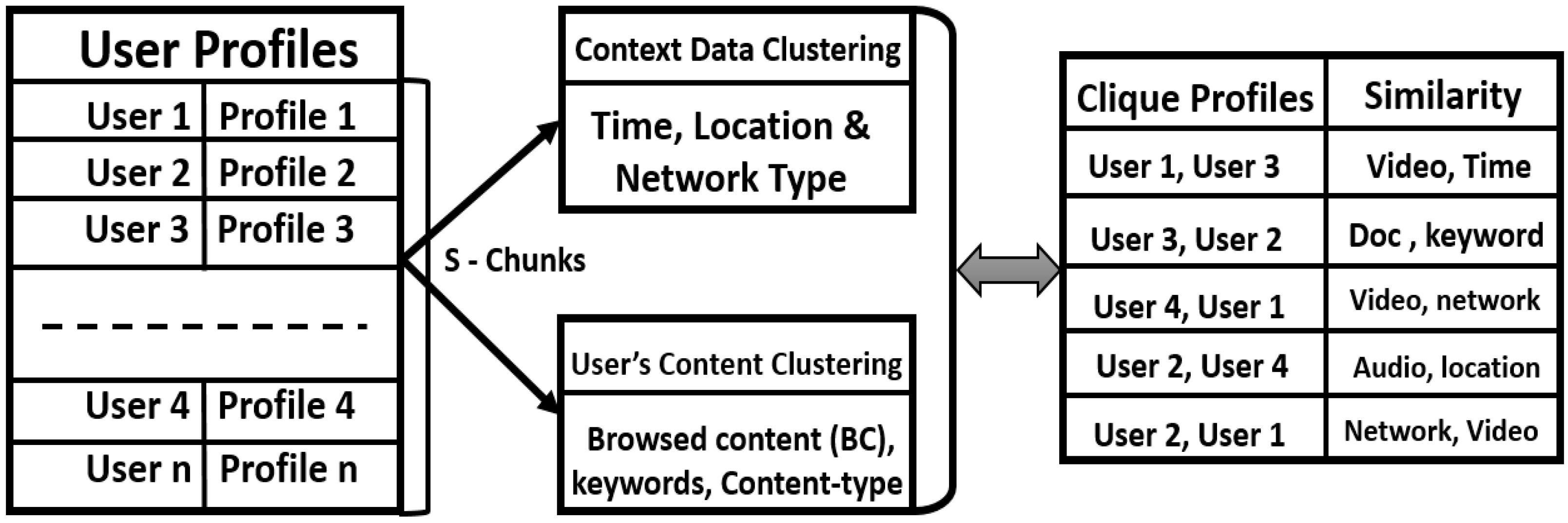
i.e., network types, time and location) is significant. For example: consider YouTube, a famous entertainment application with billions of users enjoying their favorite music and videos at any one time. In this context several users have similarities in accessing the same video clip or music album on either a particular network (3G/4G, Wi-Fi), or at a particular time or location. We use these context similarities to cluster and form several groups of users based on their similarities. Through research studies considering examples like the above, we perform a clustering method on context data to notify the user automatically only if there is any update relevant to the user’s interests, according to their context entities. As said before, to obtain an exact recommendation system, we use cluster algorithms for user satisfaction. In our paper we perform the K-means clustering operation shown in
Figure 3:
- (1)
User profiles are divided into s chunks; each truck includes the profile of different users. We compare user profile context data (time, location, and network type) to find parallel context between profiles.
- (2)
K-means clustering algorithm collects the user’s content information (browsed content (BC), keywords, and content-type) and again matches the user profiles to obtain content similarities.
- (3)
Next it will match user profiles by both context and content; finally, the results are stored in clique profiles with their similarities.
- (4)
If any user does not find similarities, his/her profile will be stored in clique profiles for future use.
Figure 3.
User’s Context & Content Clustering.
User’s profiles are exploited by the recommendation system to find user content similarities. Multimedia content applications retrieve the user’s favorite contents by browsing history, audio, video files, documents, keywords,
etc. In addition, several user groups are formed based on similarities with content illustrations (browsed content, keywords, content type). For instance, in
Figure 3, the second row shows similarities between user 3 and 2 with keywords. This means users 2 and 3 are searching the same document in a multimedia application. Our system considers the similarities in a set of user profiles and sends notifications automatically if any updates are available for their related research. This feature lessens the storage concerns for cloud servers (by not saving an individual profile with his/her contents of interest). Relying on content illustration, the recommendation system requires little computation and provides exact information. Naturally, a user’s interests change according to context and old profiles produce a lot of noise throughout the recommendation process; to control these concerns we merge the context clustering (
Figure 3) to get exact and complete information according to the user profile. We do this by placing the group of users in one truck and performing K-means clustering on user’s data (context and content). Based on clustering, the data cloud server collects a group of users’ information with shared interests or other features in common; this method helps the application providers to make implicit recommendations for users.
Users usually browse multimedia content applications (i.e., YouTube, IEEE, Naver, etc.) for their favorite content; many users have highly similar interests in the resources. By considering similar resources (i.e., browsing history, audio video files, documents, etc.), research studies find users with highly similar behavior. The recommendation system uses a Clique Profiles Collector to achieve better performance and reduce the storage and computing complexities for the cloud server, based on the similarities between several users. Moreover, users’ clustering data (context and content) is replaced by the Clique Profiles Collector to remove the collisions between several groups of user profiles and also give exact results for individuals as well as for groups of users. For example, a person is searching for a job opportunities with his/her user ID and his friend (or another authorized user with similar interests) is browsing the same website. First the recommendation system considers individual histories (context and content data) and performs matching with several user profiles; if any match exists it will store the similar data (content and context) in a group with several users, and send notifications only if there is any update regarding the user’s interests. In cases where the user does not match with another user, his/her profile will be stored in clique profiles for future use. This approach reduces the computing cost for the cloud server. After performing the recommendation process, results are directed towards the distribution process, which performs real-time recommendation process.
3.3. Service Scenario of CIMS
This section explains the general process and core mechanisms of our proposed system (CIMS) with defined functions shown in
Table 1.
Table 1.
Explanation of terms.
| Terms | Explanation |
|---|
| MU | Mobile User |
| APP | Application |
| CS | Cloud Server |
| OFF | Offloading |
| DB | Data Base |
| RS | Recommendation System |
| DP | Distribution Process |
| RR | Real-Time Recommendation |
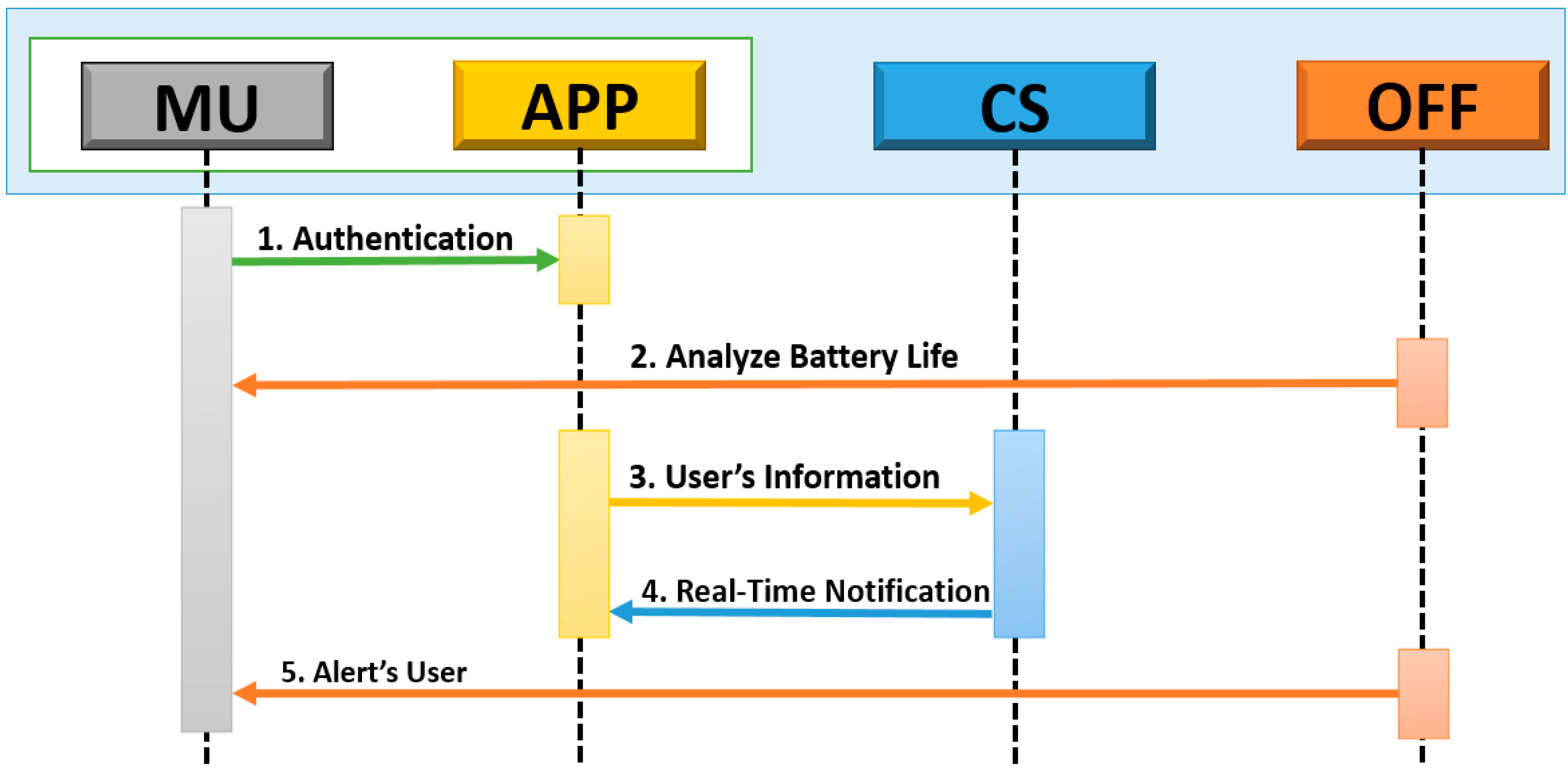
Figure 4 illustrates the general process of CIMS.
Figure 4.
General process of CIMS.
Step 1 MU→APP: Authentication
After installation of the application, the mobile user performs authentication with his/her personal username and password.
Step 2 OFF→MU: Analyze the Battery Life
An offloading process analyzes the battery life of the user’s mobile by using an energy model and allows the application to store user information to the cloud only if battery life is efficient.
Step 3 APP→CS: User Information
The user application collects information (i.e., context and multimedia contents) and stores it on the cloud server database.
Step 4 CS→APP: Real-Time Notification
With all users’ data, the cloud server performs its core operations to post updated notifications to a mobile user’s application in real time.
Step 5 OFF→MU: Alerts the User
The offloading system alerts the user while downloading large contents, to lessen the energy consumption based on the user context.
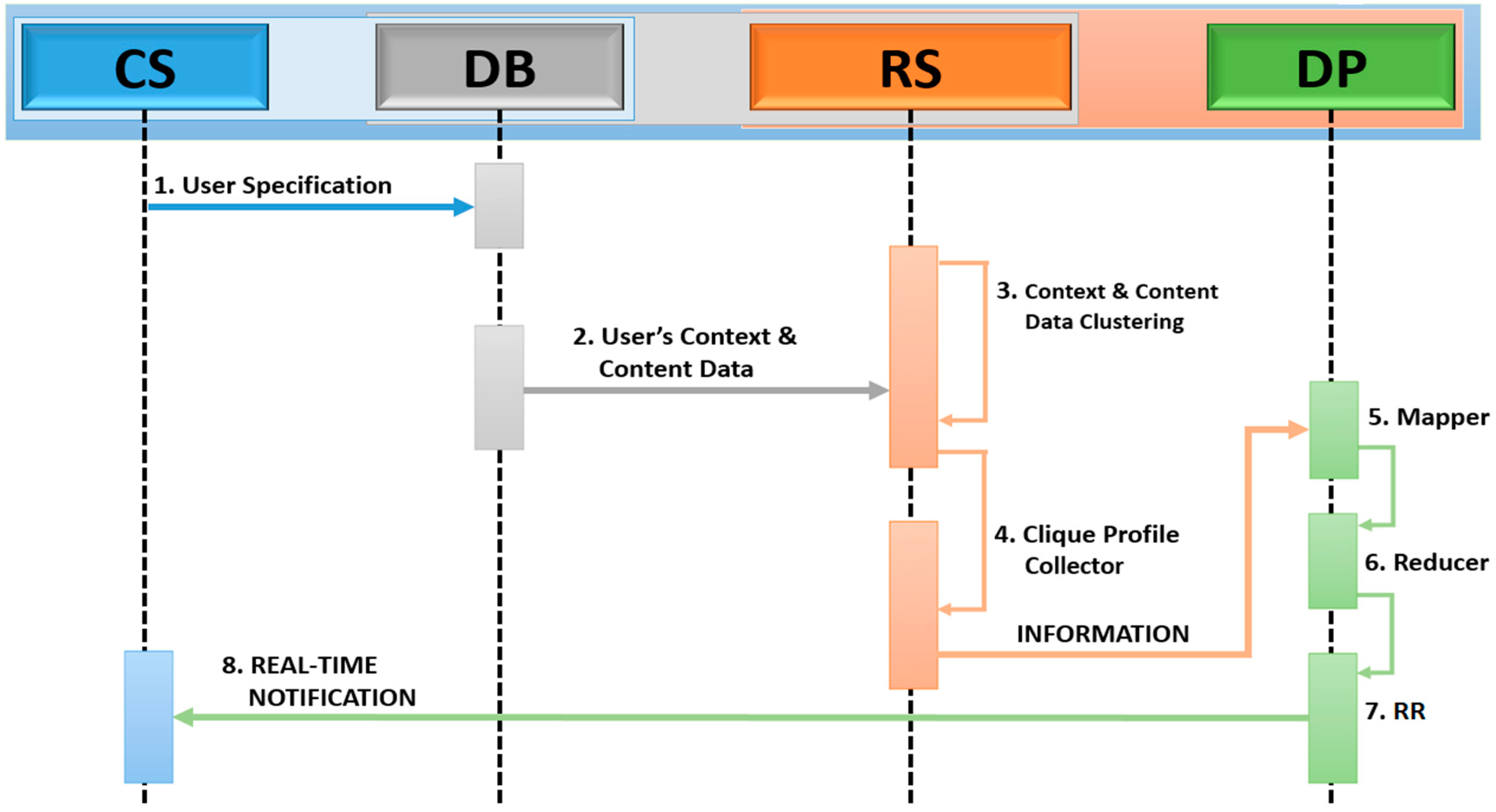
Figure 5 demonstrates the core mechanisms of our system (CIMS). After obtaining the user’s information, the cloud server uses the recommendation system to generalize about users’ similarities based on context and content information. The distribution system obtains the similarities between attributes to provide real-time notifications to mobile users.
Figure 5.
Core Mechanisms of CIMS.
Step 1 CS→DB: User Specification
The application requests the user to enter fields of interests, because without basic information it is very difficult for the server to analyze the user’s interests at this initial stage. Along with the user’s interests, his/her browsing data (i.e., context, multimedia contents) are stored to the cloud database.
Step 2 DB→RS: User’s Context and Content Data
A cloud database containing many users’ profiles with their context data and multimedia contents of interest is processed by the recommendation system.
Step 3 RS: Context and Content Data Clustering
K-means clustering first finds similarities in context and then proceeds for content information between many users.
Step 4 RS: Clique Profile Collector
A clustering process is performed between the context and multimedia contents of users’ data to form several groups of users based on their similarities.
Step 5 RS→DP: Mapper
Obtain Clique Profile information from RS for cluster mapping. Then the mapper computes user similarities based on attributes, arranges the user profiles according to high similarities, and organizes them into one cluster.
Step 6 DP: Reducer
The reducer performs similarly to the mapper, but to deepen the search it considers K clusters by mixing the KS profiles. If any similarities are found it will merge them; otherwise it updates the cluster.
Step 7 DP: Real-Time Recommendation (RR)
This can be obtained by analyzing user behavior in cloud-based clustering.
Step 8 DP→CS: Real-Time Notification
Recommendation rules (
Figure 8) help the cloud server to convey notifications to mobile users’ applications in real time by matching the user context in order.
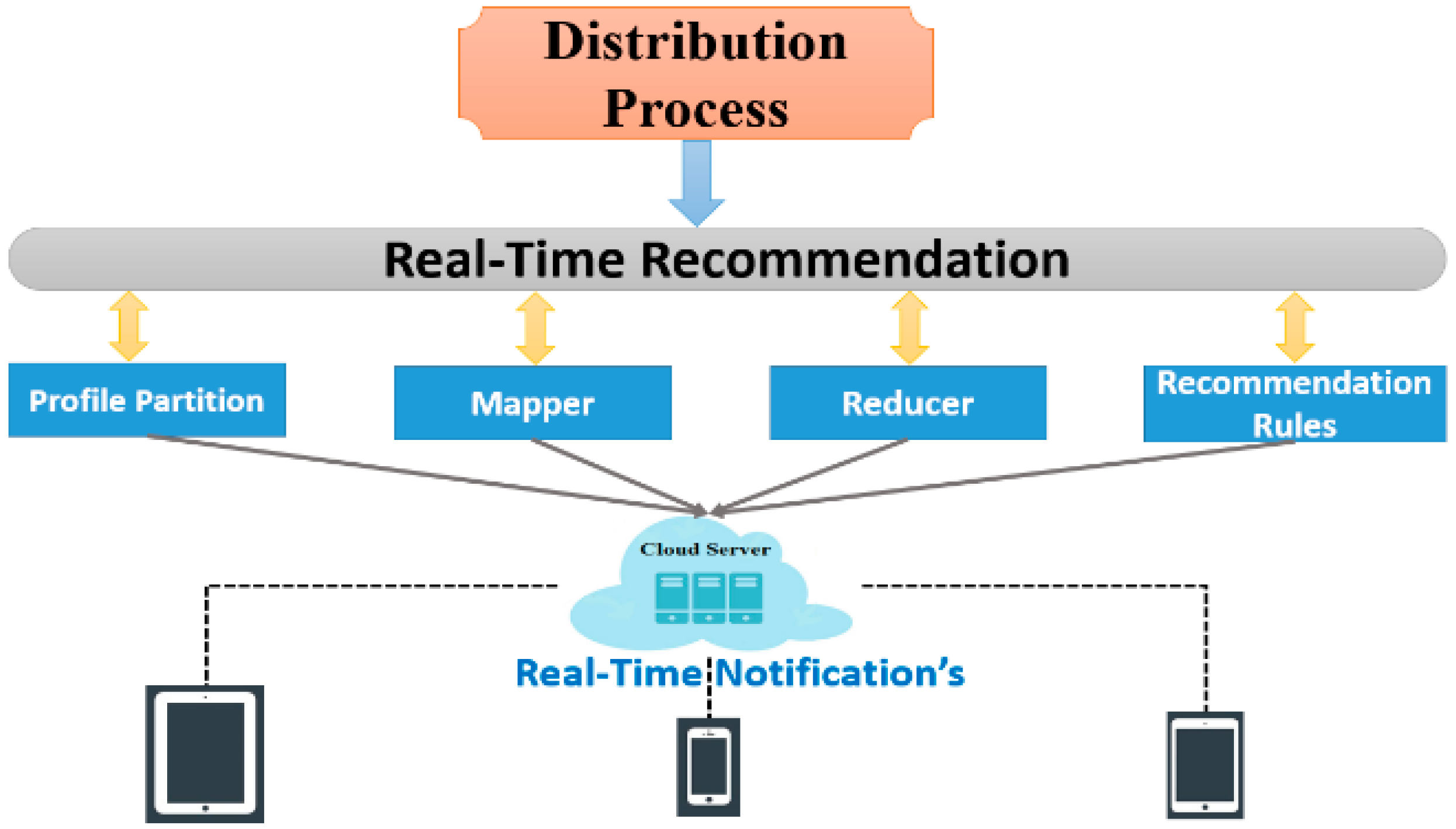
3.3.1. Distribution Process for CIMS Service
After obtaining recommendation results, the distribution process performs real-time recommendation (
i.e., time, location, and network) and automatically returns favorite notifications to the applications according to user profiles, as shown in
Figure 6. By having these recommendation rules, we ensure that user needs are met in real time. To reduce the burden for the recommendation system we include a profile partition using cluster mapping and a reducer to merge user profiles with similar interests in both context and multimedia contents. These functions reduce the computation and give real-time notifications to the mobile user. Clustering mappers are prompted as in
Figure 7, to process the partition profiles.
Figure 6.
Distribution Process Design.
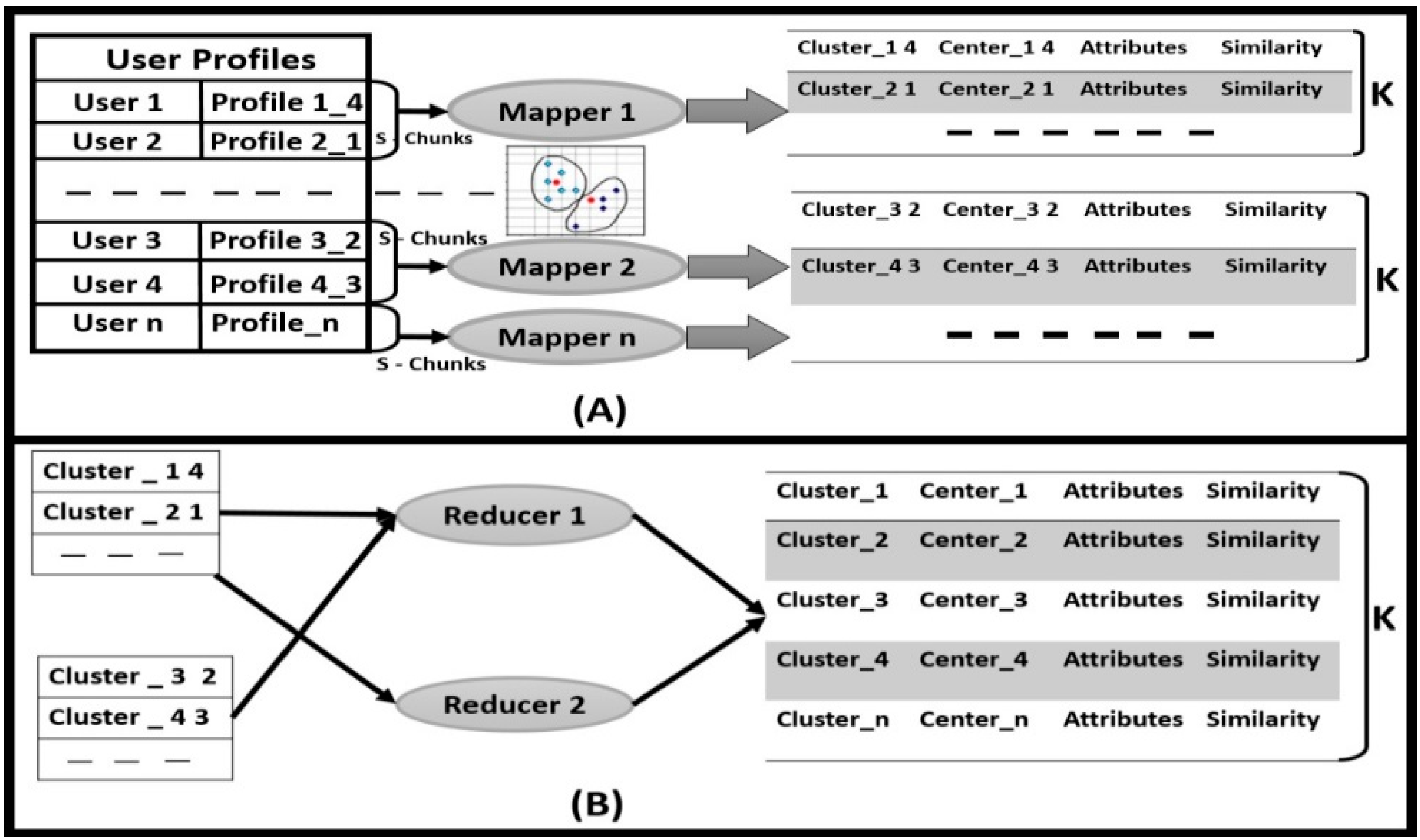
Figure 7.
K-Means Clustering Mapper & Reducer.
To compute similarities in attributes between user profiles at chunk-s, we employ a mapper in the distribution system to find the central point of
K clusters, as shown in
Figure 7A. For example, if many users in YouTube search for their favorite music, based on attributes (
i.e., key words, browsing history, location, time and network type) application stores the information on the cloud server in the user’s profile. The mapper computes the similarities between users based on attributes and arranges the user profiles linked by close similarities into one cluster. To minimize the memory size requirements, we re-choose the cluster central point
K and compare it with old clusters; if no matches exist, the mapper ends the task. Otherwise it updates the central point
K cluster to give surety and stability to the cluster.
The reducer is the final phase for lessening memory size in cloud servers. A mapper with a central profile acquires the K-clustering means of similarities by using profile attributes (
i.e., key words, browsing history, location, time, and network type). In the distribution system, after processing with the mapper, the reducer intermixes the KS profiles into single
K clusters, as shown in
Figure 7B. The reducer performs similarly to the mapper; taking a step in advance, it builds
K clusters by mixing the KS profiles, because user profile attributes with similarities are merged directly. Otherwise the reducer does the same job as the mapper, stabilizing the K-means clustering through iteration.
Real-time recommendation can be obtained by analyzing user behavior in cloud-based clustering. Example recommendation rules are shown in
Figure 8. The cloud-server notifies the user when new updates are available. For example, users often access the Google map application to reach their office, but the next day bus timings might have changed. Our real-time recommendation helps the user to get the notification in real time and thus choose another way to reach the office. The rules help the application server to convey the information at the right time by achieving the rules one by one in order by matching the user contexts. As we discussed before, the user context and interests change from day to day, so we should keep on updating recommendation rules to improve the real-time process.
Figure 8.
Recommendation Rules.
3.3.2. Offloading System
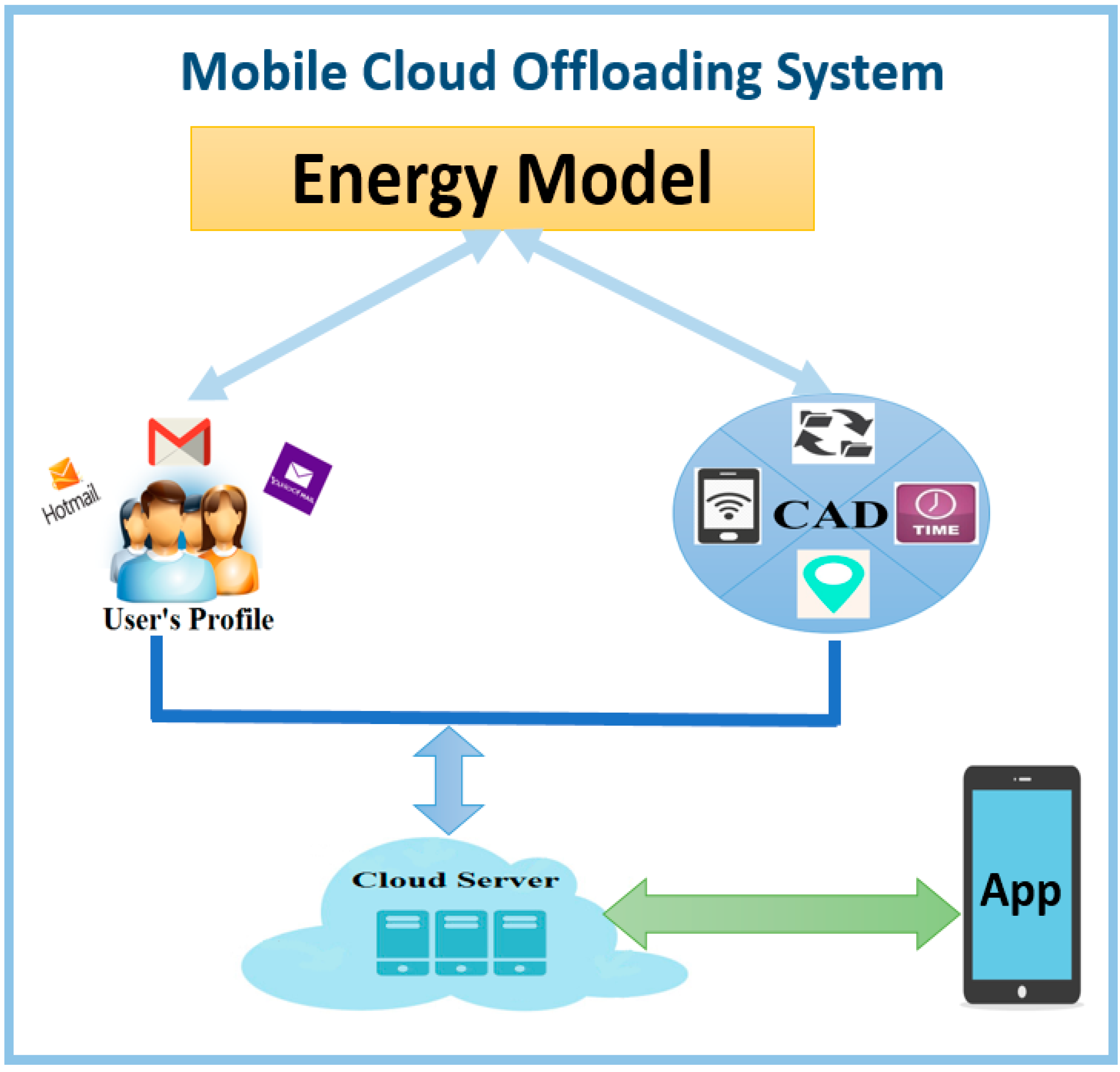
Mobile cloud computing appears to lessen the resource constrains of smart devices, but it suffers from continuously offloading actions as long as network is available. The process of offloading between the smart phone and the cloud server is shown in
Figure 9, which consists of three components: energy model, user profiler, and context-aware decision (CAD). We detail each component in the following subsections.
Several aspects underlying user profiles are required to process the offloading decisions. We assess four important contexts: (1) Network Signal—periodically collects the latest network signal (i.e., Wi-Fi, 3G/4G); (2) Transmission rate—by transmitting dummy data to/from cloud server, we measure the transmission time and energy estimation; (3) Time—by partitioning the 24 hours into time slots and recording the opportunities for offloading; (4) Location—obtaining a user’s geographical location by GPS every half an hour.
Figure 9.
Mobile Cloud Offloading System Design.
Considering the existing research on offloading systems, we strongly believe that power saving does not always happen while offloading to the cloud. For example, if a mobile performs offload computation, especially on a 3G/4G network, the transmission energy may be greater than consumption energy. However, a context-aware decision engine is deployed to lessen the energy consumption. We assess four important contexts—network signal, transmission rate, time, and location—in a CAD engine to measure a user’s regular behaviors, i.e. the places a user regularly visits at the same time, particularly on weekdays, thus accessing the same network conditions and applications. For example, user might go to the office Monday–Friday, 9 a.m. to 5 p.m., and go to the park on weekends from 5 p.m. to 8 p.m. Generally the wireless network (Wi-Fi) in an office will be sufficient for offloading computation, and power consumption does not matter. However, for a user in the park, a wireless network (3G/4G) is not as good as an office network. Based on users’ past context data, CAD executes the offloading process. Before calling up users’ data, CAD checks the present user’s context. If it is good enough, it will carry on; otherwise, it utilizes past execution costs.
Once the process of recommendation system, distribution process, and offloading mechanisms is executed, the costs including computing time, energy consumption, and time are recorded in a secure database in the cloud server. Our energy model estimates energy consumption using the above costs based on network signal, transmission rate, location, and time. We store all these context data in the user profile on the cloud sever. A CAD engine with context rules (
Figure 8) uses all this contextual information to perform offloading computation on a mobile device and returns the standard performance to the cloud. Another important point to bear in mind so as to avoid null results is that CAD requests information from the user at the initial stage.
3.4. Efficiency Analyses of CIMS
This section presents the efficiency of our proposed system, CIMS, and presents a comparative analysis with existing research models. We compare and analyze the recommendation and offloading systems, presented in
Section 2.1 [
1,
3,
6] with our proposed system. We obtain the following considerations for comparison analysis: computing process, data-base management, real-time processing, and power consumption.
Table 2 shows the analysis results.
Table 2.
Analyses of performance.
| Performance | CIMS | [1] | [3] | [6] |
|---|
| Computing Process | ⊙ | X | ∆ | ∆ |
| Data-Base Management | ⊙ | X | ∆ | X |
| Real-time Processing | ⊙ | ⊙ | ⊙ | X |
| Power Consumption | ⊙ | ∆ | X | X |
A resource-constrained mobile device refers to a cloud server over the Internet that is used to simplify the computing process. An offloading engine [
1] deploys a mobile and uses the CAD algorithm for offloading to cloud servers. The existing literature only considers video applications [
3,
6]. The recommendation system [
3] considers video sharing websites that collect user context, relationship, and profiles to generate multimedia recommendation rules. The recommendation system created by Go
et al. studies three user behaviors: favorites, uploads, and viewing of videos in YouTube [
6]. The proposed system conveys real time notifications to mobile user by obtaining the users’ profile, contexts, multimedia contents of interest, and attributes. The offloading engine in the cloud server performs offloading actions to/from the mobile user, based on the user’s context. The above factors are included in our system without user interaction via cloud computing, which reduces the high computation task for a smartphone.
Database management refers to how to reduce the database concerns in cloud servers in the upcoming years. Mo
et al. [
3] utilized user profiles to find content similarities between users; several communities were formed based on access patterns and content descriptions were mapped and clustering algorithms performed to obtain users’ similarities in content. Existing literature does not consider database management in the cloud server [
1,
6]. Our system performs K-means clustering on user profiles and procures similarities between user contexts and multimedia contents, and then we use a clique profile collector to acquire groups of user profiles with features in common. We use a reducer to deepen the search based on arranging highly similar user profiles into one cluster to reduce storage concerns for cloud servers.
Real-time processing is a must and should guarantee the quality of the user experience. Our proposed system and mobile cloud offloading engine [
1] perform similar actions, by notifying the user according to their contexts. A new user request is accepted by the real-time component and returns recommendation lists to the user [
3]. The component translates the request into recommendation rules on the basis of keywords and user context and then searches for user favorites according to those rules. By contrast, the proposed system makes it easier for the user, by collecting the user’s information and sending absolute notifications related to the mobile user’s profile to his/her applications in real time, from the cloud server. We employ the reducer in a distribution process to avoid collisions between several user profiles and impart absolute information in real time, based on the recommendation rules in
Figure 8.
Most smartphones with many multimedia applications continuously perform offloading actions when connected to a network, which leads to high power consumption. A mobile cloud offloading system [
1], on the other hand, decides whether to offload from cloud servers and evaluates the CAD algorithm for low power consumption. The existing literature does not review power consumption in smartphones [
3,
6]. However, in our system downloading as well as offloading are performed via the cloud server, relying on CAD with a user’s context to reduce the power consumption for mobile users. Therefore, the proposed system has better availability in ubiquitous cloud computing than the previously proposed schemes.


_Park.png)





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





